高级学习算法(神经网络 决策树)
神经网络 需求预测 图像识别 人脸识别 层 前向传播 TensorFlow 激活函数 ReLU 多类别分类 Softmax回归 多标签分类 高级优化方法 Adam算法 密集层 卷积层 模型评估 偏差与方差 正则化 学习曲线 误差分析 数据增强 数据合成 迁移学习 倾斜数据集 精确率 召回率 F1 Score 决策树 信息增益 独热编码 回归树 树集成 随机森林 XGBoost 梯度提升
目录
- 神经网络 (Neural networks)
-
- 神经网络的介绍
- 需求预测 (Demand Prediction)
- 例子:图像识别
- 神经网络中的层
- 更复杂的神经网络
- 推理:前向传播 (Forward Propagation)
- 代码中的推理
- TensorFlow中的数据
- 构建一个神经网络
- 在一个单层中的前向传播
- 前向传播的一般实现
- 通向 AGI 的可能性
- 神经网络如何高效实现
- 矩阵乘法
- TensorFlow实现
- 训练细节
- sigmoid的替代
- 选择激活函数
- 多类别分类 (Multiclass Classification)
- 多标签分类 (Multi-label Classification)
- 高级优化方法
- Aditional Layer Types
- 机器学习项目中下一步做什么
- 模型评估
- 模型选择和训练交叉验证测试集
- 诊断偏差和方差
- 正则化和偏差或方差
- 判断高偏差和高方差
- 学习曲线
- 再次决定下一步做什么
- 偏差或方差与神经网络
- 机器学习的迭代过程
- 误差分析
- 添加数据
- 迁移学习 (Transfer Learning)
- 机器学习项目的完整周期
- 倾斜数据集的误差指标
- 决策树 (Decision Tree)
神经网络 (Neural networks)
神经网络的介绍

NLP: Natural Language Processing
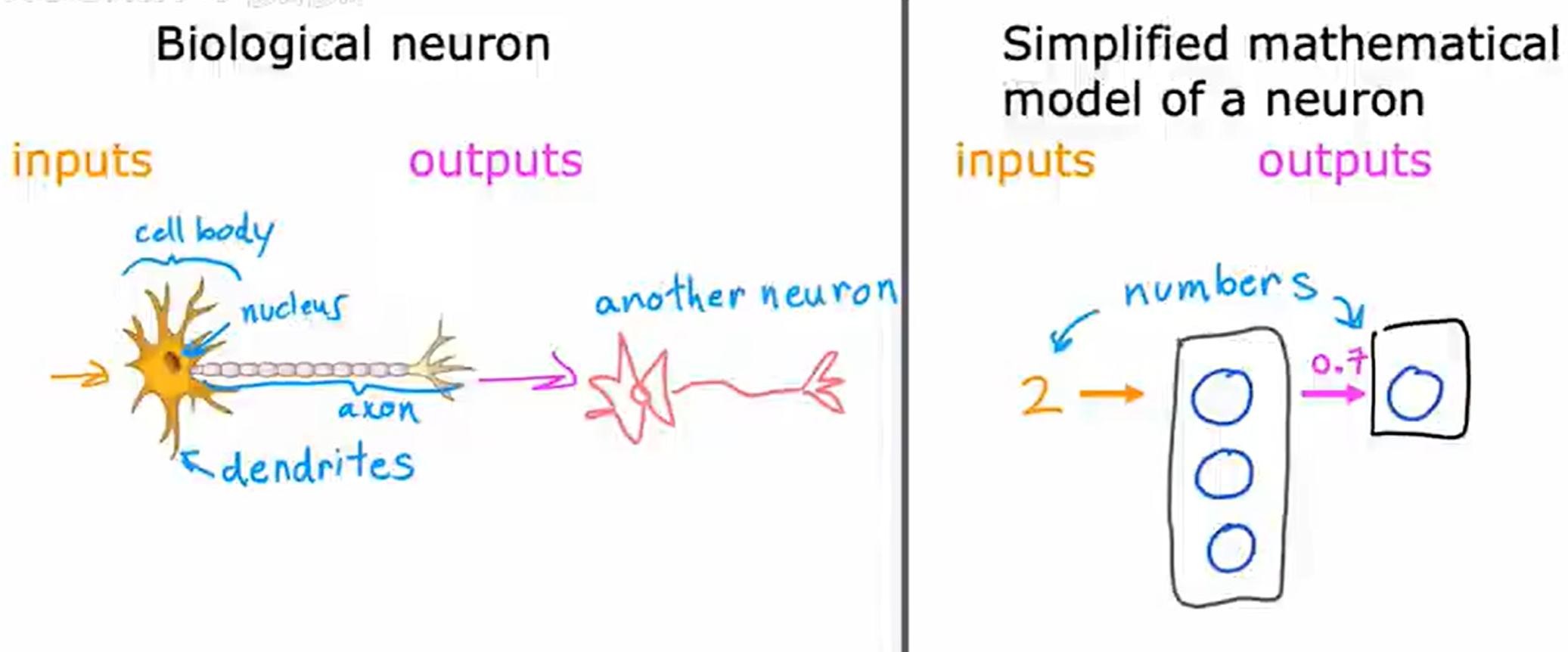
尽管初略将生物神经元和人工神经元进行类别,但如今对人脑如何工作还存疑问,因此盲目模仿人脑可能不会在构建真正的智能方面走得太远。即便是如此简化的神经元模型,依旧能够构建非常强大的深度学习算法。
Q: 为什么在过去几年里神经网络才真正的兴起?
【大数据量 + 高性能】
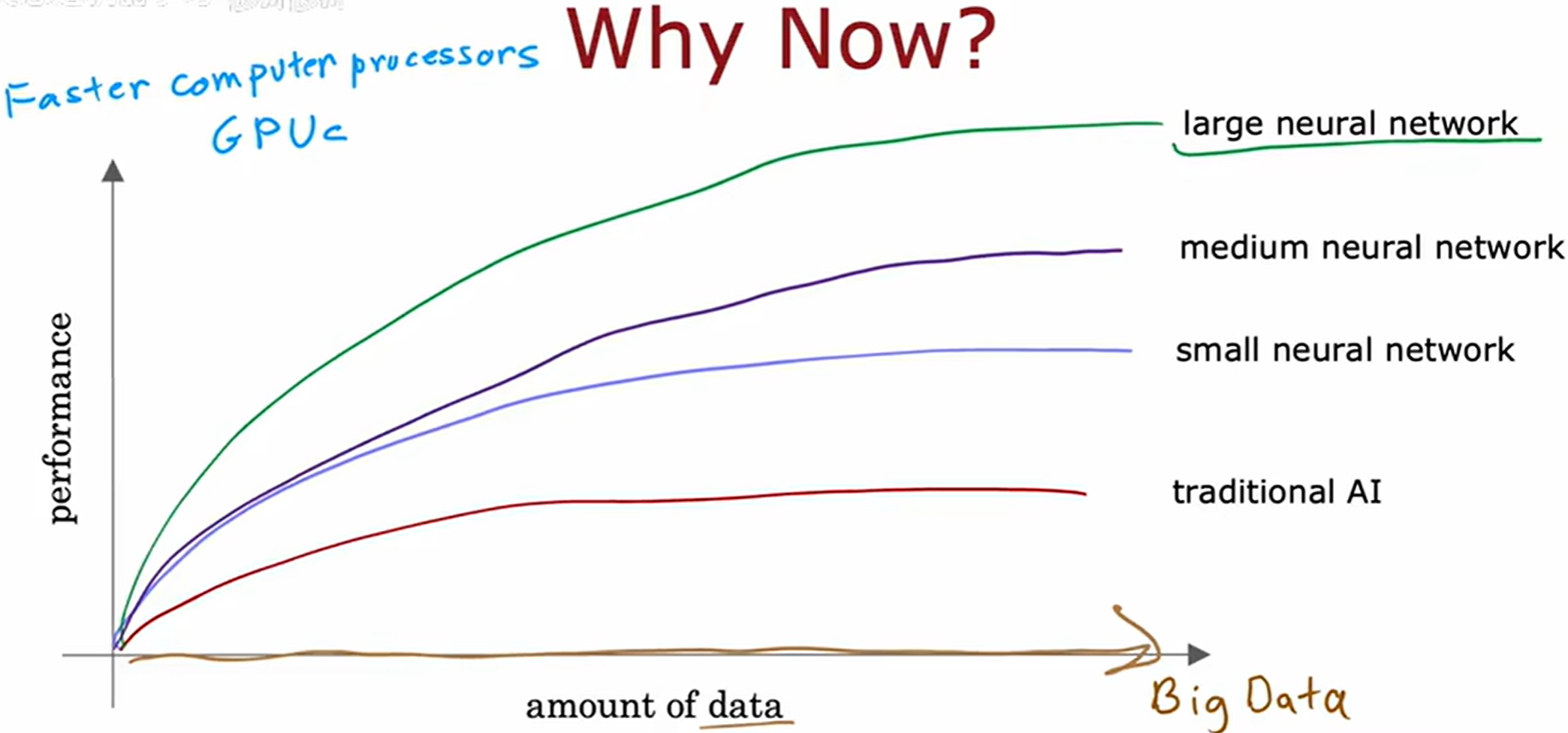
传统机器学习算法,例如逻辑回归和线性回归,即使给这些算法再多的数据,也很难让其性能不断提升。
传统机器学习算法在数据扩展性(Scalability)方面存在固有局限性,无法像现代大规模机器学习方法(如深度学习或分布式算法)那样高效利用海量数据。
越大型的神经网络(参数量越多)通常具备越强的数据扩展性(Data Scalability)
训练更大型的神经网络需要更高的计算性能
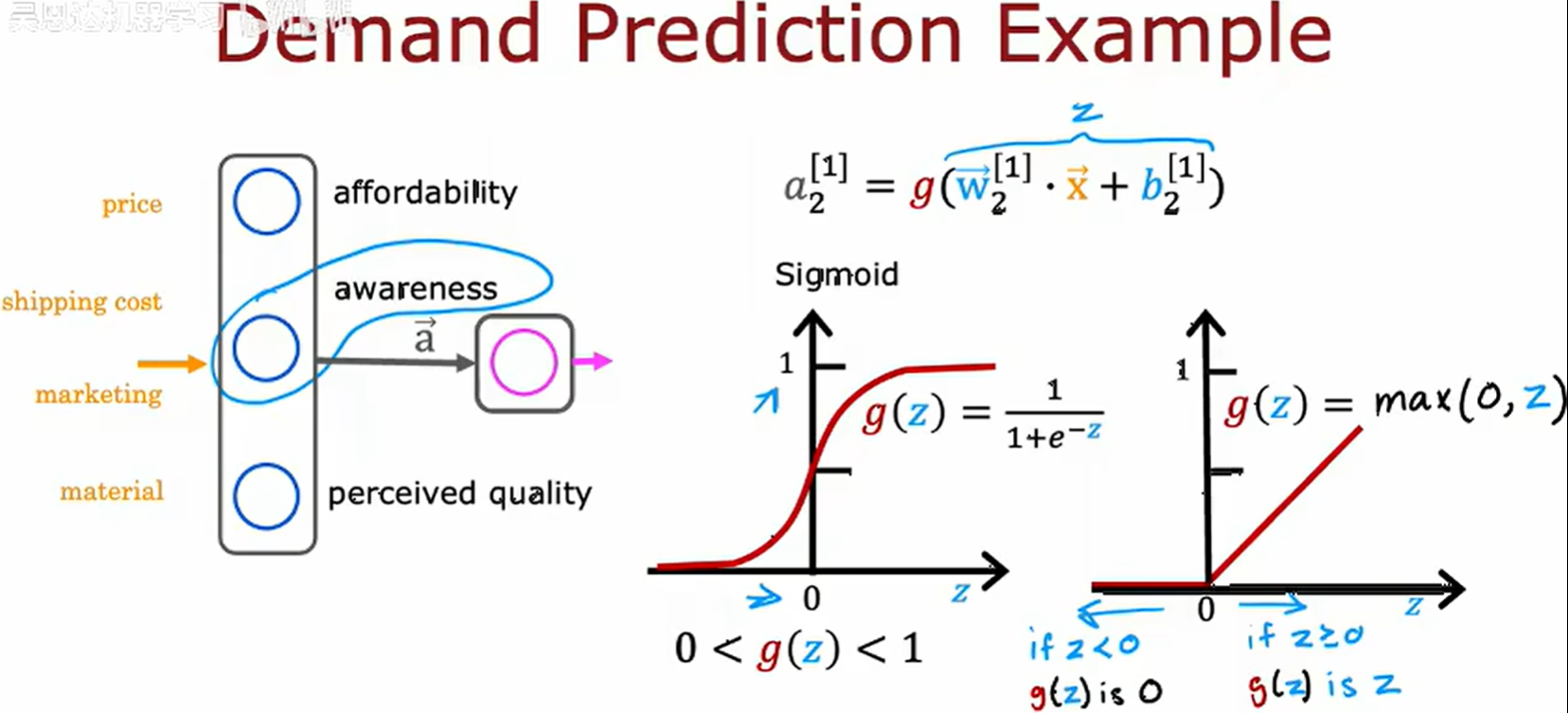
需求预测 (Demand Prediction)
activation ——激活
神经学中,指的是一个神经元向下游的其他神经元发送高输出的程度
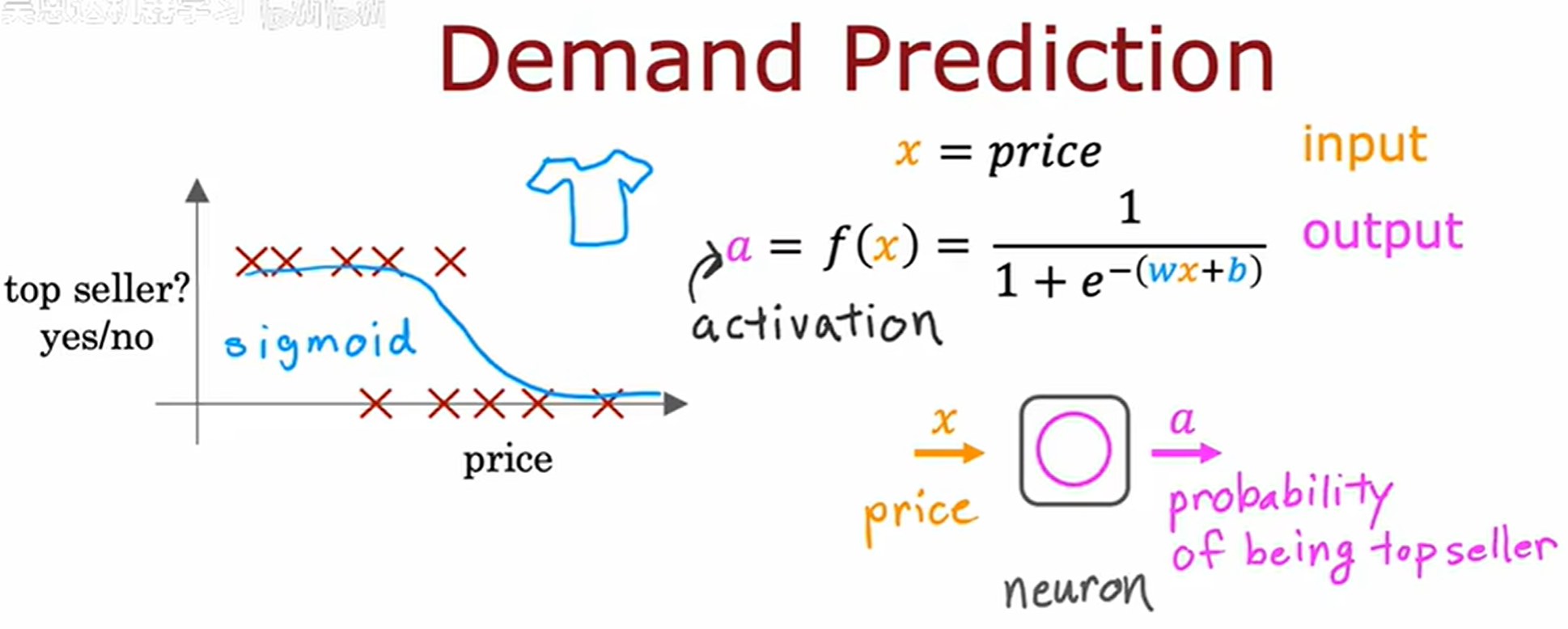
如图中的逻辑回归,可以作为大脑中单个神经元的简化模型。而构建神经网络只需要把这些神经元组合在一起。

