自然语言处理前馈网络(MLP、CNN)
介绍两种前馈神经网络:多层感知器和卷积神经网络。多层感知器在结构上将多个感知器分组在一个单层,并将多个层叠加在一起。我们稍后将介绍多层感知器,并在“示例:利用MLP实现通过姓氏预测国籍”中展示它们在多层分类中的应用。积神经网络,在处理数字信号时深受窗口滤波器的启发。通过这种窗口特性,卷积神经网络能够在输入中学习局部化模式,这不仅使其成为计算机视觉的主轴,而且是检测单词和句子等序列数据中的子结构的理
自然语言处理前馈网络(MLP、CNN)
一、背景介绍
1.1、实验简介
这本实验我们将介绍两种前馈神经网络:多层感知器和卷积神经网络。多层感知器在结构上将多个感知器分组在一个单层,并将多个层叠加在一起。我们稍后将介绍多层感知器,并在“示例:利用MLP实现通过姓氏预测国籍”中展示它们在多层分类中的应用。
本实验研究的第二种前馈神经网络,卷积神经网络,在处理数字信号时深受窗口滤波器的启发。通过这种窗口特性,卷积神经网络能够在输入中学习局部化模式,这不仅使其成为计算机视觉的主轴,而且是检测单词和句子等序列数据中的子结构的理想候选。我们在“卷积神经网络”中概述了卷积神经网络,并在“示例:使用实现通过姓氏预测国籍”中演示了它们的使用。
在本实验中,多层感知器和卷积神经网络被分组在一起,因为它们都是前馈神经网络。我们将在自然语言处理领域中实现
在我们介绍这些不同的模型时,需要理解事物如何工作的一个有用方法是在计算数据张量时注意它们的大小和形状。每种类型的神经网络层对它所计算的数据张量的大小和形状都有特定的影响,理解这种影响可以极大地有助于对这些模型的深入理解。
1.2、数据介绍——The Surname Dataset
姓氏数据集,它收集了来自18个不同国家的10,000个姓氏,这些姓氏是作者从互联网上不同的姓名来源收集的。该数据集具有一些使其有趣的属性。第一个性质是它是相当不平衡的。排名前三的课程占数据的60%以上:27%是英语,21%是俄语,14%是阿拉伯语。剩下的15个民族的频率也在下降——这也是语言特有的特性。第二个特点是,在国籍和姓氏正字法(拼写)之间有一种有效和直观的关系。有些拼写变体与原籍国联系非常紧密(比如“O ‘Neill”、“Antonopoulos”、“Nagasawa”或“Zhu”)。
二、利用MLP实现通过姓氏预测国籍
2.1MLP介绍
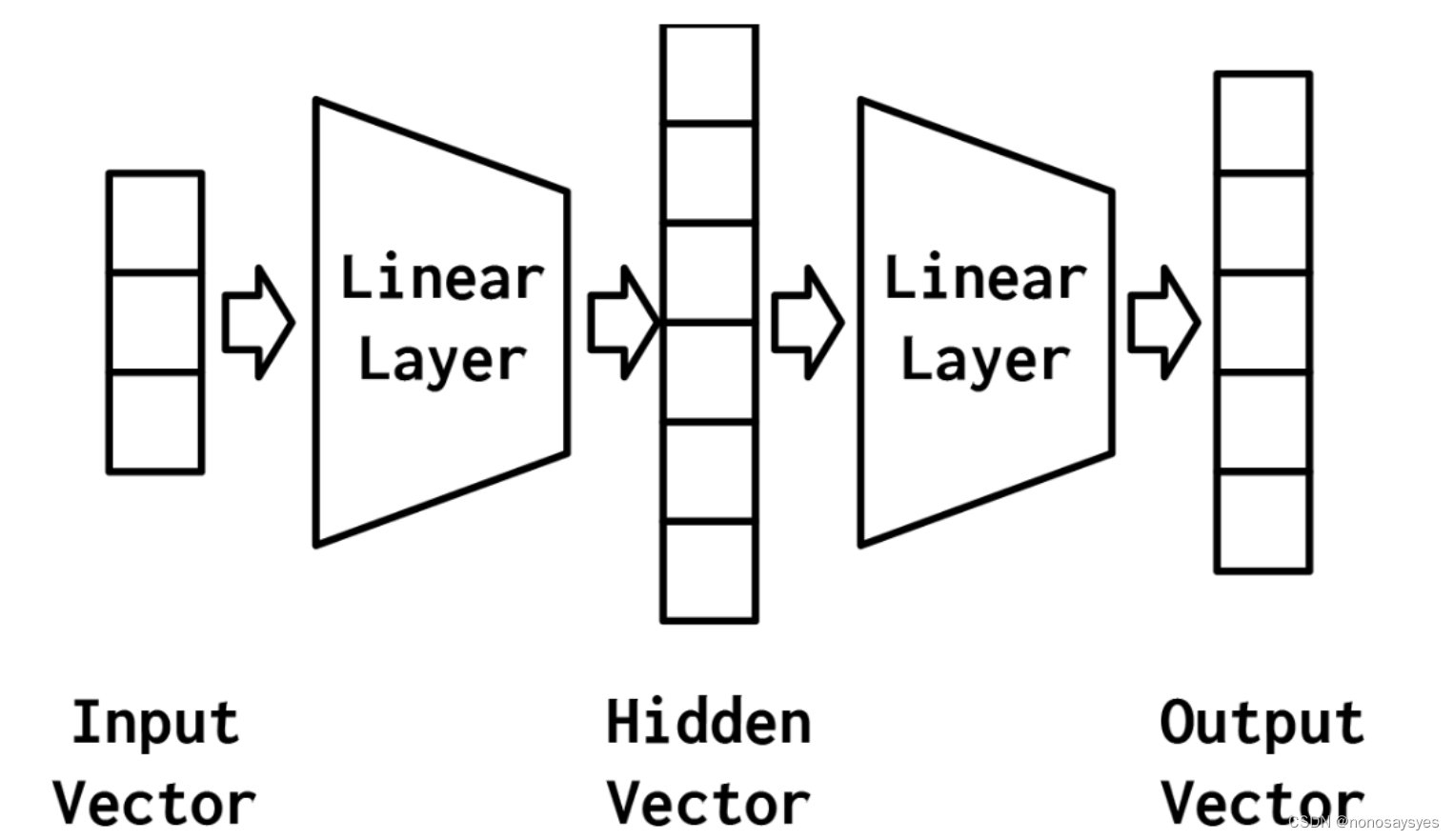
多层感知器(MLP)被认为是最基本的神经网络构建模块之一。感知器将数据向量作为输入,计算出一个输出值。在MLP中,许多感知器被分组,以便单个层的输出是一个新的向量,而不是单个输出值。在PyTorch中,正如您稍后将看到的,这只需设置线性层中的输出特性的数量即可完成。MLP的另一个方面是,它将多个层与每个层之间的非线性结合在一起。
最简单的MLP,如图所示,由三个表示阶段和两个线性层组成。第一阶段是输入向量。这是给定给模型的向量。给定输入向量,第一个线性层计算一个隐藏向量——表示的第二阶段。隐藏向量之所以这样被调用,是因为它是位于输入和输出之间的层的输出。我们所说的“层的输出”是什么意思?理解这个的一种方法是隐藏向量中的值是组成该层的不同感知器的输出。使用这个隐藏的向量,第二个线性层计算一个输出向量。在二进制任务中,输出向量仍然可以是1。在多类设置中,将在本实验后面的“示例:带有多层感知器的姓氏分类”一节中看到,输出向量是类数量的大小。虽然在这个例子中,我们只展示了一个隐藏的向量,但是有可能有多个中间阶段,每个阶段产生自己的隐藏向量。最终的隐藏向量总是通过线性层和非线性的组合映射到输出向量。

