C++之fmt库介绍和使用(1)
本文介绍了C++中的fmt库,一个现代化的格式化库,旨在替代传统的iostream和printf方法。fmt库由Victor Zverovich开发,具有安全性、可扩展性、高性能、Unicode支持、快速编译、小二进制体积、可移植性和开源等特点。文章详细列举了fmt库的主要特性,并提供了性能对比数据,显示fmt库在速度和效率上优于其他常见格式化方法。此外,文章还介绍了fmt库的编译时间和代码膨胀测
C++之fmt库介绍与使用(1)
Author: Once Day Date: 2025年5月12日
一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦…
漫漫长路,有人对你微笑过嘛…
全系列文章可参考专栏: 源码分析_Once-Day的博客-CSDN博客
参考文章:
文章目录
1. 介绍
1.1 概述
fmtlib是一个现代化的C++格式化库,它提供了一种安全、高效、灵活的方式来格式化和输出文本。该库由Victor Zverovich开发,旨在替代C++标准库中的iostream和printf等传统格式化方法。
使用fmtlib非常简单,只需包含fmt/core.h头文件,然后使用fmt::format()函数或fmt::print()函数即可。例如:
#include <fmt/core.h>
int main() {
std::string name = "Alice";
int age = 18;
fmt::print("Her name is {} and she is {} years old.\n", name, age);
return 0;
}
以上代码将输出:“Her name is Alice and she is 18 years old.”
fmtlib具有具有如下的特性:
(1)安全性:受 Python 格式化功能的启发,{fmt} 为printf系列函数提供了安全的替代方案。格式字符串中的错误在 C 语言中是常见的漏洞来源,而在 {fmt} 中,这类错误会在编译时被报告出来。
fmt::format("{:d}", "I am not a number");
上述代码会产生编译时错误,因为d不是字符串的有效格式说明符。像fmt::format这样的 API 通过自动内存管理来防止缓冲区溢出错误。
(2)可扩展性:{fmt} 开箱即支持大多数标准类型的格式化,包括所有容器、日期和时间。例如:
fmt::print("{}", std::vector{1, 2, 3});
上述代码会以类似 JSON 的格式打印向量:
[1, 2, 3]
你可以让自己定义的类型支持格式化,甚至还能对它们进行编译时检查。
(3)性能:{fmt} 比输入输出流(iostreams)和sprintf快 20 - 30 倍,在数值格式化方面表现尤为突出。

{fmt} 库尽量减少动态内存分配,并且可以选择将格式字符串编译为最优代码。
(4)Unicode 支持:{fmt} 在主要操作系统上通过 UTF - 8 和char字符串提供可移植的 Unicode 支持。例如:
fmt::print("Слава Україні!");
上述代码在 Linux、macOS 甚至 Windows 控制台上都能正确打印,而无需考虑代码页问题。
{fmt} 默认与区域设置无关,但你也可以选择进行本地化格式化,{fmt} 能够使其与 Unicode 协同工作,解决了标准库中存在的相关问题。
(5)快速编译:该库广泛使用类型擦除技术来实现快速编译。fmt/base.h提供了一部分 API,其包含的依赖关系极少,并且具备足够的功能来替代所有*printf的使用场景。
使用 {fmt} 的代码编译速度通常比等效的输入输出流代码快几倍。虽然printf的编译速度仍然更快,但两者之间的差距正在逐渐缩小。
(6)较小的二进制体积:类型擦除技术还用于防止模板膨胀,从而生成紧凑的单次调用二进制代码。例如,调用带单个参数的fmt::print仅需几条指令,尽管它增加了运行时安全性,但其二进制体积与printf相当,并且比等效的输入输出流代码小得多。
该库本身的二进制体积较小,像浮点格式化这样的一些组件可以被禁用,以便在资源受限的设备上进一步减小其体积。
(7)可移植性:{fmt} 拥有一个小巧且自包含的代码库,其核心仅由三个头文件组成,并且没有外部依赖。
该库具有高度的可移植性,仅需要 C++11 的一小部分特性,这些特性在 GCC 4.9、Clang 3.4、MSVC 19.10(2017)及更高版本中均可用。如果编译器和标准库支持更新的特性,{fmt} 会加以利用,从而启用更多功能。
在可能的情况下,格式化函数的输出在各个平台上保持一致。
在可能的情况下,格式化函数的输出在各个平台上保持一致。
(8)开源:{fmt} 是 GitHub 上排名前一百的开源 C++ 库,拥有数百名贡献者。
该库基于宽松的 MIT 许可证分发,被许多开源项目所依赖,包括 Blender、PyTorch、苹果的 FoundationDB、Windows Terminal、MongoDB 等。
fmtlib的主要特点包括:
- 简单的 格式化 API,支持位置参数以方便本地化。
- 实现了 C++20 的
