十大经典排序算法
十大经典排序算法-面试必考
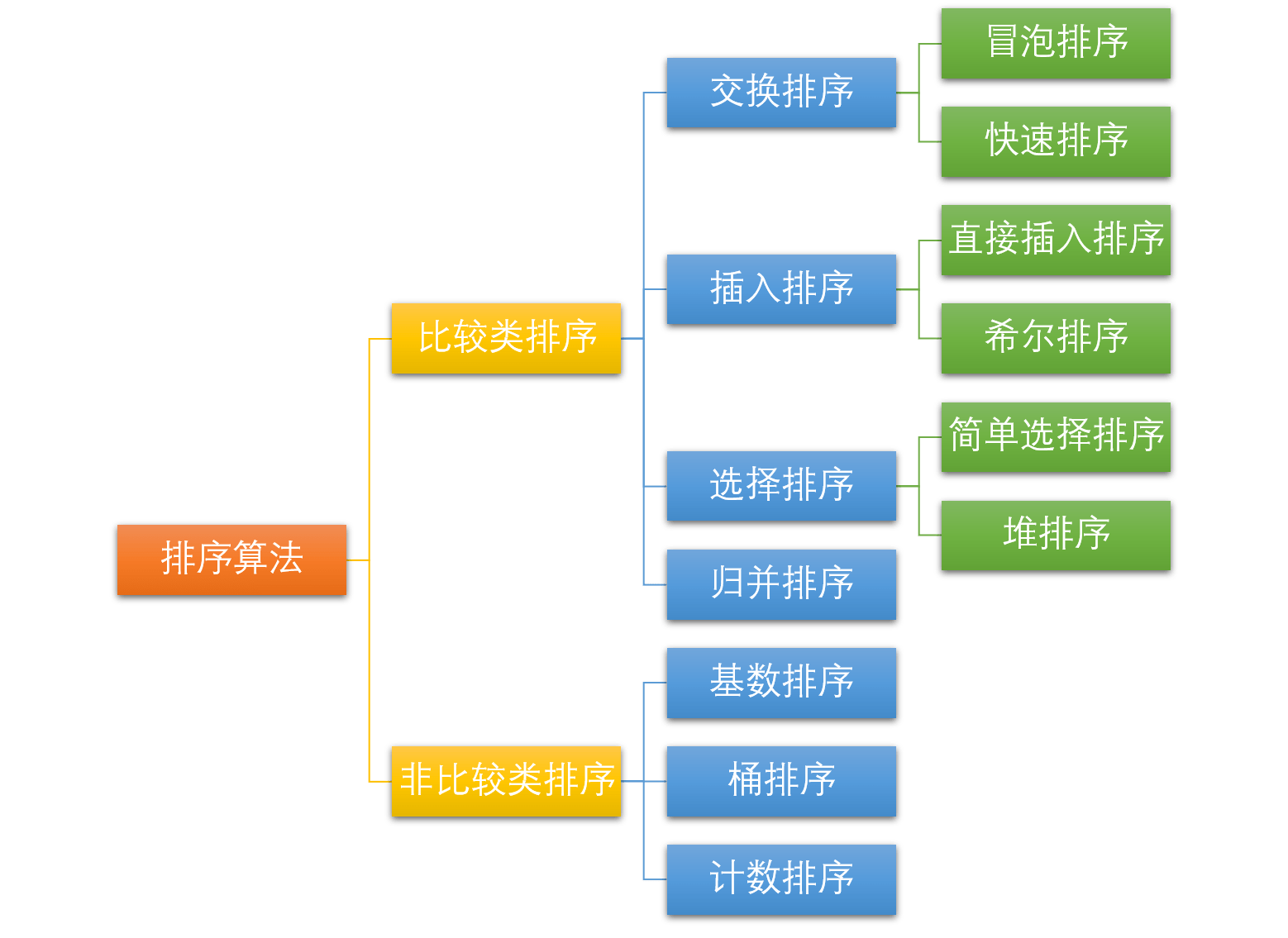
简介
常见排序算法包括:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序
| 排序算法 | 时间复杂度(平均) | 时间复杂度(最差) | 时间复杂度(最好) | 空间复杂度 | 排序方式 | 稳定性 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n^2) | O(n) | O(1) | 内部排序 | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 内部排序 | 不稳定 |
| 插入排序 | O(n^2) | O(n^2) | O(n) | O(1) | 内部排序 | 稳定 |
| 希尔排序 | O(nlogn) | O(n^2) | O(nlogn) | O(1) | 内部排序 | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 外部排序 | 稳定 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | 内部排序 | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 内部排序 | 不稳定 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 外部排序 | 稳定 |
| 桶排序 | O(n+k) | O(n^2) | O(n+k) | O(n+k) | 外部排序 | 稳定 |
| 基数排序 | O(n×k) | O(n×k) | O(n×k) | O(n+k) | 外部排序 | 稳定 |
- n:数据规模,表示待排序的数据量大小。
- k:“桶” 的个数,表示分割成的独立的排序区间或类别的数量(如基数排序、桶排序等)。
- 内部排序:所有排序操作都在内存中完成。适用于数据量小到足以完全加载到内存中的情况。
- 外部排序:当数据量过大,不可能全部加载到内存中时使用。外部排序通常涉及到数据的分区处理,部分数据被暂时存储在外部磁盘等存储设备上。
- 稳定:如果 A 原本在 B 前面,而 A = B A=B A=B,排序之后 A 仍然在 B 的前面。
- 不稳定:如果 A 原本在 B 的前面,而 A = B A=B A=B,排序之后 A 可能会出现在 B 的后面。
- 时间复杂度:定性描述一个算法执行所耗费的时间。
- 空间复杂度:定性描述一个算法执行所需内存的大小。
排序算法分类:
主要分为两类:比较类排序 和 非比较类排序
快速排序、归并排序、堆排序以及冒泡排序等都属于比较类排序算法。比较类排序是通过比较来决定元素间的相对次序,由于其时间复杂度不能突破 O(nlogn),因此也称为非线性时间比较类排序。在冒泡排序之类的排序中,问题规模为 n,又因为需要比较 n 次,所以平均时间复杂度为 O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为 logn 次,所以时间复杂度平均 O(nlogn)。
计数排序、基数排序、桶排序则属于非比较类排序算法。非比较排序不通过比较来决定元素间的相对次序,而是通过确定每个元素之前,应该有多少个元素来排序。由于它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。 非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度 O ( n ) O(n) O(n)。
非比较排序时间复杂度低,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
冒泡排序
思路:将大元素向后移动(升序:大泡下沉,小泡上浮;降序反之)