2.2数据预处理
2.2.1读取、查看数据,并将数据按照训练集70%,验证集15%,测试集15%进行划分
import collections
import numpy as np
import pandas as pd
import re
from argparse import Namespaceargs
#定义命名空间,用于后续调用
args = Namespace(
raw_dataset_csv="data/surnames/surnames.csv",
#训练70%,验证15%,测试15%
train_proportion=0.7,
val_proportion=0.15,
test_proportion=0.15,
output_munged_csv="data/surnames/surnames_with_splits.csv",
seed=1337
)
#读取数据,初步分析数据
surnames = pd.read_csv(args.raw_dataset_csv, header=0)
surnames.head()
#查看国籍种类
set(surnames.nationality)
#根据国籍对姓氏划分
by_nationality = collections.defaultdict(list)
for _, row in surnames.iterrows():
by_nationality[row.nationality].append(row.to_dict())#根据国籍划分
# 对每一个国籍内的数据按照比例划分为训练集、验证集、测试集,并贴上相应标签
final_list = []
np.random.seed(args.seed)#随机种子
for _, item_list in sorted(by_nationality.items()):#对内部数据进行排序
np.random.shuffle(item_list)
n = len(item_list)
n_train = int(args.train_proportion*n)
n_val = int(args.val_proportion*n)
n_test = int(args.test_proportion*n)
# Give data point a split attribute
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:]:
item['split'] = 'test'
# Add to final list
final_list.extend(item_list)
#将文件保存至对应路径,方便后续调用
final_surnames = pd.DataFrame(final_list)
final_surnames.to_csv(args.output_munged_csv, index=False)
2.2.2定义Vocabulary类
用于处理文本并提取词汇以进行映射
class Vocabulary(object):
"""处理文本并提取词汇以进行映射的类"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): 一个预先存在的词汇到索引的映射
add_unk (bool): 是否添加UNK标记的标志
unk_token (str): 要添加到词汇表中的UNK标记
"""
#如果 token_to_idx 为 None,则初始化为空字典。接着,将传入的或初始化的 token_to_idx 赋值给实例变量 self._token_to_idx。然后创建一个从索引到单词的反向映射字典 self._idx_to_token。
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
#初始化 add_unk 和 unk_token 参数,并设置 unk_index 为 -1。如果 add_unk 为 True,则调用 add_token 方法将 unk_token 添加到词汇表,并更新 unk_index。
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
#定义序列化方法,返回一个可序列化的字典
def to_serializable(self):
""" returns a dictionary that can be serialized """
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
#反序列化,可以从序列化字典中实例化一个Vocabulary对象
def from_serializable(cls, contents):
""" instantiates the Vocabulary from a serialized dictionary """
return cls(**contents)
#添加单词,将一个单词添加到词汇表中。如果单词已经存在,则返回其索引;否则,分配一个新的索引。
def add_token(self, token):#
"""根据单词更新映射字典
Args:
token (str):要添加到词汇表中的单词
Returns:
index (int): 对应于单词的整数索引
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
#多次调用,添加多个单词
def add_many(self, tokens):
"""将一个单词列表添加到词汇表中
Args:
tokens (list): 字符串单词列表
Returns:
indices (list): 对应于这些单词的索引列表
"""
return [self.add_token(token) for token in tokens]
#根据单词寻找index
def lookup_token(self, token):
"""检索与单词关联的索引,如果单词不存在则返回UNK索引.
Args:
token (str): 要查找的单词
Returns:
index (int): 对应于单词的索引
Notes:
`unk_index` 需要 >=0(已添加到词汇表中)才能启用UNK功能
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
#根据index寻找单词
def lookup_index(self, index):
"""返回与索引关联的单词
Args:
index (int): 要查找的索引
Returns:
token (str): 对应于索引的单词
Raises:
KeyError: 如果索引不在词汇表中
"""
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
2.2.3定义SurnameVectorizer类
将姓氏进行向量化处理,同时管理字符和国籍的词汇表
class SurnameVectorizer(object):
""" 协调词汇表并将其付诸使用的矢量化器"""
def __init__(self, surname_vocab, nationality_vocab):
"""
Args:
surname_vocab (Vocabulary): 将字符映射为整数
nationality_vocab (Vocabulary):将国籍映射为整数
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
Args:
surname (str):姓氏
Returns:
one_hot (np.ndarray): 压缩的一次性编码
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""从数据集数据帧实例化矢量化器
Args:
surname_df (pandas.DataFrame): 姓氏数据集
Returns:
SurnameVectorizer 的一个实例
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab)
def to_serializable(self):
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable()}
2.2.4定义Dataset类
用于处理包含姓氏及其对应国籍的数据集。这个类适用于 PyTorch 框架,非常适合机器学习任务。
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
Args:
surname_df (pandas.DataFrame): 数据集
vectorizer (SurnameVectorizer): 用于转换数据的向量化器实例。
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# 类别权重
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
#加载数据集并从头创建一个新的向量化器
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
#加载数据集和相应的向量化器,用于向量化器已经缓存以供重用的情况
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""Load dataset and the corresponding vectorizer.
Used in the case in the vectorizer has been cached for re-use
Args:
surname_csv (str): location of the dataset
vectorizer_filepath (str): location of the saved vectorizer
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
#从文件中加载向量化器的静态方法
def load_vectorizer_only(vectorizer_filepath):
"""a static method for loading the vectorizer from file
Args:
vectorizer_filepath (str): the location of the serialized vectorizer
Returns:
an instance of SurnameVectorizer
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
#使用 JSON 将向量化器保存到磁盘
