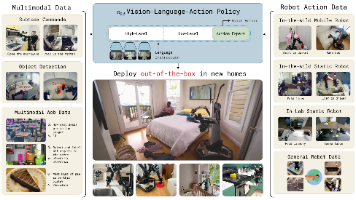
π0.5——让VLA走出实验室,泛化在开放世界中的π0推理加强版:同一个模型中先高层拆解出子任务,后低层执行子任务
今天4.23一早「本文起笔于25年4.23日上午,后因当天下午受邀去长理做了个面对200研究生的大模型与具身落地实践的讲座,导致在4.23当天 没有写完——一直放在草稿箱里,直到4.24日凌晨 才写完了一半,随后才对外发布,所以你看到的发表日期是4.24日凌晨」
朋友圈刷到π0所在的公司Physical Intelligence (π)于4.22日推出π0的0.5版本了「详见《π0.5: a VLA with Open-World Generalization》」,之后,我组建的「七月具身:π0复现微调交流群」群中,也在讨论这事,并说:七月老师要更新博客了
这不就来了
现在具身模型的发展 还不如大语言模型那样成熟
- 大语言模型,现在无论国内外,基本都有迭代,比如国内deepseek qwen glm,国外的gpt llama gemini
- 但不少具身模型只有第一版,大概率没后续版本、没后续的升级/维护,但即便如此,依然非常感谢他们宝贵的idea,以及对外开放的paper,更别说 还开源代码的了——very respect
更何况这其中,也有一些机构 在之前模型上 想大力度创新,因为改动大,故命名新的模型,而非是老模型的几点几版本
π0 发新版了,意味着和Google的RT(大概率是不更了),以及figure(没开源过)等等——还有别的一些模型 没列举全,进入了少数迭代型的具身模型的行列
而且在π0至π0.5之间,他们还发布了π0的各种变体、比如FAST π0、Hi Robot
额外说个事,目前国内具身赛道分为三派(彼此交叉 各有侧重)
- 一派是以清华为代表的学院派,侧重科研,比如具身模型的底层突破
- 一派是以宇树为代表的硬件派,侧重运动控制
- 一派是以七月为代表的落地派,侧重场景落地与定制开发
具体而言
- 我司「七月在线」作为具身智能的场景落地与定制开发商,今年有望交付10个集团客户的具身订单,且交付的过程中,会适时摘取出部分可以分享的细节,分享到本博客内
- 且我们也在持续招人且持续扩大合作开发圈
比如我司长沙、武汉、上海具身团队都在招人,特别是上海具身团队的扩充,如果在上海,做过sim2real/运动控制、或上肢操作的,欢迎垂询
第一部分 全新的π0.5
1.1 提出背景
要想让机器人走出实验室,到现实世界中具备可执行各种任务的泛化能力,则意味着它必须能够从各种信息来源中转移经验和知识
- 其中一些来源是与当前任务直接相关的亲身经验
- 一些则需要从其他机器人形态、环境或领域中进行迁移,就像人类也会利用他人告诉自己的事实,或者在他人书中得到知识
- 还有一些则代表完全不同的数据类型,例如基于网络数据的语言指令、感知任务或高层语义命令的预测
这些不同数据来源的异质性构成了一个主要障碍,但幸运的是:通过将不同模态纳入相同的序列建模框架,VLA 可以适应机器人数据、语言数据、计算机视觉任务以及上述组合的训练
在本文中,作者们利用这一观察设计了一种用于VLA的协同训练框架,该框架能够利用异质和多样的知识来源,实现广泛的泛化能力
总的来说,π0.5借鉴了来自多种来源的经验:
- 除了使用在各种真实家庭环境中直接用移动操作机器人收集的中型数据集(约400 小时)之外
- π0.5 还使用了其他非移动机器人数据、在实验室条件下收集的相关任务数据、需要基于机器人观察预测” 高层次” 语义任务的训练示例——即高级语义下的子任务预测、人类监督者提供给机器人的口头语言指令
- 以及由网络数据创建的各种多模态示例,例如图像描述、问答和目标定位

在首次训练阶段提供给 π0.5 的绝大多数训练示例(97.6%)并非来自执行家庭任务的移动机械臂,而是来自这些其他来源——即上述的后两者,例如其他机器人或网络数据
尽管如此,π0.5 仍能够在训练期间未曾见过的全新家庭中控制移动机械臂,执行诸如挂毛巾或整理床铺之类的复杂任务,并且能够根据仅有的高级提示执行长达10到15分钟的长时程操作技能,例如清洁整个厨房或卧室
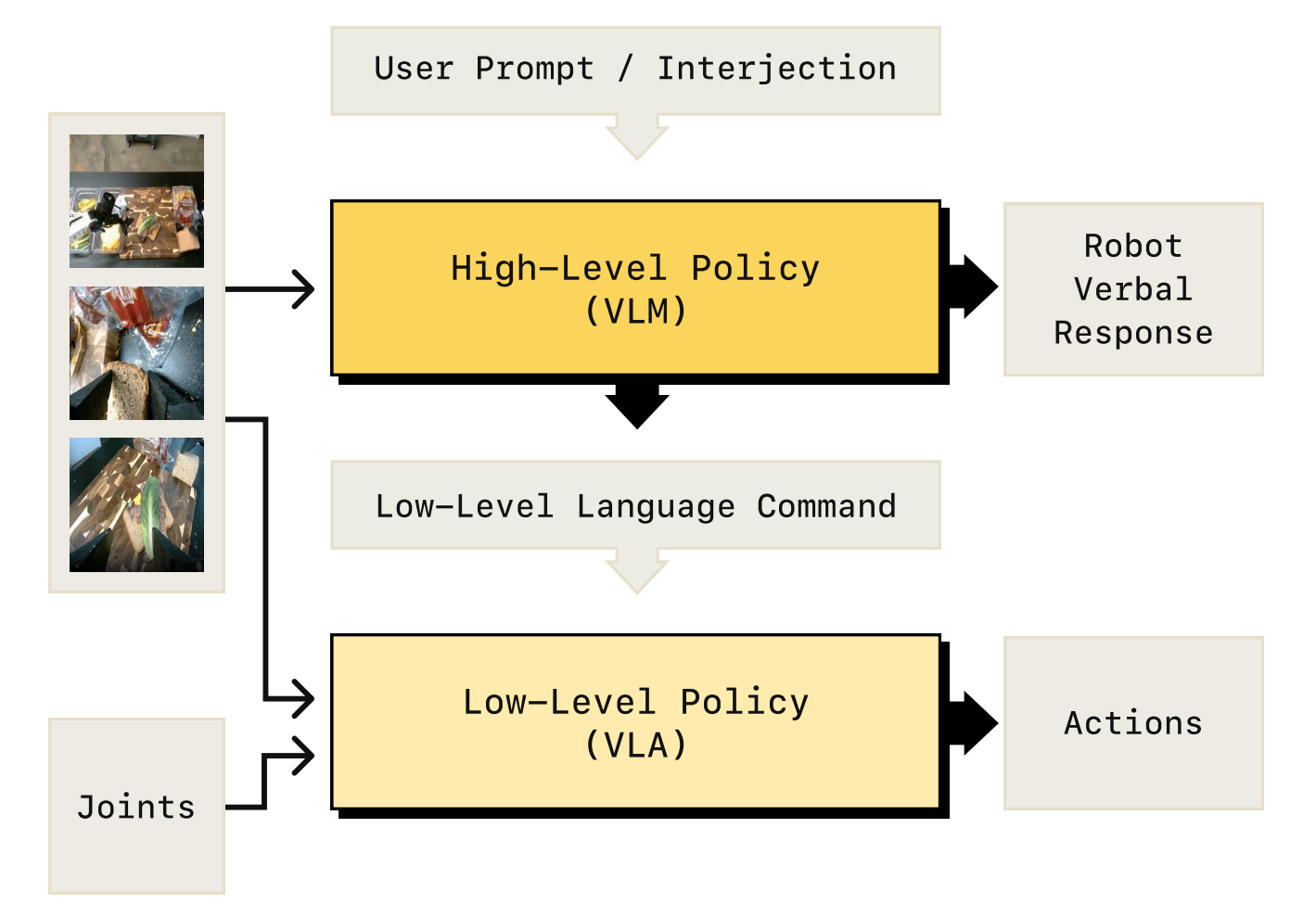
π0.5的设计遵循一个简单的分层架构:
- 首先在异构训练任务的混合体上对模型进行预训练,然后通过「高级语义动作-低级动作示例」对移动的操作进行专门的微调,这些低级动作对应于所预测的子任务标签,例如“拿起砧板” 或 “重新整理枕头”——相当于当人类给出了一个高级语义指令 比如 “清洁整个厨房或卧室 ”,机器人需要预测其对应的子任务 比如“ 拿起砧板” 或” 重新整理枕头”
