YOLO-V7模型解读基本模块(一)
通常指的是CONV和BN的组合,同样是上述提到的优化的一部分,需要通过卷积,得到特征向量,最后使用激活函数。
目录
(目前简单描述每个模块存在的特征,下一篇会写一篇训练时候是怎么使用这些模块,如有缺少的要素点,下一篇也即将补上)
一:YOLO概述
YOLO 并非一蹴而就,而是在不断迭代中变得更加强大
一:实际应用:
- 智能交通:检测道路上的车辆、行人、交通标志等。
- 安防监控:检测监控画面中的异常行为,例如人员入侵、打架斗殴等。
- 工业质检:检测产品表面的缺陷,例如划痕、污渍等。
二:YOLO 的广泛应用
- 自动驾驶 (Autonomous Driving) :识别车辆、行人、交通标志等,提高驾驶安全性。
- 视频监控与安防 (Video Surveillance and Security) :实时监测异常行为,提供预警。
- 工业质检 (Industrial Quality Control) :检测产品缺陷,提高生产效率。
- 零售与物流 (Retail and Logistics) :自动识别商品,减少人工成本。
- 医疗影像分析 (Medical Image Analysis) :辅助医生诊断,提高诊断准确性。
- 增强现实与虚拟现实 (Augmented Reality and Virtual Reality) :实现物体识别与跟踪,提供沉浸式体验。
二:YOLO7优化部分
1:数据增强:对样本图片采用了Mosaic增强、随机仿射变换、颜色抖动等方法
2:更快的速度:针对网络层的CONV(卷积)和BN(标准化)进行了合并,并且对3*3卷积和1*1的卷积网络也进行了合并 ,达到了优化网络对速度的提升
3:更高的精度:在模型中添加了E-ELAN结构,这是一种一种高效的层聚合网络结构,它通过特定的方式将不同层的特征信息进行融合,以增强模型对目标特征的学习能力。
4:增加了对多个分辨率的支持:YOLOv7 可以支持多个分辨率的输入图像,并在每个分辨率上生成独立的结果,从而提高检测精度
三:网络模型分析
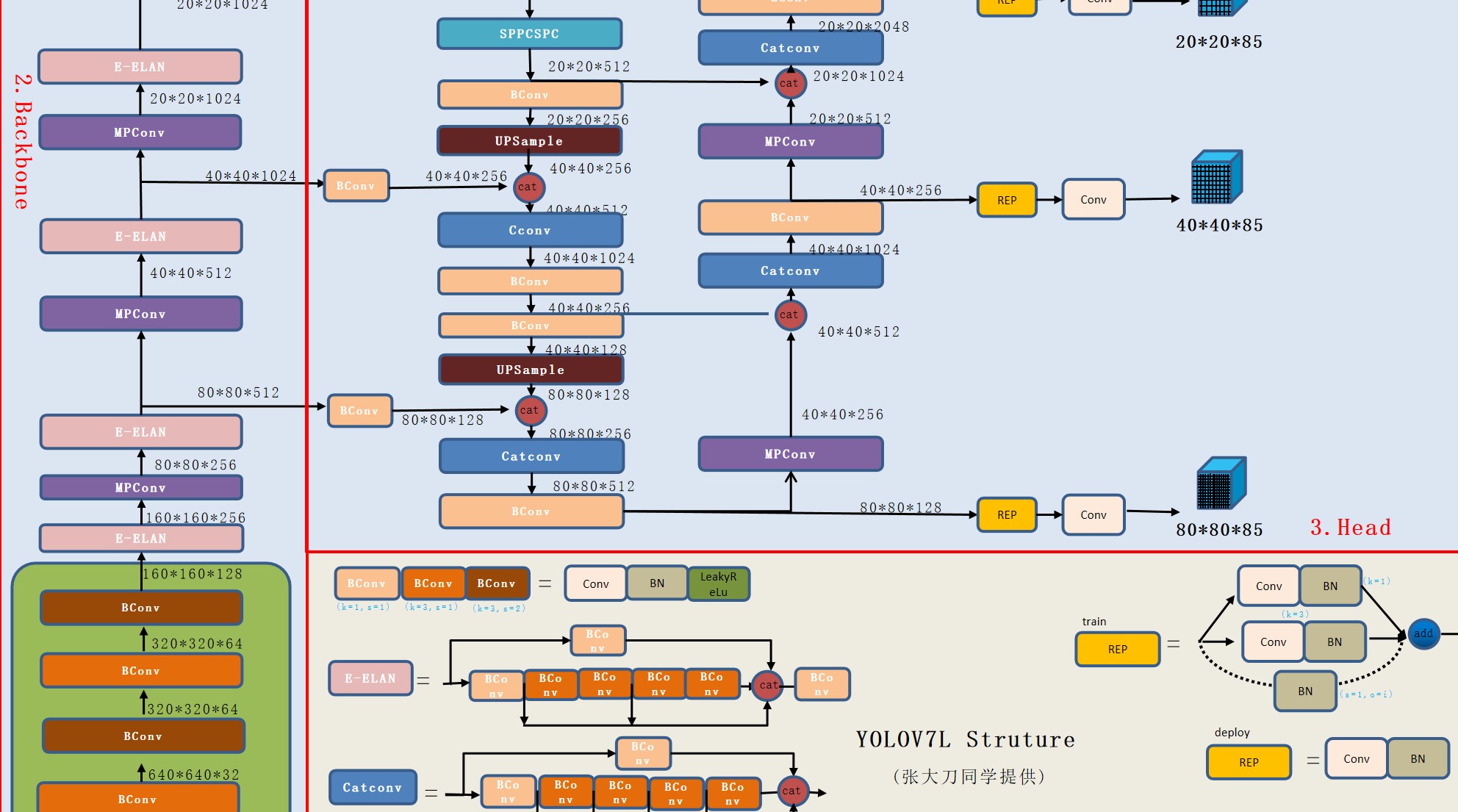 图1-1
图1-1
一:YOLO中所用到的模块以及网络
1:BConv
a):介绍
1:大致流程:
通常指的是CONV和BN的组合,同样是上述提到的优化的一部分,需要通过卷积,得到特征向量,最后使用激活函数
2:CONV层
提取一个局部区域特征,不同卷积核相当于不同的特质提取器。然而图像是二维的,为了更加充分的利用图像的局部信息,通常将神经元组织为三位结构的神经层,通常为高度(M)*宽度(N)*深度(N)。
特征映射为一副画像在卷积提取道德特征,每个特征可以作为一类抽取的图像特征,提高卷积网络的表现能力。可以再每一层用多个不同的特征映射。
输入层的特征映射是本身,如果是灰度图像特征映射只有一个,深度D=1,如果是彩色RGB,特征映射有三个,深度是D=3
二位转换四维:
1:由上述得知一张图片是单通道二维(如灰度)(M*N*1)
2:当输入为多通道(如RGB图像有P通道),需为每个通道分配独立二维核。此时卷积核变为m×n×P,每个通道的输入与对应核卷积后求和,输出仍为单通道(M'×N'×1)
3:四维卷积核:为生成多通道输出(Q通道),需重复三维卷积操作Q次。每次使用不同的m×n×P核组,最终堆叠Q个结果,形成M'×N'×Q输出。因此卷积核升维为m×n×P×Q,其中P对应输入通道,Q对应输出通道13。
示例:输入5通道图像(100×100×5),用10个3×3核处理时,卷积核为10×5×3×3,输出为98×98×103。
3:BN层:
BN做归一化在训练过程中加速收敛过程,并提高模型的稳定性。它的基本思想是对每个小批量(batch)的输入进行归一化处理,使得每个小批次的输入数据具有相同的分布和尺度,
4:silu激活函数或Swish激活函数:
特点:具有平滑性,非线性,非单调性
比RULE的优势在于:无区域死亡,自适应性,零中心性
b):过程
conv-->bn--->silu
代码如下