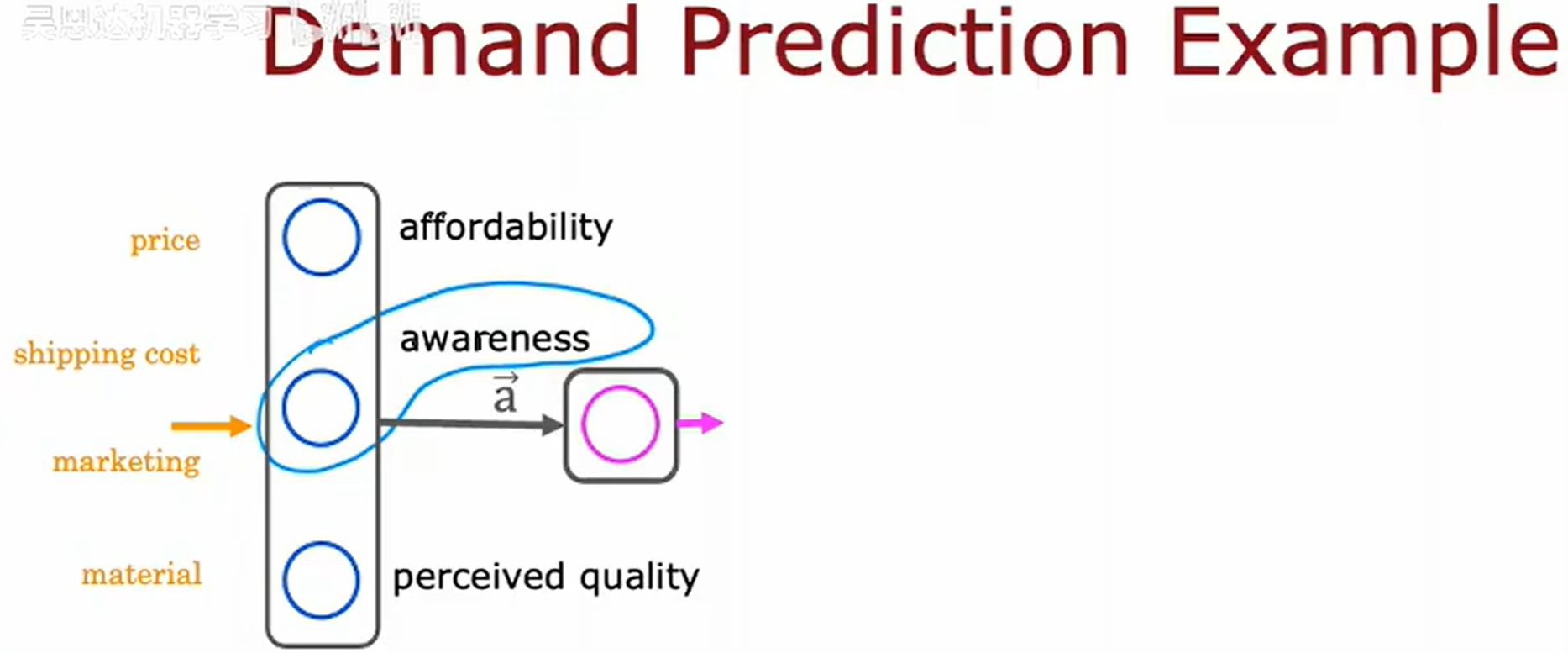
首先你拥有四个特征,价格、运费、销量、材料质量,而可能称为畅销品可能取决于如下几个因素。
- 价格实惠 (affordability)
- 认知度 (awarness)
- 感知质量 (perceived quality)
由此根据四个特征,构建神经元来对应几个因素,关系如下。
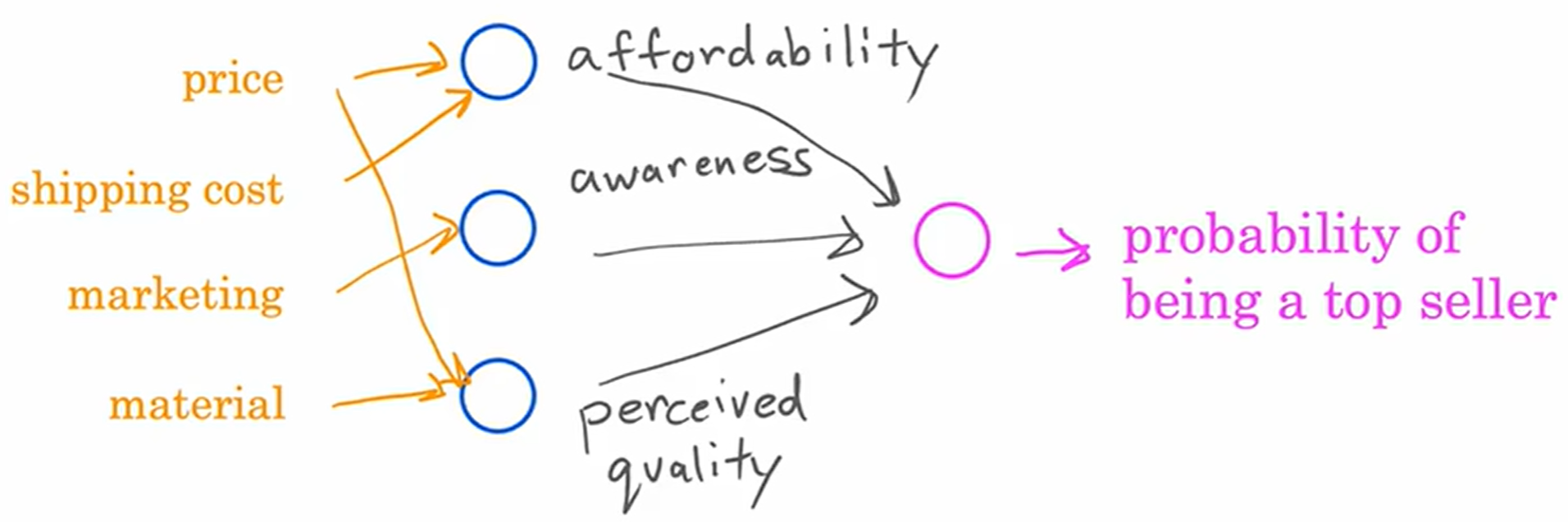
每个神经元都采用逻辑回归。
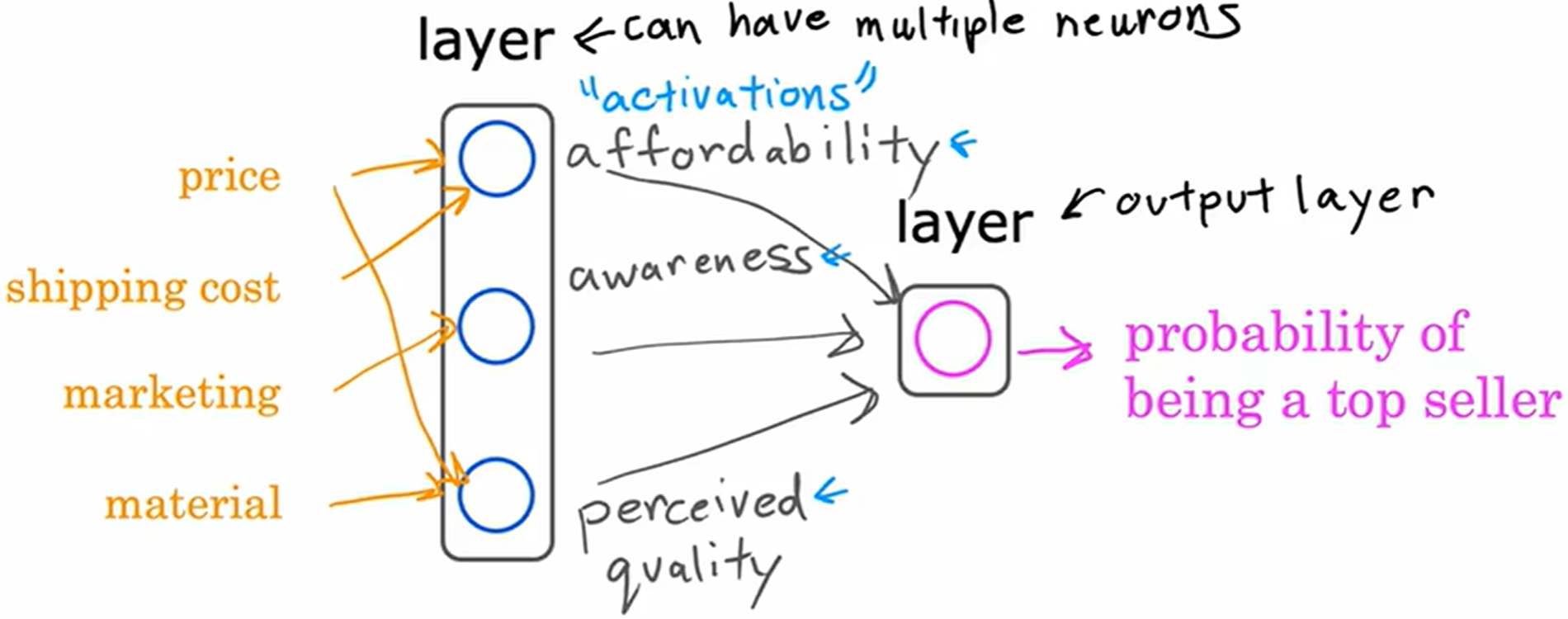
将左边三个神经元组合在一起,称之为层 (layer);右边的一个神经元也是一层,称之为输出层 (output layer)。
层(Layer)是神经网络的组成单元,由一组神经元(Neurons)构成。每个神经元接收前一层输出的特征表示(通常以数值向量的形式),通过加权求和、非线性激活函数等运算,生成新的特征表示并传递到下一层。每一层的作用是对输入数据进行逐级抽象和变换,最终形成更高层次的语义特征。
深度学习的核心优势之一在于其多层(深层)架构,这使得它能够通过分层特征提取和组合,从数据中学习到更复杂、更高维度的抽象表示,从而在许多任务上超越传统的单层机器学习模型。
图中的 affordability awareness perceived quality 也被称为激活值 (activation values),这层三个神经元的激活,最后的输出层的输出概率也是最右侧神经元的激活值 (activation values)。
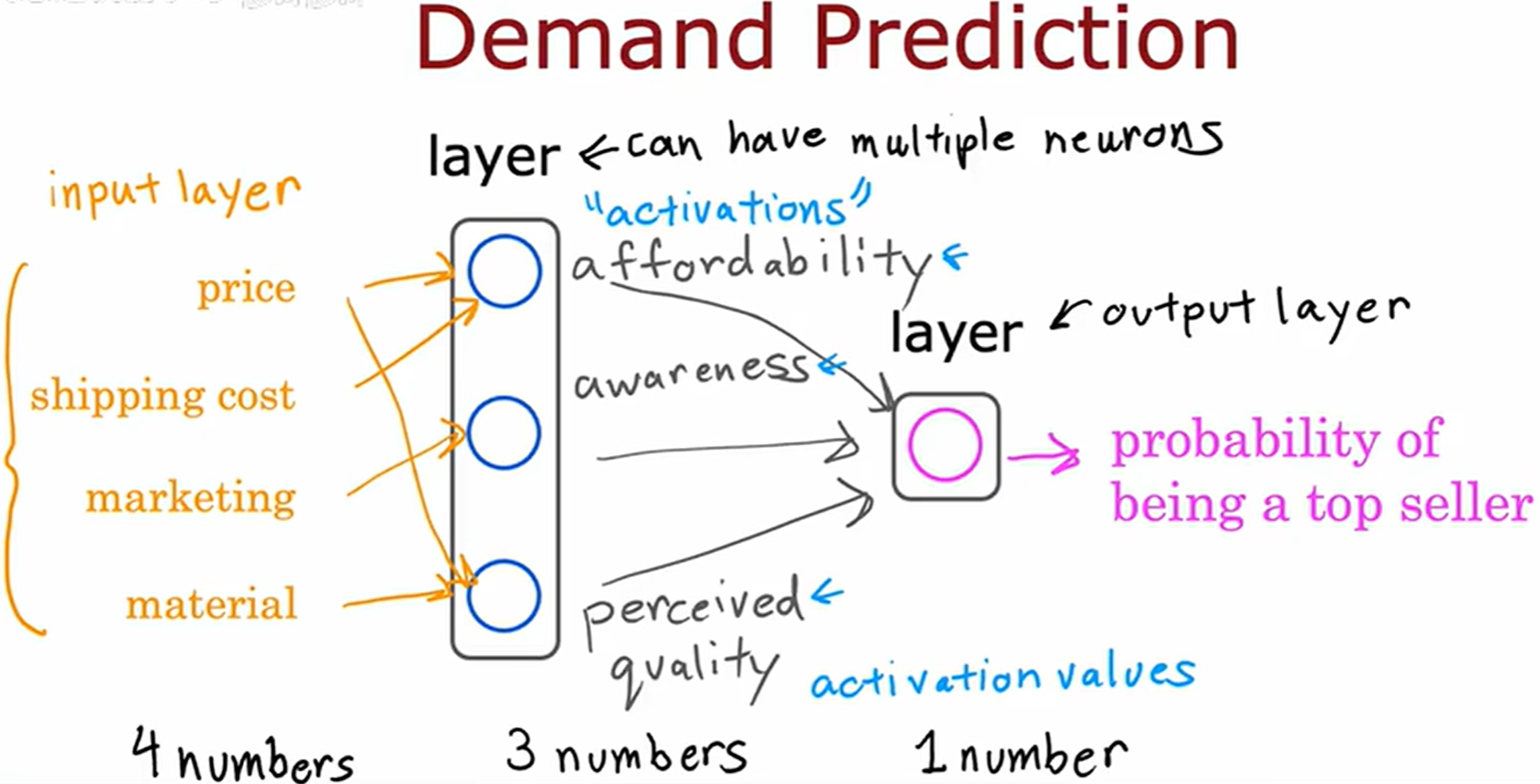
price shipping cost marketing material 这四个数据的列表也成为输入层 (input layer)。
截止学习的目前,构造神经网络必须逐个神经元地决定它从上一层获取哪些输入,但是如果在构建一个大型的神经网络,逐个手动决定哪些神经元应该以哪些特征作为输入将会是很大的工作。
实际上的神经网络,每个神经元将可以访问每一个特征,每个上一层的值,如下图。
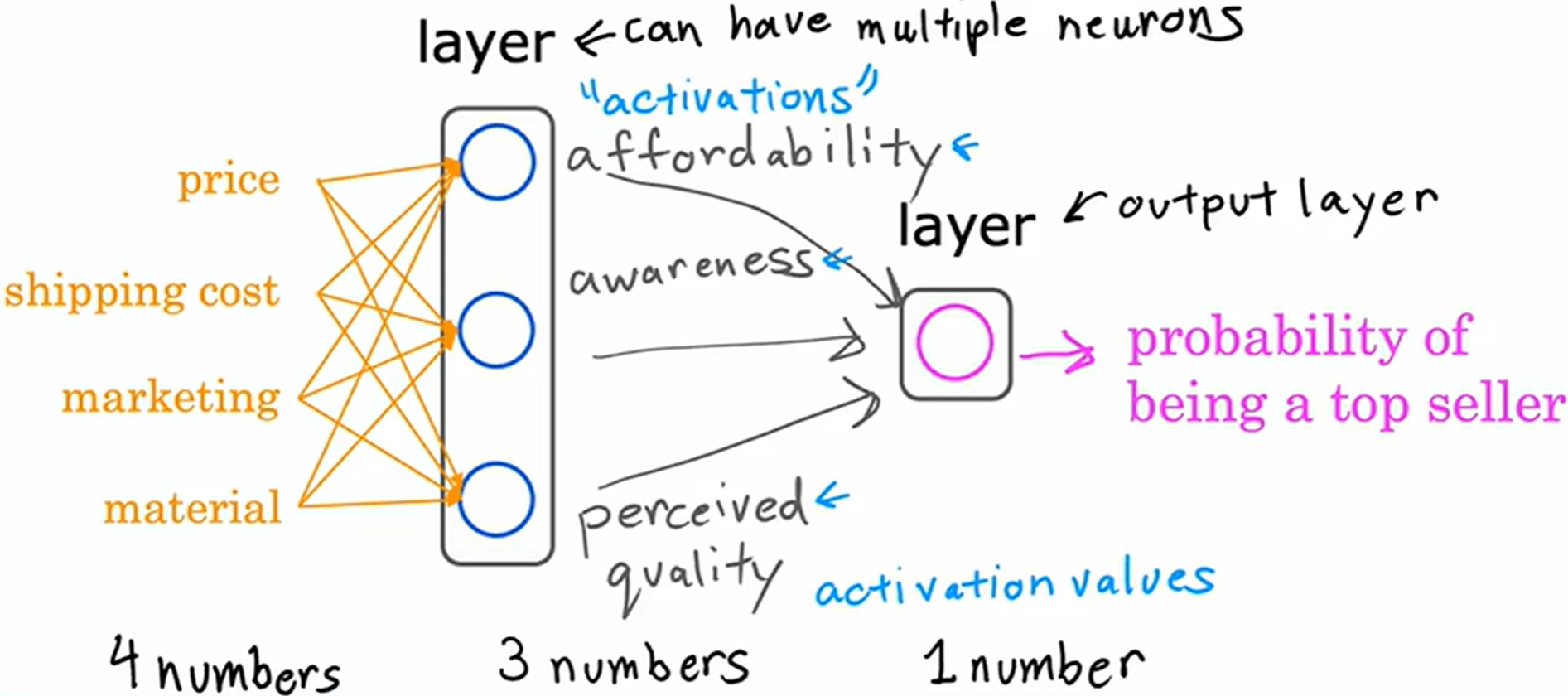
通过改变权值来专注于相关的特征子集(就像前面学习的正则化那样)。
输入层和输出层的中间一层被称为隐藏层 (hidden layer)。因为在训练集中,可以容易观察到 ( x , y ) (x, y) (x,y) 训练样本的正确值,但是不会给出如图中 affordability awareness perceived quality 的正确值,故称为隐藏层。
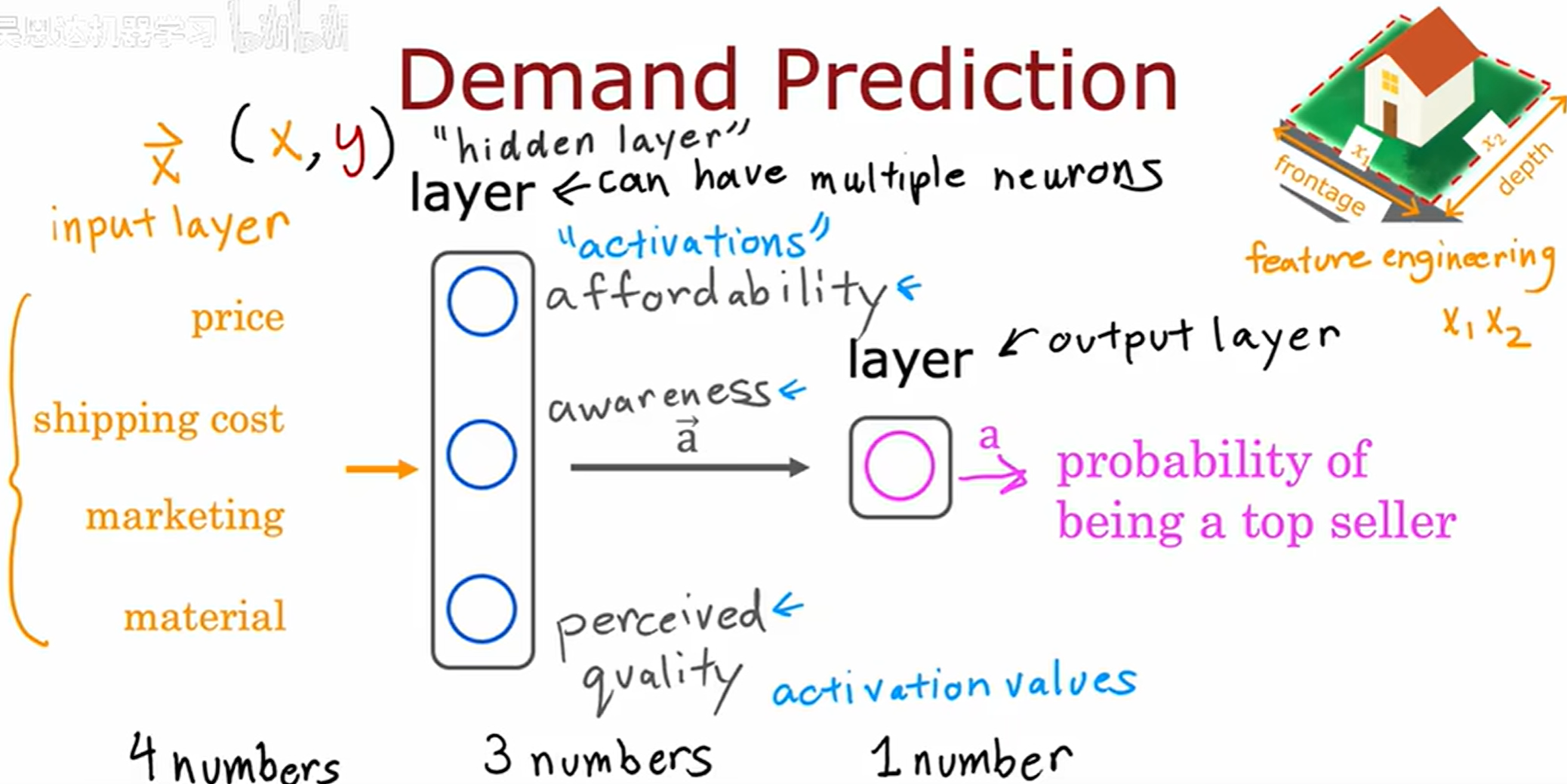
a ⃗ \vec{a} a 是隐藏层输出的激活向量,a 是神经网络的最终激活或最终预测。神经网络非常好的特性是,当从训练集中训练它,不需要决定当前层的需要专注的特征(例如上图中的 price shipping cost marketing material),神经网络会自己找出在隐藏层中想要使用的特征。
自动特征工程
- 深度学习通过反向传播和梯度下降自动优化每一层的权重,无需人工设计特征。例如:
- CNN的卷积核自动学习图像的空间模式。
- Transformer的注意力机制动态捕捉文本的上下文依赖。
传统机器学习(单层或浅层模型)的局限性
- 特征依赖性强:传统模型(如SVM、逻辑回归、决策树等)严重依赖人工特征工程。模型的性能很大程度上取决于特征提取的质量。
- 线性或简单非线性:即使使用核方法(如SVM)或集成学习(如随机森林),其非线性能力通常较浅,难以捕捉数据中的层次化结构(例如图像中的边缘→纹理→物体部件→整体物体)。
- 高维数据表现差:对于图像、语音、文本等高维数据,传统模型容易过拟合或计算效率低下。
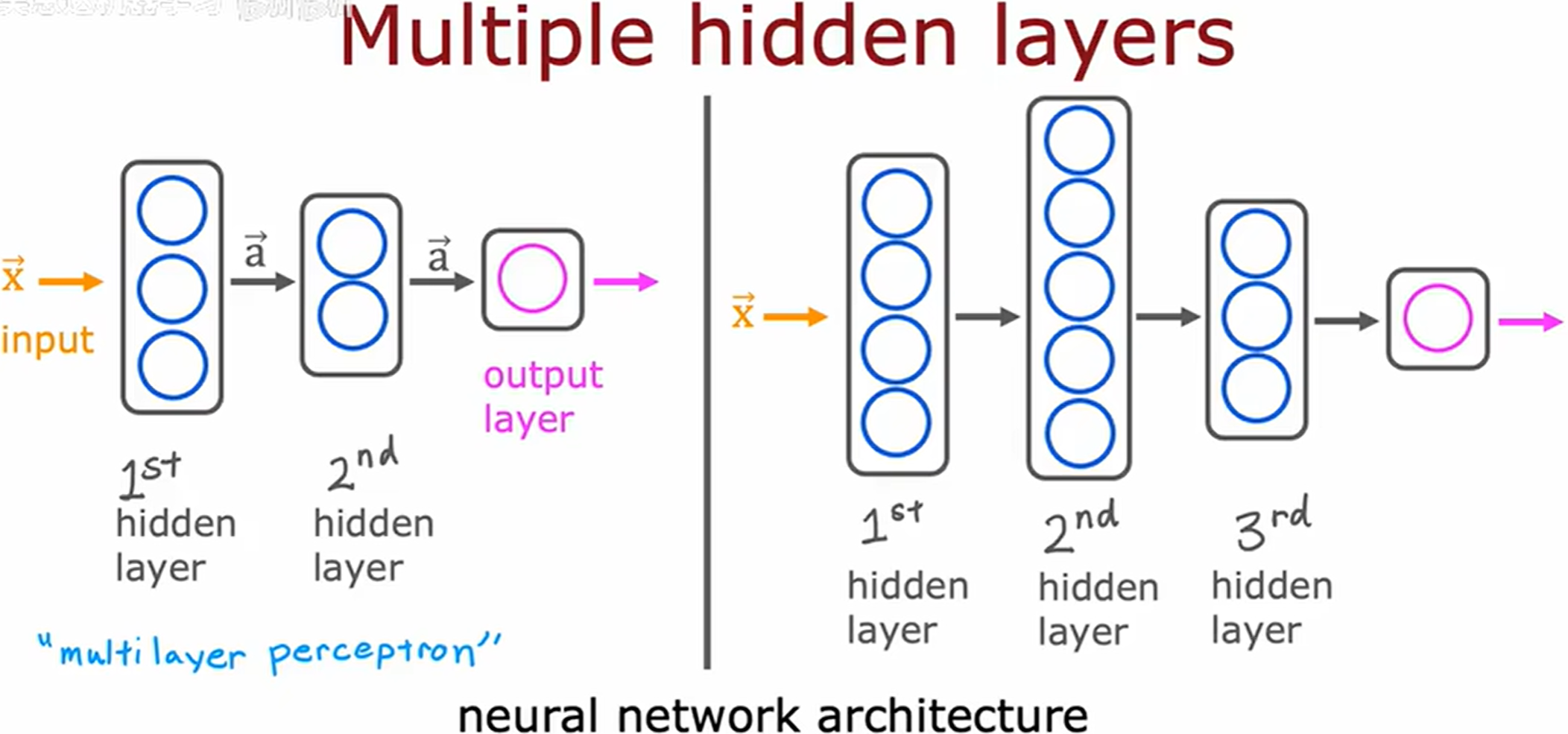
在构建神经网络时,需要做出的关键决策之一是确定隐藏层的数量以及神经元的数量。
在一些文献中,这种具有多个层的神经网络被称为多层感知机(multi-layer perceptron [缩写 MLP])。
例子:图像识别
人脸识别(Face recognition)
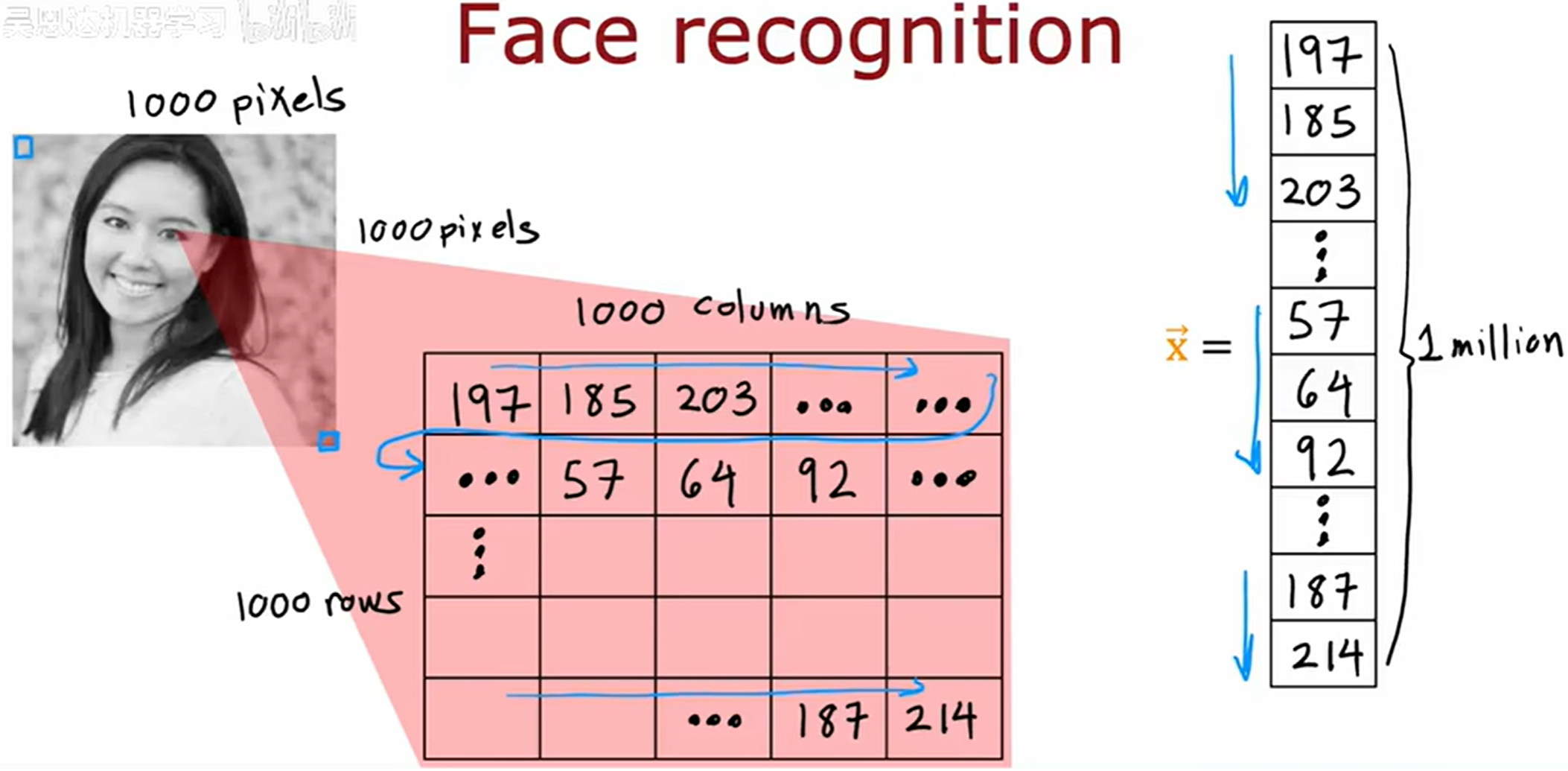
这张照片是 1000x1000 的像素 (pixels),在计算机中实际表示为一个 1000x1000 的网格,在这个例子中像素的亮度值范围是 [ 0 , 255 ] [0, 255] [0,255], x ⃗ \vec{x} x 是将网格展开后记录成的向量。
任务:训练一个神经网络,输入为包含一百万个像素亮度值的特征向量,输出为图片中人物的身份。
如果在一个大量人脸图像上训练过的神经网络,观察隐藏层中的不同神经元的计算过程,如下图所示。
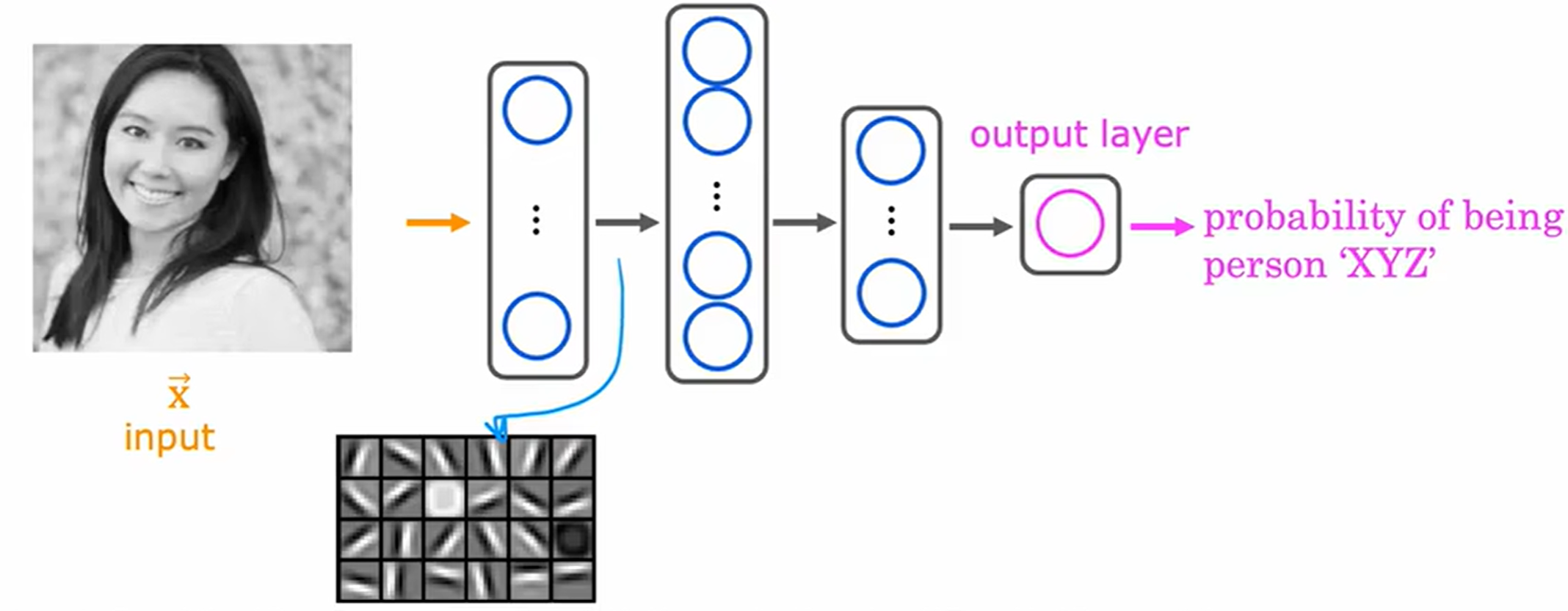
在网络的第一隐藏层(最底层),神经元通常学习检测基础的局部视觉特征:
- 某些神经元会对特定方向的边缘(如垂直、水平或对角线条)产生响应
- 其他神经元可能检测简单的纹理模式或颜色变化
- 这些特征具有平移不变性,能在图像的任何位置被识别
在神经网络的最早层,你可能发现神经元在图像中寻找非常短的线条或者边缘。
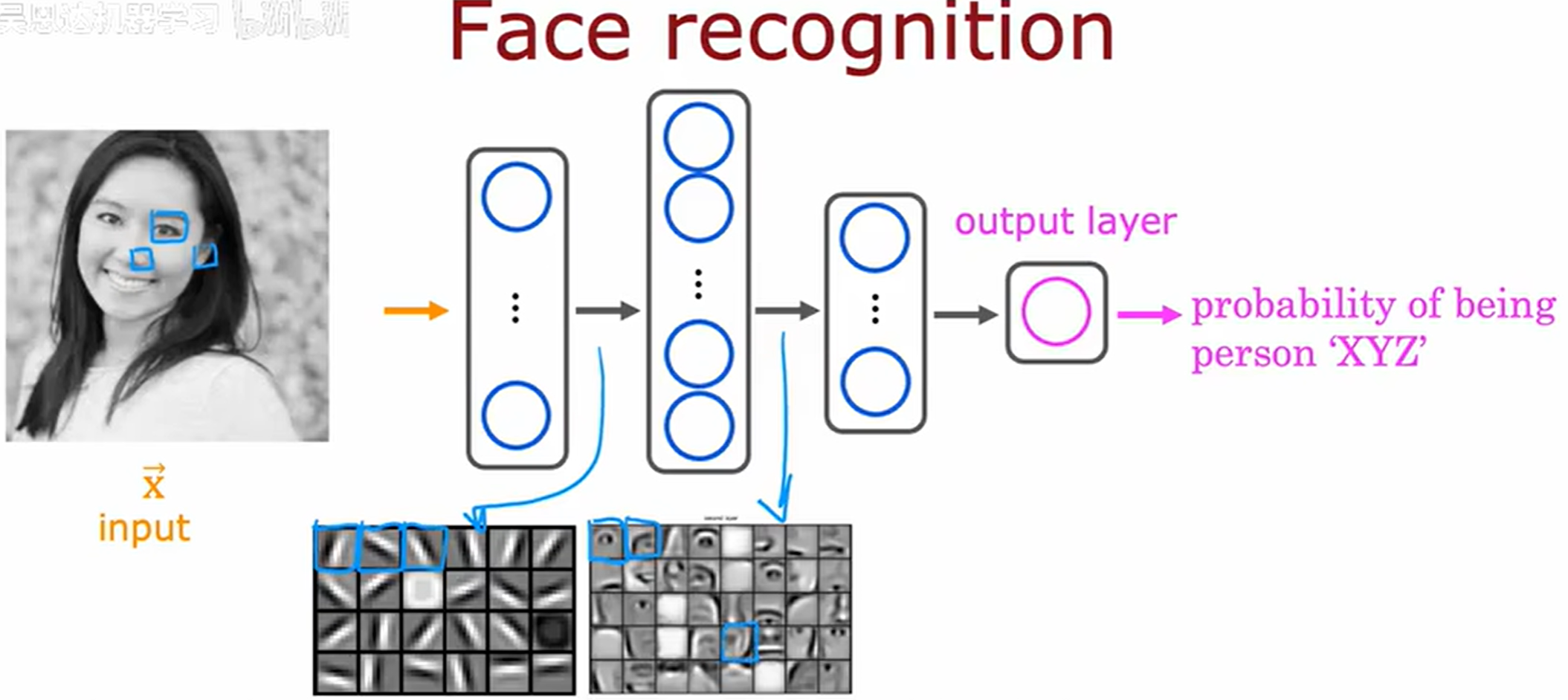
在第二隐藏层,这些神经元可能学会将许多小短线组合在一起,以便寻找面部的部分。
神经元会组合低级特征来构建更复杂的结构:
- 部分神经元学会检测面部组成部分(如眼角、鼻翼轮廓或眉毛片段)
- 这些检测器对特定面部区域的几何排列敏感
- 例如某个神经元可能在图像中出现眼睛轮廓时达到最大激活
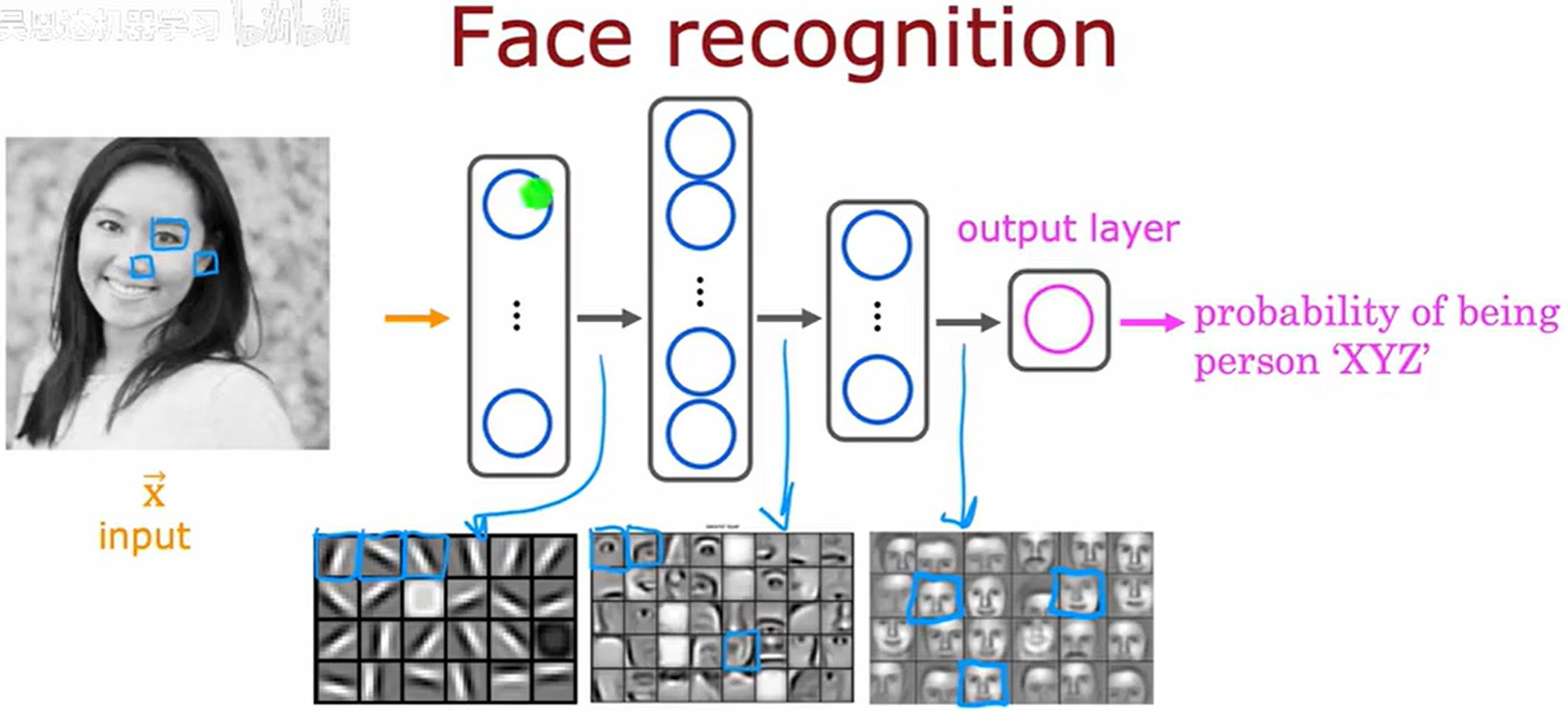
在第三隐藏层,神经网络正在聚合面部的不同部分,然后尝试检测是否存在更大更粗略的面部形状。
神经元进一步整合中级特征:
- 开始表征面部的整体空间结构(如眼鼻相对位置)
- 能够响应更高级的语义特征(如完整眼部区域或嘴部形状)
- 最终层神经元可能对应特定人脸身份或表情的抽象表征
这种层级特征学习机制(从边缘→局部部件→整体结构)正是卷积神经网络(CNN)能有效处理视觉任务的核心原因。随着网络深度增加,特征的语义层级逐步提升,空间敏感性逐渐降低。
在深度神经网络中,随着层级的加深,神经元感受野(receptive field)会逐层扩大,从而能够检测越来越复杂的特征:
- 第一隐藏层的神经元具有较小的感受野,通常只能检测图像中局部区域的低层特征(如边缘、纹理或颜色变化)。
- 第二隐藏层的神经元的感受野更大,能够整合前一层的局部特征,从而检测更复杂的结构(如眼睛轮廓、鼻子局部等)。
- 更高层的神经元的感受野进一步扩大,能够覆盖图像的更大部分,甚至全局上下文信息,从而识别高级语义特征(如完整的人脸、物体或场景)。
从上述例子可知:
深层网络的激活值表征更高层次的特征
神经网络激活值在不同层级中逐步编码更高层次的特征
汽车分类(Car classification)
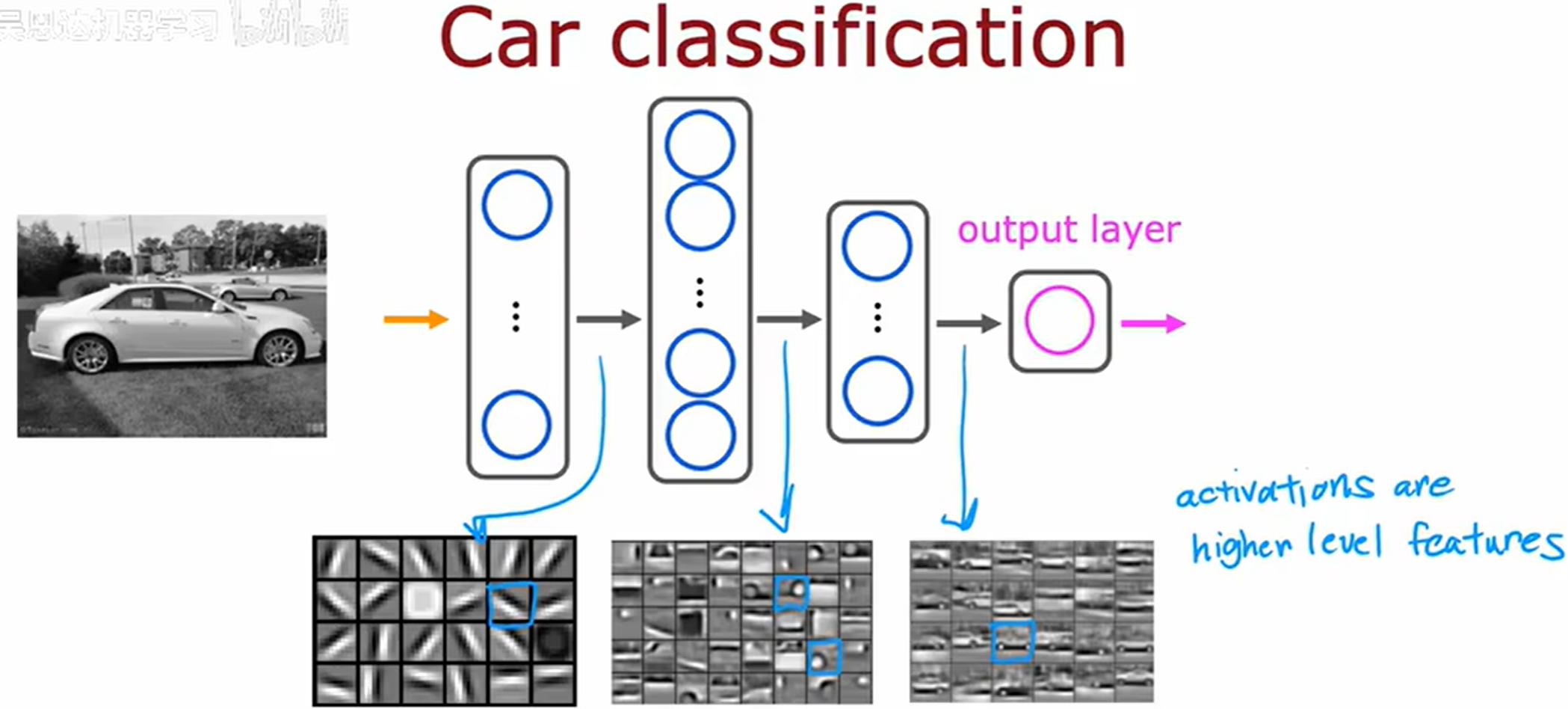
同理,第一隐藏层学习边缘,第二隐藏层学习检测汽车部分,第三隐藏层学习更完整的汽车形状。
所以只需提供不同的数据,神经网络就会自动学习检测非常不同的特征。
稳定性与记忆功能的正确理解:
✓ 神经网络确实没有传统意义上的长期记忆(不像人类大脑)
✓ 其"记忆"完全存储在模型参数(权重)中
✓ 但稳定性取决于:
- 训练数据的充分性和代表性
- 正则化技术的使用(如dropout, weight decay)
- 模型容量与任务复杂度的匹配程度
关键区别:
- 灾难性遗忘(Catastrophic Forgetting):
当用新数据重新训练时,网络会覆盖之前学到的模式(除非采用持续学习技术) - 参数稳定性:
良好训练的模型对同类数据的小变化应保持稳定(通过权重正则化实现)
神经网络中的层
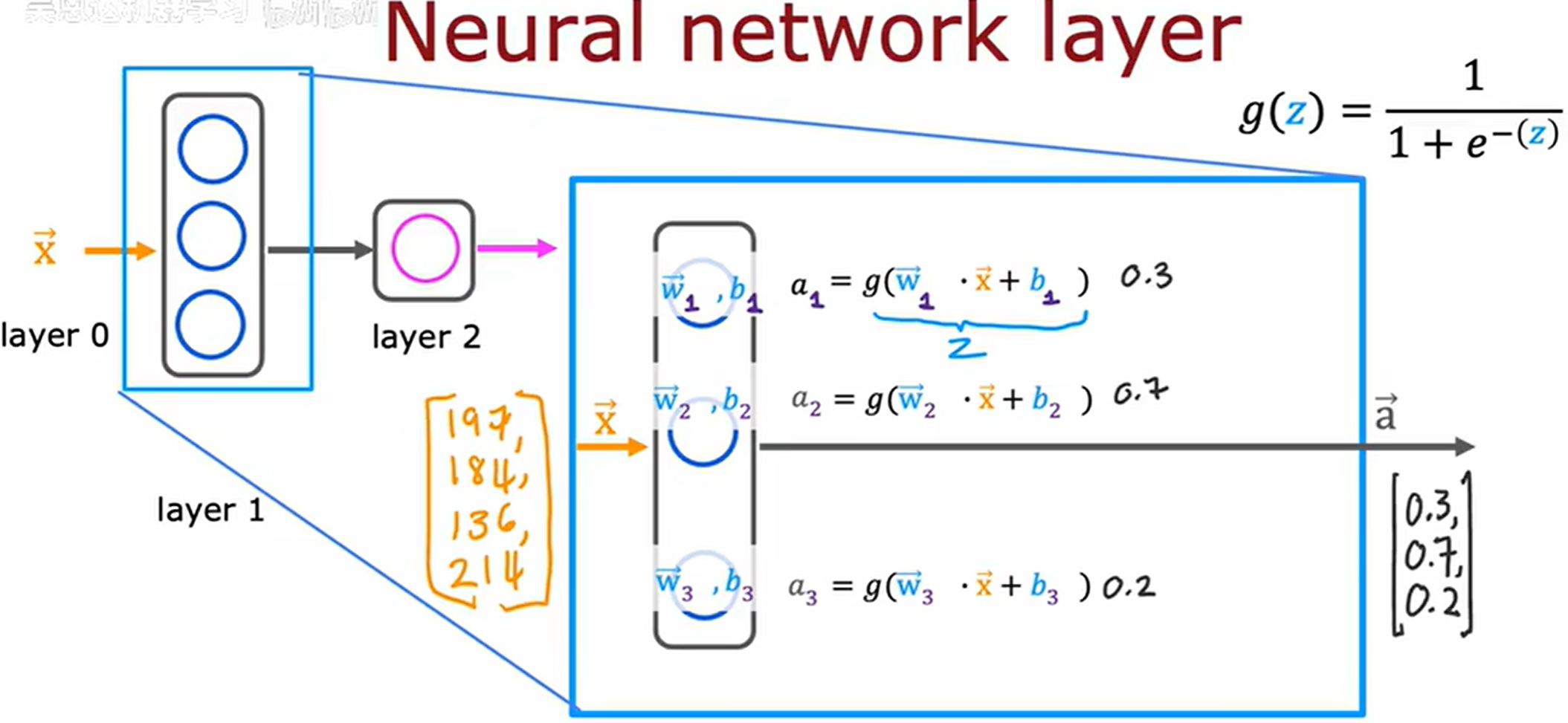
输入层有的时候会被称为
layer 0
采用上标 [ i ] [i] [i] 来表示第 i i i 层
下标 j j j 表示该层的第 j j j 个隐藏神经元
a ⃗ [ 1 ] \vec{a}^{[1]} a[1] 表示 layer 1 的激活值
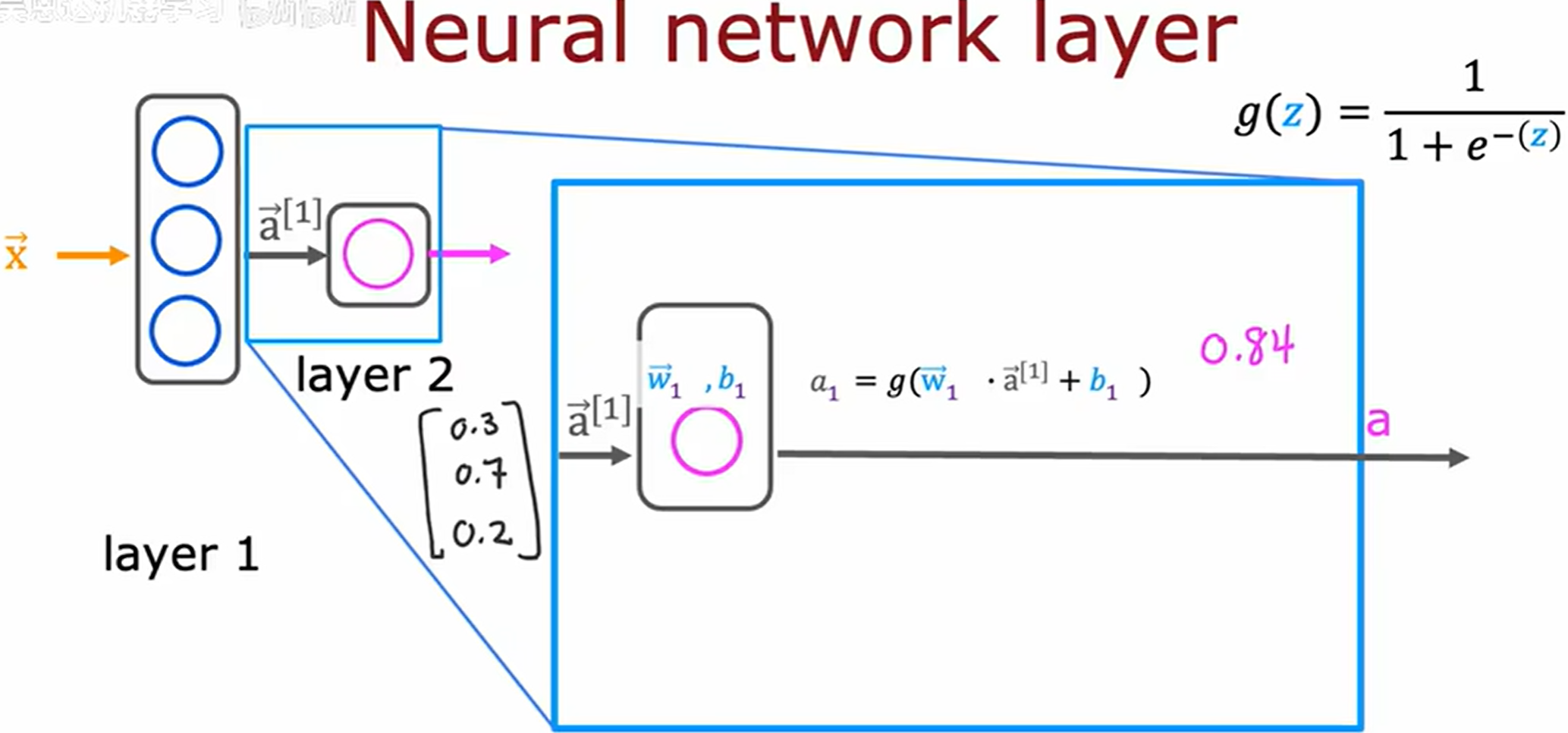
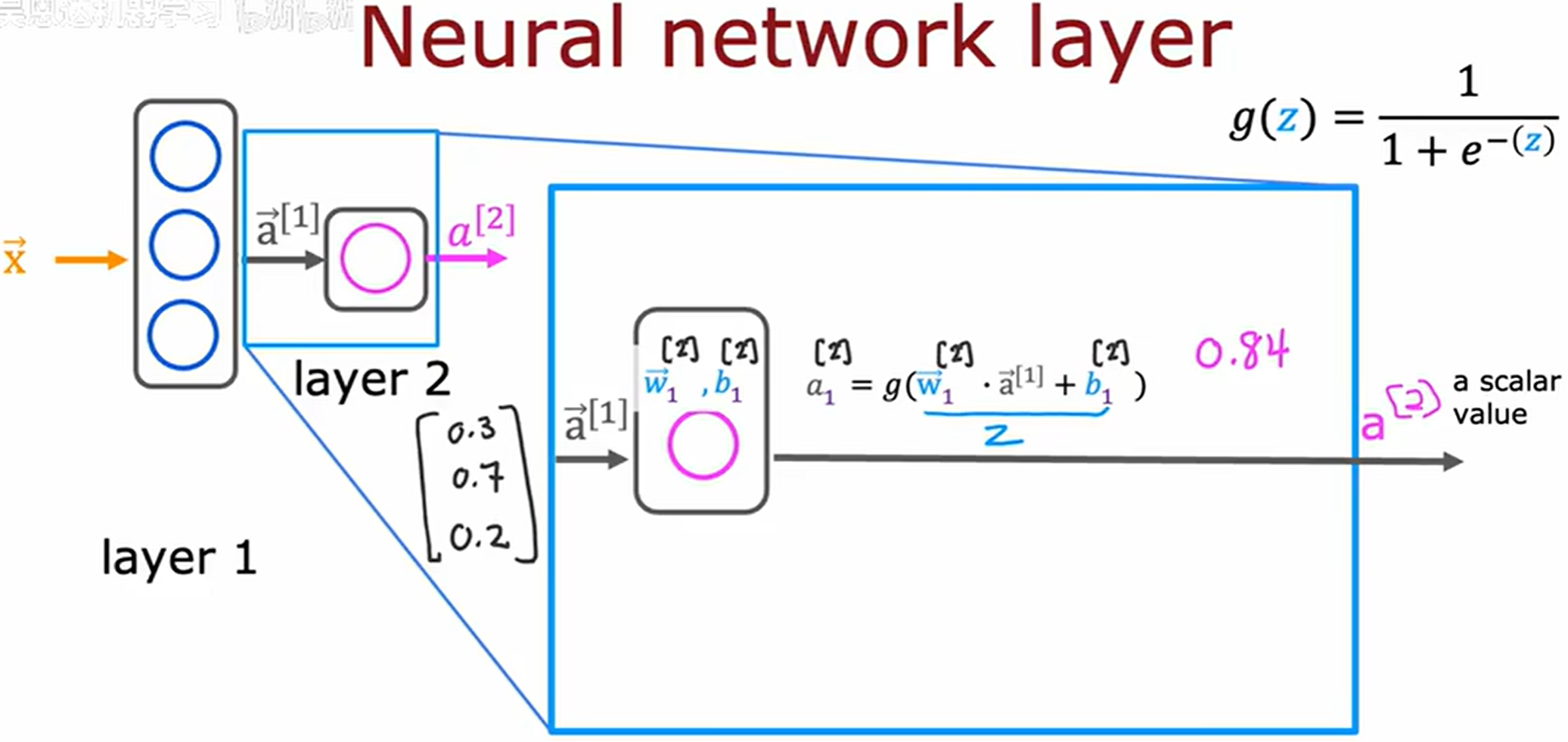
上层激活作为下层输入
a scalar value 一个标量值
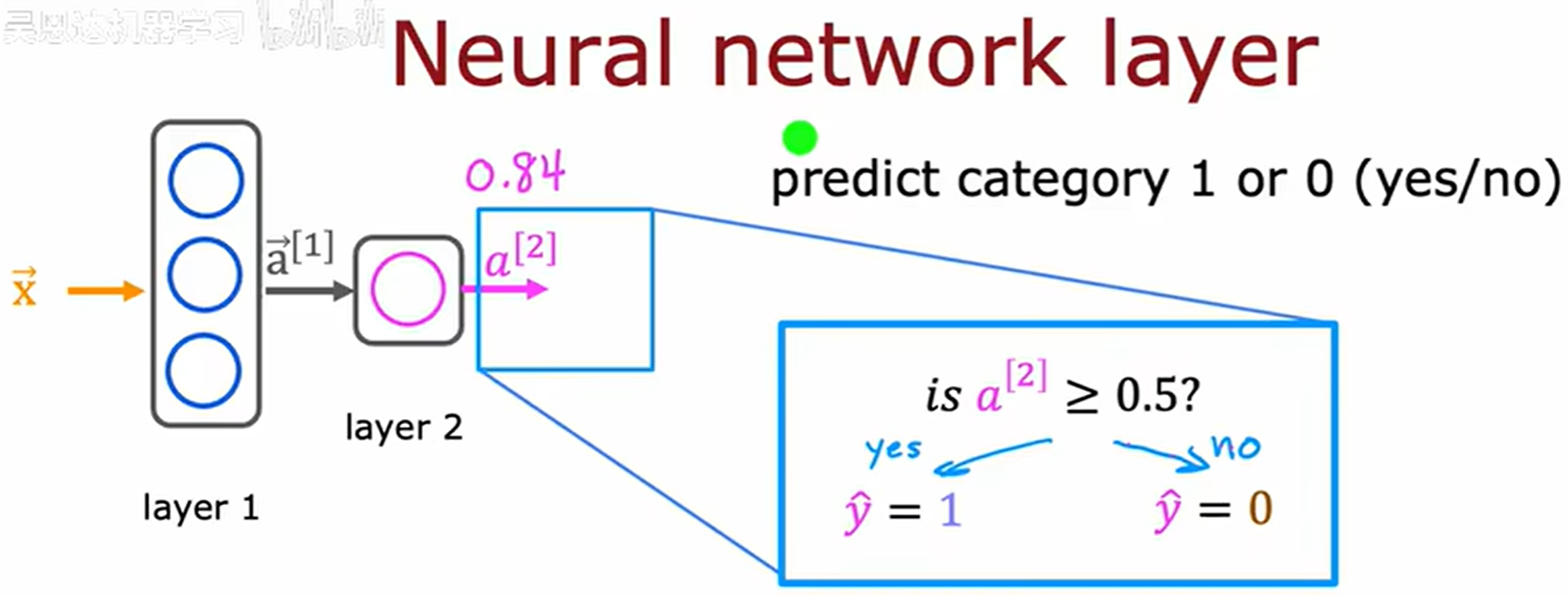
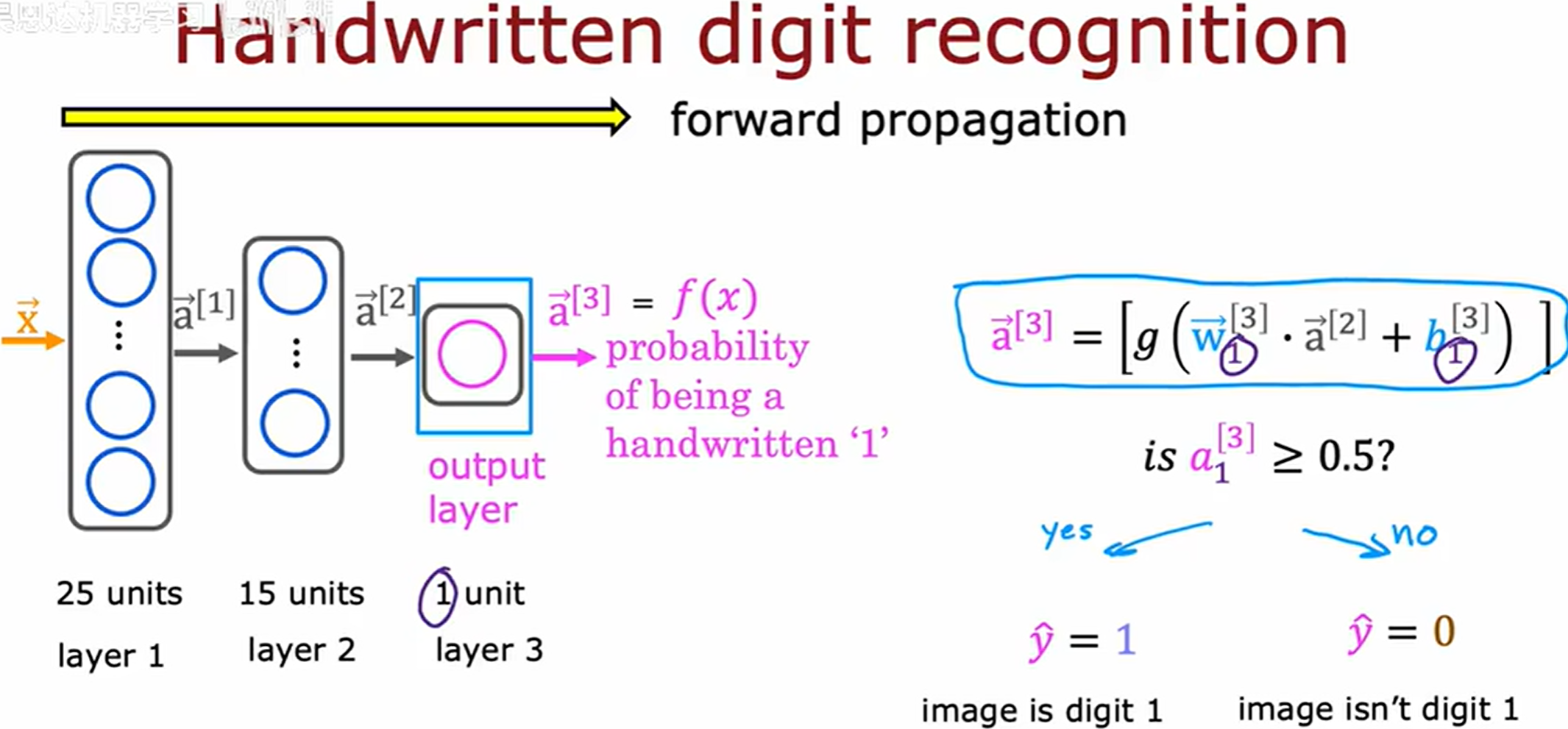
最后一步,根据阈值 (threshold) 处理预测结果。
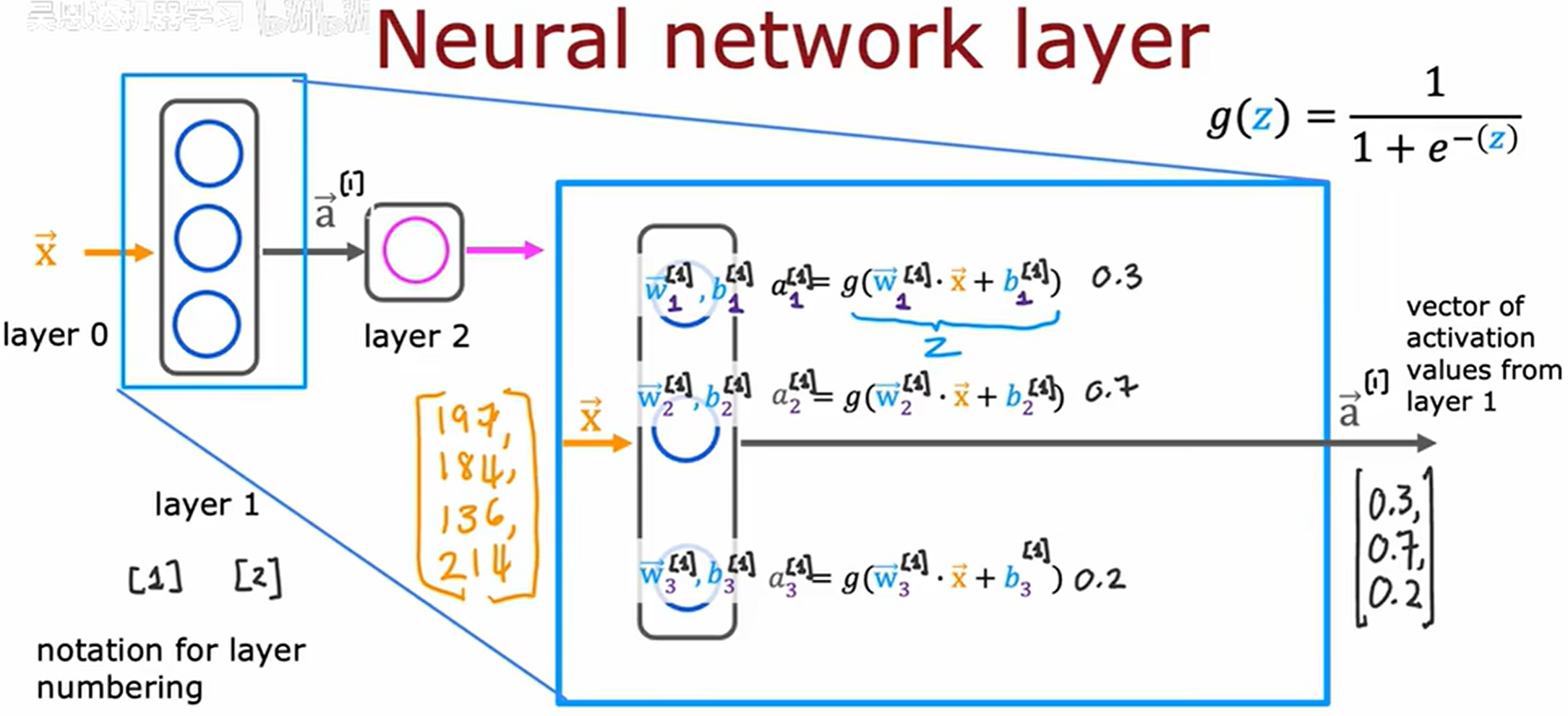
更复杂的神经网络
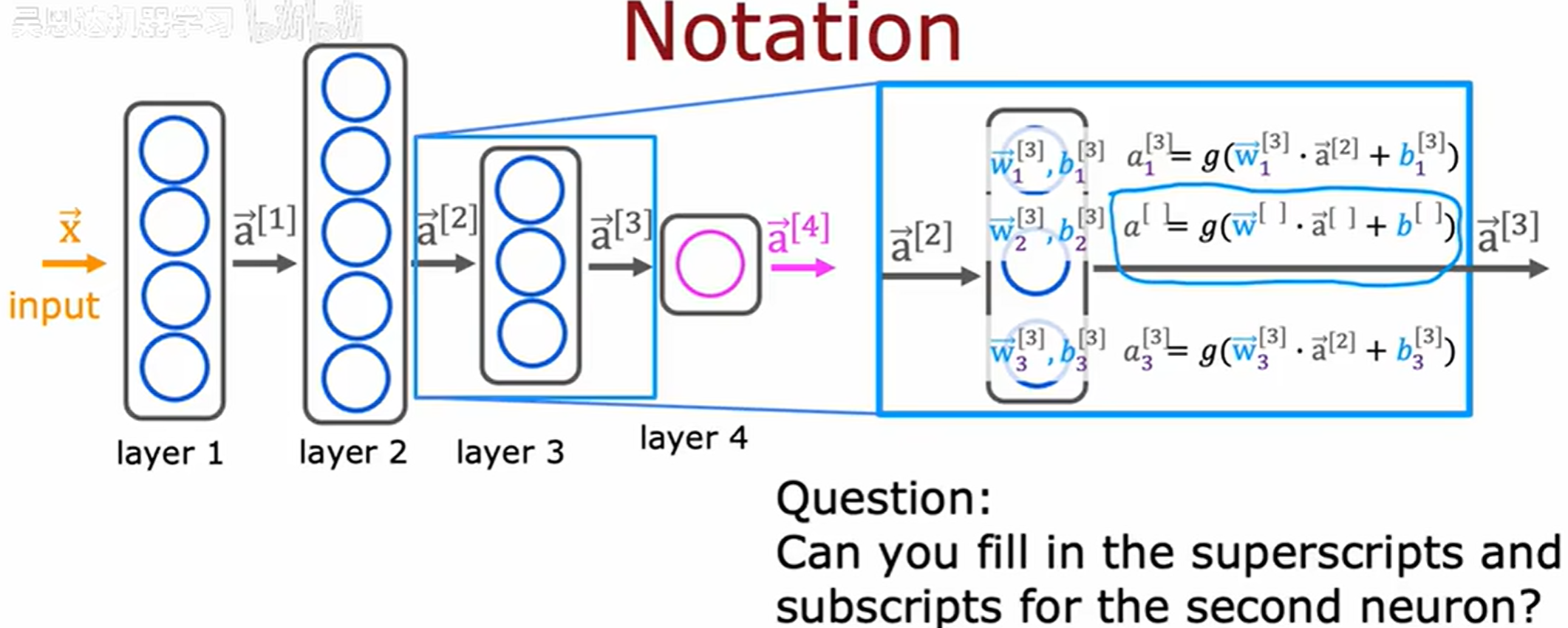

