电影推荐及数据分析可视化系统(Python+Echarts+Mysql+Flask框架)
电影推荐及数据分析可视化系统(Python+Echarts+Mysql+Flask框架)
提升自己,掌握数据分析的能力,最快的方式就是实践!
下面是对本项目的一些功能展示、介绍以及部分核心代码的展示,附项目系统展示的视频,制作不易如需完整代码后台私信我有偿获取!
一 、系统分析及功能介绍
1.系统分析
系统采用Python作为开发语言,拥有丰富的库和强大的生态系统。Flask框架轻量级且灵活,易于构建Web应用,处理用户请求和业务逻辑。协同过滤推荐算法有成熟理论,借助Python相关库能高效实现个性化推荐。ECharts可实现数据可视化,其丰富的图表类型和良好的交互性,能满足多种数据展示需求。
2.功能介绍
(1)用户功能
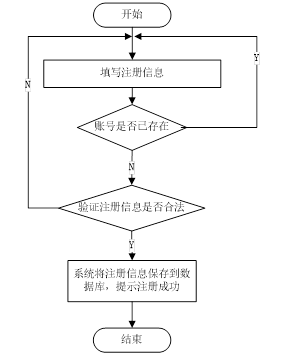
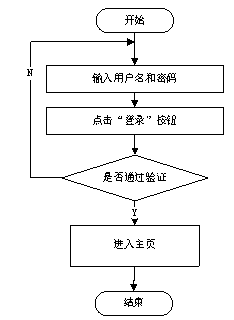
登录/注册:用户需通过注册账号并登录系统才能访问个性化功能。系统应提供简便的注册和登录流程,并确保用户信息的安全性。
电影信息查看:用户能够浏览系统中各类电影的信息,包括电影海报、基本介绍和评分等。提供简单易用的搜索和筛选功能,以帮助用户快速找到感兴趣的电影。
电影收藏:用户可以将喜欢的电影添加到个人收藏列表中,以便于日后查看和管理。系统需支持对收藏列表的增删改查操作。
电影详情评论:用户可以查看每部电影的详细信息和其他用户的评论,系统还应提供发表评论的功能,提升互动性和用户参与感。
电影推荐:系统将基于用户的历史观看记录和偏好,提供个性化的电影推荐,帮助用户发现新电影,提升用户的观影体验。
(2)数据可视化功能
上映地区分布:系统可以通过地图或图表形式显示电影在不同地区的上映情况,帮助用户了解电影的地域分布。
电影类型分布:展示不同类型电影的数量和比例,让用户能够更好地了解市场趋势及观众偏好。
上映年份分布:通过时间轴或柱状图展示不同年份上映电影的数量,分析电影行业的变化和发展趋势。
电影评分分布:系统应展示电影评分的分布情况,帮助用户了解不同评分段电影的数量,提供更全面的参考。
时间轴评分排行:对电影进行时间轴评分排行,便于用户快速获取评分变化的趋势,了解新旧电影的受欢迎程度。
时间轴评论数排行:展示各电影在不同时间段的评论数变化,帮助分析用户互动的活跃度和受欢迎程度,为后续的市场分析提供数据支持。
(3)管理员功能
登录:管理员通过专属的登录页面进行登录,输入正确的用户名和密码后成功登录进入后台管理页面。
用户管理:管理员能够查看用户信息,并且能够对用户进行添加以及删除操作。
电影管理:管理员能够查看所有的电影数据以及对电影数据进行添加以及删除操作。
留言管理:管理员能够查看用户的留言记录,并且能够对留言记录进行添加以及删除操作。
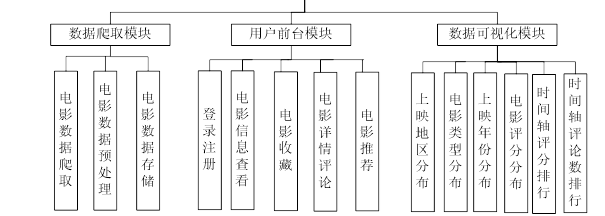
二、 系统功能详细设计
1.数据爬取
利用Python的Requests库编写网络爬虫代码,对豆瓣电影数据展开爬取。向豆瓣电影返回数据的接口发起请求,请求时带上请求头信息和随机IP。把返回的结果加载成json格式,再用with open语句将结果写入文件。
此数据爬取功能可采集豆瓣电影网站的电影数据,涵盖主演信息、上映日期、电影id、电影url地址、海报图片、上映地区、评分、电影简介、电影名称、电影类型等字段。管理员在后台运行特定脚本文件来触发数据采集操作。系统运用Python语言,结合网络爬虫框架进行数据抓取与存储,同时记录相关日志信息,以此保障数据的准确性和完整性,为后续的电影个性化推荐系统提供数据支撑。
2.系统流程设计
用户注册过程在系统里是极为关键且不可或缺的步骤。用户通过注册,能够获取登录系统所必需的账号与密码,并且填写一些必要的个人信息,这样系统就能更精准地为用户提供个性化服务。要是用户还没有注册账号,系统就会提醒用户去进行注册。
注册流程具体包含填写账号、密码以及其他必要信息。一旦用户填写的用户名已经存在于系统中,系统会马上提示用户该用户名已被占用,同时要求用户重新填写。当用户完成注册流程中的所有步骤后,就能够成功注册。
对于已经注册的用户,他们可以直接依照既定流程进行登录操作。
用户登录是系统中必不可少的环节,通过登录验证用户身份,同时也为系统管理员提供了登录用户相关信息的来源,为系统数据分析提供了基础数据。用户在登录过程中需在相应窗口输入账号、密码以及正确的验证码,系统将验证用户输入信息的正确性,若验证通过,则用户可以成功登录系统。
3.推荐模块设计
本模块主要功能是根据用户历史行为数据分析结果,结合协同过滤算法进行个性化、精准化的电影推荐。
系统读取用户收藏信息,并将其转化为相应的文件格式,再将其存储到相应的数据库表,生成推荐模型,推荐模型根据用户评分以及收来对每部电影进行排序,然后优先将符合用户喜好的电影加入推荐表中,进行可视化展示。
在实现电影推荐的过程中,重点在于评估系统里不同用户之间的关联相似度。本研究把用户的收藏行为当作衡量标准,要是两个用户的收藏行为相近,那就表明他们对某些电影有着相似的兴趣。
就拿用户1001和用户1002来说,这里设定N(1001)代表用户1001曾经收藏过的电影集合,N(1002)代表用户1002曾经收藏过的电影集合。运用Jaccard相似度公式来计算用户1001和用户1002之间的兴趣相似度。通过计算Jaccard相似度,就可以得出用户1001和用户1002之间的相似度数值。相似度值越高,意味着这两个用户对电影的兴趣越相似,则给用户1001推荐用户1002喜欢的电影,反过来也是同样的道理。
