
BitFit: 基于Transformer掩码语言模型的参数高效调优
22年9月来自一所以色列的大学和西雅图AI2研究院的论文“BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models“。
22年9月来自一所以色列的大学和西雅图AI2研究院的论文“BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models“。

BitFit是一种稀疏微调方法,其中仅修改模型(或其子集)的bias项。 对于中小型训练数据,在预训练的 BERT 模型上应用 BitFit 比微调整个模型具有竞争力(有时甚至更好)。 对于较大型的数据,该方法比其他稀疏微调方法具有竞争力。 除了实用性之外,还与微调过程相关:微调主要是暴露语言建模训练产生的知识,而不是学习新的特定任务语言知识。
每个任务微调非常有效,但也会为每个预训练任务生成一个独特的大模型,很难推断微调过程中发生了什么变化,并且也难以部署, 尤其是任务数量增加的情况。 理想情况下,人们需要一种微调方法4个标准:
(i) 匹配完全微调模型的结果;
(ii) 仅更改模型参数的一小部分;
(iii) 在一个流中任务到达,不需要同时访问所有数据集。
(iv):改变的参数集在不同任务之间保持一致。
在(Houlsby2019)提出的“适配器”,是在预训练模型各层之间注入小型、可训练的特定任务“适配器”模块,其中原始参数在任务之间共享。
(Guo2020)的“Diff-Pruning”,原始参数保持固定并在任务之间共享,然后添加稀疏的、特定任务的差异向量实现相同的目标。 差异向量正则化为稀疏的。
两种方法都允许为每个任务仅添加少量可训练参数(标准 ii),并且可以添加每个任务而无需重新访问以前的任务(标准 iii)。它们还部分满足标准 (i),与全微调相比,性能仅略有下降。
“适配器“方法(但不包括 Diff-Pruning 方法)也支持条件 (iv)。 然而,Diff-Pruning 比“适配器”方法的参数效率更高(特别是它不添加新参数),并且还获得了更好的任务分数。
BitFit(BIas-Term Fine-Tuning)方法,其中冻结了大部分Transformer编码器参数,并仅训练bias项和特定任务的分类层。 BitFit 具有三个关键属性,即标准(i-iii)。
BitFit具有参数高效性:每个新任务仅需要存储bias项参数向量(不到参数总数的 0.1%)以及特定任务的最终线性分类器层。
具体来说,BERT(注:作者的工作是以BERT为大语言模型进行实验分析)编码器由L层组成,其中每层l以M个自注意头开始,其中自注意头(m,l)具有Key、查询和Value编码器,每个编码器采用线性层的形式:
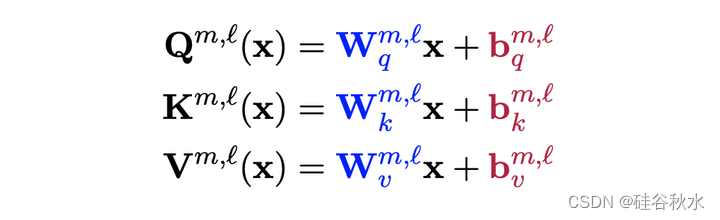
其中 x 是前一个编码器层的输出(对于第一个编码器层,x 是嵌入层的输出)。 然后用不涉及新参数的注意机制将它们组合起来:
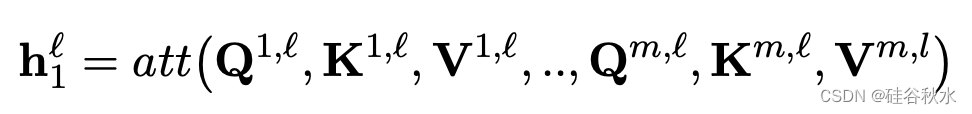
接着送入一个带分层归一化(LN)的MLP:
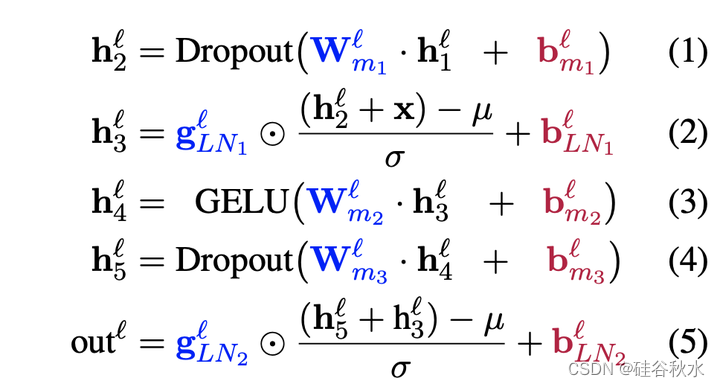
bias项是可加的,并且对应于网络的很小一部分,在 BERT BASE 和 BERT LARGE bias参数中分别占每个总模型参数的 0.09% 和 0.08%。
通过冻结所有参数 W(·) 和 g(·) 并仅微调加性bias项 b(·),迁移学习的性能与整个网络的微调进行比较:可以仅微调bias参数的子集,即与查询和第二个 MLP 层相关的参数(仅 bq(·) 和 bm2(·) ),并且仍然达到与全模型微调相媲美的精度。
下表报告了开发集和测试集性能与Diff-Pruning和“适配器”两个方法参数数量的比较。
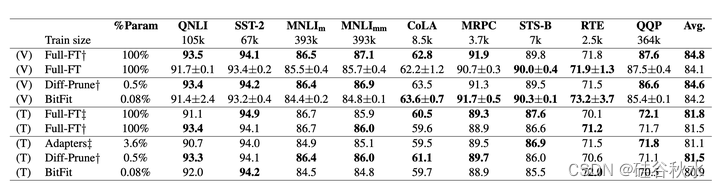
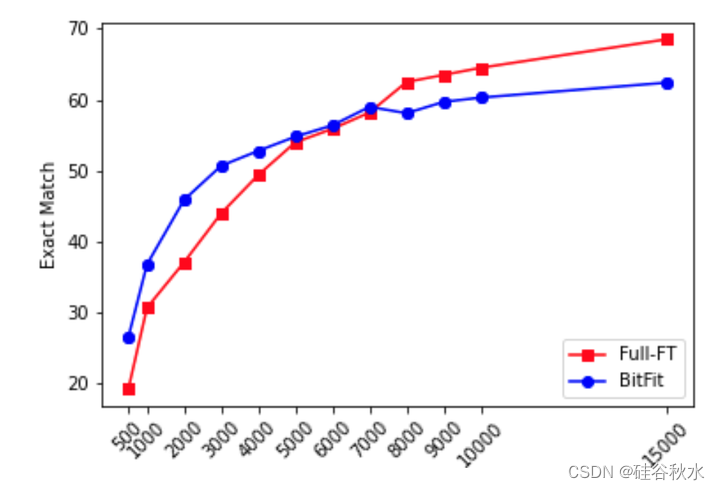
如下图给出的:在较小数据范围内,BitFit 优于 全参数调优(Full-FT),而当有更多训练数据可用时,趋势会发生逆转。 结论是,BitFit 在中小型数据体系中是一种有价值的有针对性的微调方法。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)