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): #groups (int, optional) – 从输入通道到输出通道的阻塞连接数。默认值:1
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self,x): ##普通前向传播 (forward
return self.act(self.bn(self.conv(x)))
def fuseforward(self,x):###正对yolo里面的已经融合的模型前向传播
return self.act(self.conv(x))2:E-ELAN
ELAN作为基础模块将不同层的特征信息进行融合,以增强模型对目标特征的学习能力。 这么多堆叠其实对应了更密集的残差结构,残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题
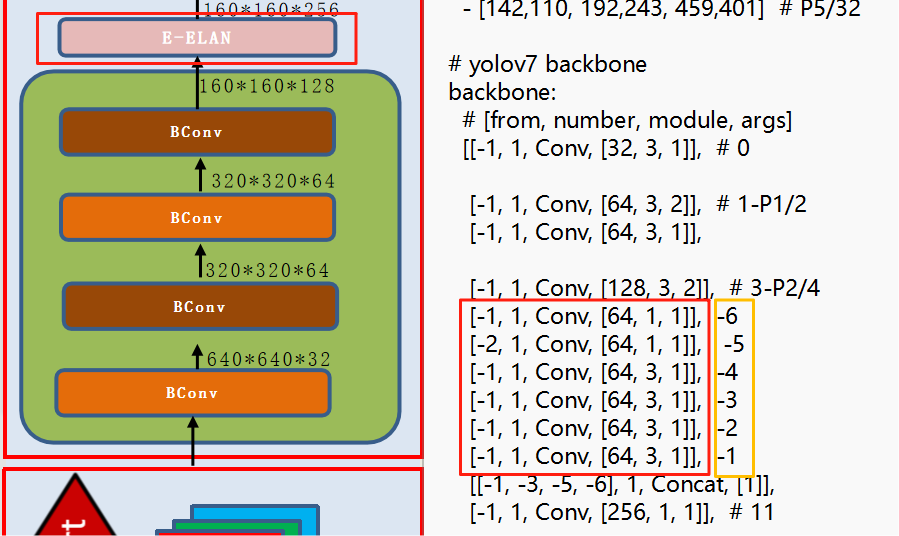
图2-1
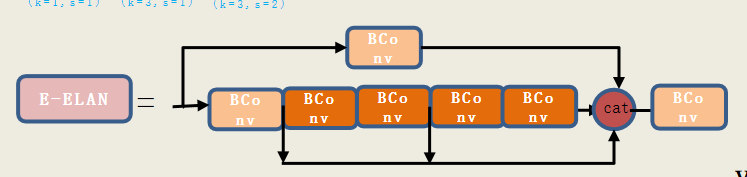 图2-2
图2-2
根据上述图2-2可以看出,数据最终的数据,是由两条路线进行合并得出的结果,通过图片 先了解上面的参数代表什么,from(层数),number(数量 ),model(模型 ),args(卷积核,步长,padding),黄色的框以便下面阐述,图2-1就是图2-2的模型流程,在3-p2/4位置进行卷积得到下一层,-5标注的位置也是通过3-p2/4得到,后面的卷积都是通过上一层进行卷积,因此-5和-6数据是同等,因此根据图2-2得知-1,-3,-5,-6连接在一起就是E-ELAN
3:MPConv
这是一种基于多路径卷积实现的模块,旨在提高卷积的效率和准确性,从而提升目标检测算法的速度和精度,他的网络结构相对简单很多
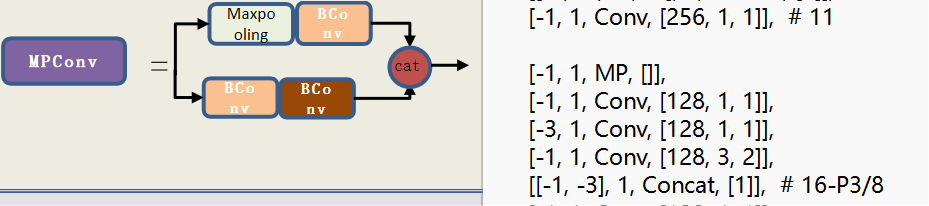
图3-1
这一层就相当于当我们的卷积核是256,我们首先一级处理,一部分提取macpoing,另一部分卷积 ,最后分别在做一次卷积,最后相结合,通过图片右侧的数据可以看出来,每一层都对上一次卷积,除了第四行,对前第三行进行卷积,就是图右边下面黄色的卷积相互对应。最后链接得到MP
4:Catconv
主要作用是将不同层的特征图进行拼接,从而融合不同层次的信息,增强模型的表示能力。通过将多个特征图在通道维度上进行拼接,CatConv模块可以帮助模型更好地理解和识别复杂的场景和对象
5:UpSample
通常用于特征图的尺寸放大。具体来说,当特征图经过某些操作(如卷积或池化)后,其尺寸可能会变小,这时需要通过上采样来恢复其原始尺寸,主要特征是回复特征图尺寸,特征融合
6:SPPCSPC
增加模型的感受野并提升模型在不同分辨率图像上的适应性,通过多个池化层,对特征图进行不同尺度的池化操作,提取多尺度的上下文信息,将特征图分成几个部分,分别进行处理后再合并,减少计算量的同时增强特征的学习能力
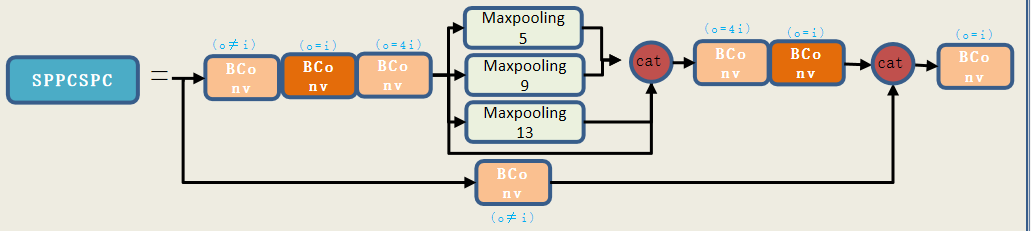
图6-1
如图,流程和前面几个模块一样,一条路通过上层卷积进行卷积处理,另一条路通过多次卷积再进行三种不同程度的池化合并之后再进行两次卷积,最后将两条路合并
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))7:REP
结合了重参数化(Reparameterization)技术,在训练和推理阶段结构不同,以提升模型的精度与速度。在以下主要是以融合3*3和1*1卷积以及残差的融合,并且卷积和BN的融合处理。
RepConv 是一个可重参数化的卷积模块,通常由多个并行分支组成(如 3x3 卷积、1x1 卷积、残差连接等),在训练时保持多分支结构,在推理时将这些分支融合为一个等效的 3x3 卷积
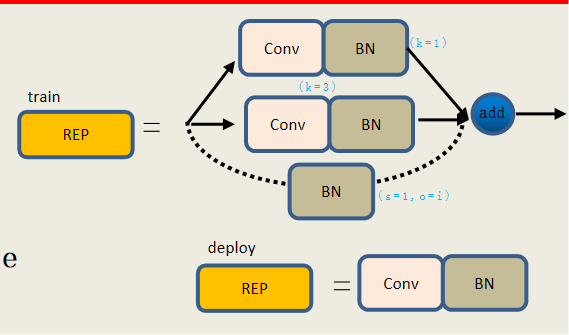
图7-1