def save_vectorizer(self, vectorizer_filepath):
"""saves the vectorizer to disk using json
Args:
vectorizer_filepath (str): the location to save the vectorizer
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
#返回向量化器实例。
def get_vectorizer(self):
""" returns the vectorizer """
return self._vectorizer
#设置当前数据集切分(训练、验证或测试),更新目标数据集和其大小。
def set_split(self, split="train"):
""" selects the splits in the dataset using a column in the dataframe """
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dictionary holding the data point's:
features (x_surname)
label (y_nationality)
"""
row = self._target_df.iloc[index]
surname_vector = \
self._vectorizer.vectorize(row.surname)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_vector,
'y_nationality': nationality_index}
#给定批量大小,返回数据集中批次的数量
def get_num_batches(self, batch_size):
"""Given a batch size, return the number of batches in the dataset
Args:
batch_size (int)
Returns:
number of batches in the dataset
"""
return len(self) // batch_size
#一个包装 PyTorch DataLoader 的生成器函数, 它将确保每个张量都位于正确的设备位置。
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
A generator function which wraps the PyTorch DataLoader. It will
ensure each tensor is on the write device location.
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
2.3确定模型——MLP
class SurnameClassifier(nn.Module):
""" A 2-layer Multilayer Perceptron for classifying surnames """
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): 输入向量的大小
hidden_dim (int): 第一个线性层的输出大小
output_dim (int): 第二个线性层的输出大小
"""
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""分类器的前向传播
Args:
x_in (torch.Tensor): 输入数据张量。.
x_in的形状应为 (batch, input_dim)
apply_softmax (bool): 是否应用 softmax 激活函数
如果与交叉熵损失一起使用,则应为 False
Returns:
结果张量。其形状应为 (batch, output_dim)
"""
intermediate_vector = F.relu(self.fc1(x_in))
prediction_vector = self.fc2(intermediate_vector)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
2.4模型训练
2.4.1训练前准备工作
#确定训练参数
def make_train_state(args):
return {'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'learning_rate': args.learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': args.model_state_file}
#更新训练状态
def update_train_state(args, model, train_state):
"""处理训练状态更新.
Components:
- Early Stopping:防止过拟合。
- Model Checkpoint: 如果模型性能更好,则保存模型
:param args: 主参数
:param model: 要训练的模型
:param train_state: 一个表示训练状态值的字典
:returns:
一个新的 train_state
"""
# 至少保存一次模型
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# 如果性能提升则保存模型
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# 如果损失变大
if loss_t >= train_state['early_stopping_best_val']:
# 更新步数
train_state['early_stopping_step'] += 1
# 损失减少
else:
# 保存最好的模型
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# Reset early stopping step
train_state['early_stopping_step'] = 0
# Stop early ?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
#计算准确率
def compute_accuracy(y_pred, y_target):
_, y_pred_indices = y_pred.max(dim=1)
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
#设置随机种子
def set_seed_everywhere(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
#如果目录路径不存在,创建该目录
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
2.4.2开始训练
#定义命名空间,确定各类参数
args = Namespace(
# 数据和路径信息
surname_csv="data/surnames/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/surname_mlp",
# 模型超参数
hidden_dim=300,
# 训练超参数
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# 运行时选项
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# 检查cuda
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# 设置种子
set_seed_everywhere(args.seed, args.cuda)
# 处理dirs
handle_dirs(args.save_dir)
#初始化
if args.reload_from_files:
# 从检查点继续训练
print("Reloading!")
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# 创建数据集和向量化器
print("Creating fresh!")
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))
#训练周期
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
#使用交叉熵作为loss
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
#优化器选择Adam
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
#迭代训练数据集
#setup: 批量生成器,设置损耗和acc为0,设置训练模式
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# 训练周期为以下5步:
# --------------------------------------
# 第一步.梯度置0
optimizer.zero_grad()
# 第二步.计算输出
y_pred = classifier(batch_dict['x_surname'])
# 第三步.计算loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 第四步:反向传播计算梯度
loss.backward()
# 第5步.使用优化器采取梯度步骤
optimizer.step()
# -----------------------------------------
# 计算当前批次的准确率,并更新 running_acc
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
更新训练进度条,显示当前的损失、准确率和周期
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# 迭代验证集
# setup: 批量生成器,设置损耗和acc为0; 设置为eval模式
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 计算loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")

