人工智能(二)-Transformer模型
上篇文章以对话模式为例讲了目前人工智能的整体架构,但是大模型依然有很多细节问题,这里作者讲一讲目前的Transformers模型原理。
一、引言
上篇文章以对话模式为例讲了目前人工智能的整体架构,但是大模型依然有很多细节问题,这里作者讲一讲目前的Transformers模型原理。
二、简介
1、什么是Transformer
Transformers模型是一种特定的神经网络架构,他可以使用深度学习框架提供的功能来训练模型,并在验证集和测试集上评估模型的性能。
研究者和开发者通常会使用预构建的Transformers库,如Hugging Face的Transformers库。这个库提供了大量预训练的Transformers模型,以及用于构建、训练和部署这些模型的工具。
举例,怎么用几行代码加载一个预训练的BERT模型
rom transformers import BertTokenizer, BertModel# 加载预训练的BERT模型及其分词器tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertModel.from_pretrained('bert-base-uncased')# 准备输入文本text = "Here is some text to encode"# 使用分词器对文本进行编码,然后转换为PyTorch张量inputs = tokenizer(text, return_tensors="pt")# 获取编码后的输入张量input_ids = inputs["input_ids"]# 使用BERT模型生成文本的表示with torch.no_grad():outputs = model(input_ids)# 最后一层的隐藏状态作为文本的表示last_hidden_states = outputs.last_hidden_state
我们看看Transformers发展的历史,大体上,它们可以分为三类:
GPT-like (也被称作自回归Transformer模型)BERT-like (也被称作自动编码Transformer模型)BART/T5-like (也被称作序列到序列的 Transformer模型)
他的历史进程涵盖了目前著名的各类模型,transformer是大部份对话模型的基础架构,其他的模型都是或多或少使用他的组件,加入自己的优化,适应不同的训练任务。
比如BERT在Transformer的基础上引入了双向上下文编码、预训练和微调范式、MLM和NSP等创新点、GPT-3在Transformer的基础上通过扩大模型规模、增加预训练数据的多样性和量级、优化学习策略等方面进行了显著的改进。

2、模块
-
自注意力机制:自注意力允许模型在处理序列中的每个元素时,同时考虑序列中的其他元素。这是通过计算注意力分数来实现的,注意力分数表示序列中每个元素对当前元素的重要性。自注意力机制通常包括三个主要组件:查询(Query)、键(Key)和值(Value)。对于序列中的每个元素,模型都会计算一个查询向量、一个键向量和一个值向量。然后,通过计算查询向量与所有键向量的点积来得到注意力分数,接着对这些分数进行缩放和softmax操作,得到最终的注意力权重。这些权重与对应的值向量相乘并求和,得到该元素的输出表示。
-
多头注意力:为了让模型能够同时从不同的表示子空间学习信息,Transformers模型使用了多头注意力机制。这意味着自注意力过程被复制多次,每个复制都有不同的权重矩阵。最后,这些不同的头的输出被拼接在一起,并通过一个线性层进行变换。
-
位置编码:由于自注意力机制本身不具有捕捉序列顺序的能力,Transformers模型引入了位置编码来给模型提供关于元素在序列中位置的信息。位置编码通常是一个与序列元素嵌入向量维度相同的向量,它被加到每个元素的嵌入向量上,以此来提供位置信息。
-
