【从零开始学习RabbitMQ | 第二篇】生成交换机到MQ的可靠性保障
这是我在学习rabbitMQ所进行的记录,这章我主要学习了RabbitMQ的交换机生成,以及如何保障我们消息队列MQ的安全性,本文章所借鉴的图片主要为黑马视频,主要文章学习来自csdn,b站等。在学习一门新技术的过程中,我们要先会使用,从整体上去大概了解这门技术,然后我们再抽丝剥茧的去学习,这样不仅会让我们有学习全局观,还会更能理解使用场景,事半功倍。交换机什么时候会有这样子的需求呢:就比如我们在
目录
 前言
前言
这是我在学习rabbitMQ所进行的记录,这章我主要学习了RabbitMQ的交换机生成,以及如何保障我们消息队列MQ的安全性,本文章所借鉴的图片主要为黑马视频,主要文章学习来自csdn,b站等。在学习一门新技术的过程中,我们要先会使用,从整体上去大概了解这门技术,然后我们再抽丝剥茧的去学习,这样不仅会让我们有学习全局观,还会更能理解使用场景,事半功倍。
交换机
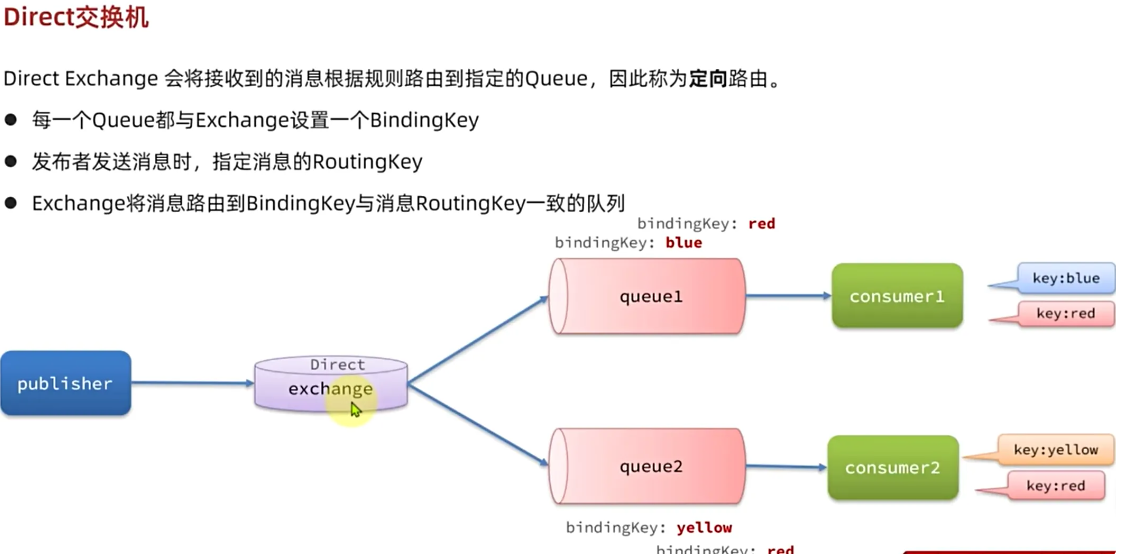
什么时候会有这样子的需求呢:就比如我们在电商项目中,用户下单玩去支付,并且支付成功,我们就可以去异步通知我们的交易服务,积分服务等等。但是如果取消订单那么我们就不用发送给通知服务,积分服务了,这时候就用到了定向路由
Direct交换机与Fanout交换机的差异
- anout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同RoutingKey,则与Fanout功能类似
Topic交换机
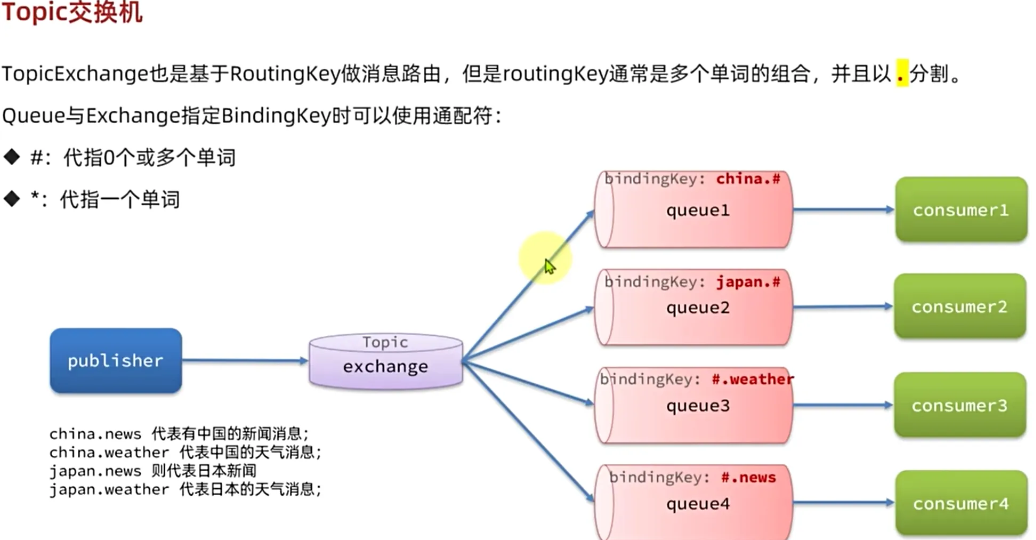
Topic交换机相比Direct交换机的差异
