【网安AIGC专题】46篇前沿代码大模型论文、24篇论文阅读笔记汇总
网络安全专题是针对当前热点安全问题进行研讨,通常分成四类热门主题进行介绍和研讨,包括的热门主题有:攻击行为与漏洞分析,分享最新的攻防进展;下一代网络安全,分享物联网、工控网络等相关协议安全、网络防御等技术;动态行为分析,分享内存相关安全以及动态污点技术等;人工智能安全,分享人工智能,人工智能安全应用,以及联邦学习安全等最新知识。围绕着几个热门主题,在最近五年的信息安全顶尖会议上挑选一些代表性论文,
网安AIGC专题
- 写在最前面
-
* 一些碎碎念- 课程简介
- 0、课程导论
- 1、应用 - 代码生成
- 2、应用 - 漏洞检测
- 3、应用 - 程序修复
- 4、应用 - 生成测试
- 5、应用 - 其他
- 6、模型介绍
- 7、模型增强
- 8、数据集
- 9、模型安全
写在最前面
本系列文章不仅涵盖了46篇关于前沿代码大模型的论文,还包含了24篇深度论文阅读笔记,全面覆盖了代码生成、漏洞检测、程序修复、生成测试等多个应用方向,深刻展示了这些技术如何在网络安全领域中起到革命性作用。同时,本系列还细致地介绍了大模型技术的基础架构、增强策略、关键数据集,以及与网络安全紧密相关的模型安全问题。
本篇博客旨在整理这些宝贵的笔记,方便未来的阅读和研究,同时也希望能够对广大读者产生启发和帮助。让我们一起踏上这场网络安全的未来探索之旅,共同在这个不断变化的领域中寻找属于我们的立足点。
一些碎碎念
纯散养、跨方向的直博开局,幸运的遇到了网络安全专题这门课,于是像每周组会一样在上课。
感谢邹德清、李珍、文明老师的授课,感谢课堂每一位同学的交流,受益匪浅。
带我打开一个全新视角,领略AIGC与大模型技术的革新之旅。同时理解最新的技术成就,发现它们的不足之处,并培养出创新能力。还有一些全英文PPT,“被迫”学了很多英文名词hh
对于我来说,这不仅仅是学术上的成长之旅,更是一次思维和视角的重大转变。通过课堂汇报、论文阅读和交流讨论,我逐渐培养了阅读论文的习惯,并学会了如何形成自己的思路。
这是2023秋季的三个月,也是积极的开始。希望之后的自己能延续每周阅读文献,积极推进科研进度,争取早日毕业!
课程简介
网络安全专题是针对当前热点安全问题进行研讨,通常分成四类热门主题进行介绍和研讨,包括的热门主题有:攻击行为与漏洞分析,分享最新的攻防进展;下一代网络安全,分享物联网、工控网络等相关协议安全、网络防御等技术;动态行为分析,分享内存相关安全以及动态污点技术等;人工智能安全,分享人工智能,人工智能安全应用,以及联邦学习安全等最新知识。
围绕着几个热门主题,在最近五年的信息安全顶尖会议上挑选一些代表性论文,组织学生研讨,启发他们理解最新成果,并发现最新成果的不足,从而达到培养创新能力的目的;另外也提高他们用英文介绍知识,以及进行讨论的能力。
0、课程导论
【网安AIGC专题10.11】软件安全+安全代码大模型
【网安AIGC专题10.11】①代码大模型的应用:检测、修复②其安全性研究:模型窃取攻击(API和网页接口) 数据窃取攻击 对抗攻击(用途:漏洞隐藏)
后门攻击(加触发器+标签翻转)
1、应用 - 代码生成
| 主题 | 论文 | 出处及时间 | 论文笔记 |
|---|---|---|---|
| [Enabling Programming Thinking in Large Language Models Toward Code | |||
| Generation](https://arxiv.org/pdf/2305.06599.pdf) | arXiv 2023.5.11 | ||
| [Self-Edit: Fault-Aware Code Editor for Code | |||
| Generation](https://arxiv.org/pdf/2305.04087.pdf) | arXiv 2023.5.6 | ||
| [Improving Code Example Recommendations on Informal Documentation Using BERT | |||
| and Query-Aware LSH: A Comparative | |||
| Study](https://arxiv.org/pdf/2305.03017.pdf) | arXiv 2023.5.4 | ||
| 自动程序修复 | [Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation | ||
| of Large Language Models for Code | |||
| Generation](https://arxiv.org/pdf/2305.01210.pdf) | arXiv 2023.5.2 | ||
| 论文1:生成式模型GPT\CodeX填充式模型CodeT5\INCODER+大模型自动程序修复(生成整个修复函数、修复代码填充、单行代码生产、生成的修复代码排序和过滤) | |||
| 代码生成 | [Self-collaboration Code Generation via | ||
| ChatGPT](https://arxiv.org/pdf/2304.07590.pdf) | arXiv 2023.4.15 | ||
| 论文3代码生成:ChatGPT+自协作代码生成+角色扮演(分析员、程序员、测试员)+消融实验、用于MBPP+HumanEval数据集 | |||
