【机器学习案列分析】逻辑回归预测银行客户是否会开设定期存款账户
本数据集旨在预测银行客户是否会开设定期存款账户。数据集包含了大量银行客户的个人信息和交易历史,涵盖了各种可能影响客户决策的因素。通过对这些数据的分析,银行可以更好地理解客户的需求和偏好,进而制定更有效的营销策略。
一、数据介绍
1、数据集概述
本数据集旨在预测银行客户是否会开设定期存款账户。数据集包含了大量银行客户的个人信息和交易历史,涵盖了各种可能影响客户决策的因素。通过对这些数据的分析,银行可以更好地理解客户的需求和偏好,进而制定更有效的营销策略。
2、数据集来源
本数据集来源于一家大型银行的历史客户数据,经过脱敏处理后用于学术研究和机器学习竞赛。数据涵盖了不同年龄段、职业、教育背景和社会经济地位的客户,确保了样本的多样性和代表性。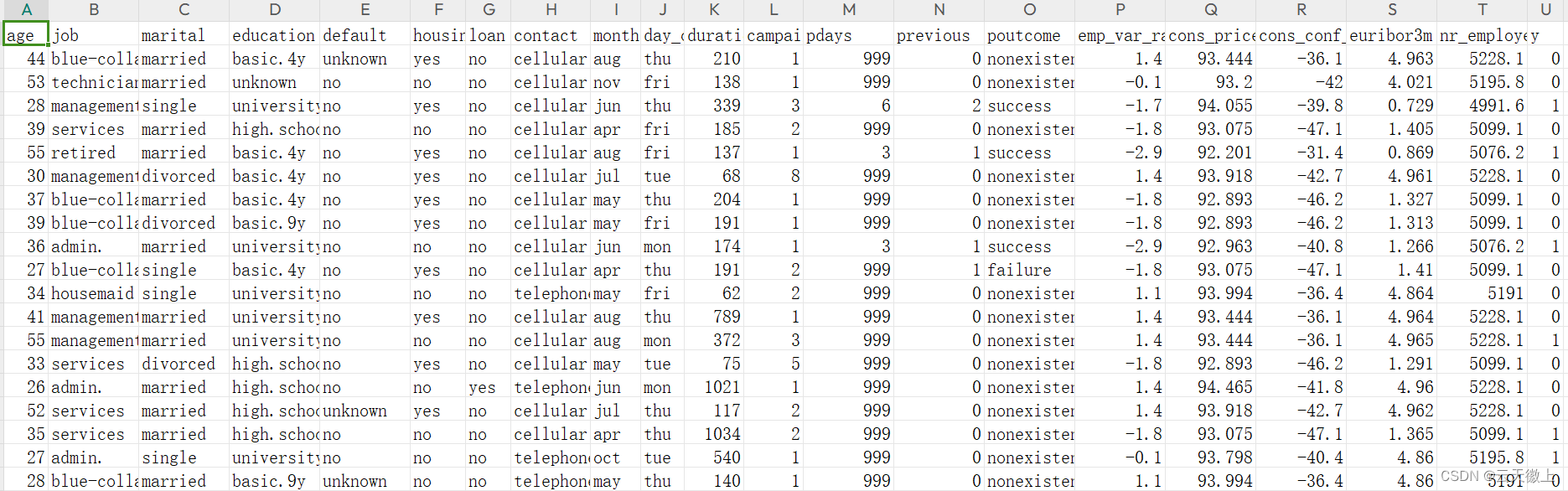
本文使用的数据集下载https://download.csdn.net/download/qq_38614074/89497593。
3、数据字段说明
](https://img-blog.csdnimg.cn/direct/23608ad22e3c4e0aaf1045b7ed97df48.png)
- age:客户的年龄,以岁为单位。
- job:客户的职业类别,如“管理”、“蓝领”、“家庭主妇”等。
- marital:客户的婚姻状况,如“已婚”、“未婚”、“离婚”等。
- education:客户的教育程度,如“高中”、“大学”、“研究生”等。
- default:客户是否有违约记录,用“yes”或“no”表示。
- housing:客户的住房情况,如“自有住房”、“贷款购房”、“租房”等。
- loan:客户是否有其他贷款,用“yes”或“no”表示。
- contact:银行与客户的联系方式,如“电话”、“电子邮件”等。
- month:最后一次联系客户的月份。
- day_of_week:最后一次联系客户的星期几。
- duration:最后一次通话的持续时间,以秒为单位。
- campaign:与客户联系的营销活动次数。
- pdays:上次联系后的天数。
- previous:之前与客户的接触次数。
- poutcome:上次接触的结果,如“成功”、“失败”等。
- emp_var_rate:就业变动率,反映了就业市场的波动情况。
- cons_price_idx:消费者价格指数,反映了物价水平的变化。
- cons_conf_idx:消费者信心指数,反映了消费者对经济的信心程度。
- euribor3m:欧元短期利率,反映了市场的利率水平。
- nr_employed:雇员人数,反映了就业市场的规模。
- y:目标变量,表示客户是否会开设定期存款账户,用“yes”或“no”表示。
二、数据预处理
需要说明的是在进行预测的数据预处理时,需要对数据进行可视化的分析,来展示数据间的分布关系来指导我们数据预处理的流程,后续将添加详细的数据可视化博文,来提升我们预测的精度;本文重点介绍预测的流程,重点不会考虑数据可视化部分;
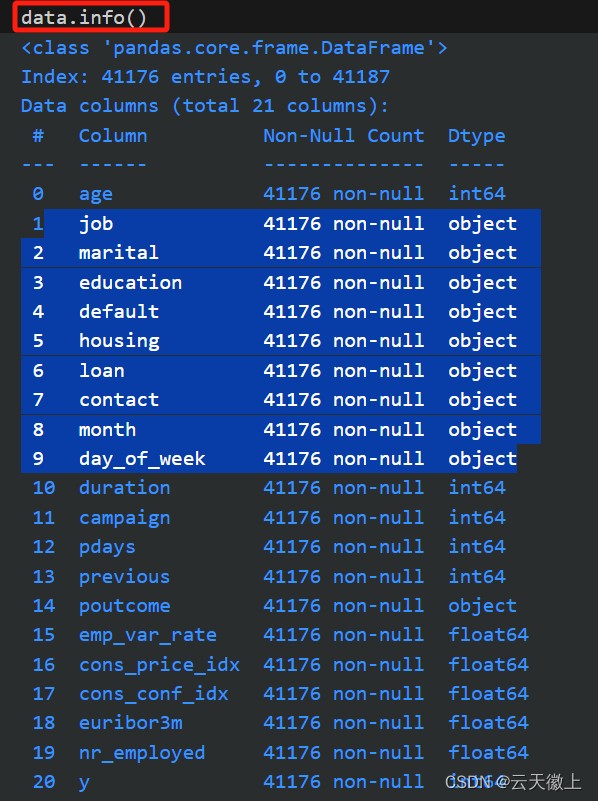
1. 数据加载
首先,我们需要加载数据集。这里假设数据集已经以CSV格式存储。
import pandas as pd
# 加载数据
data = pd.read_csv('bank_data.csv')
# 查看数据的前几行
print(data.head())

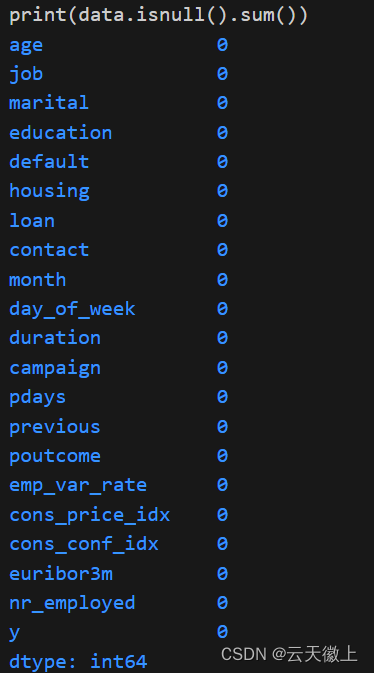
2. 数据清洗
检查数据集中是否存在缺失值、异常值或重复项,并进行相应的处理。
# 检查缺失值
print(data.isnull().sum())
# 如果有缺失值,可以使用均值、中位数、众数或删除行等方式填充
# 假设我们删除包含缺失值的行
data = data.dropna()
# 检查重复项
print(data.duplicated().sum())
# 如果有重复项,可以删除它们
data = data.drop_duplicates()

3. 特征工程
- 分类变量编码:将分类变量(如’job’, ‘marital’, 'education’等)编码为数值型,可以使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)。