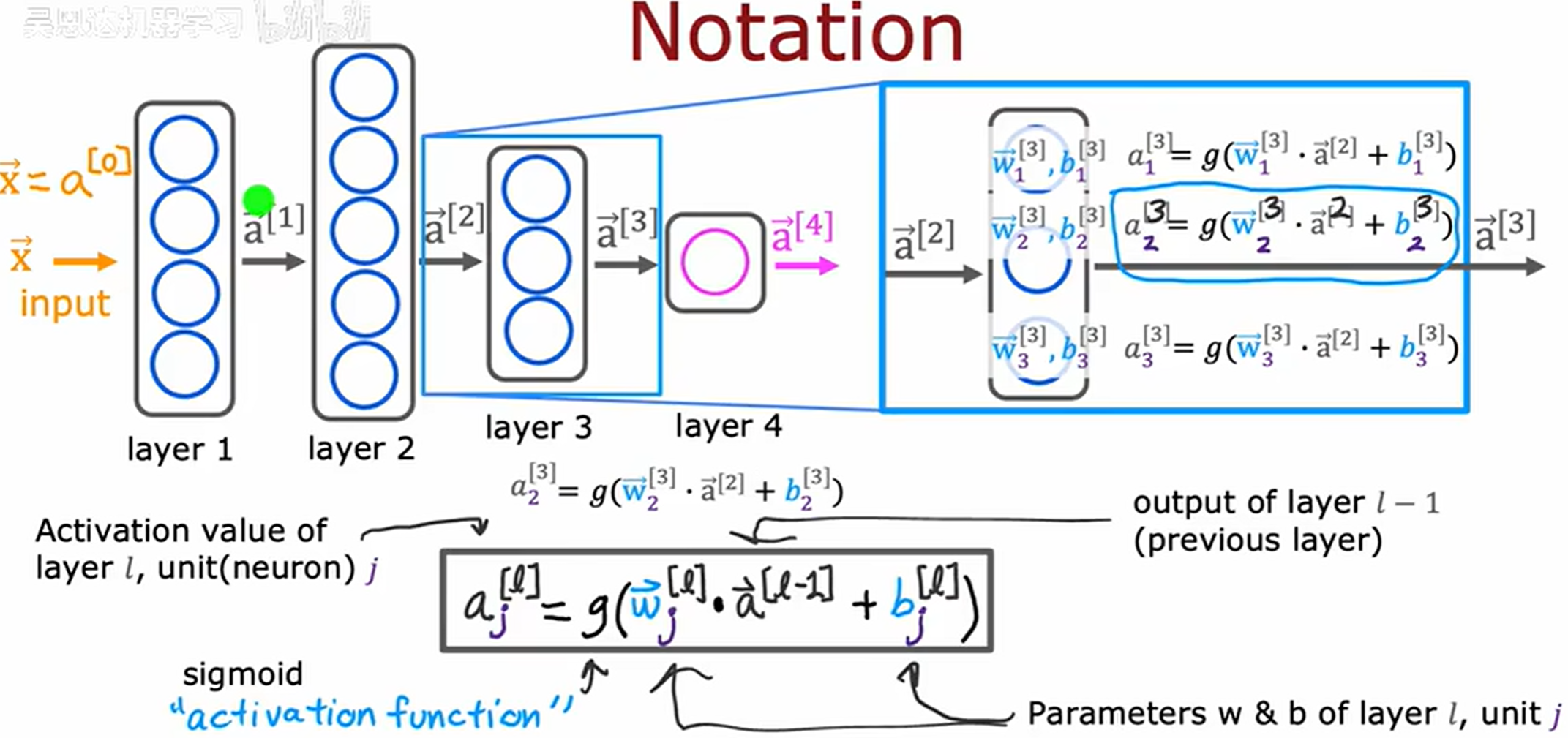
每层的激活值可以写为 a ⃗ [ l ] \vec{a}^{[l]} a[l]
输入 x ⃗ \vec{x} x 也可以写作 a ⃗ [ 0 ] \vec{a}^{[0]} a[0]
更新公式:
a j [ l ] = g ( w ⃗ j [ l ] ∗ a ⃗ [ l − 1 ] + b j [ l ] ) a_j^{[l]} = g(\vec{w}_j^{[l]} * \vec{a}^{[l - 1]} + b_j^{[l]}) aj[l]=g(wj[l]∗a[l−1]+bj[l])
在神经网络的上下文中,图中的 g 函数也称为激活函数 (activation function),因为 g 函数输出激活值。到目前为止,见过的唯一激活函数是 sigmoid 函数。
推理:前向传播 (Forward Propagation)
以手写数字识别作为示例,作为一个二分类问题,判断图片是 0 还是 1。
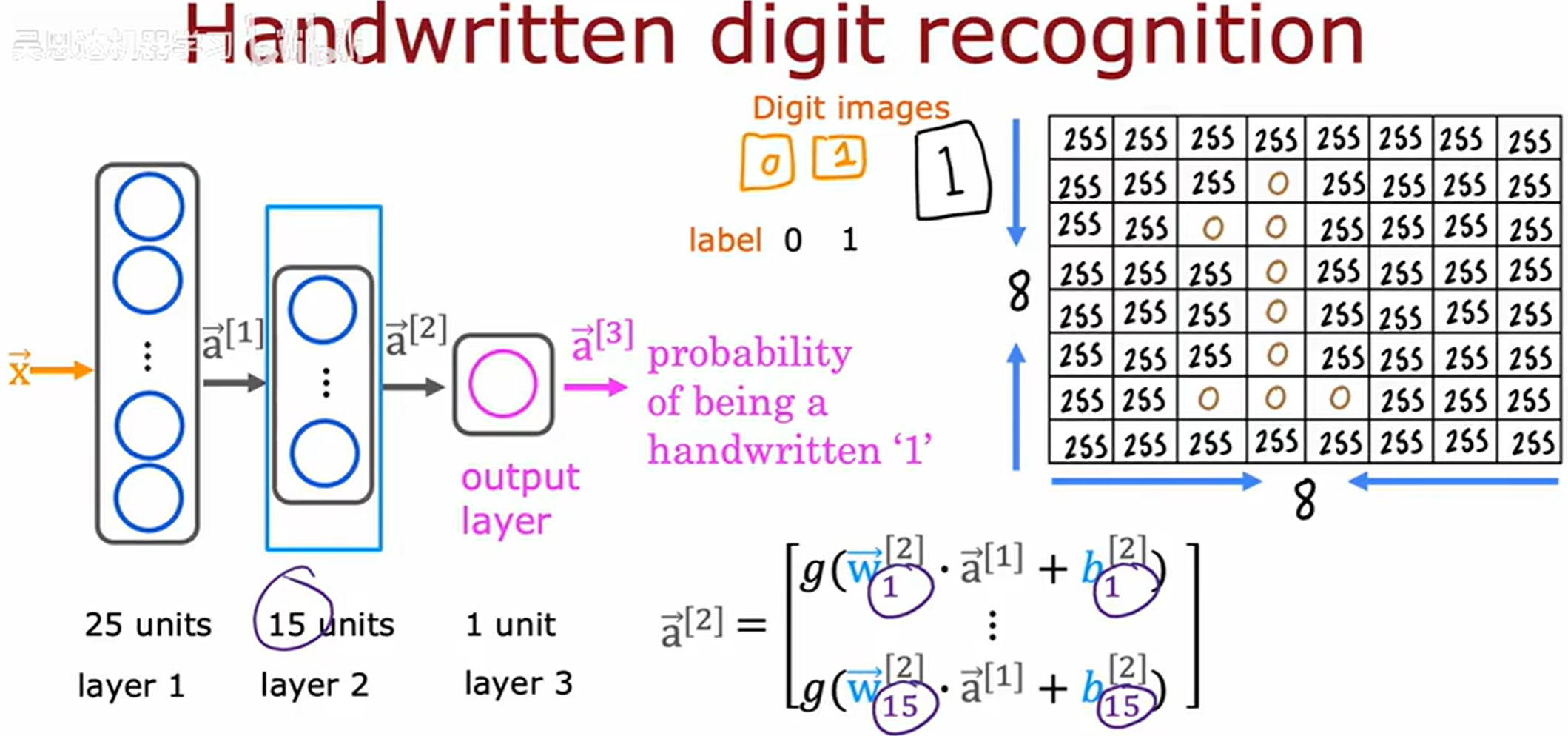
输入层
- 输入为 8 × 8 8×8 8×8 灰度像素矩阵,展平为 64 64 64 维特征向量 x ∈ R 64 x∈\mathbb{R}^{64} x∈R64,对应输入层 64 64 64 个神经元。
隐藏层前向计算
- 网络采用层级递进的全连接结构,每一层的输出通过非线性激活函数变换后作为下一层的输入。
输出层
- 最终通过 Sigmoid 激活函数输出标量概率值 y ∈ ( 0 , 1 ) y∈(0,1) y∈(0,1),表示输入样本属于类别1的置信度。
层级递进的前向计算,这就是前向传播。
这种漏斗型拓扑结构设计的神经网络架构类型,一开始有很多的隐藏神经元,然后随着接近输出层,数量逐渐减少。
代码中的推理
关于神经网络最显著的事情之一就是相同的算法可以应用于如此多不同的应用程序。
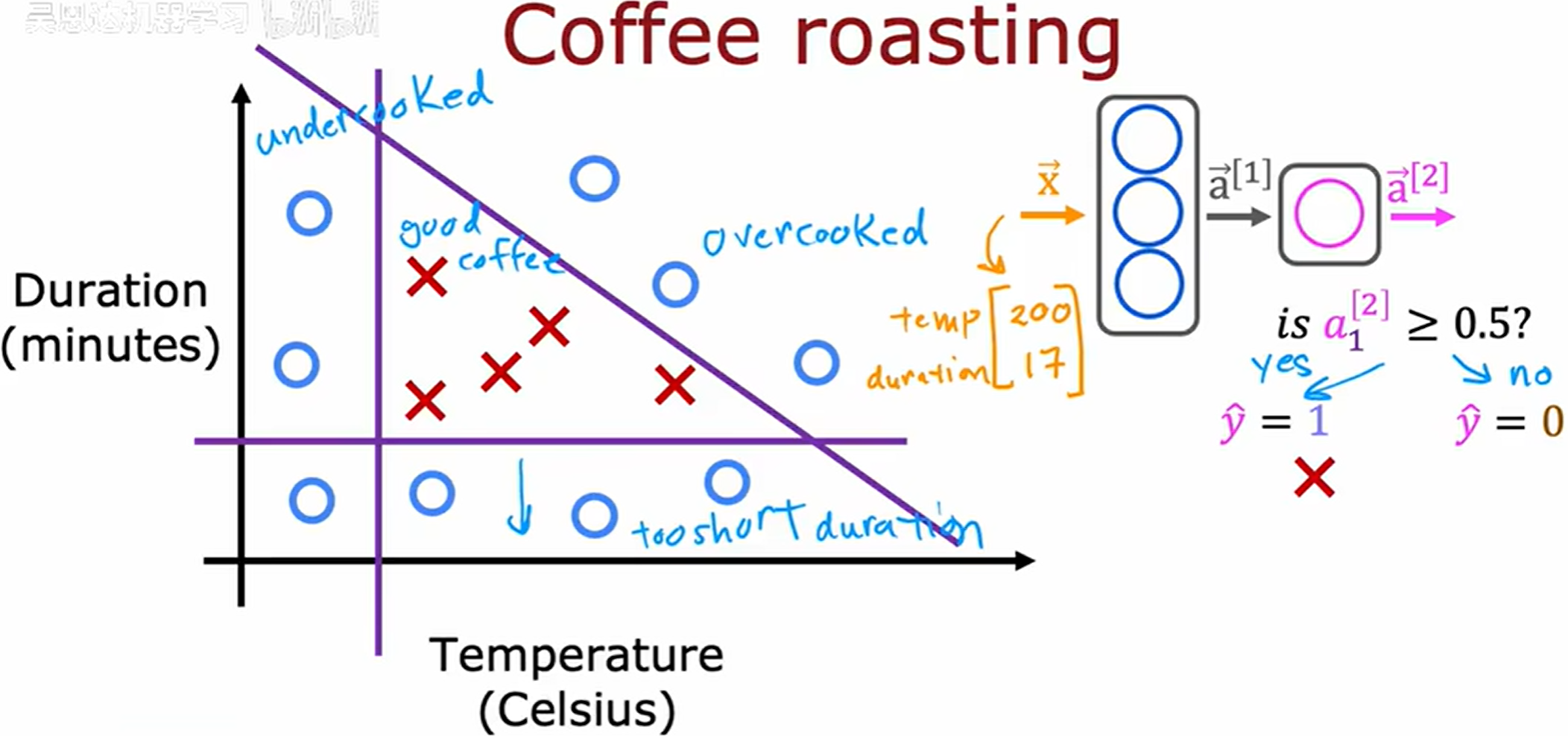
以煮咖啡为例,以 Duration 和 Temperature 为特征构,这里采用 Tensorflow 构建神经网络。
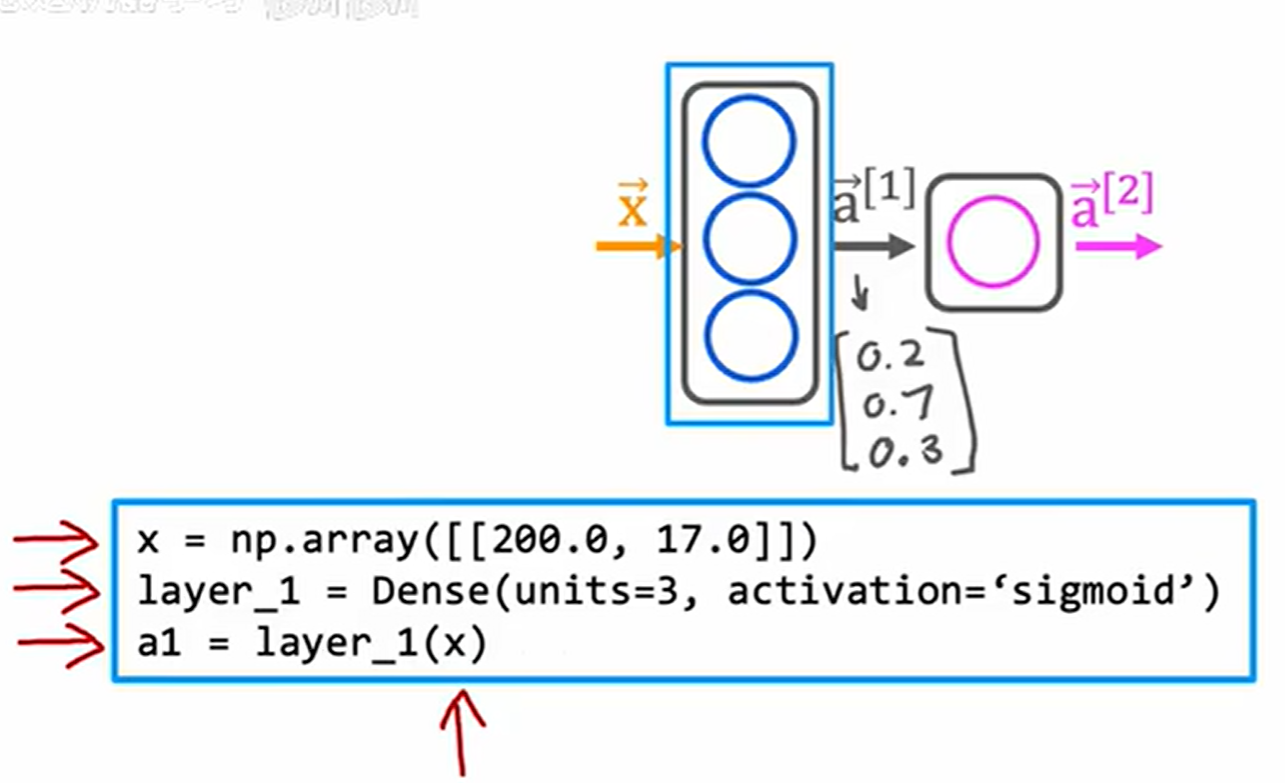
TensorFlow 的 Dense 函数,构造神经元个数为 3,采用 sigmoid 作为激活函数的全连接层,layer_1 会作为一个函数。
Dense层(密集层)
Dense层,在深度学习中通常被称为全连接层( fully connected layer),它是神经网络中最基础也最常用的层之一。每个神经元都与前层的所有神经元相连,这意味着该层会接收所有输入特征并生成相应的输出。
回到之前的手写数字识别,利用以上例子构建对应的神经网络。

TensorFlow中的数据
TensorFlow 使用 numpy 来存放数据


[200, 17] 不算是矩阵,属于 1-D 数组。
采用 [[200, 17]] 来表示 1 x 2 矩阵,来表示行向量。
[[200], [17]] 来表示 2 x 1 矩阵,来表示列向量。
TensorFlow设计用于处理非常大的数据集,惯例采用的矩阵来表示数据,而不是 1-D(一维)来表示数据。

将特征向量用矩阵表示,因此使用 [[200.0, 17.0]] 来表示。
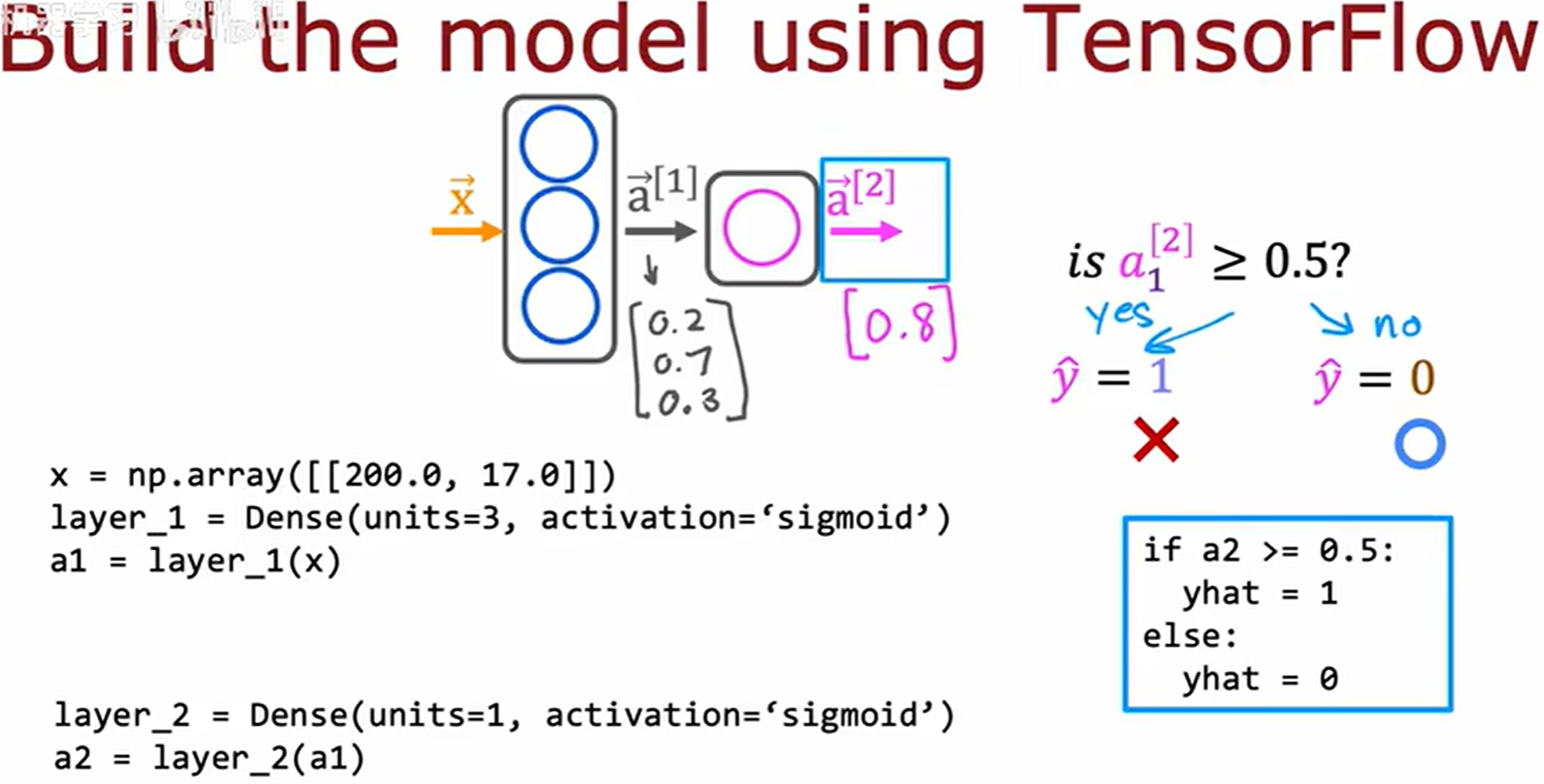
回到前一节继续实现咖啡的神经网络

Tensor 由 TensorFlow 团队创建的数据类型,用于存储和执行计算,高效地处理矩阵。当将 numpy 数据传入 TensorFlow,TensorFlow 会转为内部格式 tensor,然后高效操作,最后结果可以保留为 tensor 或是 numpy() 转换为 numpy 类型。
TensorFlow 函数会返回 tensor 数据类型,可以用 numpy() 函数进行转换为 numpy 数据类型。
上图中a2.numpy() 将会返回 ( 1 , 1 ) (1, 1) (1,1) 的矩阵,如图中的 [ [ 0.8 ] ] [[0.8]] [[0.8]]。
矩阵是张量的特例
矩阵:仅适用于 2阶张量(2D数组,形如
[行, 列]),例如一个灰度图像可表示为 128 × 128 128×128 128×128 的矩阵。张量:广义的 N维数组,覆盖所有维度(0阶到N阶):
阶数 张量类型 示例 数学表示 0 标量 (Scalar) 温度值 36.5s ∈ R s∈\mathbb{R} s∈R 1 向量 (Vector) RGB颜色 [255,0,0]v ∈ R 3 v∈\mathbb{R}^3 v∈R3 2 矩阵 (Matrix) 灰度图像 [128,128]M ∈ R 128 × 128 M∈\mathbb{R}^{128×128} M∈R128×128 3+ 高阶张量 彩色视频 [帧,高,宽,通道]T ∈ R 10 × 1080 × 1920 × 3 T∈\mathbb{R}^{10×1080×1920×3} T∈R10×1080×1920×3
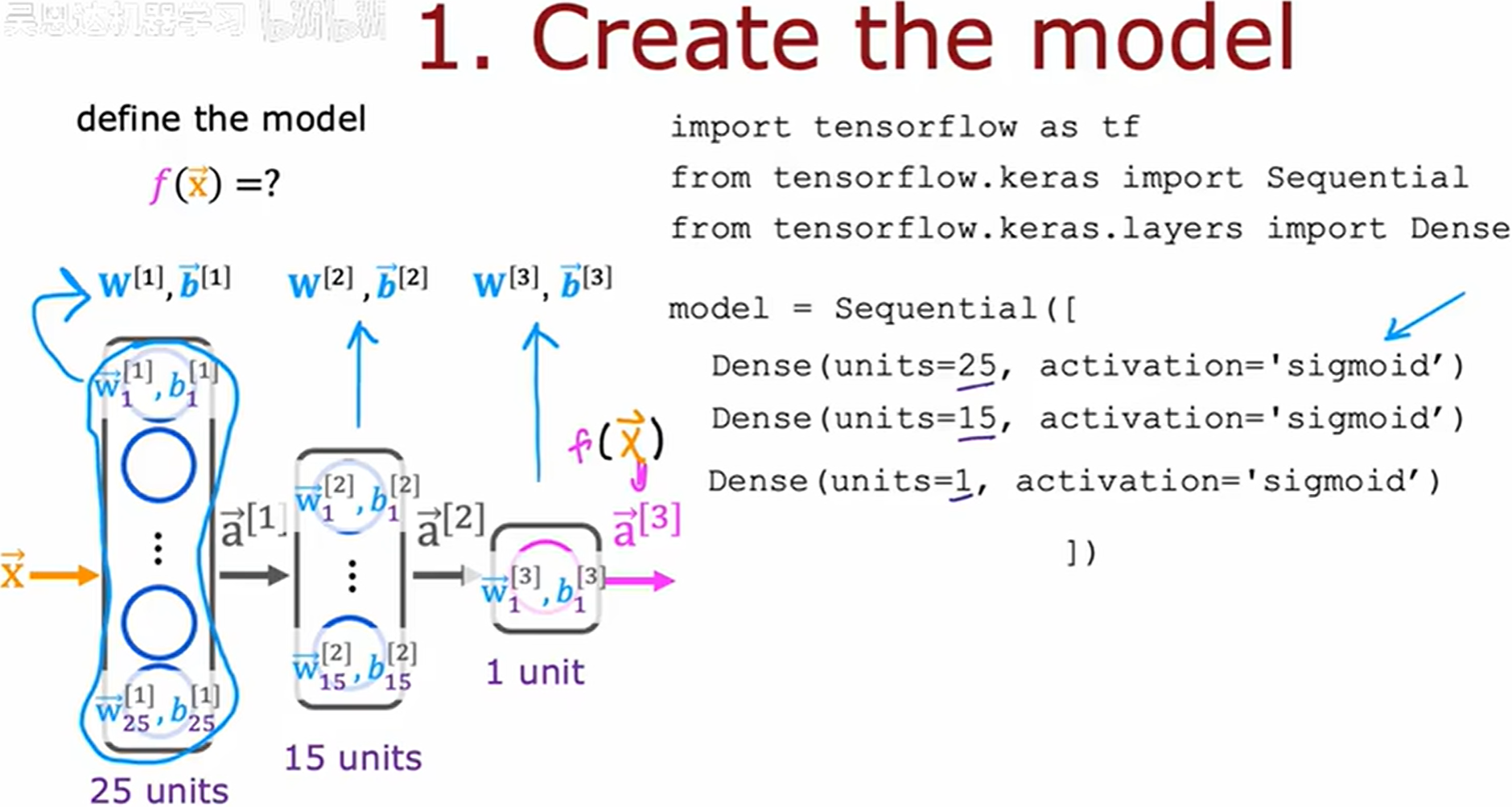
构建一个神经网络

前面学习的前向传播的方式,通过逐层计算进行前向传播的一种显示方法。
下面介绍另一种实现前向传播以及学习的方法。
在 TensorFlow 中,Sequential 是一个用于构建线性堆叠神经网络模型的 Keras API 类。它允许用户通过简单地按顺序添加层(Layer)来快速构建模型,适用于大多数前馈神经网络(Feedforward Neural Network)结构。
图中按照
layer_1layer_2按照从左到右的顺序叠加
创建 Sequential 模型的两种方式
(1) 通过 add() 方法逐层添加
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) # 第一层需指定input_shape
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax')) # 输出层
(2) 直接传入层列表初始化
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
关键方法
| 方法 | 用途 |
|---|---|
model.summary() |
打印模型结构及参数统计(示例输出见下文) |
model.compile() |
配置训练参数(优化器、损失函数、评估指标) |
model.fit() |
训练模型 |
model.predict() |
推理 |
summary() 输出示例:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
flatten (Flatten) (None, 21632) 0
dense (Dense) (None, 128) 2769024
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 2,770,634
Trainable params: 2,770,634
Non-trainable params: 0
_________________________________________________________________
关于先前的 数字图像识别的二分类问题,我们同样可以用 TensorFlow 进行类似的构建。
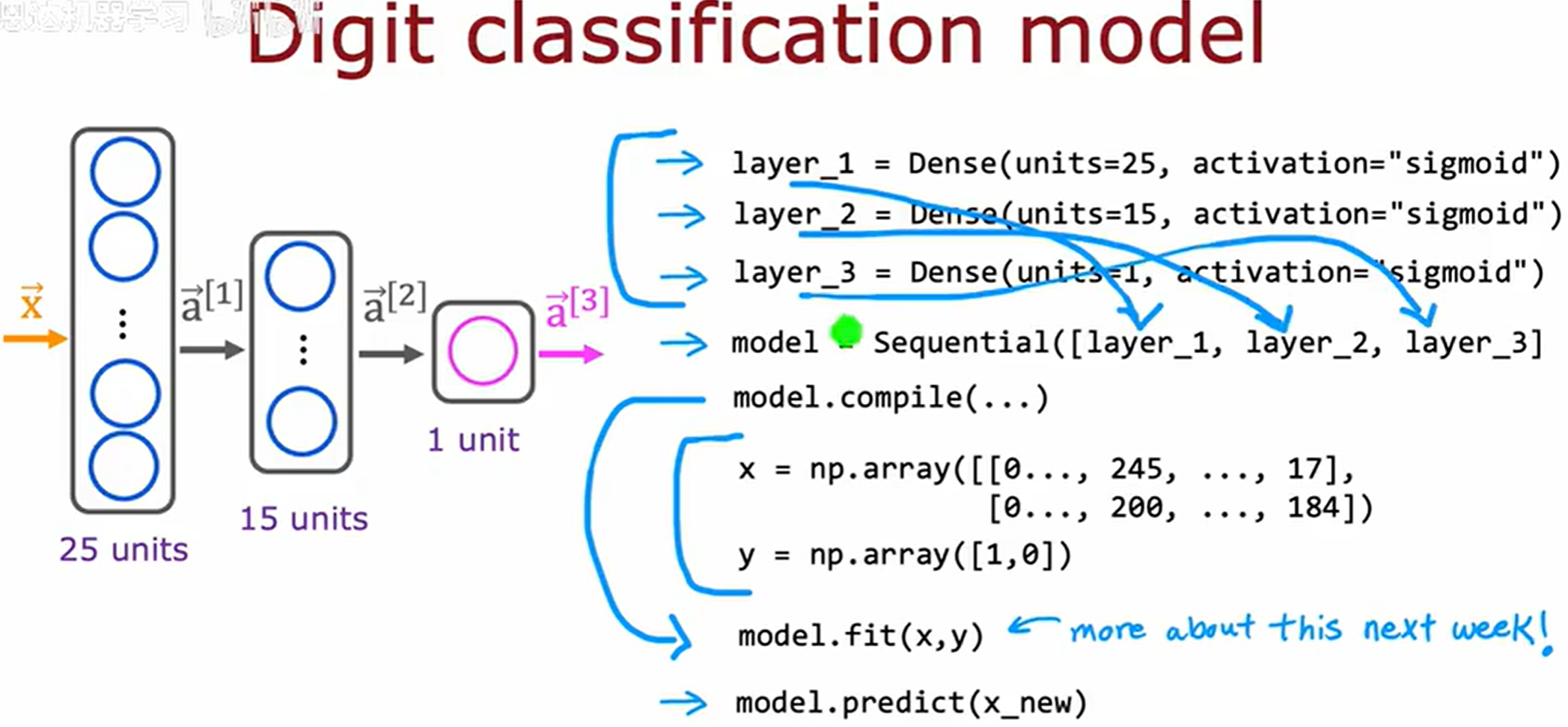
简化后

在一个单层中的前向传播
forward prop (缩写) 前向传播
forward propagation (全称)

仅用 Python 和 Numpy 实现前向传播
前向传播的一般实现
实现 dense() 函数
通过编写函数来实现一个密集层 (Dense Layer),接受上一层的激活值作为输入,以及给定层中神经元的参数 w w w 和 b b b。

Numpy 切片注意事项
Q: 为什么 [:, j] 会返回一维数组?
A: 在 NumPy 中,当你对某一维进行“精确索引”(即给定了具体的数字,比如 j),而不是用切片(比如 j:j+1),NumPy 默认会:
压缩掉(squeeze)那一维。
也就是说:
w[:, j]
上述代码中的 j 是一个整数索引 → 表示“精确指定第 j 列”,不是一个范围。
所以 NumPy 就会把“列这个维度”给挤没了,返回一个一维数组,形状是 (m,)。
举个例子来对比:
假设:
w = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
# 精确索引,压缩列维度,结果是一维:
w[:, 1]
# -> array([2, 5, 8]) shape: (3,)
# 切片形式,保留列维度,结果是二维(列向量):
w[:, 1:2]
# -> array([[2],
# [5],
# [8]]) shape: (3, 1)
实现 sequential() 顺序串联函数