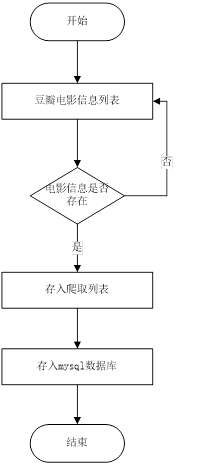

三、项目功能图片展示
数据爬取结果展示 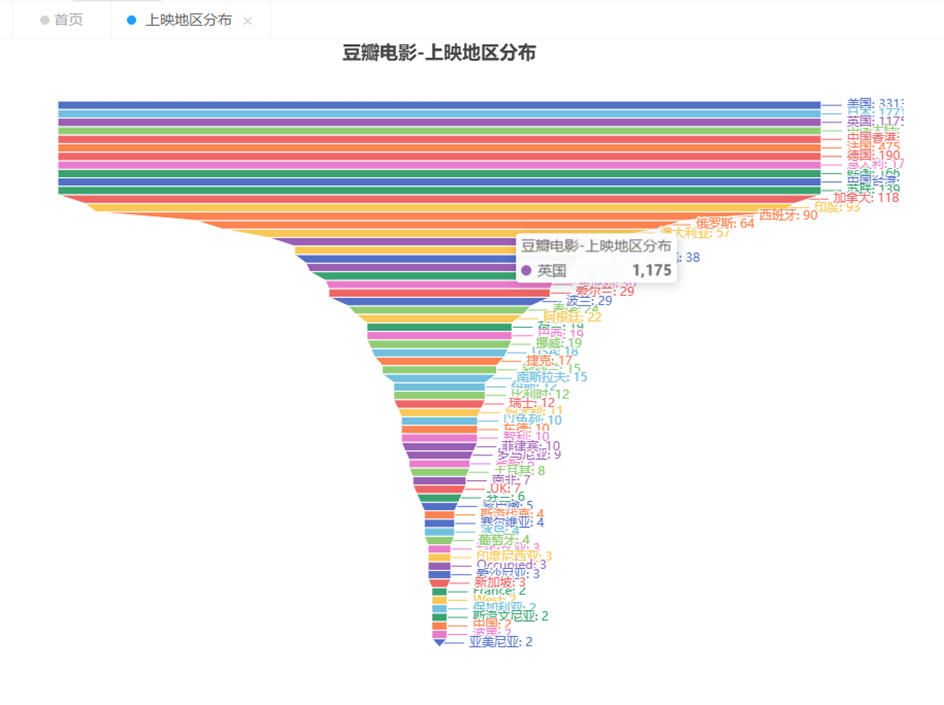
可视化部分展示
四、部分核心代码展示
1.数据爬取模块
import csv
import json
import os
import random
import time
import requests
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9",
"origin": "https://movie.douban.com",
"priority": "u=1, i",
"referer": "https://movie.douban.com/explore",
"sec-ch-ua": "\"Not A(Brand\";v=\"8\", \"Chromium\";v=\"132\", \"Google Chrome\";v=\"132\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
cookies = {
"bid": "aSEkw2BmMy0",
"ll": "\"118163\"",
"douban-fav-remind": "1",
"_ga_RXNMP372GL": "GS1.1.1726020007.1.1.1726020014.53.0.0",
"_vwo_uuid_v2": "D198CDC8B0A44076199DA8D05449AF077|3e376f7533096e5b359997a603c09ab0",
"_ga": "GA1.2.1806896010.1723441748",
"_ga_PRH9EWN86K": "GS1.2.1734079184.1.0.1734079184.0.0.0",
"viewed": "\"33474750_37093283_25888061_36999799\"",
"dbcl2": "\"279168322:XDbIgnxunIQ\"",
"push_noty_num": "0",
"push_doumail_num": "0",
"__utmv": "30149280.27916",
"ck": "_Dv9",
"ap_v": "0,6.0",
"__utma": "30149280.1806896010.1723441748.1736760449.1737437299.5",
"__utmb": "30149280.0.10.1737437299",
"__utmc": "30149280",
"__utmz": "30149280.1737437299.5.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic",
"frodotk_db": "\"ba3b2147d5f487f62eb163d781dd97e2\""
}
def spider(tags, p):
# 定义请求的url
url = "https://m.douban.com/rexxar/api/v2/movie/recommend"
# 使用 format 方法填充 tags
selected_categories = '{{"类型":"{}"}}'.format(tags)
# 定义请求参数
params = {
"refresh": "0",
"start": f"{p}",
"count": "20",
"selected_categories": selected_categories,
"uncollect": "false",
"sort": "S",
"tags": f"{tags}",
"ck": "_Dv9"
}
#发送 HTTP GET 请求
response = requests.get(url, headers=headers, cookies=cookies, params=params)
print(response.text)
# 解析JSON数据
data = json.loads(response.text)
# 提取电影信息列表
feeds = data['items']
# CSV文件路径
csv_file_path = 'movies.csv'
# 检查文件是否存在
file_exists = os.path.exists(csv_file_path)
# 打开文件以追加模式写入数据
with open(csv_file_path, mode='a', encoding='utf-8', newline='') as csvfile:
# 定义CSV列名
# fieldnames = ['电影ID', '标题', '副标题', '年份', '评分', '星级人数', '评论数', '评论', '海报', '用户头像', '用户名', '排名']
fieldnames = ['movie_id', 'title', 'subtitle', 'year', 'rating', 'star_count', 'comment_count', 'comment',
'poster', 'user_avatar', 'user_name', 'rank']
