
GPU 用于 ETL?为 Apache Spark SQL 操作进行 ETL 体系结构优化
然而,这是以更高的相关集群成本为代价的。对于 CROSS JOIN,一种不太常见的高计算和高度并行化操作, GPU 在更高的速度和更低的成本方面占据主导地位。这导致复杂性呈指数级增长。对于计算量大的 CROSS JOIN 操作,我们观察到通过在光子( GPU )上使用 RAPIDS 加速器( GPU )可以节省一个数量级的时间和成本。成本差异的主要驱动因素是,我们实验的 CPU 集群的 DBU 评
目录
使用 GPU 进行提取、转换和加载(ETL)操作的 NVIDIA RAPIDS Accelerator for Apache Spark 可以在大规模数据上运行,从而节省成本并提高性能。我们在上一篇文章 “GPUs for ETL? Run Faster, Less Costly Workloads with NVIDIA RAPIDS Accelerator for Apache Spark and Databricks” 中展示了这一点。在这篇文章中,我们深入了解了哪一个 Apache Spark SQL 操作对于给定的处理体系结构是加速的。
这篇文章是关于 GPU 和提取转换加载(ETL)操作的系列文章的一部分.
将 ETL 迁移到 GPU
是否应将所有 ETL 迁移到 GPU ?或者,评估哪种处理体系结构最适合特定的 Spark SQL 操作有好处吗?
CPU 针对顺序处理进行了优化,单个内核明显更少但速度更快。在内存管理、处理 I/O 操作、运行操作系统等方面都有明显的计算优势。
GPU 优化用于并行处理,它具有更多但速度较慢的核心。GPU 擅长绘制图形、训练、机器学习 和 深度学习模型、执行矩阵计算以及其他受益于并行化的操作。
实验设计
我们使用计算成本高昂的 ETL 操作,根据真实客户零售销售数据创建了三个大型、复杂的数据集:
- 聚合(SUM+GROUP BY)
- 交叉连接
- 活接头
每个数据集都经过专门策划,以测试特定 Spark SQL 操作的极限和值。所有三个数据集都是基于一家全球零售商的交易销售数据集建模的。选择行大小、列数和类型是为了平衡实验处理成本,同时进行测试,以证明和评估 CPU 和 GPU 架构在特定操作条件下的优势。数据概况见表 1。
| 活动 | 行 | #COLUMNS:结构化数据 | #COLUMNS:非结构化数据 | 大小(MB) |
| 聚合(SUM+GROUP BY) | 9440 万 | 2 | 0 | 3200 |
| 交叉连接 | 630 亿 | 6 | 1 | 983 |
| 活接头 | 4 亿 4700 万 | 10 | 2 | 721 |
表 1。实验数据集摘要
本实验评估了以下计算配置:
- 工作线程和驱动类型
- 工作线程最低和最高
- RAPIDS 或光子部署
- Databricks 单元(DBU)的最大小时限制——Databrickss 计算成本的专有衡量标准
| 工作线程和驱动类型 | 工作线程最小值/最大值 | RAPIDS 加速器/PHOTON | 最大 DBU/小时 |
| 标准_NC4 as_T4_v3 | 1/1 | RAPIDS 加速器 | 2 |
| 标准_NC4 as_T4_v3 | 2/8 | RAPIDS 加速器 | 9 |
| 标准_NC8as_T4_v3 | 2/2 | RAPIDS 加速器 | 4.5 |
| 标准_NC8as_T4_v3 | 2/8 | RAPIDS 加速器 | 14 |
| 标准_NC16as_T4_v3 | 2/2 | RAPIDS 加速器 | 7.5 |
| 标准_NC16as_T4_v3 | 2/8 | RAPIDS 加速器 | 23 |
| 标准_E16_v3 | 2/2 | Photon | 24 |
| 标准_E16_v3 | 2/8 | Photon | 72 |
表 2。实验计算配置
其他实验注意事项
除了构建具有行业代表性的测试数据集外,以下还列出了其他实验因素。
- 数据集是在现收现付实例上使用几种不同的工作线程和驱动程序配置运行的,而不是现场实例,因为它们固有的可用性建立了整个实验的定价一致性。
- 对于 GPU 测试,我们在 T4 GPU’上使用了 RAPIDS 加速器,该加速器针对分析重负载进行了优化,并且每个 DBU 的成本显著降低。
- CPU 工作程序类型是一种内存优化架构,使用 Intel Xeon Platinum 8370C(Ice Lake) CPU 。
- 我们还利用了 Databricks Photon,一个原生的 CPU 加速器解决方案,以及用 C++重写的传统 Java 运行时的加速版本。
选择这些参数是为了确保实验的可重复性和对常见用例的适用性。
后果
为了以一致的方式评估实验结果,我们开发了一个名为每分钟调整 DBU(ADBU)的复合指标。ADBU 以 DBU 为基础,计算如下:

实验结果表明,不存在一个芯片组( CPU 或 CPU )占主导地位的计算 Spark SQL 任务。如图 1 所示,数据集特征和集群配置的适用性对为特定任务选择哪个框架的影响最大。尽管不足为奇,但问题仍然存在:哪些 ETL 过程应该迁移到 GPU ?