- 数值变量处理:对于数值变量,可以考虑进行标准化或归一化,以改善模型的性能。
- 查看那些特征时类别型分类变量编码,那些是数值变量处理;数值变量可以进行归一化,分桶等操作;
# 假设我们使用独热编码处理分类变量
from sklearn.preprocessing import OneHotEncoder
# 选择要编码的列
categorical_cols = ['job', 'marital', 'education','default', 'housing','loan', 'contact', 'month', 'day_of_week', 'poutcome']
data_encoded = pd.get_dummies(data, columns=categorical_cols)
# 打印结果以检查
print(data_encoded.head())
for col in data_encoded.columns:
if data_encoded[col].dtype == bool:
data_encoded[col] = data_encoded[col].astype(int)
data_encoded.drop(columns=categorical_cols, inplace=True)
4. 划分数据集
将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_split
# 划分特征和目标变量
X = data_encoded.drop('y', axis=1)
y = data_encoded['y']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
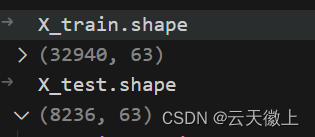
三、模型构建与训练
1. 导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
2. 训练模型
# 创建逻辑回归模型实例
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
四、模型评估
1. 预测测试集
# 使用模型预测测试集
y_pred = model.predict(X_test)
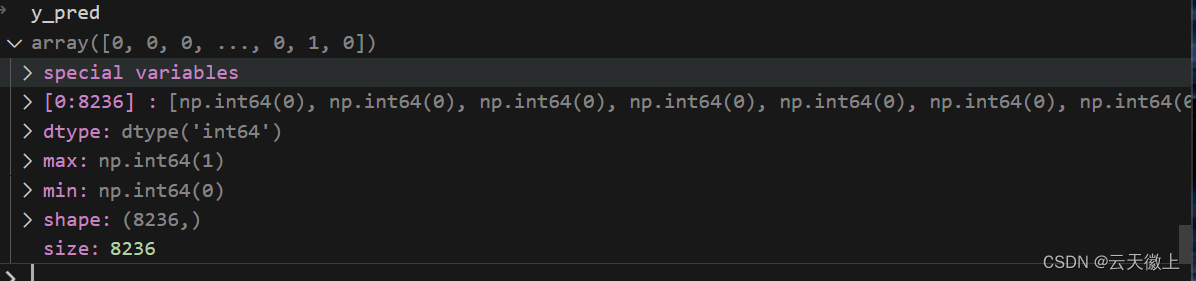
2. 计算评估指标
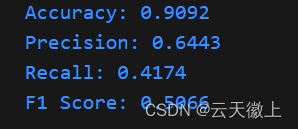
我们可以使用准确率、精确度、召回率和F1分数等指标来评估模型的性能。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.4f}')
# 计算精确度
precision = precision_score(y_test, y_pred)
print(f'Precision: {precision:.4f}')
# 计算召回率
recall = recall_score(y_test, y_pred)
print(f'Recall: {recall:.4f}')
# 计算F1分数
f1 = f1_score(y_test, y_pred)
print(f'F1 Score: {f1:.4f}')
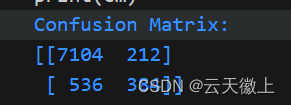
3. 混淆矩阵
混淆矩阵也是评估分类模型性能的重要工具。
from sklearn.metrics import confusion_matrix
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(cm)
至此逻辑回归的这个流程结束,后续将进行模型优化的操作;
五、模型优化
1. 特征选择
可以尝试使用不同的特征选择方法,如基于模型的特征选择(如随机森林的特征重要性),以优化模型性能。
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
# 假设 X_train 是训练特征集, y_train 是训练标签集
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# 获取特征重要性