特点:升序排序中,每一轮比较会把最大的数下沉到最低,比较次数,每轮都会比前一轮少一次。
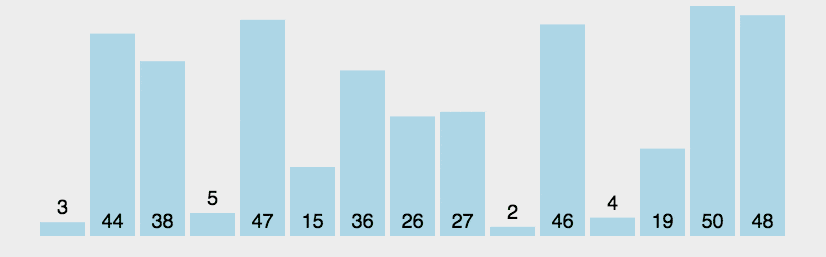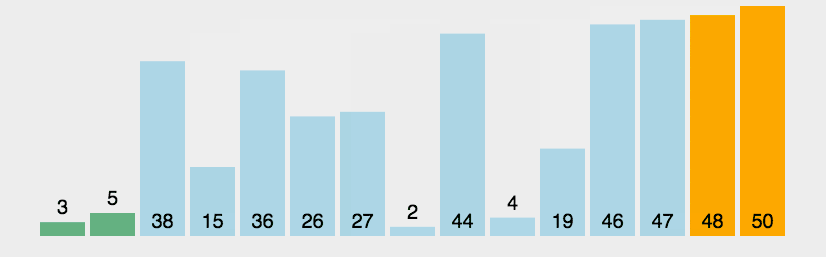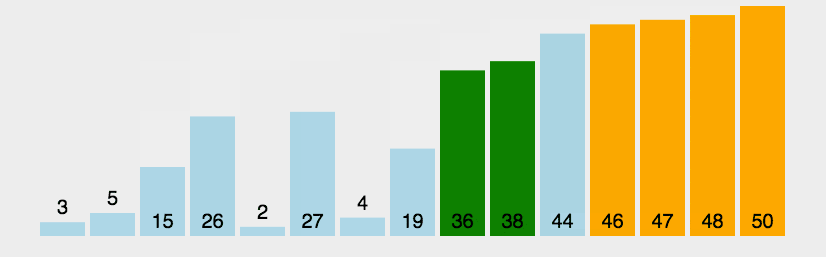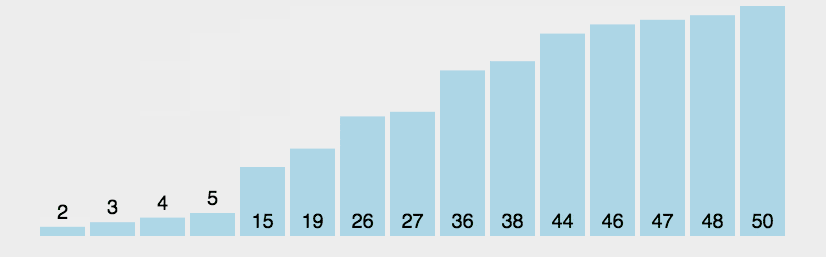
步骤:
-
如果前一个元素比后一个元素大,就交换它们两个(大泡在下);
-
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
-
针对所有的元素重复以上的步骤,除了最后一个;
-
重复步骤 1~3,直到排序完成。
/**
* 冒泡排序
*/
public static int[] bubbleSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
boolean flag = true;
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
}
}
if (flag) {
break;
}
}
return arr;
}
加入了 is_sorted Flag,目的是将算法的最佳时间复杂度优化为 O(n),即当原输入序列就是排序好的情况下,该算法的时间复杂度就是 O(n)。
算法分析
- 稳定性:稳定
- 时间复杂度:最佳: O ( n ) O(n) O(n) ,最差: O ( n 2 ) O(n^2) O(n2), 平均: O ( n 2 ) O(n^2) O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
选择排序
思路:通过索引判断最小元素位置(升序)
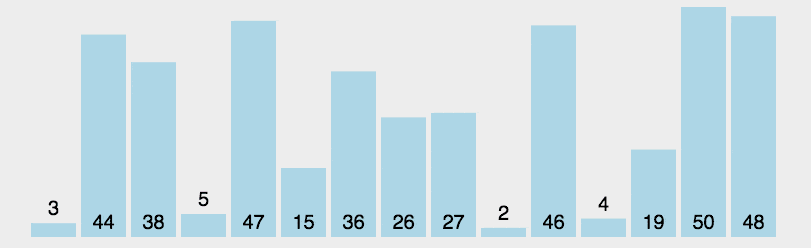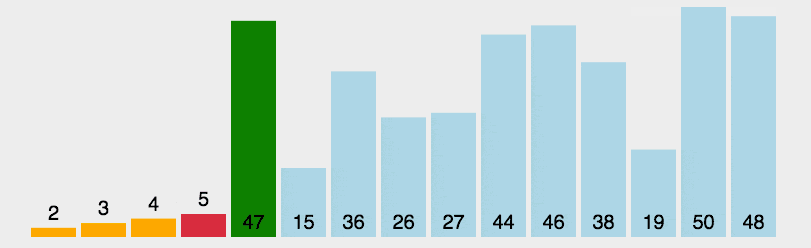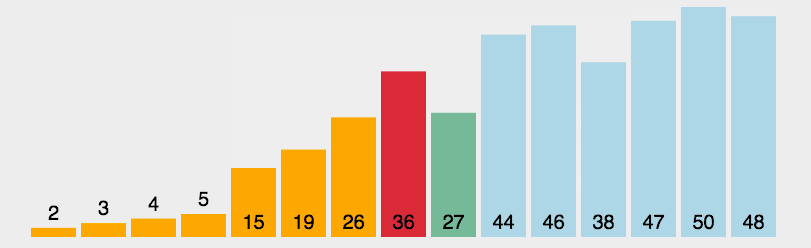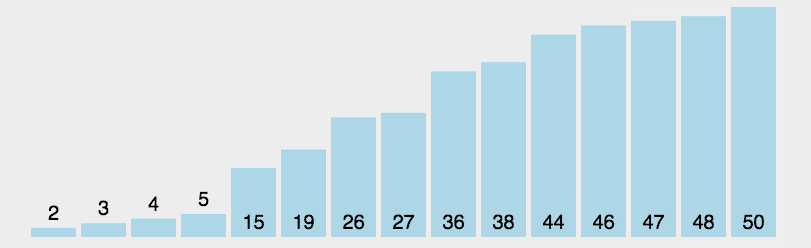
步骤:
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的后面。
- 重复第 2 步,直到所有元素均排序完毕。
/**
* 选择排序
*/
public static int[] selectionSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
if (minIndex != i) {
int tmp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = tmp;
}
}
return arr;
}
算法分析
- 稳定性:不稳定
- 时间复杂度:最佳: O ( n 2 ) O(n^2) O(n2) ,最差: O ( n 2 ) O(n^2) O(n2), 平均: O ( n 2 ) O(n^2) O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
插入排序
思路:对于未排序数据,在已排序序列中从后向前扫描,插入到相应位置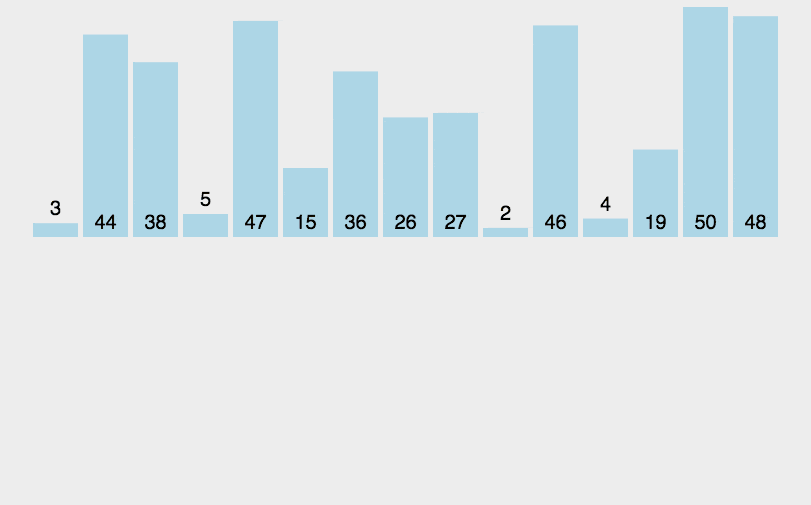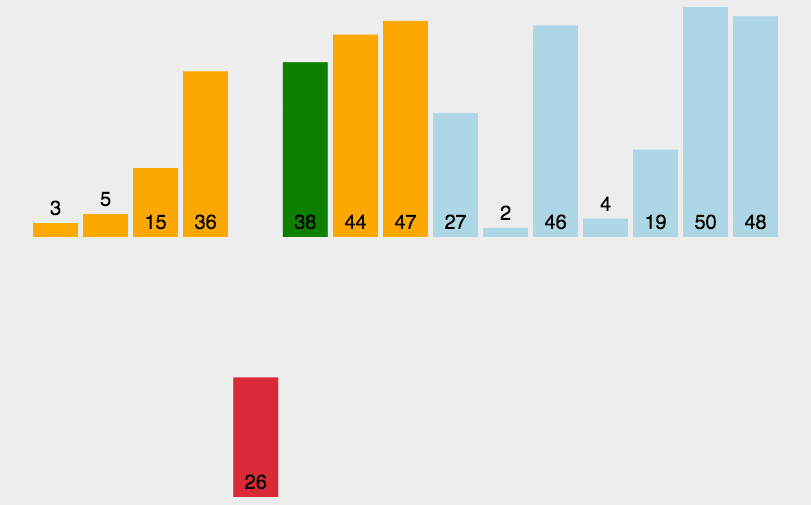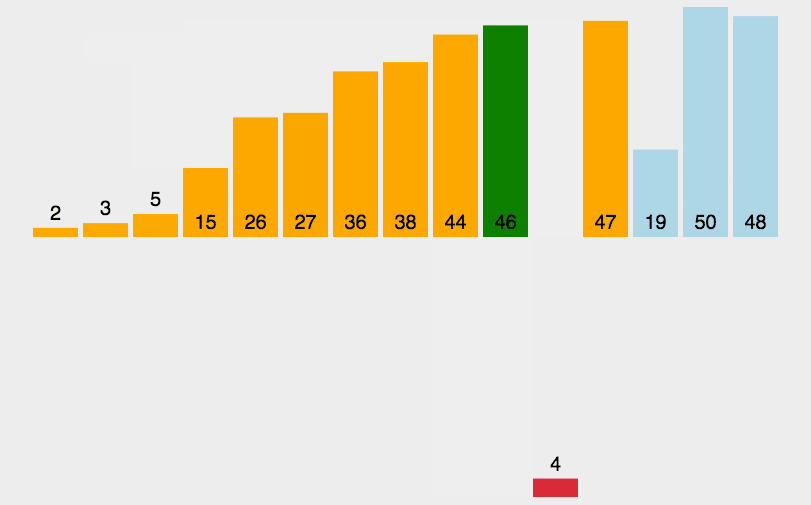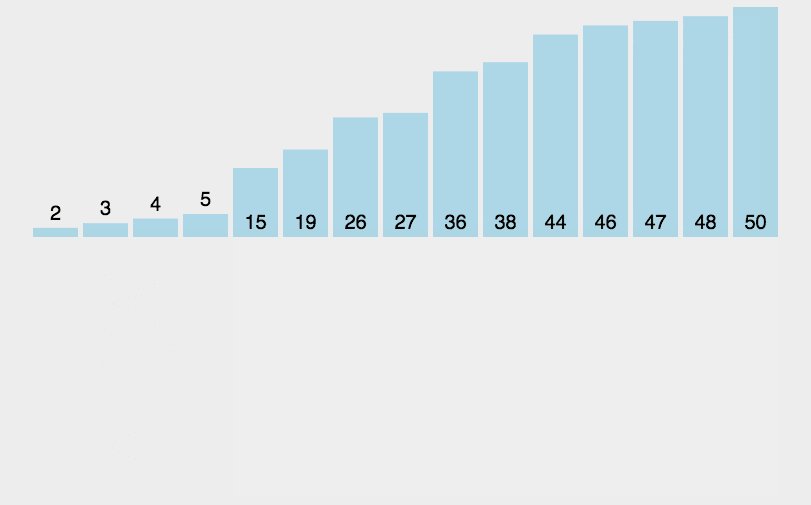
步骤:
-
从第一个元素开始,该元素可以认为已经被排序;
-
取出下一个元素,在已经排序的元素序列中从后向前扫描;
-
如果该元素(已排序)大于新元素,将该元素移到下一位置;