UNION 操作
尽管 T4 上的 RAPIDS 加速器 Spark 使用 UNION 运算生成的结果具有较低的成本和执行时间,但与 CPU 相比,差异可以忽略不计。对于数据集和 CPU SQL 操作的这种组合,将现有的 ETL 管道从 CPU 移动到 GPU 似乎是没有必要的。尽管这项研究未经测试,但更大的数据集可能会产生值得转移到 GPU 的结果。
CROSS JOIN 操作
对于计算量大的 CROSS JOIN 操作,我们观察到通过在光子( GPU )上使用 RAPIDS 加速器( GPU )可以节省一个数量级的时间和成本。
对这些性能提高的一种可能解释是,CROSS JOIN 是一个笛卡尔乘积,它涉及非结构化数据列与自身的乘积。这导致复杂性呈指数级增长。 GPU 的性能增益非常适合这种类型的大规模并行操作。
成本差异的主要驱动因素是,我们实验的 CPU 集群的 DBU 评级远高于所选的 GPU 集群。
SUM+GROUP BY 运算
对于聚合操作(SUM+GROUP BY),我们观察到混合结果。光子( CPU )提供了显著更快的计算时间,而 RAPIDS 加速器( GPU )提供更低的总体成本。观察单个实验运行,我们观察到光子成本越高,DBU 就越高,而与 T4 相关的成本则明显更低。
这就解释了在这部分实验中使用 RAPIDS 加速器的总体成本较低的原因。总之,如果速度是目标,光子显然是赢家。更注重价格的用户可能更喜欢 RAPIDS 加速器更长的计算时间,以显著节省成本。
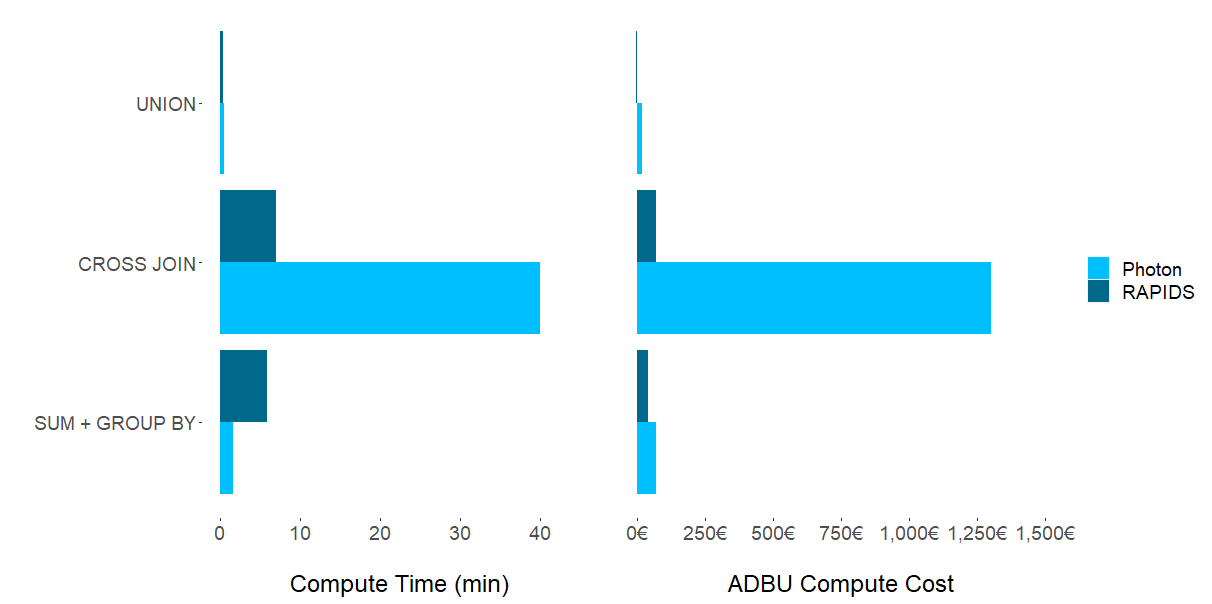
图 1。平均计算时间和平均成本的比较
决定使用哪个体系结构
在常用的聚合(SUM+GROUP BY)实验中, CPU 集群在执行时间方面获得了性能。然而,这是以更高的相关集群成本为代价的。对于 CROSS JOIN,一种不太常见的高计算和高度并行化操作, GPU 在更高的速度和更低的成本方面占据主导地位。UNION 在计算时间和成本方面的比较差异可以忽略不计。
GPU (以及关联的 RAPIDS 加速器)在很大程度上取决于数据结构、数据规模、执行的 ETL 操作和用户的技术深度。
GPU 用于 ETL
通常, GPU 非常适合大型复杂数据集和 Spark SQL 操作,这些操作具有高度并行性。实验结果表明,在 CROSS JOIN 情况下使用 GPU ,因为它们易于并行化,并且可以随着数据大小和复杂性的增长而轻松扩展。
需要注意的是,数据的规模并不如数据的复杂性和所选操作重要,如 SUM+GROUP BY 实验所示。(与 CROSS JOIN 相比,这个实验涉及更多的数据,但计算复杂度更低。)NVIDIA 免费提供预计的 GPU 加速收益估计,基于对 Spark 日志文件的分析。
CPU 用于 ETL
根据实验,某些 Spark SQL 操作(如 UNIONs)在成本和计算时间方面的差异可以忽略不计。在这种情况下,可能不需要转换到 GPU 。此外,对于聚合(SUM+GROUP BY),可以根据情景需求有意识地选择速度而非成本,其中 CPU 执行速度更快,但成本更高。
在内存中的计算很简单的情况下,使用已建立的 CPU ETL 架构可能是理想的。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)