# 创建CSV写入对象
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 如果文件不存在,写入表头
if not file_exists:
writer.writeheader()
# 写入每个电影的详细信息
for feed in feeds:
try:
movie_data = {
'movie_id': feed['id'],
'title': feed['title'],
'subtitle': feed['card_subtitle'],
'year': feed['year'],
'rating': feed['rating']['value'],
'star_count': feed['rating']['star_count'],
'comment_count': feed['rating']['count'],
'comment': feed['comment']['comment'],
'poster': feed['pic']['large'],
'user_avatar': feed['comment']['user']['avatar'],
'user_name': feed['comment']['user']['name'],
'rank': feed['honor_infos'][0]['rank'] if feed['honor_infos'] else None # 确保有荣誉信息
}
print(movie_data)
writer.writerow(movie_data) # 写入行
except:
continue
# 定义电影类型列表并循环爬取
tags_list = ['动作', '科幻', '动画', '悬疑', '犯罪', '惊悚', '冒险', '音乐', '历史', '奇幻', '恐怖', '战争', '传记', '歌舞', '武侠', '情色', '灾难', '西部',
'纪录片', '短片']
for tags in tags_list:
for p in range(1, 30):
print(f'第{p}页爬取中')
# 计算请求的起始位置
p = p * 20
# 调用 spider 函数进行爬取
spider(tags, p)
# 随机暂停 1 - 5 秒
time.sleep(random.randint(1, 5))
2.数据清洗模块
import pandas as pd
# 读取CSV文件
df = pd.read_csv('movies.csv',
names=['电影ID', '标题', '副标题', '年份', '评分', '星级人数', '评论数', '评论', '海报', '用户头像', '用户名', '排名'], skiprows=1)
# 拆分副标题为多个列
subtitle_split = df['副标题'].str.split(' / ', expand=True)
# 检查拆分后的列数量
n_columns = subtitle_split.shape[1]
if n_columns == 5:
# 如果有5列,将第四列和第五列合并成一个列
subtitle_split[3] = subtitle_split[3] + ' / ' + subtitle_split[4] # 合并第四和第五列
subtitle_split = subtitle_split.drop(columns=[4]) # 删除原来的第五列
elif n_columns > 5:
# 如果大于5列,将第四列和第五列以后的所有列合并为一个列
subtitle_split[3] = subtitle_split.iloc[:, 4:].apply(lambda row: ' / '.join(row.dropna()), axis=1) # 合并第四列及以后的列
subtitle_split = subtitle_split.iloc[:, :4] # 只保留前4列
# 重命名列
subtitle_split.columns = ['发布年份', '发布地区', '电影类型', '主演'] # 这里定义 "主演" 列
# 将拆分后的列加入到原DataFrame
df = pd.concat([df, subtitle_split], axis=1)
# 删除原副标题列
df.drop(columns=['副标题'], inplace=True)
df['主演'] = df['主演'].replace('/', '', regex=True)
df['发布地区'] = df['发布地区'].str.split(' ').str[0]
df['电影类型'] = df['电影类型'].str.split(' ').str[0]
df['排名'] = df['排名'].fillna('0')
# 保存处理后的DataFrame
df.to_csv('clean.csv', index=False, encoding='utf-8-sig')
3.数据分析模块
from collections import Counter
import jieba
import pandas as pd
import pymysql
conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
db='hot_movie_analysis',
charset='utf8mb4'
)
cursor = conn.cursor()
df = pd.read_csv('clean.csv')