通向 AGI 的可能性
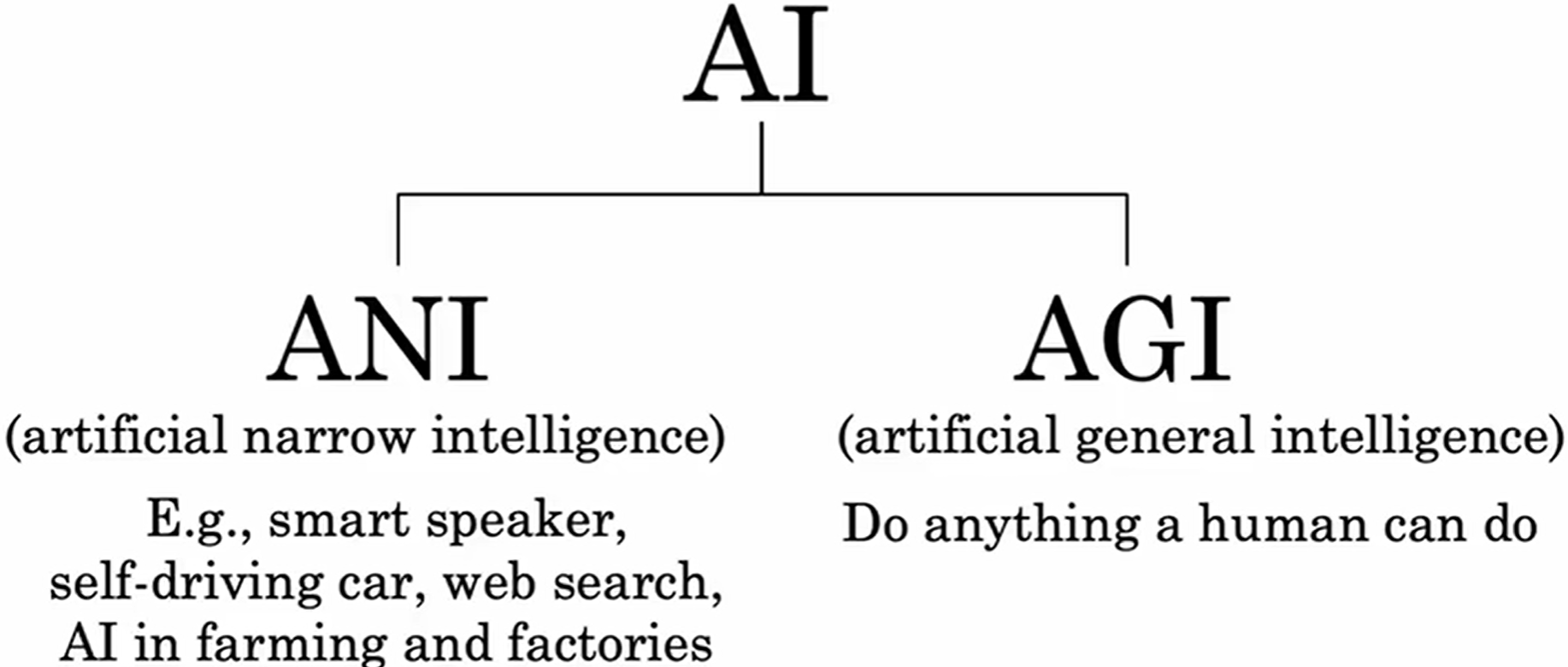
狭义人工智能 (ANI) (Artificial narrow intelligence)
- 专精于单一任务(如人脸识别、围棋、语音助手)。
- 依赖大量标注数据和特定规则,缺乏泛化能力。
- 当前所有工业应用均属此类(如ChatGPT仍是任务导向的对话系统)。
通用人工智能 (AGI) (Artificial General Intelligence)
- 具备人类水平的跨领域学习、推理和适应能力。
- 关键特征:自主性(无需预设任务)和元学习能力(从少量数据中归纳通用规律)。
但近几年都是 ANI 方向的发展,对于 AGI 的发展鲜有涉及。
由于生物大脑组织可以完成出人意料的广泛任务,这导致了一个学习算法的假设,也许大量的智能是由少数几个学习算法决定的,如果能搞清或许某天能在计算机中实现。
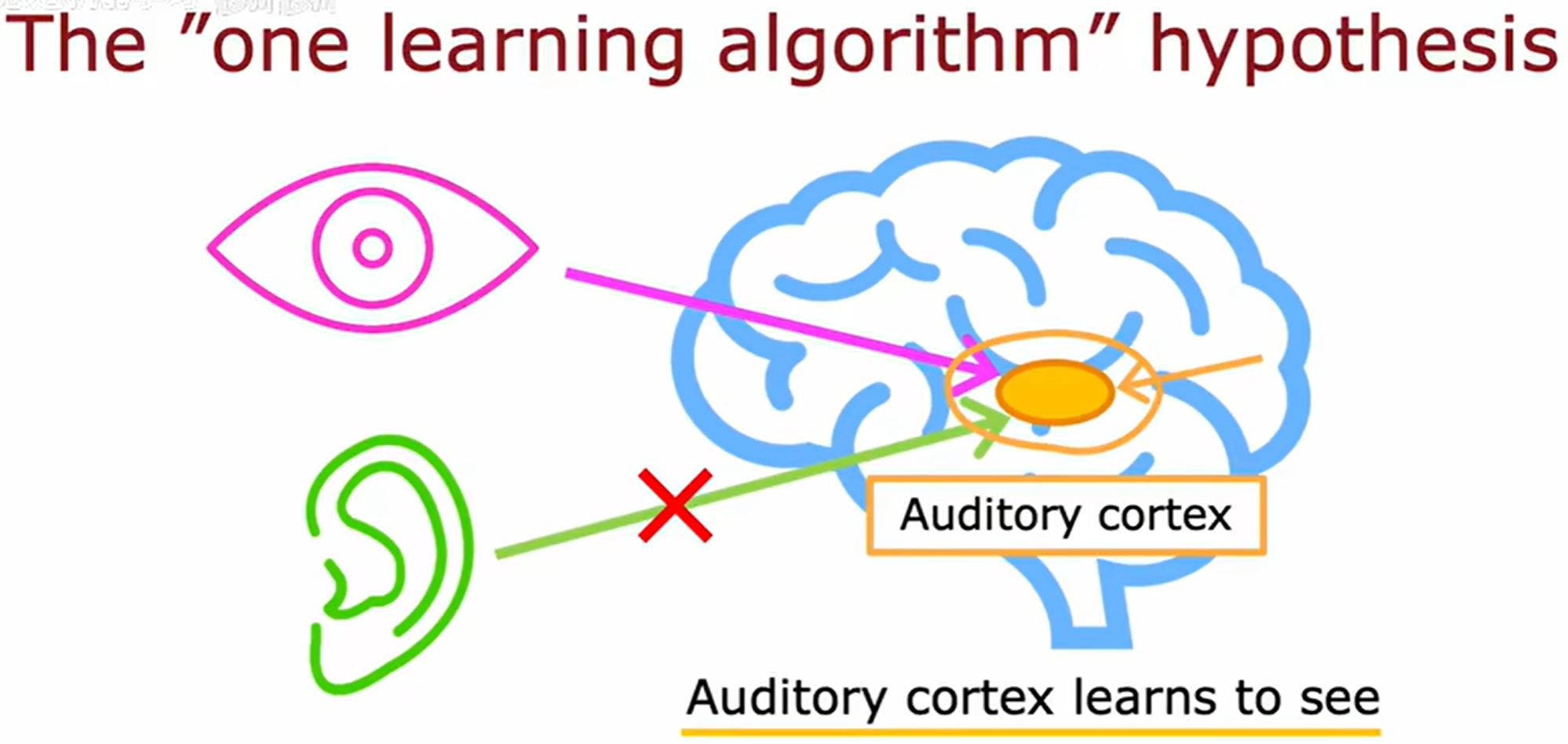
一项实验,将图像输入到听觉皮层,那么听觉皮层就会学会看。
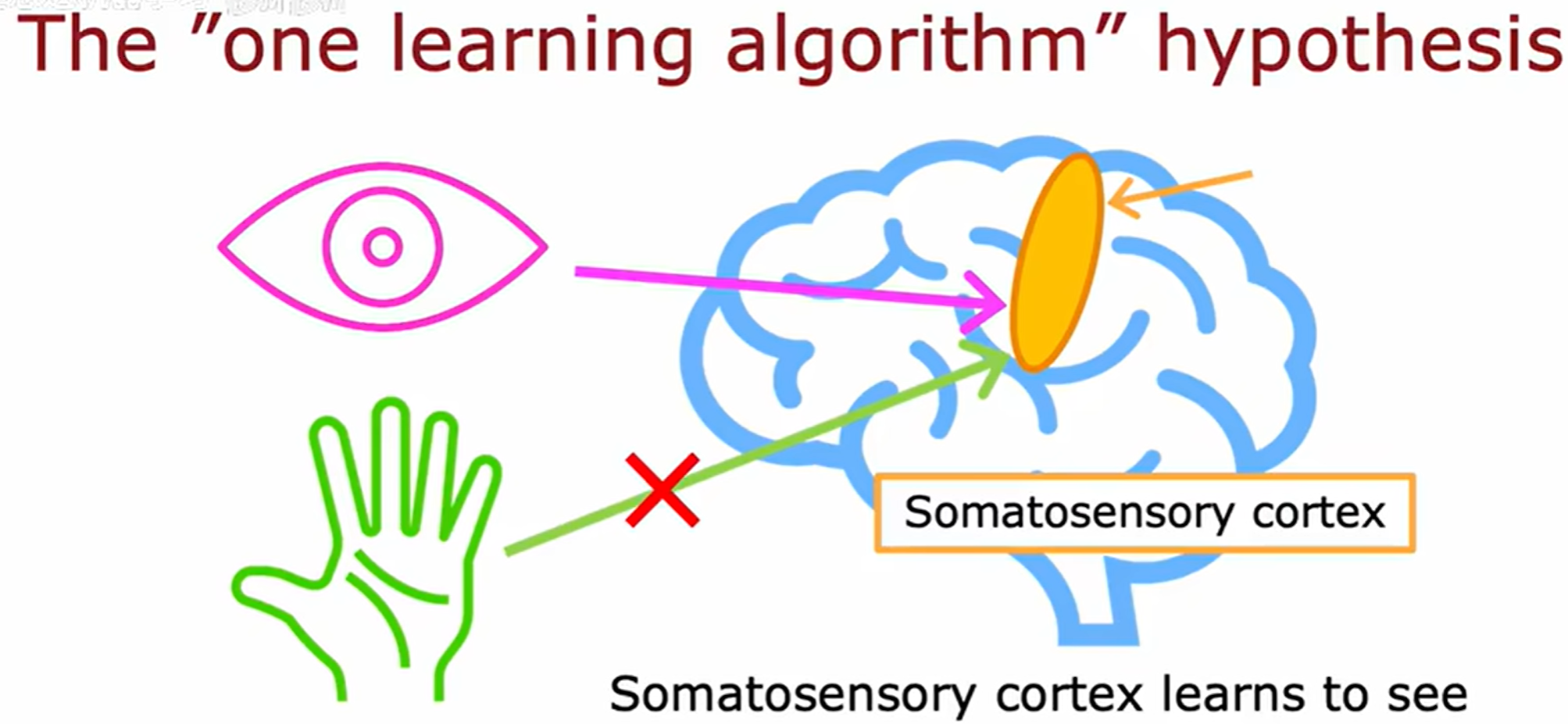
将图像输入到躯体感觉皮层,那么躯体感觉皮层就会学会看。
就好像有个算法,只取决于收到的数据,学习相应地处理输入。
神经可塑性实验(如视觉信号输入听觉皮层)表明:
- 大脑皮层可能存在统一的学习算法,通过数据输入动态重组功能。
- 支持这一假设的理论包括:
- 赫布学习法则(Hebbian Learning):“一起激活的神经元连在一起”。
- 预测编码理论:大脑通过不断预测输入信号优化内部模型。
争议点:大脑是否真的依赖单一算法?小脑(负责运动协调)的微电路结构与新皮层明显不同,暗示可能存在多种学习机制。
构建像人脑一样的学习算法
神经网络如何高效实现
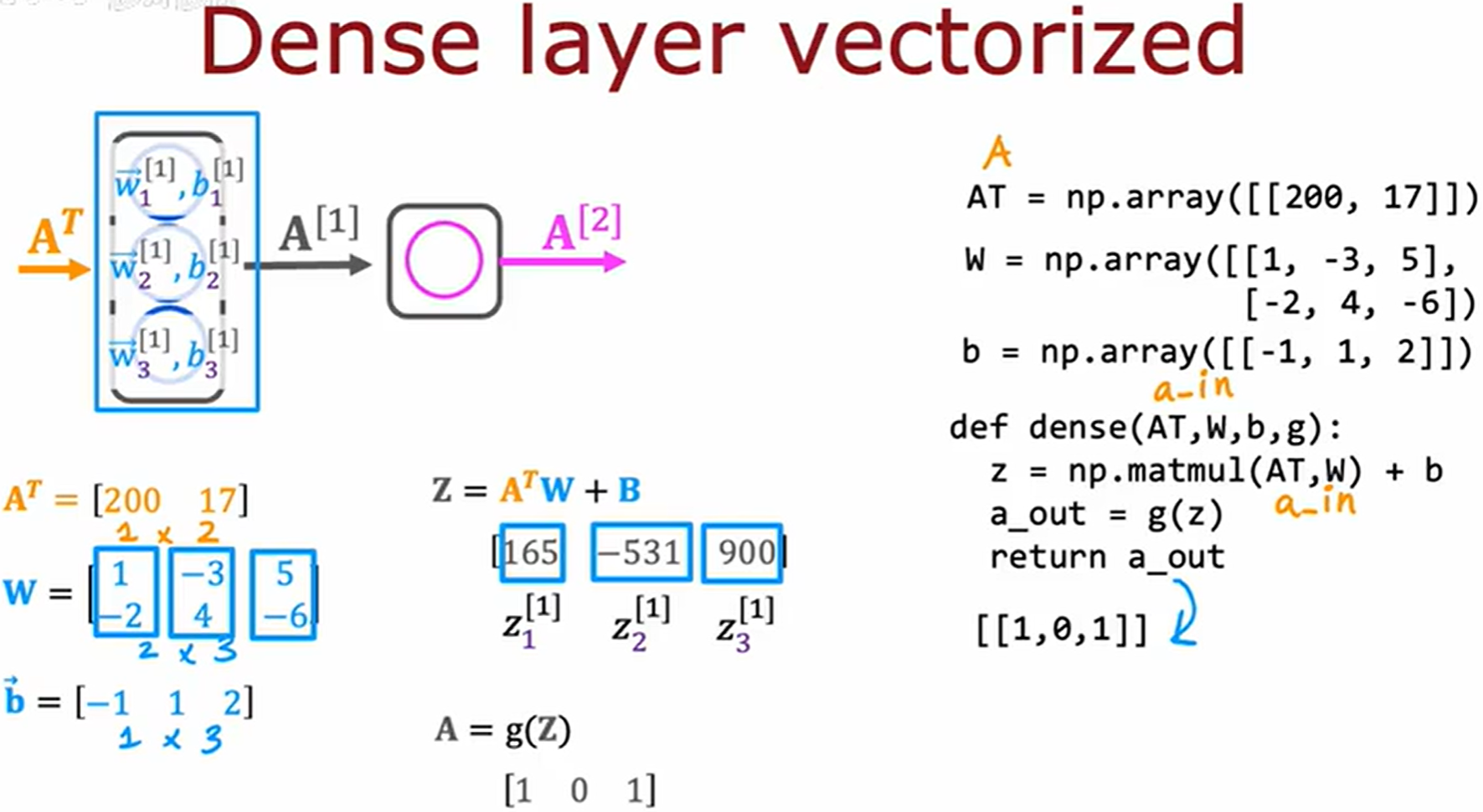
在过去十年间,神经网络能够被扩展的原因之一是因为神经网络可以矢量化,可以通过矩阵乘法非常高效地实现。

matmul 函数进行矩阵乘法
全称 matrix multiplication
矩阵乘法
transpose 转置
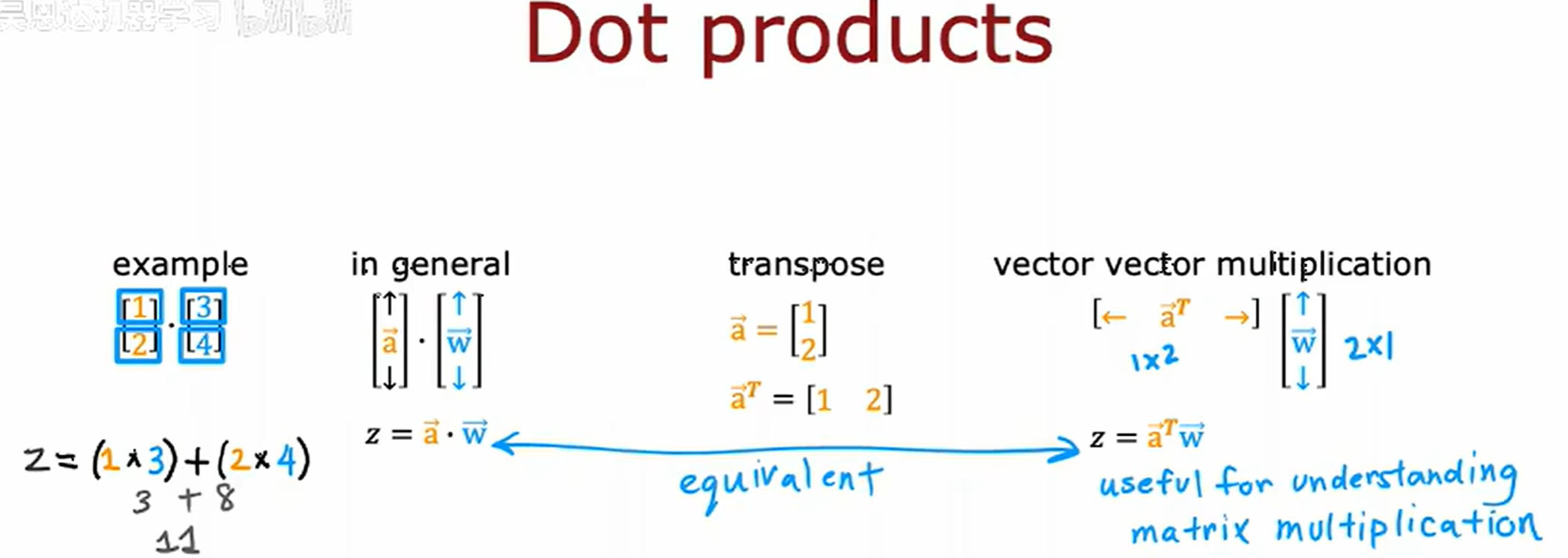

矩阵可以看作为向量组的扩展
而转置之后列向量变为横向量

Z = np.matmul(AT, W)
# 矩阵相乘还可以写为
Z = AT @ W
TensorFlow实现
Binary Cross Entropy 二元交叉熵
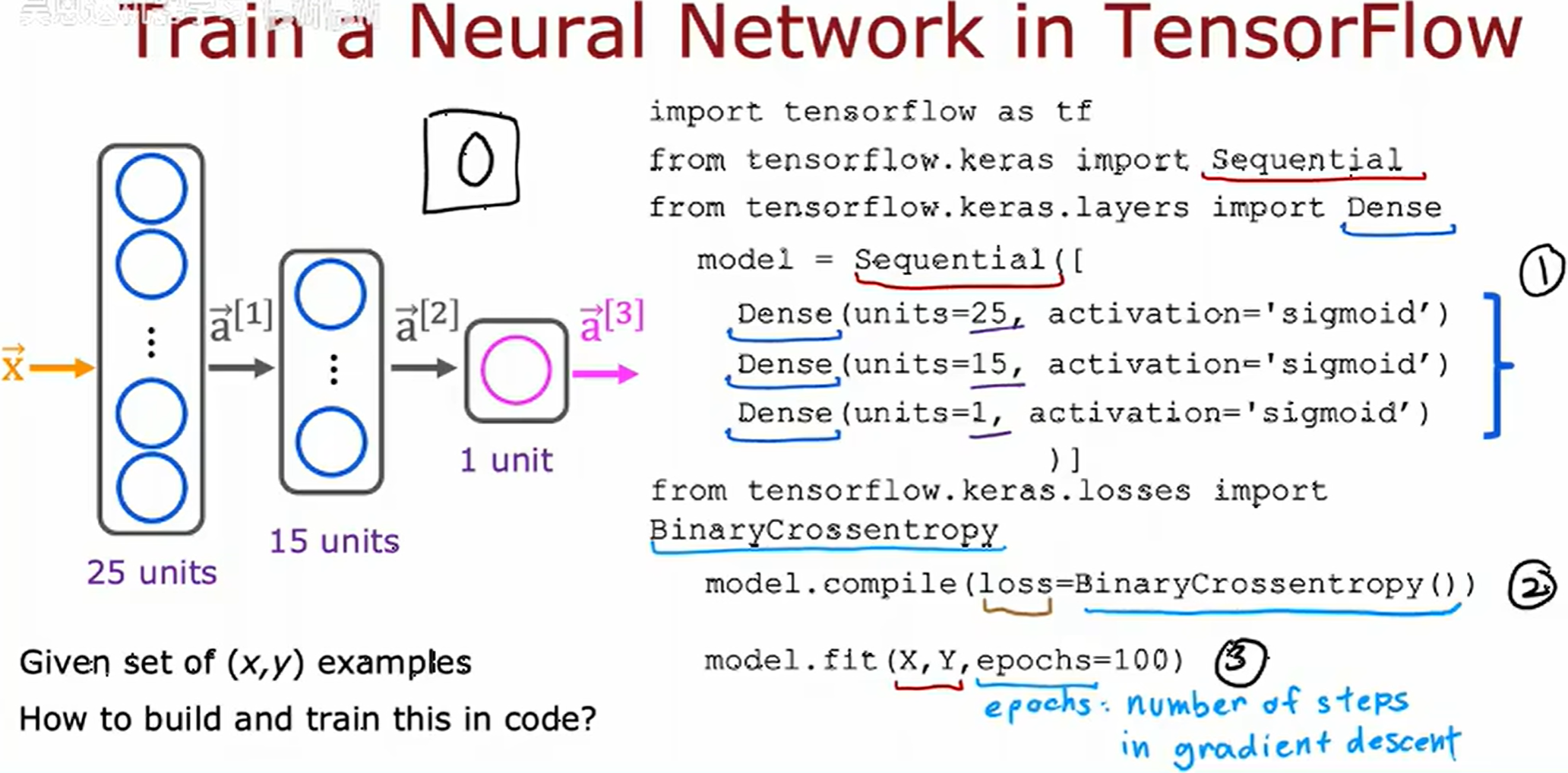
使用 TensorFlow 训练神经网络:
- 模型定义:使用 TensorFlow 的 Keras API 构建神经网络模型架构,明确指定各层的类型(如 Dense、Conv2D 等)、激活函数以及前向传播的计算逻辑。
- 模型编译:通过
model.compile()方法配置训练过程,需指定:- 优化器(如
adam、sgd) - 损失函数(如
crossentropy、mse) - 评估指标(如
accuracy)
- 优化器(如
- 模型训练:调用
model.fit()方法执行训练,需传入:- 训练数据集
- 批次大小(batch_size)
- 训练周期数(epochs)
- 验证数据(可选)
训练细节
① 指定如何根据输入 x 和参数计算输出
② 指定损失和代价函数
③ 最小化代价函数



fit 自动实现了前向传播、计算损失、方向传播、迭代(重复)的过程。
sigmoid的替代
问题的提出
如上图中,认知度可能不是二元数字,而是任何非负值,从0到一个非常大的值。所以之前采用 sigmoid 函数的效果可能不是很好,可以选择换用不同的激活函数。
ReUL
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元
ReLU是目前深度神经网络中常用的激活函数之一
ReLU(Rectified Linear Unit)更适合深层次网络和高维数据
- 缓解梯度消失:ReLU在正区间的导数为1,能有效避免深层网络中的梯度指数级衰减问题(优于sigmoid的饱和区梯度接近于零)。
- 稀疏激活:负区间输出为零的特性可产生稀疏激活,提升计算效率。
- 线性特性:正区间的线性行为使优化更稳定,适合高维数据(如图像、文本等)的复杂特征学习。
Sigmoid更适合二分类问题和浅层网络的原因
- 概率化输出:其输出范围(0,1)天然适配二分类的概率解释(如逻辑回归),输出可直接视为类别概率。
- 平滑性:全程可导的S型曲线适合浅层网络的梯度计算,但深层网络中易导致梯度消失(尤其在饱和区)。
- 历史局限性:早期神经网络(如单层感知机)常使用sigmoid,但现代深层架构中多被ReLU或其变种取代。
选择激活函数
输出层的激活函数选择

二分类

回归

回归(数据非负)

隐藏层的激活函数选择
事实证明,ReLU(Rectified Linear Unit)激活函数已成为训练神经网络时的首选。这一领域的实践已逐渐转向普遍使用 ReLU,而 sigmoid 的使用显著减少,唯一的常见例外是二分类任务的输出层(此时仍需使用 sigmoid 将输出压缩到 [0,1] 范围内)。
主要原因如下:
主要原因如下:
-
计算效率
ReLU 的计算为简单的阈值操作( R e L U ( x ) = m a x ( 0 , x ) ReLU(x)=max(0,x) ReLU(x)=max(0,x)),仅需比较和取零操作;而 sigmoid( σ ( x ) = 1 1 + e − x σ(x)=\frac{1}{1 + e^{−x}} σ(x)=1+e−x1)涉及指数运算和除法,计算成本显著更高。这在深层网络和大规模数据训练中尤为关键。 -
梯度消失问题
- ReLU 的梯度在正区间恒为 1,负区间恒为 0,仅在一侧(负半轴)存在“平坦”区域。
- Sigmoid 的梯度( σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) σ′(x)=σ(x)(1−σ(x)) σ′(x)=σ(x)(1−σ(x)))在输入绝对值较大时( ∣ x ∣ ≫ 0 |x|≫0 ∣x∣≫0)会趋近于 0,导致函数在两侧均呈现“平坦化”。
在反向传播中,若梯度值过小(例如 sigmoid 的饱和区),根据梯度下降公式 θ t + 1 = θ t − η ∇ θ J \theta_{t+1} = \theta_t - \eta \nabla_\theta J θt+1=θt−η∇θJ,参数更新步长会极度缓慢,需要更多迭代次数才能收敛,甚至可能因梯度消失而无法训练深层网络。
-
稀疏激活性
ReLU 的负半轴输出为零,可引入稀疏性,可能减少过拟合并提升模型泛化能力,而 sigmoid 的输出始终为非零,缺乏这一特性。
注意
当输入值为负数时,其输出值和导数值均为0,意味着该神经元会处于熄灭状态,逆向参数调整过程中不产生梯度调整值,这个时候会用到Leakly ReLU。
总结

隐藏层默认选择 ReLU
输出层根据输出选择
为什么需要激活函数
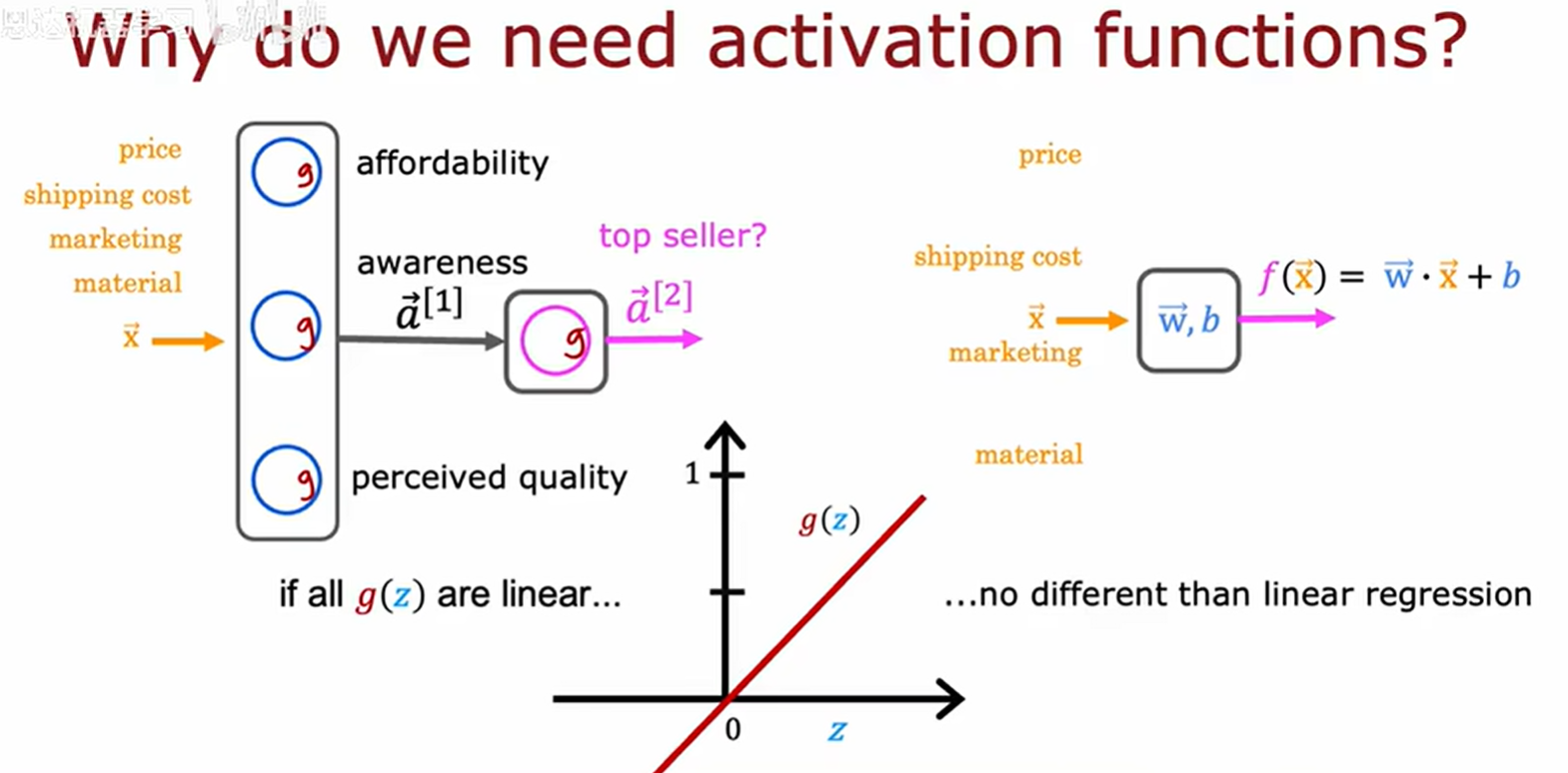
如果所有节点都使用线性激活函数(相当于没有使用线性激活函数),会发现这个大型神经网络将于线性回归没有任何区别,这样会完全破坏使用神经网络的目的,因为其无法拟合。
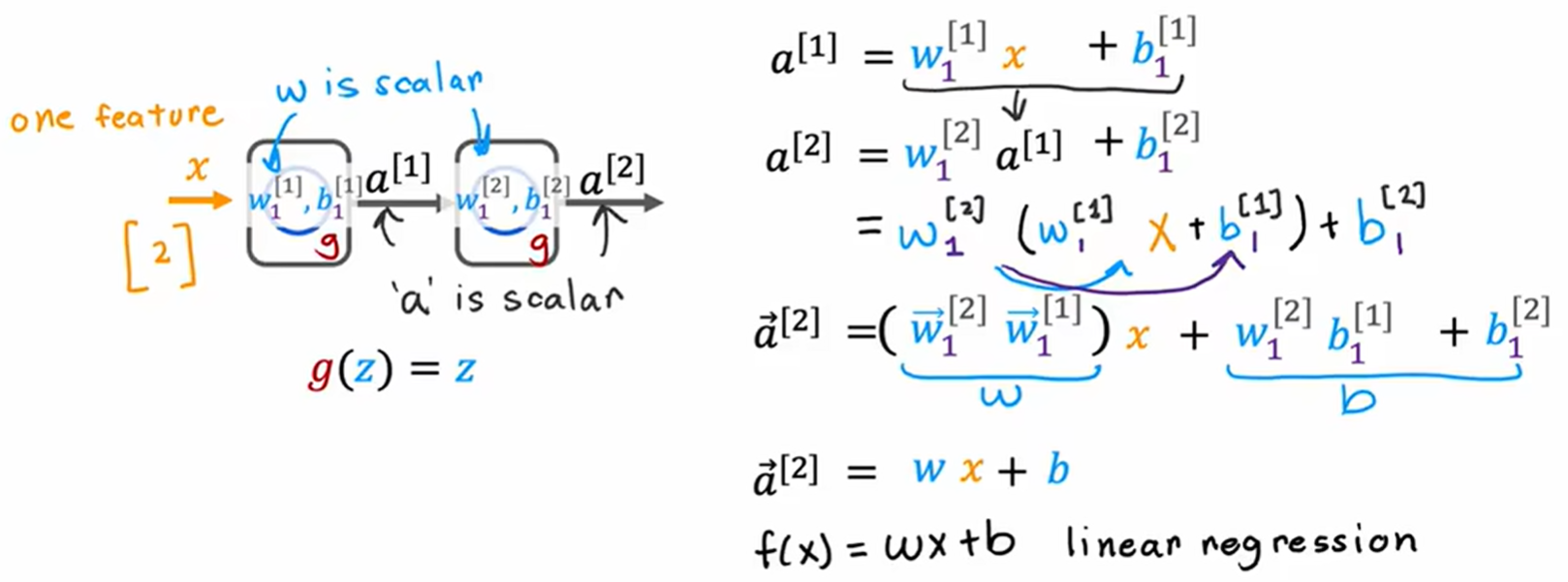
如果神经网络中所有层都使用线性激活函数,那么整个网络就等价于一个线性回归模型,无论它有多少层。这是因为线性变换的叠加仍然是线性变换。
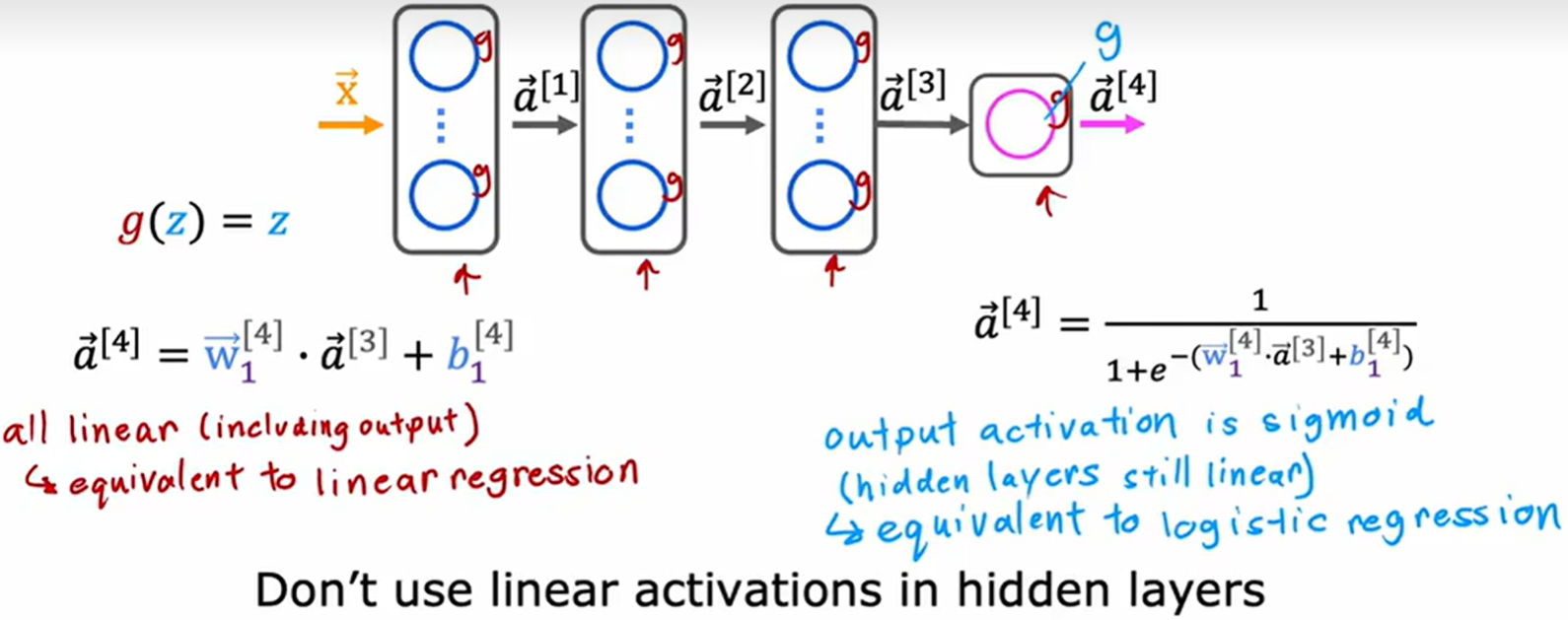
隐藏层全部线性函数,最后输出层激活函数使用 sigmoid 函数,最后整个网络等同于一个逻辑回归模型。
因此 建议使用 ReLU 作为隐藏层激活函数。
线性回归模型的形式为:
y = w T x + b \quad y = \mathbf{w}^T\mathbf{x} + b y=wTx+b
关键修正说明:
-
关于线性回归的非线性拟合:
-
严格来说,线性回归只能拟合输入特征的线性组合
-
若要拟合非线性曲线,必须手动构造非线性特征(如多项式特征):
y = w 1 x + w 2 x 2 + . . . + w n x n + b y = w_1x + w_2x^2 + ... + w_nx^n + b y=w1x+w2x2+...+wnxn+b -
这种人工特征工程效率有限
-
-
神经网络的核心优势:
-
通过多层非线性激活函数(如ReLU)自动学习特征变换:
h = ReLU ( W 1 x + b 1 ) \mathbf{h} = \text{ReLU}(\mathbf{W}_1\mathbf{x} + \mathbf{b}_1) h=ReLU(W1x+b1)y = W 2 h + b 2 y = \mathbf{W}_2\mathbf{h} + \mathbf{b}_2 y=W2h+b2
-
每层都能进行非线性变换,形成层次化特征表示
-
通用逼近定理证明:只需单隐藏层即可逼近任意连续函数
-
-
本质区别:
- 线性回归:固定特征空间中的线性决策
- 神经网络:可学习非线性的特征空间变换
示例对比:
- 拟合正弦曲线:
- 线性回归需手动设计傅里叶基函数
- 神经网络自动学习适合的波形特征
那么为什么采用 ReLU 可以避免这种情况
由于 ReLU 右侧依旧是线性函数,要是输入和权重全部强制非负(例如某些特殊设计的约束网络),那么 ReLU 会退化为线性函数。但在标准的神经网络中,偏置是可正可负的,因此 ReLU 总能引入非线性。
ReLU 的非线性本质
ReLU 的定义是 R e L U ( x ) = m a x ( 0 , x ) ReLU(x)=max(0,x) ReLU(x)=max(0,x),它是一个分段线性函数:
- 当 x > 0 x>0 x>0 时,输出 x x x(线性部分)。
- 当 x ≤ 0 x≤0 x≤0 时,输出 0 0 0(非线性部分,因为截断了负值)。
即使输入特征 xx 全是非负数,权重 W W W 和偏置 b b b 仍然可能产生负值:
- 例如,某神经元的输入是 z = W x + b z=Wx+b z=Wx+b,如果 W W W 或 b b b 为负,则 z z z 可能为负,此时 ReLU 会输出 0 0 0,从而引入非线性。
直观例子
⚠️ 没有 ReLU 的情况(纯线性网络)
设输入是一个数 x,网络结构如下:
- 第一层: y 1 = 2 x + 1 y_1 = 2x + 1 y1=2x+1
- 第二层: y 2 = 3 y 1 + 4 y_2 = 3y_1 + 4 y2=3y1+4
我们计算一下输出:
y 2 = 3 ( 2 x + 1 ) + 4 = 6 x + 3 + 4 = 6 x + 7 y_2 = 3(2x + 1) + 4 = 6x + 3 + 4 = 6x + 7 y2=3(2x+1)+4=6x+3+4=6x+7
也就是说:虽然有两层,但整个网络的效果就是一个线性函数: y=6x+7y = 6x + 7y=6x+7,没有任何非线性。
✅ 加上 ReLU 的情况
现在我们把中间加一个 ReLU,结构变为:
- 第一层: y 1 = ReLU ( 2 x + 1 ) y_1 = \text{ReLU}(2x + 1) y1=ReLU(2x+1)
- 第二层: y 2 = 3 y 1 + 4 y_2 = 3y_1 + 4 y2=3y1+4
这就不一样了,我们来看两种情况:
情况1:当 2 x + 1 > 0 2x + 1 > 0 2x+1>0
y 1 = 2 x + 1 ⇒ y 2 = 3 ( 2 x + 1 ) + 4 = 6 x + 7 y_1 = 2x + 1 \Rightarrow y_2 = 3(2x + 1) + 4 = 6x + 7 y1=2x+1⇒y2=3(2x+1)+4=6x+7
情况2:当 2 x + 1 ≤ 0 2x + 1 \leq 0 2x+1≤0
y 1 = 0 ⇒ y 2 = 3 ⋅ 0 + 4 = 4 y_1 = 0 \Rightarrow y_2 = 3 \cdot 0 + 4 = 4 y1=0⇒y2=3⋅0+4=4
所以这个网络变成了一个分段函数:
f ( x ) = { 6 x + 7 , x > − 0.5 4 , x ≤ − 0.5 f(x) = \begin{cases} 6x + 7, & x > -0.5 \\ 4, & x \leq -0.5 \end{cases} f(x)={6x+7,4,x>−0.5x≤−0.5
这就是非线性的本质了 —— 一个简单的 ReLU 就让模型具备了分段建模能力!
多类别分类 (Multiclass Classification)