当是deploy的时候直接通过卷积+BN得出结果,如果是训练的时候,需要构建三个分支 3x3 Conv + BN, 1x1 Conv + BN,残差连接
程序构造:
融合准备阶段:fuse_repvgg_block
作用:在部署前调用,将多个分支融合成一个等效的 3x3 卷积层。
关键步骤:
调用 fuse_conv_bn 融合每个分支的 Conv + BN
将 1x1 卷积核扩展为 3x3 形式
构造 Identity 分支的等效 3x3 卷积核
所有分支权重和偏置相加后赋值给 输出数据
删除冗余分支并设置 deploy=True
卷积与BN融合函数:fuse_conv_bn
作用:将 Conv + BatchNorm 层融合为一个带偏置的卷积层。
核心操作:
归一化卷积权重与偏置
返回融合后的卷积层对象
获取等效参数:get_equivalent_kernel_bias
作用:获取融合后的等效卷积核与偏置。
调用子函数:
_fuse_bn_tensor ➤ 获取单个分支的等效参数
pad_1x1_to_3x3_tensor ➤ 将 1x1 卷积核填充为 3x3
BN张量融合:_fuse_bn_tensor
作用:从给定分支(如 Sequential 或 BN)中提取等效的卷积核和偏置。
支持类型:
nn.Sequential ➤ Conv + BN
nn.BatchNorm2d ➤ Identity 分支构造单位矩阵作为卷积
导出模型参数:repvgg_convert
| 阶段 | 调用函数顺序 |
| 训练阶段 | init ➝ forward |
| 推理部署前 | init ➝ fuse_repvgg_block ➝ forward |
| 模型导出 | init ➝ fuse_repvgg_block ➝ repvgg_convert |
class RepConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy=deploy ###测试
self.groups=g
self.in_channels=c1
self.out_channels=c2
assert k==3
assert autopad(k,p)==1
padding_1= autopad(k, p) - k // 2
self.act = SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d(c1, c2, 1, s, padding_1, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self,inputs):
if hasattr(self, "rbr_repgram"):return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:id_out = 0
else:id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return (
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
bias3x3 + bias1x1 + biasid,
)
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None: return 0
else:nn.functional.pad(kernel1x1,[1,1,1,1])
def _fuse_bn_tensor(self, branch):
'''
融合权重和偏执
输入:一个包含 Conv + BN 的分支。
输出:融合后的卷积核 [weight, bias]。
:param branch:
:return:
'''
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros(
(self.in_channels, input_dim, 3, 3), dtype=np.float32