| 代码生成 | [Improving Code Generation by Training with Natural Language | ||
| Feedback](https://arxiv.org/pdf/2303.16749.pdf) | arXiv 2023.3.28 | [2 | |
| ILF利用人类编写的 自然语言反馈 来训练代码生成模型:自动化反馈生成+多步反馈合并+处理多错误反馈+CODEGEN -M ONO 6.1 B | |||
| model](http://t.csdnimg.cn/OvRJA) | |||
| [Learning Performance-Improving Code | |||
| Edits](https://arxiv.org/pdf/2302.07867.pdf) | arXiv 2023.2.15 |
2、应用 - 漏洞检测
| 论文 | 出处及时间 |
|---|---|
| [Large Language Models of Code Fail at Completing Code with Potential | |
| Bugs](https://arxiv.org/abs/2306.03438) | arXiv |
| [Large Language Models and Simple, Stupid | |
| Bugs](https://arxiv.org/pdf/2303.11455.pdf) | arXiv 2023.3.20 |
| [Prompting Is All Your Need: Automated Android Bug Replay with Large Language | |
| Models](https://arxiv.org/abs/2306.01987) | arXiv |
| [When GPT Meets Program Analysis: Towards Intelligent Detection of Smart | |
| Contract Logic Vulnerabilities in GPTScan](https://arxiv.org/abs/2308.03314) | |
| arXiv |
3、应用 - 程序修复
| 主题 | 论文 | 出处及时间 | 论文笔记 |
|---|---|---|---|
| [Towards Generating Functionally Correct Code Edits from Natural Language | |||
| Issue Descriptions](https://arxiv.org/pdf/2304.03816.pdf) | arXiv 2023.4.7 | ||
| 自动程序修复 | [Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 | ||
| each using ChatGPT](https://arxiv.org/pdf/2304.00385.pdf) | arXiv 2023.4.1 | [5 | |
| ChatRepair:ChatGPT+漏洞定位+补丁生成+补丁验证+APR方法+ChatRepair+不同修复场景+修复效果(韦恩图展示)](https://blog.csdn.net/wtyuong/article/details/133906940) | |||
| [CCTEST: Testing and Repairing Code Completion | |||
| Systems](https://arxiv.org/pdf/2208.08289.pdf) | ICSE 2023 | ||
| [Examining Zero-Shot Vulnerability Repair with Large Language | |||
| Models](https://arxiv.org/pdf/2112.02125.pdf) | S&P 2023 | ||
| 自动程序修复 | [Automated Program Repair in the Era of Large Pre-trained Language | ||
| Models](http://lingming.cs.illinois.edu/publications/icse2023a.pdf) | ICSE | ||
| 2023 | |||
| 大模型自动程序修复(生成整个修复函数、修复代码填充、单行代码生产、生成的修复代码排序和过滤)+生成式模型GPT\CodeX填充式模型CodeT5\INCODER | |||
| 漏洞修复 | [How Effective Are Neural Networks for Fixing Security | ||
| Vulnerabilities](https://arxiv.org/abs/2305.18607) | arXiv | [论文6(顶会ISSTA | |
| 2023):提出新Java漏洞自动修复数据集:数据集 VJBench+大语言模型、APR技术+代码转换方法+LLM和DL- | |||
| APR模型的挑战与机会](https://blog.csdn.net/wtyuong/article/details/133908816) | |||