2.5评估模型
该模型对测试数据的准确性达到50%左右。会注意到在训练数据上的性能更高。这是因为模型总是更适合它所训练的数据,所以训练数据的性能并不代表新数据的性能。如果遵循代码,你可以尝试隐藏维度的不同大小,应该注意到性能的提高。然而,这种增长不会很大(尤其是与“用CNN对姓氏进行分类的例子”中的模型相比)。其主要原因是收缩的one-hot向量化方法是一种弱表示。虽然它确实简洁地将每个姓氏表示为单个向量,但它丢弃了字符之间的顺序信息,这对于识别起源非常重要
# 使用最佳可用模型计算测试集上的损失和精度
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 计算loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))

2.6使用模型预测
def predict_nationality(surname, classifier, vectorizer):
"""利用新的姓氏预测国籍
Args:
surname (str): 需要分类的姓氏
classifier (SurnameClassifer): 一个现有的分类器
vectorizer (SurnameVectorizer): 相应的向量化器
Returns:
一个字典,包含可能性最大的国籍和对应概率
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).view(1, -1)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.to("cpu")
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
给定一个姓氏作为字符串,该函数将首先应用向量化过程,然后获得模型预测。注意,我们包含了apply_softmax标志,所以结果包含概率。模型预测,在多项式的情况下,是类概率的列表。我们使用PyTorch张量最大函数来得到由最高预测概率表示的最优类