-
重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置;
-
将新元素插入到该位置后;
-
重复步骤 2~5。
/**
* 插入排序
*/
public static int[] insertionSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int preIndex = i - 1;
int current = arr[i];
while (preIndex >= 0 && current < arr[preIndex]) {
arr[preIndex + 1] = arr[preIndex];
preIndex -= 1;
}
arr[preIndex + 1] = current;
}
return arr;
}
算法分析:
- 稳定性:稳定
- 时间复杂度:最佳: O ( n ) O(n) O(n) ,最差: O ( n 2 ) O(n^2) O(n2), 平均: O ( n 2 ) O(n2) O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
希尔排序
思路:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 “基本有序” 时,再对全体记录进行依次直接插入排序。
/**
* 希尔排序
*/
public static int[] shellSort(int[] arr) {
int n = arr.length;
int gap = n / 2;
while (gap > 0) {
for (int i = gap; i < n; i++) {
int current = arr[i];
int preIndex = i - gap;
while (preIndex >= 0 && arr[preIndex] > current) {
arr[preIndex + gap] = arr[preIndex];
preIndex -= gap;
}
arr[preIndex + gap] = current;
}
gap /= 2;
}
return arr;
}
算法分析
- 稳定性:不稳定
- 时间复杂度:最佳: O ( n l o g n ) O(nlogn) O(nlogn), 最差: O ( n 2 ) O(n^2) O(n2) 平均: O ( n l o g n ) O(nlogn) O(nlogn)
- 空间复杂度: O ( 1 ) O(1) O(1)
归并排序
思路: 将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为 2 - 路归并。
步骤:
-
如果输入内只有一个元素,则直接返回,否则将长度为 n n n 的输入序列分成两个长度为 n / 2 n/2 n/2 的子序列;
-
分别对这两个子序列进行归并排序,使子序列变为有序状态;
-
设定两个指针,分别指向两个已经排序子序列的起始位置;
-
比较两个指针所指向的元素,选择相对小的元素放入到合并空间(用于存放排序结果),并移动指针到下一位置;
-
重复步骤 3 ~ 4 直到某一指针达到序列尾;
-
将另一序列剩下的所有元素直接复制到合并序列尾。
/**
* 归并排序
*/
public static int[] mergeSort(int[] arr) {
if (arr.length <= 1) {
return arr;
}
int middle = arr.length / 2;
int[] arr_1 = Arrays.copyOfRange(arr, 0, middle);
int[] arr_2 = Arrays.copyOfRange(arr, middle, arr.length);
return merge(mergeSort(arr_1), mergeSort(arr_2));