| 自动程序修复 | [Conversational Automated Program | ||
| Repair](https://arxiv.org/pdf/2301.13246.pdf) | arXiv 2023.1.30 | ||
| [论文7:Chatgpt/CodeX引入会话式 APR 范例+利用验证反馈+LLM | |||
| 长期上下文窗口:更智能的反馈机制、更有效的信息合并策略、更复杂的模型结构、鼓励生成多样性](https://blog.csdn.net/wtyuong/article/details/134043342) | |||
| 静默漏洞修复识别 | [CoLeFunDa-Explainable Silent Vulnerability Fix | ||
| Identification](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10172826) | |||
| ICSE 2023 | [8 | ||
| CoLeFunDa华为团队:静默漏洞检测(识别+多分类)+数据增强、样本扩充+对比学习+微调+结果分析(降维空间,分类错误样本归纳,应用场景优势,有效性威胁分析)](https://blog.csdn.net/wtyuong/article/details/134073916) |
4、应用 - 生成测试
| 主题 | 论文 | 出处及时间 | 论文笔记 |
|---|---|---|---|
| [No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test | |||
| Generation](https://arxiv.org/pdf/2305.04207.pdf) | arXiv 2023.5.9 | ||
| [Finding Failure-Inducing Test Cases with | |||
| ChatGPT](https://arxiv.org/pdf/2304.11686.pdf) | arXiv 2023.4.30 | ||
| [Large Language Models are Edge-Case Fuzzers: Testing Deep Learning | |||
| Libraries via FuzzGPT](https://arxiv.org/pdf/2304.02014.pdf) | arXiv 2023.4.4 | ||
| 自动化测试 | [Large Language Models are Few-shot Testers: Exploring LLM-based | ||
| General Bug Reproduction](https://arxiv.org/pdf/2209.11515.pdf) | arXiv | ||
| 2022.9.23 | [9 | ||
| LIBRO方法(ICSE2023顶会自动化测试生成):提示工程+查询LLM+选择、排序、后处理(测试用例函数放入对应测试类中,并解决执行该测试用例所需的依赖)](https://blog.csdn.net/WTYuong/article/details/134261336) | |||
| 模糊测试 | [Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning | ||
| Libraries via Large Language | |||
| Models](http://lingming.cs.illinois.edu/publications/issta2023a.pdf) | ISSTA | ||
| 2023 | [10 | ||
| TitanFuzz完全自动化执行基于变异的模糊测试:生成式(如Codex)生成种子程序,逐步提示工程+第一个应用LLM填充模型(如InCoder)+差分测试](https://blog.csdn.net/wtyuong/article/details/134264170) |
5、应用 - 其他
| 主题 | 论文 | 出处及时间 | 论文笔记 |
|---|---|---|---|
| 信息提取 | [CODEIE: Large Code Generation Models are Better Few-Shot Information | ||
| Extractors](https://arxiv.org/pdf/2305.05711.pdf) | arXiv 2023.5.11 | [12 | |
| CODEIE用于NER和RE:顶刊OpenAI | |||
| API调用、CodeX比chatgpt更好:提示工程设计+控制变量对比实验(格式一致性、模型忠实度、细粒度性能)](https://blog.csdn.net/wtyuong/article/details/134145851) | |||
| 代码搜索 | [On Contrastive Learning of Semantic Similarity for Code to Code | ||
| Search](https://arxiv.org/pdf/2305.03843.pdf) | arXiv 2023.5.5 | ||
| [14Cosco跨语言代码搜索代码: (a) 训练阶段 相关程度的对比学习 对源代码(查询+目标代码)和动态运行信息进行编码 (b) | |||
