【重识云原生】第六章容器基础6.4.9.1节——Service综述
Service服务也是Kubernetes里的核心资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个微服务,受kube-proxy管理,运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。

1 Service概述
1.1 Service产生背景
在k8s中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。
为了解决这个问题,k8s提供了service资源,service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址。通过访问service的入口地址就能访问到后面的pod服务。
Service服务也是Kubernetes里的核心资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个微服务,受kube-proxy管理,运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。
随着 kubernetes 用户的激增,用户场景的不断丰富,又产生了一些新的负载均衡机制。目前,kubernetes 中的负载均衡大致可以分为以下几种机制,每种机制都有其特定的应用场景:
- Service:直接用 Service 提供 cluster 内部的负载均衡,并借助 cloud provider 提供的 LB 提供外部访问;
- Ingress Controller:还是用 Service 提供 cluster 内部的负载均衡,但是通过自定义 Ingress Controller 提供外部访问;
- Service Load Balancer:把 load balancer 直接跑在容器中,实现 Bare Metal 的 Service Load Balancer;
- Custom Load Balancer:自定义负载均衡,并替代 kube-proxy,一般在物理部署 Kubernetes 时使用,方便接入公司已有的外部服务;
1.2 Services 和 Pods
Kubernetes Pods是有生命周期的。他们可以被创建,而且销毁不会再启动。如果您使用Deployment来运行您的应用程序,则它可以动态创建和销毁 Pod。
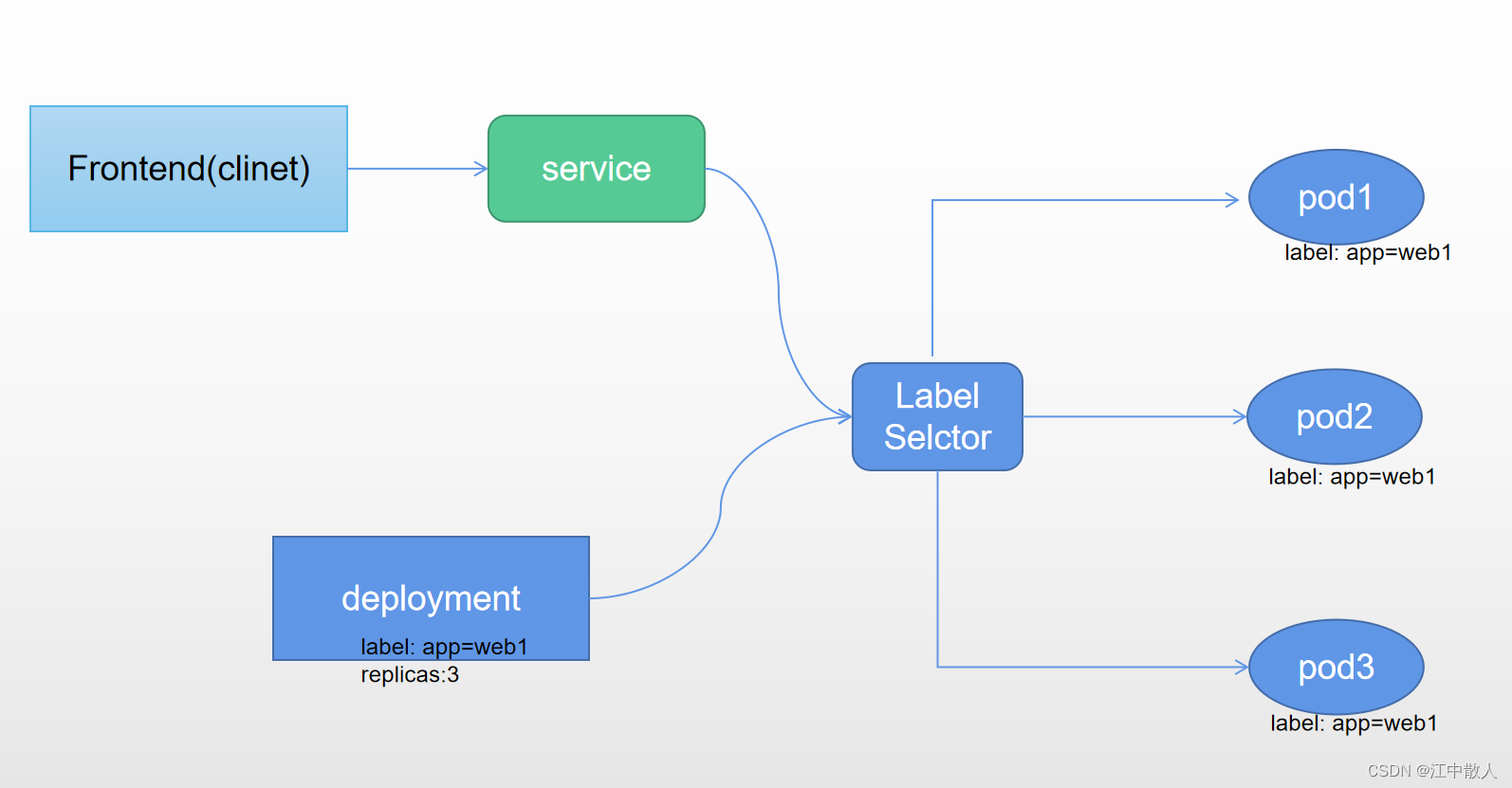
一个Kubernetes的Service是一种抽象,它定义了一组Pods的逻辑集合和一个用于访问它们的策略 - 有的时候被称之为微服务。一个Service的目标Pod集合通常是由Label Selector 来决定的(下面有讲一个没有选择器的Service 有什么用处)。
举个例子,想象一个处理图片的后端运行了三个副本。这些副本都是可以替代的 - 前端不关心它们使用的是哪一个后端。尽管实际组成后端集合的Pod可能会变化,前端的客户端却不需要知道这个变化,也不需要自己有一个列表来记录这些后端服务。Service抽象能让你达到这种解耦。
不像 Pod 的 IP 地址,它实际路由到一个固定的目的地,Service 的 IP 实际上不能通过单个主机来进行应答。相反,我们使用 iptables(Linux 中的数据包处理逻辑)来定义一个虚拟IP地址(VIP),它可以根据需要透明地进行重定向。当客户端连接到 VIP 时,它们的流量会自动地传输到一个合适的 Endpoint。环境变量和 DNS,实际上会根据 Service 的 VIP 和端口来进行填充。
kube-proxy支持三种代理模式: 用户空间,iptables和IPVS;它们各自的操作略有不同。


