Springboot整合Tess4J在Linux上运行OCR识别
我需要使用整合进项目中进行OCR识别图像中的文字,然后发现了这个整合包。然后我引入这个的时候发现本地环境下可以直接运行,环境下就初始化失败。网上找了各类相关文章,踩了不少坑,特此记录下如何整合并成功运行。
1.前言
我需要使用Tessract整合进Springboot项目中进行OCR识别图像中的文字,然后发现了Tess4J这个整合包。然后我引入这个Tess4J的时候发现本地Window环境下可以直接运行,Linux环境下就初始化失败。网上找了各类相关文章,踩了不少坑,特此记录下如何整合并成功运行。
2.引入pom文件
<!-- Tess4J是对Tesseract OCR API.的Java JNA 封装。使java能够通过调用Tess4J的API来使用Tesseract OCR。支持的格式:TIFF,JPEG,GIF,PNG,BMP,JPEG,and PDF -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.1</version>
</dependency>
3.Linux需要安装对应的Tesseract响应的环境
由于tess4j是对tesseract的封装,tesseract又依赖于leptonica。所以我们需要先安装好tesseract与leptonica。
3.1安装依赖,最基本的环境
yum install autoconf automake libtool libjpeg-devel libpng-devel libtiff-devel zlib-devel gcc gcc-c++
3.2 提前下载好两个文件
通过下方传送门下载
leptonica-1.79.0.tar.gz
tesseract-4.1.1.tar.gz
下载好后放在自己定义好的服务器文件夹中。这里我们放到/usr/local/下。
3.3安装两个文件命令
linux下执行命令
cd /usr/local
mkdir /usr/local/leptonica
tar -xzvf leptonica-1.79.0.tar.gz
cd leptonica-1.79.0
./configure --prefix=/usr/local/leptonica && make && make install
cd /usr/local
mkdir /usr/local/tesseract
tar -xzvf 4.1.1.tar.gz
cd tesseract-4.1.1
# 必须先运行autogen.sh文件才会有configuer文件
./autogen.sh
# 编译安装到指定文件夹
./configure --prefix=/usr/local/tesseract && make && make install
配置leptonica环境变量
执行命令
vim /etc/profile
在文件末尾追加配置
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/leptonica/lib/pkgconfig
export PKG_CONFIG_PATH
CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/leptonica/include/leptonica
export CPLUS_INCLUDE_PATH
C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/leptonica/include/leptonica
export C_INCLUDE_PATH
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/leptonica/lib
export LD_LIBRARY_PATH
LIBRARY_PATH=$LIBRARY_PATH:/usr/local/leptonica/lib
export LIBRARY_PATH
LIBLEPT_HEADERSDIR=/usr/local/leptonica/include/leptonica
export LIBLEPT_HEADERSDIR
现在可以去下载自己需要的识别库,后期将自己训练的识别库放到这个初始化目录下就行。前期我们用官方默认的识别库。所有的识别库地址:https://github.com/tesseract-ocr/tessdata
我只需要中文识别库,所以下面通过中文识别库举例。
点击下载中文简体语言库chi_sim.traineddata,上传到 /usr/local/tesseract/share/tessdata/目录。
若是java项目中已经使用了识别库,不需要再下载,只需要下一步配置时配置到java中使用的目录地址即可。
3.4配置tesseract环境变量
vim /etc/profile
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/leptonica/lib:/usr/local/tesseract/lib
export LD_LIBRARY_PATH
LIBRARY_PATH=$LIBRARY_PATH:/usr/local/leptonica/lib:/usr/local/tesseract/lib
export LIBRARY_PATH
LIBLEPT_HEADERSDIR=/usr/local/leptonica/include/leptonica
export LIBLEPT_HEADERSDIR
PATH=$PATH:/usr/local/tesseract/bin
export PATH
export TESSDATA_PREFIX=/usr/local/xxx/xxxx ##注意:该位置是训练库所在文件目录
export PATH=$PATH:$TESSDATA_PREFIX
再输入生效配置命令
source /etc/profile
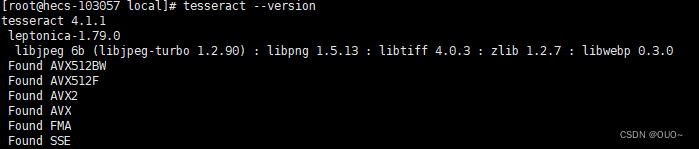
3.5测试安装是否成功
tesseract --version
控制台出现tesseract版本号和leptonica版本号就算成功了

4.Springboot项目配置
完成了上面的环境基础后,我们回到项目里来,有两个文件得从安装tesseract后的lib文件夹里面获取

这两文件需要下载下来,然后放到项目resources中再打包成jar包

。然后我们就可以选择两种,我没有去配置Datapath。因为我发现Tess4J封装源码可以选默认路径。如下图。如果配置环境变量TESSDATA_PREFIX理论上也是可以访问到tesseract。我选第二种,就是将训练库模型放到jar同级目录下也是能直接调用

服务器项目与训练库文件路径如下图

调用代码成功图片

借鉴文章
https://blog.csdn.net/Princeliu999/article/details/130953176
https://blog.csdn.net/weixin_47914635/article/details/128715110
https://blog.csdn.net/weixin_45822002/article/details/132606562?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-1-132606562-blog-128715110.235v38pc_relevant_sort_base1&spm=1001.2101.3001.4242.2&utm_relevant_index=4

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)