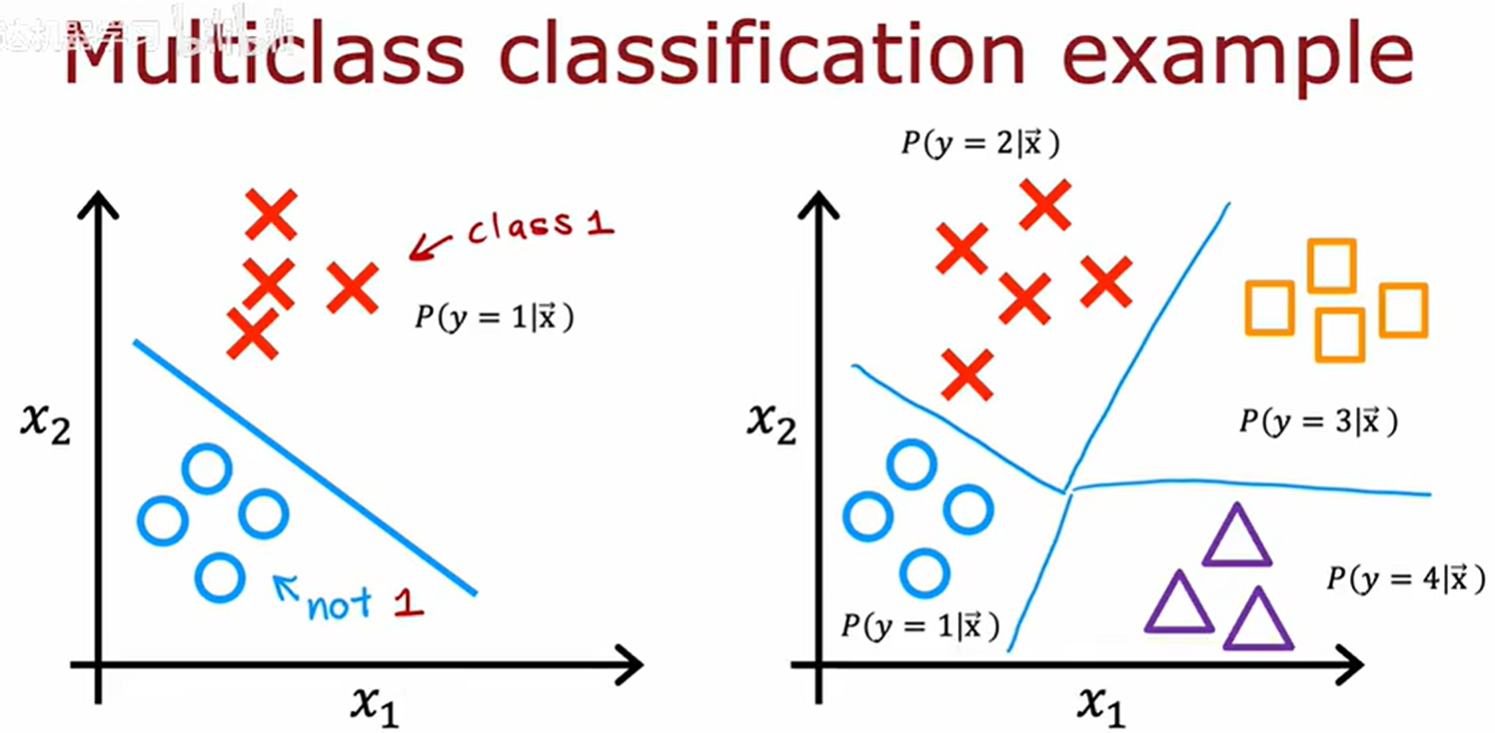
多类别分类将会采用 softmax 回归学习算法,是逻辑回归的推导。
Softmax回归
Softmax回归介绍
Softmax函数,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的 K K K 维向量 z z z “压缩”到另一个 K K K 维实向量 σ ( z ) σ(z) σ(z) 中,使得每一个元素的范围都在 ( 0 , 1 ) (0,1) (0,1) 之间,并且所有元素的和为 1 1 1。

logistic 函数可以看作是 softmax 函数中的 n = 2 的一种情况
对比 logistic 函数的 loss函数,我们可以通过同构来得到 softmax 的 loss 函数。
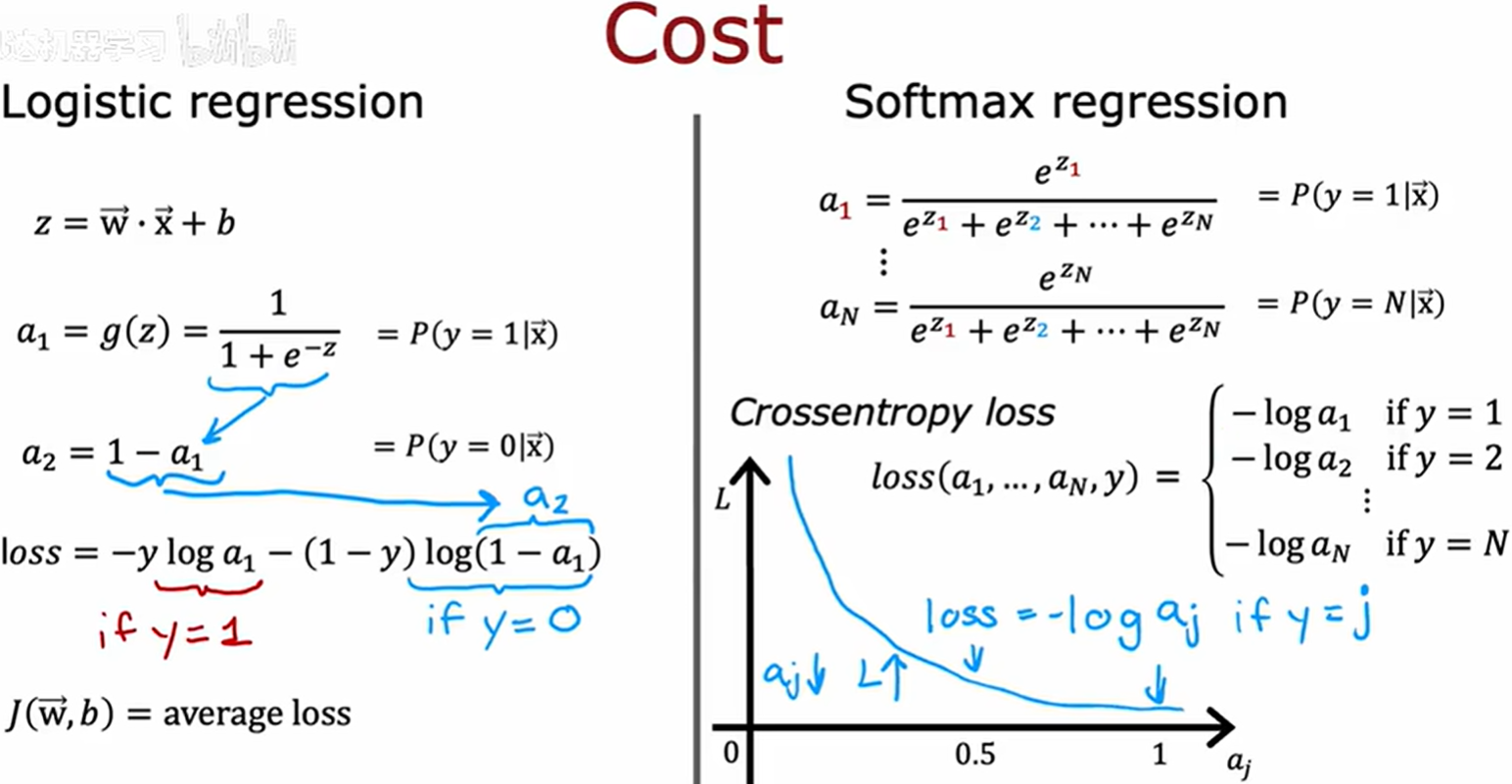
交叉熵(Cross Entropy)
在图中,每一个真实值 y y y 对应 a j a_j aj 概率,我们都希望非常的大,因此在 a j a_j aj 靠向 1 1 1 的时候,其惩罚值非常的小。
神经网络的Softmax输出
采用 softmax 作为输出层激活函数,来实现手势识别 0 − 9 0 - 9 0−9 的数字分类。
Softmax把神经网络的"原始得分"变成"清晰易懂的概率",让模型能明确告诉你:「我认为最可能是这个!」。
更准确地说,Softmax函数将神经网络最后一层的原始输出通过指数归一化处理,转化为一个概率分布,使得:
- 每个类别的概率值严格介于0和1之间
- 所有类别的概率之和为1
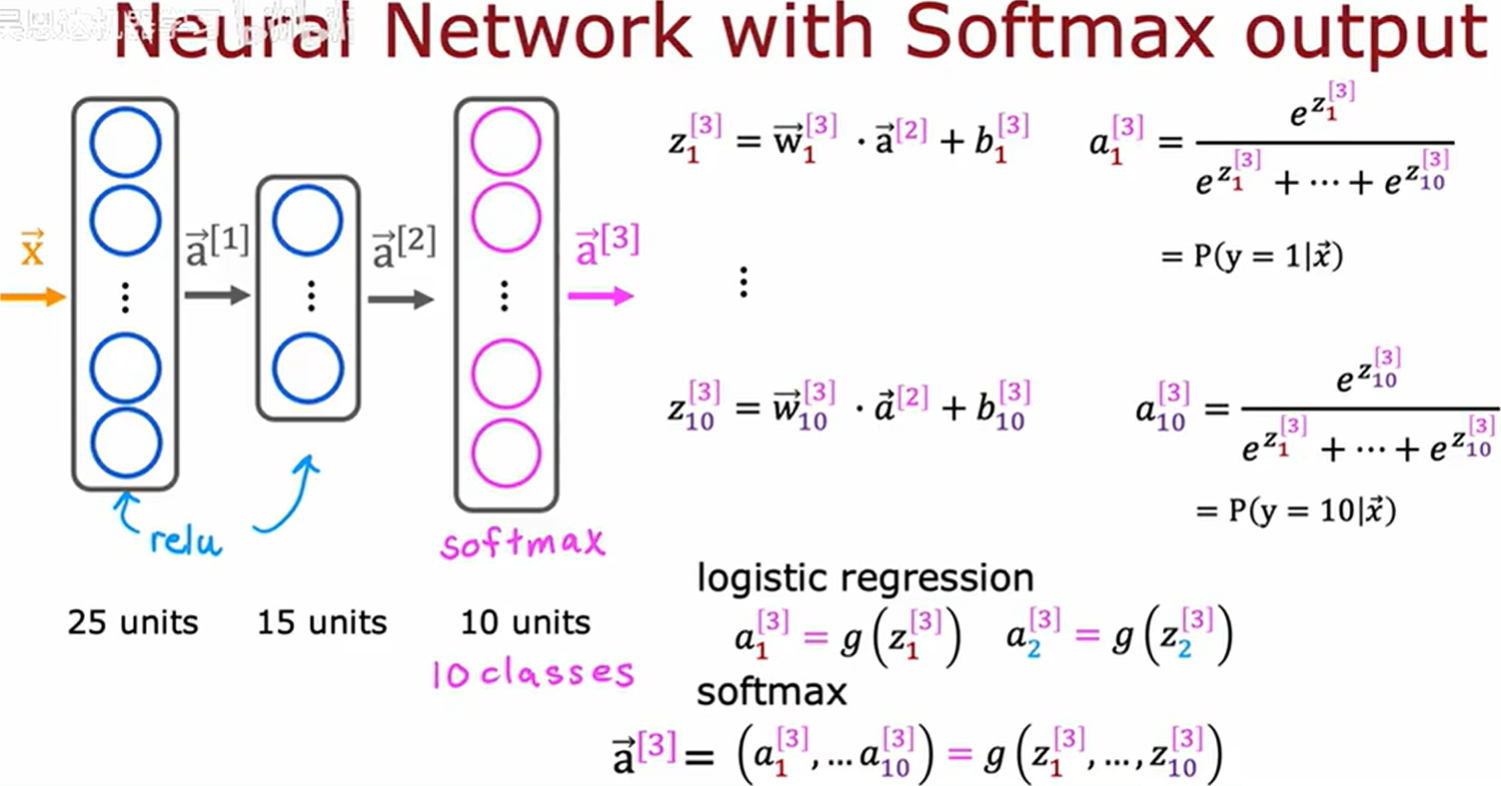
通过 TensorFlow 实现
在 TensorFlow 中将 Softmax 函数的 loss 函数称为
sparse categorical cross-entropy function(稀疏类别交叉熵函数)

尽管上述实现代码可以运行,但是尽量不要使用上述实现的版本,后续会有更加推荐的版本。
Softmax的改进实现
Roundoff 舍入
Numerical Roundoff Errors 数值舍入误差

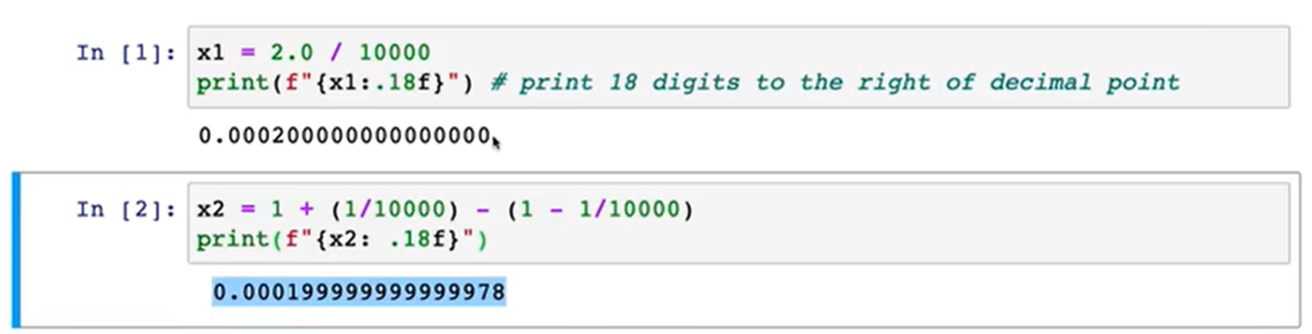
数值舍入误差

原始实现,先将 a 给精确计算了出来作为中间量,这样会导致后续的舍入误差。
但是通过如图底部的 loss 函数将整个表达式展开,整体作为一个 loss 函数,这样 TensorFlow 就会有更多的灵活性来计算(如合并 log 项等),并决定是否需要把 a 精确计算出来。

Logit 是模型最后一层(通常是线性层)的直接输出,没有经过任何概率归一化。Logit 通常指模型输出的原始预测分数(raw score),尚未经过概率转换(如 Softmax 或 Sigmoid)
Logit 的数学意义
(1) 二分类任务(Sigmoid) Logit 通过 Sigmoid 函数转换为概率: σ ( z ) = 1 1 + e − z (其中 z 是 logit) \sigma(z) = \frac{1}{1 + e^{-z}} \quad \text{(其中 } z \text{ 是 logit)} σ(z)=1+e−z1(其中 z 是 logit) 例如:当 z = 2.0 时,概率为 σ ( 2.0 ) ≈ 0.88 \sigma(2.0) \approx 0.88 σ(2.0)≈0.88
(2) 多分类任务(Softmax) Logits 通过 Softmax 转换为概率分布: softmax ( z i ) = e z i ∑ j = 1 K e z j ( K 为类别数) \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} \quad \text{(} K \text{ 为类别数)} softmax(zi)=∑j=1Kezjezi(K 为类别数) 例如:当 z = [1.0, 0.5, -1.0] 时,概率分布为 softmax ( [ 1.0 , 0.5 , − 1.0 ] ) ≈ [ 0.53 , 0.32 , 0.15 ] \text{softmax}([1.0, 0.5, -1.0]) \approx [0.53, 0.32, 0.15] softmax([1.0,0.5,−1.0])≈[0.53,0.32,0.15]
在 TensorFlow/Keras 中,from_logits=True 是一个关键参数,主要用于 交叉熵损失函数(如 BinaryCrossentropy、CategoricalCrossentropy 和 SparseCategoricalCrossentropy),它决定了输入数据的格式以及是否需要在损失函数内部自动应用 Softmax/Sigmoid 激活函数。它的作用直接影响数值稳定性和计算效率。
当设置 from_logits=True 时:
- 输入数据(logits)的格式:模型最后一层不应用 Softmax(多分类)或 Sigmoid(二分类),直接输出原始分数(raw logits)。
- 损失函数内部处理:损失函数会自动应用 Softmax/Sigmoid,并采用数值稳定的方式计算交叉熵损失。
from_logits=True内部使用 Log-Sum-Exp Trick 合并 Softmax/Sigmoid 和交叉熵计算,避免数值溢出。

通过将 loss 函数进行展开,TensorFlow 可以重新排列,避免出现一些非常小或者非常大的数字,并找到一个更准确的方式来计算 loss 函数。如上图中,要是 Z i Z_i Zi 非常大的话, e Z i e^{Z_i} eZi 会非常非常大,要是 Z i Z_i Zi 非常小的话, e Z i e^{Z_i} eZi 会更小。
通过添加 SparseCategoricalCrossEntropy(from_logits=True)

由于将输出层换成了 linear 函数,最后输出的不是 a ⃗ \vec{a} a 而是 z ⃗ \vec{z} z 。

执行
logit = model(X)的作用是 使用训练好的模型对输入数据X进行前向传播计算,输出未经过激活函数(如 softmax/sigmoid)的原始预测值(logits)。【因为输出层激活函数是 linear ,所以输出出来的数据其实就是 logits】
多标签分类 (Multi-label Classification)
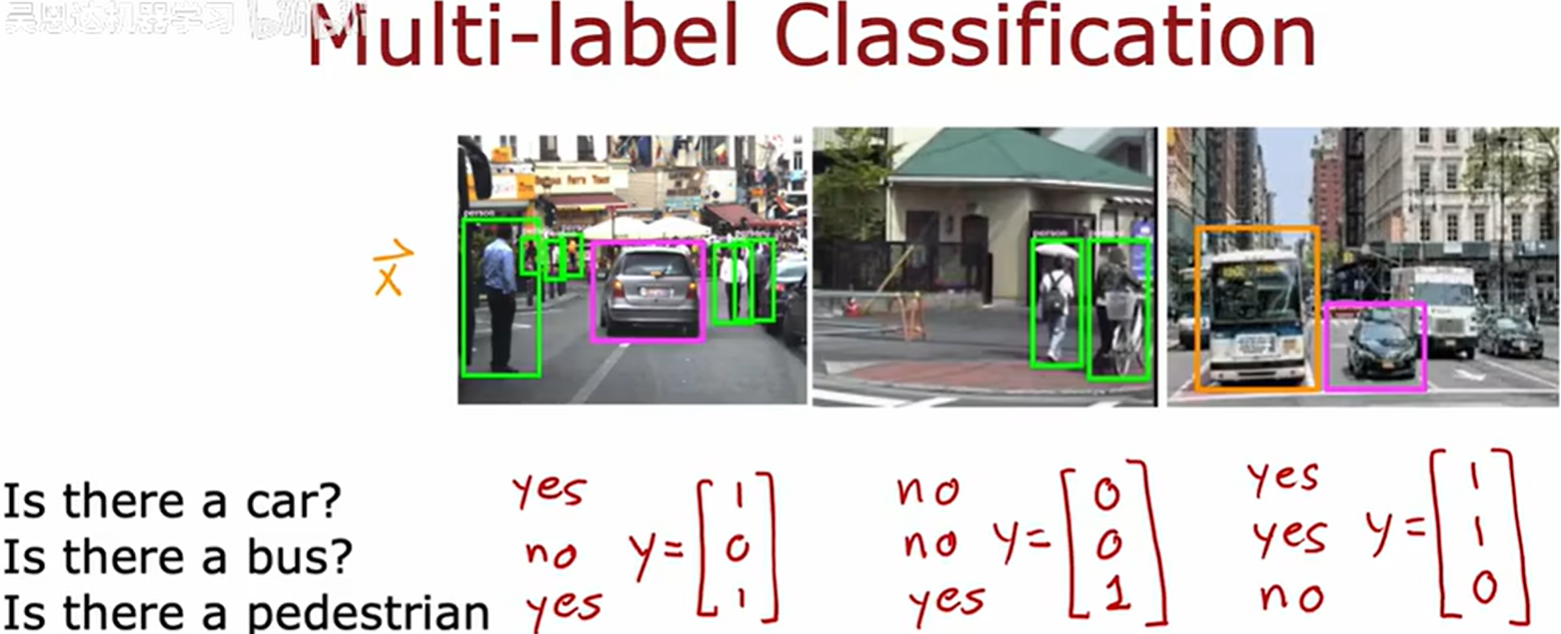
与识别数字 0 - 9 的多类别分类不同
在多标签分类中 y y y 是个向量
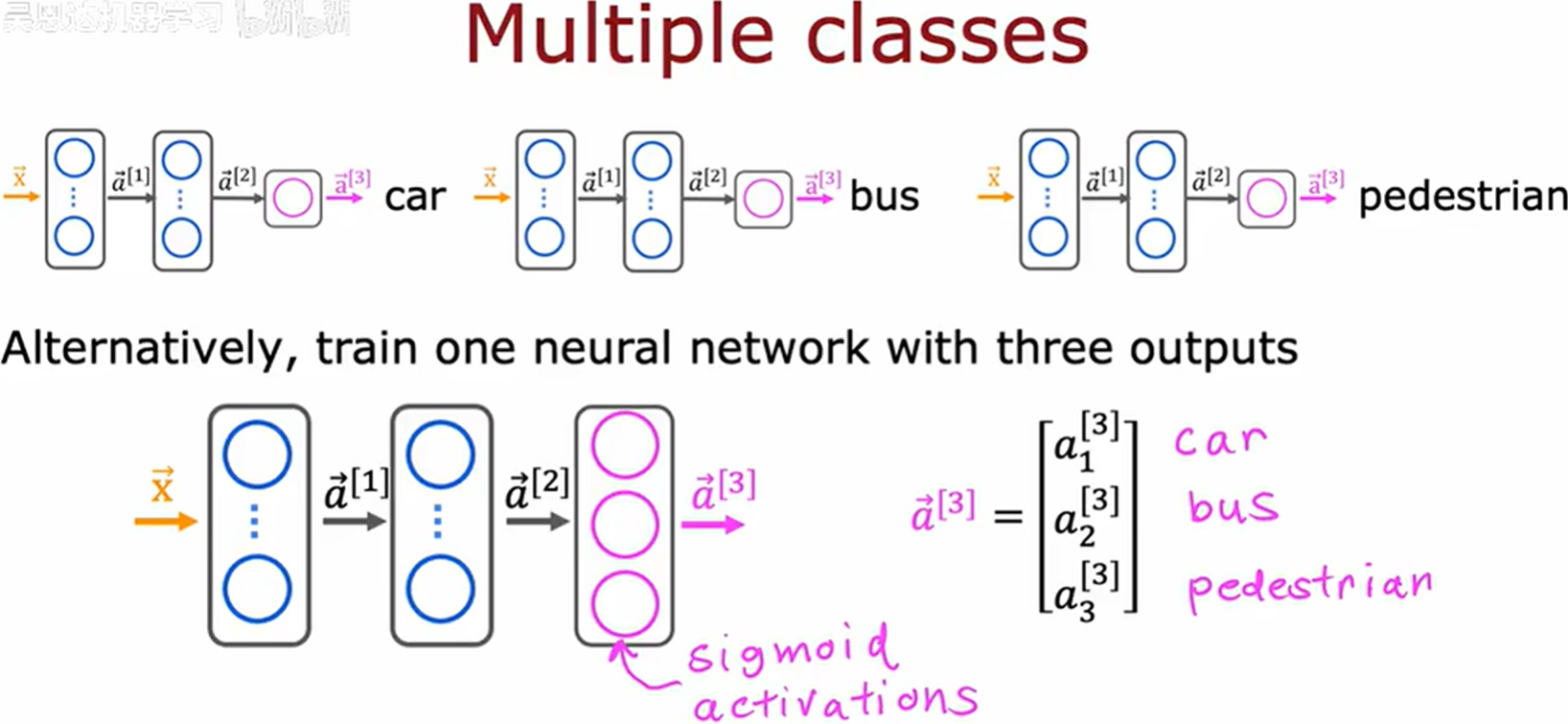
上图两种实现,一种分为三个神经网络分别作用,另一种将三种神经网络整合到了一起。
| 维度 | 多个独立网络 | 单个统一网络 |
|---|---|---|
| 计算效率 | 低(重复计算) | 高(共享特征) |
| 标签相关性 | 无法自动利用 | 自动学习 |
| 灵活性 | 高(可定制模型) | 低(共享架构) |
| 参数量 | 多(独立参数) | 少(共享参数) |
| 适用规模 | 小规模标签(<10) | 大规模标签(>10) |
单个统一网络的标签干扰风险:若标签间存在冲突特征,可能影响整体性能。
高级优化方法
引入
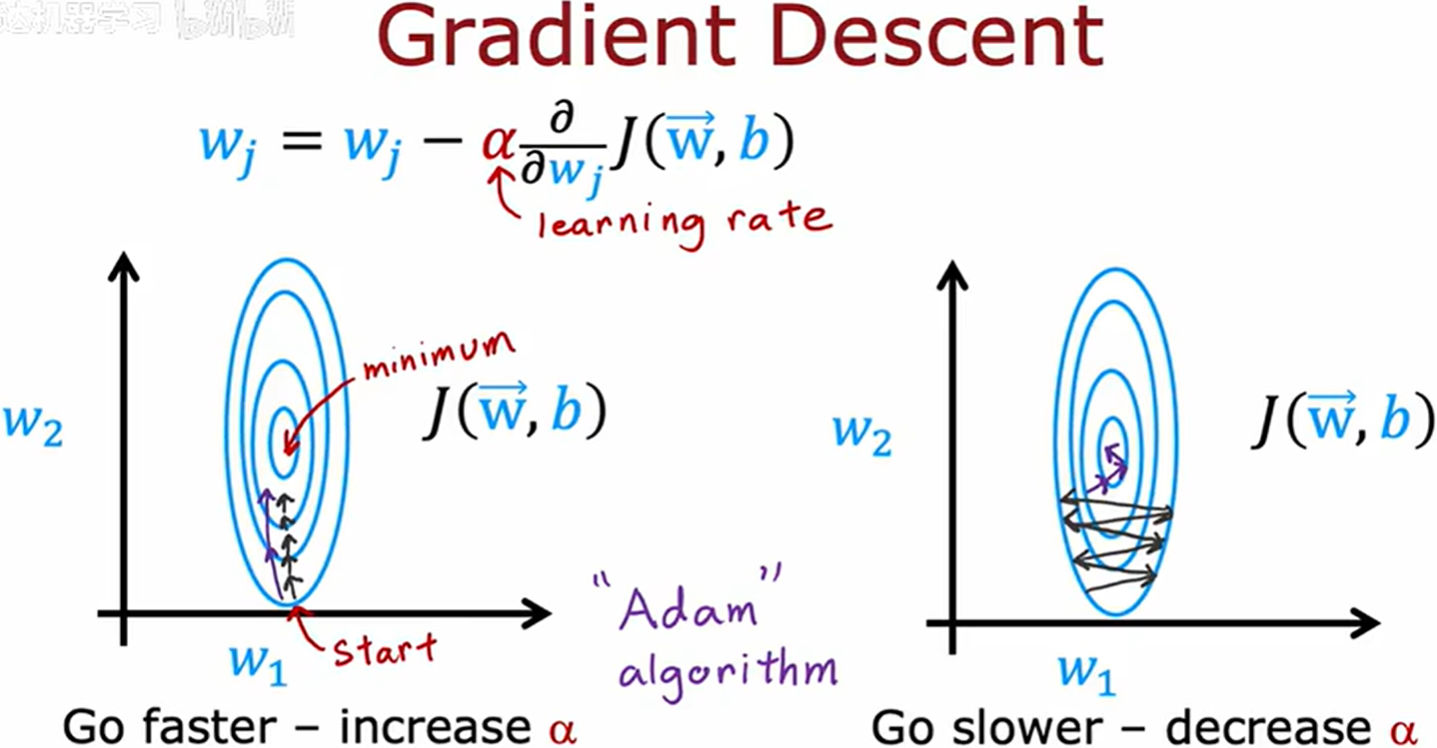
动态学习率(Dynamic Learning Rate)是深度学习训练过程中的一种优化策略,通过根据训练状态(如迭代次数、损失变化、梯度波动等)动态调整学习率,以提升模型收敛速度、稳定性和最终性能。
在梯度下降时,通过动态调整学习率,来优化梯度下降的过程。左图梯度下降的每一步几乎都在朝同一个方向前进,可以增大学习率更快达到最低值。右图出现振荡,因此可以调低学习率。
一种可以动态调整学习率的算法叫做 Adam(Adaptive Moment Estimation)。

Adam 算法给每个不同的参数都分配不同的学习率参数
oscillation 振动
Adam 算法的直观理解
-
如果 w j w_j wj 或 b b b 似乎一直在大致相同的方向上移动,就增加该参数的学习率**(加速收敛)**。
-
如果 w j w_j wj 或 b b b 不断振荡,就减小该参数的学习率**(稳定训练)**。
Adam 算法的简略解释
1. 方向趋势(动量规则)
Adam 用加权平均记住最近的梯度方向,数学表示为:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
- m t m_t mt:当前的方向趋势(类似“惯性”)
- g t g_t gt:当前梯度(参数该往哪走)
- β 1 \beta_1 β1(通常=0.9):控制历史梯度的权重
作用:
如果最近梯度方向一致(比如连续为正), m t m_t mt 会累积变大 → 增大学习率加速更新。
2. 波动检测(缩放规则)
Adam 同时计算梯度平方的加权平均,检测波动:
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
- v t v_t vt:当前的梯度波动强度
- β 2 \beta_2 β2(通常=0.999):控制历史波动的权重
作用:
如果梯度忽大忽小( g t 2 g_t^2 gt2 变化剧烈), v t v_t vt 会很大 → 减小学习率防止震荡。
3. 最终学习率计算
结合方向和波动,生成自适应学习率:
实际学习率 = η ⋅ m t v t + ϵ \text{实际学习率} = \eta \cdot \frac{m_t}{\sqrt{v_t} + \epsilon} 实际学习率=η⋅vt+ϵmt
- η \eta η:初始学习率
- ϵ \epsilon ϵ(如1e-8):防止除零的极小常数
直观理解:
- 方向稳( m t m_t mt 大) + 波动小( v t v_t vt 小) → 调大学习率
- 方向乱( m t m_t mt 小)或 波动大( v t v_t vt 大) → 调小学习率
TensorFlow 应用 Adam

在 compile 阶段指定要使用的优化器 optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),其中 1e-3 是初始学习率。
Aditional Layer Types
Dense Layer (密集层)
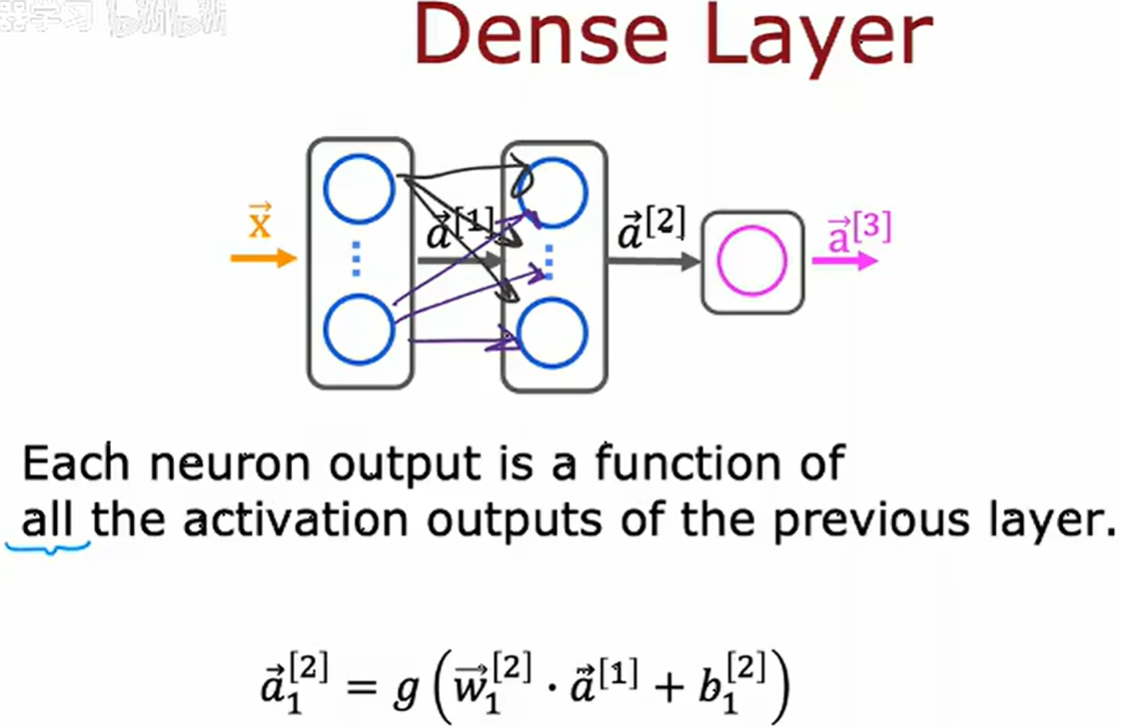
Convolutional Layer (卷积层)

卷积层中的单个神经元只能查看输入图像的一个区域
以 1-D 图像(心电图[EKG])为例讲述卷积神经网络
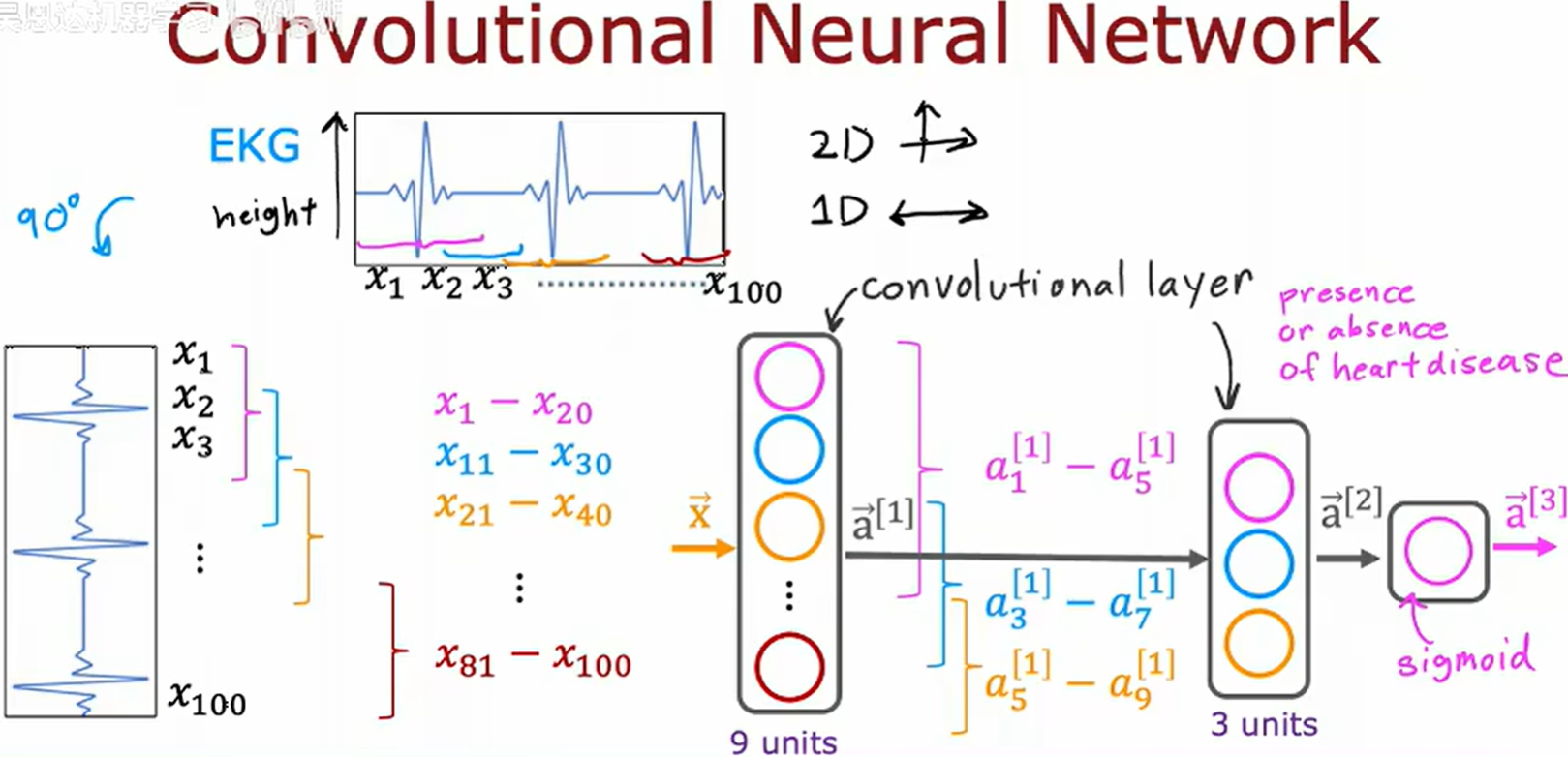
在卷积神经网络(CNN)中,关键架构参数包括卷积核尺寸(Kernel Size)和滤波器数量(Number of Filters),通过系统化优化这些参数,可以构建高效的特征提取器。相较于密集层(Dense Layer),CNN通过局部感受野(Local Receptive Fields)和权值共享(Weight Sharing)机制,显著提升模型对空间局部模式的建模能力,尤其在处理高维结构化数据(如图像、时序信号)时,具有更强的参数效率和泛化性能。
如Transformer 模型、LSTM、注意力模型,不同类型的层作为构建模块组合在一起,以形成更复杂、更强大的神经网络。
机器学习项目中下一步做什么
Debugging a learning algorithm

假如已经实现了正则化线性回归来预测房价,但是在训练模型后发现在预测中出现了不可接受的大误差。


模型评估
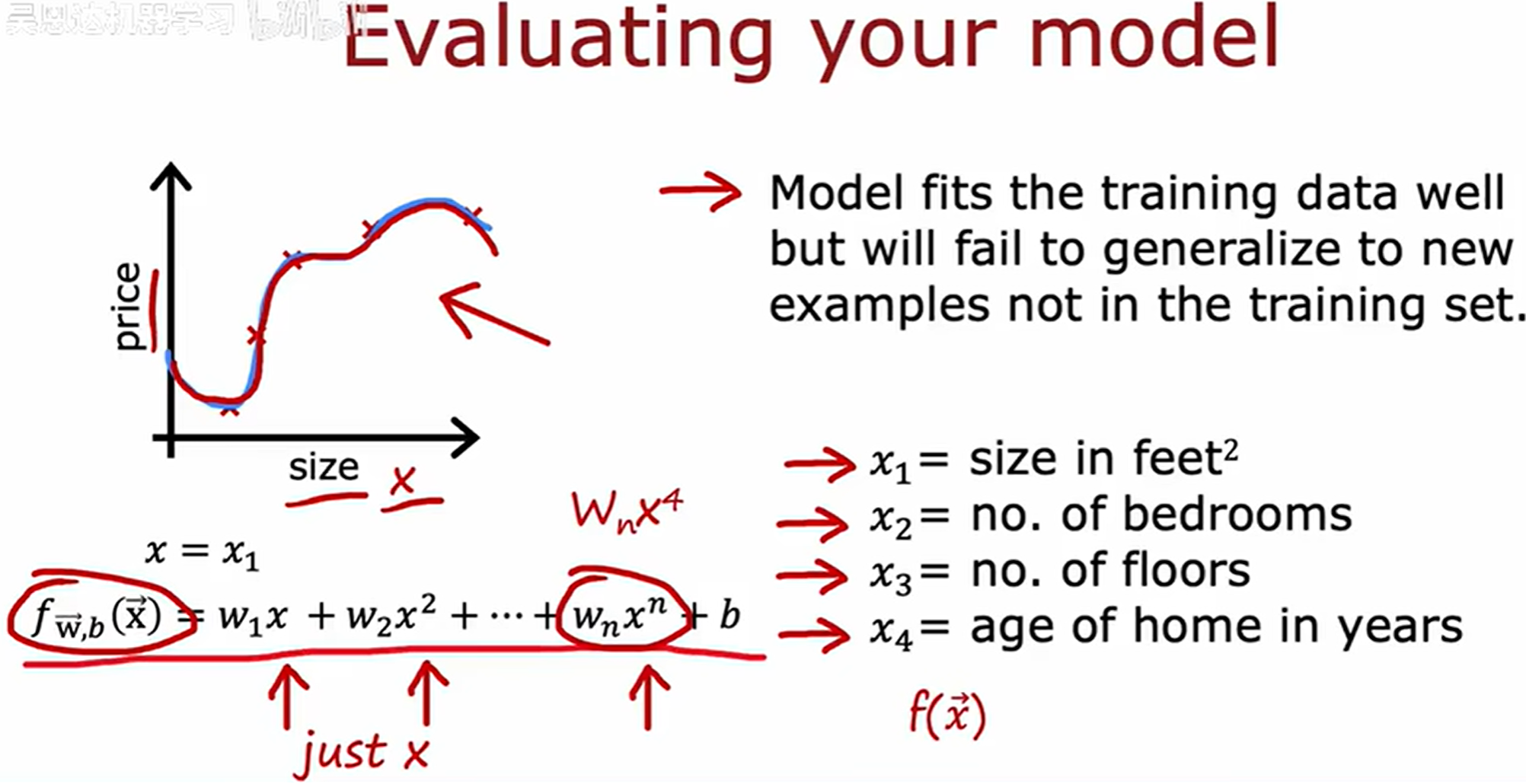
在低维情况下(如一到两个特征),我们可以通过可视化模型决策边界或拟合曲线的波动程度来直观判断过拟合。然而,当特征数量较多时,高维数据难以直接可视化,此时需要依赖系统化的评估方法来判断模型是否过拟合。