- Topic的RoutingKey和bindingKey可以是多个单词,以.分割
- Topic交换机与队列绑定时的bindingKey可以指定通配符
- #:代表0个或多个词
- *:代表1个词
可以使用通配符,routingkey和bindingkey可以多个单词
就比如写两个bindingkey,china.#,和#.news,再对应绑定两个队列,这时候发送routingkey,china.news就所有绑定队列都可以收到
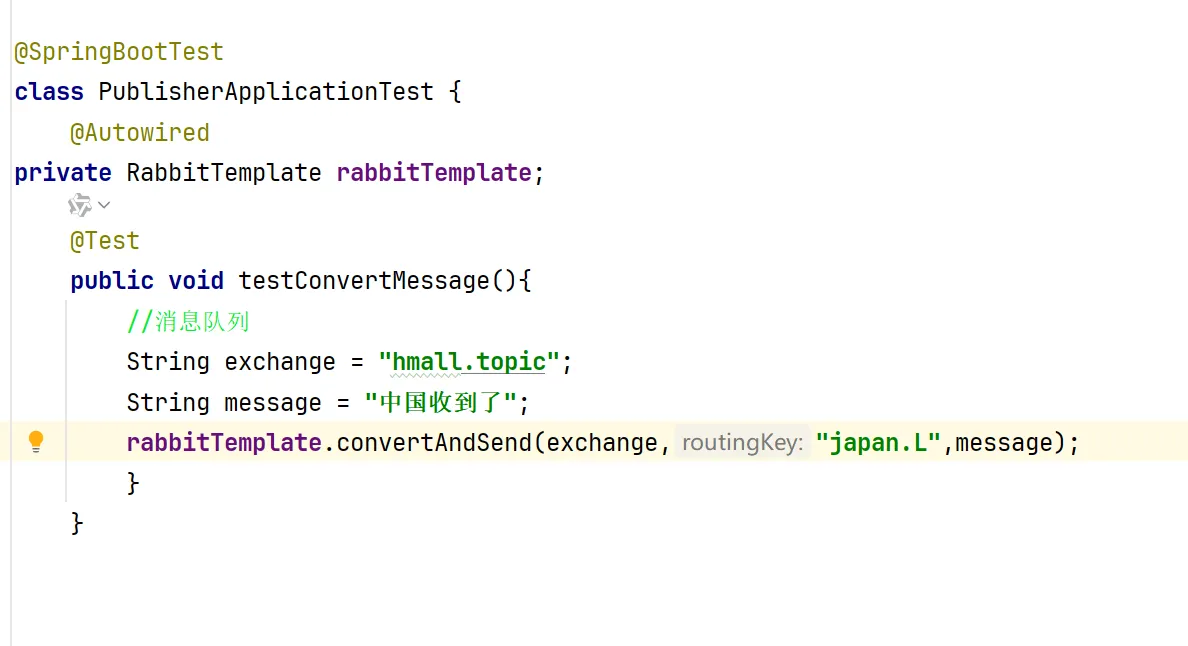
生成我们的交换机,队列,以及绑定关系
基于代码去生成交换机和队列
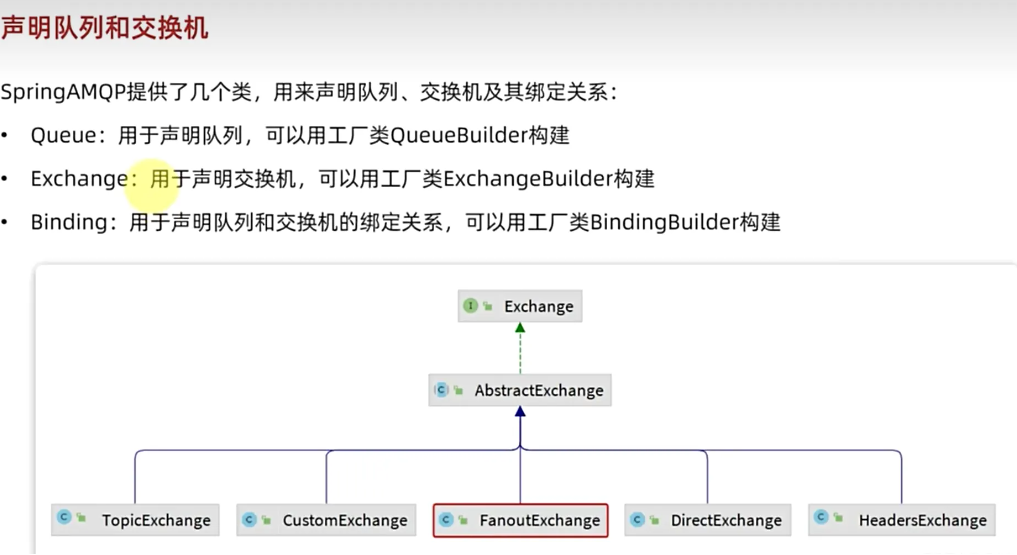
通过工厂类去构建我们的队列,交换机,以及我们的绑定关系。当然交换机和队列也可以使用new的方法,很多人说通过注解更加方便,就不去学习我们根据bean的方法生成交换机,队列,和绑定关系了,但是其实后面无论是我们自己生成私信交换机需要使用,在引入延时插件和lazyqueue的时候我们也需要去主动声明。

基于注解去声明队列和交换机
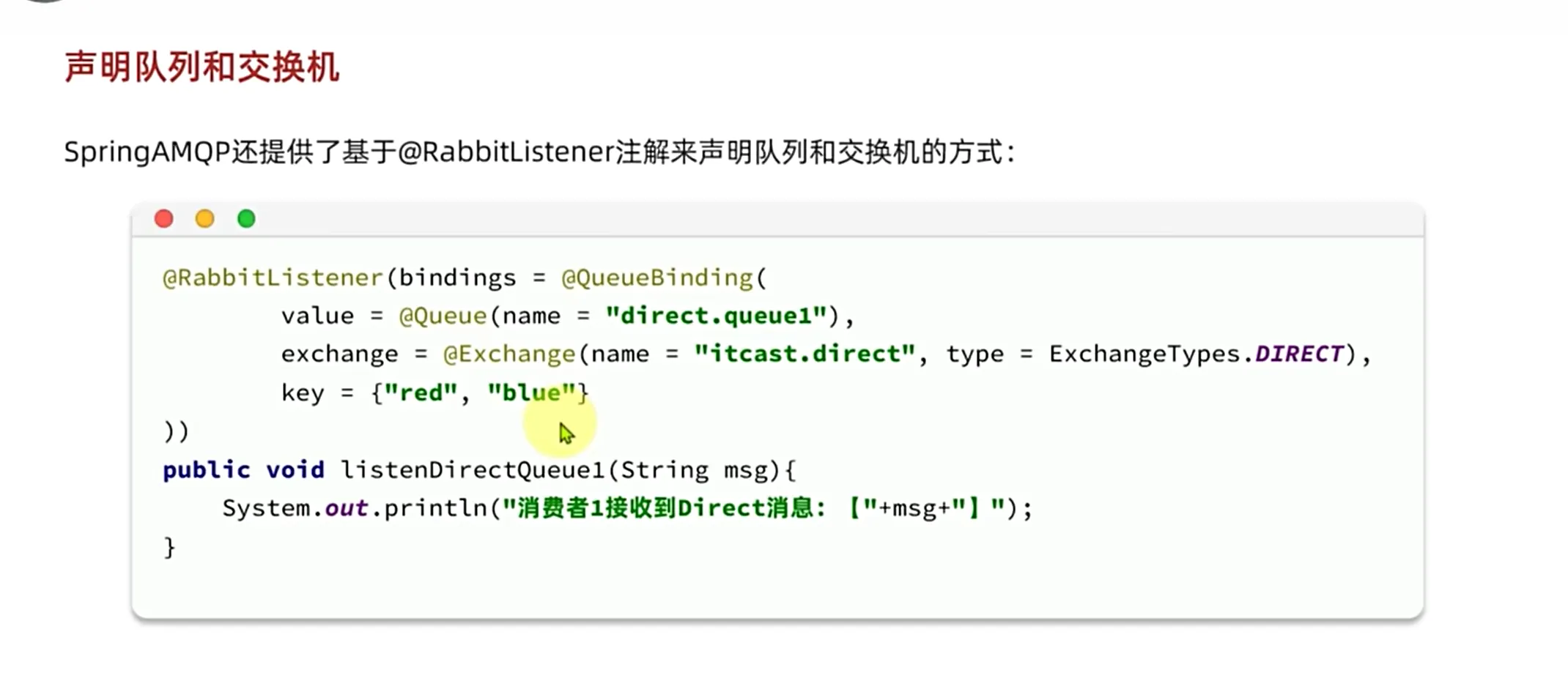
消息转换器
对消息对象的默认处理是由jdk的序列化实现的
Spring的对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter来处理的。而
默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化。
存在下列问题:
- JDK的序列化有安全风险
- JDK序列化的消息太大
- JDK序列化的消息可读性差,太长了很难去读
推荐使用json序列化,万物难读用Json,Json真是java的最好伙伴呀