importances = rf.feature_importances_
# 选择重要性超过某个阈值的特征
sfm = SelectFromModel(rf, prefit=True)
X_train_selected = sfm.transform(X_train)
# 现在 X_train_selected 只包含被选择的特征
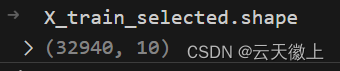
经过特征选择后训练数据只保留了10个维度的数据;
2. 超参数调优
使用网格搜索(GridSearchCV)或随机搜索(RandomizedSearchCV)来寻找逻辑回归模型的最佳超参数。
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
# 定义参数网格
param_grid = {
'C': [0.1, 1, 10, 100],
'penalty': ['l1', 'l2']
}
# 创建逻辑回归实例
logreg = LogisticRegression(solver='lbfgs', random_state=42)
# 使用网格搜索
grid_search = GridSearchCV(logreg, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_selected, y_train)
# 输出最佳参数
print("Best parameters found by grid search:", grid_search.best_params_)

3. 模型验证
通过交叉验证(Cross-Validation)来评估模型的稳定性和泛化能力。
from sklearn.model_selection import cross_val_score
# 使用网格搜索后的最佳模型进行交叉验证
scores = cross_val_score(grid_search.best_estimator_, X_train_selected, y_train, cv=5, scoring='accuracy')
print("Cross-validation scores:", scores)
print("Mean cross-validation score:", scores.mean())

4. 其他的特征工程
进行其他优质特征的生成,或者数据的SMOTE均衡化采样等形式,总之需要在在一个方面多下功夫来提升模型的性能;
六、结果解释与可视化
1. 特征重要性
对于逻辑回归模型,虽然不像随机森林那样直接提供特征重要性,但可以通过系数的绝对值来评估特征对预测结果的影响。
# 获取逻辑回归的系数
coef = grid_search.best_estimator_.coef_[0]
# 假设 feature_names 是特征名称列表
importances_logreg = abs(coef)
# 打印特征重要性
for feature, importance in zip(feature_names, importances_logreg):
print(f"{feature}: {importance}")
2. 可视化决策边界
对于二维特征空间,可以绘制决策边界来直观地理解模型的分类效果。然而,由于我们的特征空间维度较高,这通常不可行。但我们可以选择两个最重要的特征进行可视化。
# 假设我们选择了两个特征进行可视化
from matplotlib import pyplot as plt
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
# 这里为了演示,我们使用一个二维数据集
X_vis, y_vis = make_classification(n_samples=100, n_features=2, random_state=42)
scaler = StandardScaler()
X_vis_scaled = scaler.fit_transform(X_vis)
# 使用逻辑回归训练模型
logreg_vis = LogisticRegression(C=1, solver='lbfgs', random_state=42)
logreg_vis.fit(X_vis_scaled, y_vis)