df = df.drop_duplicates(subset=['标题'])
def part1():
# 首先去除空值
df['主演'] = df['主演'].replace('', None) # 将空字符串替换为 None
# 提取每个演员并统计出现次数
actor_counts = df['主演'].dropna().str.split(' ').explode().value_counts() # 使用 dropna() 去掉空值
# 将结果转换为 DataFrame
actor_counts_df = actor_counts.reset_index()
actor_counts_df.columns = ['演员', '出现次数'] # 重命名列
# 移除演员列为空的行
actor_counts_df = actor_counts_df[actor_counts_df['演员'].str.strip() != '']
print(actor_counts_df)
truncate_sql = 'truncate table part1'
cursor.execute(truncate_sql)
conn.commit()
sql = 'insert into part1(name,value) values(%s,%s)'
for index, row in actor_counts_df.iterrows():
cursor.execute(sql, (row['演员'], row['出现次数']))
conn.commit()
def part2():
# 首先去除空值
df['主演'] = df['主演'].replace('', None) # 将空字符串替换为 None
# 创建一个列表用于存储演员和相关评论数
actor_comments_list = []
# 确保评论数是数值类型
df['评论数'] = pd.to_numeric(df['评论数'], errors='coerce') # 将评论数转换为数值类型,无法转换的将变为 NaN
# 提取每个演员和对应的评论数
for index, row in df.iterrows():
# 检查主演是否为 NaN
if pd.notna(row['主演']):
actors = row['主演'].split(' ')
comments_count = row['评论数']
for actor in actors:
if actor.strip(): # 确保演员名称不是空的
actor_comments_list.append({'演员': actor.strip(), '评论数': comments_count})
# 将列表转换为 DataFrame
actor_comments = pd.DataFrame(actor_comments_list)
# 计算每个演员的平均评论数
average_comments = actor_comments.groupby('演员')['评论数'].mean().reset_index().sort_values(by='评论数',
ascending=False).head(10)
average_comments.columns = ['演员', '平均评论数'] # 重命名列
# 输出结果
print(average_comments)
truncate_sql = 'truncate table part2'
cursor.execute(truncate_sql)
conn.commit()
sql = 'insert into part2(name,value) values(%s,%s)'
for index, row in average_comments.iterrows():
cursor.execute(sql, (row['演员'], row['平均评论数']))
conn.commit()
def part3():
# 确保年份列是数值类型
df['年份'] = pd.to_numeric(df['年份'], errors='coerce')
# 确保评论数是数值类型
df['评论数'] = pd.to_numeric(df['评论数'], errors='coerce')
# 计算不同年份的平均评论数
average_comments_by_year = df.groupby('年份')['评论数'].mean().reset_index()
# 重命名列
average_comments_by_year.columns = ['年份', '平均评论数']
# 输出结果
print(average_comments_by_year)
truncate_sql = 'truncate table part3'
cursor.execute(truncate_sql)
conn.commit()
sql = 'insert into part3(name,value) values(%s,%s)'
for index, row in average_comments_by_year.iterrows():
cursor.execute(sql, (row['年份'], row['平均评论数']))
conn.commit()
def part4():
global df
# 确保评论数是数值类型
df['评论数'] = pd.to_numeric(df['评论数'], errors='coerce') # 将评论数转换为数值类型,无法转换的将变为 NaN