std::format和 C++23 的std::print。 - 格式化字符串语法 类似于 Python 的 format。
- 快速的 IEEE 754 浮点数格式化器,使用 Dragonbox 算法,保证正确的舍入、最短表示和往返转换。
- 可移植的 Unicode 支持。
- 安全的 printf 实现,包括支持位置参数的 POSIX 扩展。
- 可扩展性:支持用户自定义类型。
- 高性能:比常见的标准库实现(如
(s)printf、iostreams、to_string)更快。 - 安全性:该库是完全类型安全的,格式化字符串中的错误可以在编译时报告,自动内存管理可防止缓冲区溢出错误。
- 易用性:代码库小巧且自包含,无外部依赖,采用宽松的 MIT 许可证。
- 可移植性:跨平台输出一致,支持较旧的编译器。
- 代码干净,即使在高警告级别(如
-Wall -Wextra -pedantic)下也无警告。 - 默认与区域设置无关。
- 可通过
FMT_HEADER_ONLY宏启用可选的仅头文件配置。
1.2 性能对比
{fmt}是基准测试中最快的方法,比printf快约20%。
| Library | Method | Run Time, s |
|---|---|---|
| libc | printf | 0.91 |
| libc++ | std::ostream | 2.49 |
| {fmt} 9.1 | fmt::print | 0.74 |
| Boost Format 1.80 | boost::format | 6.26 |
| Folly Format | folly::format | 1.87 |
上述结果是在macOS 12.6.1上使用clang++ -O3 -DNDEBUG -DSPEED_TEST -DHAVE_FORMAT编译tinyformat_test.cpp,并取三次运行中的最佳结果生成的。
在测试中,格式字符串%0.10f:%04d:%+g:%s:%p:%c:%%\n或等效字符串被填充2,000,000次,输出被发送到/dev/null;
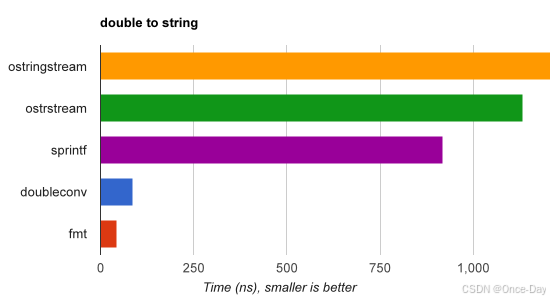
在IEEE754浮点数和双精度格式化(dtoa-benchmark)方面,{fmt}比std::ostringstream和sprintf快20-30倍,并且比double-conversion和ryu更快:

1.3 编译时间和代码膨胀
format-benchmark中的脚本bloat-test.py测试了非平凡项目的编译时间和代码膨胀。它生成100个翻译单元,并在每个单元中使用printf()或其替代方法五次,以模拟一个中等规模的项目。生成的可执行文件大小和编译时间(Apple clang version 15.0.0 (clang-1500.1.0.2.5),macOS Sonoma,三次中的最佳结果)如下表所示。
优化构建(-O3):
| Method | Compile Time, s | Executable size, KiB | Stripped size, KiB |
|---|---|---|---|
| printf | 1.6 | 54 | 50 |
| IOStreams | 25.9 | 98 | 84 |
| fmt 83652df | 4.8 | 54 | 50 |
| tinyformat | 29.1 | 161 | 136 |
| Boost Format | 55.0 | 530 | 317 |
{fmt}编译速度快,在每次调用的二进制大小方面与printf相当(在此系统上在舍入误差范围内)。
非优化构建:
| Method | Compile Time, s | Executable size, KiB | Stripped size, KiB |
|---|---|---|---|
| printf | 1.4 | 54 | 50 |
| IOStreams | 23.4 | 92 | 68 |
| {fmt} 83652df | 4.4 | 89 | 85 |
| tinyformat | 24.5 | 204 | 161 |
| Boost Format | 36.4 | 831 | 462 |
libc、lib(std)c++和libfmt都作为共享库进行链接,以仅比较格式化函数的开销。Boost Format是一个仅包含头文件的库,因此它不提供任何链接选项。
1.4 CMake编译
{fmt} 提供了两个 CMake 目标:fmt::fmt用于编译库,fmt::fmt-header-only用于仅包含头文件的库。为了缩短构建时间,建议使用编译库。
在 CMake 中使用 {fmt} 主要有三种方式:
FetchContent:从 CMake 3.11 开始,可以使用FetchContent在配置时自动下载 {fmt} 作为依赖项:
include(FetchContent)
FetchContent_Declare(
fmt
GIT_REPOSITORY https://github.com/fmtlib/fmt
GIT_TAG e69e5f977d458f2650bb346dadf2ad30c5320281) # 10.2.1
