
ChatGPT技术报告
ChatGPT技术报告
ChatGPT是一个由OpenAI开发的大型语言模型,是GPT(Generative Pretrained Transformer)系列模型的一部分。它使用了 Transformer 架构,并在大量的文本数据上进行了预训练。预训练的目的是使模型能够从大量的文本中学习语言知识和模式,从而在接下来的任务中更好地进行语言生成。
ChatGPT 的应用领域广泛,包括聊天机器人,问答系统,文本生成,语音识别等。在聊天机器人领域,ChatGPT可以提供人类般的自然语言回答,并且在语法和语义方面的表现十分出色。
- GPT发展历程
Generative Pre-trained Transformer (GPT),是一种基于互联网可用数据训练的文本生成深度学习模型。它用于问答、文本摘要生成、机器翻译、分类、代码生成和对话 AI。
1.GPT-1
2018 年,GPT-1 诞生,这一年也是 NLP(自然语言处理)的预训练模型元年。性能方面,GPT-1 有着一定的泛化能力,能够用于和监督任务无关的 NLP 任务中。其常用任务包括:
- 自然语言推理:判断两个句子的关系(包含、矛盾、中立)
- 问答与常识推理:输入文章及若干答案,输出答案的准确率
- 语义相似度识别:判断两个句子语义是否相关
- 分类:判断输入文本是指定的哪个类别
虽然 GPT-1 在未经调试的任务上有一些效果,但其泛化能力远低于经过微调的有监督任务,因此 GPT-1 只能算得上一个还算不错的语言理解工具而非对话式 AI。
2.GPT-2
GPT-2 也于 2019 年如期而至,不过,GPT-2 并没有对原有的网络进行过多的结构创新与设计,只使用了更多的网络参数与更大的数据集:最大模型共计 48 层,参数量达 15 亿,学习目标则使用无监督预训练模型做有监督任务。在性能方面,除了理解能力外,GPT-2 在生成方面第一次表现出了强大的天赋:阅读摘要、聊天、续写、编故事,甚至生成假新闻、钓鱼邮件或在网上进行角色扮演通通不在话下。在“变得更大”之后,GPT-2 的确展现出了普适而强大的能力,并在多个特定的语言建模任务上实现了彼时的最佳性能。
3.GPT-3
之后,GPT-3 出现了,作为一个无监督模型,几乎可以完成自然语言处理的绝大部分任务,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答等等。而且,该模型在诸多任务上表现卓越,例如在法语-英语和德语-英语机器翻译任务上达到当前最佳水平,自动产生的文章几乎让人无法辨别出自人还是机器,更令人惊讶的是在两位数的加减运算任务上达到几乎 100% 的正确率,甚至还可以依据任务描述自动生成代码。一个无监督模型功能多效果好,似乎让人们看到了通用人工智能的希望,这就是 GPT-3 影响如此之大的主要原因。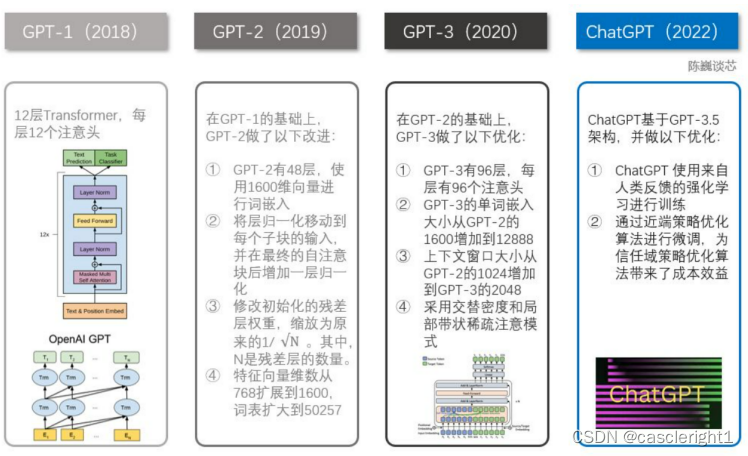
由于 GPT-3 更强的性能和明显更多的参数,它包含了更多的主题文本,显然优于前代的 GPT-2 。作为目前最大的密集型神经网络,GPT-3 能够将网页描述转换为相应代码、模仿人类叙事、创作定制诗歌、生成游戏剧本,甚至模仿已故的各位哲学家——预测生命的真谛。且 GPT-3 不需要微调,在处理语法难题方面,它只需要一些输出类型的样本(少量学习)。可以说 GPT-3 似乎已经满足了我们对于语言专家的一切想象。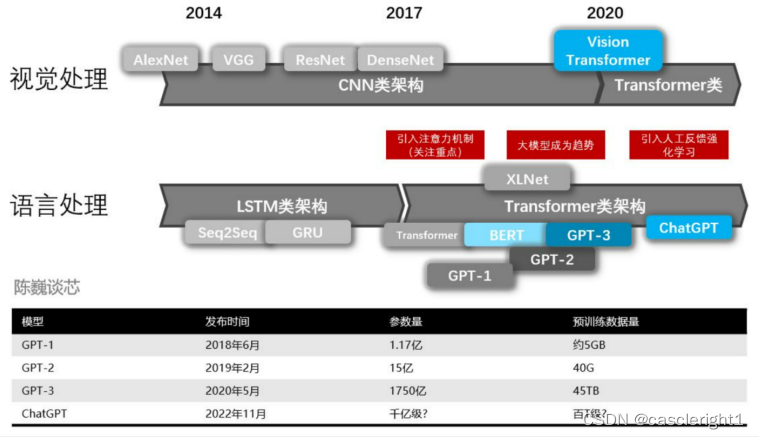
- ChatGPT“前身”InstructGPT