)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return (kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),)
def fuse_conv_bn(self,conv,bn):
std=(bn.running_var+bn.eps).sqrt()
bias=bn.bias- bn.running_mean * bn.weight / std
t = (bn.weight / std).reshape(-1, 1, 1, 1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels=conv.in_channels,
out_channels=conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
dilation=conv.dilation,
groups=conv.groups,
bias=True,
padding_mode=conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)
return conv
def fuse_repvgg_block(self): #来启用推理优化路径。
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1]) #2. 融合 rbr_dense 分支(3x3 Conv + BN)
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
'''获取 1x1 分支的偏置,并扩展其卷积核为 3x3'''
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
'''处理 Identity 分支(即残差连接)'''
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity,
nn.modules.batchnorm.SyncBatchNorm)):
# print(f"fuse: rbr_identity == BatchNorm2d or SyncBatchNorm")
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()###去除大小为1的对角线。最终变成二维矩阵,方便设置对角线值。
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1.weight.data.fill_(0.0)#将整个权重矩阵填充为 0。,初始化为零矩阵后,再手动设置对角线为 1,构造单位矩阵。
identity_conv_1x1.weight.data.fill_diagonal_(1.0)##将权重矩阵的主对角线元素设为 1。得到一个单位矩阵,表示输入通道与输出通道一一对应。C_in == C_out == 64,那么现在权重是一个 64x64 的单位矩阵。
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)#将二维的单位矩阵 [C_out, C_in] 扩展为四维的卷积核 [C_out, C_in, 1, 1]。,.unsqueeze(2) → 在第 2 维增加一个维度 → [C_out, C_in, 1],unsqueeze(3) → 在第 3 维增加一个维度 → [C_out, C_in, 1, 1],构造出一个 1x1 卷积核
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
'''将所有分支的权重和偏置融合进 rbr_dense'''
bias_identity_expanded = torch.nn.Parameter(torch.zeros_like(rbr_1x1_bias))