可以看到上面的架构图,service服务通过标签选择器定位后端pod,前提是service的selector必须和后端Pod标签对应上才能找到相对应的Pod,而前端frontend通过service就可以访问到后端提供服务的pod了,而service默认IP类型主要分为:
- ClusterIP:主要是为集群内部提供访问服务的;(默认类型)
- NodePort:可以被集群外部所访问,访问方式为宿主机:端口号;
- LoadBalancer:在NodePort的基础上,借助cloud provider(云提供商)创建一个外部负载均衡器并将请求转发到NodePort;
- ExternalName:把集群外部的访问引入到集群内部来,在集群内部直接使用,没有任何代理被创建;
当Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的Cluster IP不会发生改变,service会通过标签选择器与后端的pod进行连接并被kubo-proxy监控,当后端pod被重建时会通过标签自动加入到对应的service服务中,从而避免失联。
1.3 如何通过Service访问Pod
有两种方式:选择算符的Service和没有选择算符的Service;
1.3.1 选择算符的Service
这是最常见的方式,指定 spec.selector即通过打标签的方式,主要是针对集群内部同命名空间的Pod:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376创建上面的Service,会自动创建相应的 Endpoint 对象。
kubectl describe ep/my-service查看自动创建的Endpoint对象:
...
Subsets:
Addresses: 10.244.2.1,10.244.4.1
...1.3.2 没有选择算符的Service
主要是针对希望服务指向另一个名字空间或者其他集群中的服务,比如外部的ES集群:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376此服务没有选择算符,因此不会自动创建相应的 Endpoint 对象, 需要手动添加 Endpoint 对象,将服务手动映射到运行该服务的网络地址和端口。
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- ip: 192.0.2.42
ports:
- port: 9376不管哪种方式最终请求都是被路由到Endpoint,通过Endpoint进行访问处理的,详见下文的访问实现原理
1.4 service三种代理模式
1.4.1 userspace