}
/**
* 合并
*/
public static int[] merge(int[] arr_1, int[] arr_2) {
int[] sorted_arr = new int[arr_1.length + arr_2.length];
int idx = 0, idx_1 = 0, idx_2 = 0;
while (idx_1 < arr_1.length && idx_2 < arr_2.length) {
if (arr_1[idx_1] < arr_2[idx_2]) {
sorted_arr[idx] = arr_1[idx_1];
idx_1 += 1;
} else {
sorted_arr[idx] = arr_2[idx_2];
idx_2 += 1;
}
idx += 1;
}
if (idx_1 < arr_1.length) {
while (idx_1 < arr_1.length) {
sorted_arr[idx] = arr_1[idx_1];
idx_1 += 1;
idx += 1;
}
} else {
while (idx_2 < arr_2.length) {
sorted_arr[idx] = arr_2[idx_2];
idx_2 += 1;
idx += 1;
}
}
return sorted_arr;
}
算法分析
- 稳定性:稳定
- 时间复杂度:最佳: O ( n l o g n ) O(nlogn) O(nlogn), 最差: O ( n l o g n ) O(nlogn) O(nlogn), 平均: O ( n l o g n ) O(nlogn) O(nlogn)
- 空间复杂度: O ( n ) O(n) O(n)
快速排序
思路:通过一趟排序将待排序列分隔成独立的两部分,其中一部分记录的元素均比另一部分的元素小,则可分别对这两部分子序列继续进行排序,以达到整个序列有序。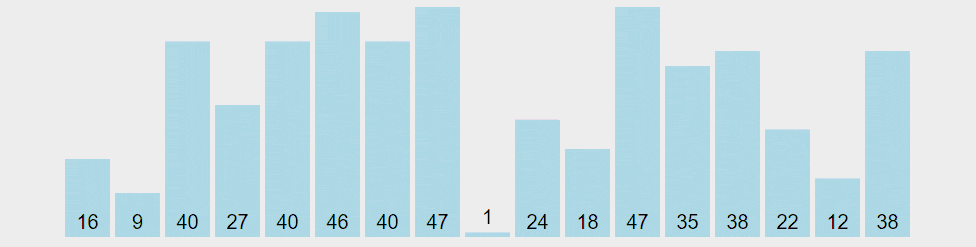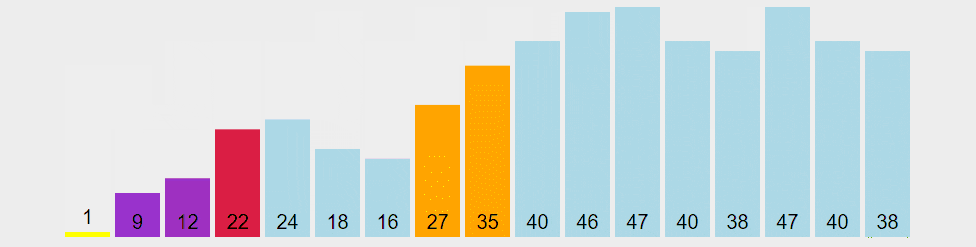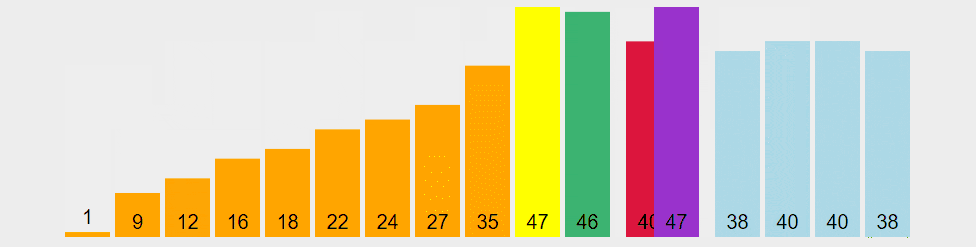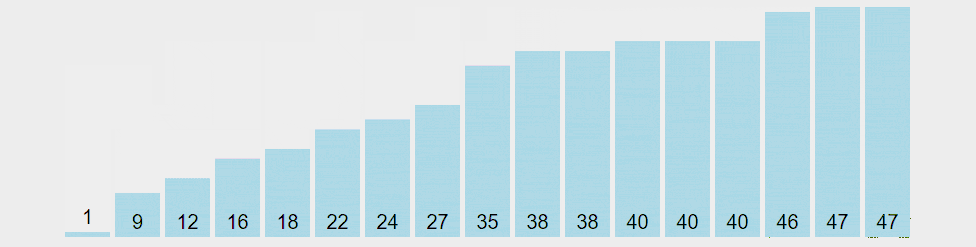
步骤:
- 从序列中随机挑出一个元素,做为 “基准”(
pivot); - 重新排列序列,将所有比基准值小的元素摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个操作结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地把小于基准值元素的子序列和大于基准值元素的子序列进行快速排序。
public static int partition(int[] array, int low, int high) {
int pivot = array[high];
int pointer = low;
for (int i = low; i < high; i++) {
if (array[i] <= pivot) {
int temp = array[i];
array[i] = array[pointer];
array[pointer] = temp;
pointer++;
}
System.out.println(Arrays.toString(array));
}
int temp = array[pointer];
array[pointer] = array[high];
array[high] = temp;
return pointer;
}
public static void quickSort(int[] array, int low, int high) {
if (low < high) {
int position = partition(array, low, high);
