5分钟上手Coze插件开发,利用阿里云大模型实现精准图图像理解
当你为Coze平台插件调用付费时,是否想过:那些看似神秘的插件开发,实则只需一杯咖啡的时间就能自主实现?本文将颠覆您对AI插件开发的认知——无需机器学习背景,不必研究复杂算法,以阿里云百炼大模型为基座,带你用5分钟完成一个专业级图像识别插件的开发全流程
作者:后端小肥肠
🍊 有疑问可私信或评论区联系我。
🥑 创作不易未经允许严禁转载。
姊妹篇:
目录
1. 前言
当你为Coze平台插件调用付费时,是否想过:那些看似神秘的插件开发,实则只需一杯咖啡的时间就能自主实现?本文将颠覆您对AI插件开发的认知——无需机器学习背景,不必研究复杂算法,以阿里云百炼大模型为基座,带你用5分钟完成一个专业级图像识别插件的开发全流程。
在接下来的实战中,你将亲历从模型选型、代码编写到服务部署的完整闭环。即使你是首次接触大模型开发的工程师,也能轻松完成Coze插件开发。文末更附赠提示词工程秘籍,助你突破大模型应用效果天花板。
当你成功部署第一个自研插件时,或许会惊叹:原来插件开发 so easy~。
2. 基于阿里云百炼大模型编写图像识别插件实战
2.1. 寻找合适的大模型
在进行图像识别插件的开发前,第一步是选择适合的基础模型。在阿里云百炼模型广场中(访问模型广场),可以找到各种类型的大模型,这些模型根据不同的任务需求分类,包括图像理解、文本生成、语音识别等。对于本次任务,我选择了支持图像内容理解的 qwen-vl-plus 模型。
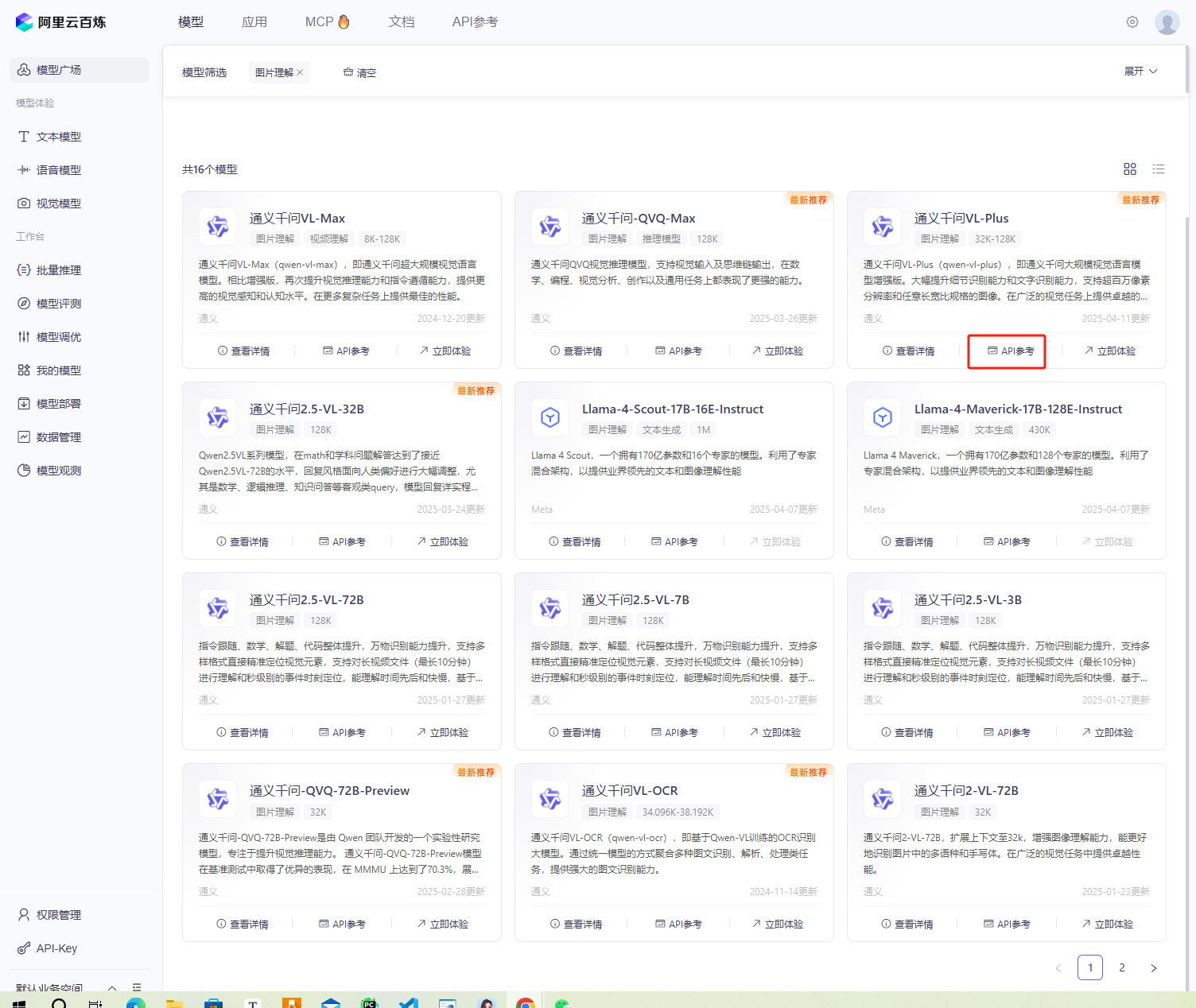
点击 API参考 按钮,进入模型的使用文档页面。这份文档详细描述了如何调用模型,包括所需的参数信息以及具体的调用格式:
- model 参数:指定要调用的模型名称(这里是
qwen-vl-plus)。 - messages 参数:用于传递消息列表,包含与模型交互的历史对话记录。
