LLM后训练绝招:1%预训练成本,实现最高20倍算力扩展效果
根据规模定律,扩大训练计算规模可以提高大型语言模型(LLM)性能的关键,但调研机构Epoch AI的研究,LLM再训练无需高额费用,也能让AI能力获得显著提升。在该研究中,他们引入了一个基本框架,用于量化后训练增强的收益和成本,特别是通过计算等效增益来衡量收益。他们将该框架应用于一系列具有代表性的后训练增强,并发现性能提升非常显著,但微调成本通常与预训练成本相比非常小,某些后训练增强技术可以在不到

根据规模定律,扩大训练计算规模可以提高大型语言模型(LLM)性能的关键,但调研机构Epoch AI的研究,LLM再训练无需高额费用,也能让AI能力获得显著提升。
在该研究中,他们引入了一个基本框架,用于量化后训练增强的收益和成本,特别是通过计算等效增益来衡量收益。他们将该框架应用于一系列具有代表性的后训练增强,并发现性能提升非常显著,但微调成本通常与预训练成本相比非常小,某些后训练增强技术可以在不到1%预训练成本的情况下,提供相当于增加5到20倍预训练计算资源获得的效果。
(本文由OneFlow编译发布,转载请联系授权。原文:https://epochai.org/blog/ai-capabilities-can-be-significantly-improved-without-expensive-retraining)
作者 | EPOCH AI
OneFlow编译
翻译|刘乾裕
题图由SiliconCloud平台生成
近年来,训练大语言模型和类似基础模型所需的高强度计算资源,已成为推动人工智能进步的主驱动力之一。这也让人们深刻认识到一个“惨痛教训”:更好利用计算资源的通用方法最终被证明是最有效的。如今,训练最前沿模型的成本已经高到只有少数参与者能够承担(https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems)。
我们的研究探讨了在训练完成后提升模型性能的方法,这些方法无需依赖大量计算资源。我们将这些改进措施分为五类,详见下表。
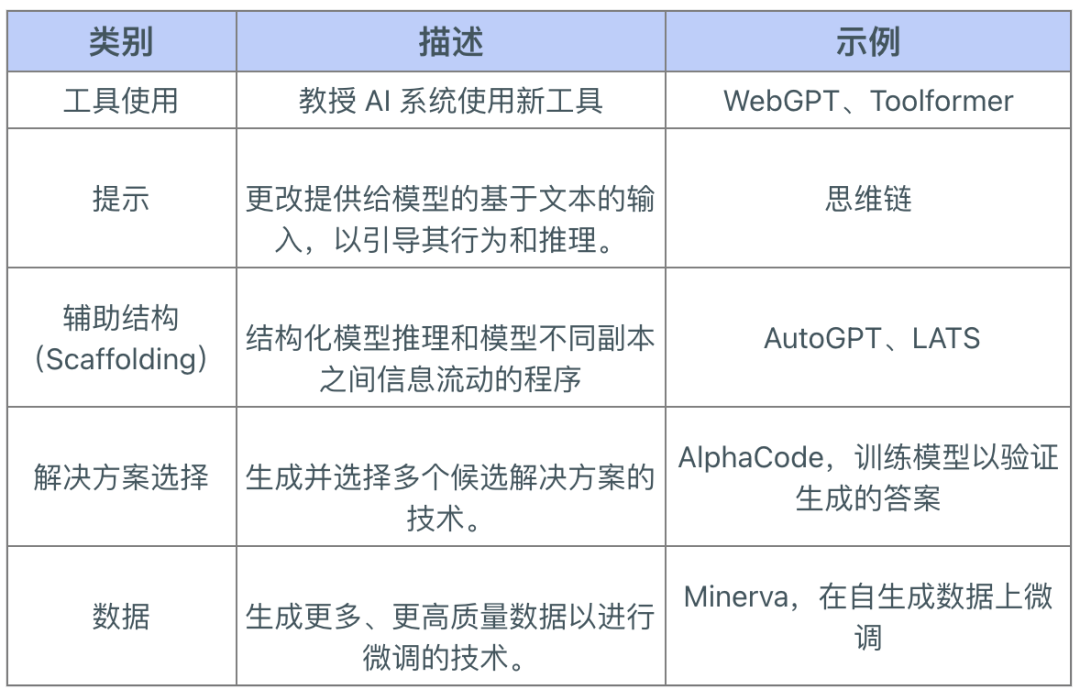
后训练增强的类别及示例
你可以在此处阅读完整论文(https://arxiv.org/abs/2312.07413)。本文由Epoch AI、Open Philanthropy、加州大学伯克利分校和ORCG合作完成。
1
关键成果