we first pre-train the model on the heterogeneous mixture of training tasks, and then fine-tune it specifically for mobile manipulation with both low-level action examples and
high-level “semantic” actions, which correspond to predicting subtask labels such as “pick up the cutting board” or “rearrange the pillow.” - 即在运行时,每次推理步骤中,模型首先预测语义子任务,根据任务结构和场景的语义推断下一步适合执行的行为,然后基于该子任务预测低级机器人动作块
比如如下图所示,机器人被指派清洁一个家中未包含在训练数据中的厨房。模型被赋予了4个常规任务——关闭柜子,将物品放入抽屉,擦拭溢出物,并将餐具放入水槽
比如,对于最后一个任务,它通过预测“并将餐具放入水槽”任务的子任务(例如,拿起盘子)并执行低级动作来完成该任务
这种简单的架构既提供了对长时间跨度多阶段任务进行推理的能力,也提供了利用两级不同知识来源的能力
- 低级动作推理过程能够直接受益于其他机器人收集的动作数据,包括在其他环境中的简单静态机器人
- 而高级推理过程则能从网络上的语义示例、高级注释预测甚至人类“监督者”向机器人提供的口头指令中获益
这种设计通过逐步引导机器人完成复杂任务,就像指导一个人那样,指示它完成诸如打扫房间之类的复杂任务所需的适当子任务
1.2 相关工作:VLA、基于VLM的推理与规划等等
1.2.1 通用操作策略、VLA、非机器人数据的共同训练
第一,对于通用机器人操作策略
- 最近的研究表明,将机器人操作策略的训练数据分布从狭窄的单任务数据集扩展到涵盖许多场景和任务的多样化数据集[17-Robonet, 25-Bridge data, 80-BridgeData v2, 63-Open X-Embodiment, 41-Droid, 6-Roboagent, 30-Rh20t, 67-On bringing robots home, 1-Agibot world colosseo],不仅可以使得生成的策略能够开箱即用地解决更广泛的任务,还能提高其在新场景和任务中的泛化能力[9-Rt-1, 63-Open X-Embodiment,62-Octo, 22-Scaling cross-embodied learning]
- 训练这种通用策略需要新的建模方法来处理通常涵盖数百个不同任务和场景的数据集的规模和多样性
第二,对于视觉-语言-动作模型VLAs——下面大部分的模型 在本博客内其他文章内 都已解读过
- [23-Palme: An embodied multimodal language model、92-Rt-2、42-Openvla、8-π0、83-Tinyvla、90-3dvla、55-Rdt-1b、45-Cogact、3-Minivla、75-From multimodal llms to
generalist embodied agents: Methods and lessons、64- FAST: Efficient action tokenization for vision-language-action models、74-Open-world object manipulation using pre-trained vision-language models、84-Dexvla、7-Gr00t n1、37-Otter: A vision-language-action model with text-aware visual feature extraction] 提供了供了一种有吸引力的解决方案:通过微调预训练的视觉-语言模型用于机器人控制,VLAs可以利用从网络规模的预训练中获得的语义知识,并将其应用到机器人学问题上 - 当与高度表达的动作解码机制相结合时,例如流匹配[8-π0]、扩散[55-Rdt-1b, 84-Dexvla, 52-Hybridvla],或先进的动作token化方案[64-FAST: Efficient action tokenization for vision-language-action models],VLAs可以在现实世界中执行广泛的复杂操作任务
- 然而,尽管具有令人印象深刻的语言跟随能力,VLAs通常仍在与其训练数据密切匹配的环境中进行评估
