YOLOv11小白的进击之路(二)从YOLO类-DetectionModel类出发看YOLO代码运行逻辑...
按照YOLOv11的运行顺序,从YOLO类到DetectionModel类到DetectionTrainer类依次深挖YOLOv11的运行逻辑。
这里以目标检测为例,让我们来看看YOLOv11这个大家伙是怎么跑起来的:
在我们自己写的train.py中,会指定模型配置文件的路径,例如
model = YOLO(model='ultralytics/cfg/models/11/my.yaml')以及,通过关键词参数定制训练过程,例如
model.train(data='./data.yaml',epochs=3,batch=-1,imgsz=640) 那一个是YOLO类,另一个是model.train函数,可以作为我们探寻YOLO运行逻辑的两个起点。
YOLO类
话分两头,先来看YOLO类,我们按住Ctrl键+鼠标左键可以跳转到YOLO类,发现其位置在于/ultralytics-main/ultralytics/models/yolo/model.py,可以看到与之并列的是六个文件夹,分别代表不同的任务类型,即分类(Classify)、检测(Detect)、定向边界框(OBB)、姿态估计(Pose)、分割(Segment)和综合框架(World)。
继续追踪,看到YOLO类实际上继承于Model类,跳转后发现其位于/ultralytics-main/ultralytics/engine/model.py处,同在一个文件夹engine的几个.py文件里都是非常基础的类,以这个model.py为例,其Docstring介绍道,
A base class for implementing YOLO models, unifying APIs across different model types.表明这是一个实现YOLO模型的基类,统一了不同模型类型的API
回到YOLO类,具体来看,其内容比较简单,只有_init_方法(初始化 YOLO 模型,如果模型文件名包含 '-world' 则切换到 YOLOWorld)和task_map属性(返回一个字典,映射不同任务的类),以目标检测为例,也就是下图中的“detect”:
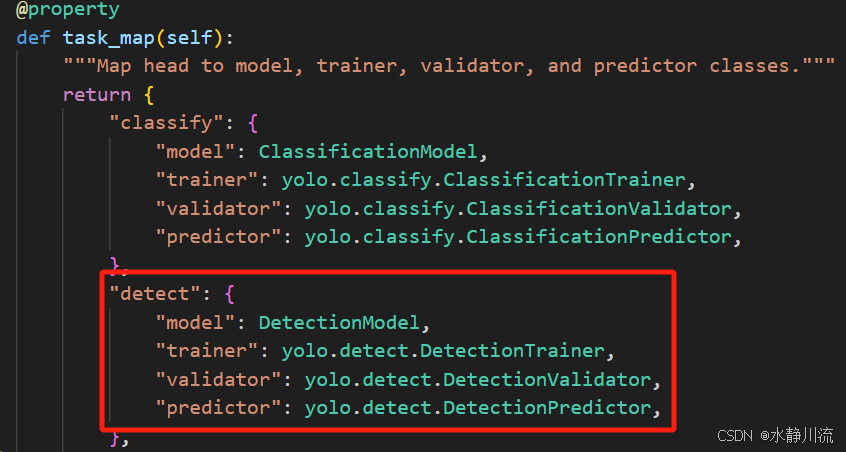
我们继续追踪,分别研究"model": DetectionModel,以及"trainer": yolo.detect.DetectionTrainer
task.py中的DetectionModel类
先来看DetectionModel,跳转后看到其位于/ultralytics-main/ultralytics/nn/tasks.py,与之并列的文件夹是modules(里面包含了YOLO运行时需要的各个模块,例如卷积模块conv.py、检测头head.py等)。
聚焦于此处的tasks.py,其内有不同任务的Model类和一些功能函数,与目标检测相关的是DetectionModel(继承于BaseModel基础类),其内部共有五个函数,我们一一来看
__init__ 方法
主要用于模型初始化,直接看关键代码
加载配置文件
self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict- 输入:
cfg(路径或字典)。 - 输出:
self.yaml(模型配置字典)。 - 作用: 判断
cfg是否是字典。如果是,则直接赋值;否则,调用yaml_model_load(cfg)读取配置文件并将其解析为字典。
定义模型
获取通道数channels:
ch = self.yaml["ch"] = self.yaml.get("ch", ch) # input channels检查并覆盖类别数量(这里就是我们按照自己需求初始化nc的地方,可以覆盖从配置文件中加载的类别数量) :
if nc and nc != self.yaml["nc"]:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml["nc"] = nc # override YAML value解析配置以构建模型
self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist- 输入: 复制的
self.yaml(确保不修改原数据),输入通道数ch,以及verbose。 - 输出:
self.model: 构建的YOLO模型。self.save: 用于保存模型中某些层的输出列表。
- 作用: 调用
parse_model函数(非常重要的函数,这个函数也位于此task.py文件中,主要作用是将 YOLO model.yaml 字典解析为 PyTorch 模型,这个我们有时间再来探讨)解析模型配置并构建YOLO模型架构,输出模型和保存的层列表。
设置基本属性
self.names = {i: f"{i}" for i in range(self.yaml["nc"])} # default names dict
self.inplace = self.yaml.get("inplace", True)
self.end2end = getattr(self.model[-1], "end2end", False)主要就是初始化了一个默认的类别名称字典names,判断模型是否在计算时试图节省内存(省事的inplace),以及判断模型是否是端到端训练(确定训练模式)。
初始化检测层
主要作用是初始化YOLO模型的最后检测层,设置步幅并准备模型进行前向传播。
m = self.model[-1] # Detect(),获取模型的最后一层(检测层),self.model是一个包含多个层的列表
if isinstance(m, Detect): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
s = 256 # 2x min stride
m.inplace = self.inplace
def _forward(x):
"""Performs a forward pass through the model, handling different Detect subclass types accordingly."""
