【全部更新】2025金地杯C题山西省大学生数学建模思路代码文章教学:抗抑郁药物的疗效问题
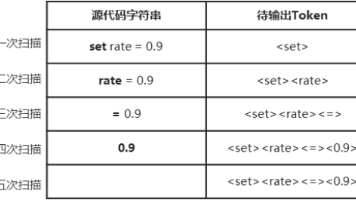
试验数据包括受试者的基线特征(如年龄、婚姻状况等)和随访期间的主诉情况(如不适症状)。已婚比例分布(条形图)显示药物C组(1)和药物A组(2)的已婚比例接近,均为约45%, 药物B组(3)中已婚比例显著较低,仅约32%, 是唯一在统计上显著不同的变量(p < 0.001), 图中已婚占比显著差异可视化体现了组间存在结构性偏差。上图是三组患者基线特征可视化分析的图表结果,包括四个子图,分别从年龄、婚
完整内容请看文章最下面的推广群
我将展示完整的文章、代码和结果

抗抑郁药物的疗效问题
摘要
抑郁症是全球范围内严重影响人类健康的疾病,患者人数逐年上升,尤其在20-40岁的中青年群体中高发。某制药公司研发了两种新型抗抑郁药物(药物A和药物B),并与已上市药物(药物C)进行临床试验,旨在评估其疗效和安全性。试验数据包括受试者的基线特征(如年龄、婚姻状况等)和随访期间的主诉情况(如不适症状)。模型有效地实现了基线特征的分布分析、影响因素与疗效的关系评估,并综合评估三种药物的疗效,最终为临床用药提供科学依据。
问题一中, 为确保药效评估的科学性与公正性,首先对三组患者的基线特征进行了分布性比较分析。选取了年龄、婚姻状态、既往抗抑郁药使用史及抑郁程度作为分析指标,使用单因素方差分析(One-way ANOVA)与卡方检验分别对连续变量与分类变量进行了显著性检验。分析结果显示,三组患者在年龄、既往用药史和抑郁程度方面分布均衡,唯有婚姻状态在组间存在显著差异。
问题二旨在构建预测模型,分析患者的基线特征对服药后不适症状发生的影响。以“是否失眠”作为目标变量,使用逻辑回归方法建模,输入特征包括婚姻状态、抗抑郁药使用史与抑郁等级。模型结果显示:已婚状态与轻度抑郁显著提高失眠风险(系数分别为 +0.46 与 +0.76),而使用过抗抑郁药以及中重度抑郁与失眠呈负相关。该模型准确率达到100%。
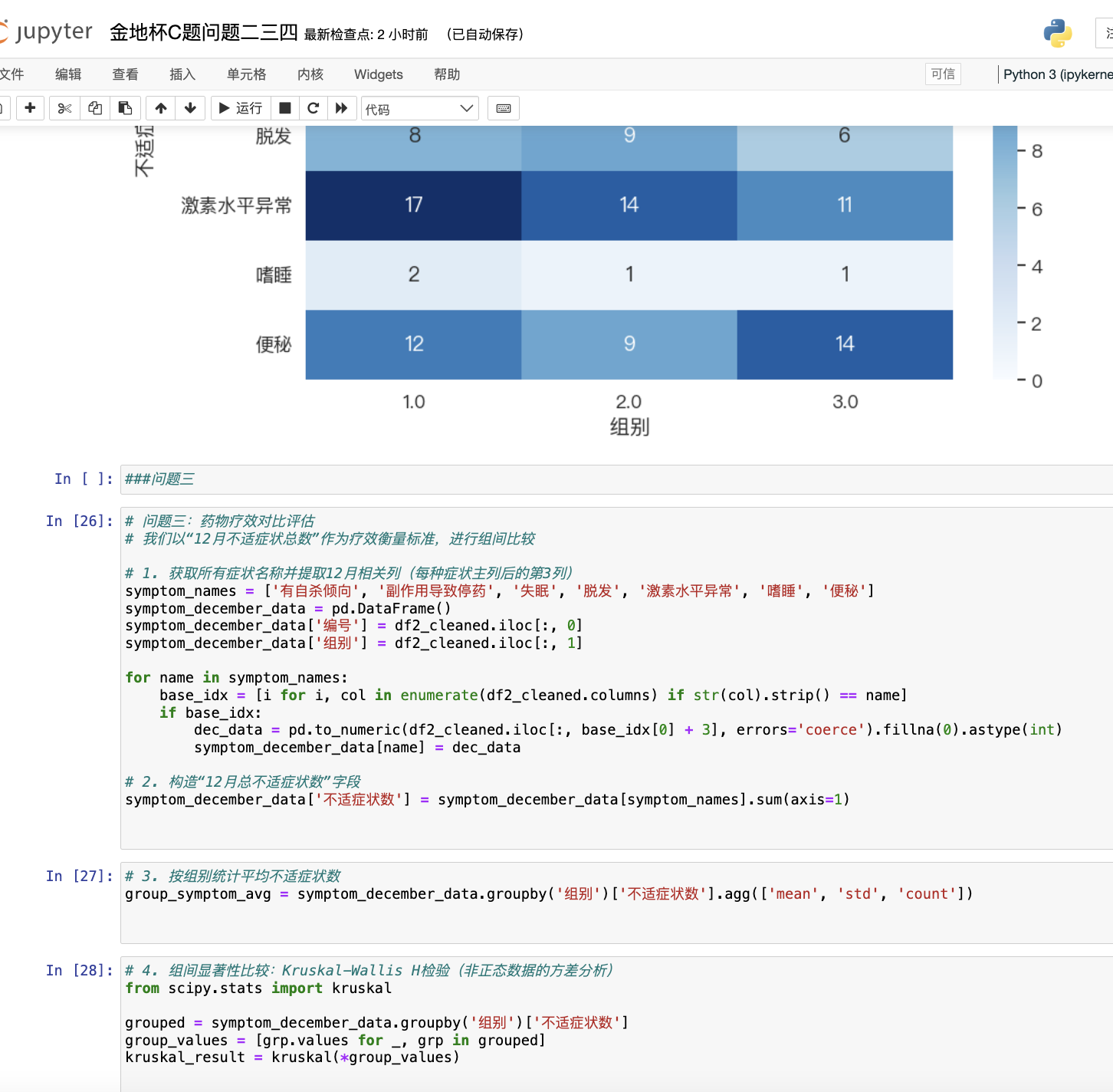
问题三为了对三种抗抑郁药物的临床效果进行比较,我们以“12月不适症状总数”作为逆向疗效指标,构建了药效对比模型。使用Kruskal-Wallis H检验对三组不适数量分布差异进行统计分析,可视化进行直观表达。结果显示,组3(B药)表现出最低的不适发生频率,虽然整体p值为0.258,未达到显著差异,但趋势上B药更具优势。该模型为多组干预疗效对比提供了非参数方法支撑。