虽然一些研究表明,通过在更广泛的环境中收集机器人数据,可以使得简单技能(如拾取物体或打开抽屉)实现泛化[14-UMI, 67-On bringing robots home,28-Robot utility models, 49-Data scaling laws in imitation learning for robotic manipulation, 64-FAST π0],但将同样的方法应用于更复杂的长时间任务(如清理厨房)却充满挑战,因为通过强行扩大机器人数据收集范围来实现可能场景的广覆盖 不总是行得通的——更何况大规模层面的数据收集 并不是一件轻松的事
第三,对于非机器人数据的共同训练
- 许多先前的研究试图利用多样的非机器人数据来改进机器人策略的泛化能力。先前的方法探索了从计算机视觉数据集[85-Masked visual pre-training for motor control,58-R3m,57-Where are we in the search for an artificial visual cortex for embodied intelligence?,18- An unbiased look at datasets for visuomotor pre-training]初始化视觉编码器
或利用现成的任务规划器[38- Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,48-Code as policies: Language model programs for embodied control,73- Progprompt: Generating situated robot task plans using large language models,81- Llmˆ3: Large language model-based task and motion planning with motion failure reasoning] - VLA策略通常从预训练的视觉语言模型初始化,该模型已接触到大量的互联网视觉和语言数据[23- Palme,92-Rt-2,42-Openvla]。值得注意的是,VLA架构具有灵活性,允许在多模态视觉、语言和动作token的输入和输出序列之间进行映射
因此,VLA扩展了可能的迁移方法的设计空间,不仅仅是简单的权重初始化,而是支持在不仅机器人动作模仿数据,而且任何交织上述一种或多种模态的数据集上对单一统一架构进行协同训练 - 先前的研究表明,用 用于VLM训练的数据混合协同训练VLA[23- Palme,92-Rt-2,86-Magma: A foundation model for multimodal ai agents]可以提高其泛化能力,例如在与新物体或未见过的场景背景交互时
在π0.5这项工作中,他们设计一个系统,用于利用更广泛的机器人相关监督数据源对VLAs进行协同训练,这些数据源包括来自其他机器人的数据、高级语义下的子任务预测以及口头语言指令
虽然多任务训练和协同训练并非新概念,但他们展示了他们系统中特定的数据源组合使移动机器人能够在全新的环境中执行复杂且长期的行为。他们认为,这种泛化水平,尤其是考虑到任务的复杂性,远远超出了先前工作的成果
1.2.2 基于大语言模型的机器人推理和规划
第四,对于基于大语言模型的机器人推理和规划
许多先前的研究表明,通过高层次推理增强端到端策略可以显着提高长时间任务的性能——特别是当高层次子任务推断能够从大型预训练的LLMs和VLMs中受益时,比如
- 2-Do as i can and not as i say,36- Look before you leap,44-Interactive task planning with language models,74- Open-world object manipulation using pre-trained vision-language models,
- 71-Yell at your robot,4-Rt-h,16-Racer,11-Automating robot failure recovery
- using vision-language models with optimized prompts,53 -Okrobot,88-Robotic control
- via embodied chain-of-thought reasoning,
- 51-Moka: Open-vocabulary robotic manipulation
- through mark-based visual prompting,59-Pivot: Iterative visual prompting