if self.end2end:
return self.forward(x)["one2many"]
return self.forward(x)[0] if isinstance(m, (Segment, Pose, OBB)) else self.forward(x)
m.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))])
# forward
self.stride = m.stride
m.bias_init() # 初始化检测层的偏置项 only run once
else:
self.stride = torch.Tensor([32]) # default stride for i.e. RTDETR我们重点关注s = 256以及stride的计算。对于变量s注释这里的“2x min stride”,我的理解是某一最小步幅的2倍,主要用于计算步幅stride。
把m.stride单独拿出来看:
# 调用_forward函数来计算每个特征图的步幅(stride)
m.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))]) # forward主要步骤:
- 创建零填充的张量:
torch.zeros(1, ch, s, s)创建一个形状为(1, ch, 256, 256)的零张量,表示一次性输入的批次(batch)大小为 1,输入通道数为ch,图像的高度和宽度为 256。 - 前向传播:这里的
for循环遍历_forward返回的特征图。_forward(...)函数执行前向传播,计算并返回模型输出。这里我们是端到端,因此返回的是self.forward(x)["one2many"],也就是包含检测信息(边界框坐标、置信度和类别概率等)的一个张量。 - 步幅计算:
x.shape[-2]获取每个输出特征图的高度height。将256除以各个特征图的高度得到步幅,即s / x.shape[-2]。例如,如果一个特征图的高度(x.shape[-2])是64,则步幅为256 / 64 = 4,表示每次跳过4个像素生成一个特征图输出。 - 最终结果:生成的
m.stride张量,包含了所有特征图的步幅信息。torch.tensor的主要作用是将 Python 列表转换为 PyTorch 的张量(tensor),为什么要转换成张量呢?一方面使用张量可以利用 GPU 加速,另一方面,在深度学习框架中很多操作(如模型训练、推理等)都期望输入的是张量格式。
_predict_augment方法
主要作用是通过多尺度和翻转处理来增强输入图像,并返回增强后的推断和训练输出。
检查模型支持类型
if getattr(self, "end2end", False) or self.__class__.__name__ != "DetectionModel":
LOGGER.warning("WARNING ⚠️ Model does not support 'augment=True', reverting to single-scale prediction.")
return self._predict_once(x)- 这里首先检查类的
end2end属性,getattr(self, "end2end", False):尝试从当前对象self获取end2end属性:如果end2end存在并为True,那么这个函数返回True;如果不存在,则返回False。我们看到,这段代码中的逻辑是,如果end2end存在并且为True,模型会显示警告“不支持数据增强”。 - 再检查类名是否为
DetectionModel(确认这是一个检测模型)。 - 如果模型不支持增强,发出警告并直接调用
_predict_once(x)函数进行单一尺度的预测。
为什么如果模型被标记为“端到端”,代码逻辑选择不使用数据增强呢?
主要是因为端到端”(end-to-end)训练通常指的是将整个系统作为一个整体进行训练,而不对中间结果进行单独的优化。在这种情况下,模型的输入和输出通常是一一对应的,整个过程被视为一个黑箱,优化是通过调整整个网络的参数来进行的。
在端到端训练时,如果启用数据增强可能会干扰网络训练的目标,可能改变输入数据的原始特性或与目标标签的不一致性(例如,如果进行过度的数据增强,某些特征可能会被“扭曲”或“遮挡”,导致模型无法准确学习输入与输出之间的关系)。
重要参数初始化
img_size = x.shape[-2:] # 获取输入图像的尺寸(高度和宽度)
s = [1, 0.83, 0.67] # 定义了不同的缩放比例
f = [None, 3, None] # 定义翻转选项,None表示不翻转
# 3表示从左到右翻转(水平翻转),2表示从上到下翻转(垂直翻转)
y = [] # outputs 初始化输出列表,用来存储每次增强后的输出结果进行重新缩放和预测
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = super().predict(xi)[0] # forward
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)- 利用
zip(s, f)循环同时访问scales和flips的值。x.flip(fi) if fi else x:如果fi不为None,则翻转输入图像,反之则直接使用原图。scale_img(...):对图像进行缩放(使用当前的尺度si),gs用来指定一些参数。super().predict(xi)[0]:调用超类的方法进行预测,返回预测结果。self._descale_pred(yi, fi, si, img_size):用于对预测结果进行降尺度的自定义方法。y.append(yi):将处理后的结果添加到y列表中。
裁剪增强后的结果并输出
y = self._clip_augmented(y) # 裁剪增强结果,去除不必要的或超出边界的数据。
return torch.cat(y, -1), None # 将所有输出按最后一个维度拼接,形成完整的增强推断结果其他方法
DetectionModel类中的其他方法都属于 @staticmethod,这些方法不依赖于类的实例,可以通过类本身被直接调用。这些方法比较简单,不过多赘述
_descale_pred方法
由于训练时可能有图像翻转或裁剪等,所以在某些情况下(如评估模型性能、可视化结果等)需要将经过处理后的预测结果反向处理,使之恢复到原始图像的特征。
def _clip_augmented方法
主要作用是对增广的推理输出进行裁剪(clip tails),以确保只保留有效的检测结果(没错,就是刚刚_predict_augment方法调用的)
init_criterion方法
根据模型的配置(是否使用端到端模式)初始化并返回适当的损失函数对象。
至此,我们把DetectionModel类成功搞清楚啦!下篇文章我们继续追踪"trainer": yolo.detect.DetectionTrainer !YOLOv11小白的进击之路(三)从YOLO类-DetectionTrainer类出发看YOLO代码运行逻辑...-CSDN博客
最后
YOLOv11小白的进击之路系列持续更新中...欢迎一起交流探讨 ~ 砥砺奋进,共赴山海!
文章推荐

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 78
78 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)