- User Message:表示用户发送给模型的具体消息内容,包括文本和图像的URL。
2.2. Coze新建插件
为了将模型功能封装为一个易用的插件,我们需要在 Coze 平台上新建插件,选择任意空间(可以是个人空间或者你自己任意新建的),点击新建插件:
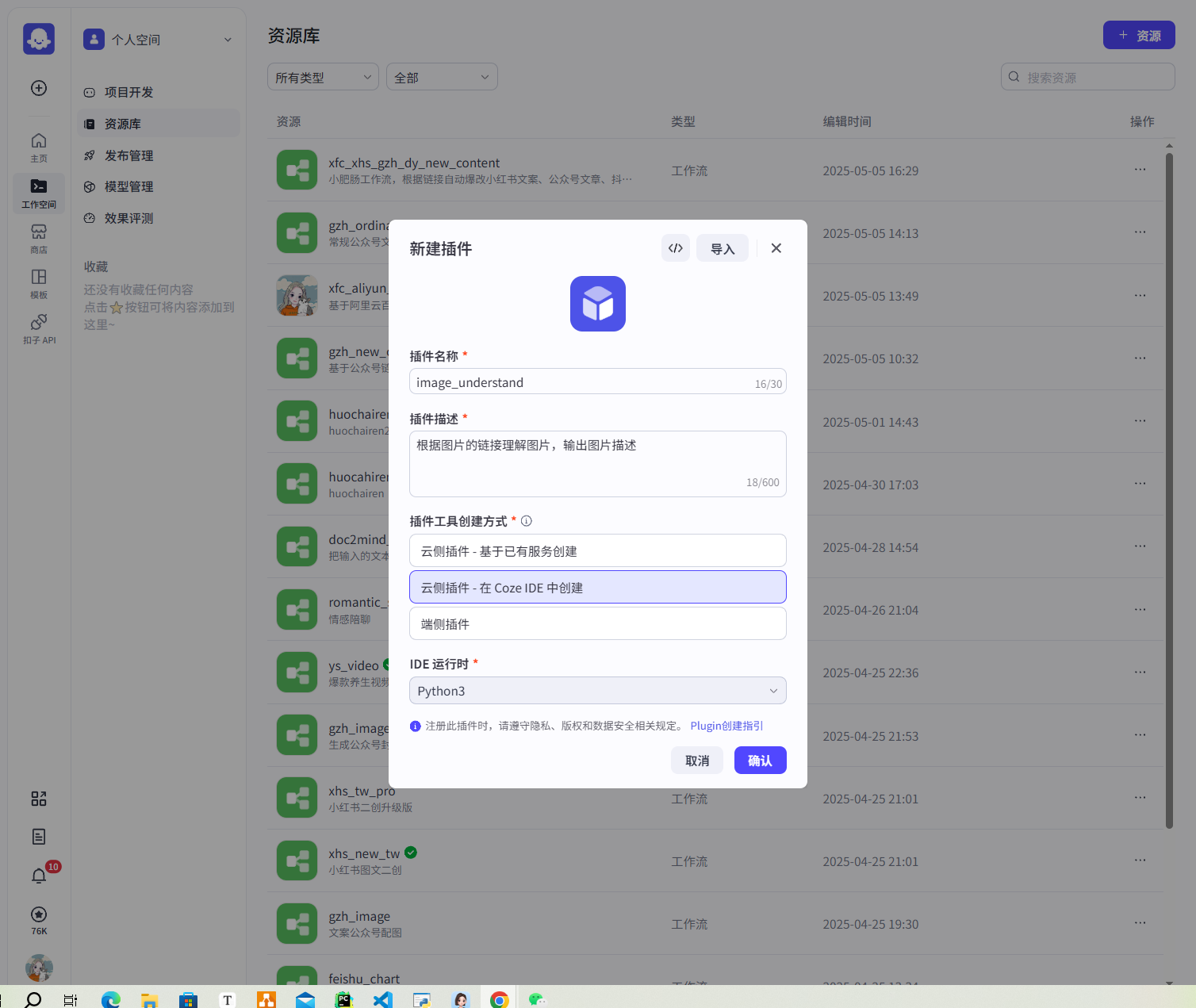
创建完插件以后还需要创建工具,这里可以写成一样(插件和工具的关系,你可以理解为工具是插件的子集):
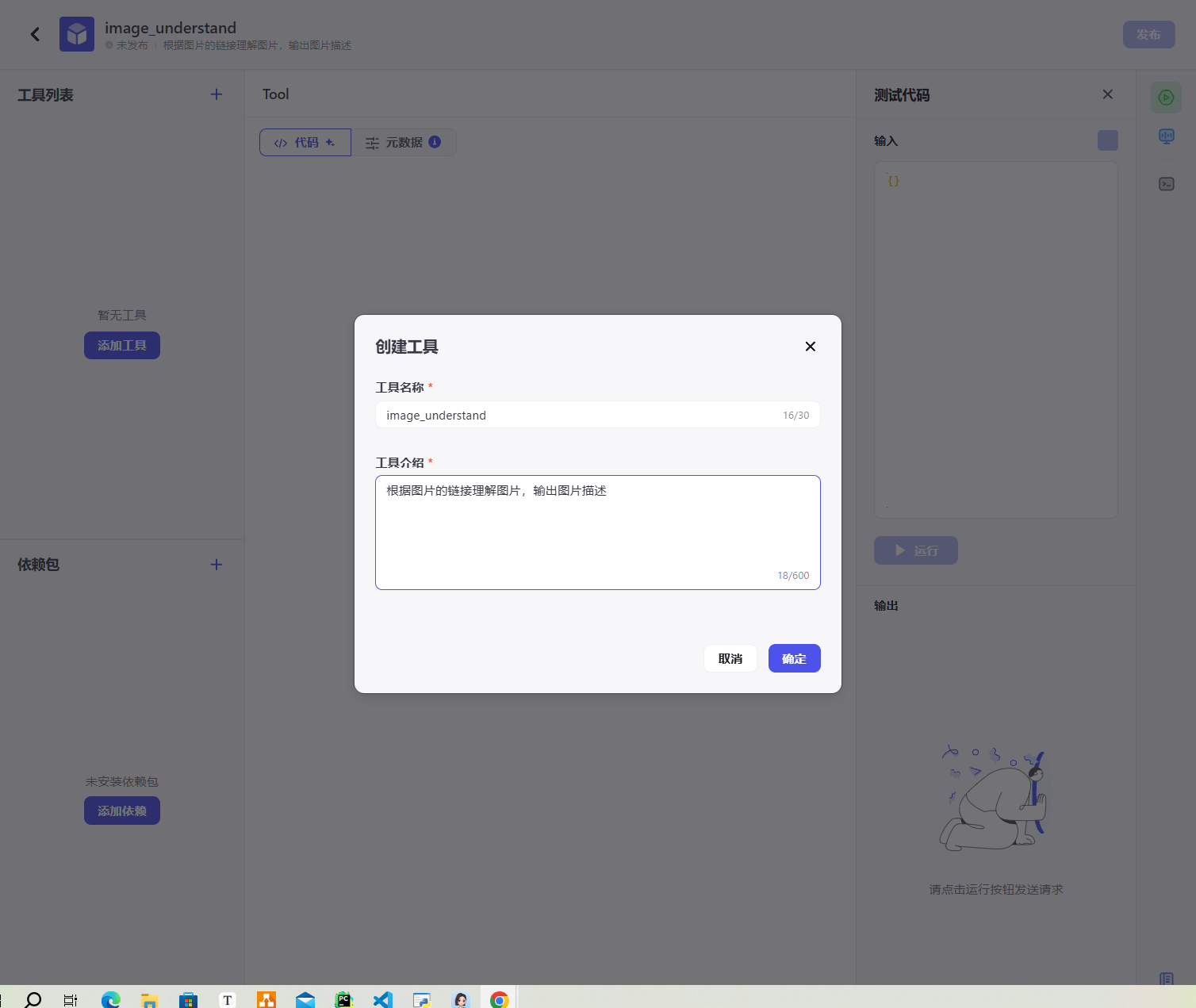
2.3. 编写插件代码
完成工具构建后,我们就可以进行插件代码编写了:
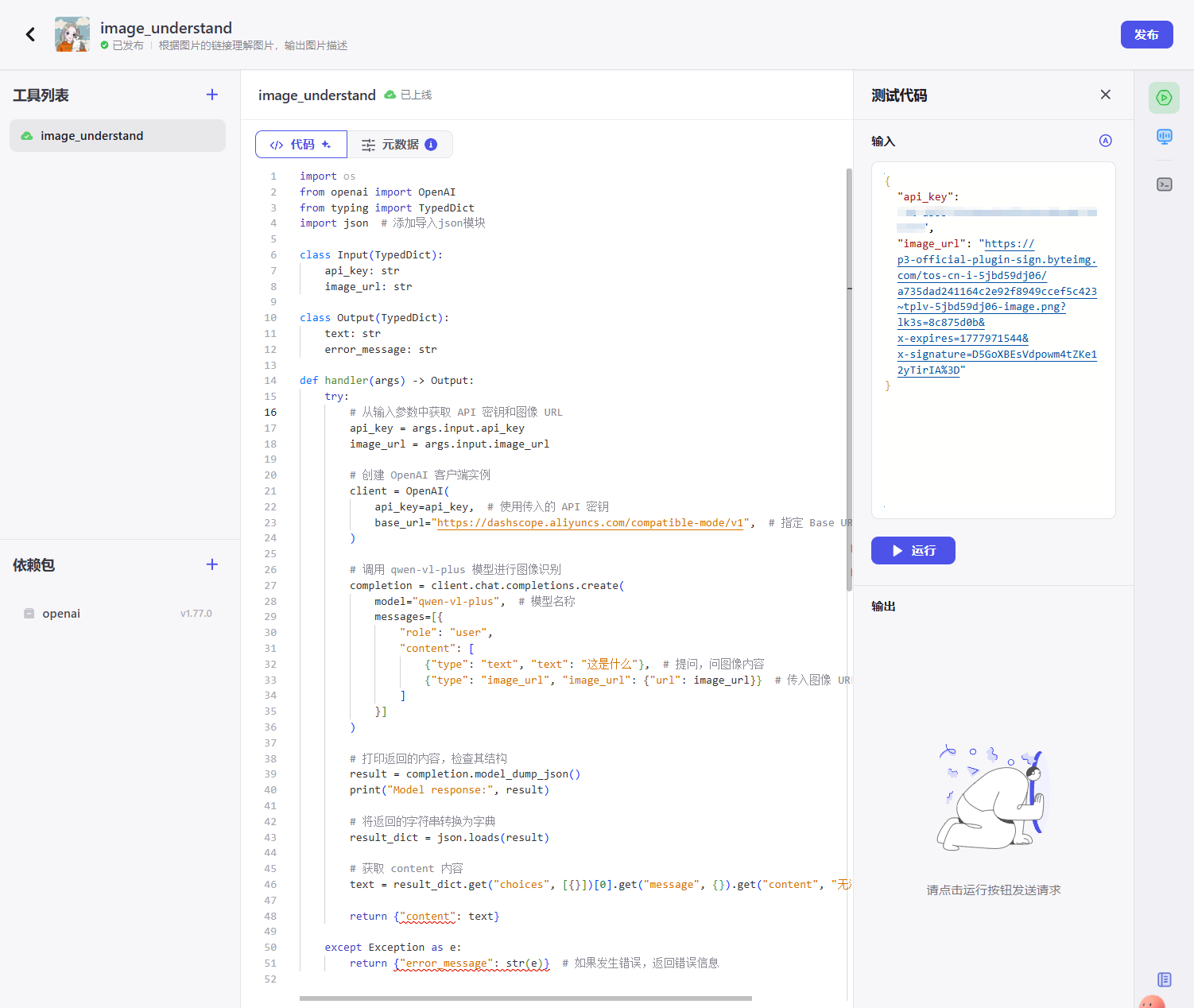
代码详情:
import os
from openai import OpenAI
from typing import TypedDict