引入依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
再consumer和publisher里面都要去配置我们的消息转换器
@Bean
public MessageConverter messageConverter(){
return new Jackson2JsonMessageConverter();}
消息队列的高可靠性
终于来到我们的消息队列高级可靠性篇章了,这一次我们将用多种机制去保障我们的消息队列可靠性,守护甚多,从发送者,接收者,mq本身,构建出了一套高安全性的mq机制
使用消息队列进行异步操作,可能出现的安全问题,主要来自于我们的发送者出现问题,消息队列出现安全问题,消费者出现安全问题
我们要学的就是如何使用mq去实现我们异步操作的高可靠性
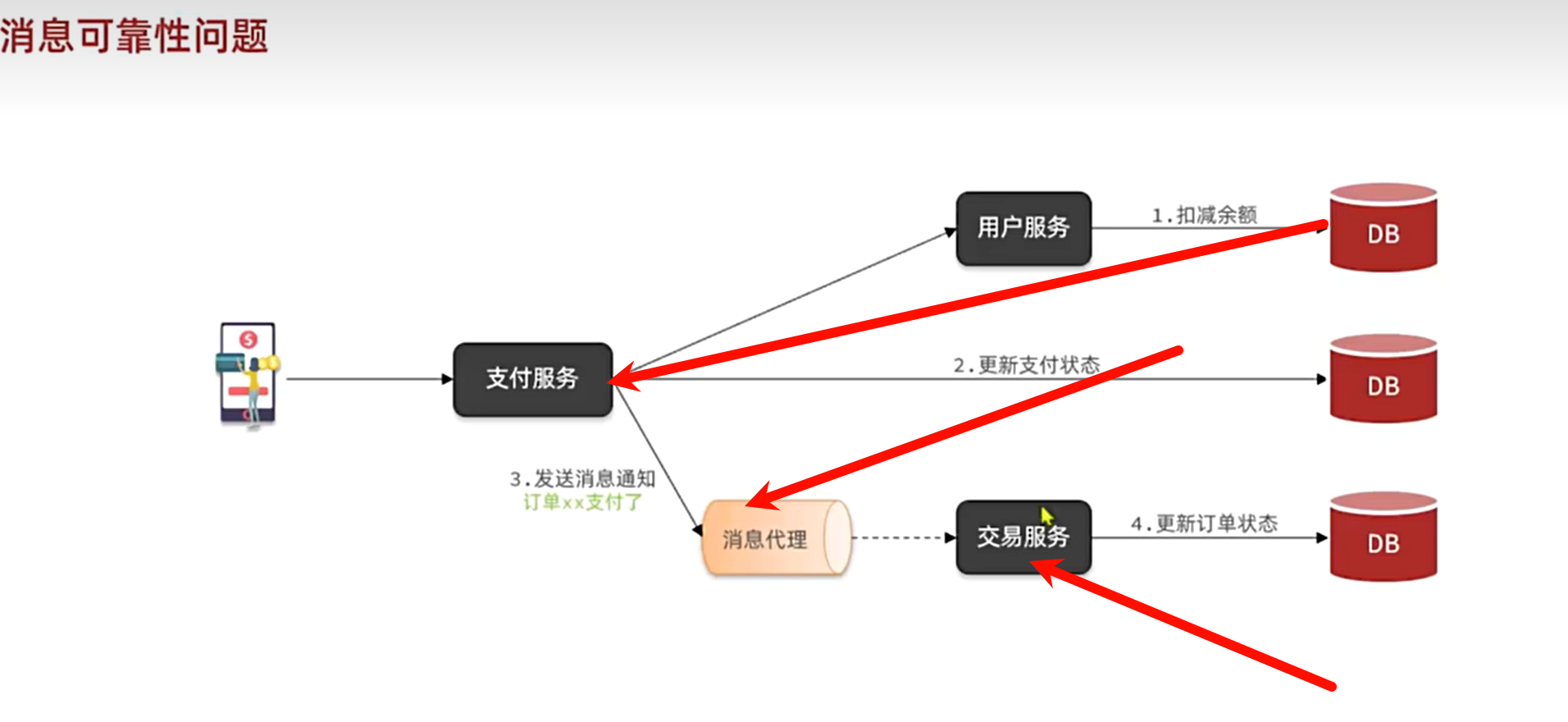
发送者可靠性
发送者重连
配置yml文件的retry配置
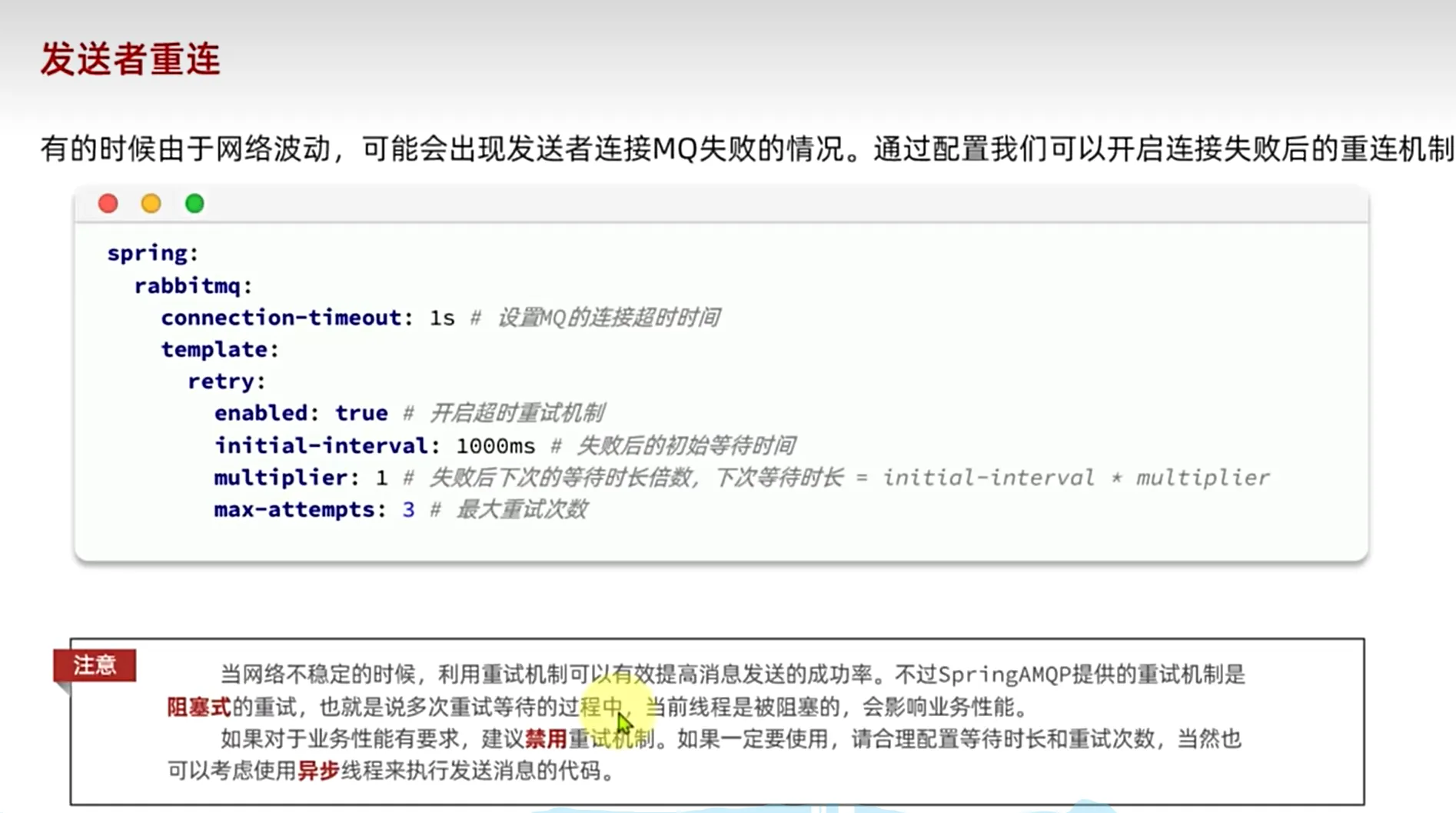
由于发送者重试机制是阻塞式的重试,也就是我们再重试等待的过程中当前线程是阻塞的 ,会影响业务性能
默认连接超时时间是1s,默认等待重连实践是1s
发送者确认机制
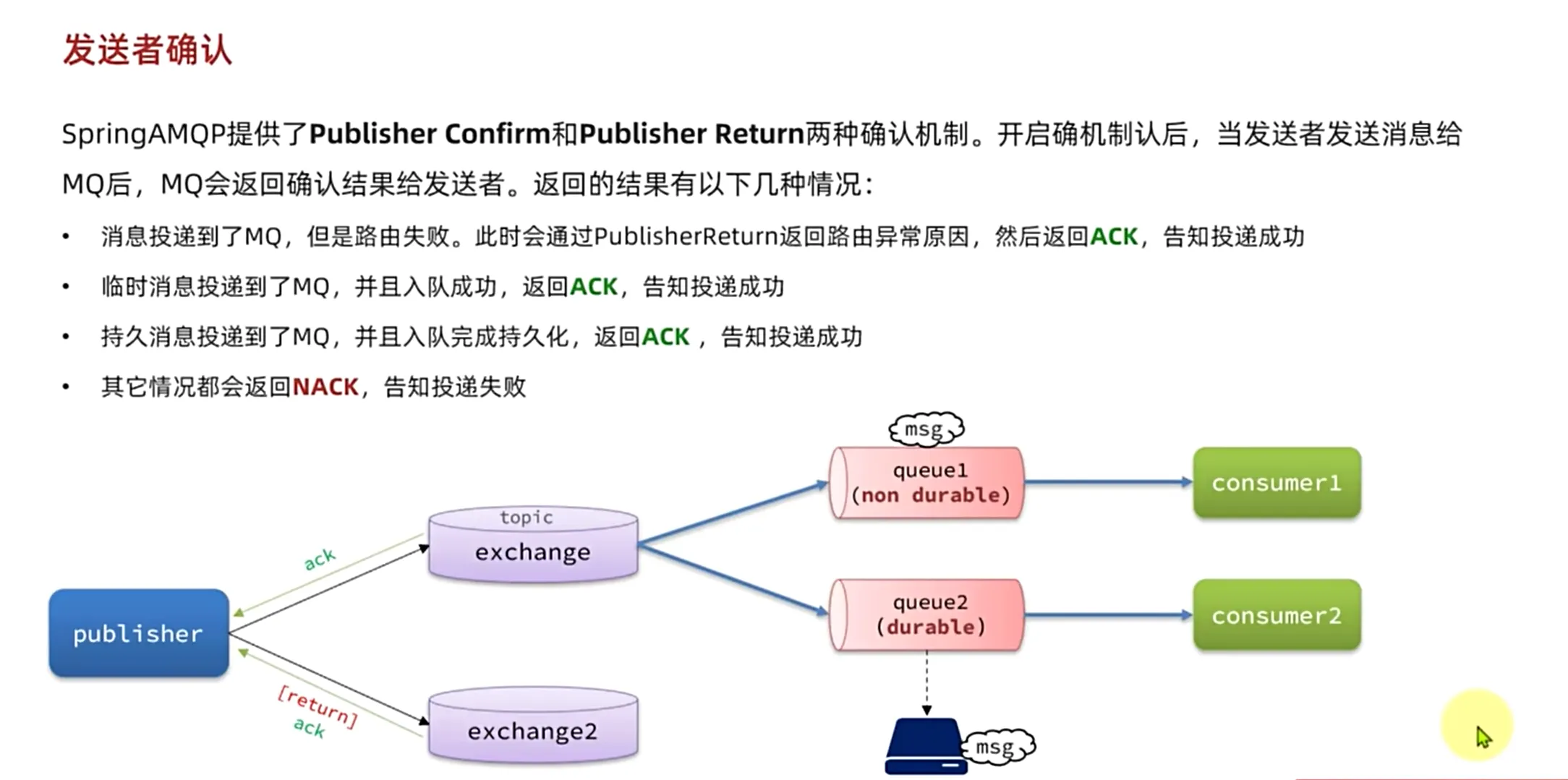
返回nack的情况就是,我们的消息没有发送到我们的交换机里面,我们的消息发送成功了但是没有持久化到我们的持久化队列
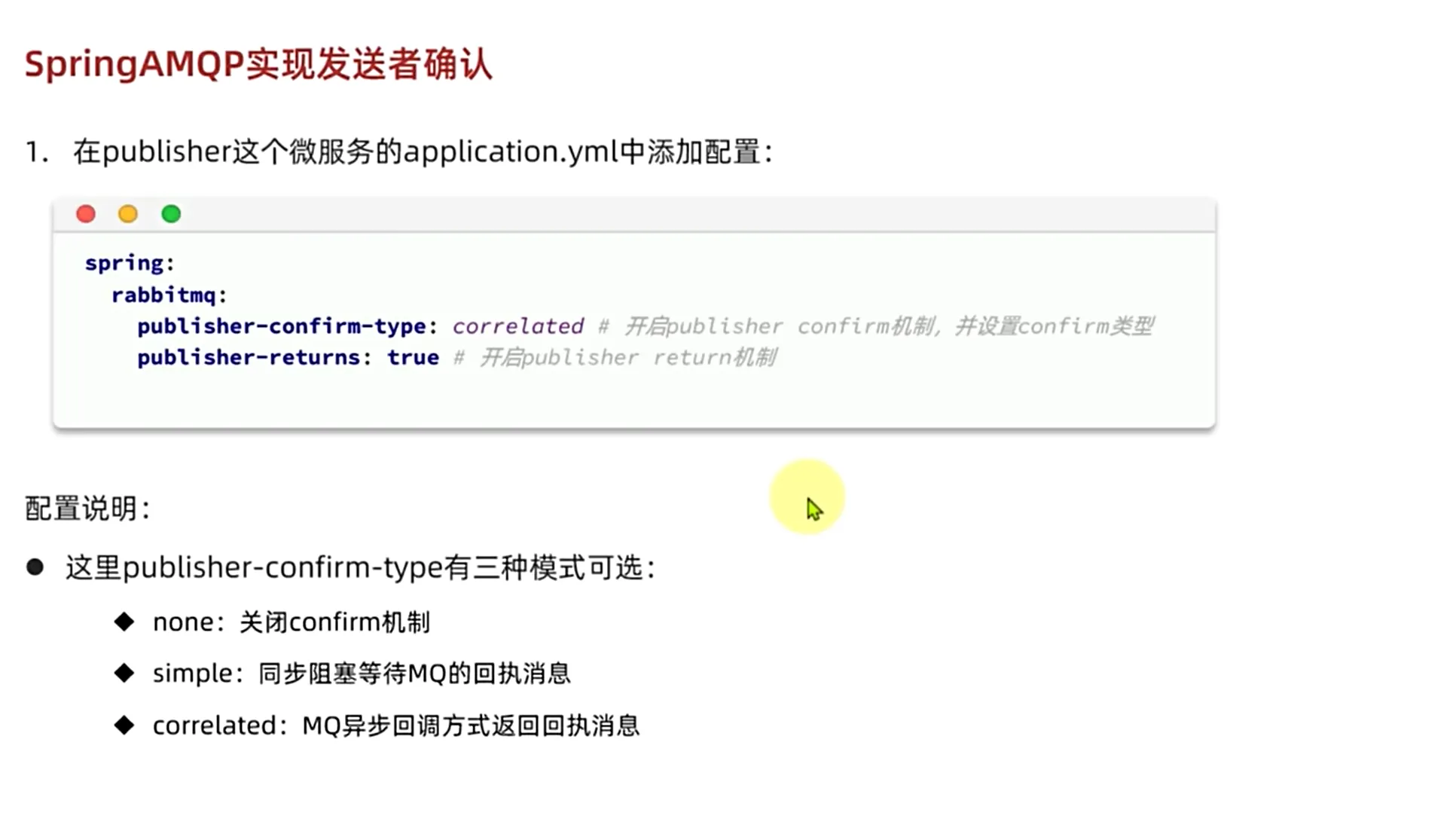
发送者确认机制的写法
1.首先我们需要先去配置如同上文
首先我们需要在我们的yml文件当中去处理我们的配置信息,就比如我们的发送者确认机制和我们的发送者返回机制