编码器和解码器:在完整的Transformers模型中,编码器负责处理输入序列,而解码器负责生成输出序列。编码器由多个编码器层堆叠而成,每个层包含一个多头自注意力子层和一个前馈神经网络子层。解码器也由多个解码器层堆叠而成,但每个解码器层还包含一个额外的多头注意力子层,用于关注编码器的输出。
-
前馈神经网络:在每个编码器和解码器层中,除了自注意力子层之外,还有一个前馈神经网络(FFN)。FFN由两个线性变换组成,中间有一个ReLU激活函数。
-
残差连接和层归一化:为了避免在深层网络中出现梯度消失或爆炸的问题,每个子层(自注意力层和前馈神经网络)的输出都通过残差连接,即将子层的输入加到其输出上。然后,应用层归一化来稳定训练过程。
接下来主要是解析这几个模块,搞清楚也就对Transformers的原理有了初步的了解
三、原理
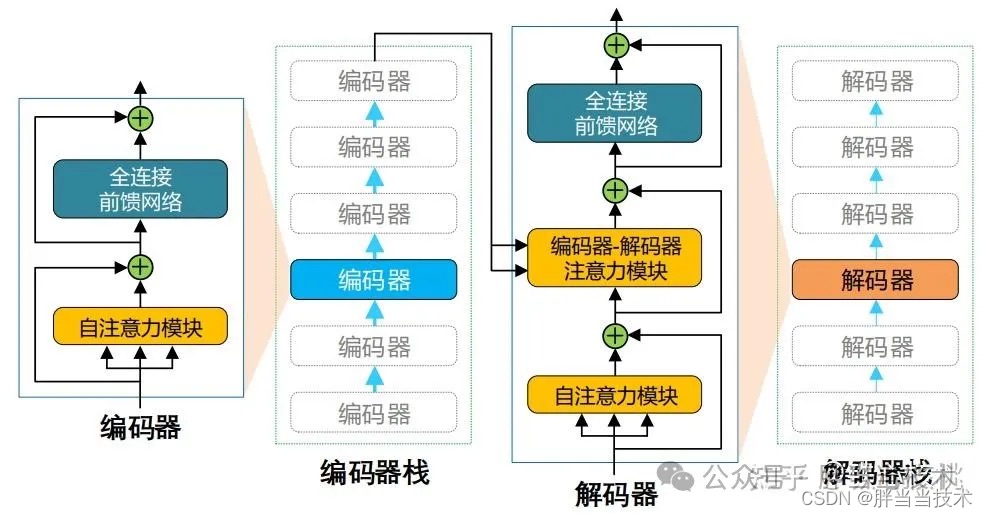
1、编解码器
这个作者理解就是输入输出,
-
Encoder (左侧): 编码器接收输入并分析,相当于理解你在说什么。最适合于需要理解完整句子的任务,例如:句子分类、命名实体识别(以及更普遍的单词分类)和阅读理解后回答问题。
-
Decoder (右侧): 解码器使用编码器的特征和之前的对话加上自注意力机制进行分析,判断回答你需不需要结合上下文,需不需要偏重点,需不需要结合其他知识,最后输出文本。通常围绕预测句子中的下一个单词进行。适合于涉及文本生成的任务
综合使用就被称为序列到序列模型,适合于围绕根据给定输入生成新句子的任务,如摘要、翻译或生成性问答

2、自注意力机制
Transformer模型中的自注意力机制是一种允许输入序列中的每个元素都与序列中的其他元素进行交互的机制,从而能够捕捉序列内部的复杂依赖关系。自注意力机制的核心思想是通过计算序列中每个元素对其他元素的“关注度”来动态地调整元素的表示。计算一个查询(Query)、一个键(Key)和一个值(Value)之间的关系。这些都是向量
作者认为最主要的是语境问题,比如你讽刺性的说一句很好,和夸奖性的说一句,大模型怎么理解你?那就必须结合上下文和其他的输入文本来进行分析,然后理解不同的含义
举个例子:“我爱大红袍”,我们想要理解每个字在句子中的作用和与其他字的关系。自注意力机制可以帮助我们做到这一点。
词嵌入:首先,我们将句子中的每个字转换为一个向量(词嵌入)。假设“我”、“爱”、“大”、“红袍”分别转换为向量v1, v2, v3, v4。生成Q、K、V:对于每个字的向量,我们通过乘以三个不同的权重矩阵来生成三个新的向量:查询(Q)、键(K)和值(V)。例如,v1乘以权重矩阵Wq、Wk、Wv生成了v1的Q、K、V向量。计算注意力分数:我们计算每个字的Q向量与其他所有字的K向量的点积,得到一个分数。这个分数表示一个字对句子中其他字的关注程度。例如,计算“我”的Q向量与“爱”、“大”、“红袍”的K向量的点积,得到“我”对“爱”、“大”、“红袍”的关注分数。归一化:为了让关注分数更加平滑,我们通常会除以K向量维度的平方根,并应用softmax函数进行归一化。这样,每个字对其他字的关注分数加起来就等于1。计算加权的V向量:每个字的V向量乘以它对其他字的关注分数,得到加权的V向量。这意味着如果“我”对“红袍”关注度很高,那么“红袍”的V向量在计算“我”的最终表示时会有更大的权重。求和:对于每个字,我们将它对所有字的加权V向量求和,得到一个新的向量,这个向量包含了整个句子的信息,并且强调了与当前字最相关的部分。输出:最后,我们得到了每个字的新表示,这个表示考虑了句子中所有字对当前字的影响。
3、前馈神经网络
前馈神经网络的结构通常包括以下几个部分:
-
输入层:接收输入数据的层,每个输入节点代表数据集中的一个特征。
-
隐藏层:一个或多个隐藏层,每个层由多个节点组成。这些节点将输入层或前一个隐藏层的输出进行加权和,然后通常会应用一个非线性激活函数。
-
输出层:将隐藏层的输出转换为最终的预测结果。输出层的节点数通常与任务的输出类别或预测值的数量相匹配。