- elicits actionable knowledge for vlms,13-Navila: Legged robot vision-language-action model for navigation,70-Bumble: Unifying reasoning and acting with vision-language models for building-wide mobile manipulation,
- 91-Closed-loop open-vocabulary mobile manipulation with gpt-4v,65-Open-vocabulary mobile manipulation in unseen dynamic environments with 3d semantic maps,
- 72-Hi robot: Open-ended instruction following with hierarchical vision-language-action models,47-Hamster: Hierarchical action models for open-world robot manipulation,76-Gemini robotics: Bringing ai into the physical world,8-π0
π0.5的方法也采用了两阶段推理过程:首先推断出来高层次语义的子任务(例如,“拿起盘子”),然后根据此子任务预测动作
但许多先前的方法为此目的使用了两个独立的模型,一个VLM预测语义步骤,另一个独立的低层次策略执行这些步骤,比如
- 2-Do as i can and not as i say,
- 71- Yell at your robot,详见此文《YAY Robot——斯坦福和UC伯克利开源的:人类直接口头喊话从而实时纠正机器人行为(含FiLM详解)》——值得一提的是,π0.5也有类似这个YAY Robot 通过通过口头反馈进行改进的能力,当然 他们新闻页面也说了,他们期望未来也可以利用自主经验,在更少的监督下变得更好,或者在不熟悉的情况下明确请求帮助或建议
- 13-Navila,详见此文《NaVILA——可语音交互的用于四足和人形导航与避障的VLA模型:在VLM的导航规划下,执行基于视觉的运动策略(含NaVILA和rsl_rl的源码解析)》
- 24-Manipulate-anything: Automating real-world robots using vision-language models,
- 70-Bumble: Unifying reasoning and
- acting with vision-language models for building-wide mobile manipulation,
- 72-Hi robot, 详见此文《Hi Robot——大脑加强版的π0:基于「VLM的高层次推理+ VLA低层次任务执行」的复杂指令跟随及交互式反馈》
- 47-Hamster: Hierarchical action models for open-world robot manipulation]
而π0.5的方法在高层次推理和低层次推理中都使用了完全相同的模型,其流程更类似于链式思维[82-CoT],或测试时计算[39-Openai o1 system card,详见此文《一文总览OpenAI o1相关的技术:从CoT、Quiet-STaR、Self-Correct、Self-play RL、MCTS等到类o1模型rStar-Math》]方法
且π0.5与具身链式思维方法
- 88- Robotic control via embodied chain-of-thought reasoning,
- 46-Llara: Supercharging robot learning data for visionlanguage policy,
- 61-Llarva: Vision-action instruction tuning enhances robot learning
不同的是,高级推理过程的运行频率仍低于低级动作推理