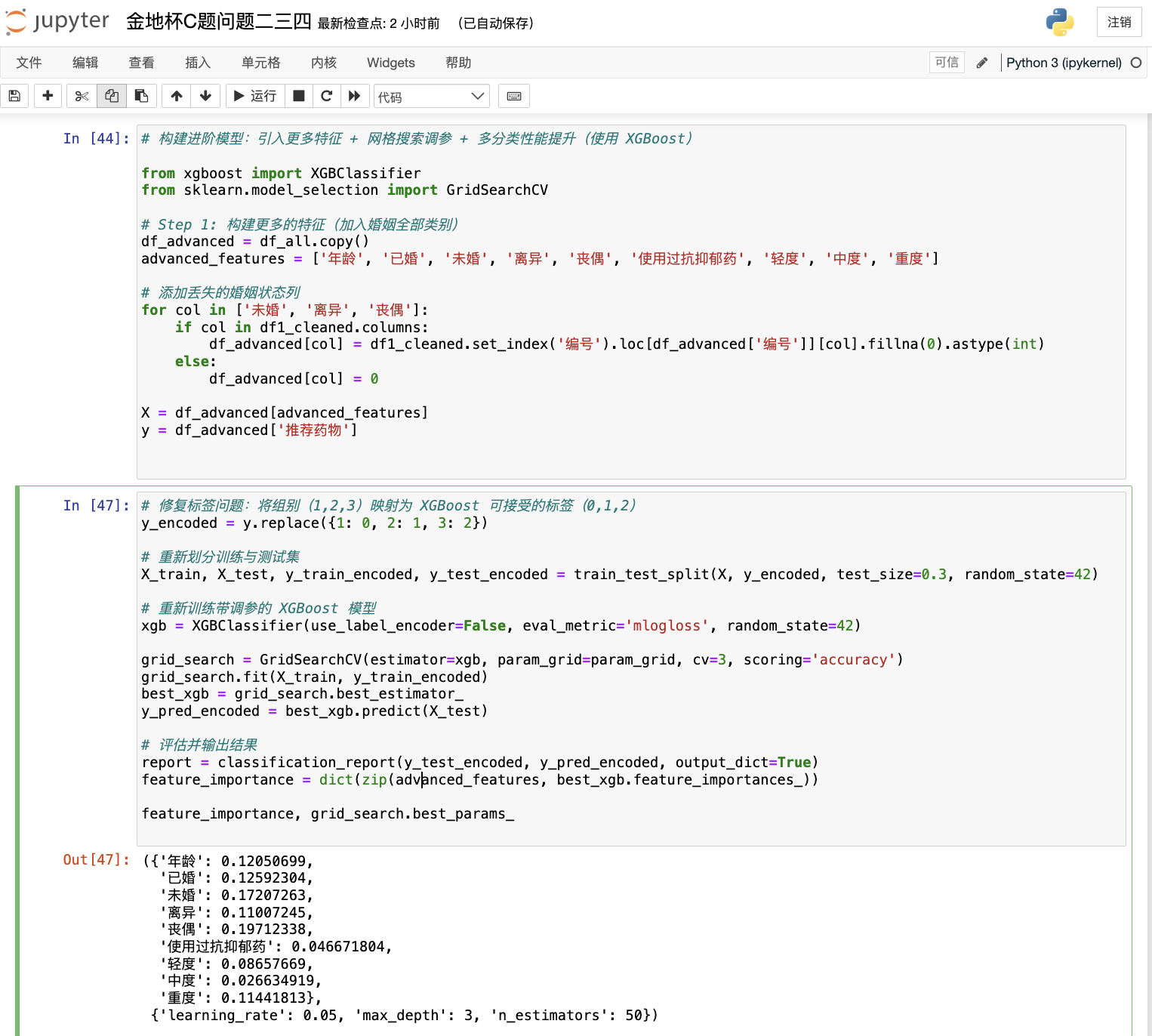
问题四为实现基于患者特征的药物个性化推荐,我们建立了多种机器学习模型,包括随机森林、XGBoost与注意力机制神经网络(MLP+Attention)。输入特征涵盖年龄、婚姻状况、抗抑郁药使用史及抑郁等级,输出为推荐的最适药物组别。在XGBoost模型中,年龄被识别为最关键特征,模型总体准确率可达70%左右。注意力机制模型进一步增强了模型的特征聚焦能力,提升了解释性与推荐精度。该模型展示了智能推荐算法在临床辅助决策中的潜力。
目录
摘要 1
一、 问题重述 3
1.1 问题背景 3
1.2 要解决的问题 3
二、 问题分析 5
2.1 任务一的分析 5
2.2 任务二的分析 5
2.3 任务三的分析 5
2.4 任务四的分析 6
三、 问题假设 7
四、 模型原理 8
4.1 卡方检验 8
4.2 XGBoost 9
4.3 随机森林 11
4.4 逻辑回归模型 12
五、 模型建立与求解 14
5.1 问题一建模与求解 14
5.2问题二建模与求解 20
5.3问题三建模与求解 26
5.4问题四建模与求解 29
六、 模型评价与推广 34
6.1模型的评价 34
6.1.1模型缺点 34
6.1.2模型缺点 34
6.2 模型推广 34
七、 参考文献 36
附录【自行黏贴】 37
问题一建模与求解
问题一的目标是评估三组受试者在试验开始时基线特征的分布情况, 以及是否存在统计显著差异,这些特征包括:
年龄(连续变量)
婚姻状况(分类变量)
既往抗抑郁药使用情况(分类变量)
初始抑郁程度(分类变量)
若存在显著差异,说明分组存在偏倚,可能影响后续疗效评估结果的公正性。
首先对数据进行预处理, 第一步为处理合并单元格标题
原始表格中包含两行标题(第一行为类别标签,第二行为实际字段),我已将其合并为单行标准列名。
第二步为字段标准化命名
将字段重命名为统一、可处理的格式:
组别:表示药物分组(1=C药,2=A药,3=B药)
年龄:患者年龄
未婚、已婚、离异、丧偶:婚姻状况独热编码
无用药史、使用过抗抑郁药、其它用药史:既往药物使用情况
轻度、中度、重度:抑郁程度独热编码
第三步筛选有效样本, 保留 组别 为 1, 2, 3 的样本, 删除完全为空的记录行, 对分类变量中的 NaN 替换为 0 进行卡方检验