import json # 添加导入json模块
class Input(TypedDict):
api_key: str
image_url: str
class Output(TypedDict):
text: str
error_message: str
def handler(args) -> Output:
try:
# 从输入参数中获取 API 密钥和图像 URL
api_key = args.input.api_key
image_url = args.input.image_url
# 创建 OpenAI 客户端实例
client = OpenAI(
api_key=api_key, # 使用传入的 API 密钥
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 指定 Base URL
)
# 调用 qwen-vl-plus 模型进行图像识别
completion = client.chat.completions.create(
model="qwen-vl-plus", # 模型名称
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "这是什么"}, # 提问,问图像内容
{"type": "image_url", "image_url": {"url": image_url}} # 传入图像 URL
]
}]
)
# 打印返回的内容,检查其结构
result = completion.model_dump_json()
print("Model response:", result)
# 将返回的字符串转换为字典
result_dict = json.loads(result)
# 获取 content 内容
text = result_dict.get("choices", [{}])[0].get("message", {}).get("content", "无法获取识别结果")
return {"content": text}
except Exception as e:
return {"error_message": str(e)} # 如果发生错误,返回错误信息上述代码调用了阿里云百炼平台的 qwen-vl-plus 模型,识别传入图片的内容,并返回识别到的文字说明。总的来说做了以下几件事:
- 从输入参数中提取 API 密钥和图像 URL;
- 使用这些参数创建 OpenAI 客户端,指定使用阿里云的兼容 API 地址;
- 调用
qwen-vl-plus图像识别模型,请求包含一段文本“这是什么”和用户提供的图像; - 将模型返回的 JSON 字符串解析成 Python 字典;
- 从返回结果中提取模型的回答内容(即
