【机器学习】基于层次的聚类方法:理论与实践
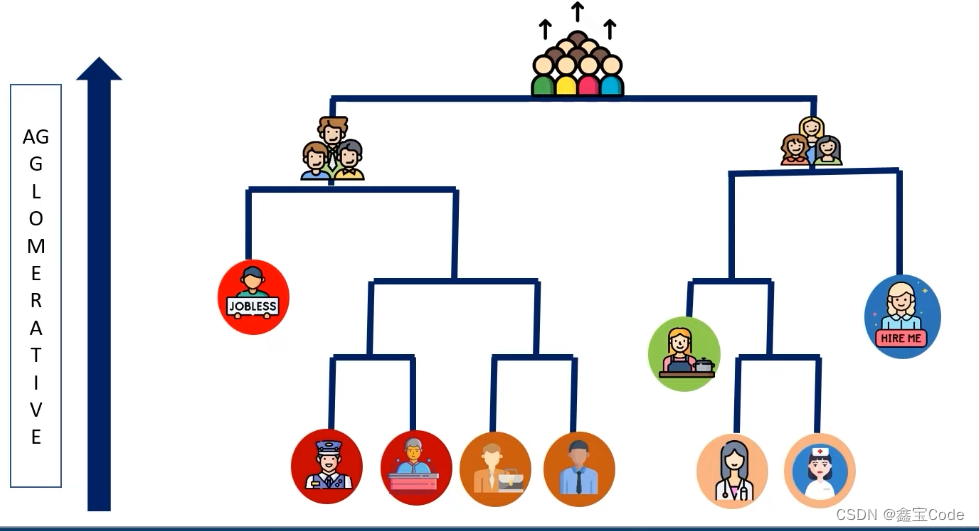
层次聚类算法通过逐步合并或分裂数据点(或簇)来构建一个层次结构。根据合并或分裂的方向,层次聚类可分为两种主要类型:凝聚型(Agglomerative)和分裂型(Divisive)。凝聚型聚类:从每个数据点自成一簇开始,逐步合并最相似的簇,直至所有数据点合并成一个簇或达到预设的终止条件。分裂型聚类:初始将所有数据作为一个簇,然后逐渐分裂成越来越小的簇,直到每个数据点成为一个独立的簇或满足终止条件。


🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
基于层次的聚类方法:理论与实践
引言
在数据科学与机器学习领域,聚类算法是无监督学习的重要组成部分,用于探索数据的内在结构,识别数据点之间的相似性并将其分组成有意义的簇。层次聚类(Hierarchical Clustering)作为一种经典的聚类方法,因其能够提供数据点之间层次关系的直观树状图(又称树状聚类图或 dendrogram),在生物学、社会网络分析、图像分割等多个领域有着广泛的应用。本文将深入探讨层次聚类的基本概念、算法类型、实现步骤、优缺点以及实际应用案例,帮助读者全面理解这一重要算法。
1. 层次聚类基础
1.1 概述
层次聚类算法通过逐步合并或分裂数据点(或簇)来构建一个层次结构。根据合并或分裂的方向,层次聚类可分为两种主要类型:凝聚型(Agglomerative)和分裂型(Divisive)。
- 凝聚型聚类:从每个数据点自成一簇开始,逐步合并最相似的簇,直至所有数据点合并成一个簇或达到预设的终止条件。
- 分裂型聚类:初始将所有数据作为一个簇,然后逐渐分裂成越来越小的簇,直到每个数据点成为一个独立的簇或满足终止条件。
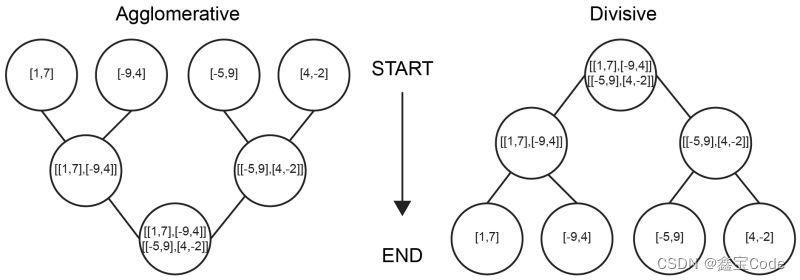
1.2 距离度量
层次聚类算法的关键在于如何定义数据点或簇之间的相似度或距离。常见的距离度量包括欧氏距离、曼哈顿距离、余弦相似度和Jaccard相似度等。
2. 算法实现步骤
2.1 凝聚型聚类步骤
- 初始化:每个数据点视为一个簇。
- 计算距离:根据所选距离度量,计算每对簇间的距离。
- 合并簇:选择距离最近的两个簇合并为一个新的簇。
- 更新距离:重新计算新簇与其他簇之间的距离,常用方法有单连接(最小距离)、全连接(最大距离)、平均连接(簇间所有点对距离的平均)和重心连接。
- 重复步骤3-4,直到满足终止条件(如指定的簇数量、距离阈值或达到最大迭代次数)。
2.2 分裂型聚类步骤
分裂型聚类的步骤与凝聚型相反,从一个包含所有数据点的大簇开始,根据某种准则(如簇内差异最大化)逐步分裂簇,直至达到预定的簇数量或分裂标准。
3. 树状聚类图(Dendrogram)
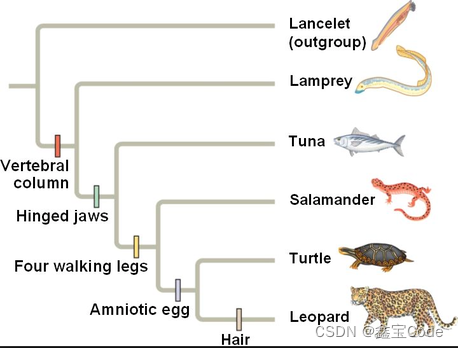
树状聚类图是层次聚类结果的图形化展示,横轴表示数据点或簇,纵轴表示合并或分裂时的距离。通过设定一个截断阈值,可以从dendrogram中得到一个特定数量的簇。
4. 优缺点
4.1 优点
- 直观性:树状图提供了数据点间关系的直观展示。
- 灵活性:用户可以根据需要选择不同的距离度量和簇合并规则。
- 可解释性:层次结构易于理解和解释,便于发现数据的层次结构。
4.2 缺点
- 计算复杂度:随着数据点数量的增加,计算距离矩阵的时间复杂度和空间复杂度呈平方级增长。
- 选择难题:确定最佳的簇数目较为困难,通常依赖于主观判断或额外的评估标准。
- 敏感性:对初始距离度量和连接准则敏感,不同的选择可能导致显著不同的聚类结果。
5. 实践应用
5.1 生物信息学
在基因表达数据分析中,层次聚类用于识别具有相似表达模式的基因或样本,帮助理解基因功能和疾病机制。
5.2 社交网络分析
通过对社交网络中的用户或社区进行层次聚类,可以发现网络中的子群结构,理解用户之间的互动模式和影响力传播路径。

5.3 图像分割
在计算机视觉领域,层次聚类可用于图像分割,通过将像素点根据颜色、纹理等特征聚类,实现对图像内容的有效划分。
6. 结论
层次聚类作为一种强大的无监督学习工具,为复杂数据的组织和理解提供了有效的途径。尽管存在计算复杂度高和簇数选择困难等局限性,但通过合理的参数选择和优化策略,层次聚类在众多领域展现出其独特的价值和应用潜力。随着算法理论的进一步发展和计算资源的不断进步,层次聚类方法有望在未来的数据分析和机器学习任务中扮演更加重要的角色。



助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 112
112 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)