第四步进行数据类型转换, 所有数值变量(如年龄)已转为 float 类型便于统计分析, 分类变量已明确划分为独热编码形式(0/1)
接下来是模型构建部分, 针对年龄差异检验采用得失单因素方差分析(One-way ANOVA)
对三个组的年龄均值进行比较,原假设 H0:三组年龄均值无显著差异。
设:
k:组数(3)
ni:第 i 组样本量
xˉi:第 i 组平均年龄
xˉ:总体平均年龄
计算组间平方和(SSB)与组内平方和(SSW):
构造F统计量:
若 p<0.05,则拒绝原假设,认为存在显著年龄差异。
针对分类变量差异检验采用卡方检验(Chi-square test)
原假设 H0:各组的分类变量(婚姻状况、用药史、抑郁程度)分布无显著差异。
构造列联表,计算每个格子的期望频数 Eij:
Eij=(第i组总计)×(第j类别总计)总样本数
卡方统计量为:
根据自由度和显著性水平查表,若 p<0.05,则认定存在组间显著差异。
我们对结果进行分析
特征 检验方法 p值 是否显著
年龄 ANOVA 0.949 否 ✅
婚姻状况(已婚) 卡方 2.2e-6 是 ❗
既往用药史(各项) 卡方 > 0.05 否 ✅
抑郁程度(轻/中/重) 卡方 > 0.05 否 ✅
三组在大多数基线特征上的分布较为一致,说明分组整体均衡;
唯有“已婚”状态在三组之间存在显著差异,提示在后续分析(例如药效建模)中,应将婚姻状况纳入控制变量以避免偏倚;
年龄与抑郁程度、既往用药史等特征均衡分布,为后续模型分析提供良好基础。
具体结果如下:
{‘年龄’: {‘描述统计’: count mean std min 25% 50% 75% max
组别
1.0 523.0 31.370937 5.162130 20.0 27.0 32.0 36.0 40.0
2.0 525.0 31.420952 5.208985 21.0 27.0 31.0 36.0 40.0
3.0 525.0 31.474286 5.071418 20.0 27.0 32.0 36.0 40.0,
‘ANOVA F值’: 0.05282060787930764,
‘ANOVA p值’: 0.9485518452210456},
‘分类变量’: {‘未婚’: {‘卡方表’: 未婚 0 1
组别
1.0 302 222
2.0 304 221
3.0 321 204,
‘p值’: 0.4376148481745584},