quickSort(array, low, position - 1);
quickSort(array, position + 1, high);
}
}
算法分析
- 稳定性:不稳定
- 时间复杂度:最佳: O ( n l o g n ) O(nlogn) O(nlogn), 最差: O ( n 2 ) O(n^2) O(n2),平均: O ( n l o g n ) O(nlogn) O(nlogn)
- 空间复杂度: O ( l o g n ) O(logn) O(logn)
堆排序
思路:堆是一个近似完全二叉树的结构,并同时满足堆的性质:即子结点的值总是小于(或者大于)它的父节点。
步骤:
- 将初始待排序列 ( R 1 , R 2 , … , R n ) (R_1, R_2, \dots, R_n) (R1,R2,…,Rn) 构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素 R 1 R_1 R1 与最后一个元素 R n R_n Rn 交换,此时得到新的无序区 ( R 1 , R 2 , … , R n − 1 ) (R_1, R_2, \dots, R_{n-1}) (R1,R2,…,Rn−1) 和新的有序区 R n R_n Rn, 且满足 R i ⩽ R n ( i ∈ 1 , 2 , … , n − 1 ) R_i \leqslant R_n (i \in 1, 2,\dots, n-1) Ri⩽Rn(i∈1,2,…,n−1);
- 由于交换后新的堆顶 R 1 R_1 R1 可能违反堆的性质,因此需要对当前无序区 ( R 1 , R 2 , … , R n − 1 ) (R_1, R_2, \dots, R_{n-1}) (R1,R2,…,Rn−1) 调整为新堆,然后再次将 R 1 R_1 R1 与无序区最后一个元素交换,得到新的无序区 ( R 1 , R 2 , … , R n − 2 ) (R_1, R_2, \dots, R_{n-2}) (R1,R2,…,Rn−2) 和新的有序区 ( R n − 1 , R n ) (R_{n-1}, R_n) (Rn−1,Rn)。不断重复此过程直到有序区的元素个数为 n − 1 n-1 n−1,则整个排序过程完成。
// Global variable that records the length of an array;
static int heapLen;
/**
* Swap the two elements of an array
*/
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
/**
* Build Max Heap
*/
private static void buildMaxHeap(int[] arr) {
for (int i = arr.length / 2 - 1; i >= 0; i--) {
heapify(arr, i);
}
}
/**
* Adjust it to the maximum heap
*/
private static void heapify(int[] arr, int i) {
int left = 2 * i + 1;
int right = 2 * i + 2;
int largest = i;
if (right < heapLen && arr[right] > arr[largest]) {
largest = right;
}
if (left < heapLen && arr[left] > arr[largest]) {
largest = left;
}
if (largest != i) {
swap(arr, largest, i);
heapify(arr, largest);
}
}
/**
* Heap Sort
*/