message.content)作为识别文本; - 如果一切正常,返回识别出的内容;如发生错误,则返回错误信息。
2.4. 元数据设置
编写完代码需要设置一下元数据信息(输入的参数信息):
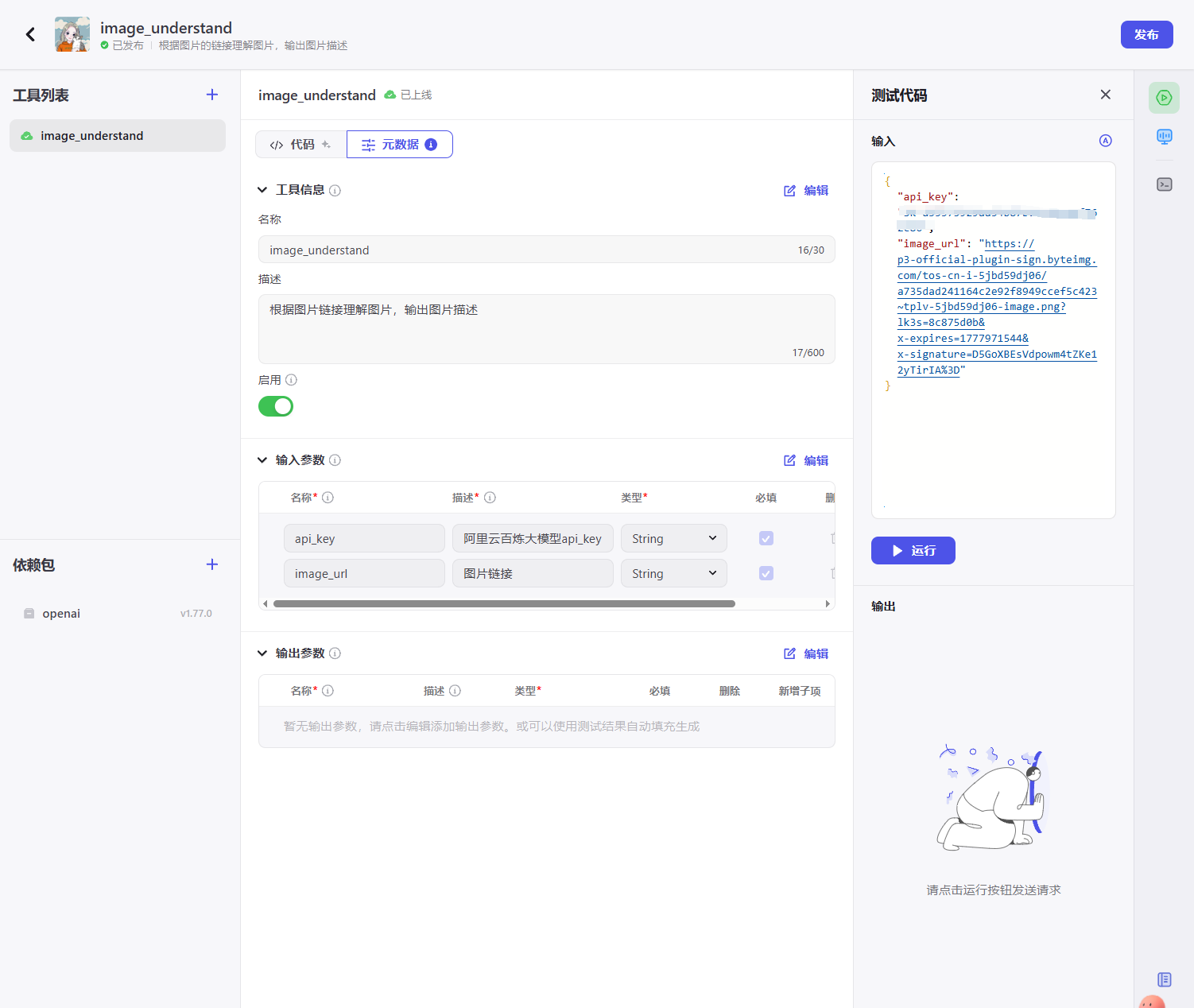
设置完元数据,在测试代码中输入测试数据就能进行插件测试了:
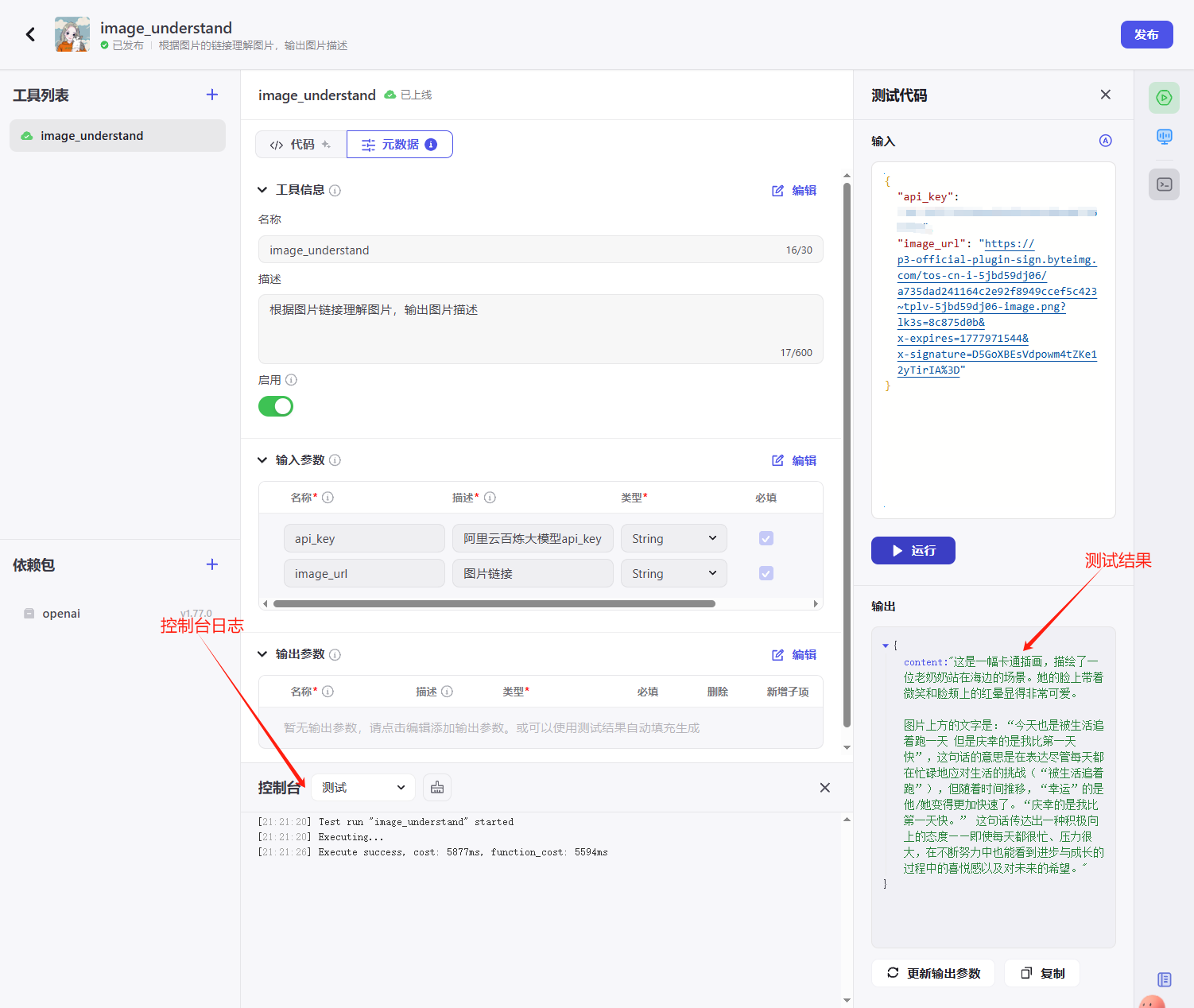
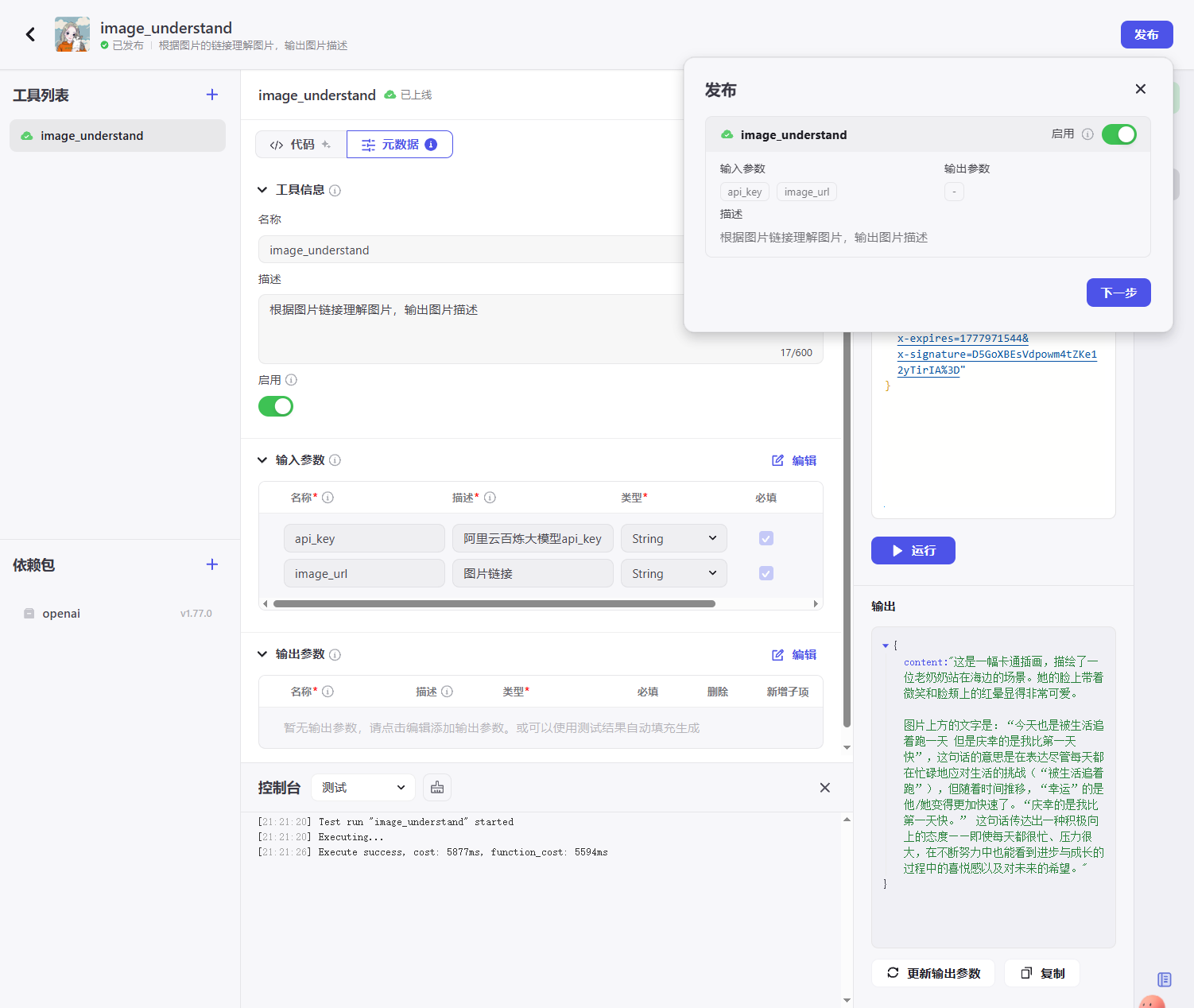
2.5. 插件发布
当我们测试了插件没问题后就能对插件进行发布了,点击右上角发布按钮就能对插件进行发布操作,发布后的插件可以在本空间内使用:
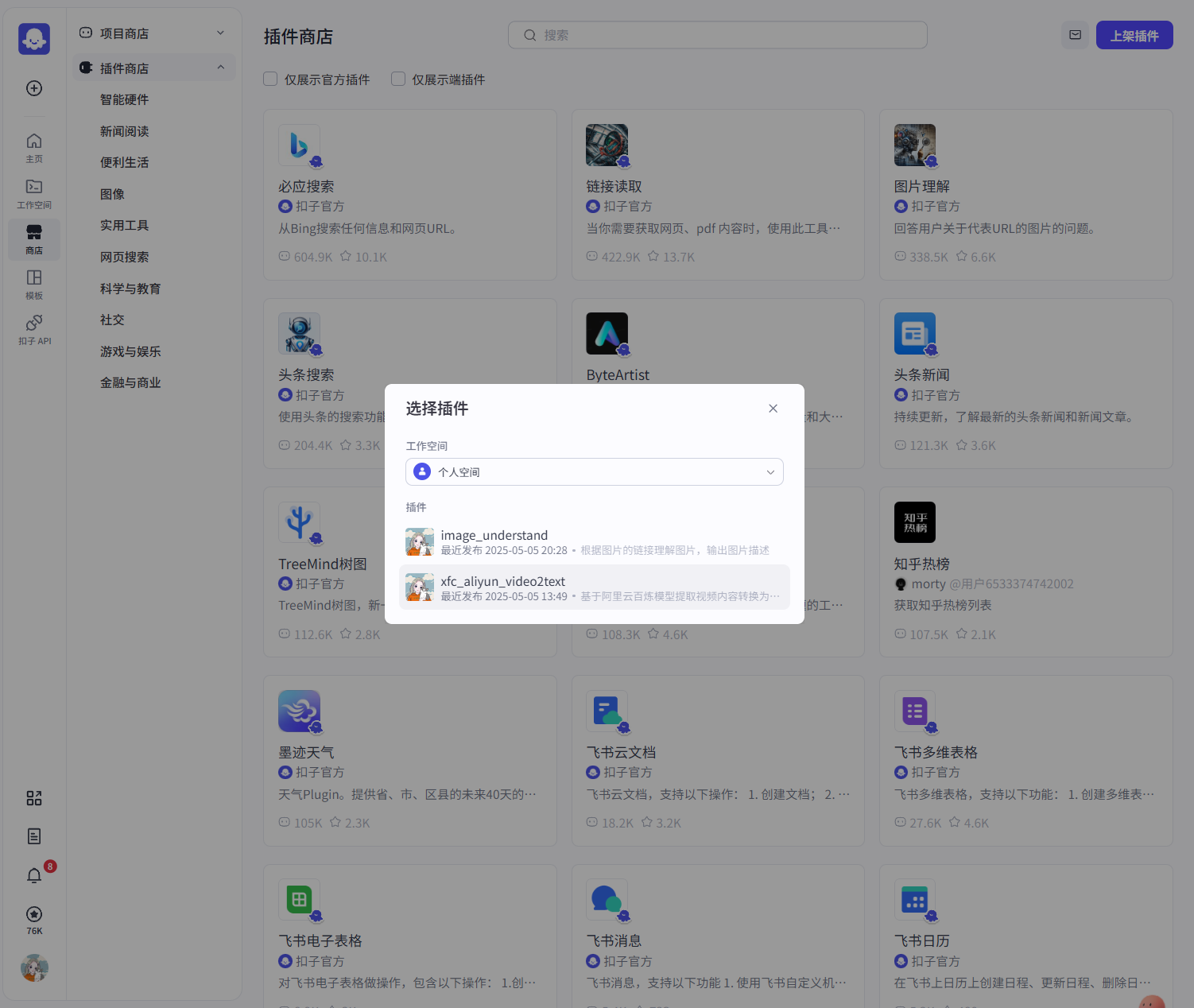
如果要让别人可以使用你的插件,可以在插件商店上架你的插件,操作很简单,就不演示了:
3. 资料领取
你觉得大模型不好用,可能是你不会写提示词,小肥肠为你准备了海量提示词模板和DeepSeek相关教程,只需关注gzh后端小肥肠,点击底部【资源】菜单即可领取。
4. 结语
通过本文的实战演示,相信你已经感受到:插件开发并非高不可攀,借助阿里云百炼大模型和Coze平台,即使零基础也能快速上手,开发出高质量的图像识别插件。掌握这一技能,不仅能够节省昂贵的API调用成本,更是迈向AI原生应用开发的重要一步。
现在,轮到你亲自实践了。放下犹豫,打开Coze,写下你的第一行代码,属于你的AI插件时代,从此刻启航!
如果本文对你有帮助,请动动小手点点关注哦~小肥肠将持续更新AI相关干货知识和好用工具。


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 45
45 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)