即Our method uses the same exact model for both high-level and low-level inference, in a recipe that more closely resembles chain-of-thought [82] or test-time compute [39] methods, though unlike embodied chain-of-thought methods [88, 46, 61], the high-level inference process still runs at a lower frequency than low-level action inference
1.2.3 具有开放世界泛化能力的机器人学习系统
第五,对于具有开放世界泛化能力的机器人学习系统
- 虽然大多数机器人学习系统是在与训练数据密切匹配的环境中进行评估的,但一些先前的研究探索了更广泛的开放世界泛化
比如当机器人的任务被限制在更狭窄的基本任务集合中时,例如拾取物体,允许任务特定假设的方法(例如抓取预测,或结合基于模型的计划和控制)已被证明可以广泛地推广,甚至适用于全新的家庭环境 [40-Robots at the tipping point: the road to irobot roomba,20-Reviews-consumer technology. the teardownamazon astro consumer robot,60-Autonomously learning to visually detect where manipulation will succeed,56-Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,29-Anygrasp] - 然而,这些方法并不能轻易推广到通用机器人可能需要执行的所有可能任务范围
最近,在许多领域收集的大规模数据集[41-Droid: A large-scale inthe-wild robot manipulation dataset,68-Gnm: A general navigation model to drive any robot,63-Open-X,67- On bringing robots home,14-UMI,49-Data scaling laws in imitation learning for robotic manipulation] 被证明可以使简单但端到端学习的任务推广到新环境
再比如[33-Robot learning in homes: Improving generalization and reducing dataset bias,31- Navigating to objects in the real world,67-On bringing robots home,69-ViNT: A foundation model for visual navigation,26-Spoc:Imitating shortest paths in simulation enables effective navigation and manipulation in the real world,49-Data scaling laws in imitation learning for robotic manipulation,28-Robot utility models: General policies for zero-shot deployment in new environments,64-FAST π0] - 且这些演示中的任务仍然相对简单,通常少于一分钟,并且成功率通常较低。而π0.5可以执行长时间的多阶段任务,例如将所有餐具放入水槽或将新卧室地板上的所有衣物拾起,同时推广到全新的家庭环境
1.3 π0.5模型
1.3.1 预备知识
视觉-语言-动作模型(VLAs)通常通过模仿学习在多样化的机器人示范数据上(比如数据集)进行训练
- 其通过最大化在观察
和自然语言任务指令
给定的情况下,动作
(或更一般地,动作序列
)的对数似然值:
其中的观察和本体感受状态
,这反映了机器人关节的位置
- VLA架构遵循现代语言和视觉-语言模型的设计,采用特定模态的分词器将输入和输出映射到离散(“硬”)或连续(“软”)的token表示,并且有一个大型的自回归transformer骨干网络,该网络经过训练可将输入token映射到输出token。这些模型的权重从预训练的视觉语言模型中初始化
通过将策略输入和输出编码为tokenized表示,上述模仿学习问题可以被描述为在「特定的观察、指令和动作token序列上」的下一个token的预测问题,这样就可以利用现代机器学习的可扩展工具对其进行优化
在实践中,图像和文本输入的分词器选择遵循现代视觉语言模型的做法。对于动作,先前的工作已经开发出了基于压缩的高效分词方法[64-FAST π0],他们在本π0.5研究的预训练阶段使用了这些方法