这种模式(v1.2版本之前的默认模式),kube-proxy 会监视 Kubernetes 控制平面对 Service 对象和 Endpoints 对象的添加和移除操作。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的后端 Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个后端 Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
说明:userspace是在用户空间,通过kube-proxy来实现service的代理服务,service的请求会先从用户空间进入内核iptables,然后再回到用户空间,由kube-proxy完成后端Endpoints的选择和代理工作,这样流量从用户空间进出内核带来的性能损耗是不可接受的,因此这种方式已经不用了。
1.4.2 iptables

这种模式,kube-proxy 会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会配置 iptables 规则,从而捕获到达该 Service 的 clusterIP 和端口的请求,进而将请求重定向到 Service 的一组后端中的某个 Pod 上面。 对于每个 Endpoints 对象,它也会配置 iptables 规则,这个规则会选择一个后端组合。
默认的策略是,kube-proxy 在 iptables 模式下随机选择一个后端。
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败, 并会自动使用其他后端 Pod 重试。
你可以使用 Pod 就绪探测器 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着你避免将流量通过 kube-proxy 发送到已知已失败的 Pod。
1.4.3 ipvs
在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端 Pod 之一。
IPVS 代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 提供了更多选项来平衡后端 Pod 的流量。这些是:
- rr:轮替(Round-Robin)
- lc:最少链接(Least Connection),即打开链接数量最少者优先
- dh:目标地址哈希(Destination Hashing)
- sh:源地址哈希(Source Hashing)
- sed:最短预期延迟(Shortest Expected Delay)
- nq:从不排队(Never Queue)说明:
要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前使 IPVS 在节点上可用。
当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。

在这些代理模型中,绑定到服务 IP 的流量: 在客户端不了解 Kubernetes 或服务或 Pod 的任何信息的情况下,将 Port 代理到适当的后端。
如果要确保每次都将来自特定客户端的连接传递到同一 Pod, 则可以通过将 service.spec.sessionAffinity 设置为 "ClientIP" (默认值是 "None"),来基于客户端的 IP 地址选择会话亲和性。 你还可以通过适当设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 来设置最大会话停留时间。(默认值为 10800 秒,即 3 小时)。
说明: 在 Windows 上,不支持为服务设置最大会话停留时间。
1.5 服务发布(服务类型)
1.5.1 VIP 和 Service 代理
在 Kubernetes集群中,每个 Node运行一个 kube-proxy进程。 kube-proxy负责为 Service实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName的形式。在 Kubernetes v1.0版本,代理完全在 userspace。在 Kubernetes v1.1版本,新增了 iptables代理,但并不是默认的运行模式。从 Kubernetes v1.2起,默认就是 iptables代理。在 Kubernetes v1.8.0-beta.0中,添加了 ipvs代理。在 Kubernetes 1.14版本开始默认使用 ipvs代理。
在 Kubernetes v1.0版本, Service是 4 层( TCP/ UDP over IP)概念。在 Kubernetes v1.1版本,新增了 Ingress API( beta版),用来表示 7 层( HTTP)服务为何不使用 round-robin DNS?
DNS会在很多的客户端里进行缓存,很多服务在访问 DNS进行域名解析完成、得到地址后不会对 DNS的解析进行清除缓存的操作,所以一旦有他的地址信息后,不管访问几次还是原来的地址信息,导致负载均衡无效。
1.5.2 ClusterIp
k8s默认的ServiceType,通过集群内的ClusterIP在内部发布服务,Service创建时会自动分配一个仅Cluster内部可以访问的虚拟IP。

ClusterIP主要在每个node节点使用iptables,将发向ClusterIP对应端口的数据,转发到kube-proxy中。然后kube-proxy自己内部实现有负载均衡的方法,并可以查询到这个service下对应pod的地址和端口,进而把数据转发给对应的pod的地址和端口。

为了实现图上的功能,主要需要以下几个组件的协同工作:
- apiserver:用户通过 kubectl命令向 apiserver发送创建 service的命令, apiserver接收到请求后将数据存储到 etcd中;
- kube-proxy: Kubernetes的每个节点中都有一个叫做 kube-porxy的进程,这个进程负责感知 service、 pod的变化,并将变化的信息写入本地的 iptables规则中;
- iptables:使用 NAT等技术将 virtualIP的流量转至 endpoint中;
创建 myapp-deploy.yaml文件

创建 Service信息:

执行命令:

1.5.3 Handless Service
有时不需要或不想要负载均衡,以及单独的 Service IP。遇到这种情况,可以通过指定 spec.clusterIP的值为 None来创建 Headless Service 。这类 Service并不会分配 Cluster IP, kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。

1.5.4 NodePort
用来对集群外暴露Service,你可以通过访问集群内的每个NodeIP:NodePort的方式,访问到对应Service后端的Endpoint。此机制是在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过NodeIP: NodePort来访问该服务。

创建 Service信息:

执行命令:

1.5.4 LoadBalancer
这也是用来对集群外暴露服务的,不同的是这需要借助Cloud Provider提供一个外部负载均衡器,并将请求转发到NodePort,比如AWS等。

1.5.5 ExternalName
这个也是在集群内发布服务用的,需要借助KubeDNS(version >= 1.7)的支持,就是用KubeDNS将该service和ExternalName做一个Map,KubeDNS返回一个CNAME记录。
这种类型的 Service通过返回 CNAME和它的值,可以将服务映射到 externalName字段的内容( 例: hub.hc.com )。
ExternalName Service是 Service的特例,它没有 selector,也没有定义任何的端口和 Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。

当查询主机 my-service.defalut.svc.cluster.local时,集群的 DNS服务将返回一个值 hub.hc.com的 CNAME记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS层,而且不会进行代理或转发。
每种服务类型都是会指定一个clusterIP的,由clusterIP进入对应代理模式实现负载均衡,如果强制 spec.clusterIP: "None"(即headless service),集群无法为它们实现负载均衡,直接通过Pod域名访问Pod,典型是应用是StatefulSet。
1.6 Service的域名访问
上面讲的Pod之间调用,采用Service进行抽象,服务之间可以通过clusterIP 进行访问调用,不用担心Pod的销毁重建带来IP变动,同时还能实现负载均衡。但是clusterIP也是有可能变动,况且采用IP访问始终不是一种好的方式。通过DNS和环境变量可以实现通过服务名来访问。
1.6.1 DNS
k8s采用附加组件(CoreDNS)为集群提供DNS服务,会为每个服务创建DNS记录,CoreDNS只为Service和Pod创建DNS记录。kubernetes强烈推荐采用DNS方式。
例如,如果你在 Kubernetes 命名空间 my-ns 中有一个名为 my-service 的服务, 则控制平面和 DNS 服务共同为 my-service.my-ns 创建 DNS 记录。 my-ns 命名空间中的 Pod 应该能够通过按名检索 my-service 来找到服务,其他命名空间中的 Pod 必须将名称限定为 my-service.my-ns。 这些名称将解析为为服务分配的集群 IP。
Kubernetes 还支持命名端口的 DNS SRV(服务)记录。 如果 my-service.my-ns 服务具有名为http的端口,且协议设置为 TCP, 则可以对 _http._tcp.my-service.my-ns 执行 DNS SRV 查询查询以发现该端口号, "http" 以及 IP 地址。
1.6.2 环境变量
当 Pod 运行在 Node上,kubelet 会为每个活跃的 Service 添加一组环境变量。 简单的 {SVCNAME}_SERVICE_HOST 和 {SVCNAME}_SERVICE_PORT 变量。 这里 Service 的名称需大写,横线被转换成下划线。
举个例子,一个名称为 nginx-svc 的 Service 暴露了 TCP 端口 8080, 同时给它分配了 Cluster IP 地址 10.0.0.11,这个 Service 生成了如下环境变量:
进入example容器,env打印环境变量:
NGINX_SVC_SERVICE_HOST=10.0.0.11
NGINX_SVC_SERVICE_PORT=8080
NGINX_SVC_PORT=tcp://10.0.0.11:8080
NGINX_SVC_PORT_8080_TCP=tcp://10.0.0.11:8080
NGINX_SVC_PORT_8080_TCP_PROTO=tcp
NGINX_SVC_PORT_8080_TCP_PORT=8080
NGINX_SVC_PORT_8080_TCP_ADDR=10.0.0.11访问Nginx服务可以使用
curl http://${NGINX_SVC_SERVICE_HOST}:${NGINX_SVC_SERVICE_PORT}当你创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。需要注意: 要想一个Pod中注入某个Service的环境变量,则必须Service要先比该Pod创建