# 按评论数排序,选择前20个
top_20_movies = df.sort_values(by='评论数', ascending=False).head(30)
# 选择需要的列进行展示
top_20_movies_summary = top_20_movies[['标题', '年份', '评分', '评论数', '主演']]
# 输出结果
print(top_20_movies_summary)
truncate_sql = 'truncate table part4'
cursor.execute(truncate_sql)
conn.commit()
sql = 'insert into part4(name,value) values(%s,%s)'
for index, row in top_20_movies_summary.iterrows():
cursor.execute(sql, (row['标题'], row['评论数']))
conn.commit()
def load_stopwords(file_path):
"""加载停用词文件,确保使用 UTF-8 编码"""
with open(file_path, 'r', encoding='utf-8') as f:
stopwords = set(f.read().strip().splitlines())
return stopwords
def part5():
# 加载停用词
stopwords = load_stopwords('stopwords.txt')
comments = df['评论'].tolist()
# 分词并过滤停用词
word_list = []
for comment in comments:
words = (word for word in jieba.cut(comment) if word not in stopwords and word.strip())
word_list.extend(words)
# 统计词频
word_counts = Counter(word_list)
# 转换为 DataFrame 以便更好地查看结果
word_freq_df = pd.DataFrame(word_counts.items(), columns=['词语', '出现次数'])
# 按出现次数排序
word_freq_df = word_freq_df.sort_values(by='出现次数', ascending=False)
# 输出结果
print(word_freq_df)
truncate_sql = 'truncate table part5'
cursor.execute(truncate_sql)
conn.commit()
sql = 'insert into part5(name,value) values(%s,%s)'
for index, row in word_freq_df.iterrows():
cursor.execute(sql, (row['词语'], row['出现次数']))
conn.commit()
if __name__ == "__main__":
# part1()
# part2()
# part3()
# part4()
part5()
4.电影推荐模块
# coding = utf-8
# 推荐算法实现
import csv
import pymysql
import math
from operator import itemgetter
class UserBasedCF():
# 初始化相关参数
def __init__(self):
# 找到与目标用户兴趣相似的3个用户,为其推荐5部电影
self.n_sim_user = 5
self.n_rec_movie = 6
self.dataSet = {}
# 用户相似度矩阵
self.user_sim_matrix = {}
self.movie_count = 0
print('Similar user number = %d' % self.n_sim_user)
print('Recommneded movie number = %d' % self.n_rec_movie)
# 读文件得到“用户-电影”数据
def get_dataset(self, filename, pivot=0.75):
dataSet_len = 0
for line in self.load_file(filename):
movie, user, rating = line.split(',')
# print(type(movie), type(user), type(rating))
# if random.random() < pivot:
self.dataSet.setdefault(int(user), {})
self.dataSet[int(user)][int(movie)] = rating
print(self.dataSet)
dataSet_len += 1
# else:
# self.testSet.setdefault(user, {})
# self.testSet[user][movie] = rating
# testSet_len += 1
print('Split trainingSet and testSet success!')