| 在线查询嵌入与搜索:不必计算相似性](https://blog.csdn.net/wtyuong/article/details/134289033) | |||
| 生成知识图谱 | [CodeKGC: Code Language Model for Generative Knowledge Graph | ||
| Construction](https://arxiv.org/pdf/2304.09048.pdf) | arXiv 2023.4.18 | ||
| 软件工程 | [The Scope of ChatGPT in Software Engineering: A Thorough | ||
| Investigation](https://arxiv.org/abs/2306.01250) | arXiv | [15 | |
| ChatGPT在软件工程中的全面作用:程序语法(AST生成、表达式匹配) 静态行为、动态分析(数据依赖和污点分析、指针分析) | |||
| 提示设计(角色提示、指令提示)](https://blog.csdn.net/wtyuong/article/details/134291072) | |||
| 代码摘要 | [Improving Few-shot Prompts with Relevant Static Analysis | ||
| Products](https://arxiv.org/pdf/2304.06815.pdf) | arXiv | ||
| 17ASAP如何更好地改进少样本提示:在LLMs的prompt中添加语义信息,来提高代码摘要生成+代码补全任务的性能。CodeSearchNet数据集 | |||
| 代码解释 | [Comparing Code Explanations Created by Students and Large Language | ||
| Models](https://arxiv.org/pdf/2304.06815.pdf) | arXiv 2023.4.13 | ||
| 论文13:理解和解释代码,GPT-3大型语言模型&学生创建的代码解释比较+错误代码的解释(是否可以发现并改正) | |||
| 代码学习 | [Active Code Learning: Benchmarking Sample-Efficient Training of Code | ||
| Models](https://arxiv.org/pdf/2304.03938.pdf) | arXiv 2023.4.8 | [11 Coreset-C | |
| 主动学习:特征选择+11种采样方法+CodeBERT、GraphCodeBERT+多分类(问题分类)二元分类(克隆检测)非分类任务(代码总结)](https://blog.csdn.net/wtyuong/article/details/134161486) | |||
| 许可证版权保护 | [CODEIPPROMPT: Intellectual Property Infringement Assessment of Code | ||
| Language Models](https://openreview.net/pdf?id=zdmbZl0ia6) | ICML 2023 | ||
| [16CODEIPPROMPT:顶会ICML’23 | |||
| 从GitHub到AI,探索代码生成的侵权风险与缓解策略的最新进展:训练数据`有限制性许可;模型微调+动态Token过滤](https://blog.csdn.net/wtyuong/article/details/134292265) | |||
| LLM4SE综述 | [Large Language Models for Software Engineering: A Systematic | ||
| Literature Review](https://arxiv.org/pdf/2308.10620.pdf) | arXiv 2023.9.12 | ||
| [18LLM4SE革命性技术揭秘:大型语言模型LLM在软件工程SE领域的全景解析与未来展望 - | |||
| 探索LLM的多维应用、优化策略与软件管理新视角](https://blog.csdn.net/wtyuong/article/details/134420526) |
6、模型介绍
| 论文 | 出处及时间 |
|---|---|
| [StarCoder: may the source be with | |
| you!](https://arxiv.org/pdf/2305.06161.pdf) | arXiv 2023.5.9 |
| Textbooks Are All You Need | arXiv |
| 2023.6.20 | |
| Analysis of ChatGPT on Source Code | arXiv |
7、模型增强
| 主题 | 论文 | 出处及时间 | 论文笔记 |
|---|---|---|---|
| 代码预训练 | [ContraBERT: Enhancing Code Pre-trained Models via Contrastive | ||
| Learning](https://arxiv.org/pdf/2301.09072.pdf) | ICSE 2023 | ||