计算等效增益 (CEG):我们提出了计算等效增益这一概念,用于量化各类增强方法带来的性能提升。CEG被定义为在不采用增强的情况下,预训练计算量需要增加多少才能达到与增强方法相同的基准性能提升。我们开发了一种基于公开基准进行评估的估算方法,以此来计算CEG。
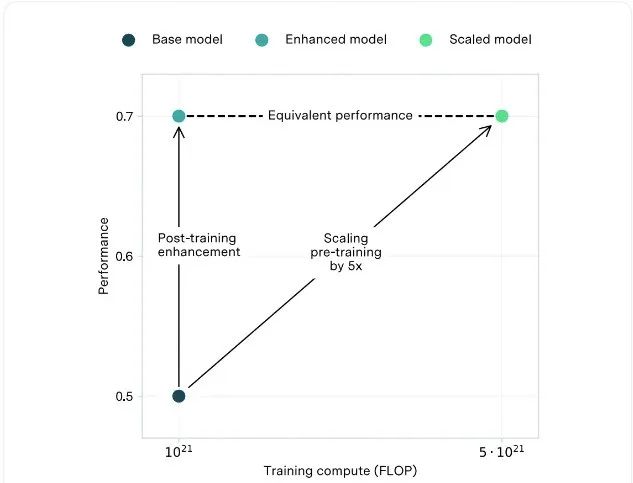
该示例中,CEG(计算等效增益)是5倍。同样的性能提升可以通过应用后训练增强(PTE)或将预训练计算规模扩大5倍来实现。
后训练增强效果调查(PTE):我们对PTE进行了研究,涵盖了五个方面即工具、提示、辅助结构(scaffolding)、解决方案选择和数据增强。他们的CEG估算值通常在相关基准数值的5到30倍之间。
我们还对这些PTE的计算成本进行了估算,主要包括两类:一是使模型能够应用PTE所需的初始成本(例如,微调模型以学习使用某种工具);二是推理过程中产生的持续成本(例如,增强方法需要生成多个样本并从中选取最佳结果)。对于我们评估的所有PTE,其初始成本通常低于预训练成本的10%,大部分甚至不到0.1%。尽管大多数情况下推理成本不会受到明显影响,但在个别情况下推理成本可能会增加至100倍左右。
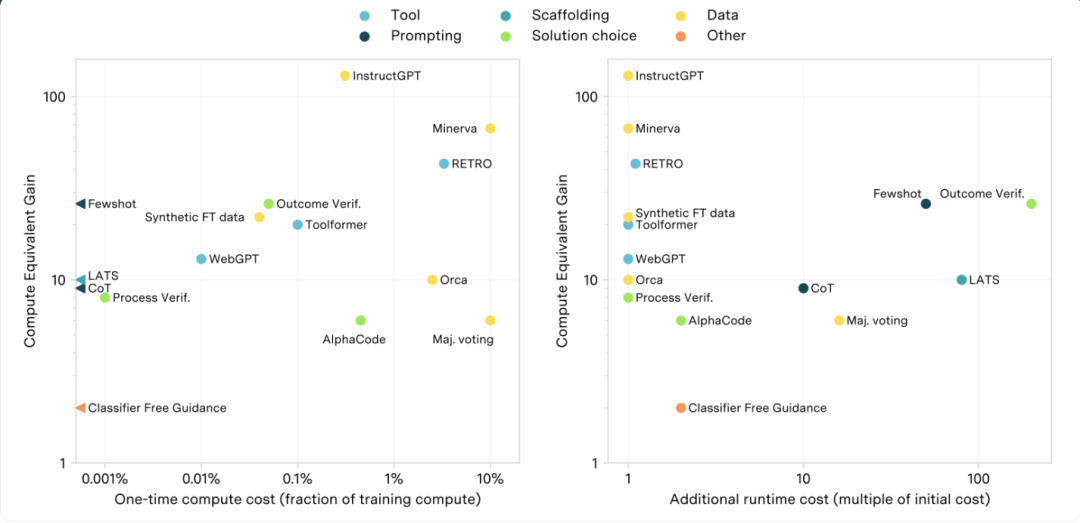
结果概要:使用计算等效增益量化的技术所产生的改进。x轴展示了相关的一次性成本(左)和推理成本(右)。
2
政策影响
随着后训练增强技术的不断发展和完善,已部署的大语言模型功能将会随着时间推移而增强。这一发现表明,安全策略(例如,负责任扩展策略,metr.org/blog/2023-09-26-rsp)应当包含一个“安全缓冲区”:限制那些在未来随着后训练增强,可能达到危险水平的模型功能。
由于这些增强功能的计算成本较低,更多参与者能够加入开发,不再局限于那些具备大规模预训练能力的主体。这使得能力提升趋向民主化,但也为AI发展的监管带来新挑战,因为仅关注那些拥有大量计算资源的实体已不足以有效应对未来的风险。
其他人都在看
让超级产品开发者实现“Token自由”
邀请好友体验SiliconCloud,狂送2000万Token/人
邀请越多,Token奖励越多
siliconflow.cn/zh-cn/siliconcloud

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 23
23 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)