public static int[] heapSort(int[] arr) {
// index at the end of the heap
heapLen = arr.length;
// build MaxHeap
buildMaxHeap(arr);
for (int i = arr.length - 1; i > 0; i--) {
// Move the top of the heap to the tail of the heap in turn
swap(arr, 0, i);
heapLen -= 1;
heapify(arr, 0);
}
return arr;
}
算法分析
- 稳定性:不稳定
- 时间复杂度:最佳: O ( n l o g n ) O(nlogn) O(nlogn), 最差: O ( n l o g n ) O(nlogn) O(nlogn), 平均: O ( n l o g n ) O(nlogn) O(nlogn)
- 空间复杂度: O ( 1 ) O(1) O(1)
计数排序
思路:将输入的数据值转化为键存储在额外开辟的数组空间。
注意:计数排序要求输入的数据必须是有确定范围的整数。
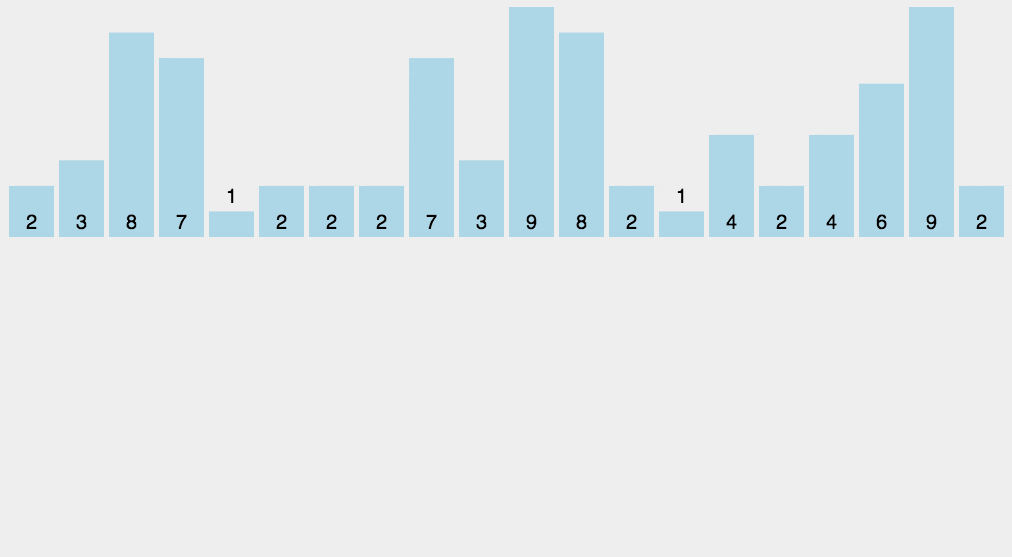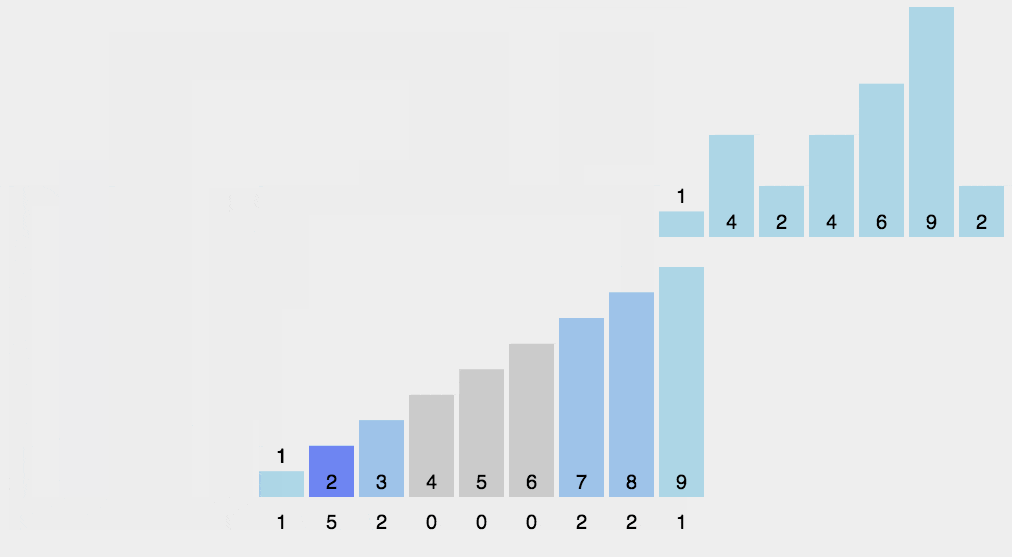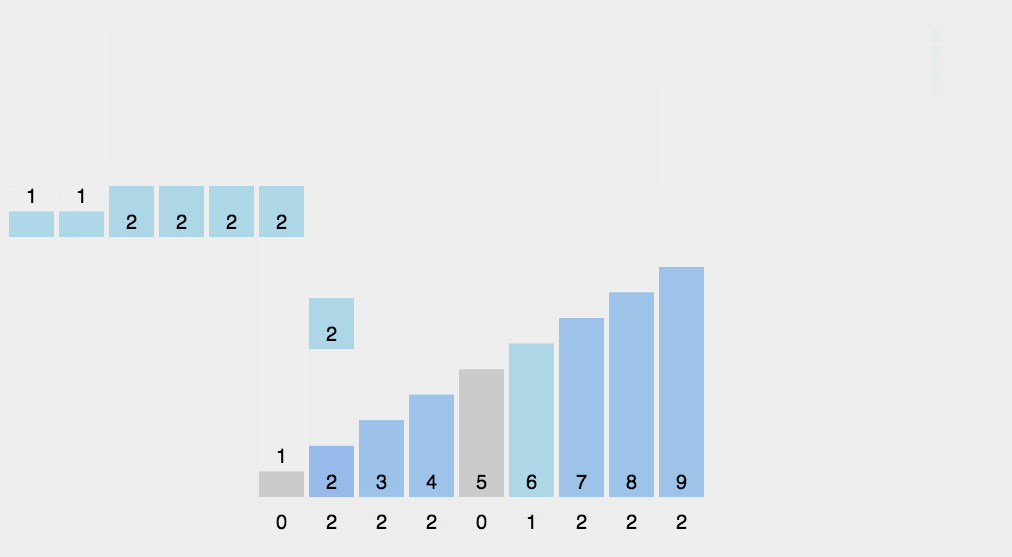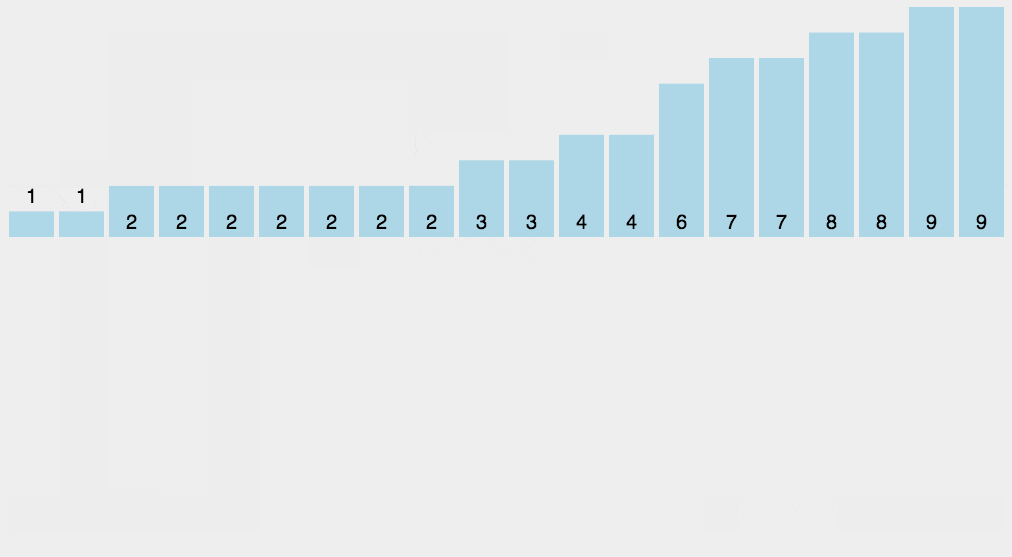
步骤:
-
找出数组中的最大值
max、最小值min; -
创建一个新数组
C,其长度是max-min+1,其元素默认值都为 0; -
遍历原数组
A中的元素A[i],以A[i] - min作为C数组的索引,以A[i]的值在A中元素出现次数作为C[A[i] - min]的值; -
对
C数组变形,新元素的值是该元素与前一个元素值的和,即当i>1时C[i] = C[i] + C[i-1]; -
创建结果数组
R,长度和原始数组一样。 -
从后向前遍历原始数组
A中的元素A[i],使用A[i]减去最小值min作为索引,在计数数组C中找到对应的值C[A[i] - min],C[A[i] - min] - 1就是A[i]在结果数组R中的位置,做完上述这些操作,将count[A[i] - min]减小 1。
/**
* Gets the maximum and minimum values in the array
*/
private static int[] getMinAndMax(int[] arr) {
int maxValue = arr[0];
int minValue = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > maxValue) {
maxValue = arr[i];
} else if (arr[i] < minValue) {
minValue = arr[i];
}
}
return new int[] { minValue, maxValue };
}
/**
* Counting Sort
*/
public static int[] countingSort(int[] arr) {
if (arr.length < 2) {
return arr;
}
int[] extremum = getMinAndMax(arr);
int minValue = extremum[0];
int maxValue = extremum[1];
int[] countArr = new int[maxValue - minValue + 1];
int[] result = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
countArr[arr[i] - minValue] += 1;