-
权重和偏置:每个连接(从一个节点到另一个节点)都有一个权重,每个节点(除了输入节点)都有一个偏置。这些权重和偏置是网络在训练过程中学习的参数。
-
激活函数:隐藏层和输出层的节点通常会使用激活函数来引入非线性,使得网络能够学习和模拟复杂的函数。常见的激活函数包括ReLU、Sigmoid、Tanh等。
前馈神经网络的训练过程通常包括前向传播和反向传播两个阶段:
-
前向传播:输入数据在网络中从输入层流向输出层,每一层的节点都会计算其加权和,然后应用激活函数。
-
反向传播:计算输出层的预测值与真实值之间的误差,并将这个误差通过网络反向传播,以计算每个权重对误差的贡献。然后使用梯度下降或其他优化算法来更新权重和偏置,以减少误差
4、残差连接和层归一化
在每个Transformer层中,我们有两个主要的子层:一个是多头自注意力层,另一个是前馈神经网络层。在每个子层后面,我们都会使用残差连接,具体来说:
-
输入问题和段落的嵌入表示 X 通过多头自注意力层得到 A。
-
然后,我们将 A 与原始输入 X 直接相加,得到 X + A。这就是残差连接,它允许原始信息直接传递到后面的层,减少了信息丢失的风险。
相加不是文本的简单拼接,而是将两个张量在元素层面上进行逐元素的加法操作
X = [x11, x12x21, x22]A = [a11, a12a21, a22]X + A = [x11 + a11, x12 + a12x21 + a21, x22 + a22]
在每个残差连接后,我们通常会应用层归一化来稳定训练过程。具体步骤如下:
1、我们取残差连接的输出 X + A,计算它在特定维度上的均值和标准差。2、使用这些统计量对 X + A 进行归一化,得到一个均值为0、标准差为1的输出。对于一个数据集中的每个特征按照以下步骤进行标准化:计算该特征的均值(平均值)和标准差。从每个数据点中减去该特征的均值。将结果除以该特征的标准差。[ z = \frac{(x - \mu)}{\sigma} ]3、最后,通过可学习的参数(比例因子 g 和偏移 b)对归一化的输出进行缩放和平移,得到最终的层归一化结果。
这带来了一些新的问题,层归一化进行数据标准化有什么好处?
数据的标准化处理,主要是为了得到均值为0、标准差为1的输出,这样的输出对于大模型的层转换来说有很多好处
加速学习过程:当输入特征具有相似的范围时,梯度下降算法可以更快地收敛。这是因为标准化后的特征会使得优化过程中的梯度更新更加稳定,减少了某些维度可能比其他维度更新快或慢的情况。避免梯度消失或爆炸:在深度网络中,如果数据没有适当的标准化,激活值的分布可能会在网络的层之间传播时发生显著的变化,导致梯度消失或爆炸。这会使得网络难以学习。通过标准化,可以帮助维持激活值和梯度在合理的范围内。提高泛化能力:标准化可以减少模型对输入特征尺度的依赖,从而提高模型对未见数据的泛化能力。减少权重初始化的敏感性:适当的数据预处理可以减少模型对权重初始值的依赖。这是因为标准化后的数据有助于保持激活值的分布,使其不会随着网络深度的增加而发生太大变化。更好的条件数:在涉及到优化问题时,如果数据被标准化,那么问题的条件数(condition number)通常会更好,这意味着优化问题更加稳定,容易找到解。减少内部协变量偏移(Internal Covariate Shift):在训练深度网络时,层与层之间的分布变化(即内部协变量偏移)可能会导致训练过程不稳定。通过标准化,可以减少这种分布变化,使得每层的输入分布更加稳定,从而有助于网络的训练。允许使用更高的学习率:由于标准化有助于稳定梯度,因此可以使用更高的学习率而不会导致训练过程发散,这有助于加快模型的收敛速度。减少过拟合:某些标准化技术(如批量归一化)可以提供轻微的正则化效果,因为在每个批次中对特征进行标准化会引入一些噪声,这类似于正则化技术,有助于模型泛化。
最终提高训练稳定性,加速收敛,提高模型的泛化能力,并允许使用更复杂的网络架构。
可学习的参数是什么?