注意,也就意味着,π0.5的预训练是基于下一个token的预测技术,且分词技术用的π0_FAST提出的高效tokenization方法 - 最近的许多视觉语言架构模型还提出通过扩散[55- Rdt-1b, 84-Dexvla, 52-Hybridvla]或流匹配[8-π0]来表示动作分布,这为连续值的动作块提供了更具表现力的表示
在π0.5模型的训练后阶段,他们基于 π0 模型[8]的设计进行构建,该模型通过流匹配来表示动作分布——与动作相对应的token接收来自流匹配前一步骤的部分去噪动作作为输入,并输出流匹配向量场
这些token使用一组不同的模型权重,称之为“动作专家”,类似于专家混合架构。这个动作专家可以专门用于基于流匹配的动作生成,其参数量可以 显著少于 LLM 主干的其余部分
下图图3 中提供了π0.5 模型和训练方法的概述
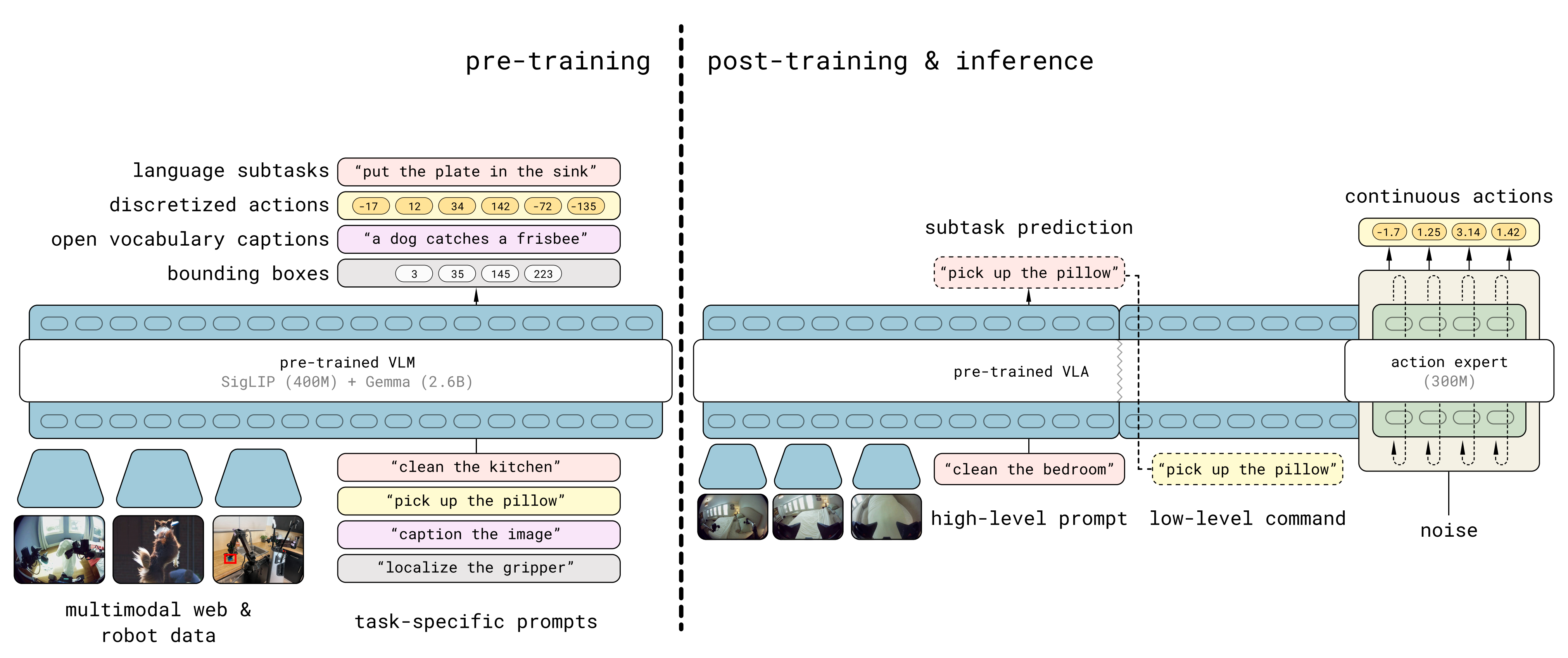
模型权重通过「一个在网络数据上训练的标准VLM」做初始化,然后训练分为两个阶段:
- 一个是用于将模型适应于多种机器人任务的预训练阶段
在预训练阶段,所有任务(包括涉及机器人动作的任务),均使用离散token表示,这使得训练变得简单、可扩展且高效[64-FAST π0]
换言之,将所有不同的数据源结合起来生成具有离散token的初始 VLA。此阶段使用来自不同机器人平台的数据、高级语义动作预测以及来自网络的数据。机器人数据使用 FAST action tokenizer将动作表示为离散token[64] - 另一个是后训练阶段,旨在将其专门用于移动操作,并为其配备高效的测试时推理机制(类似OpenAI o1的test-time inference)
在后训练阶段,他们还给模型配备一个动作专家,就π0一样,以便既可以更细粒度地表示动作,又可以为实时控制实现更高效的推理
即,在后训练阶段,利用与任务最相关的数据(包括来自人类监督员的口头指令)对模型进行专门化处理,使其适用于移动操作的低级和高级推理。此阶段使用流匹配来表示动作分布,从而能够实现高效的实时推理,并能够表示精细的连续动作序列
在推理时,模型首先为机器人生成一个高层次的子任务,然后基于该子任务,通过动作专家预测低层次的动作「At inferencetime, the model first produces a high-level subtask for the robot to perform and then, conditioned on this subtask, predicts the low-level actions via the action expert」
即,在推理时,模型首先推断出一个高级子任务,然后基于此子任务预测动作——At inference time, the model first infers a high-level subtask, and then predicts the actions based on this subtask
1.3.2 π0.5的模型架构
π0.5架构可以灵活地表示动作块分布和tokenized文本输出,其中后者既用于协同训练任务(例如问答),又用于在层次推理过程中输出高级子任务预测
模型捕获的分布可以表示为
- 其中
由所有摄像机的图像和机器人的配置(关节角度、夹爪姿态、躯干抬升姿态以及底座速度)组成
是总体任务提示(例如,“收拾餐具”)
表示模型的(分词后的)文本输出,可以是预测的高层次子任务(例如,将餐具放入水槽”任务的子任务拿起盘子),或网络数据中视觉语言提示的答案
- 而
接下来,他们将分布分解为
通过该表达式,可以很直观的看出来:其中动作分布不依赖于,仅依赖于
,因此
- 高层推断捕捉
- 低层推断捕捉
这两个分布均由同一模型表示
该模型对应于一个Transformer,其接收个多模态输入tokens
「这里宽泛地使用token一词,指离散和连续输入」,并生成一序列多模态输出
因此,可以写为
- 每个
可以是
一个文本token:
- 观察
的前缀部分。根据token类型(由
指示),每个token不仅可以由不同的编码器处理,还可以由Transformer中的不同专家权重处理
例如,图像patch通过视觉编码器处理,文本tokens通过嵌入矩阵嵌入
依照π0[8],将动作tokens线性投影到Transformer嵌入空间,并在Transformer中使用单独的专家权重处理这些动作tokens
- 注意力矩阵
表明一个token是否可以关注另一个token
不同于LLM中的标准因果注意力,这里的图像patch、文本prompt和连续动作token使用双向注意力机制