# 绘制决策边界(此处代码省略,因为它取决于数据可视化的具体方式)
# ...
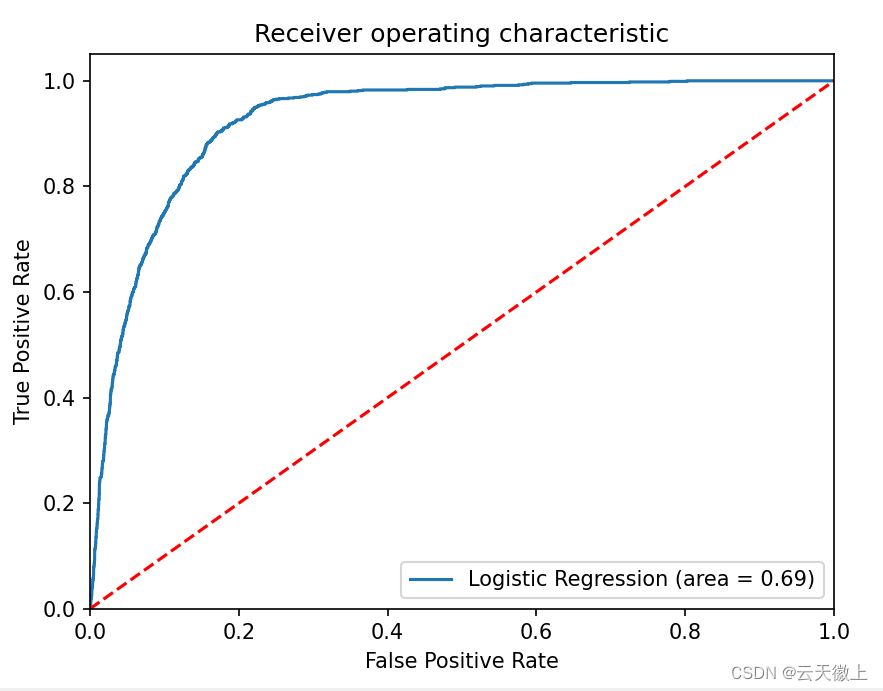
3. ROC曲线与AUC值
绘制ROC曲线并计算AUC值,以评估模型在不同阈值下的性能。
ROC曲线与AUC值
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
# 假设我们已经有了训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_train_selected, y_train, test_size=0.2, random_state=42)
# 使用最佳模型进行预测
y_pred_prob = grid_search.best_estimator_.predict_proba(X_test)[:, 1]
# 计算ROC曲线的真正率(TPR)和假正率(FPR)
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
# 计算AUC值
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
import matplotlib.pyplot as plt
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic Example')
plt.legend(loc="lower right")
plt.show()
这段代码首先计算了ROC曲线的真正率(TPR)和假正率(FPR),然后计算了AUC值,并使用matplotlib库绘制了ROC曲线。
请注意,这些代码片段假设您已经有一个准备好的数据集(X_train, y_train, X_test, y_test等),并且已经完成了数据预处理和特征选择。此外,由于实际数据集的复杂性,您可能需要根据实际情况调整这些代码片段。
最后,请确保您已经安装了scikit-learn和matplotlib库,否则您需要先通过pip或conda进行安装。
七、结论
在这个案列分析中,我们使用逻辑回归模型预测了银行客户是否会开设定期存款账户。通过数据预处理、特征工程、模型构建与训练、模型评估和优化等步骤,我们得到了一个具有一定预测能力的模型。然而,需要注意的是,逻辑回归模型在复杂数据集上可能表现不佳,特别是对于非线性关系或高维数据。因此,在实际应用中,可能需要尝试其他更复杂的模型或集成学习方法来进一步提高预测性能。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 105
105 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)