print('dataSet = %s' % dataSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load %s success!' % filename)
# 计算用户之间的相似度
def calc_user_sim(self):
# 构建“电影-用户”倒排索引
# key = movieID, value = list of userIDs who have seen this movie
print('Building movie-user table ...')
movie_user = {}
for user, movies in self.dataSet.items():
for movie in movies:
if movie not in movie_user:
movie_user[movie] = set()
movie_user[movie].add(user)
print('Build movie-user table success!')
self.movie_count = len(movie_user)
print('Total movie number = %d' % self.movie_count)
print('Build user co-rated movies matrix ...')
for movie, users in movie_user.items():
for u in users:
for v in users:
# if u == v:
# continue
self.user_sim_matrix.setdefault(u, {})
self.user_sim_matrix[u].setdefault(v, 0)
self.user_sim_matrix[u][v] += 1
# print(self.user_sim_matrix)
print('Build user co-rated movies matrix success!')
# 计算相似性
print('Calculating user similarity matrix ...')
for u, related_users in self.user_sim_matrix.items():
for v, count in related_users.items():
self.user_sim_matrix[u][v] = count / math.sqrt(len(self.dataSet[u]) * len(self.dataSet[v]))
print('Calculate user similarity matrix success!')
# 针对目标用户U,找到其最相似的K个用户,产生N个推荐
def recommend(self, user):
K = self.n_sim_user
N = self.n_rec_movie
rank = {}
# print(user)
watched_movies = self.dataSet[user]
# print('user',type(user))
# print('111',self.user_sim_matrix)
# v=similar user, wuv=similar factor
for v, wuv in sorted(self.user_sim_matrix[user].items(), key=itemgetter(1), reverse=True)[0:K]:
for movie in self.dataSet[v]:
if movie in watched_movies:
continue
rank.setdefault(movie, 0)
rank[movie] += wuv
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print("Evaluation start ...")
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
# 打开数据库连接
db = pymysql.connect(host='localhost', user='root', password='123456', database='hot_movie_analysis',
charset='utf8')
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
sql1 = "truncate table rec;"
cursor.execute(sql1)
db.commit()
sql = "insert into rec (user_id,movie_id,rating ) values (%s,%s,%s)"
print(self.dataSet)
for i, user, in enumerate(self.dataSet):
print(user, i)
rec_movies = self.recommend(int(user))
print(user, rec_movies)
for item in rec_movies:
data = (user, item[0], item[1])
cursor.execute(sql, data)
db.commit()
# rec_movies 是推荐后的数据
# 把user-rec-rating 存到数据库
cursor.close()
db.close()
if __name__ == '__main__':
db = pymysql.connect(host='localhost', user='root', password='123456', database='hot_movie_analysis',
charset='utf8')
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
sql = "select * from user_movie"
cursor.execute(sql)
data = cursor.fetchall()
cursor.close()
db.close()
with open('rating.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['movie_id', 'user_id', 'rating'])
for item in data:
writer.writerow([item[2], item[1], 1])
rating_file = 'rating.csv'
userCF = UserBasedCF()
userCF.get_dataset(rating_file)
userCF.calc_user_sim()
userCF.evaluate()
到这里这个电影推荐数据分析可视化系统的介绍就结束了,本文章附带了项目系统展示视频,可以自行查看,本项目可以当做技术训练进阶以及毕业设计项目进行学习和使用,有需要完整代码的可以后台私信我有偿获取(#^.^#)!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)