weight_identity_expanded = torch.nn.Parameter(torch.zeros_like(weight_1x1_expanded))
self.rbr_dense.weight = torch.nn.Parameter(
self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None8:IDetect
用于实现目标检测任务中的 输出解码、坐标回归、分类预测 等功能。添加了隐式加法偏置和隐式乘法缩放增强特征表达能力(通俗的来说是使用了这两种算法优化了权重和偏置),并支持模型融合以提升推理效率。
再图像进行训练或者预测的时候,会挑选出多个正样本标注框,以下图作为例子,也许会只有一个蓝色的框是真实的需要的图像 ,但是再训练的过程中,会寻找最接近物体的框,再蓝色范围内的灰色虚线就是正样本,大概率存在我们需要的物体。
1:)正样本的分配策略
1.长宽差异 (在原始的比例范围内不能小于0.25倍,不能大于4倍数)
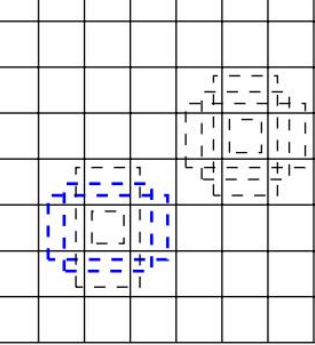 2:计算IOU:图像的交集/正样本的并级,大于一定范围 3:计算的类别需要根据损失排名之后在进行二次筛选
2:计算IOU:图像的交集/正样本的并级,大于一定范围 3:计算的类别需要根据损失排名之后在进行二次筛选
程序解读
在训练数据的时候,使用前向传播,通过卷积,缩放,偏置得到特征的转换,锚框解码、坐标转换,进行图像多样话,进行训练
在正式使用推理阶段通过训练得到的加法偏置和隐式乘法缩算法数据融合到权重和偏置中,主要用于部署优化和提升推理速度,移除冗余模块;同时需要优化路径
2):输出的几种方式:
1:训练数据直接输出
2:推理结果之后直接使用到ONNX模型输出,提高模型的性能和效率以及节约存储空间和传输宽带
3:推理结果之后选择NMS 负责筛除重复预测,保留最优结果
4:推理结果之后直接拼接输出
5:普通推理输出
分别使用场景
| 场景 | 描述 | |
| NMS | 单图推理 | 输入一张图片,模型输出多个边界框,需要去除重复预测 |
| NMS | 批量推理 | 多张图片同时推理,每张图片独立进行 NMS |
| ONNX | 边缘设备部署/工业质检系统集成性能优化测试 | 导出为 ONNX 后,在 C++、TensorRT 等部署环境中使用 NMS 层,测试不同推理框架性能差异 |
| NMS | 视频/摄像头实时检测 | 实时流处理中,每帧图像都需要执行一次 NMS |
| 拼接输出 | 自定义后处理模块 | 自己实现 NMS 或其他筛选逻辑 |
| 拼接输出 | 数据格式标准化 | 接口统一,便于封装成 API |
| 拼接输出 | 多任务联合输出 | 与其他检测头拼接输出 |
| 普通推理输出 |
模型训练过程/中间特征分析/ 模型调试阶段 |
需要原始输出参与损失计算/ 可视化特征图或做注意力分析/ 检查各层输出是否合理 |
class IDetect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
end2end = False
include_nms = False
concat = False
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(IDetect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.ia = nn.ModuleList(ImplicitA(x) for x in ch)
self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch)
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](self.ia[i](x[i])) # conv
x[i] = self.im[i](x[i])