FetchContent_MakeAvailable(fmt)
target_link_libraries(<your-target> fmt::fmt)
已安装版本:可以在CMakeLists.txt文件中查找并使用已安装的 {fmt} 版本,如下所示:
find_package(fmt)
target_link_libraries(<your-target> fmt::fmt)
嵌入方式:可以将 {fmt} 的源文件目录添加到项目中,并在CMakeLists.txt文件中包含它:
add_subdirectory(fmt)
target_link_libraries(<your-target> fmt::fmt)
安装发布版本:要在 Ubuntu 的 Linux 发行版上安装 {fmt},请使用以下命令:
apt install libfmt-dev
从源代码构建:CMake 通过生成原生的 makefile 或项目文件来工作,这些文件可以在你选择的编译器环境中使用。典型的工作流程如下:
mkdir build # 创建一个目录来存放构建输出。
cd build
cmake .. # 生成原生构建脚本。
常见的Cmake编译构建选项如下所示:
# 编译 thirdparty/fmt-11.1.4
# FMT_MASTER_PROJECT=OFF 非主项目
# FMT_UNICODE=OFF 不支持Unicode
$SOURCE_DIR/devops/scripts/cmake_build.sh thirdparty/fmt-11.1.4 \
-DFMT_MASTER_PROJECT=OFF \
-DFMT_UNICODE=OFF
2. API介绍
{fmt} 库的 API 由以下组件构成:
- fmt/base.h:基础 API,提供面向 char/UTF-8 的主要格式化函数,具备 C++20 编译时检查功能,且依赖极少。
- fmt/format.h:包含 fmt::format 及其他格式化函数,同时提供本地化支持。
- fmt/ranges.h:用于格式化范围(ranges)和元组(tuples)。
- fmt/chrono.h:实现日期和时间的格式化。
- fmt/std.h:为标准库类型提供格式化器。
- fmt/compile.h:用于格式化字符串编译。
- fmt/color.h:提供终端颜色和文本样式功能。
- fmt/os.h:包含系统相关 API。
- fmt/ostream.h:提供对 std::ostream 的支持。
- fmt/args.h:支持动态参数列表。
- fmt/printf.h:提供安全的 printf 功能。
- fmt/xchar.h:提供可选的 wchar_t 支持。
该库提供的所有函数和类型都位于 fmt 命名空间中,而宏则以 FMT_ 为前缀。
2.1 基础API
fmt/base.h 定义了基础 API,它为 char/UTF-8 提供主要的格式化函数,并具备 C++20 编译时检查功能。为了优化编译速度,它的头文件依赖被减至最少。这个头文件仅在将 {fmt} 作为库使用时(默认方式)才有优势,在仅头文件模式下并无作用。它还为以下类型提供了格式化器特化:
int,long longunsigned,unsigned long longfloat,double,long doubleboolcharconst char*,fmt::string_viewconst void*
以下函数使用的格式字符串语法类似于 Python 中 str.format 的语法。它们接受 fmt 和 args 作为参数:
fmt是一个格式字符串,包含普通文本和用花括号{}包围的替换字段。这些字段会在结果字符串中被格式化为对应的参数。fmt::format_string是一种格式字符串,它可以从字符串字面量或constexpr字符串隐式构造,并在 C++20 中进行编译时检查。若要传递运行时格式字符串,需将其包装在fmt::runtime中。args是一个参数列表,表示要格式化的对象。
除非另有说明,I/O 错误会以 std::system_error 异常的形式报告。
template <typename... T>
void print(format_string<T...> fmt, T&&... args);
fmt::print("The answer is {}.", 42);
根据 fmt 中的规范格式化 args,并将输出写入标准输出(stdout)。
template <typename... T>
void print(FILE* f, format_string<T...> fmt, T&&... args);
fmt::print(stderr, "Don't {}!", "panic");
根据 fmt 中的规范格式化 args,并将输出写入文件 f。
template <typename... T>
void println(format_string<T...> fmt, T&&... args);
根据 fmt 中的规范格式化 args,将输出写入标准输出(stdout),并在末尾添加一个换行符。
template <typename... T>