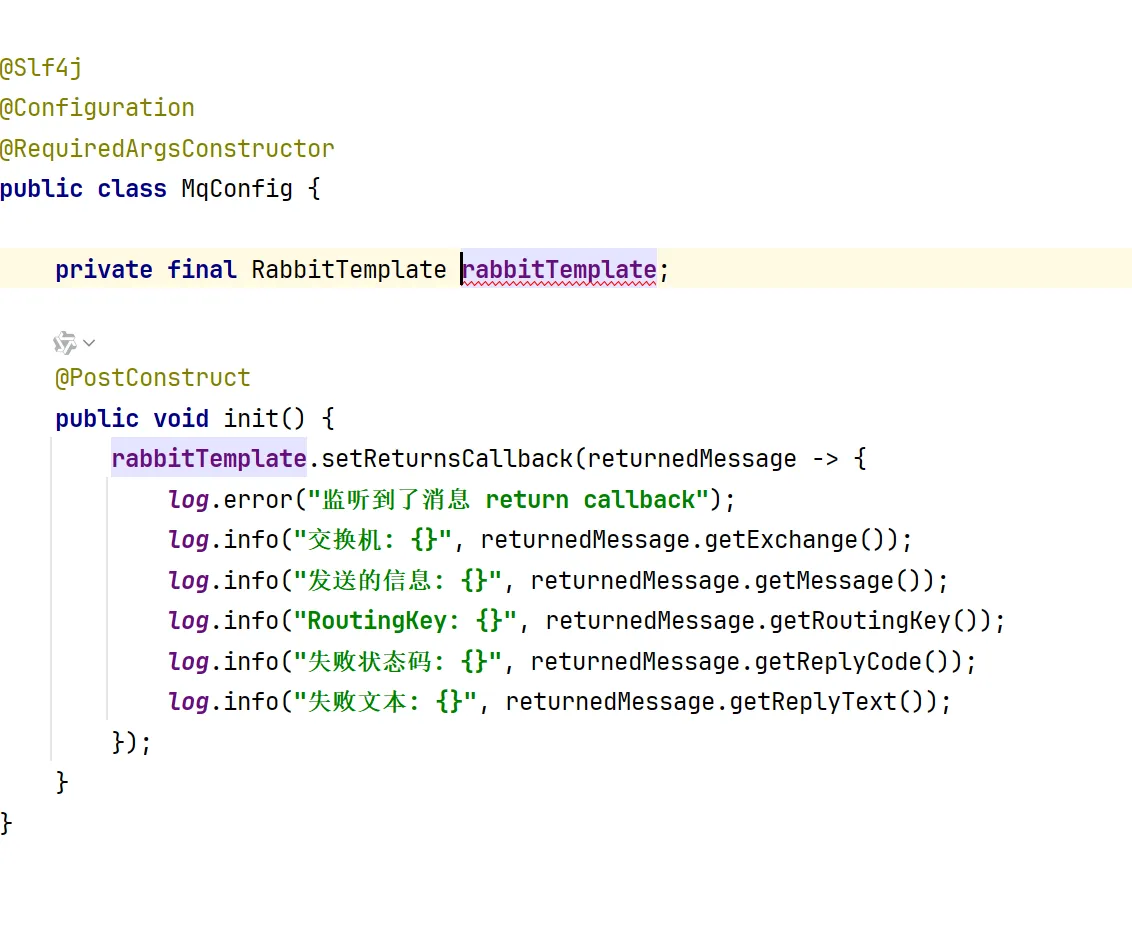
2.因为一个发送者只能由一个return callback 所以我们采取使用配置类的方式去书写我们的返回回调函数
写config包
写我们的配置类,配置我们的 returncallback,这里我们采用了@PostConstructor 因为我们期望在bean创建好之后我们就会立刻去注入我们的返回回调函数
ctrl + p 可以知道我们要填入什么函数
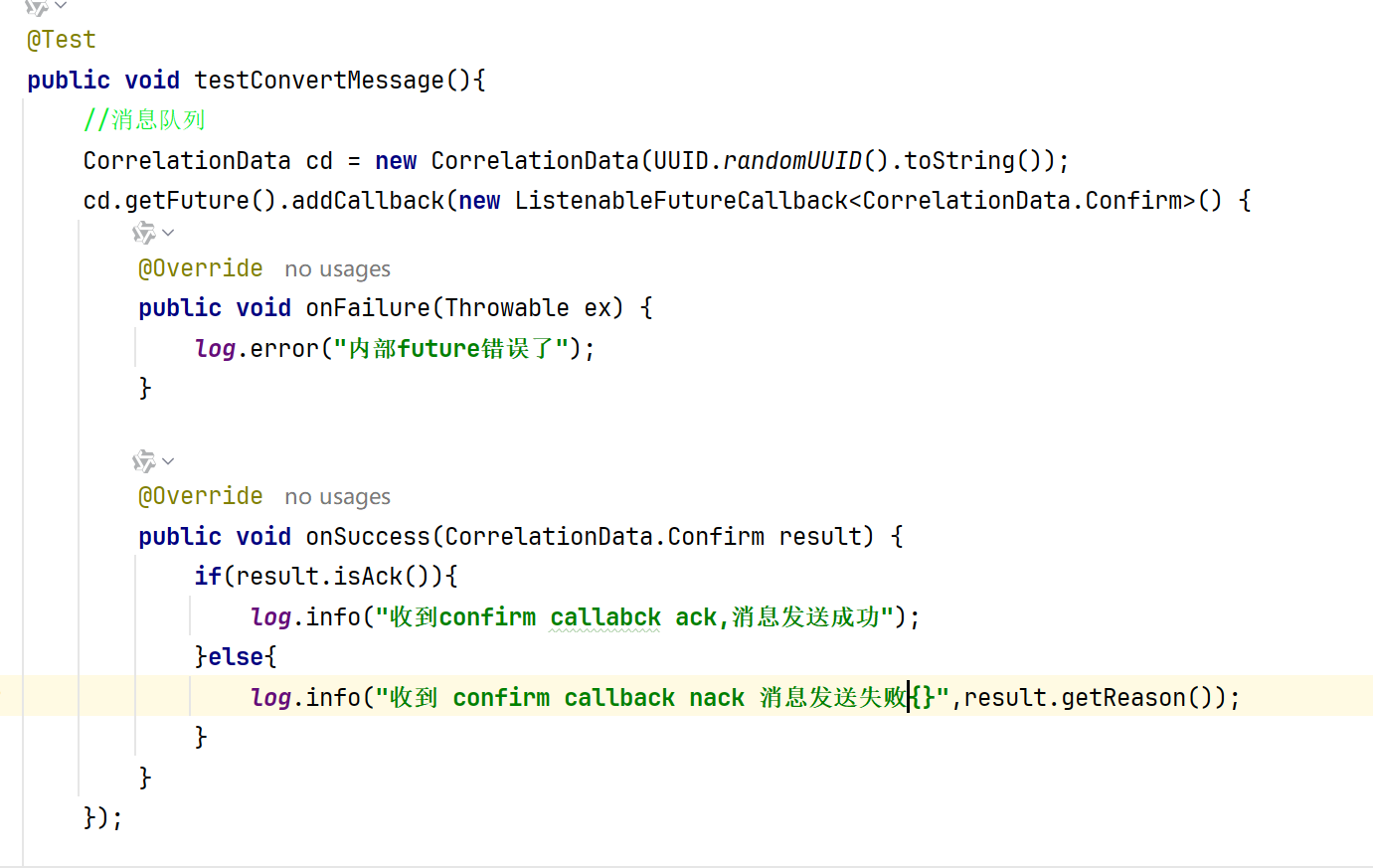
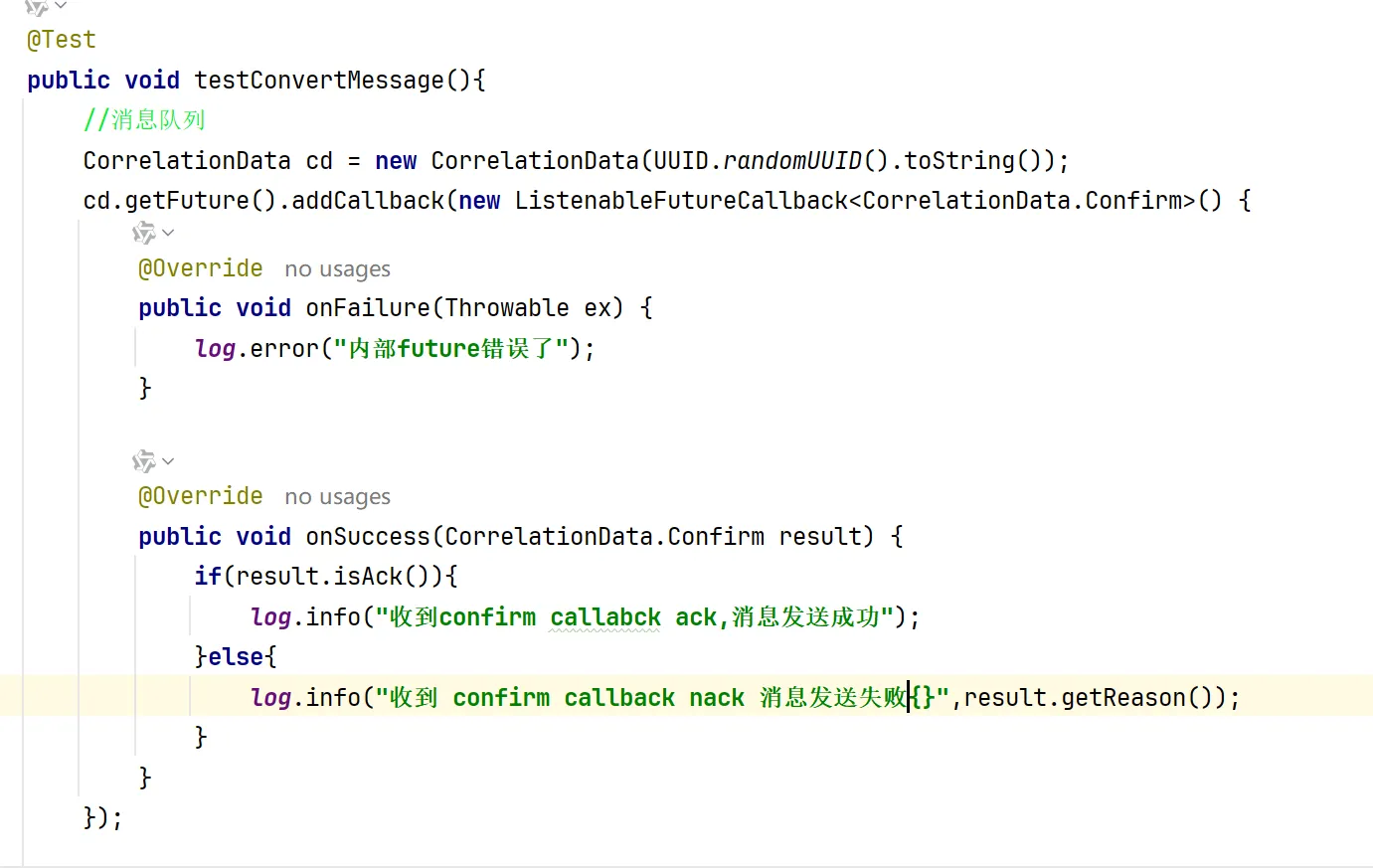
3.然后我们可以去写我们的confirm callback 函数,这里我们要使用这个函数 注意cd 就是我们写的
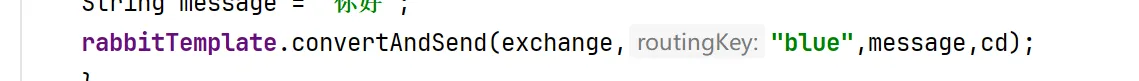
cd 是correlationdata类型的我们可以nwe一个注意要给这个函数一个唯一id,这里用简单的唯一id;
然后我们就可以用cd。getfuture addcallback函数了,可以参考如下写法
数据持久化
*我们使用注解去创建的交换机和我们的队列默认是持久化的。
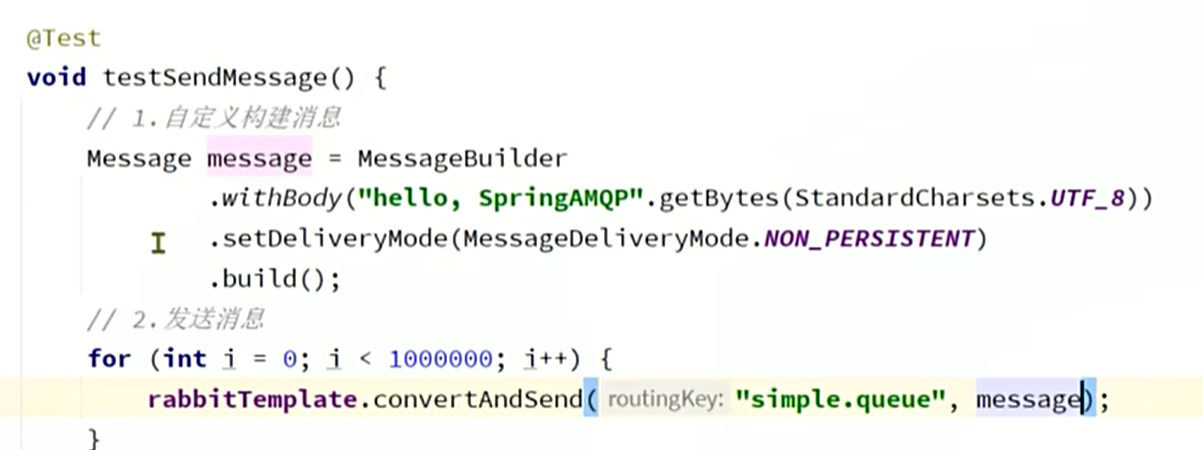
可以自定义的去构建非持久化消息
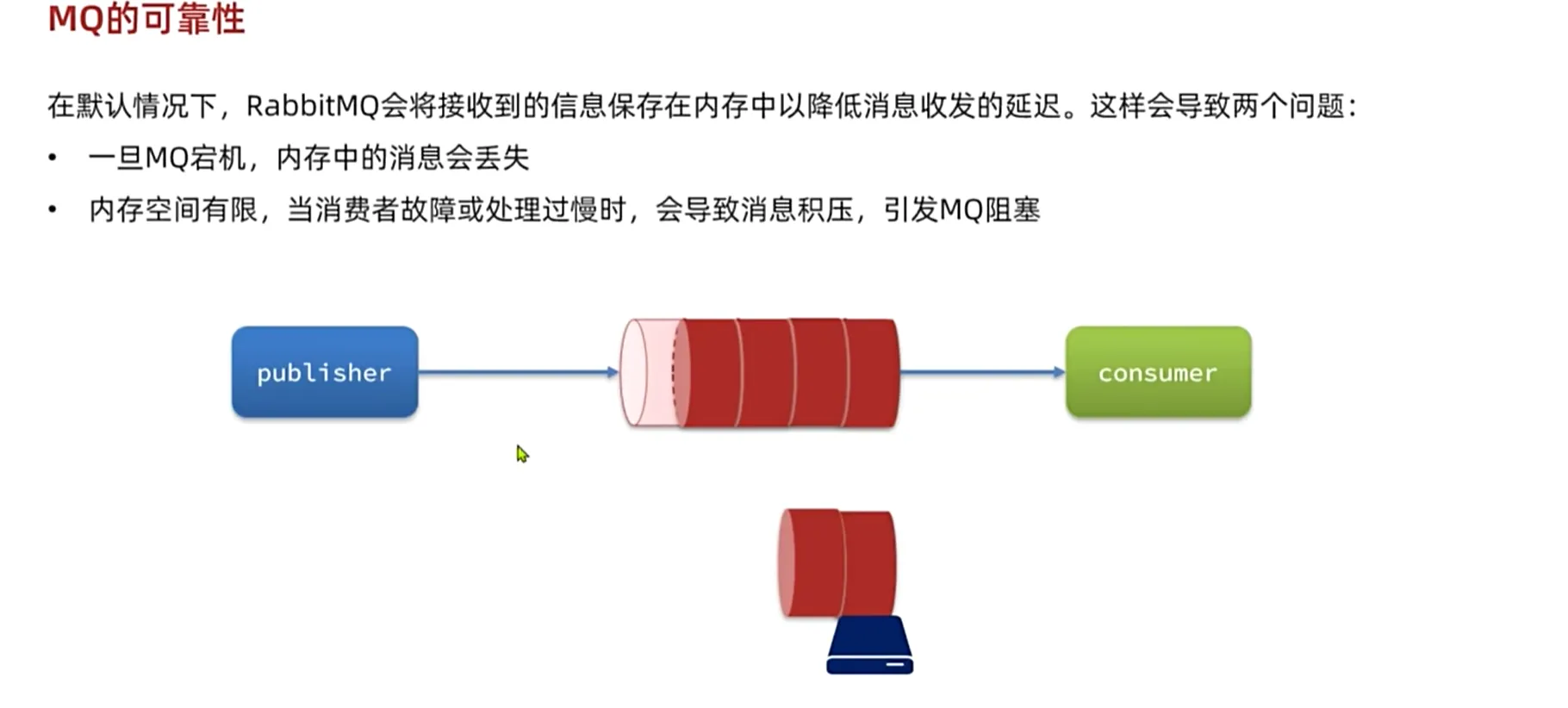
当我们消息发送过多,由于内存有限,消费者处理不过来,就会出现消息挤压,引起mq阻塞
每一次我们消息太多了要吧内存中的数据写到我们的磁盘中去,就是pageout,我们mq的吞吐能力直接降为0,直接阻塞
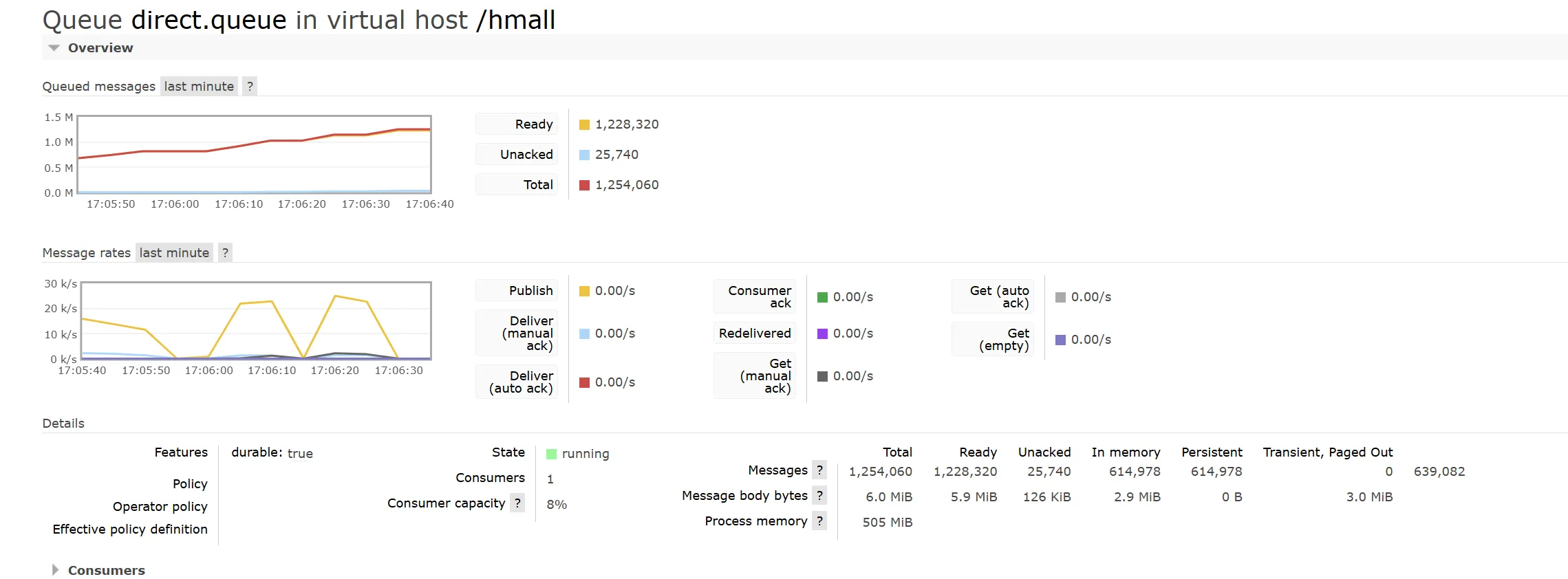
如果我们采用消息持久化呢?