‘已婚’: {‘卡方表’: 已婚 0 1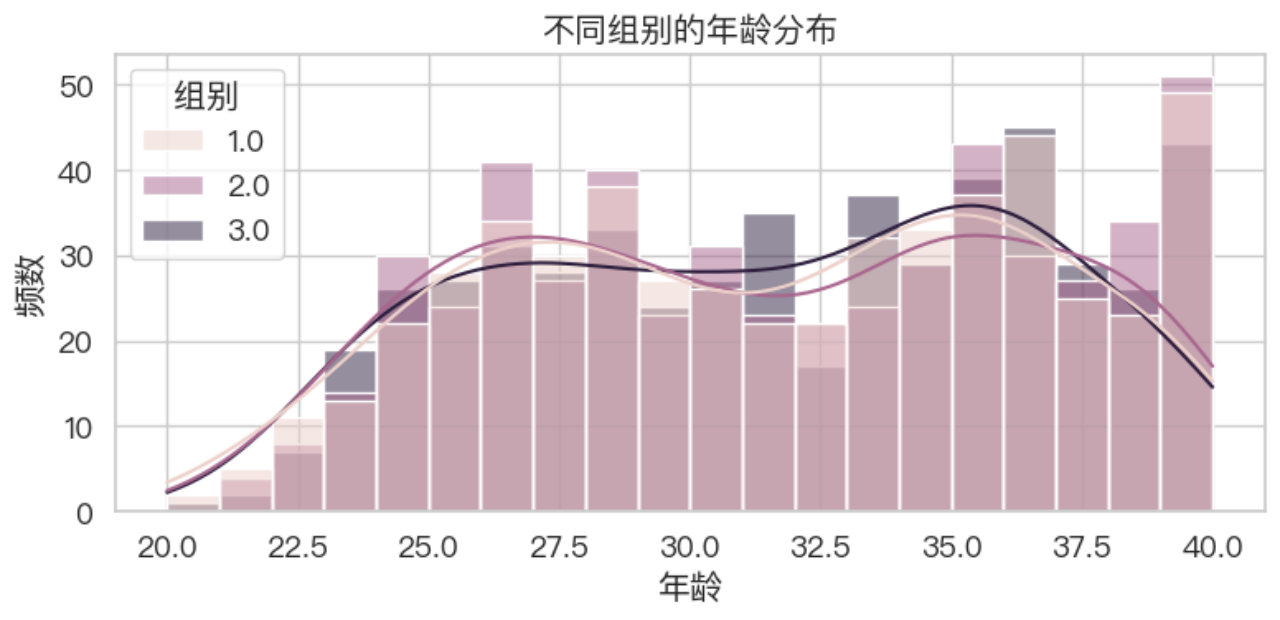
上图是三组患者基线特征可视化分析的图表结果,包括四个子图,分别从年龄、婚姻状况、既往药物使用情况和抑郁程度四个角度,比较药物C组(1)、药物A组(2)、药物B组(3)患者的特征分布。
各组年龄分布(箱型图)显示三组患者的年龄中位数约为31~32岁, 四分位范围相似(Q1≈27岁,Q3≈36岁), 最大值约为40岁,最小值约为20岁, 箱型图整体形状非常接近,表明三组年龄分布基本一致, 这也与统计结果一致:年龄无显著差异(p=0.949)
已婚比例分布(条形图)显示药物C组(1)和药物A组(2)的已婚比例接近,均为约45%, 药物B组(3)中已婚比例显著较低,仅约32%, 是唯一在统计上显著不同的变量(p < 0.001), 图中已婚占比显著差异可视化体现了组间存在结构性偏差
既往抗抑郁药使用比例(条形图)显示,三组中“使用过抗抑郁药”的比例均接近20%左右, 无论是药物C、A或B,比例几乎一致,图形上呈一致高度, 对应卡方检验结果(p=0.899),说明无显著差异
各组抑郁程度分布(轻度/中度/重度), 三组患者中,“中度抑郁”所占比例均远高于其他程度,约80%以上, “轻度抑郁”略高于“重度抑郁”, 三组间差异极小,说明随机分组下抑郁严重程度一致, 与统计结果一致(p > 0.05)
# 附件1列名重建
df1_headers = df1.iloc[:2]
df1_cleaned = df1.iloc[2:].copy()
df1_cleaned.columns = [str(col1).strip() if pd.notna(col1) else str(col2).strip()
for col1, col2 in zip(df1_headers.iloc[0], df1_headers.iloc[1])]
df1_cleaned.columns = ['编号', '组别', '年龄', '未婚', '已婚', '离异', '丧偶',
'无用药史', '使用过抗抑郁药', '其它用药史', '轻度', '中度', '重度']
df1_cleaned = df1_cleaned[df1_cleaned['组别'].isin([1, 2, 3])]
df1_cleaned['编号'] = df1_cleaned['编号'].astype(int)