InstructGPT 的工作原理是开发人员通过结合监督学习+从人类反馈中获得的强化学习。来提高 GPT-3 的输出质量。在这种学习中,人类对模型的潜在输出进行排序;强化学习算法则对产生类似于高级输出材料的模型进行奖励。开发人员将提示分为三个部分,并以不同的方式为每个部分创建响应:人类作家会对第一组提示做出响应。开发人员微调了一个经过训练的 GPT-3 ,将它变成 InstructGPT 以生成每个提示的现有响应。
下一步是训练一个模型,使其对更好的响应做出更高的奖励。对于第二组提示,经过优化的模型会生成多个响应。人工评分者会对每个回复进行排名。在给出一个提示和两个响应后,一个奖励模型(另一个预先训练的 GPT-3)学会了为评分高的响应计算更高的奖励,为评分低的回答计算更低的奖励。
开发人员使用第三组提示和强化学习方法近端策略优化(Proximal Policy Optimization, PPO)进一步微调了语言模型。给出提示后,语言模型会生成响应,而奖励模型会给予相应奖励。PPO 使用奖励来更新语言模型。
二、ChatGPT的技术原理
总体来说,Chatgpt 和 InstructGPT 一样,是使用 RLHF(从人类反馈中强化学习)训练的。不同之处在于数据是如何设置用于训练(以及收集)的。
ChatGPT是一个大型语言模型,由OpenAI训练,具有高效的语言处理能力。它的底层原理主要包括三个方面:Transformer架构、自注意力机制和预训练。
- Transformer架构:Transformer是一种用于处理序列数据(如文本)的神经网络架构,是在自注意力机制的基础上构建的。编码器和解码器是它的两个主要组成部分,分别用于处理输入数据和生成输出数据。
- 自注意力机制:自注意力机制是Transformer架构的核心,它通过编码输入单元并计算每个输入单元与每个输出单元的相关性,来实现对输入数据的分析。
- 预训练:预训练是一个在大量文本数据上训练语言模型的过程。通过预测文本中下一个词语的概率,模型学习语言的语法、语义和模式。预训练后的模型可以在新的数据上获得更好的表现。
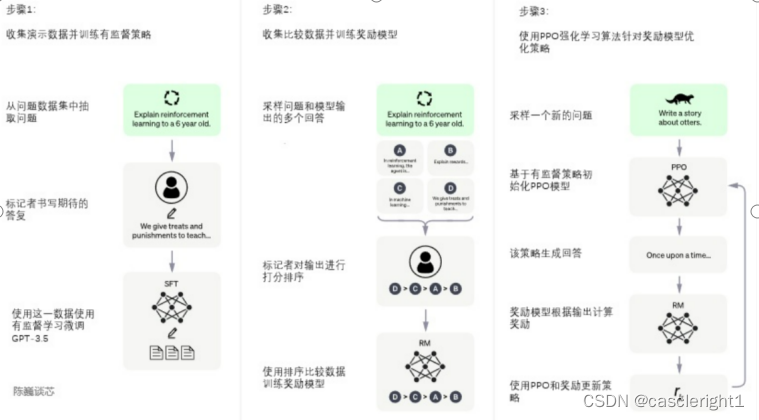
ChatGPT的训练过程分为以下三个阶段:
第一阶段:训练监督策略模型
GPT3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由人类标注人员,给出高质量答案,然后用这些人工标注好的数据来微调GPT-3.5模型(获得SFT模型,Supervised Fine-Tuning) 。此时的SFT模型在遵循指令/对话方面已经优于GPT-3,但不一定符合人类偏好。
第二阶段:训练奖励模型(Reward Mode,RM)
这个阶段的主要是通过人工标注训练数据(约33K个数据),来训练回报模型。在数据集中随机抽取问题,使用第一阶段生成的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑给出排名顺序。这一过程类似于教练或老师辅导。
接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
第三阶段:采用PPO(Proximal Policy Optimization,近端策略优化)强化学习来优化策略。
PPO的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为lmportance Sampling。这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM模型给出质量分数。把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)