Compared to standard causal attention in LLMs, image patch, textual prompt, and continuous action tokens use bidirectional attention
由于π0.5希望模型既能输出文本(用于回答有关场景的问题或输出接下来要完成的任务),又能输出动作(用于在现实世界中行动),因此函数的输出被分别拆分为文本token的对数概率和动作输出token,即
个对应于文本token的对数概率,可用于采样
个token由单独的动作专家生成,就像在 π0 中那样,并通过线性映射投影为连续输出,用于获取
请注意,,即并非所有输出都与损失相关联。机器人的本体感觉状态被离散化,并作为文本token输入到模型中
1.4 π0.5的训练方案:先预训练后微调
1.4.0 如何兼顾训练快、推理快:离散化token训练下(自回归),推理时用连续动作表示(流匹配)
类似于π0,他们一开始就想着使用流匹配[50] 来预测最终模型中的连续动作
即给定,其中
是流匹配时间索引,模型被训练以预测流向量场
然而,如[64] 所示,当动作通过离散token表示时,VLA 训练速度可以显著提高,特别是当使用一种对动作块进行高效压缩的tokenization方案(例如,FAST)时,这种离散表示对于实时推断来说不太适合,因为它需要昂贵的自回归解码进行推断[64]
我在解读FAST_π0时,也特地强调过,FAST这种模式可以让训练加速,但让推理却变慢了,详见此文《自回归版π0-FAST——打造高效Tokenizer:比扩散π0的训练速度快5倍但效果相当(含π0-FAST源码剖析)》
- 因此,一个理想的模型设计是对离散化动作进行训练,但在推断时仍然允许使用流匹配生成连续动作
- 因此,π0.5通过自回归采样token(使用 FAST 分词器)和flow field的迭代整合来预测动作「Our model is therefore trained to predict actions boththrough autoregressive sampling of tokens (using the FASTtokenizer) and iterative integration of the flow field」,将两者的优势结合起来
即他们利用注意力矩阵确保不同的动作表示不会相互关注,为优化故最小化综合损失
- 其中
是文本token和预测对数值(包括FAST编码的动作token)之间的交叉熵损失
是(较小的)动作专家的输出
是一个权衡参数
该方案使得能够
- 首先通过将动作映射到文本token (
),其以标准的VLM Transformer 模型的形式对模型进行预训练——说白了 就是用下个token的预测技术做自回归训练
- 然后在后训练阶段添加额外的动作专家权重,以非自回归的方式预测连续的动作token,从而实现快速推理
他们发现,在推理时,首先使用标准的自回归解码生成文本token ,然后在条件为文本token的情况下进行10 步去噪,从而生成动作
1.4.1 自回归预训练:离散化token下的子任务预测——类似下个token预测
在第一个训练阶段,π0.5使用广泛的机器人和非机器人数据进行训练,如下图图4所示
- 预训练数据包括来自移动操纵器(MM)的数据、多种环境下的非移动机器人(ME)的数据、在实验室条件下收集的跨体数据(CE)、高层次子任务预测(HL),以及多模态网络数据(WD)
- 在后训练阶段,额外使用了口头指令(VI),并省略了实验室跨体数据(CE),以将模型重点放在移动操纵和多样化环境上。图中展示了每个类别任务的一个示例子集」
具体而言,在预训练阶段中,它被训练为一个标准的自回归transformer,能够对「文本、物体位置和FAST编码动作token」进行下一个token的预测「It is trained as a standard auto-regressive transformer, performing next-token prediction of text, objectlocations, and FAST encoded action tokens」
而预训练中预训练数据的更清晰介绍,则如下所示
- 多样化的移动操控器数据(MM)
使用了约400小时的移动操控器执行家庭任务的数据,这些任务发生在约100个不同的家庭环境中,其中一些在图7中展示,使用的是第IV-E节中的机器人
这部分训练集与π0.5的评估任务最直接相关,这些任务包括在新的、未见过的家庭环境中进行类似的清洁和整理任务 - 多样化多环境非移动机器人数据(ME)