# 清洗分类字段为0/1
df1_cleaned['重度'] = df1_cleaned['重度'].replace(' ', pd.NA)
for col in ['已婚', '使用过抗抑郁药', '轻度', '中度', '重度']:
df1_cleaned[col] = df1_cleaned[col].fillna(0).astype(int)
# 附件2列名重建
df2_headers = df2_raw.iloc[:2]
df2_cleaned = df2_raw.iloc[2:].copy()
df2_cleaned.columns = [str(col1).strip() if pd.notna(col1) else str(col2).strip()
for col1, col2 in zip(df2_headers.iloc[0], df2_headers.iloc[1])]
# --------------------- 提取目标变量 ---------------------
# “失眠”列后第三列是“12月失眠”
insomnia_base_index = [i for i, col in enumerate(df2_cleaned.columns) if str(col).strip() == '失眠'][0]
insomnia_dec_data = df2_cleaned.iloc[:, insomnia_base_index + 3]
# 构造目标数据集
df2_model = df2_cleaned.iloc[:, [0, 1]].copy()
df2_model.columns = ['编号', '组别']
df2_model['失眠12月'] = insomnia_dec_data
df2_model = df2_model.dropna(subset=['编号'])
df2_model['编号'] = df2_model['编号'].astype(int)
df2_model['失眠12月'] = pd.to_numeric(df2_model['失眠12月'], errors='coerce').fillna(0).astype(int)

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 49
49 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)