}
for (int i = 1; i < countArr.length; i++) {
countArr[i] += countArr[i - 1];
}
for (int i = arr.length - 1; i >= 0; i--) {
int idx = countArr[arr[i] - minValue] - 1;
result[idx] = arr[i];
countArr[arr[i] - minValue] -= 1;
}
return result;
}
算法分析
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 O ( n + k ) O(n+k) O(n+k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组 C 的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上 1),这使得计数排序对于数据范围很大的数组,需要大量额外内存空间。
- 稳定性:稳定
- 时间复杂度:最佳: O ( n + k ) O(n+k) O(n+k) 最差: O ( n + k ) O(n+k) O(n+k) 平均: O ( n + k ) O(n+k) O(n+k)
- 空间复杂度: O ( k ) O(k) O(k)
桶排序
思路:先按照桶内区间放置元素,再把桶内元素按照桶的区间排序依次取出。
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
桶排序的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行)。
步骤:
- 设置一个 BucketSize,作为每个桶所能放置多少个不同数值;
- 遍历输入数据,并且把数据依次映射到对应的桶里去;
- 对每个非空的桶进行排序,可以使用其它排序方法,也可以递归使用桶排序;
- 从非空桶里把排好序的数据拼接起来。
/**
* Gets the maximum and minimum values in the array
*/
private static int[] getMinAndMax(List<Integer> arr) {
int maxValue = arr.get(0);
int minValue = arr.get(0);
for (int i : arr) {
if (i > maxValue) {
maxValue = i;
} else if (i < minValue) {
minValue = i;
}
}
return new int[] { minValue, maxValue };
}
/**
* Bucket Sort
*/
public static List<Integer> bucketSort(List<Integer> arr, int bucket_size) {
if (arr.size() < 2 || bucket_size == 0) {
return arr;
}
int[] extremum = getMinAndMax(arr);
int minValue = extremum[0];
int maxValue = extremum[1];
int bucket_cnt = (maxValue - minValue) / bucket_size + 1;
List<List<Integer>> buckets = new ArrayList<>();
for (int i = 0; i < bucket_cnt; i++) {
buckets.add(new ArrayList<Integer>());
}
for (int element : arr) {
int idx = (element - minValue) / bucket_size;