void println(FILE* f, format_string<T...> fmt, T&&... args);
根据 fmt 中的规范格式化 args,将输出写入文件 f,并在末尾添加一个换行符。
template <typename OutputIt, typename... T>
auto format_to(OutputIt&& out, format_string<T...> fmt, T&&... args) -> remove_cvref_t<OutputIt>;
auto out = std::vector<char>();
fmt::format_to(std::back_inserter(out), "{}", 42);
根据 fmt 中的规范格式化 args,将结果写入输出迭代器 out,并返回指向输出范围末尾之后的迭代器。format_to 不会追加终止空字符。
template <typename OutputIt, typename... T>
auto format_to_n(OutputIt out, size_t n, format_string<T...> fmt, T&&... args) -> format_to_n_result<OutputIt>;
根据 fmt 中的规范格式化 args,将结果的最多 n 个字符写入输出迭代器 out,并返回总输出大小(未截断)和指向输出范围末尾之后的迭代器。format_to_n 不会追加终止空字符。
template <typename OutputIt>
struct format_to_n_result;
OutputIt out;:指向输出范围末尾之后的迭代器。size_t size;:总输出大小(未截断)。
template <typename... T>
auto formatted_size(format_string<T...> fmt, T&&... args) -> size_t;
返回 format(fmt, args...) 输出的字符数。
2.2 格式化用户定义类型
{fmt} 库为许多标准 C++ 类型提供了格式化器。有关范围(ranges)和元组(包括 std::vector 等标准容器)的格式化器,请参阅 fmt/ranges.h;有关日期和时间的格式化器,请参阅 fmt/chrono.h;有关其他标准库类型的格式化器,请参阅 fmt/std.h。
有两种方法可以使自定义类型支持格式化:提供 format_as 函数或特化 formatter 结构体模板。
如果你希望将自定义类型按照另一种具有相同格式说明符的类型进行格式化,可以使用 format_as 方法。该函数应接受你的类型对象,并返回一个可格式化类型的对象。它应与你的类型定义在同一命名空间中。
#include <fmt/format.h>
namespace kevin_namespacy {
enum class film {
house_of_cards, american_beauty, se7en = 7
};
auto format_as(film f) { return fmt::underlying(f); }
}
int main() {
fmt::print("{}\n", kevin_namespacy::film::se7en); // 输出: 7
}
下面这种方法更复杂,但能完全控制解析和格式化过程。要使用此方法,需为你的类型特化 formatter 结构体模板,并实现 parse 和 format 方法。
推荐的定义格式化器的方法是通过继承或组合复用现有的格式化器。这样可以支持标准格式说明符而无需自己实现。例如:
// color.h:
#include <fmt/base.h>
enum class color {red, green, blue};
template <> struct fmt::formatter<color>: formatter<string_view> {
// parse 方法继承自 formatter<string_view>。
auto format(color c, format_context& ctx) const
-> format_context::iterator;
};
// color.cc:
#include "color.h"
#include <fmt/format.h>
auto fmt::formatter<color>::format(color c, format_context& ctx) const
-> format_context::iterator {
string_view name = "unknown";
switch (c) {
case color::red: name = "red"; break;
case color::green: name = "green"; break;
case color::blue: name = "blue"; break;
}
return formatter<string_view>::format(name, ctx);
}
注意,formatter<string_view>::format 定义在 fmt/format.h 中,因此必须在源文件中包含该头文件。由于 parse 方法继承自 formatter<string_view>,它将识别所有字符串格式规范,例如:
fmt::format("{:>10}", color::blue)
将返回 " blue"。
一般来说,格式化器具有以下形式:
template <> struct fmt::formatter<T> {
// 解析格式说明符并将其存储在格式化器中。
//
// [ctx.begin(), ctx.end()) 是一个可能为空的字符范围,
// 包含从要解析的格式规范开始的格式字符串的一部分,例如在
//
// fmt::format("{:f} continued", ...);
//
// 该范围将包含 "f} continued"。格式化器应解析说明符直到 '}' 或范围结束。
// 在这个例子中,格式化器应解析 'f' 说明符并返回指向 '}' 的迭代器。
constexpr auto parse(format_parse_context& ctx)
-> format_parse_context::iterator;
// 使用存储在格式化器中的已解析格式规范格式化 value,
// 并将输出写入 ctx.out()。
auto format(const T& value, format_context& ctx) const
-> format_context::iterator;
};
建议至少支持适用于整个对象的填充(fill)、对齐(align)和宽度(width)选项,它们的语义应与标准格式化器中的相同。
你还可以为类层次结构编写格式化器:
// demo.h:
#include <type_traits>
#include <fmt/core.h>
struct A {
virtual ~A() {}
virtual std::string name() const { return "A"; }
};
struct B : A {
virtual std::string name() const { return "B"; }
};
template <typename T>
struct fmt::formatter<T, std::enable_if_t<std::is_base_of_v<A, T>, char>> :
fmt::formatter<std::string> {
auto format(const A& a, format_context& ctx) const {
return formatter<std::string>::format(a.name(), ctx);
}
};
// demo.cc:
#include "demo.h"
#include <fmt/format.h>
int main() {
B b;
A& a = b;
fmt::print("{}", a); // 输出: B
}
注意:不允许同时提供格式化器特化和 format_as 重载。
上下文类型定义:
template <typename Char>
using basic_format_parse_context = parse_context<Char>;
class context;
context(iterator out, format_args args, detail::locale_ref loc);
构造一个上下文对象。对象中存储了对参数的引用,因此请确保这些参数具有适当的生命周期。
using format_context = context;
2.3 编译时检测
在支持 C++20 consteval的编译器上,编译时格式字符串检查默认是启用的。在较旧的编译器上,你可以使用fmt/format.h中定义的FMT_STRING宏来替代。
和 Python 的str.format以及普通函数一样,{fmt} 允许存在未使用的参数。
template <typename Char, typename... T>
using basic_format_string = basic_fstring<Char, T...>;
template <typename... T>
using format_string = typename fstring<T...>::t;
auto runtime(string_view s) -> runtime_format_string<>;
创建一个运行时格式字符串。
// 在运行时而不是编译时检查格式字符串。
fmt::print(fmt::runtime("{:d}"), "I am not a number");
2.4 命名参数(Named Arguments)
template <typename Char, typename T>
auto arg(const Char* name, const T& arg) -> detail::named_arg<Char, T>;
返回一个用于格式化函数的命名参数。它只能在调用格式化函数时使用。
fmt::print("The answer is {answer}.", fmt::arg("answer", 42));
目前,编译时检查不支持命名参数。
2.5 类型擦除
你可以创建自己的具有编译时检查和较小二进制体积的格式化函数,例如:
#include <fmt/format.h>
void vlog(const char* file, int line,
fmt::string_view fmt, fmt::format_args args) {
fmt::print("{}: {}: {}", file, line, fmt::vformat(fmt, args));
}
template <typename... T>
void log(const char* file, int line,
fmt::format_string<T...> fmt, T&&... args) {
vlog(file, line, fmt, fmt::make_format_args(args...));
}
#define MY_LOG(fmt, ...) log(__FILE__, __LINE__, fmt, __VA_ARGS__)
MY_LOG("invalid squishiness: {}", 42);
注意,与完全参数化的版本相比,vlog 没有对参数类型进行参数化,这提高了编译速度并减小了二进制代码大小。
template <typename Context, typename... T, int NUM_ARGS, int NUM_NAMED_ARGS, unsigned long long DESC>
constexpr auto make_format_args(T&... args) -> detail::format_arg_store<Context, NUM_ARGS, NUM_NAMED_ARGS, DESC>;
构造一个存储对参数的引用的对象,并且该对象可以隐式转换为 format_args。Context 可以省略,在这种情况下它默认为 context。
template <typename Context>
class basic_format_args;
void vlog(fmt::string_view fmt, fmt::format_args args); // 正确
fmt::format_args args = fmt::make_format_args(); // 悬空引用
格式化参数集合的视图。为了避免生命周期问题,它应该仅用作类型擦除函数(如 vformat)中的参数类型:
constexpr basic_format_args(const store<NUM_ARGS, NUM_NAMED_ARGS, DESC>& s);
从 format_arg_store 构造一个 basic_format_args 对象。
constexpr basic_format_args(const format_arg* args, int count, bool has_named);
从动态参数列表构造一个 basic_format_args 对象。
auto get(int id) -> format_arg;
返回具有指定 id 的参数。
using format_args = basic_format_args<context>;
template <typename Context>
class basic_format_arg;
auto visit(Visitor&& vis) -> decltype(vis(0));
根据参数类型调用适当的 visit 方法来访问参数。例如,如果参数类型是 double,则将使用 double 类型的值调用 vis(value)。
2.6 兼容性
template <typename Char>
class basic_string_view;
basic_string_view 是针对 C++17 之前版本实现的 std::basic_string_view。它提供了该类型 API 的一个子集。即使存在 std::basic_string_view,fmt::basic_string_view 也会被用于格式字符串,这样做是为了防止在库和客户端代码使用不同的 -std 选项进行编译时出现问题(不推荐使用不同的 -std 选项)。
constexpr basic_string_view(const Char* s, size_t count);
从一个 C 字符串和一个大小构造一个字符串引用对象。
basic_string_view(const Char* s);
从一个 C 字符串构造一个字符串引用对象。
basic_string_view(const S& s);
从一个 std::basic_string 或 std::basic_string_view 对象构造一个字符串引用。
constexpr auto data() -> const Char*;
返回指向字符串数据的指针。
constexpr auto size() -> size_t;
返回字符串的大小。
using string_view = basic_string_view<char>;

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 39
39 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)