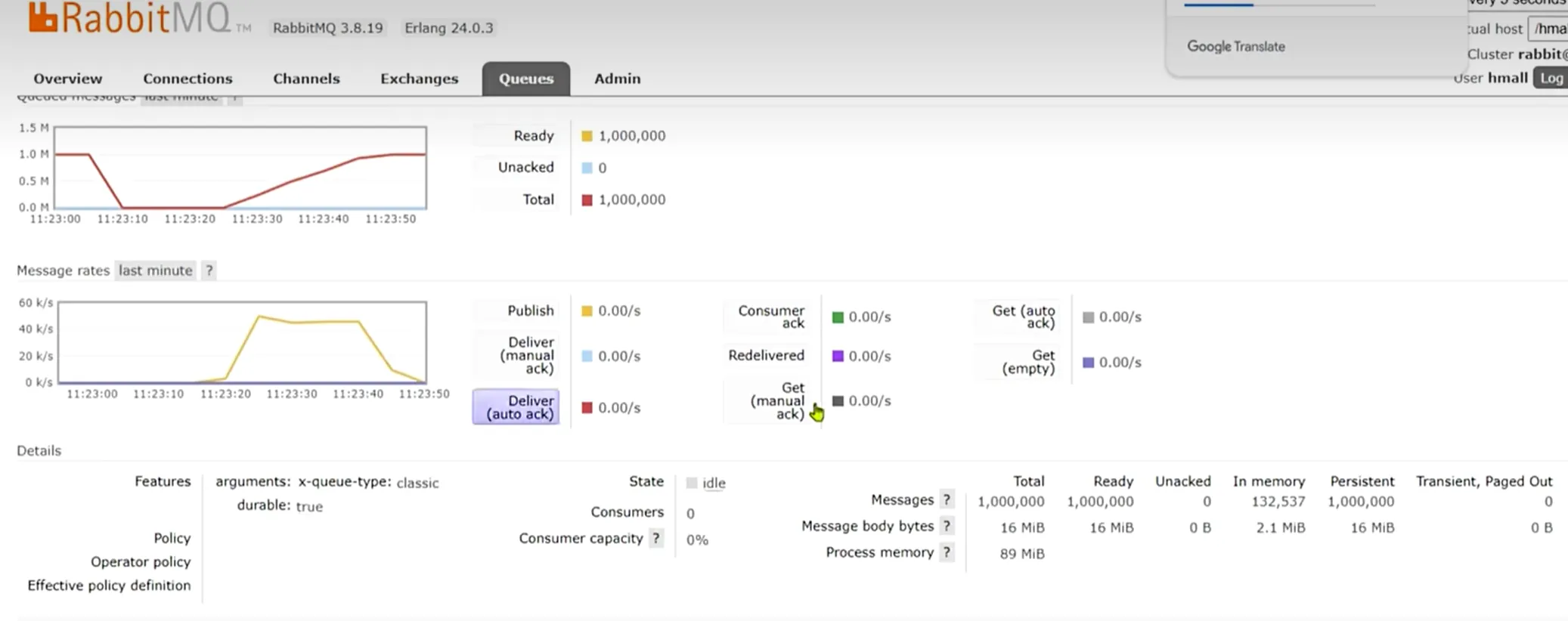
看起来我们消息队列不会突然阻塞了,而且吞吐量还很平稳和高
Lazy Queue

因为我们lazyqueue的消息直接存储在我们的磁盘当中,所以不会出现我们的消息丢失问题,同时mq还对我们的磁盘io进行了优化

使用bean去创建我们的lazyqueue
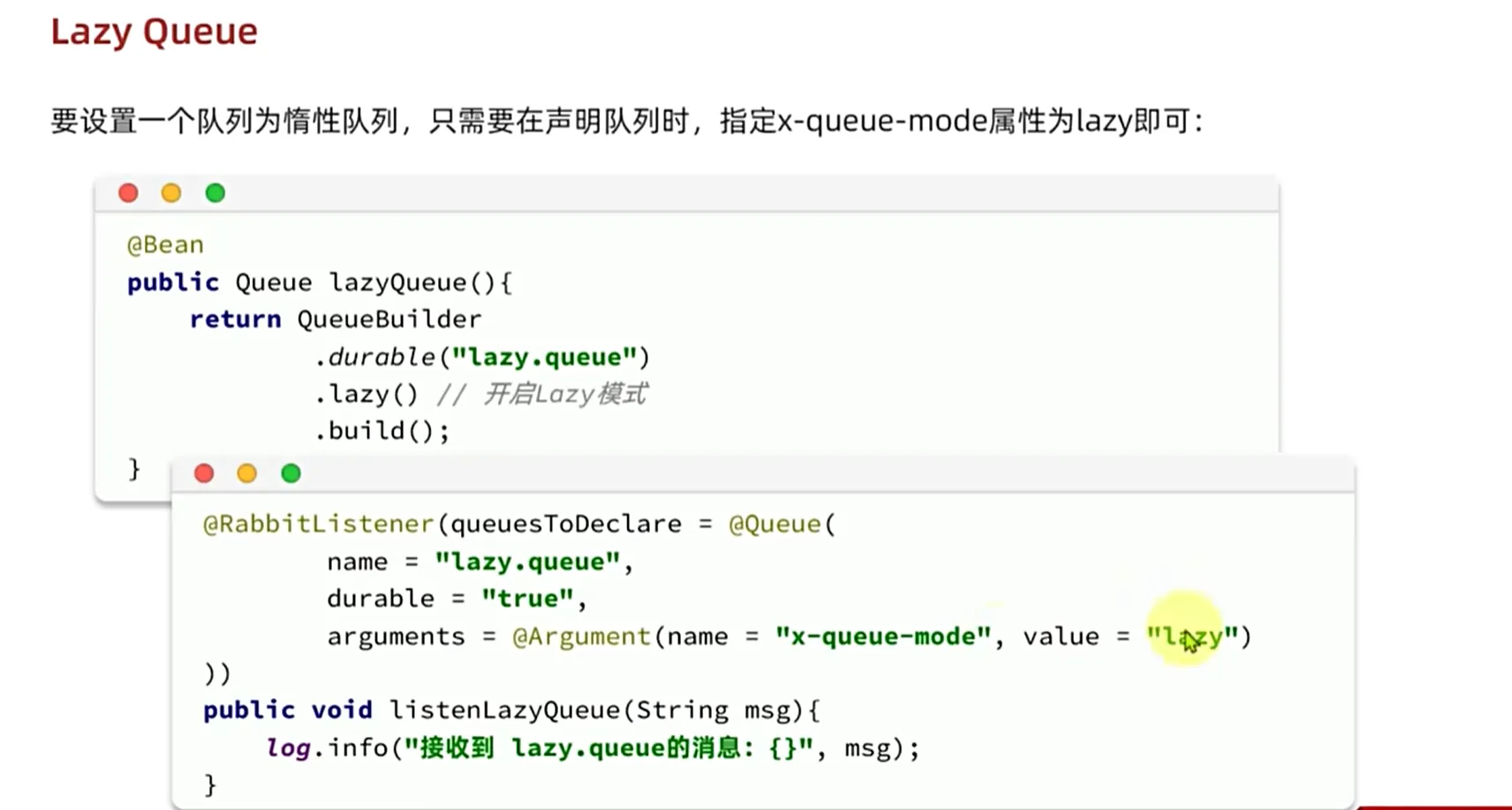
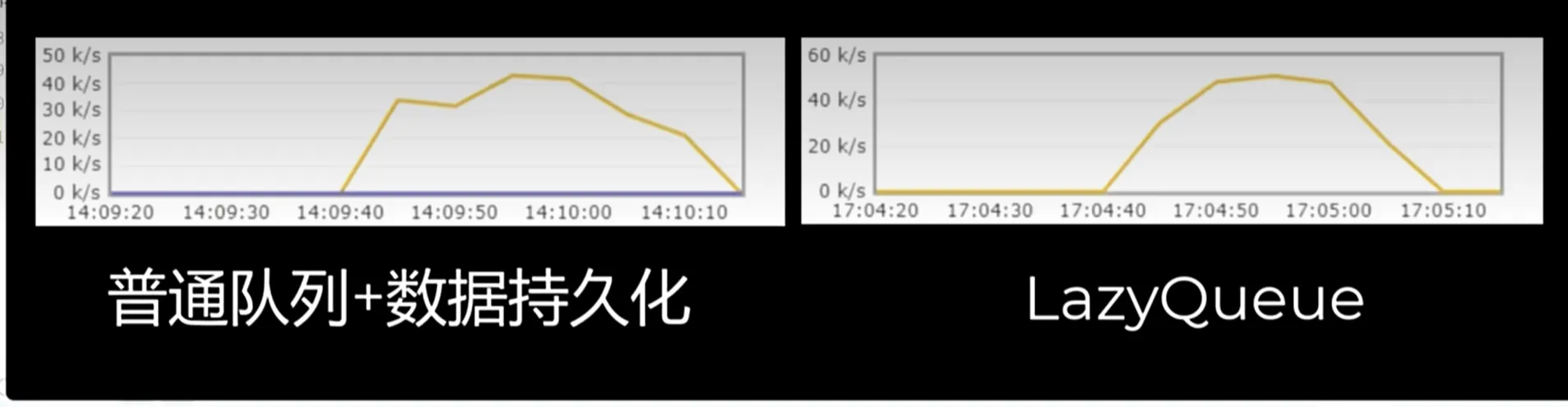
lazyqueue的并发能力更强

使用lazyqueue不管如何消息都是持久化的
消费者确认机制
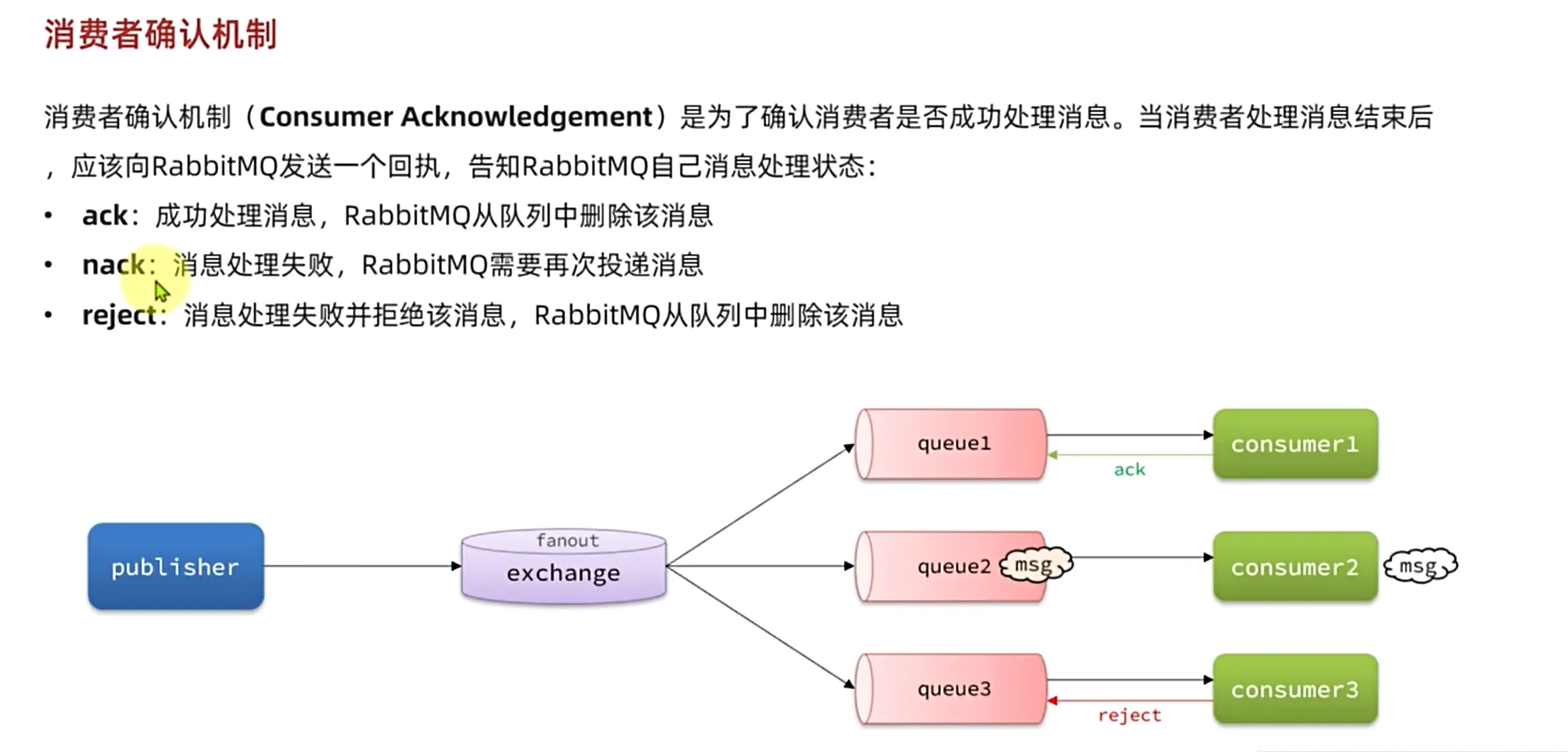
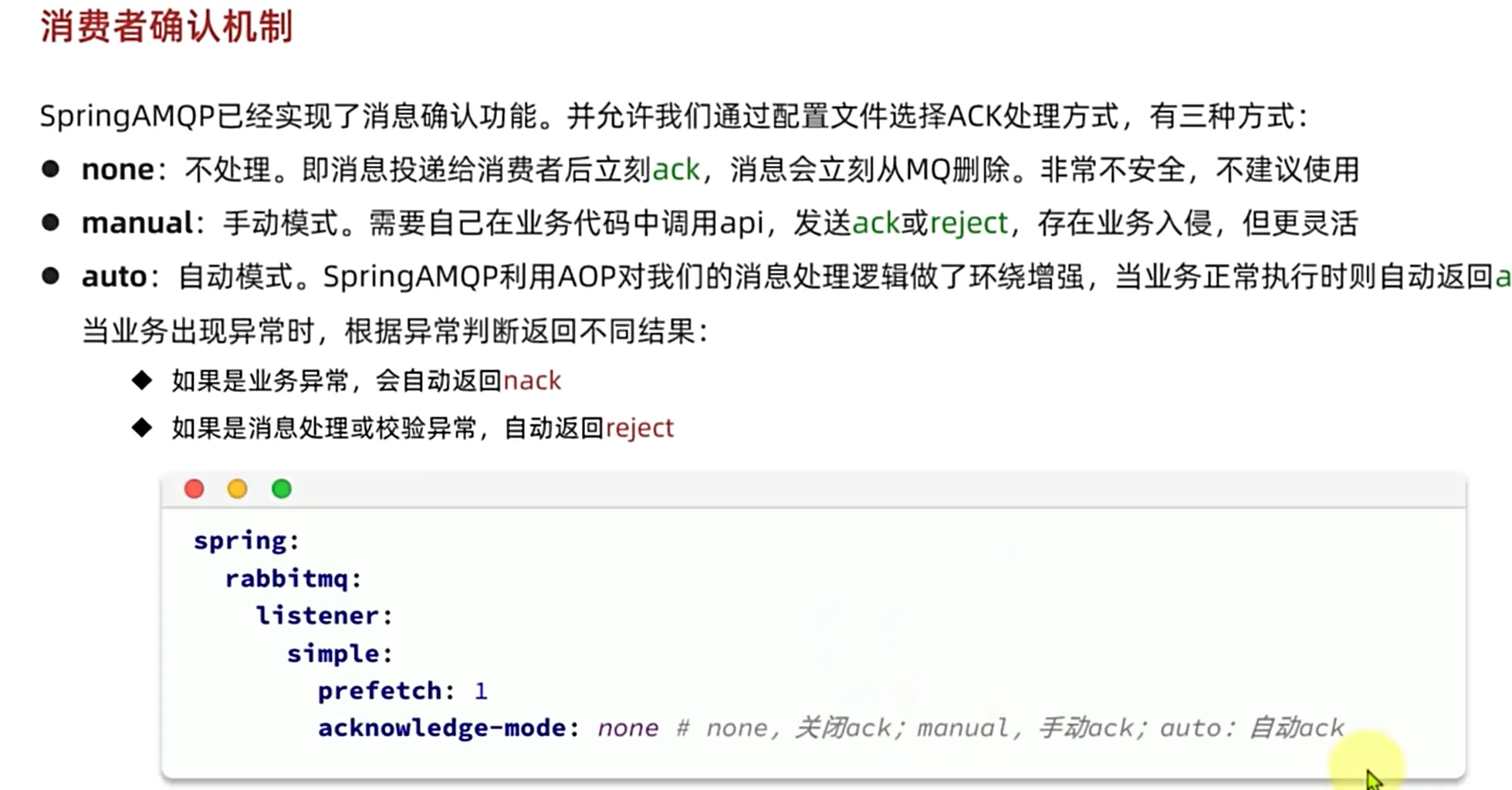
一般选择auto模式因为这个模式方便开发
throw MessageConvertException 如果抛出这个异常的话,那么我们消费者就会给mq消息队列返回reject,将消息删除

消费者重试机制
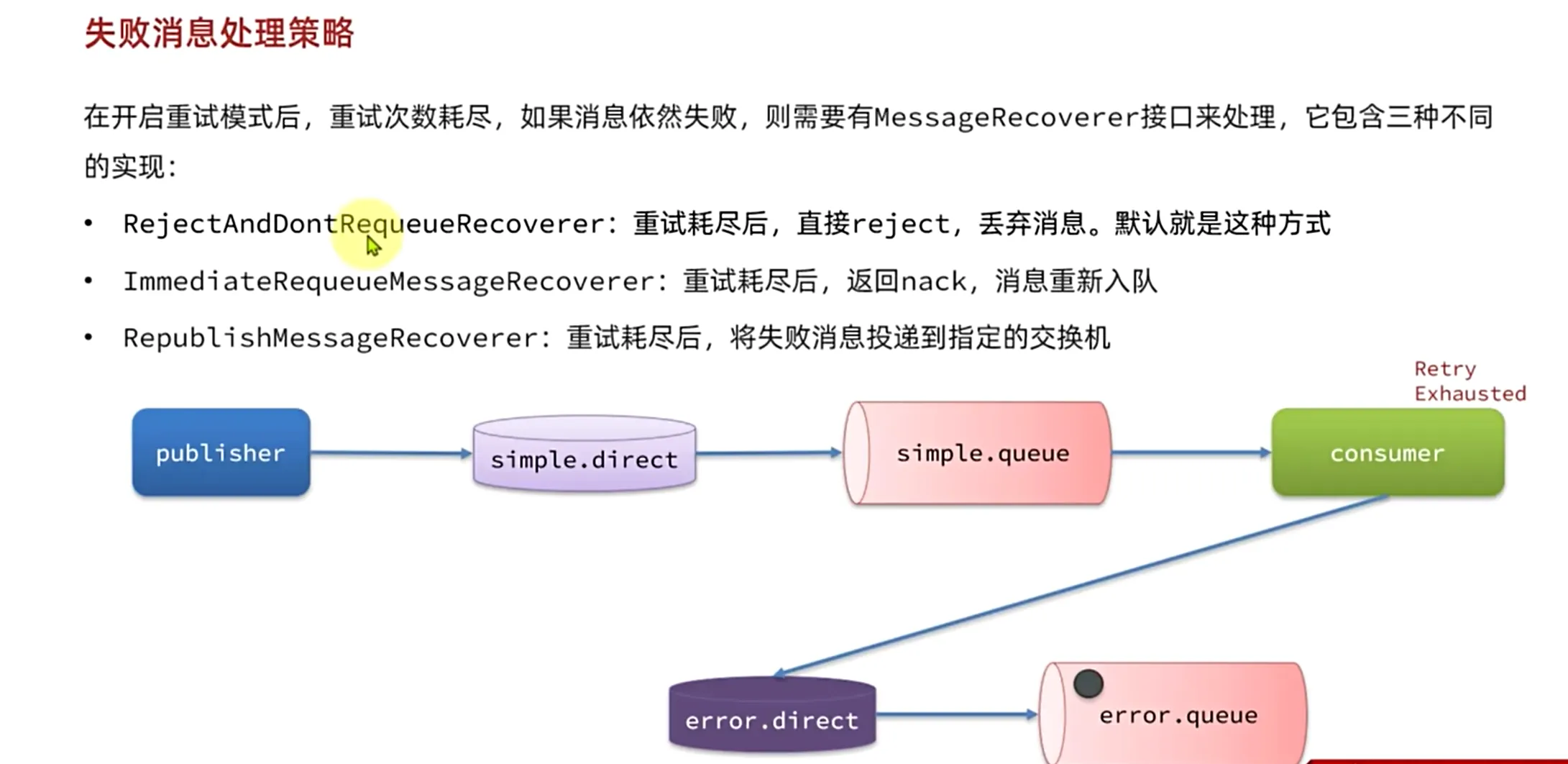