不仅要看最好的预测,还要看更多的预测。例如,NLP中的标准实践是采用k-best预测并使用另一个模型对它们重新排序。PyTorch提供了一个torch.topk函数,它提供了一种方便的方法来获得这些预测,
def predict_topk_nationality(name, classifier, vectorizer, k=5):
vectorized_name = vectorizer.vectorize(name)
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
prediction_vector = classifier(vectorized_name, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# 返回大小为1,k
probability_values = probability_values.detach().numpy()[0]
indices = indices.detach().numpy()[0]
results = []
for prob_value, index in zip(probability_values, indices):
nationality = vectorizer.nationality_vocab.lookup_index(index)
results.append({'nationality': nationality,
'probability': prob_value})
return results
new_surname = input("Enter a surname to classify: ")
classifier = classifier.to("cpu")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))


三、利用CNN实现通过姓氏预测国籍
3.1CNN介绍
3.1.1CNN
在本实验的第一部分中,我们深入研究了MLPs、由一系列线性层和非线性函数构建的神经网络。mlp不是利用顺序模式的最佳工具。例如,在姓氏数据集中,姓氏可以有(不同长度的)段,这些段可以显示出相当多关于其起源国家的信息(如“O’Neill”中的“O”、“Antonopoulos”中的“opoulos”、“Nagasawa”中的“sawa”或“Zhu”中的“Zh”)。这些段的长度可以是可变的,挑战是在不显式编码的情况下捕获它们。
在本节中,我们将介绍卷积神经网络(CNN),这是一种非常适合检测空间子结构(并因此创建有意义的空间子结构)的神经网络。CNNs通过使用少量的权重来扫描输入数据张量来实现这一点。通过这种扫描,它们产生表示子结构检测(或不检测)的输出张量。
在本节的其余部分中,我们首先描述CNN的工作方式,以及在设计CNN时应该考虑的问题。我们深入研究CNN超参数,目的是提供直观的行为和这些超参数对输出的影响。最后,我们通过几个简单的例子逐步说明CNNs的机制。在“示例:利用CNN实现通过姓氏预测国籍”中,我们将深入研究一个更广泛的示例。
3.1.2历史背景
CNNs的名称和基本功能源于经典的数学运算卷积。卷积已经应用于各种工程学科,包括数字信号处理和计算机图形学。一般来说,卷积使用程序员指定的参数。这些参数被指定来匹配一些功能设计,如突出边缘或抑制高频声音。事实上,许多Photoshop滤镜都是应用于图像的固定卷积运算。然而,在深度学习和本实验中,我们从数据中学习卷积滤波器的参数,因此它对于解决当前的任务是最优的。
3.1.3CNN超参数
为了理解不同的设计决策对CNN意味着什么,我们在图4-6中展示了一个示例。在本例中,单个“核”应用于输入矩阵。卷积运算(线性算子)的精确数学表达式对于理解这一节并不重要,但是从这个图中可以直观地看出,核是一个小的方阵,它被系统地应用于输入矩阵的不同位置