一个有效的方法就是将数据集分成两个子集,将70%作为训练集,另外30%称为测试集。

与拟合参数时的成本函数不同,这里的成本函数不需要加上正则化的项。
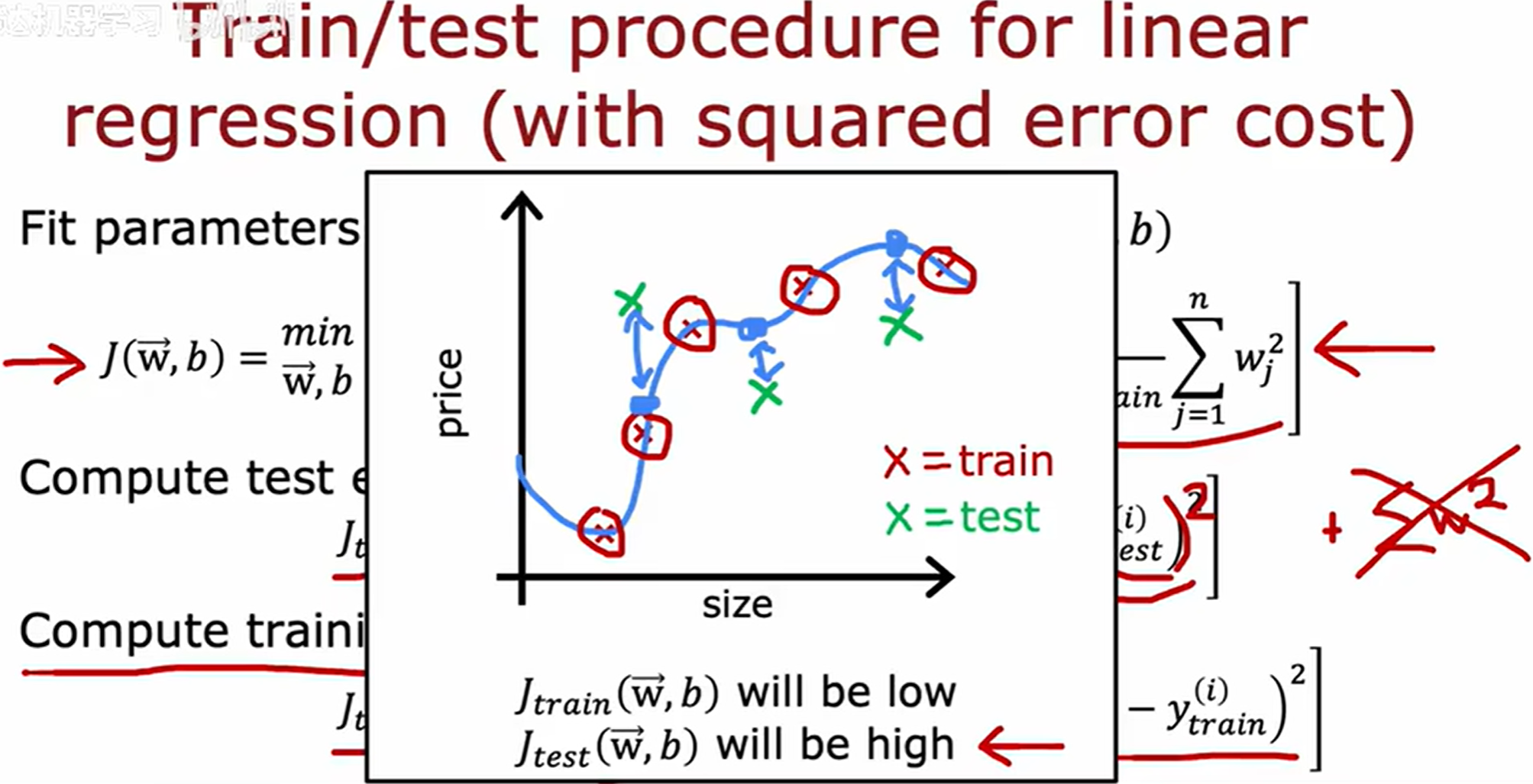
如果模型的 J t e s t ( w ⃗ , b ) J_{test}(\vec{w}, b) Jtest(w,b),非常的高,可以认为该模型的泛化能力较差。
以上是关于线性回归的,接下来将以上方法应用在分类问题上。

在实际应用中,我们通常不使用**逻辑损失(logistic loss)来计算训练误差和测试误差,而是采用分类错误率(misclassification error)**作为评估指标。
**训练误差(Training error)**定义为模型在训练集上分类错误的比例:
J train = 1 m train ∑ i = 1 m train I { y ^ ( i ) ≠ y ( i ) } J_{\text{train}} = \frac{1}{m_{\text{train}}} \sum_{i=1}^{m_{\text{train}}} \mathbb{I}\{ \hat{y}^{(i)} \neq y^{(i)} \} Jtrain=mtrain1i=1∑mtrainI{y^(i)=y(i)}
**测试误差(Test error)**定义为模型在测试集上分类错误的比例:
J test = 1 m test ∑ i = 1 m test I { y ^ ( i ) ≠ y ( i ) } J_{\text{test}} = \frac{1}{m_{\text{test}}} \sum_{i=1}^{m_{\text{test}}} \mathbb{I}\{ \hat{y}^{(i)} \neq y^{(i)} \} Jtest=mtest1i=1∑mtestI{y^(i)=y(i)}
其中:
- I { ⋅ } \mathbb{I}\{\cdot\} I{⋅} 是指示函数(当条件成立时为1,否则为0)
- y ^ ( i ) \hat{y}^{(i)} y^(i) 是模型对第i个样本的预测类别
- y ( i ) y^{(i)} y(i) 是第i个样本的真实类别
- m train m_{\text{train}} mtrain 和 m test m_{\text{test}} mtest 分别是训练集和测试集的大小
这种基于错误分类比例的评估方式更直观,直接衡量了模型在分类任务中的准确率。

模型选择和训练交叉验证测试集
自动选择一个适合的机器学习算法模型


上述的方法直接选择在测试集上错误率 J t e s t J_{test} Jtest 最小的模型,可能会导致对泛化误差的乐观估计(optimistic estimate),即低于泛化误差的实际估计,因为这相当于让模型在测试集上进行了"隐式调参"。
更推荐的方法
将数据集分成 训练集 交叉验证集 测试集

交叉验证,通过使用这个额外的数据集来交叉检验有效性,或者不同模型的准确性。
交叉验证集的别称:验证集(validation set) 开发集(dev set) (development set)

选择有最低的交叉验证误差的模型,用测试集来进行对模型泛化误差的公平估计。
- 验证误差 J c v J_{cv} Jcv 用于模型比较和选择
- 测试误差 J t e s t J_{test} Jtest 仅用于最终性能报告

以上就是自动决定为线性回归模型选择阶数的多项式
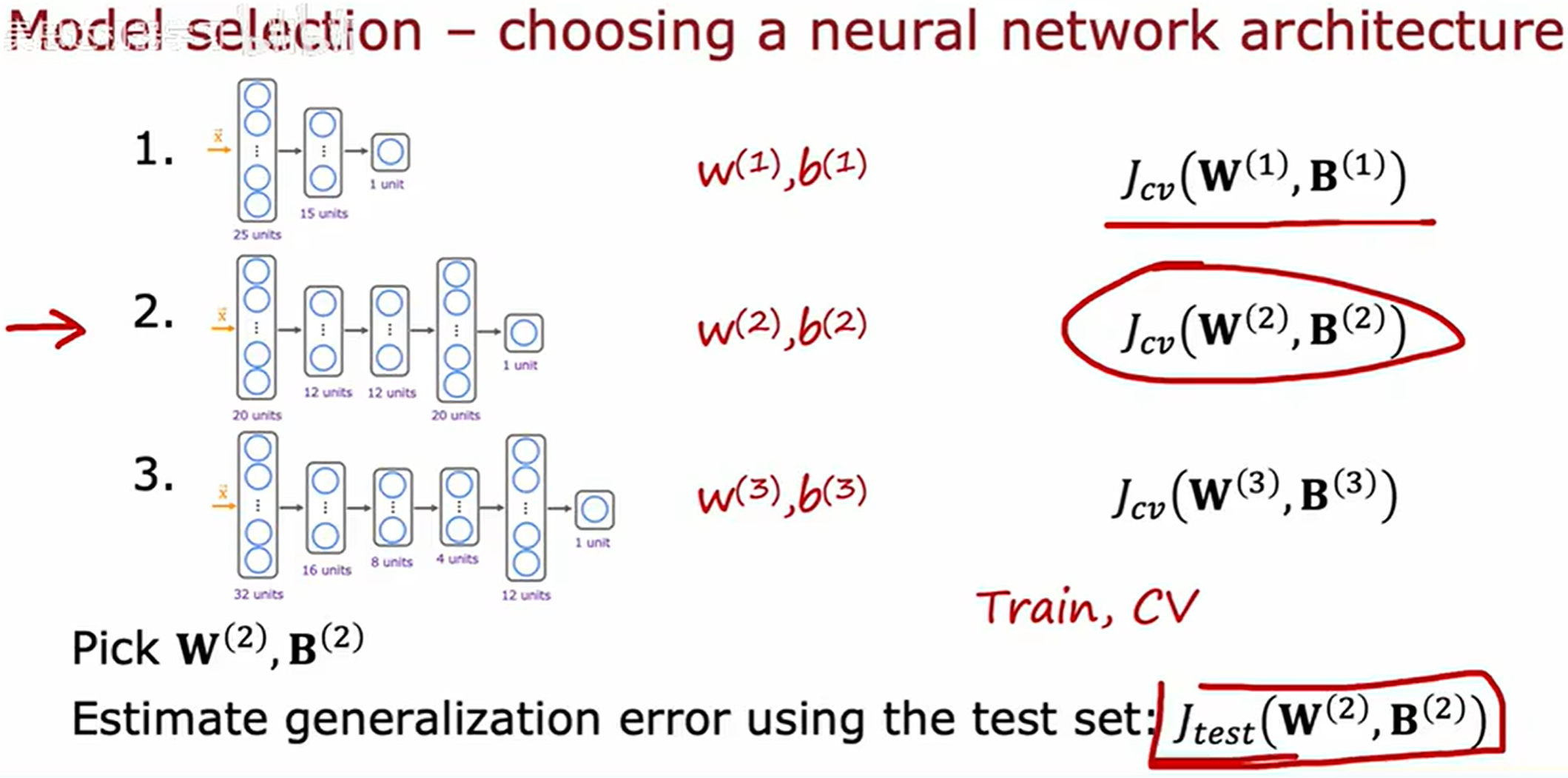
通过如上一样的流程,可以自动决定为神经网络选择,不同神经元数目和层数的架构模型。
测试集只能用于最终评估,绝不能参与任何形式的模型选择或调参。
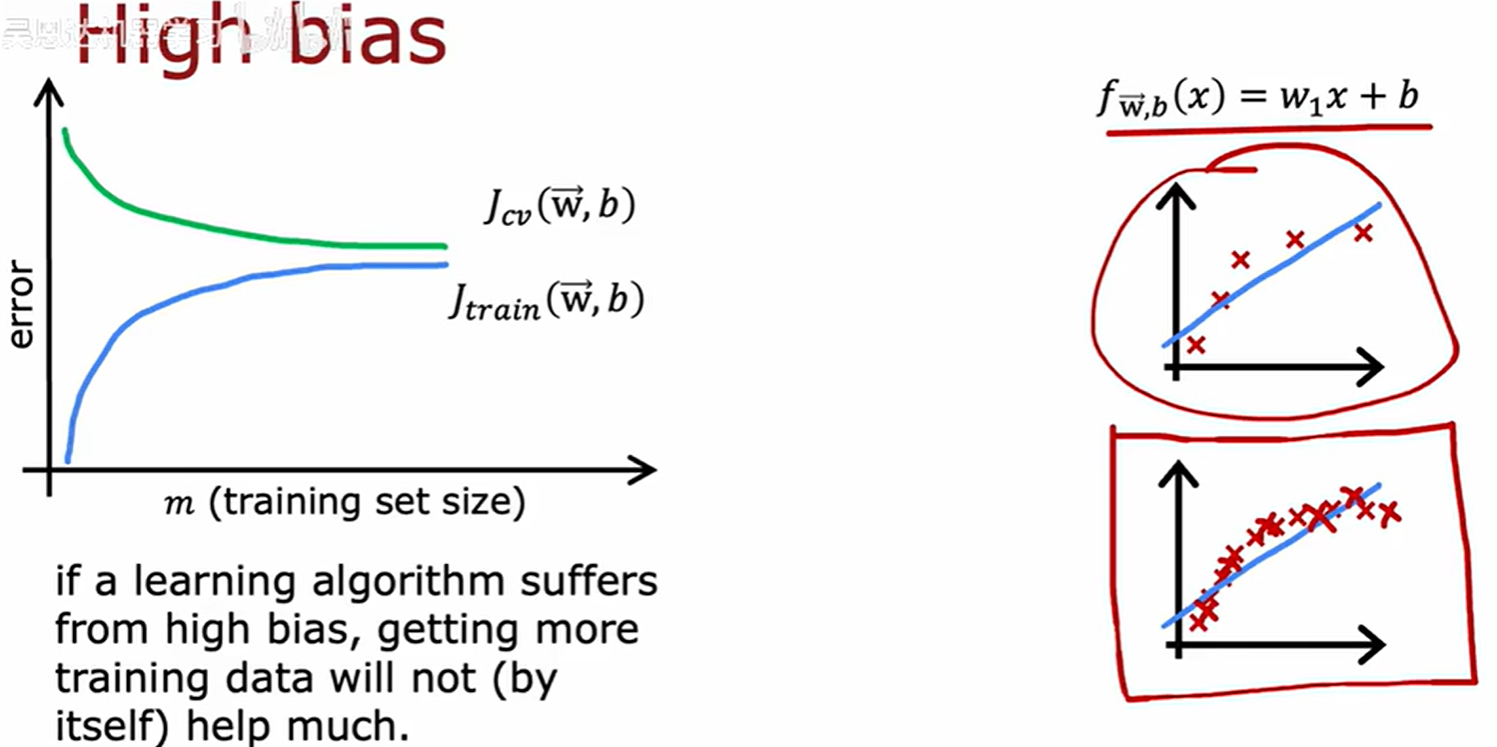
诊断偏差和方差
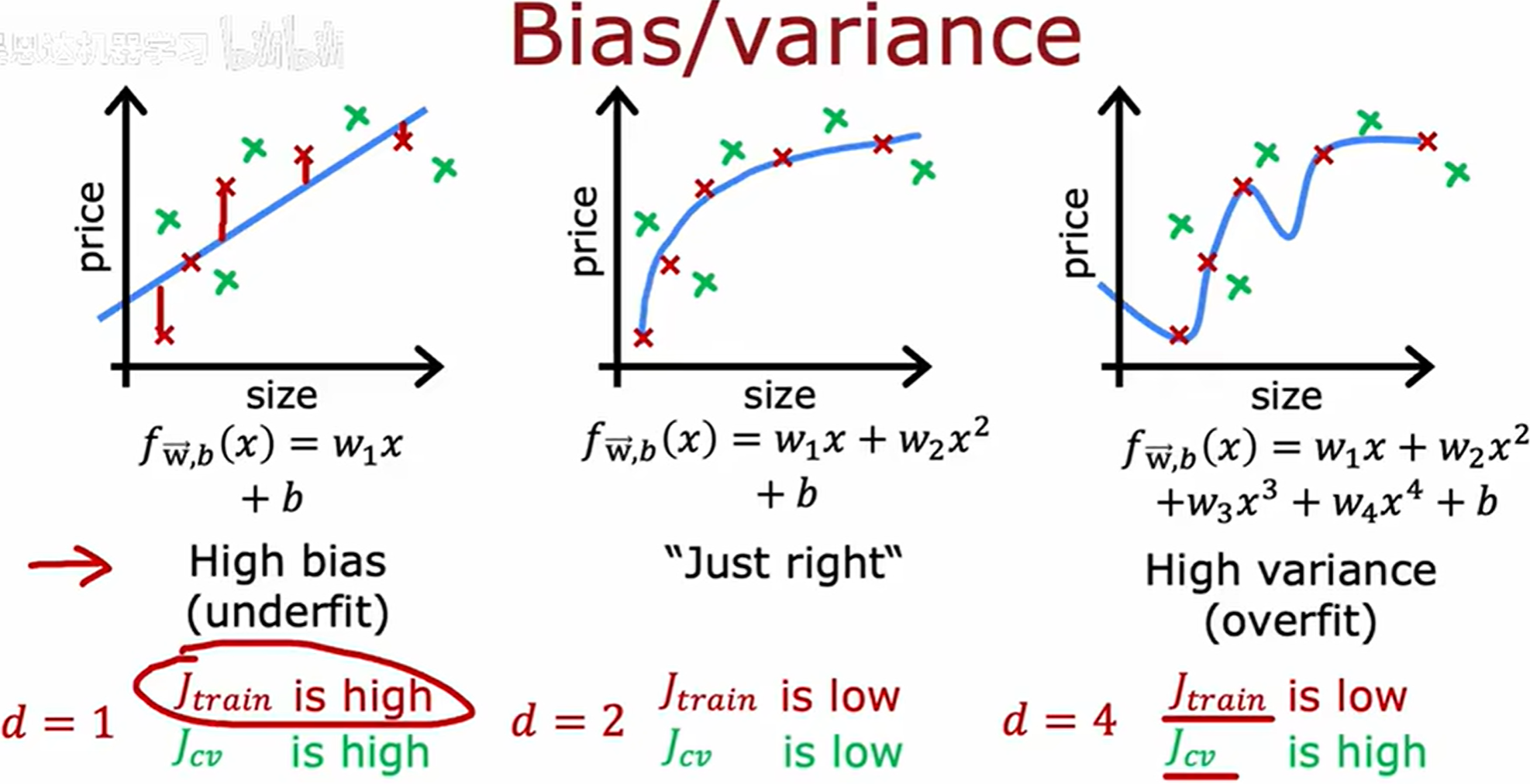
通过 J t r a i n J_{train} Jtrain 和 J c v J_{cv} Jcv 来判断偏差和方差,而非图像。
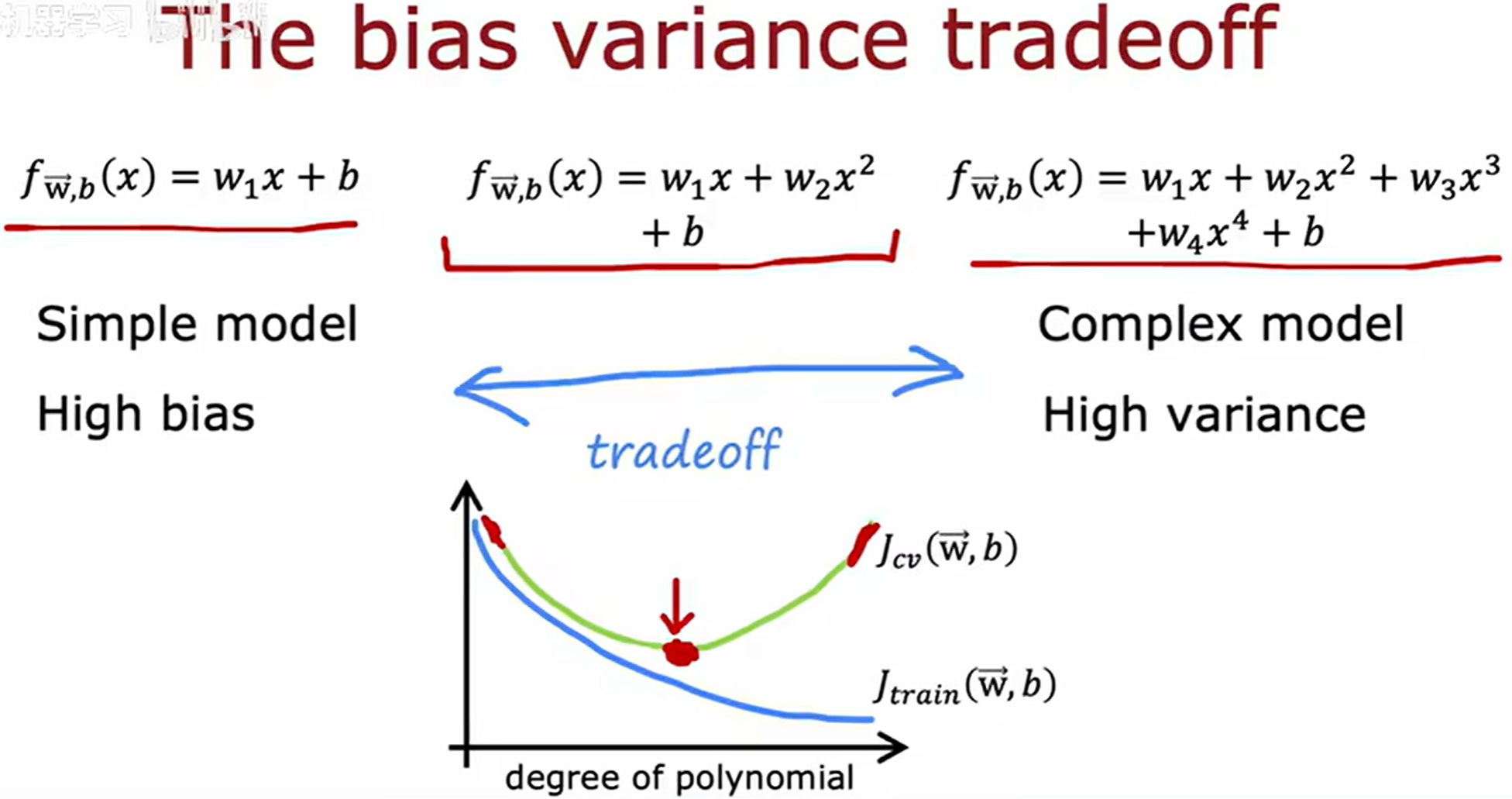
d 代表多项式的阶数

大多数应用中主要是高偏差或高方差,而不是同时出现,但是有时可能同时出现这两种问题。
正则化和偏差或方差
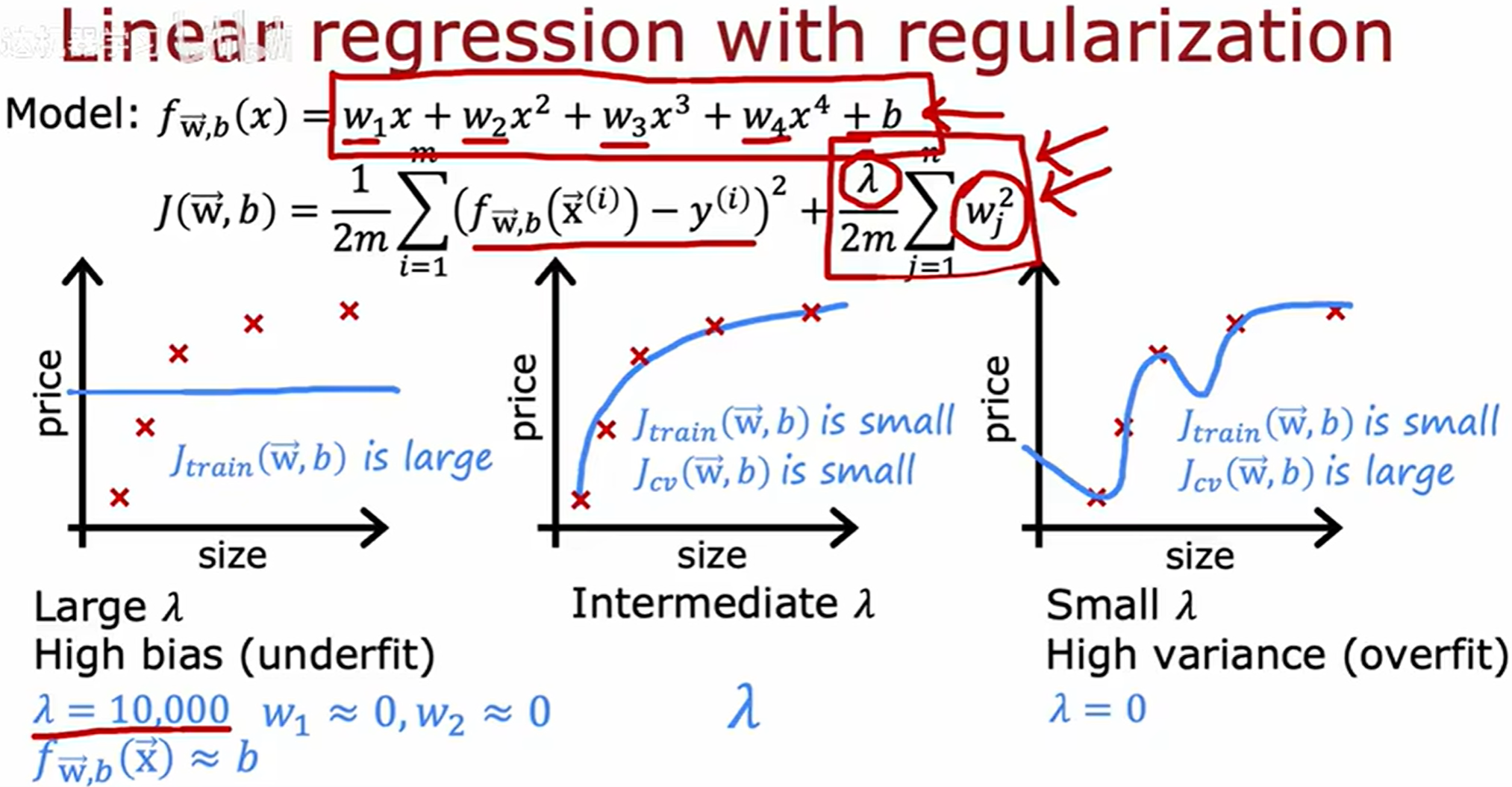
高方差的本质
高方差(过拟合)意味着模型对训练数据中的噪声或随机波动过于敏感,表现为:
- 训练误差很低,但验证误差很高。
- 模型参数值往往较大(例如某些权重极端正或负),导致对输入微小变化反应过度。
通过 λ 调整模型
判断高偏差和高方差
建立判断偏差和方差是否较高的 baseline (基线)

这里将人类表现水平作为 baseline
以下是建立 baseline level 的一些方法:

基线的应用事例:

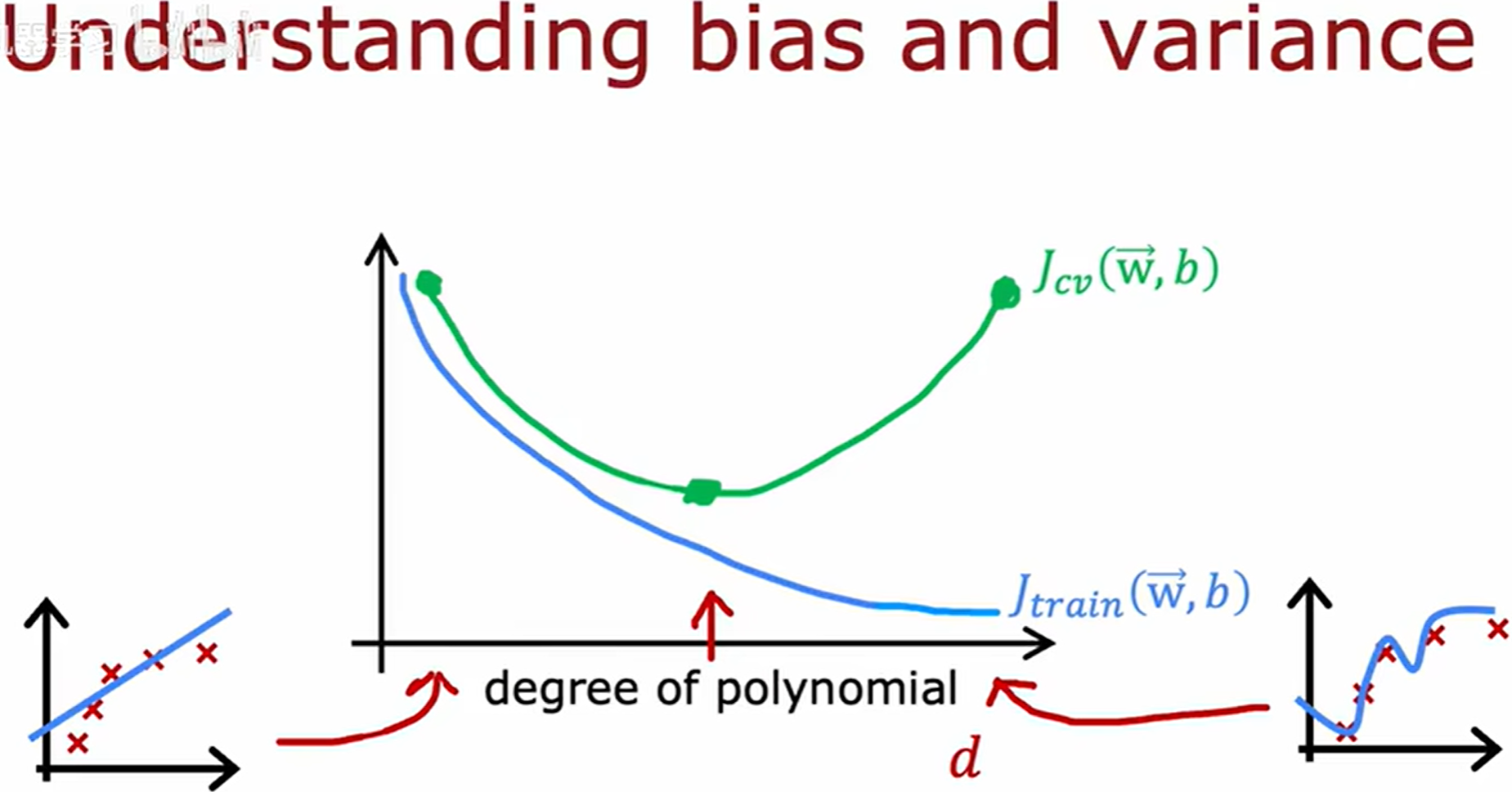
学习曲线
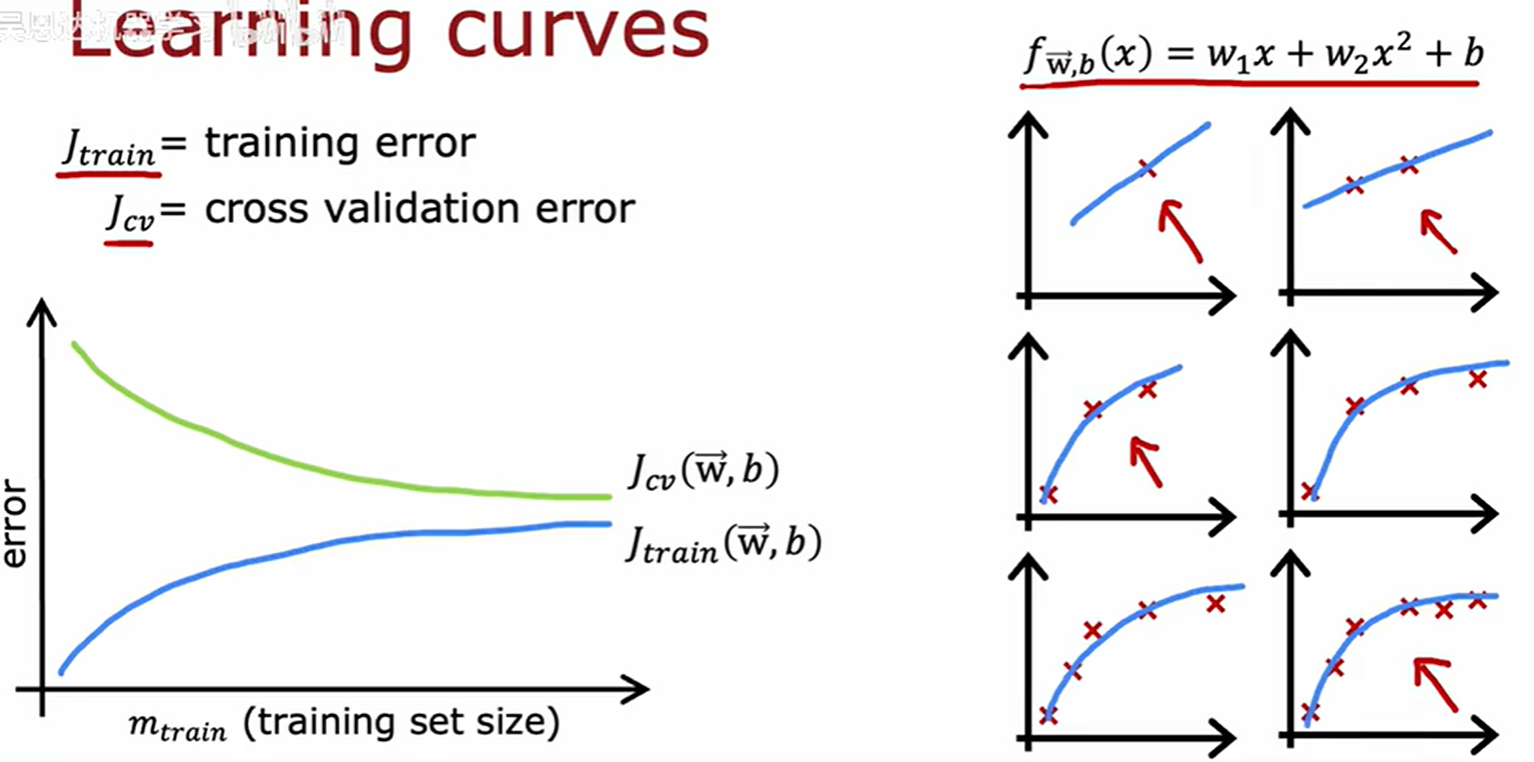
当训练集小的时候,要到达非常小的误差是相对容易的。当训练集更大时,完美拟合所有训练样本就会变得更难。
由于模型过于简单,不适合过多的数据,即给再多的数据,误差也不会发生多大的变化,这也是为什么会趋于平整。
可知一个模型有高偏差,即使增加再多的训练数据,本身也帮不了太多。

可知一个模型有高方差,增加更多的训练数据,其拟合能力接近人类准线水平。
再次决定下一步做什么

偏差或方差与神经网络
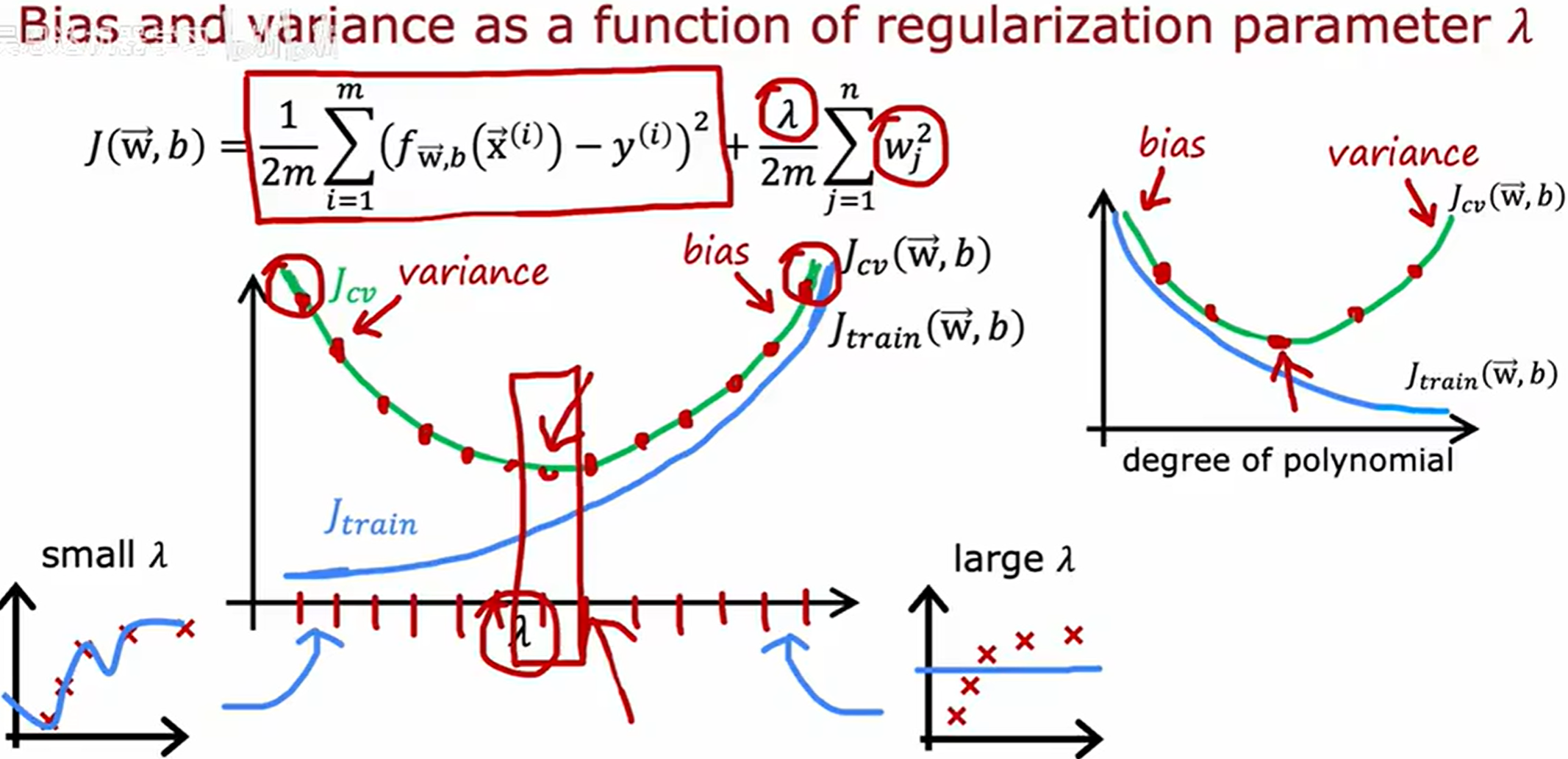
传统机器学习往往面临 偏差-方差权衡(Bias-Variance Tradeoff) 的困境,但实际上神经网络提供了一种方法,可以摆脱偏差和方差之间进行权衡的困境。
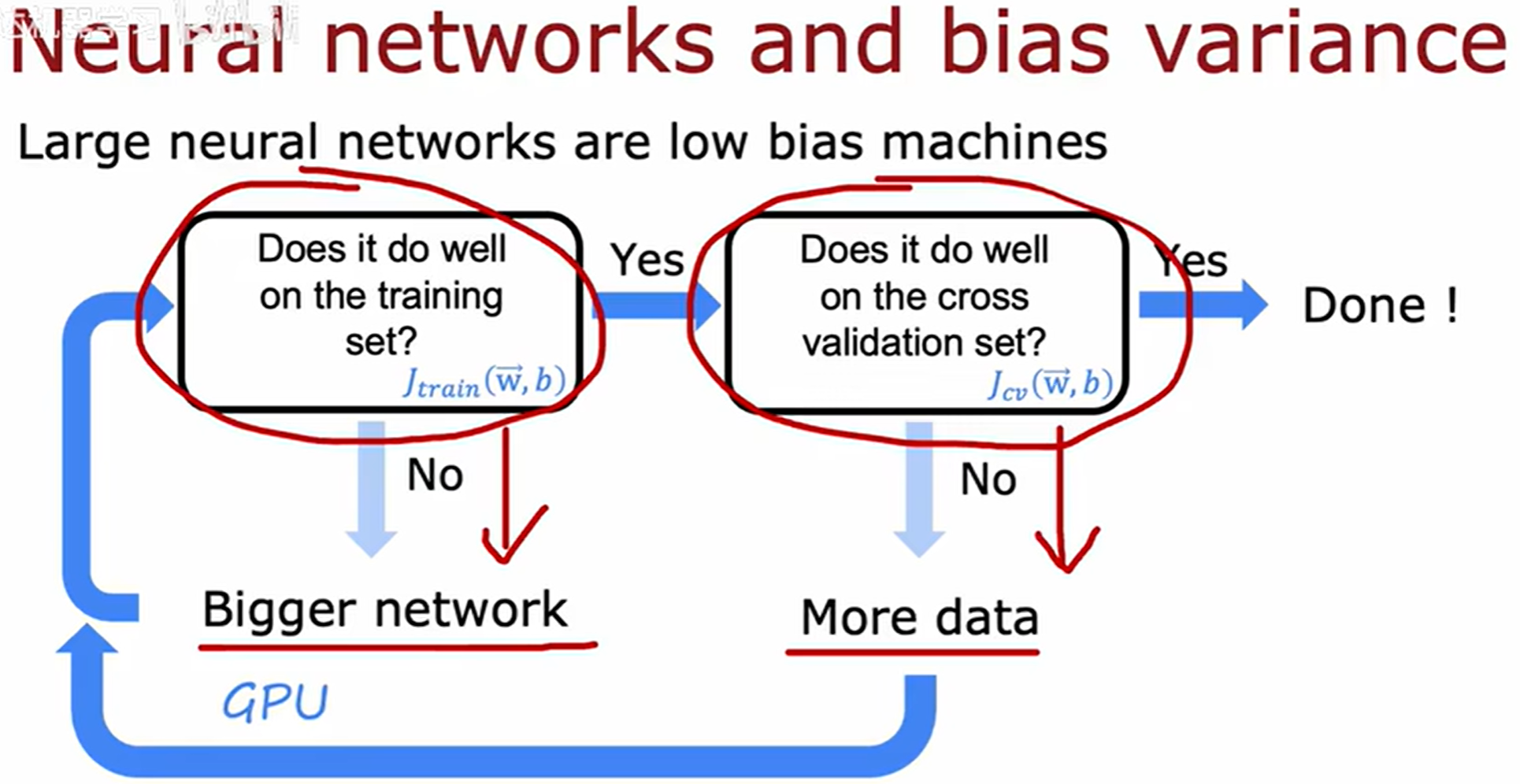
在不改变training set的体量的基础上 可以通过调节神经网络的架构(例如增大hidden layer层数或者每层中的神经元数)来尝试缓解high bais问题
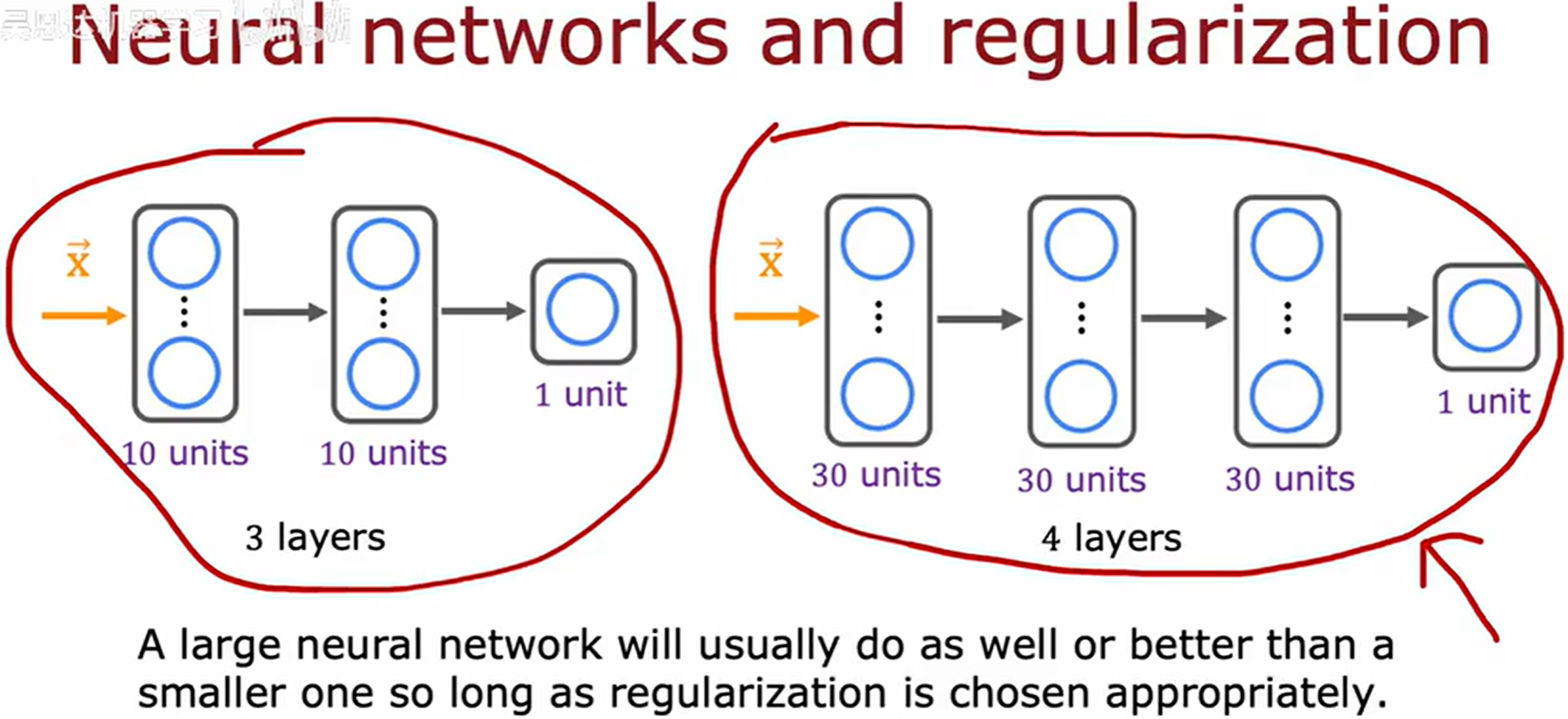
Q:神经网络太大会导致高方差吗?
A:事实证明一个经过良好正则化选择的大型神经网络通常会表现得和小网络一样好甚至更好。(只要正则化恰当,使用更大的神经网咯几乎没有坏处。)
下面对 0/1 手写识别的神经网络进行正则化