1.7 多端口 Service
对于某些服务,你需要公开多个端口。 Kubernetes 允许你在 Service 对象上配置多个端口定义。 为服务使用多个端口时,必须提供所有端口名称,以使它们无歧义。 例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377说明:
与一般的Kubernetes名称一样,端口名称只能包含小写字母数字字符 和 -。 端口名称还必须以字母数字字符开头和结尾。例如,名称 123-abc 和 web 有效,但是 123_abc 和 -web 无效。
1.8 选择自己的 IP 地址
在 Service 创建的请求中,可以通过设置 spec.clusterIP 字段来指定自己的集群 IP 地址。 比如,希望替换一个已经已存在的 DNS 条目,或者遗留系统已经配置了一个固定的 IP 且很难重新配置。
用户选择的 IP 地址必须合法,并且这个 IP 地址在 service-cluster-ip-range CIDR 范围内, 这对 API 服务器来说是通过一个标识来指定的。 如果 IP 地址不合法,API 服务器会返回 HTTP 状态码 422,表示值不合法。
1.9 流量策略
1.9.1 外部流量策略
你可以通过设置 spec.externalTrafficPolicy 字段来控制来自于外部的流量是如何路由的。 可选值有 Cluster 和 Local。字段设为 Cluster 会将外部流量路由到所有就绪的端点, 设为 Local 会只路由到当前节点上就绪的端点。 如果流量策略设置为 Local,而且当前节点上没有就绪的端点,kube-proxy 不会转发请求相关服务的任何流量。
说明:特性状态:
Kubernetes v1.22 [alpha]
如果你启用了 kube-proxy 的 ProxyTerminatingEndpoints 特性门控, kube-proxy 会检查节点是否有本地的端点,以及是否所有的本地端点都被标记为终止中。
如果本地有端点,而且所有端点处于终止中的状态,那么 kube-proxy 会忽略任何设为 Local 的外部流量策略。 在所有本地端点处于终止中的状态的同时,kube-proxy 将请求指定服务的流量转发到位于其它节点的状态健康的端点, 如同外部流量策略设为 Cluster。
针对处于正被终止状态的端点这一转发行为使得外部负载均衡器可以优雅地排出由 NodePort 服务支持的连接,就算是健康检查节点端口开始失败也是如此。 否则,当节点还在负载均衡器的节点池内,在 Pod 终止过程中的流量会被丢掉,这些流量可能会丢失。
1.9.2 内部流量策略
特性状态: Kubernetes v1.22 [beta]
你可以设置 spec.internalTrafficPolicy 字段来控制内部来源的流量是如何转发的。可设置的值有 Cluster 和 Local。 将字段设置为 Cluster 会将内部流量路由到所有就绪端点,设置为 Local 只会路由到当前节点上就绪的端点。 如果流量策略是 Local,而且当前节点上没有就绪的端点,那么 kube-proxy 会丢弃流量。
参考链接
详解k8s的4种Service类型_Dark_Ice_的博客-CSDN博客_k8s service类型
k8s之Service_江南道人的博客-CSDN博客_k8s查看service
K8S之Service详解_运维@小兵的博客-CSDN博客_k8sservice
k8s之Service详解-Service介绍 - 路过的柚子厨 - 博客园
《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第二章计算第2节——主流虚拟化技术之VMare ESXi
- 第二章计算第3节——主流虚拟化技术之Xen
- 第二章计算第4节——主流虚拟化技术之KVM
- 第二章计算第5节——商用云主机方案
- 第二章计算第6节——裸金属方案
- 第三章云存储第1节——分布式云存储总述
- 第三章云存储第2节——SPDK方案综述
- 第三章云存储第3节——Ceph统一存储方案
- 第三章云存储第4节——OpenStack Swift 对象存储方案
- 第三章云存储第5节——商用分布式云存储方案
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4.1-2节——OSPF协议综述
- 第四章云网络4.3.4.3节——OSPF协议工作原理
- 第四章云网络4.3.4.4节——[转载]OSPF域内路由
- 第四章云网络4.3.4.5节——[转载]OSPF外部路由
- 第四章云网络4.3.4.6节——[转载]OSPF特殊区域之Stub和Totally Stub区域详解及配置
- 第四章云网络4.3.4.7节——OSPF特殊区域之NSSA和Totally NSSA详解及配置
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
-
第六章容器基础6.4.10.4节——StatefulSet实操案例-使用 StatefulSet 部署Cassandra

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)