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def fuseforward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else:
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = xy * (2. * self.stride[i]) + (self.stride[i] * (self.grid[i] - 0.5)) # new xy
wh = wh ** 2 * (4 * self.anchor_grid[i].data) # new wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
if self.training:
out = x
elif self.end2end:###如果启用了端到端推理(例如部署时 ONNX 推理)。
out = torch.cat(z, 1)
elif self.include_nms: #如果需要包含 NMS(非极大值抑制)逻辑。
z = self.convert(z)
out = (z,)
elif self.concat: #如果启用了输出拼接模式。
out = torch.cat(z, 1)
else:#适用于普通推理流程。
out = (torch.cat(z, 1), x)
return out
def fuse(self):
print("IDetect.fuse")
# fuse ImplicitA and Convolution
for i in range(len(self.m)):
c1, c2, _, _ = self.m[i].weight.shape
c1_, c2_, _, _ = self.ia[i].implicit.shape
self.m[i].bias += torch.matmul(self.m[i].weight.reshape(c1, c2),
self.ia[i].implicit.reshape(c2_, c1_)).squeeze(1)
# fuse ImplicitM and Convolution
for i in range(len(self.m)):
c1, c2, _, _ = self.im[i].implicit.shape
self.m[i].bias *= self.im[i].implicit.reshape(c2)
self.m[i].weight *= self.im[i].implicit.transpose(0, 1)
@staticmethod
def _make_grid(nx=20, ny=20):###生成格子坐标
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def convert(self, z):
z = torch.cat(z, 1)
box = z[:, :, :4]
conf = z[:, :, 4:5]
score = z[:, :, 5:]
score *= conf
convert_matrix = torch.tensor([[1, 0, 1, 0], [0, 1, 0, 1], [-0.5, 0, 0.5, 0], [0, -0.5, 0, 0.5]],
dtype=torch.float32,
device=z.device)
box @= convert_matrix
return (box, score)
| 阶段 | 调用函数顺序 |
| 训练阶段 | init ➝ forward(前向传播) |
| 推理部署前 | init ➝ fuse(融合参数) ➝ fuseforward(推理路径) |
| 模型导出 | init ➝ fuse ➝ convert(后处理转换) |

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)