| [19ContraBERT:顶会ICSE23 | |||
| 数据增强+对比学习+代码预训练模型,提升NLP模型性能与鲁棒性:处理程序变异(变量重命名)](https://blog.csdn.net/wtyuong/article/details/134453166) | |||
| 持续学习 | [Keeping Pace with Ever-Increasing Data: Towards Continual Learning of | ||
| Code Intelligence Models](https://arxiv.org/pdf/2302.03482.pdf) | ICSE 2023 | ||
| [23REPEAT方法:软工顶会ICSE ‘23 大模型在代码智能领域持续学习 代表性样本重放(选择信息丰富且多样化的示例) + | |||
| 基于可塑权重巩固EWC的自适应参数正则化 | |||
| 【网安AIGC专题11.22】](https://blog.csdn.net/wtyuong/article/details/134555810) | |||
| [TRACED: Execution-aware Pre-training for Source | |||
| Code](https://arxiv.org/abs/2306.07487) | arXiv | ||
| [Symmetry-Preserving Program Representations for Learning Code | |||
| Semantics](https://arxiv.org/abs/2308.03312) | arXiv |
8、数据集
| 主题 | 论文 | 出处及时间 | 论文笔记 |
|---|---|---|---|
| [The Vault: A Comprehensive Multilingual Dataset for Advancing Code | |||
| Understanding and Generation](https://arxiv.org/pdf/2305.06156.pdf) | arXiv | ||
| 2023.5.9 | |||
| 错误代码补全 | [Large Language Models of Code Fail at Completing Code with Potential | ||
| Bugs](https://arxiv.org/pdf/2306.03438.pdf) | NeurIPS 2023 | [24 | |
| LLM错误代码补全:机器学习顶会NeurIPS‘23 智能体评估:自行构建数据集Buggy-HumanEval、Buggy- | |||
| FixEval+错误代码补全+修复模型【网安AIGC专题11.22】](https://blog.csdn.net/wtyuong/article/details/134556655) | |||
| CCF C | [LLMSecEval: A Dataset of Natural Language Prompts for Security | ||
| Evaluations](https://arxiv.org/pdf/2303.09384.pdf) | arXiv 2023.3.16 | ||
| 22LLMSecEval数据集及其在评估大模型代码安全中的应用:GPT3和Codex根据LLMSecEval的提示生成代码和代码补全,CodeQL进行安全评估【网安AIGC专题11.22】 | |||
| [CrossCodeBench: Benchmarking Cross-Task Generalization of Source Code | |||
| Models](https://arxiv.org/pdf/2302.04030.pdf) | ICSE 2023 | ||
| 数据增强 | [Data Augmentation Approaches for Source Code Models: A Survey | ||
| ](https://arxiv.org/abs/2305.19915) | arXiv | ||
| 20源代码模型的数据增强方法:克隆检测、缺陷检测和修复、代码摘要、代码搜索、代码补全、代码翻译、代码问答、问题分类、方法名称预测和类型预测对论文进行分组【网安AIGC专题11.15】 |
9、模型安全
| 主题 | 论文 | 出处及时间 |
|---|---|---|
| [Multi-target Backdoor Attacks for Code Pre-trained | ||
| Models](https://arxiv.org/abs/2306.08350) | arXiv | |
| 对抗攻击 | [Discrete Adversarial Attack to Models of | |
| Code](https://dl.acm.org/doi/pdf/10.1145/3591227) | PLDI 2023 |
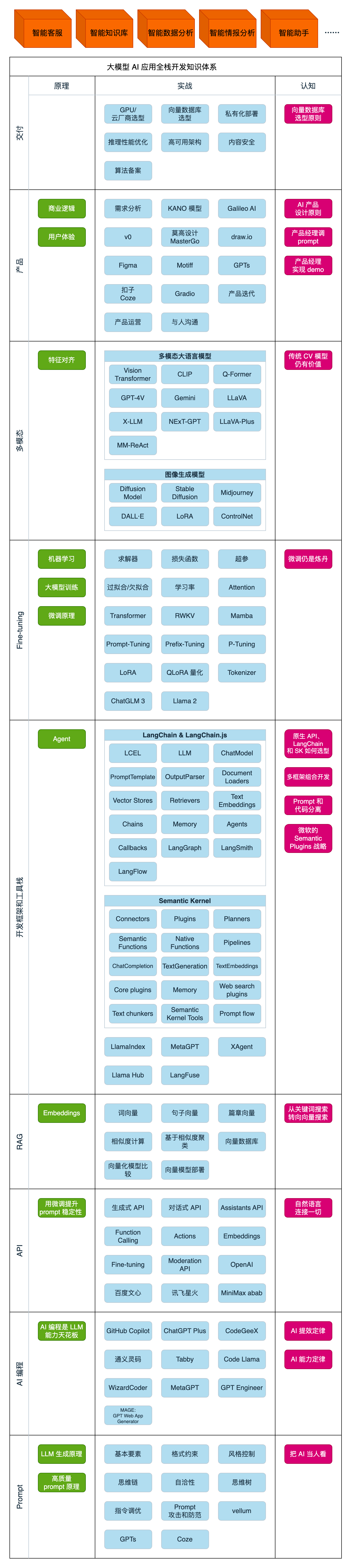
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!


第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)