输入矩阵与单个产生输出矩阵的卷积核(也称为特征映射)在输入矩阵的每个位置应用内核。在每个应用程序中,内核乘以输入矩阵的值及其自身的值,然后将这些乘法相加kernel具有以下超参数配置:kernel_size=2,stride=1,padding=0,以及dilation=1。这些超参数解释如下:
虽然经典卷积是通过指定核的具体值来设计的,但是CNN是通过指定控制CNN行为的超参数来设计的,然后使用梯度下降来为给定数据集找到最佳参数。两个主要的超参数控制卷积的形状(称为kernel_size)和卷积将在输入数据张量(称为stride)中相乘的位置。还有一些额外的超参数控制输入数据张量被0填充了多少(称为padding),以及当应用到输入数据张量(称为dilation)时,乘法应该相隔多远。在下面的小节中,我们将更详细地介绍这些超参数。
3.1.4卷积计算的维度
首先要理解的概念是卷积运算的维数。在图4-6和本节的其他图中,我们使用二维卷积进行说明,但是根据数据的性质,还有更适合的其他维度的卷积。在PyTorch中,卷积可以是一维、二维或三维的,分别由Conv1d、Conv2d和Conv3d模块实现。一维卷积对于每个时间步都有一个特征向量的时间序列非常有用。在这种情况下,我们可以在序列维度上学习模式。NLP中的卷积运算大多是一维的卷积。另一方面,二维卷积试图捕捉数据中沿两个方向的时空模式;例如,在图像中沿高度和宽度维度——为什么二维卷积在图像处理中很流行。类似地,在三维卷积中,模式是沿着数据中的三维捕获的。例如,在视频数据中,信息是三维的,二维表示图像的帧,时间维表示帧的序列。就本课程而言,我们主要使用Conv1d。
3.1.5channels
非正式地,通道(channel)是指沿输入中的每个点的特征维度。例如,在图像中,对应于RGB组件的图像中的每个像素有三个通道。在使用卷积时,文本数据也可以采用类似的概念。从概念上讲,如果文本文档中的“像素”是单词,那么通道的数量就是词汇表的大小。如果我们更细粒度地考虑字符的卷积,通道的数量就是字符集的大小(在本例中刚好是词汇表)。在PyTorch卷积实现中,输入通道的数量是in_channels参数。卷积操作可以在输出(out_channels)中产生多个通道。您可以将其视为卷积运算符将输入特征维“映射”到输出特征维。图4-7和图4-8说明了这个概念。


很难立即知道有多少输出通道适合当前的问题。为了简化这个困难,我们假设边界是1,1,024——我们可以有一个只有一个通道的卷积层,也可以有一个只有1,024个通道的卷积层。现在我们有了边界,接下来要考虑的是有多少个输入通道。一种常见的设计模式是,从一个卷积层到下一个卷积层,通道数量的缩减不超过2倍。这不是一个硬性的规则,但是它应该让您了解适当数量的out_channels是什么样子的。
3.1.6核大小
核矩阵的宽度称为核大小(PyTorch中的kernel_size)。在图4-6中,核大小为2,而在图4-9中,我们显示了一个大小为3的内核。卷积将输入中的空间(或时间)本地信息组合在一起,每个卷积的本地信息量由内核大小控制。然而,通过增加核的大小,也会减少输出的大小(Dumoulin和Visin, 2016)。这就是为什么当核大小为3时,输出矩阵是图4-9中的2x2,而当核大小为2时,输出矩阵是图4-6中的3x3。

此外,可以将NLP应用程序中核大小的行为看作类似于通过查看单词组捕获语言模式的n-gram的行为。使用较小的核大小,可以捕获较小的频繁模式,而较大的核大小会导致较大的模式,这可能更有意义,但是发生的频率更低。较小的核大小会导致输出中的细粒度特性,而较大的核大小会导致粗粒度特性。
3.1.7步长
Stride控制卷积之间的步长。如果步长与核相同,则内核计算不会重叠。另一方面,如果跨度为1,则内核重叠最大。输出张量可以通过增加步幅的方式被有意的压缩来总结信息,如图4-10所示。