和我们的publisher发送者重试机制类似
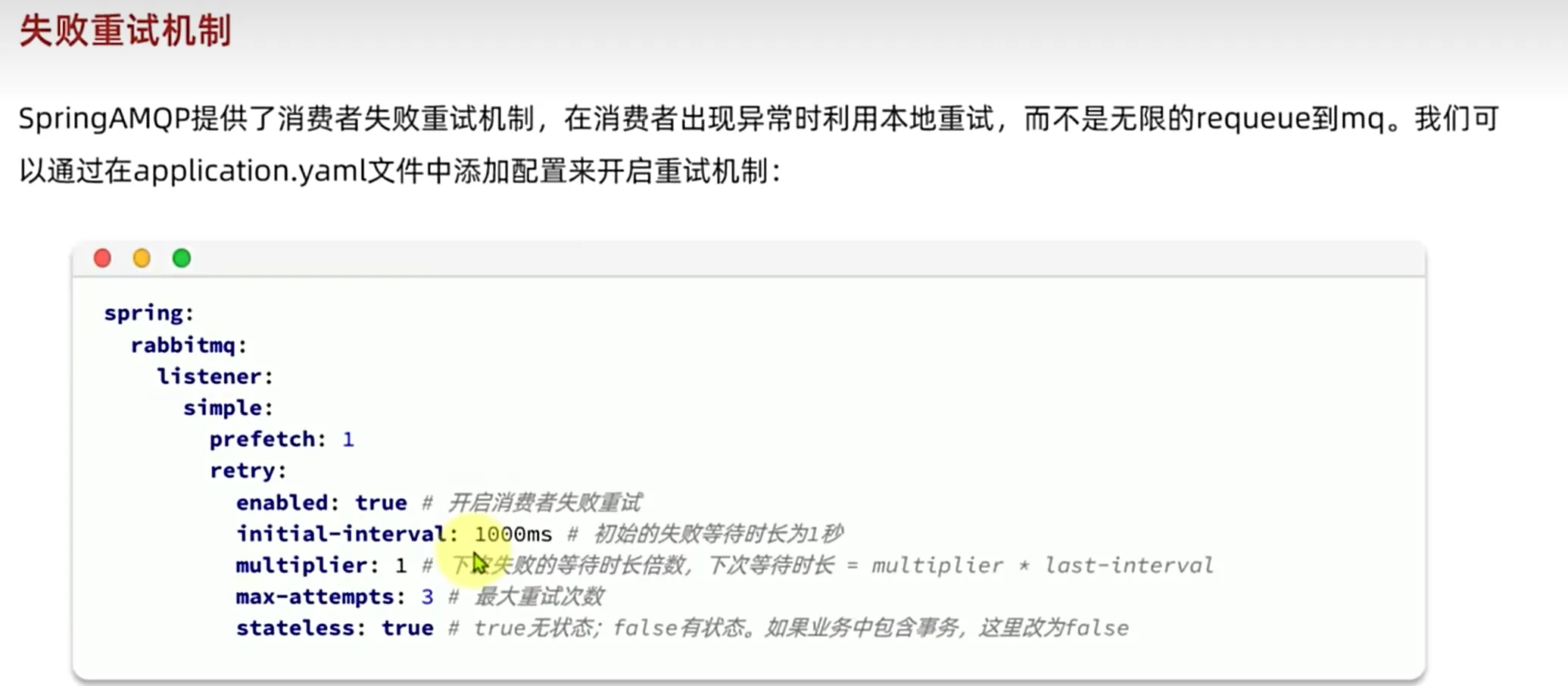
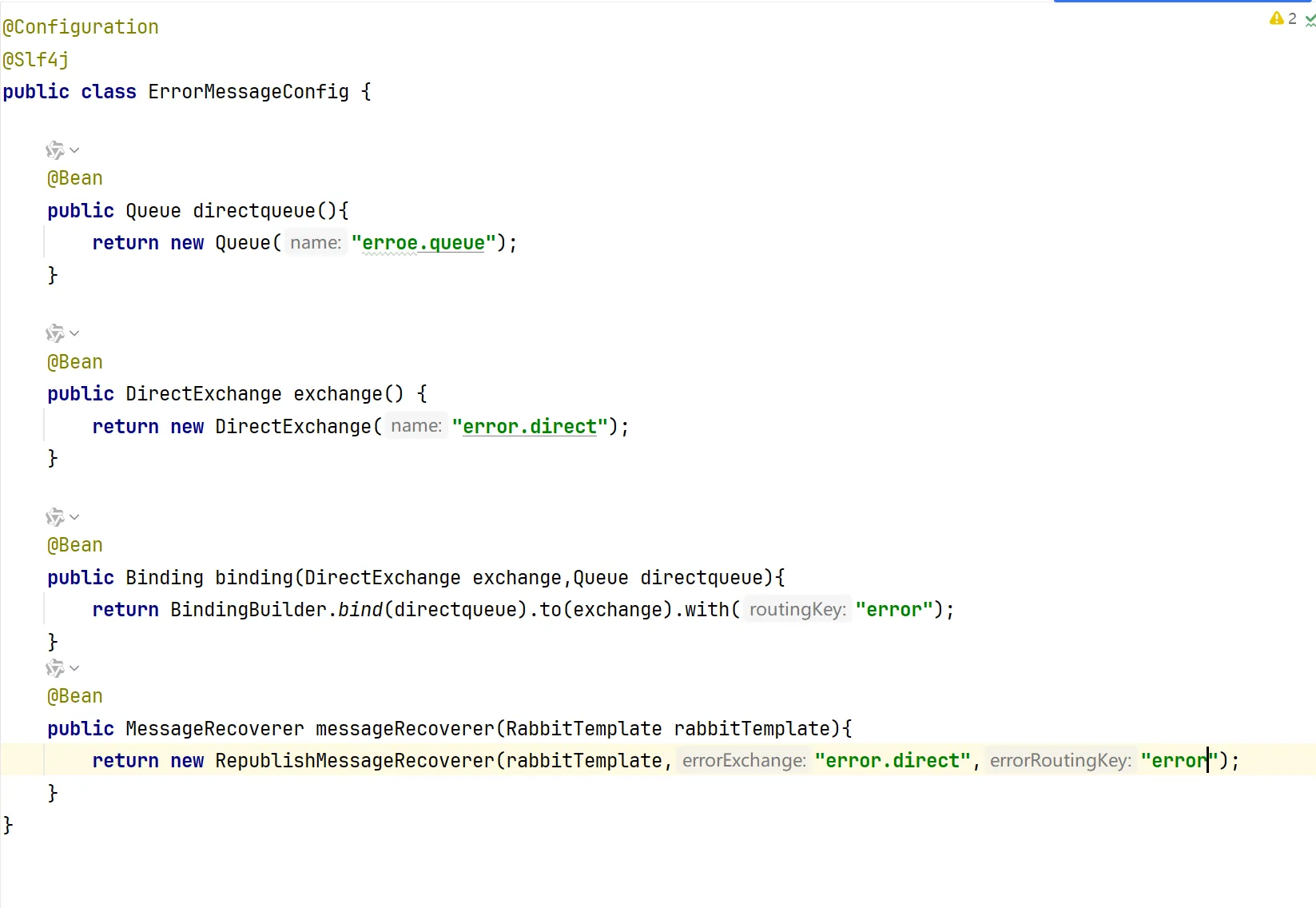
代码可以这么写,然后我们就声明了一个处理error信息的交换机和队列,重点是我们的messagerecoverer的方法实现
业务的幂等性
幂等性就是我们的业务无论调用多少次,对我们业务状态的影响是一致的

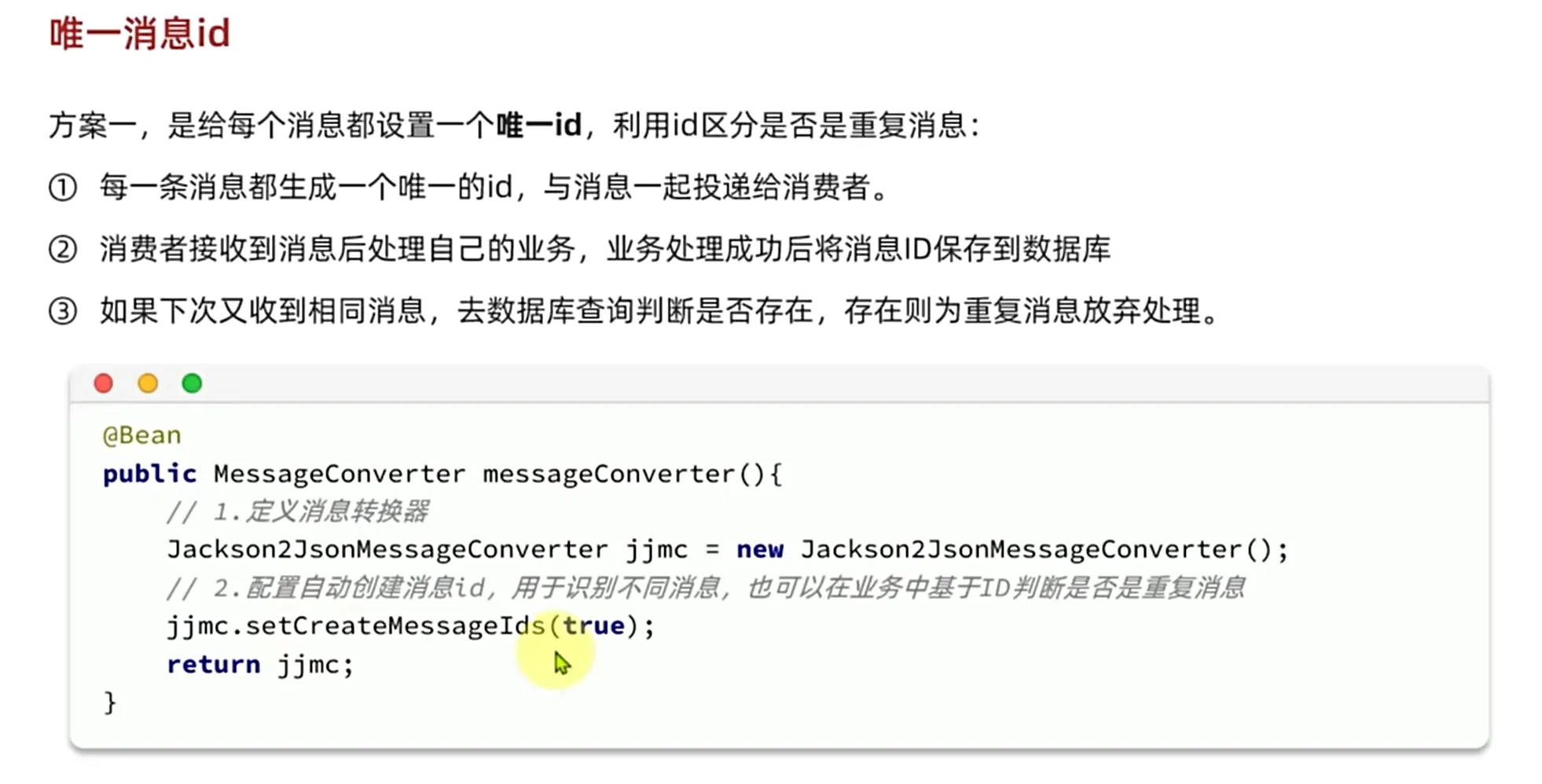
在配置我们的消息转换器的时候我们可以去配置自动生成我们的唯一id

使用唯一消息id去实现我们业务的幂等性会存在如下问题,就比如会影响我们系统的性能,额外的mysql操作,业务侵入
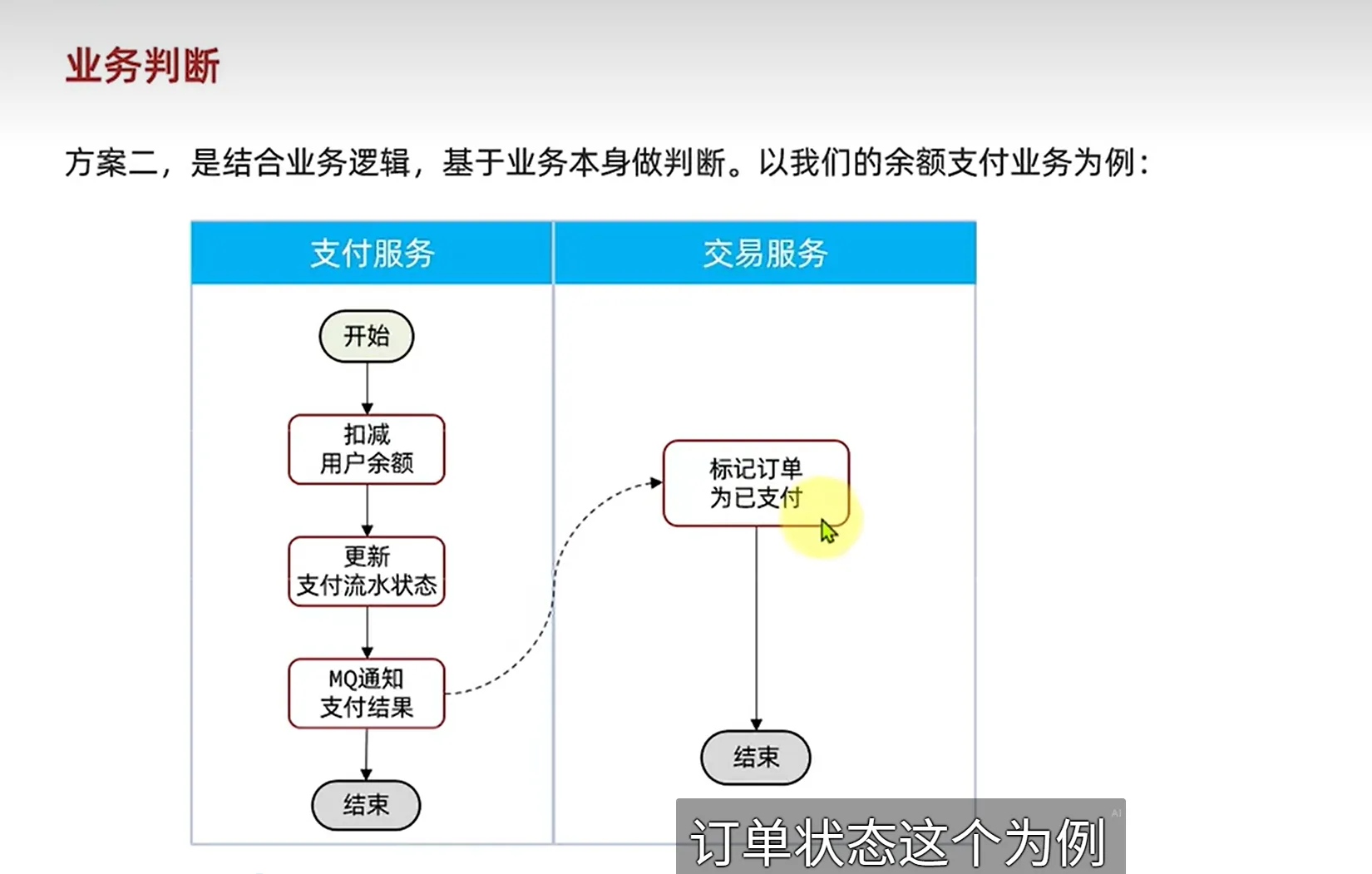
这样可以实现无侵入式的去实现我们业务的幂等性
延时消息
延时消息就可以帮我们去实现我们的消息在交换机中去暂时存储,延时发送到我们的业务中去,可以保证我们消息发送如果出现不可抗因素而无法更新业务状态时,保障业务之间的状态一致性
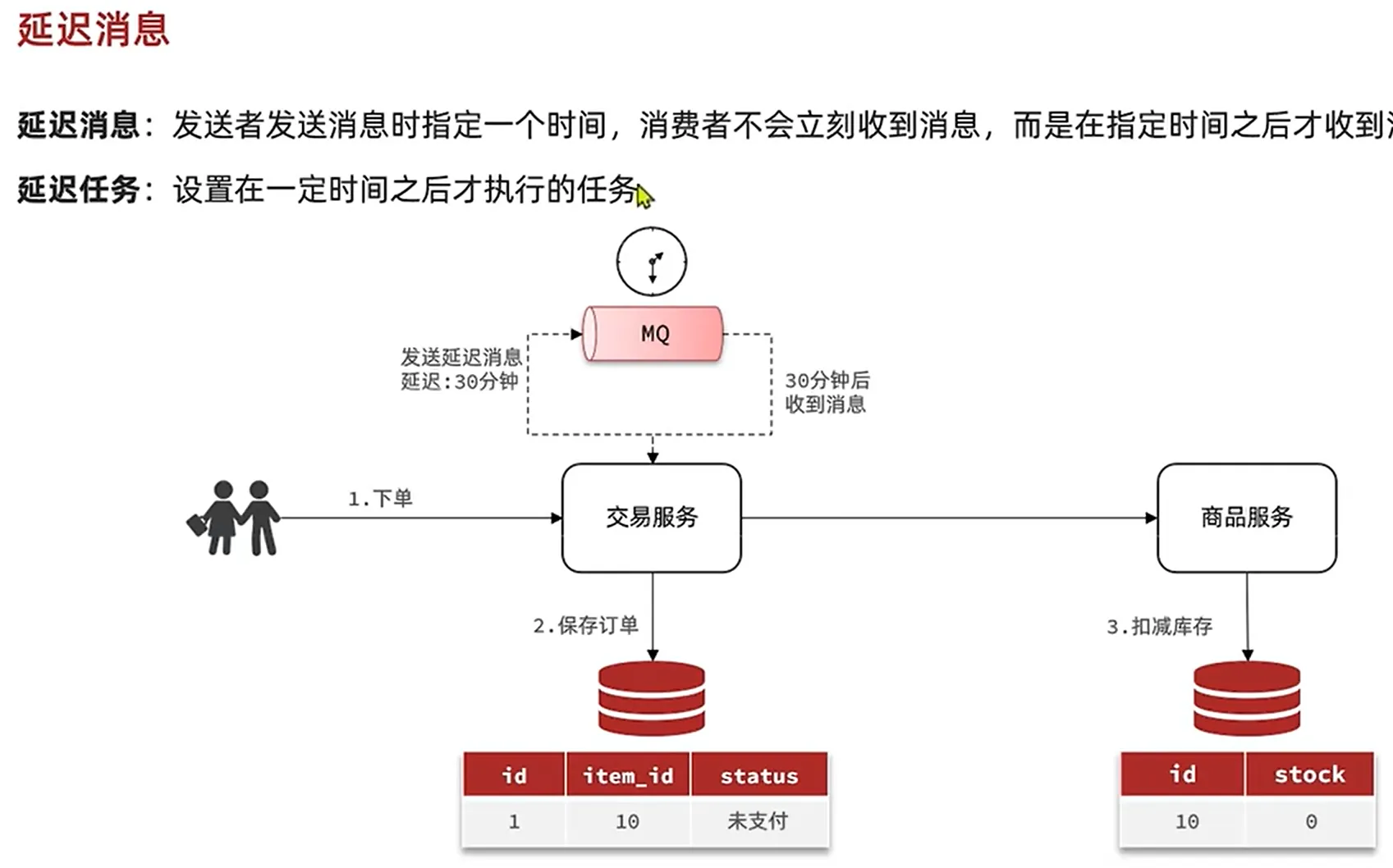
延时消息插件