TensorFlow 中通过 kernel_regularizer=L2(0.01) 来使用 L2 正则化,其中 0.01 表示 λ,同时 TensorFlow 支持给每一层都分配不同的 λ。
使用更大的神经网络,或许唯一的坏处是算法性能降低。训练神经网络常常要考虑的是方差问题,而非偏差问题。
机器学习的迭代过程
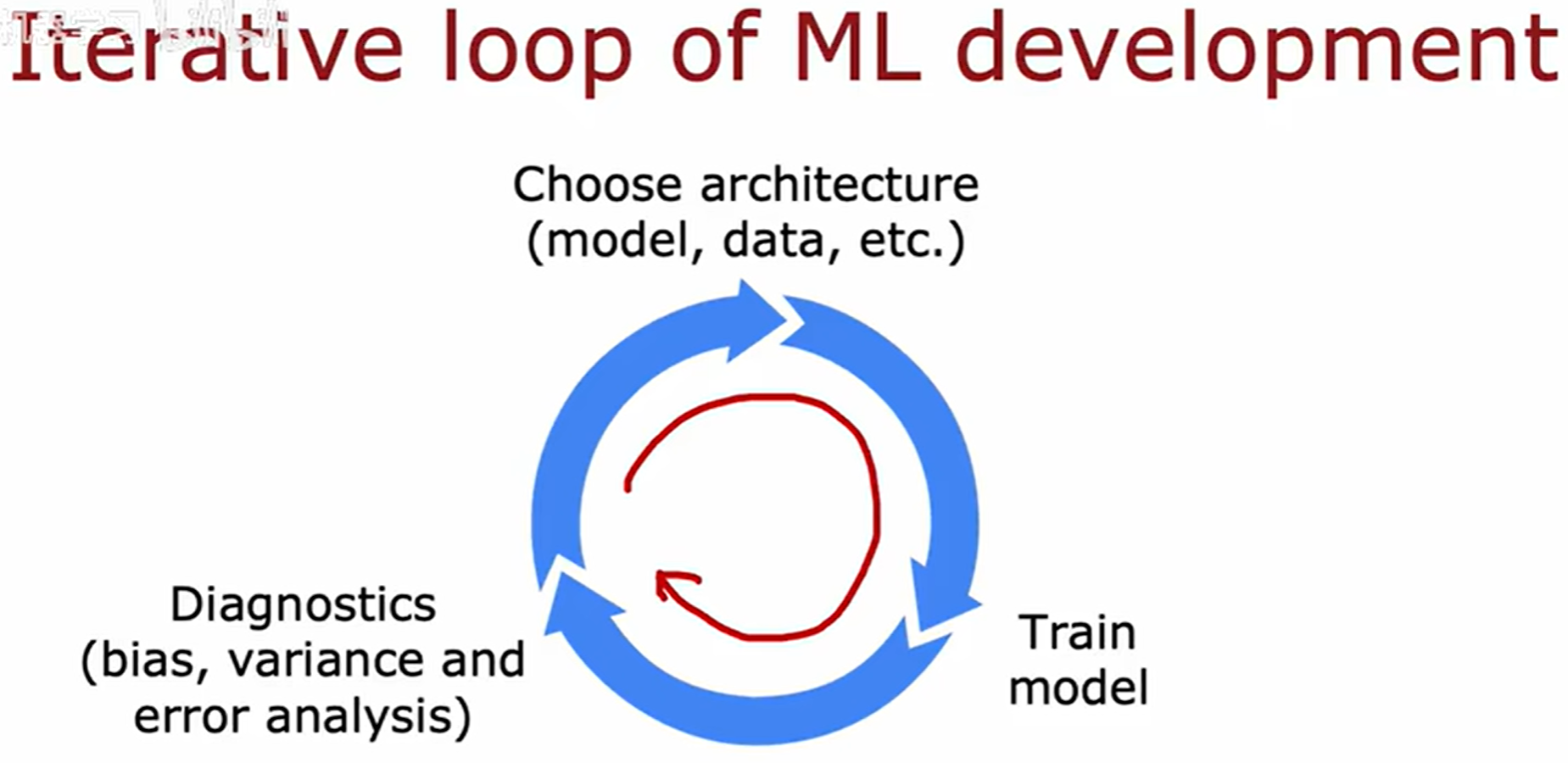
以构建垃圾邮件分类器为例

垃圾邮件会故意拼错词语来试图绕过垃圾邮件识别器

提取邮件中前1000个单词,按照垃圾邮件常用的单词的出现与否作为特征向量。

Honeypot project会创建大量虚假的电子邮箱地址,并故意让这些虚假邮件地址被垃圾邮件发送者获取,这样就可以获取到大量垃圾数据的一种方法。
误差分析

通过人力检查被错误分类的100个样例中的垃圾邮件来检测错误类型,从而知道在哪方面集中注意力可能才是最有效的。
pharma制药
上述分析表明,即使构建了非常复杂的算法来找到故意拼写错误,也只能解决100个被误分类示例中的3个。
假如在被误分类示例中制药占大部分,可以决定收集更多制药类垃圾邮件的数据,以便学习算法能更好识别这些制药垃圾邮件。也可以想出一些与制药相关的新特征,例如药品的具体名称。
添加数据
针对性地补充模型当前表现不足的特定类型数据
在模型训练过程中,获取更多涵盖所有类型的数据往往效率低下且成本高昂。一种更有效的替代方案是通过错误分析,有针对性地补充模型当前表现不足的特定类型数据,这种方法既能提升模型性能,又更高效经济(如前一节中的垃圾邮件中做的)。
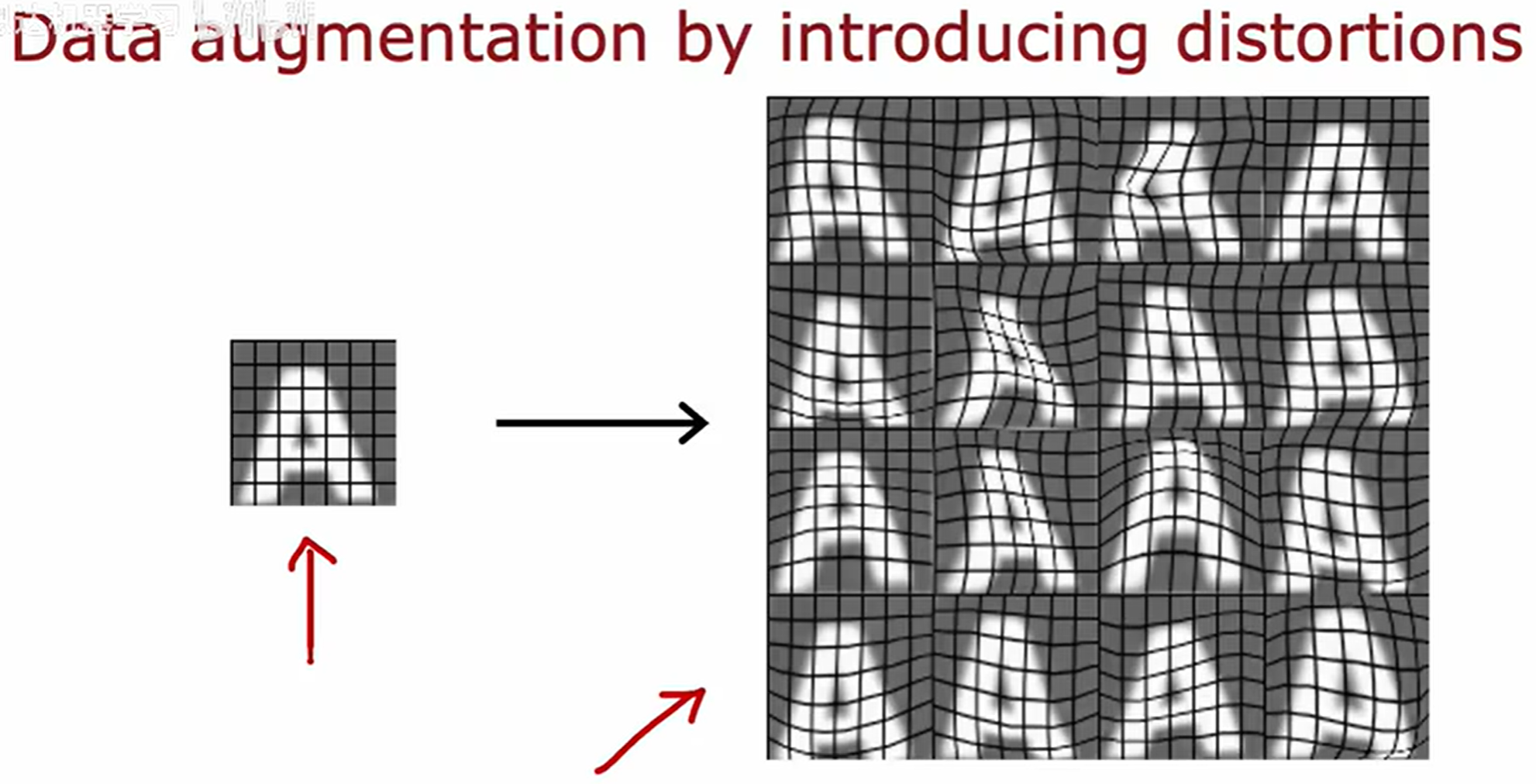
数据增强 (Data augmentation)
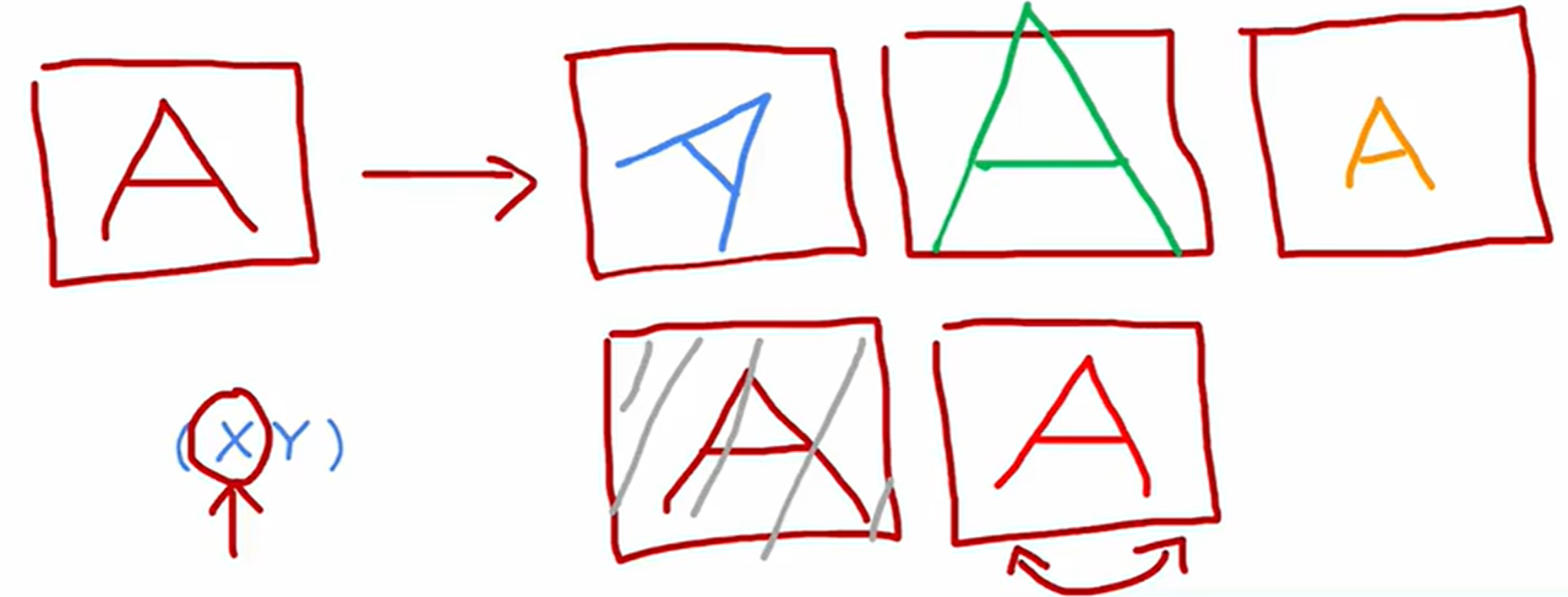
在深度学习中,**数据增强(Data Augmentation)**是一种广泛应用的技术,尤其适用于图像和音频数据。它通过对原始训练数据进行各种变换(如旋转、翻转、裁剪、添加噪声等)【变换后标签一致 增强对应标签的识别性能】,人工生成多样化的样本,从而显著扩大训练集的规模,提高模型的泛化能力。
同样能用于音频
将噪声合成组成新的数据

一个重要的数据增强原则是:对训练数据施加的变换或扰动,应当与测试数据中可能出现的噪声和失真类型相匹配。这样生成的增强数据才能有效提升模型在真实场景中的泛化能力,而不是引入无关的干扰。
例如:
- 在图像识别任务中,如果测试图像可能包含旋转或光照变化,训练时就应使用相应的旋转和亮度调整增强。
- 在语音识别任务中,若测试环境存在背景噪声,增强时就应添加类似的噪声模拟。
不合理的增强(如过度失真或无关变换)反而可能损害模型性能。

数据合成 (Data synthesis)
OCR 是 Optical Character Recognition(光学字符识别)的缩写,是一种将图像中的文字(如印刷体或手写体)转换为可编辑和可搜索的文本数据的技术。

数据合成是指通过人工或算法生成新的训练数据,而非直接从现实世界收集。它常用于数据稀缺、隐私保护或特定场景模拟等需求,能有效扩充数据集并提升模型鲁棒性。合成的数据大多用于计算机视觉人物,较少用于其他应用。
常见数据合成方法
- 基于规则的生成
- 通过预设规则(如几何变换、纹理叠加)生成数据。
- 例子:OCR 中合成带背景噪声的文本图像;自动驾驶中生成不同天气条件下的道路场景。
- 生成对抗网络(GAN)
- 利用 GAN(如 StyleGAN、CycleGAN)生成逼真数据。
- 例子:合成人脸图像、医学影像数据。
- 模拟器/引擎渲染
- 使用 3D 引擎(如 Unity、CARLA)生成虚拟场景数据。
- 例子:自动驾驶中合成多样化的交通场景;机器人训练中的虚拟环境。
- 文本到图像/语音合成
- 通过模型(如 Stable Diffusion、Tacotron)生成多模态数据。
- 例子:合成带标注的语音指令数据用于语音识别。
- 混合真实与合成数据
- 将真实数据与合成数据结合(如背景替换、数据插值)。
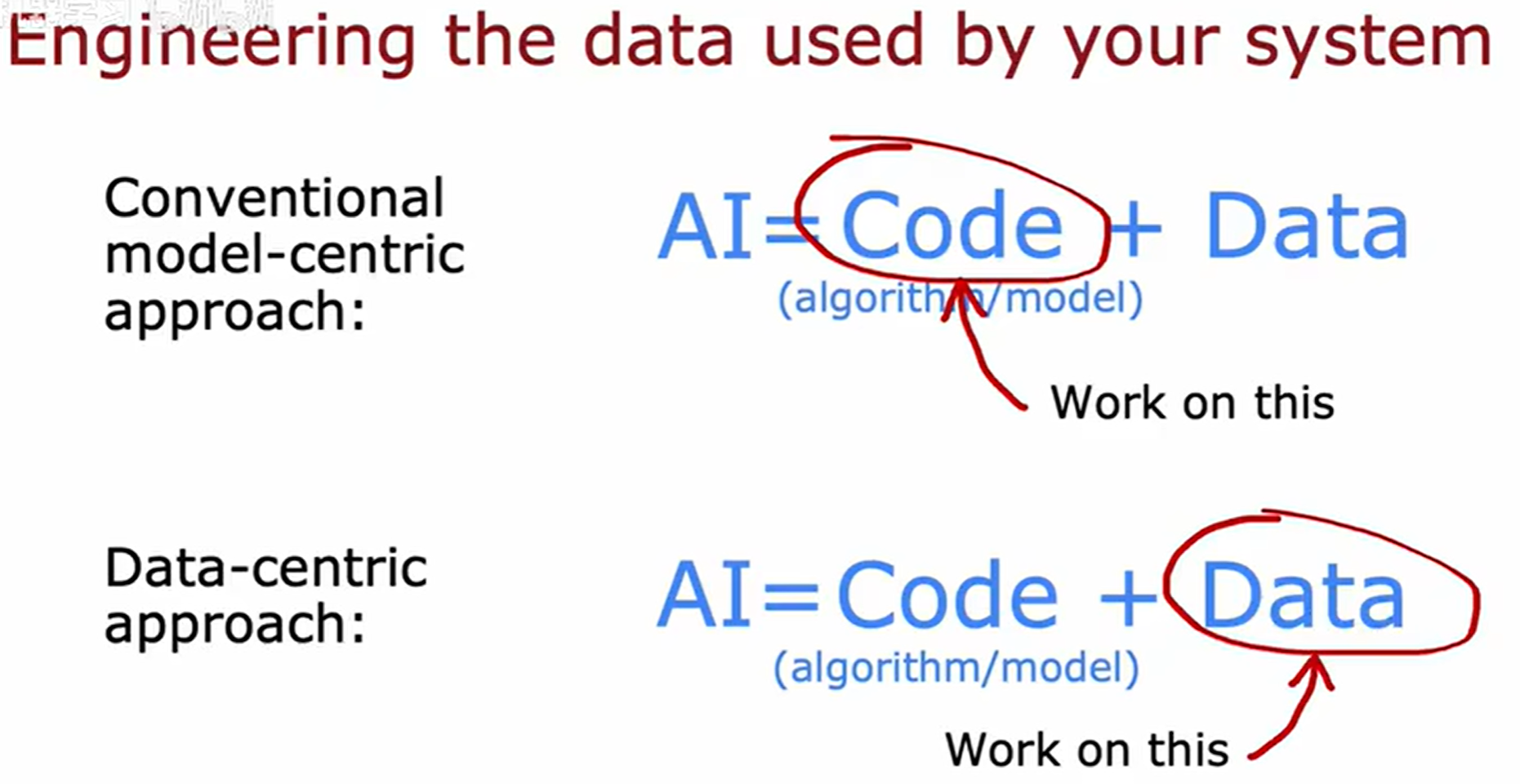
传统与现在的不同侧重点
迁移学习 (Transfer Learning)
相当于是预训练,将从其他任务那里学习较为成熟的骨干网络,拿过来对接新的任务,修改最后一层的分类头,使用前面几层已经学习得不错的网络去提取数据的特征。
核心概念
- 源任务(Source Task):已有知识的原始任务(如预训练模型的任务)。
- 目标任务(Target Task):需要解决的新任务。
- 迁移方式:通过共享模型参数、特征表示或模型结构,将源任务的知识迁移到目标任务。
为什么需要迁移学习?
- 数据稀缺:目标任务标注数据不足时,利用源任务的预训练模型(如ImageNet预训练的CNN)。
- 计算效率:避免从头训练大模型,节省时间和资源。
- 泛化能力:源任务学到的通用特征(如边缘、纹理)可能对目标任务有用。
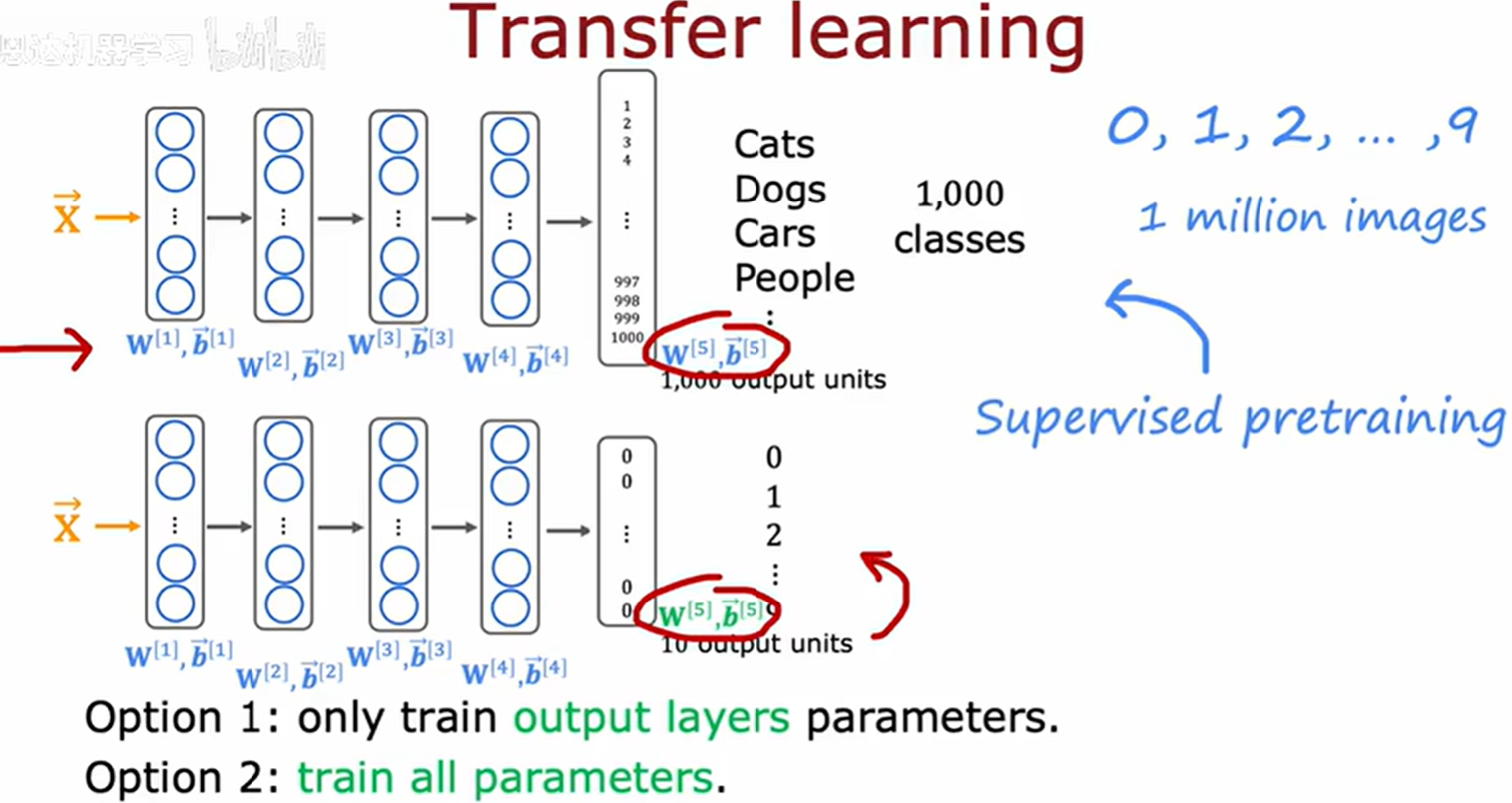
两种方式:
- 获得大型数据集上神经网络除输出层的参数后,仅训练输出层。(适合少训练集情况)
- 将大型数据集上神经网络的所有参数作为初始值,训练所有层。(适合训练集多的情况)
在大型数据集上训练神经网络的步骤称为有监督预训练(Supervised pretraining)
从有监督预训练中初始化或者获得的参数进行进一步梯度下降称为微调(Fine tuning)
比如要识别中药材图片,没多少数据,但是有一个已经训练好的模型(包含花,植物等),它已经学会了怎么识别“叶子形状”、“纹理”、“自然物体“,所以你只需要让它学一学“这是何首乌还是黄芪”,效率高、准确率也好。
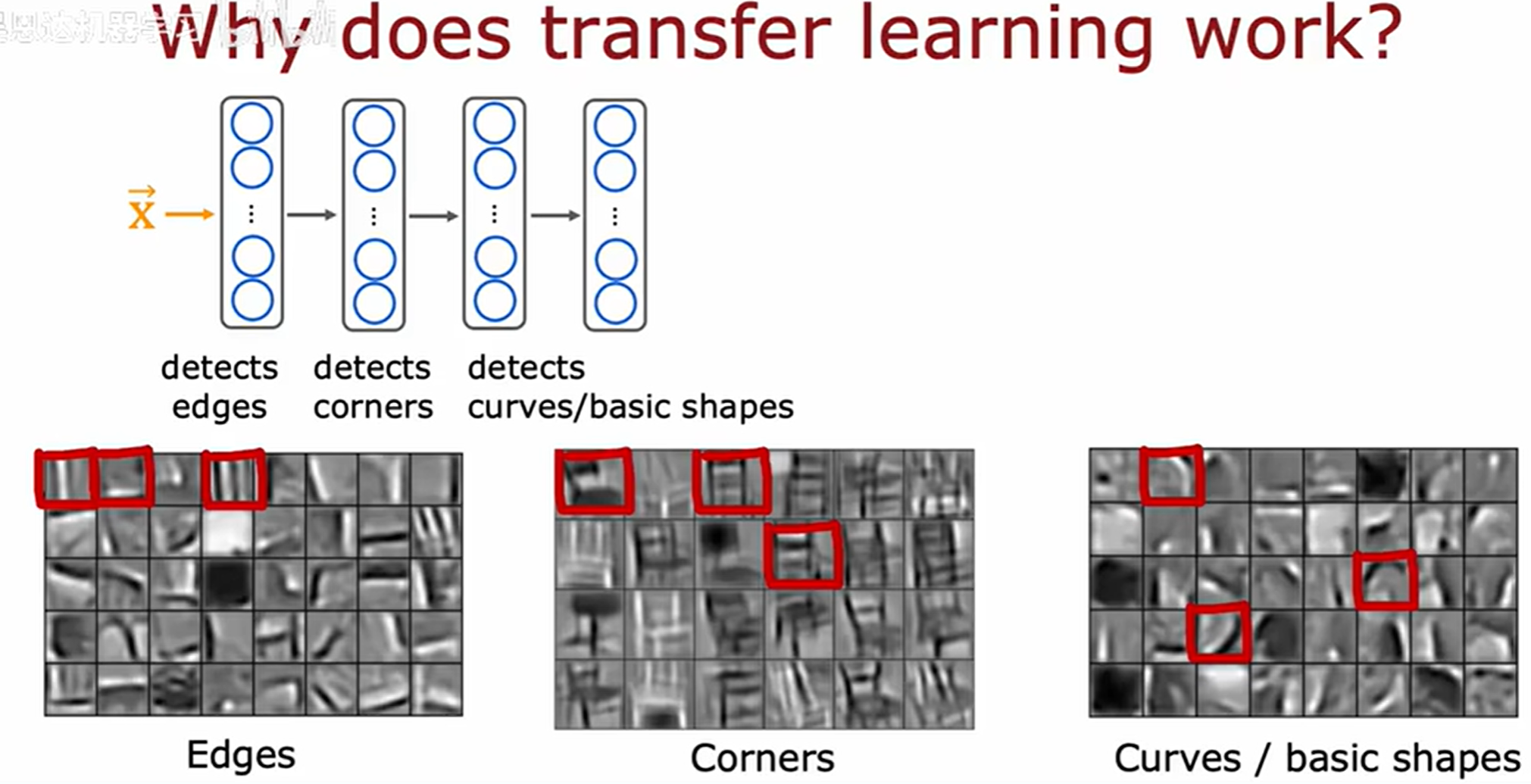
图像识别任务中,找边缘、角点、曲线、基础图形都是共性任务,因此可以直接使用现成的图像识别模型(可能该模型与当前想要识别的东西无关),再迁移学习来加快模型训练,以及减少对数据集规模的要求。
神经网络在图像识别任务中,通常从底层特征开始学习,比如边缘、角点、纹理等基础视觉元素,然后逐步组合成更复杂的高级特征。这些底层特征对大多数视觉任务都是通用的,因此通过迁移学习,我们可以利用预训练模型已经学到的这些基础特征,快速适应新的视觉任务(如手写数字识别),而无需从头开始训练。

机器学习项目的完整周期

关于机器学习项目的部署

倾斜数据集的误差指标
问题引出

上述模型正确率为 99%,但假如是罕见疾病的话,直接输出 y = 0 的正确率甚至高达 99.5%。直接从正确率或者错误率来说,很难评估哪一个实际上是最好的算法。
精确率和召回率 (Precision / recall)
这是一对常用的评估指标,尤其适用于分类任务中类别分布不平衡的情况(例如存在稀有类别时)。
应用场景:
在医学诊断、欺诈检测等任务中,若漏检正例(False Negative)的代价很高,需优先优化召回率;若误检(False Positive)的代价更高(如垃圾邮件分类),则需优先优化精确率。两者通常需要权衡(可通过F1-score调和)。
confusion matrix 混淆矩阵

构建混淆矩阵,如上图标出真正例(True positive)、假正例(False positive)、正负例(True negative)、假负例(False negative)。

-
精确率(Precision)衡量的是模型预测为正例的样本中,真实为正例的比例。
它反映模型的预测准确性(“宁缺毋滥”)。
-
召回率(Recall)衡量的是真实为正例的样本中,被模型正确预测为正例的比例。
它反映模型对正类的覆盖能力(“宁可错杀”)。
精确率(Precision) 是“在你预测为阳性的样本中,实际为阳性的比例”(例如:你预测20人有病,其中15人确实有病 → 精确率=15/20=75%)。
召回率(Recall) 是“在所有实际阳性的样本中,被你正确预测为阳性的比例”(例如:实际25人有病,你找出其中15人 → 召回率=15/25=60%)。
简记:
- 精确率 = 你声称的阳性里有多少是真的?
- 召回率 = 真正的阳性里你找出了多少?
精确率与召回率的权衡

提高阈值会导致更高的精确率,但是也会导致召回率的降低。

降低阈值会导致更高的召回率,但是也会导致精确率的降低。
精确率和召回率的关系如下:
F1 Score
由于不同算法的**精确率(Precision)和召回率(Recall)**可能此消彼长,直接比较单一指标难以评估模型整体性能,因此引入 F1 Score 作为综合衡量标准。
F1 Score 是精确率和召回率的调和平均数(Harmonic Mean),其计算公式为:
F 1 = 1 1 2 ( 1 Precision + 1 Recall ) = 2 × Precision × Recall Precision + Recall F1 = \frac{1}{\frac{1}{2}(\frac{1}{\text{Precision}} + \frac{1}{\text{Recall}})} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=21(Precision1+Recall1)1=2×Precision+RecallPrecision×Recall
特点:
- 相比算术平均,F1 更关注较低的值(即“短板效应”),避免某一指标极高而另一指标极低的情况。
- 适用于类别不平衡的场景(如罕见病检测、欺诈识别),要求模型在精确率和召回率之间取得平衡。
用途:
当需要同时优化精确率和召回率(而非偏重某一方)时,F1 Score 是比单独看 Precision 或 Recall 更合理的评估指标。