3.1.8PADDING
即使stride和kernel_size允许控制每个计算出的特征值有多大范围,它们也有一个有害的、有时是无意的副作用,那就是缩小特征映射的总大小(卷积的输出)。为了抵消这一点,输入数据张量被人为地增加了长度(如果是一维、二维或三维)、高度(如果是二维或三维)和深度(如果是三维),方法是在每个维度上附加和前置0。这意味着CNN将执行更多的卷积,但是输出形状可以控制,而不会影响所需的核大小、步幅或扩展。图4-11展示了正在运行的填充。

3.1.9膨胀
膨胀控制卷积核如何应用于输入矩阵。在图4-12中,我们显示,将膨胀从1(默认值)增加到2意味着当应用于输入矩阵时,核的元素彼此之间是两个空格。另一种考虑这个问题的方法是在核中跨跃——在核中的元素或核的应用之间存在一个step size,即存在“holes”。这对于在不增加参数数量的情况下总结输入空间的更大区域是有用的。当卷积层被叠加时,扩张卷积被证明是非常有用的。连续扩张的卷积指数级地增大了“接受域”的大小;即网络在做出预测之前所看到的输入空间的大小

3.2数据预处理
该部分可以直接沿用MLP实验中的源代码,对数据的预处理操作一致。
3.3确定模型——MLP
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): 输入特征向量的大小
num_classes (int): 输出预测向量的大小
num_channels (int): 网络中使用的常量通道大小
"""
super(SurnameClassifier, self).__init__()
#共四层卷积以及最后一层全连接
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""前向传播方法
Args:
x_surname (torch.Tensor): 输入数据张量
x_surname的形状应为 (batch, initial_num_channels, max_surname_length)
apply_softmax (bool): 是否应用 softmax 激活函数
如果与交叉熵损失一起使用,则应为 False
Returns:
结果张量。其形状应为 (batch, num_classes)
"""
features = self.convnet(x_surname).squeeze(dim=2)
prediction_vector = self.fc(features)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
3.4模型训练
3.4.1训练前准备工作
#确定训练参数
def make_train_state(args):
return {'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'learning_rate': args.learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': args.model_state_file}
#更新训练状态
def update_train_state(args, model, train_state):
"""处理训练状态更新.
Components:
- Early Stopping:防止过拟合。
- Model Checkpoint: 如果模型性能更好,则保存模型
:param args: 主参数
:param model: 要训练的模型
:param train_state: 一个表示训练状态值的字典
:returns:
一个新的 train_state
"""
# 至少保存一次模型
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# 如果性能提升则保存模型
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# 如果损失变大
if loss_t >= train_state['early_stopping_best_val']:
# 更新步数
train_state['early_stopping_step'] += 1
# 损失减少
else:
# 保存最好的模型
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# R重置早停步数
train_state['early_stopping_step'] = 0
# Stop early ?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
#计算准确率
def compute_accuracy(y_pred, y_target):
_, y_pred_indices = y_pred.max(dim=1)
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
#设置随机种子
def set_seed_everywhere(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
#如果目录路径不存在,创建该目录
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
3.4.2开始训练
#定义命名空间,确定各类参数
args = Namespace(
# 数据和路径信息
surname_csv="data/surnames/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/cnn",
# 模型超参数
hidden_dim=100,
num_channels=256,
# 训练超参数
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1,
# 运行时选项
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
catch_keyboard_interrupt=True
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# 检查 CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# 设置随机种子
set_seed_everywhere(args.seed, args.cuda)
# 处理目录
handle_dirs(args.save_dir)
if args.reload_from_files:
# 从检查点继续训练
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# 创建数据集和向量化器
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(initial_num_channels=len(vectorizer.surname_vocab),
num_classes=len(vectorizer.nationality_vocab),
num_channels=args.num_channels)
classifer = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
#使用交叉熵作为loss
loss_func = nn.CrossEntropyLoss(weight=dataset.class_weights)
#使用Adam作为优化器
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
#使用 ReduceLROnPlateau 调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
#进度条初始化
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
#训练周期
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
#迭代训练数据集
#setup: 批量生成器,设置损耗和acc为0,设置训练模式
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# 训练周期为以下5步:
# --------------------------------------
# 第一步:将梯度归零
optimizer.zero_grad()
# 第二步:计算模型输出
y_pred = classifier(batch_dict['x_surname'])
# 第三步:计算损失,并更新 running_loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 第四步:反向传播计算梯度。
loss.backward()
# 第五步:优化器更新模型参数。
optimizer.step()
# -----------------------------------------
计算当前批次的准确率,并更新 running_acc。
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
更新训练进度条,显示当前的损失、准确率和周期
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# 设置验证数据集
# setup: 批量生成器,设置损耗和acc为0; 设置为eval模式
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算模型输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失,并更新 running_loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算当前批次的准确率,并更新 running_acc。
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")