非常推荐非常推荐使用插件去实现我们的延时业务,因为我们如果使用死信交换机的话会有很多细节需要注意,一不小心就配置错误了

官方文档说明:
https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
下载
插件下载地址:
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
由于我们安装的MQ是3.8版本,因此这里下载3.8.17版本:
下载好后由于我们是基于docker部署的,所以我们去要去手动将我们的插件放到我们与之数据券挂载的地址
这里我们使用docker命令
docker volume ls查看我们有那些数据券

docker volume inspect mq-plugins
进入容器中,更新我们的配置
然后我们就可以去更改我们的交换机配置了
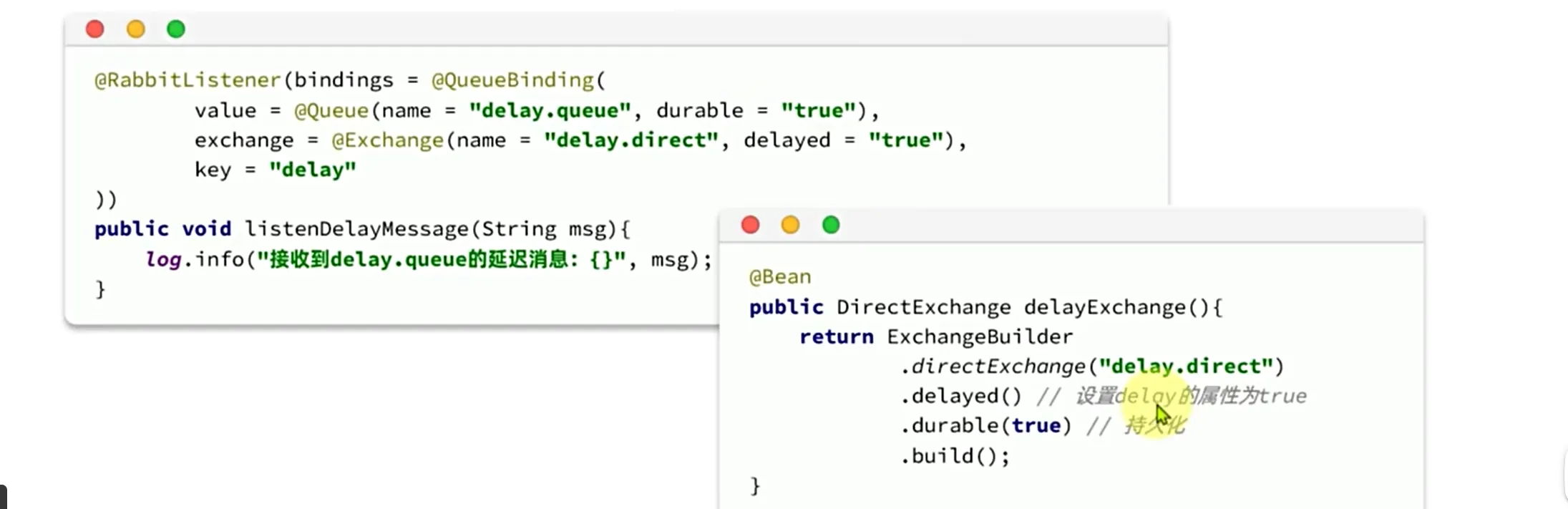
设置过期时间

这是一个消息密集型操作,尽量避免在同一时刻有太多延迟消息的产生
死信交换机
当然我们的死信交换机还是很有价值的,在没有插件的情况下我们尽量也要受搓出来
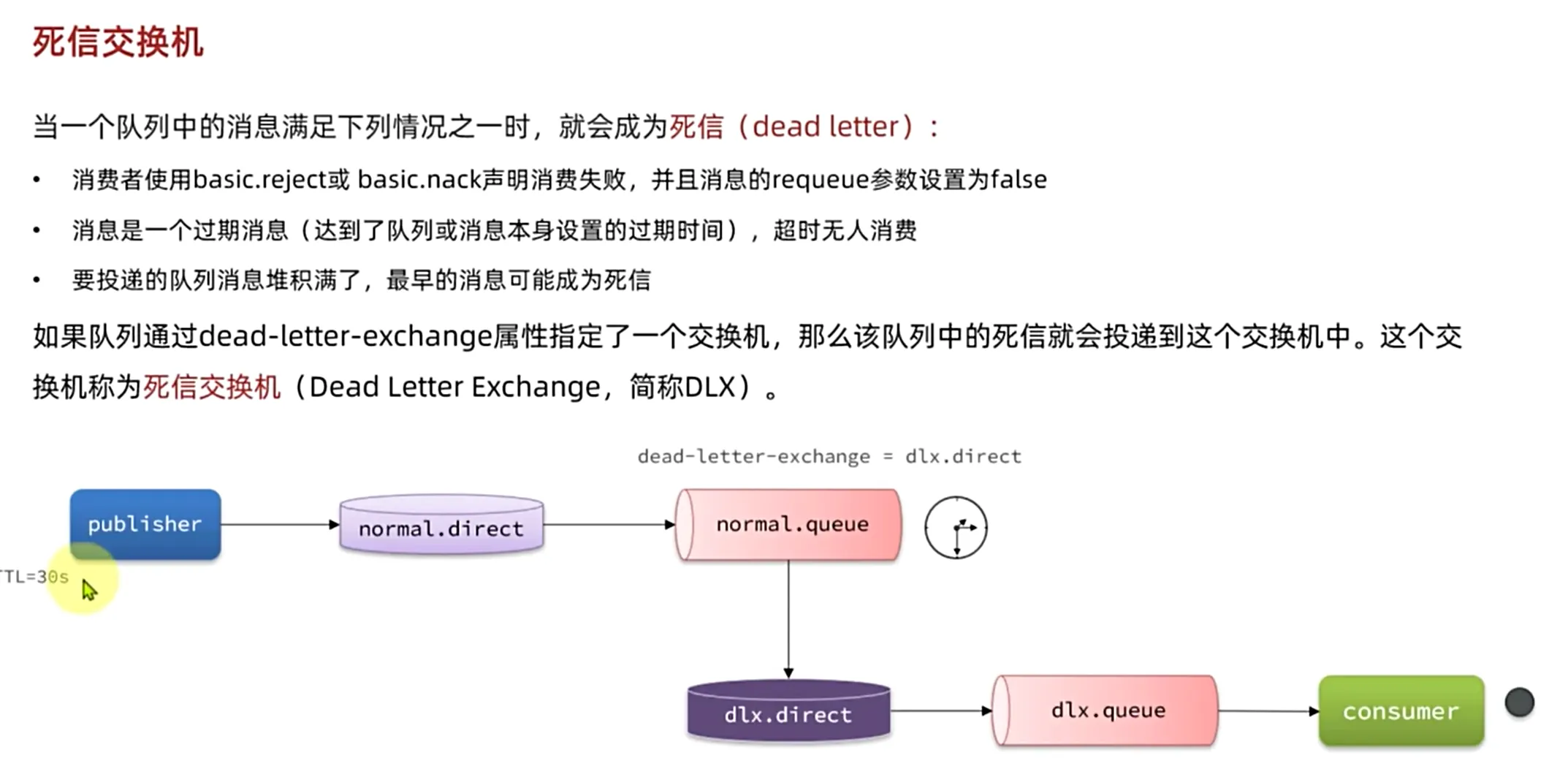
死信:消息是一个国企消息,超时无人消费,或者我们的队列消息堆积满了,最早的消息可能成为死信,又或者我们消费者使用basic.reject,或者basic.nack声明消费失败,并且消息的requeue参数设置为false
总结
在学习 RabbitMQ 时,重点掌握了交换机类型及其应用,Direct、Fanout 和 Topic 交换机各有特点,可通过多种方式创建绑定;消息处理上,推荐使用 JSON 序列化替代 JDK 默认序列化以优化消息转换;为保障消息队列高可靠性,从发送者重连与确认机制、数据持久化(含 Lazy Queue 应用)、消费者确认与重试机制等多方面着手;此外,还学习了业务幂等性的实现、延时消息插件的使用以及死信交换机的原理与作用,这些知识共同构成了 RabbitMQ 从基础到高级特性的完整知识体系,有助于构建稳定高效的消息队列应用 。
就此我都RabbitMQ的基础知识学习就到这里了,之后我们还要将理论知识应用到实践当中去,这样才是真学会了!!!!!
当然其实我已经实践过了,只不过先写在了语雀平台上

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)