buckets.get(idx).add(element);
}
for (int i = 0; i < buckets.size(); i++) {
if (buckets.get(i).size() > 1) {
buckets.set(i, sort(buckets.get(i), bucket_size / 2));
}
}
ArrayList<Integer> result = new ArrayList<>();
for (List<Integer> bucket : buckets) {
for (int element : bucket) {
result.add(element);
}
}
return result;
}
算法分析
- 稳定性:稳定
- 时间复杂度:最佳: O ( n + k ) O(n+k) O(n+k) 最差: O ( n 2 ) O(n^2) O(n2) 平均: O ( n + k ) O(n+k) O(n+k)
- 空间复杂度: O ( n + k ) O(n+k) O(n+k)
基数排序
思路:(逐位排序)对元素中的每一位数字进行排序,从最低位开始排序,复杂度为 O ( n × k ) O(n×k) O(n×k), n n n 为数组长度, k k k 为数组中元素的最大的位数;
按照低位先排序收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。推荐-基数排序(理解思路)
步骤:
-
取得数组中的最大数,并取得位数,即为迭代次数 N N N(例如:数组中最大数值为 1000,则 N = 4 N=4 N=4);
-
A为原始数组,从最低位开始取每个位组成radix数组; -
对
radix进行计数排序(利用计数排序适用于小范围数的特点); -
将
radix依次赋值给原数组; -
重复 2~4 步骤 N N N 次
/**
* Radix Sort
*/
public static int[] radixSort(int[] arr) {
if (arr.length < 2) {
return arr;
}
int N = 1;
int maxValue = arr[0];
for (int element : arr) {
if (element > maxValue) {
maxValue = element;
}
}
while (maxValue / 10 != 0) {
maxValue = maxValue / 10;
N += 1;
}
for (int i = 0; i < N; i++) {
List<List<Integer>> radix = new ArrayList<>();
for (int k = 0; k < 10; k++) {
radix.add(new ArrayList<Integer>());
}
for (int element : arr) {
int idx = (element / (int) Math.pow(10, i)) % 10;
radix.get(idx).add(element);
}
int idx = 0;
for (List<Integer> l : radix) {
for (int n : l) {
arr[idx++] = n;
}
}
}
return arr;
}
算法分析
- 稳定性:稳定
- 时间复杂度:最佳: O ( n × k ) O(n×k) O(n×k) 最差: O ( n × k ) O(n×k) O(n×k) 平均: O ( n × k ) O(n×k) O(n×k)
- 空间复杂度: O ( n + k ) O(n+k) O(n+k)
基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 64
64 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)