3.5评估模型
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算模型输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失,并更新 running_loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算当前批次的准确率,并更新 running_acc。
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))

3.6使用模型预测
在本例中,相较于MLP的对应函数,predict_nationality()函数的一部分发生了更改:我们没有使用视图方法重塑新创建的数据张量以添加批处理维度,而是使用PyTorch的unsqueeze()函数在批处理应该在的位置添加大小为1的维度。相同的更改反映在predict_topk_nationality()函数中。
def predict_nationality(surname, classifier, vectorizer):
"""Predict the nationality from a new surname
Args:
surname (str):要分类的姓氏
classifier (SurnameClassifer): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化工具
Returns:
一个字典,包含最可能的国籍及其概率
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
PyTorch提供了一个torch.topk函数,它提供了一种方便的方法来获得这些预测,可以查看多个预测
def predict_topk_nationality(surname, classifier, vectorizer, k=5):
"""Predict the top K nationalities from a new surname
Args:
surname (str): 要分类的姓氏
classifier (SurnameClassifer): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化工具
k (int): 要返回的前 K 个国籍数量
Returns:
一个字典列表,每个字典包含一个国籍及其概率
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(dim=0)
prediction_vector = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# returned size is 1,k
probability_values = probability_values[0].detach().numpy()
indices = indices[0].detach().numpy()
results = []
for kth_index in range(k):
nationality = vectorizer.nationality_vocab.lookup_index(indices[kth_index])
probability_value = probability_values[kth_index]
results.append({'nationality': nationality,
'probability': probability_value})
return results
new_surname = input("Enter a surname to classify: ")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))

四、个人梳理总结
4.1MLP与CNN模型对比
1.1准确率
多层感知机(MLP):
- 优势:MLP 的结构相对简单,适合处理已经向量化的输入数据。对于一些特征已经很明显的数据,MLP 也可以取得较高的准确率。
- 潜在问题:MLP 缺乏对局部模式的捕捉能力,可能在处理序列数据时表现不如 CNN。
卷积神经网络(CNN):
- 优势:CNN 对序列数据(如字符序列)的特征提取能力强,能够捕捉到局部的模式和模式的组合,因此在处理姓氏这种字符序列任务时,可能会表现得更好。
- 潜在问题:如果模型架构设计不当或数据不足,可能会导致欠拟合或过拟合问题。
在本实验中MLP与CNN的测试集准确率如下图所示
MLP

CNN

明显可见CNN的准确率高于MLP。
1.2训练效率
卷积神经网络(CNN):
- 训练效率:由于卷积操作的计算复杂度较高,CNN 的训练时间较长。需要更多的计算资源(如 GPU)来加速训练过程。
- 收敛速度:由于卷积层能够有效提取特征,CNN 在处理序列数据时收敛速度较快。
多层感知机(MLP):
- 训练效率:MLP 的计算复杂度相对较低,训练时间较短。对于一些简单任务,可以在 CPU 上高效训练。
- 收敛速度:MLP 的收敛速度取决于数据的特征和网络的结构。对于复杂数据,收敛速度可能较慢。
MLP

CNN

在本实验的情况中,在相同训练轮次下,MLP的训练时间为3分42,而CNN的训练时长为16分49,CNN的训练时长远大于MLP,对计算资源的要求更高。
4.2实验本身不足
本实验两个模型的准确率都不高,既取决于模型架构本身,又有很重要的原因在我们的数据预处理操作中,收缩的one-hot向量化方法是一种弱表示。虽然它确实简洁地将每个姓氏表示为单个向量,但它丢弃了字符之间的顺序信息,这对于识别起源非常重要。
4.3实验改进方向
4.3.1尝试更好的向量化表示方法
用更加合适的向量化表示方法来提取语义之间的依赖,可以更好的提升我们所能达到的上限。
4.3.2尝试不同的模型方法
对于MLP而言,可以尝试drpoout等正则方法进行尝试,尝试不同方法间的组合。
对于CNN而言,相应的Pooling操作、batch Normalization、network-in-network connection和residual connections可能会对模型效果有不同的提升。
4.3.3尝试不同的架构
可以尝试最主流的模型架构,用更合适nlp的架构来完成相应的任务。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)