其实就是模型的权重和偏置,每个神经元与其它神经元相连时都有一个权重,这个权重决定了信号传递的强度。偏置是一个额外的参数,它允许神经元的激活阈值向上或向下调整。权重和偏置一起决定了神经网络的输出。
模型的权重和偏置是可以打出来看看的,打出来会非常庞大,通常是多维数组
tensor([[-0.0083, 0.0228, -0.0256, ..., -0.0029, 0.0219, 0.0017],[ 0.0348, -0.0149, 0.0287, ..., 0.0191, -0.0453, 0.0135],...[-0.0237, 0.0024, -0.0191, ..., -0.0412, 0.0215, -0.0137]])tensor([-0.0063, 0.0101, -0.0053, ..., 0.0073, -0.0024, 0.0048])
from transformers import BertModel, BertConfig# 加载预训练的BERT模型model = BertModel.from_pretrained('bert-base-uncased')# 打印模型的所有参数的名称和尺寸for name, param in model.named_parameters():print(name, param.size())# 获取特定层的权重和偏置layer_index = 0 # 选择要查看的层的索引layer = model.encoder.layer[layer_index]# 获取该层的自注意力子层的权重和偏置attention_weights = layer.attention.self.query.weight.dataattention_biases = layer.attention.self.query.bias.data# 打印权重和偏置的数值print("Attention weights:", attention_weights)print("Attention biases:", attention_biases)
为什么要缩放和平移?
有助于减少训练过程中的内部协变量偏移,这是通过引入两个可学习的参数γ(缩放因子)和β(平移因子)来实现的。这两个参数与归一化的数据相乘和相加,分别对应缩放和平移操作。
恢复表达能力:归一化操作会改变激活值的分布,可能会限制网络层的表达能力。通过引入缩放和平移参数,网络可以学习到在归一化后最优的激活值分布,从而恢复并保持网络层的表达能力。维持非线性:深度学习模型中通常使用非线性激活函数(如ReLU)来增加模型的非线性表达能力。如果直接应用归一化,所有的激活值将被限制在一个固定的范围内,这可能会削弱非线性激活函数的效果。通过缩放和平移,模型可以调整激活值的分布,以更好地利用非线性激活函数。适应性学习:不同的层和不同的任务可能需要不同的激活值分布。缩放和平移参数是可学习的,这意味着模型可以自适应地调整这些参数以适应特定的任务和数据分布。
残差连接和层归一化通常是这样交替使用
输入 --> [多头自注意力 + 残差连接] --> [层归一化] --> [前馈神经网络 + 残差连接] --> [层归一化] --> 输出
四、总结
再次重申:transformer是大部份对话模型的基础架构,其他的模型都是或多或少使用他的组件,加入自己的优化,适应不同的训练任务。
比如BERT在Transformer的基础上引入了双向上下文编码、预训练和微调范式、MLM和NSP等创新点、GPT-3在Transformer的基础上通过扩大模型规模、增加预训练数据的多样性和量级、优化学习策略等方面进行了显著的改进。
但是我们不需要了解他的每一个实现机制,作为应用层的技术人员,我们需要了解的是这些模型的区别,对于任务数据的偏向、使用资源的消耗,然后进行接入使用,搭建我们自己的人工智能。后续的文章作者会着重于使用的原理以及分析。


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)