他们还收集了非移动机器人数据,这些机器人可能有一个或两个机械臂,位于各种家庭环境中。这些机械臂固定在表面或安装平台上,由于它们重量较轻且更易于运输,使得能够在更广泛的家庭中收集更丰富的数据集。然而,这些ME数据来源于与移动机器人不同的体型 - 跨Embodiment实验室数据(CE)
他们在实验室中为广泛的任务(例如,清理桌子、叠衣服)收集了数据,这些任务发生在简单的桌面环境和各种机器人类型中
其中一些任务与π0.5的评估高度相关(例如,将餐具放入垃圾桶),而另一些则不相关(例如,研磨咖啡豆)。这些数据包括单臂和双臂机械臂,以及固定和移动底座
此外,他们还纳入了开源的 OXE 数据集[15]。该数据集是 π0[8] 所用数据集的扩展版本 - 高级子任务预测(HL)
将诸如“打扫卧室”之类的高级任务指令分解为诸如“整理被子”和“捡起枕头”之类的较短子任务,类似于语言模型中的链式思维提示,可以帮助训练好的策略根据当前场景进行推理,并更好地确定下一步行动
对于 MM、ME 和 CE 中涉及多个子任务的机器人数据,作者们手动为所有数据标注子任务的语义描述,并训练 π0.5 基于当前观察和高级指令联合预测子任务标签(以文本形式)以及动作(以子任务标签为条件)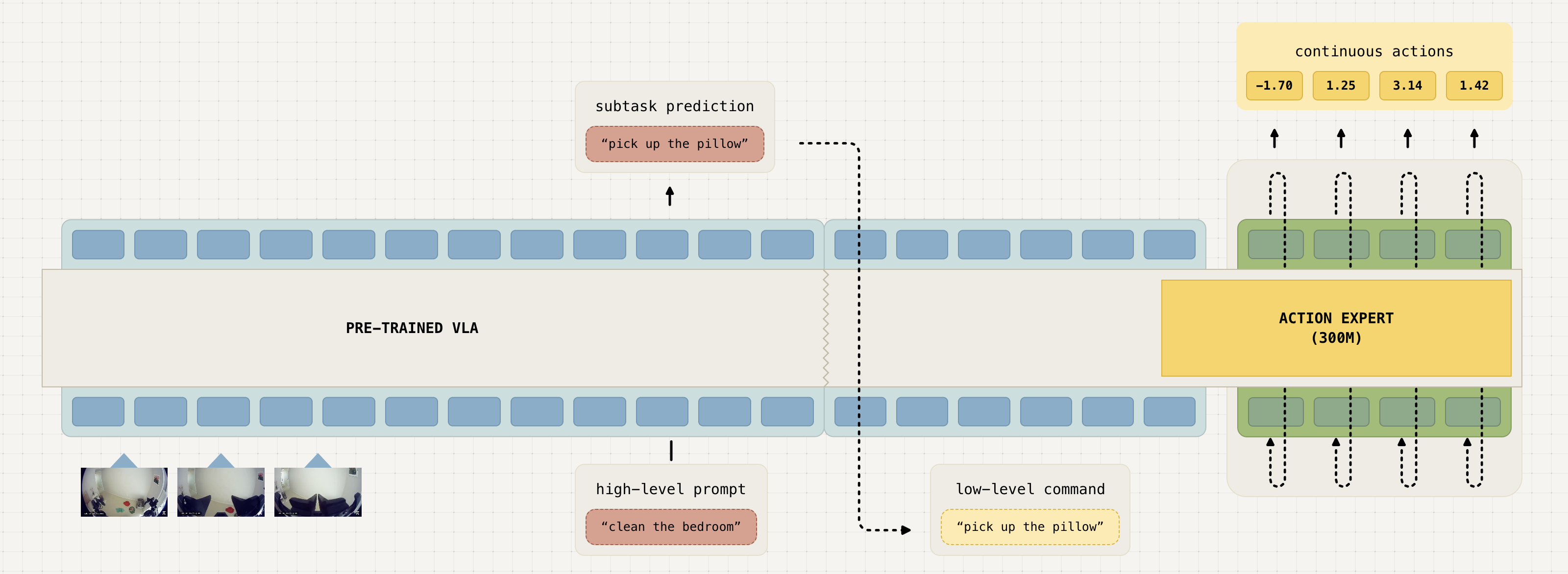
For robot data in MM, ME, and CE where the task involves multiple subtasks, we manuallyannotate all data with semantic descriptions of the subtasks andtrain π0.5 to jointly predict the subtask labels (as text) as well as the actions (conditioned on the subtask label) based on the current observation and high-level command.
这自然会形成一个既能作为高级策略(输出子任务)又能作为低级策略(为这些子任务执行动作)的模型——相当于从高级指令推断出子任务,继而再预测该子任务所对应的动作
且还标注当前观察中显示的相关边界框,并训练 π0.5 在预测子任务之前预测它们 - 多模态网络数据(WD)
即最后,他们包括了一组多样化的网络数据,涉及图像描述「CapsFusion [87], COCO[12])、问答(Cambrian-7M [77], PixMo [19], VQAv2[32]」以及预训练中的目标定位
对于对象定位,他们进一步通过额外的网络数据扩展了标准数据集,这些数据包含带有边界框标注的室内场景和家庭物品
对于所有动作数据,他们训练模型以预测目标关节和末端执行器的姿态。为了区分两者,他们在文本prompt中添加了“<控制模式>关节/末端执行器<控制模式>”
所有动作数据被归一化到[-1,1],使用各个数据集的动作维度的1%和99%分位数。且他们将动作a的维度设置为一个固定值,以适应所有数据集中最大的动作空间。对于具有低维配置和动作空间的机器人,对动作向量进行零填充
1.4.2 后训练:基于动作专家,通过流匹配生成连续动作块
在使用离散token对模型进行 280k 梯度步的预训练后,他们进行第二阶段的训练——称之为后训练
- 此阶段的目的是将模型专门化到作者的用例(家庭中的移动操控),并添加一个动作专家,通过流匹配生成连续动作块
此阶段与下一token预测联合训练,以保留文本预测能力,并为动作专家进行流匹配(该专家在后训练开始时使用随机权重初始化) - 他们优化方程 (1) 中的目标
其中 α=10.0,进行额外的 80k 步训练 - 后训练动作数据集由 MM 和 ME 机器人数据组成,过滤到低于固定长度阈值的成功片段
包括网络数据 (WD) 以保留模型的语义和视觉能力,以及对应于多环境数据集的 HL 数据切片 - 此外,为了提高模型预测恰当高级子任务的能力,他们收集了语言指令演示(VI),这些演示由专家用户通过提供“语言示范”构建而成,即选择合适的子任务指令,逐步指挥机器人执行移动操作任务
这些示例是通过实时用语言“远程操作”机器人来执行任务并结合已学习的低级策略收集的,实质上为训练好的策略提供了良好高级子任务输出的示范
// 待更

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 29
29 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)