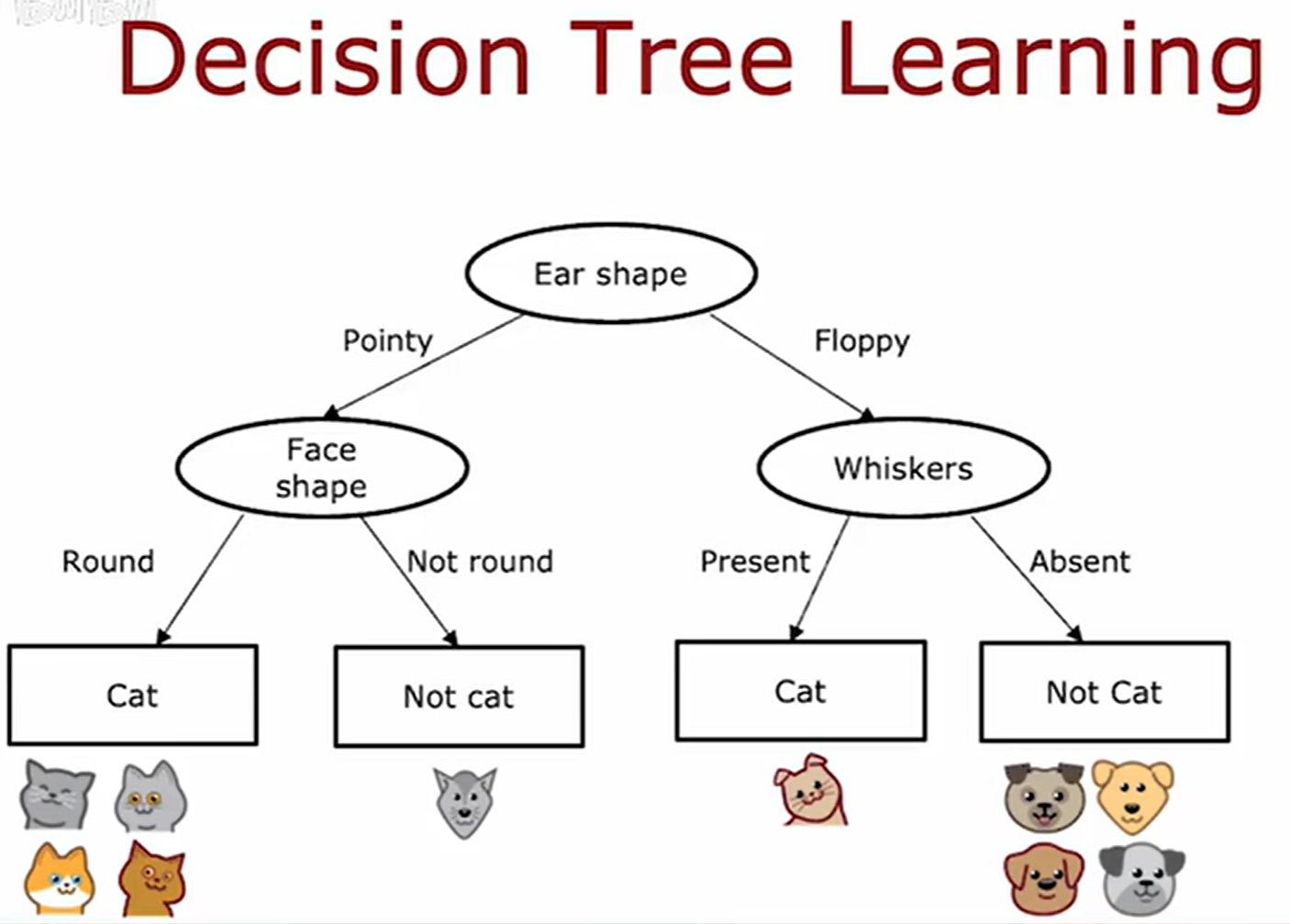
决策树 (Decision Tree)
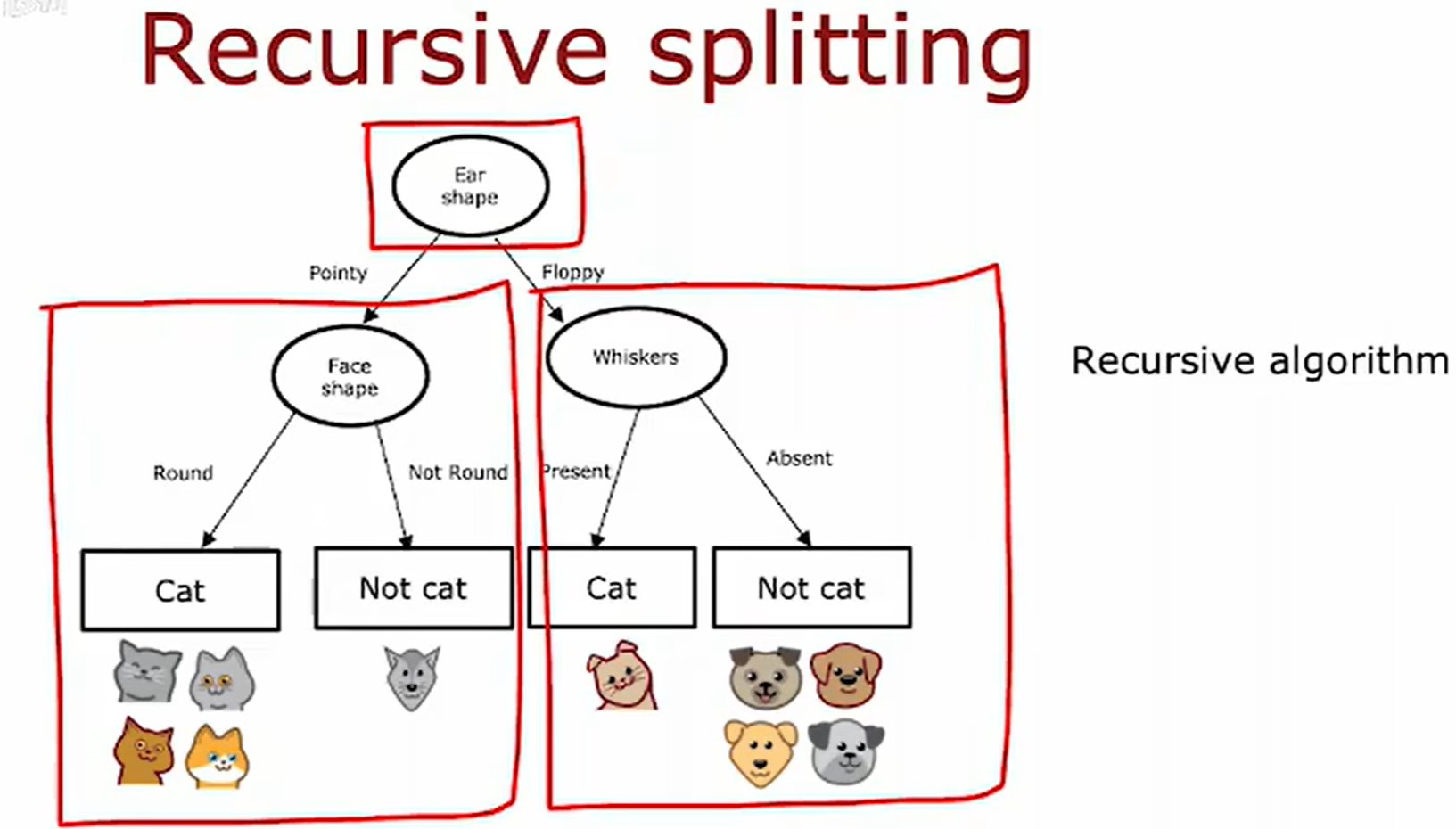
决策树的简介
训练样本如下
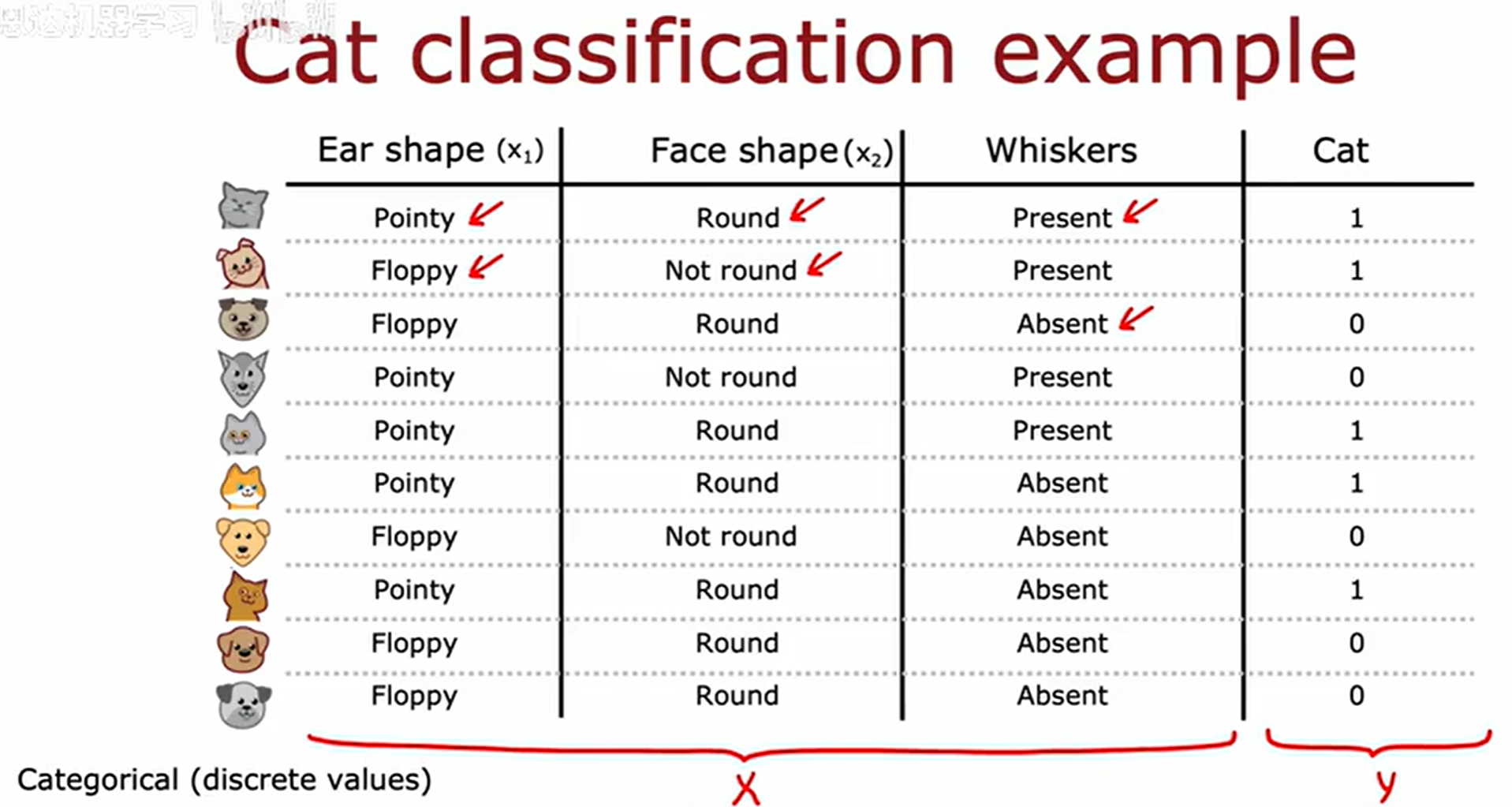
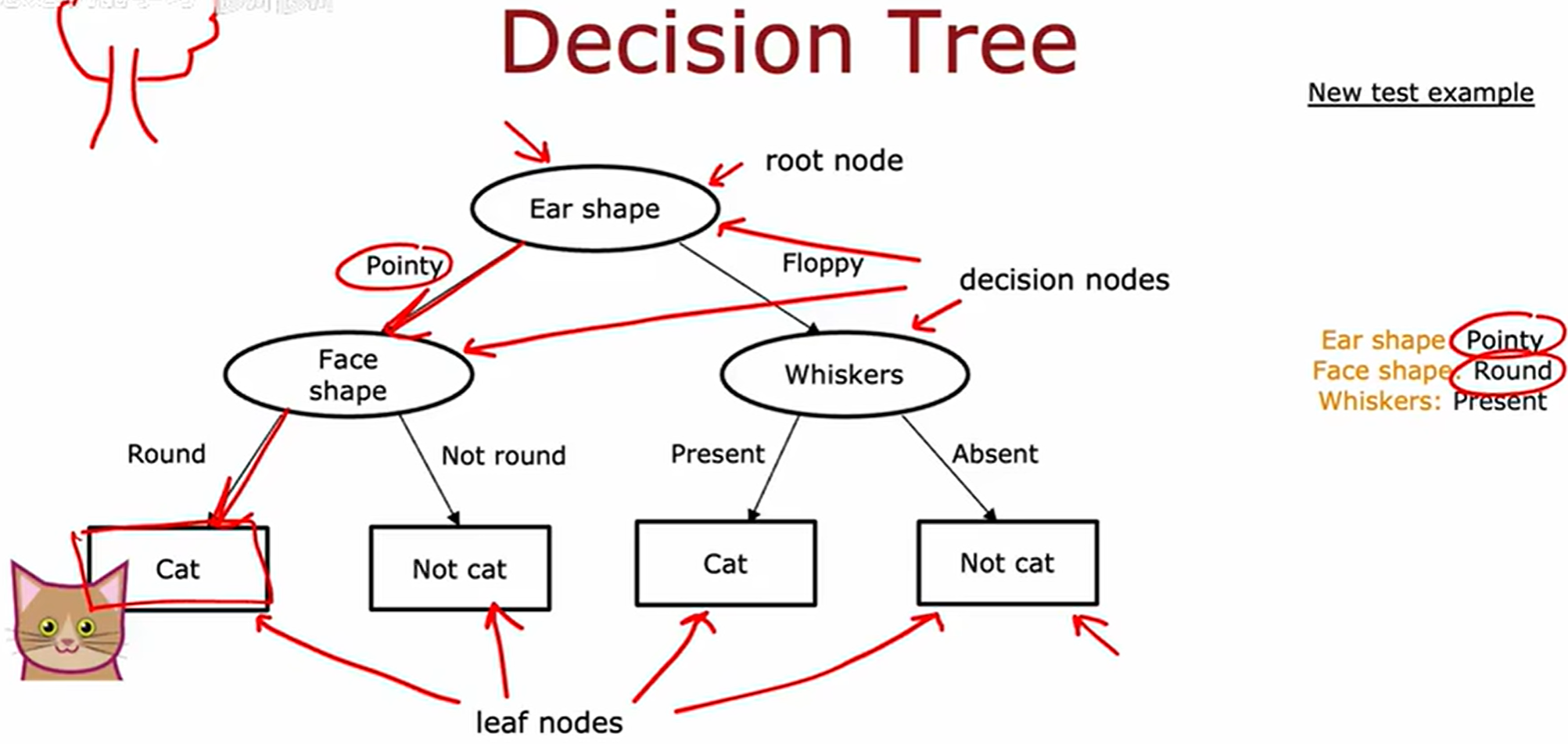
决策树学习算法的目标是从所有可能的决策树空间中,通过优化特定的评价准则(如信息增益、基尼不纯度等),选择出一个在训练集上具有良好拟合能力,同时通过剪枝等正则化方法控制模型复杂度,从而在未知测试数据上表现出强泛化性能的决策树模型。该过程需要平衡模型的偏差与方差,以避免过拟合或欠拟合问题。
决策树的学习过程
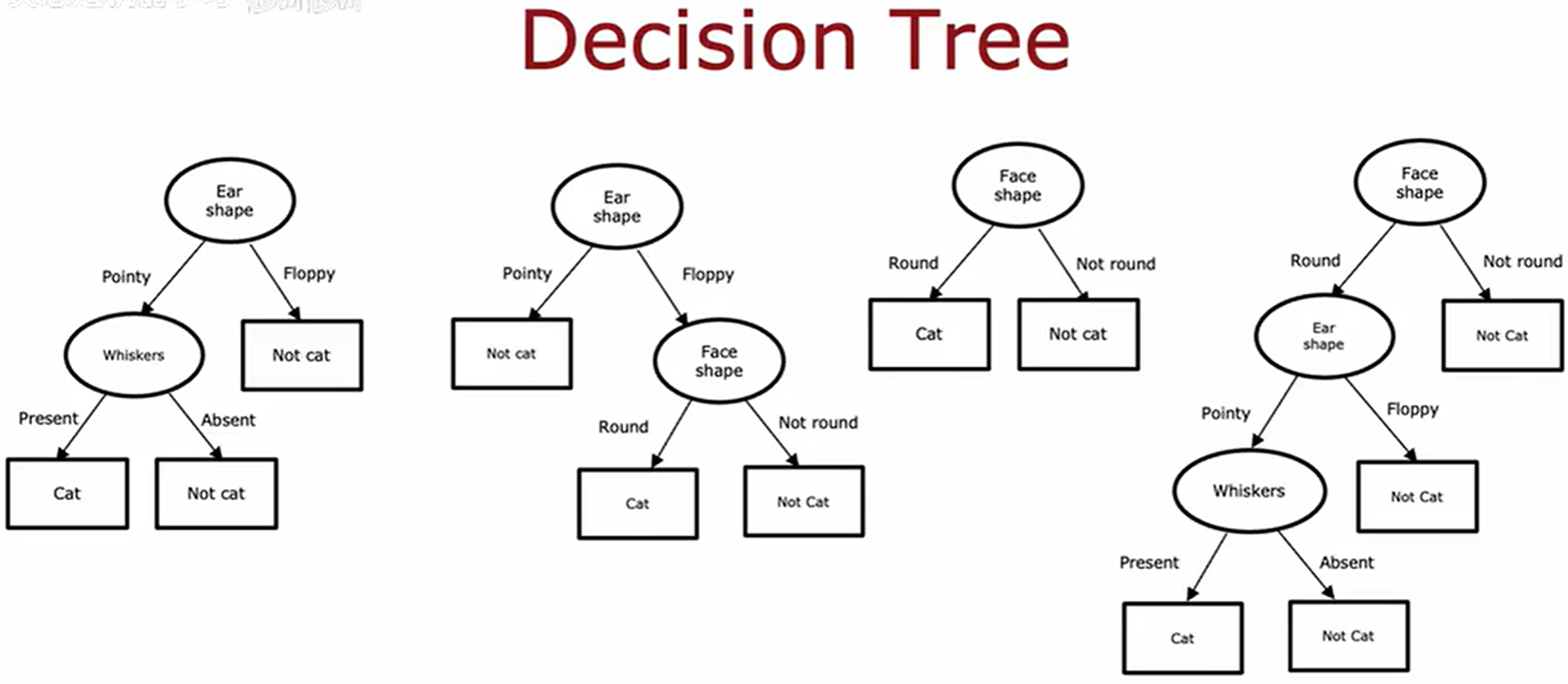
第一个决策,如何选择在每个节点进行划分的特征。
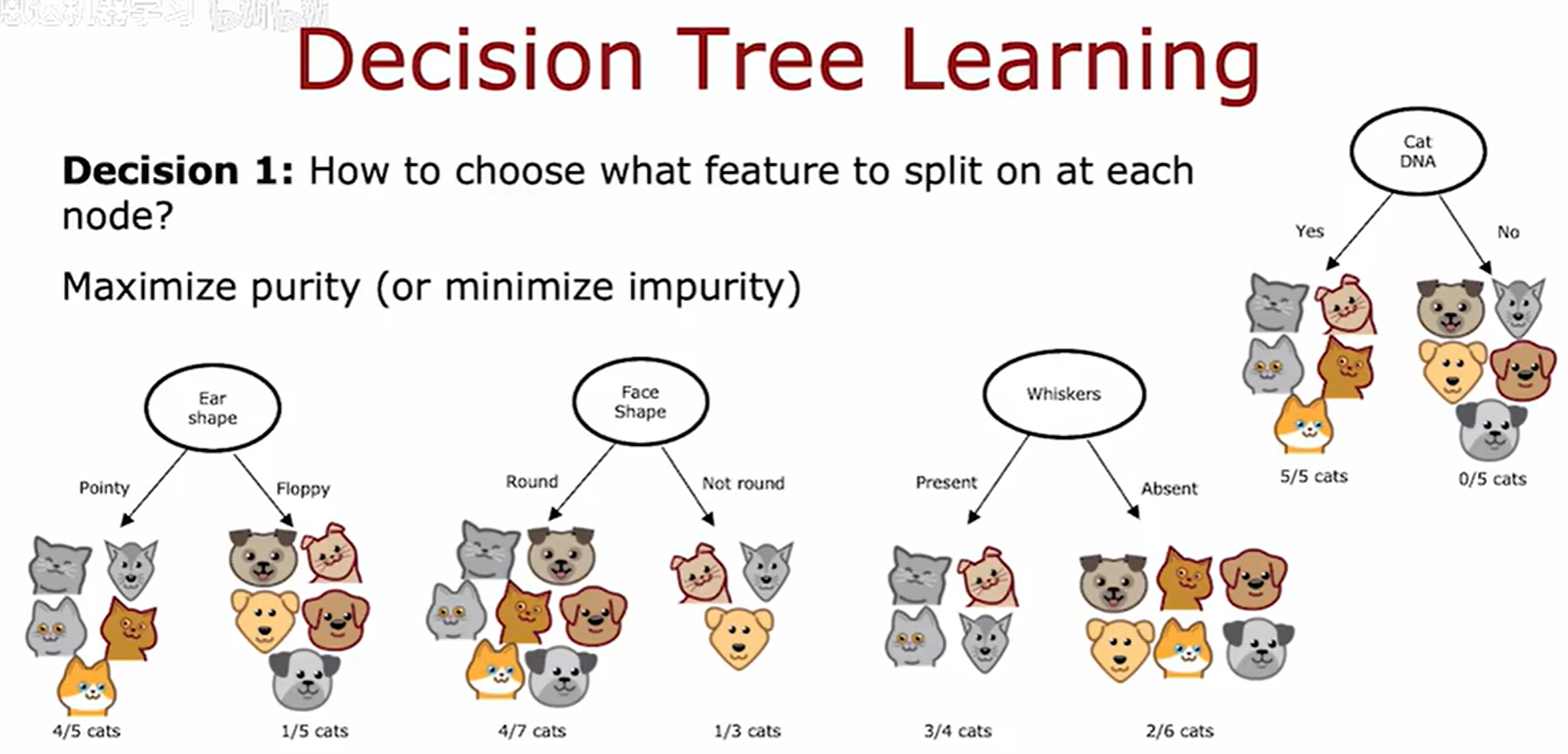
在决策树中,纯度(Purity) 衡量的是一个数据子集中样本类别的一致性程度。
在每一步特征选择时,优先选择能够使划分后子节点纯度最大化(或不纯度最小化)的特征进行分裂,从而构建具有更强分类能力的决策树。
第二个决策,什么时候停止划分。

测量纯度
量化纯度 / 不纯度
在决策树中,不纯度(Impurity) 是衡量一个数据子集中样本类别混杂程度的指标,与纯度(Purity)相反。

熵函数如下,会发现它和逻辑回归的交叉熵损失函数类似。前者是特征分裂的准则,后者是模型训练的损失函数。
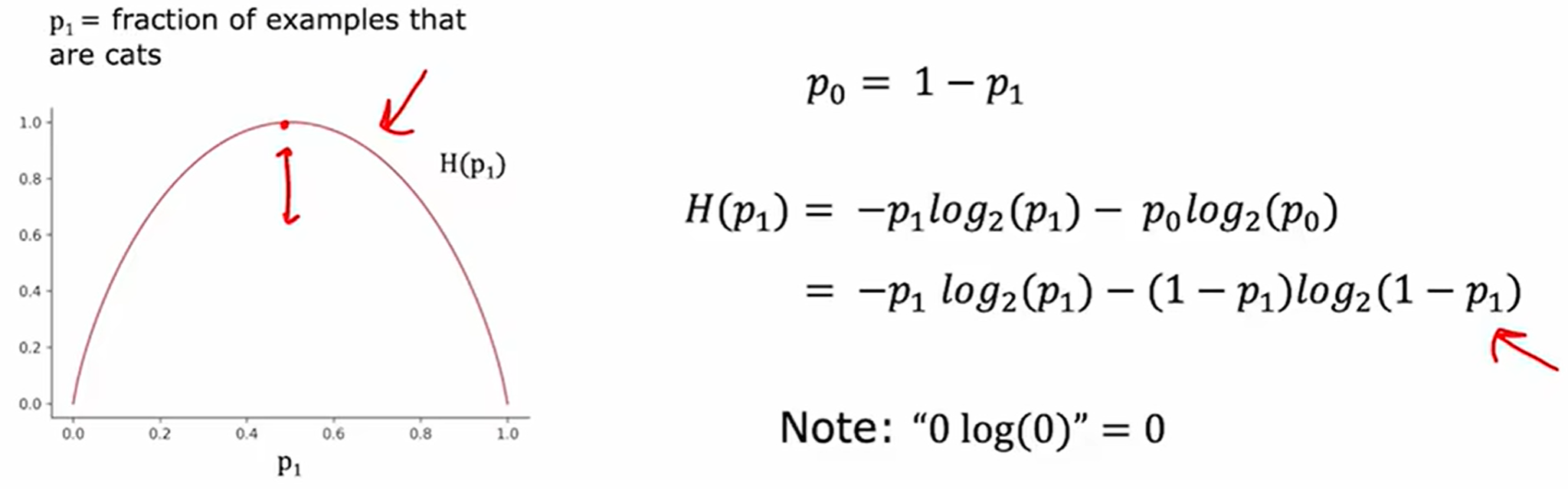
选择拆分信息增益
信息增益(Information Gain)
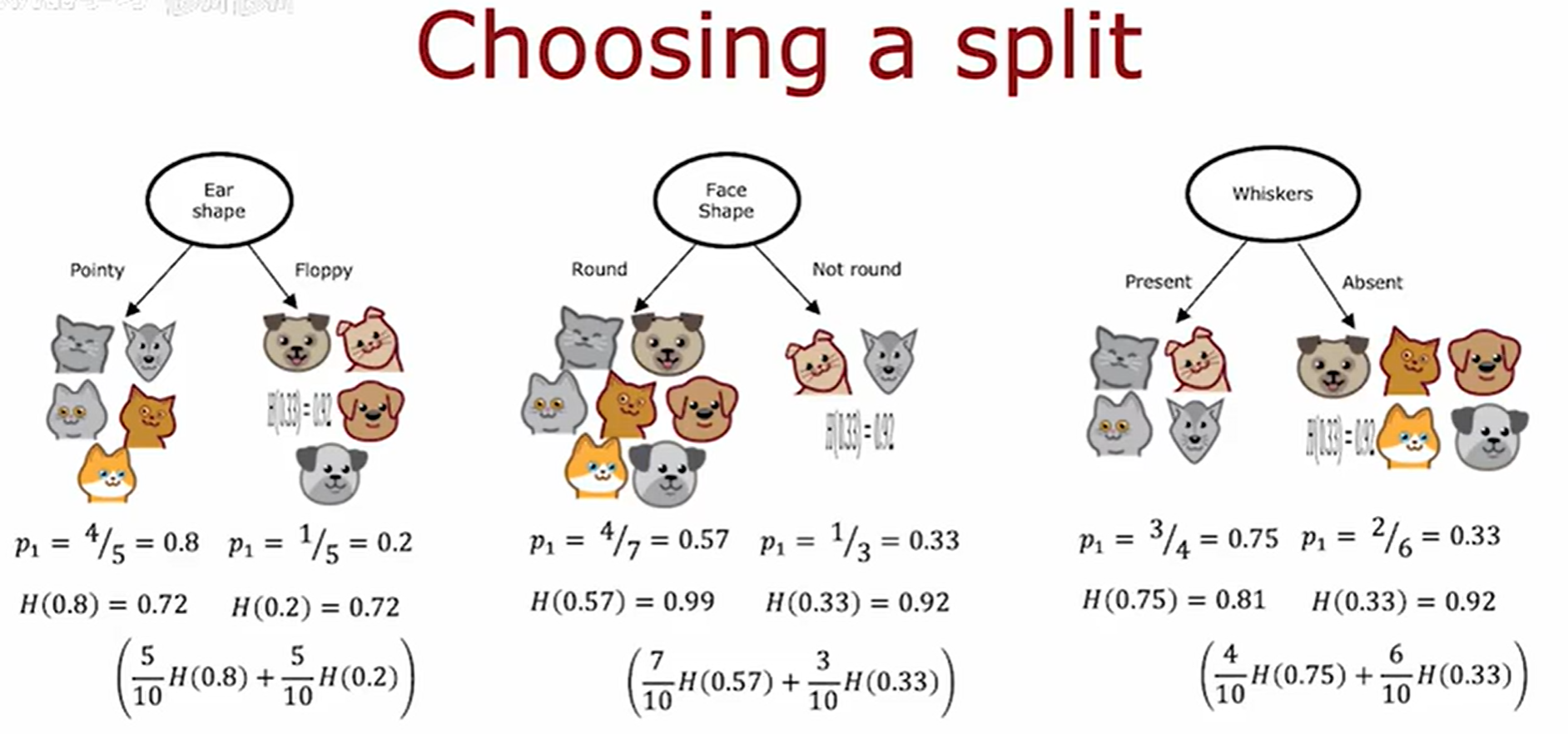
通过计算所有可能划分的左右分支加权平均熵,选择使该值最小的特征和分割点作为最优分裂方案,但是实际上并不会这样来,而是计算与没有分裂时相比的熵值的减少量。
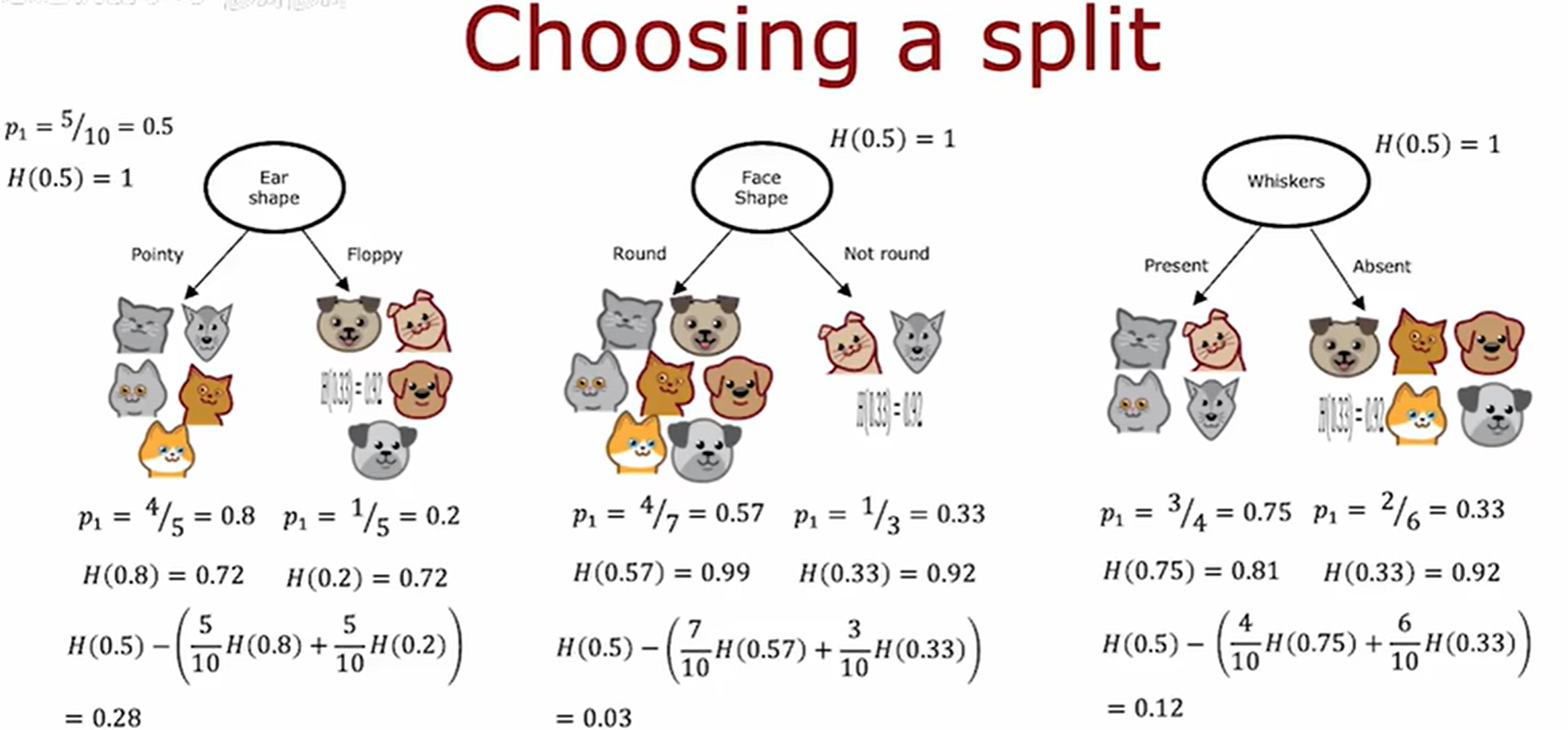
在决策树算法中,最优分裂点的选择是通过 计算信息增益 (Information Gain) 来确定的,具体步骤如下:
-
计算父节点的熵:表示分裂前的数据不纯度。
-
对每个候选特征和分割点:
- 计算划分后的左右子节点的熵
- 计算加权平均子节点熵:
H a f t e r = N l e f t N t o t a l H l e f t + N r i g h t N t o t a l H r i g h t H_{after} = \frac{N_{left}}{N_{total}}H_{left} + \frac{N_{right}}{N_{total}}H_{right} Hafter=NtotalNleftHleft+NtotalNrightHright - 计算信息增益:
I G = H b e f o r e − H a f t e r IG = H_{before} - H_{after} IG=Hbefore−Hafter
-
选择使信息增益最大的特征和分割点作为最优分裂方案。
决策树通过设定最小信息增益阈值,当候选分裂带来的熵减少量(ΔH)低于该阈值时停止拆分,以避免因过度细分数据而导致的过拟合风险,从而在模型复杂度和泛化能力之间取得平衡。

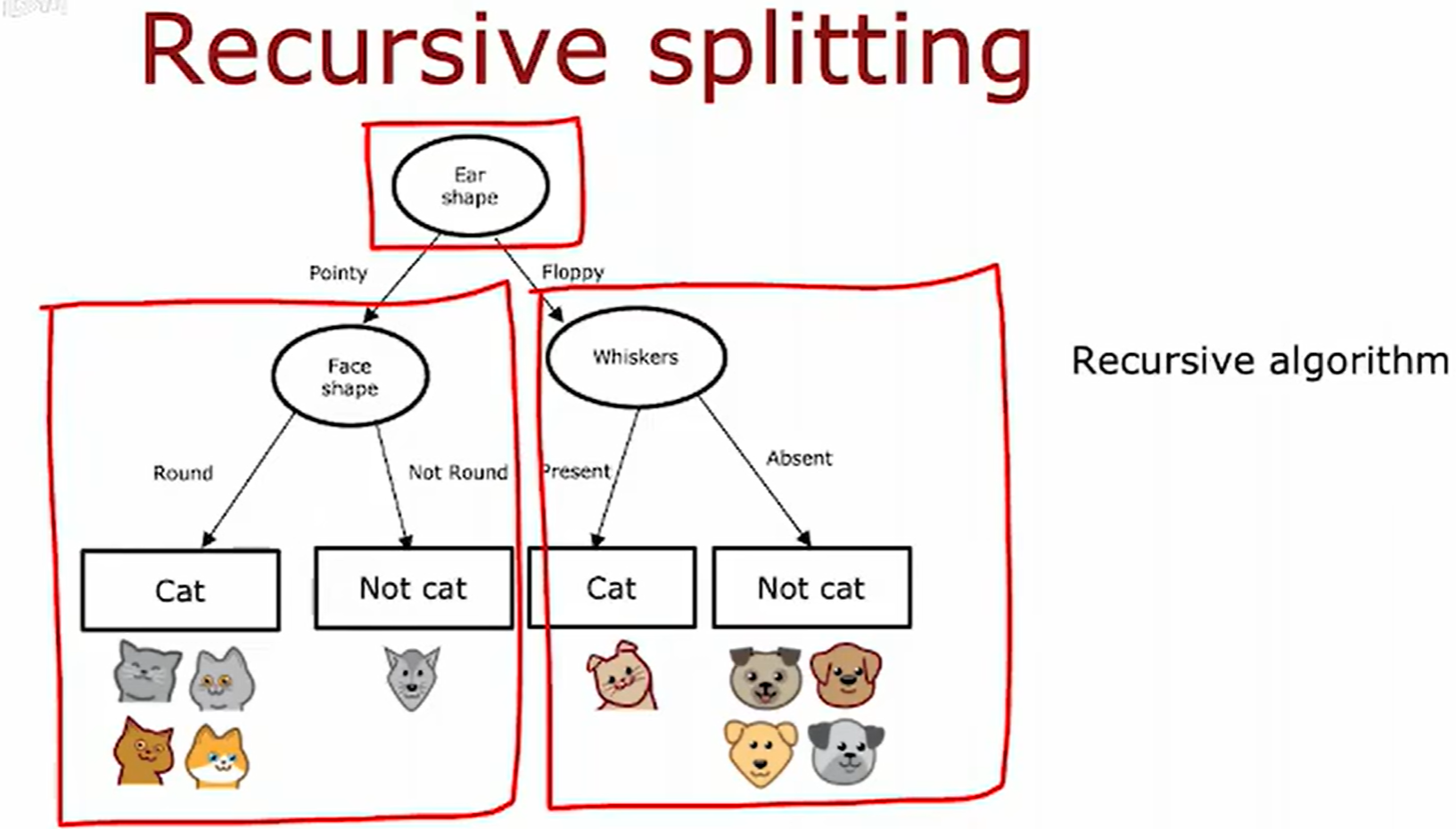
总体流程

递归构建决策树
独热编码(One-Hot Encoding)
在先前决策树算法中,当处理**多类别分类特征(Categorical Feature)时,传统的分裂方法是为每个类别值创建单独的分支(例如一个三类别特征会生成三叉分支)。但这种方法可能导致树结构过于复杂或稀疏。为此,可采用独热编码(One-Hot Encoding)**对分类特征进行优化处理。
训练数据如下
将多类别分类特征分成多个分类特征
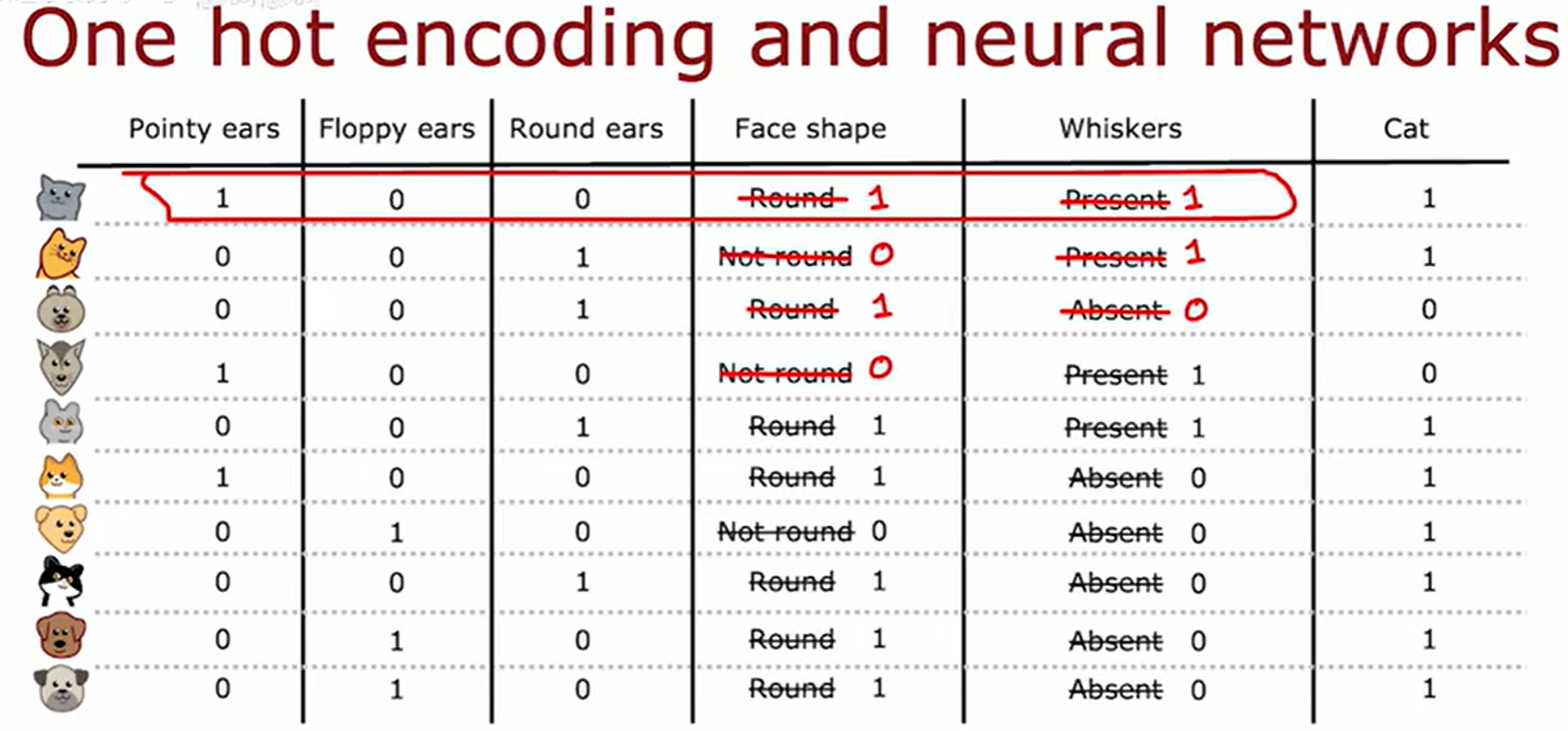
独热编码不仅适用于决策树,还可以用于神经网络。
处理连续值特征
训练数据如下
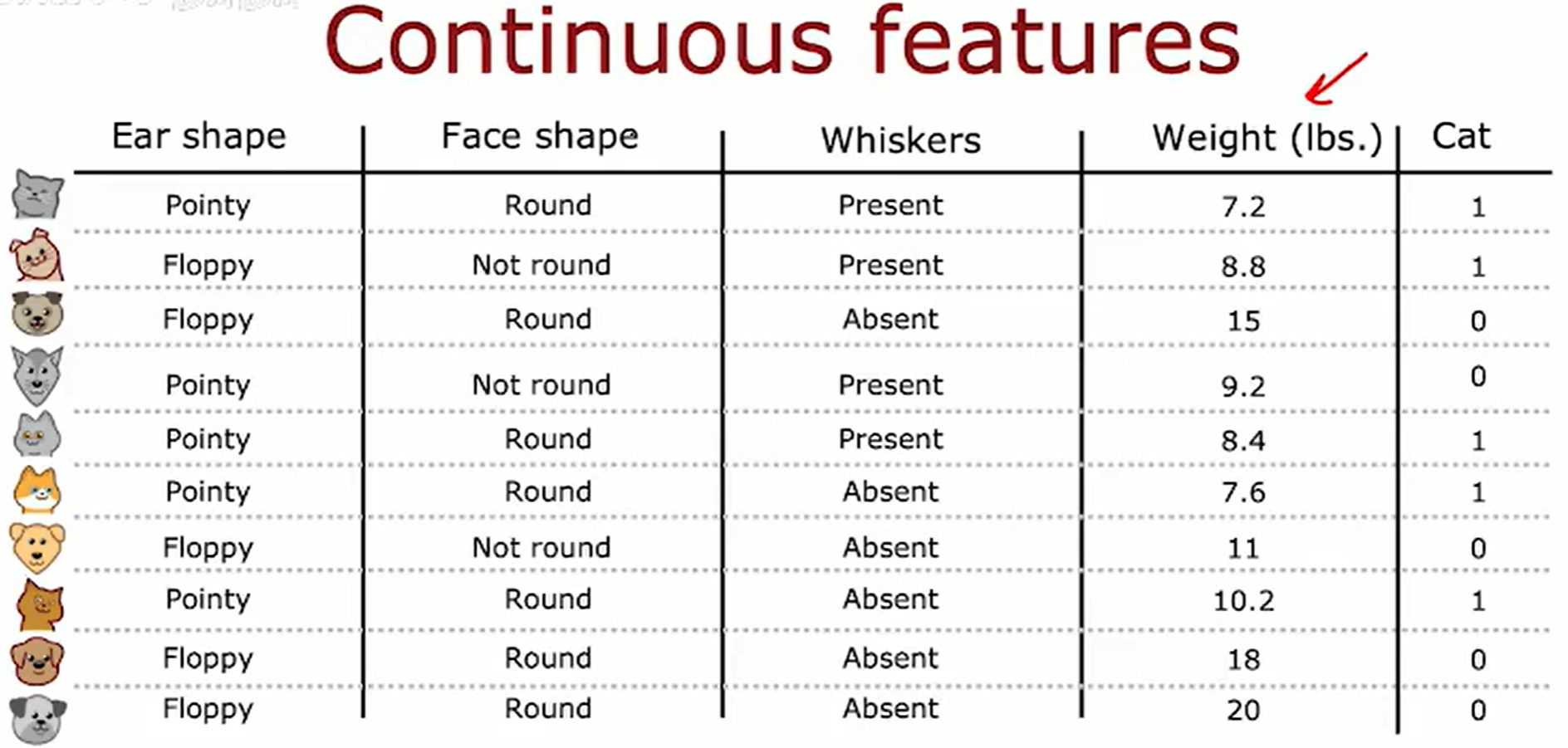
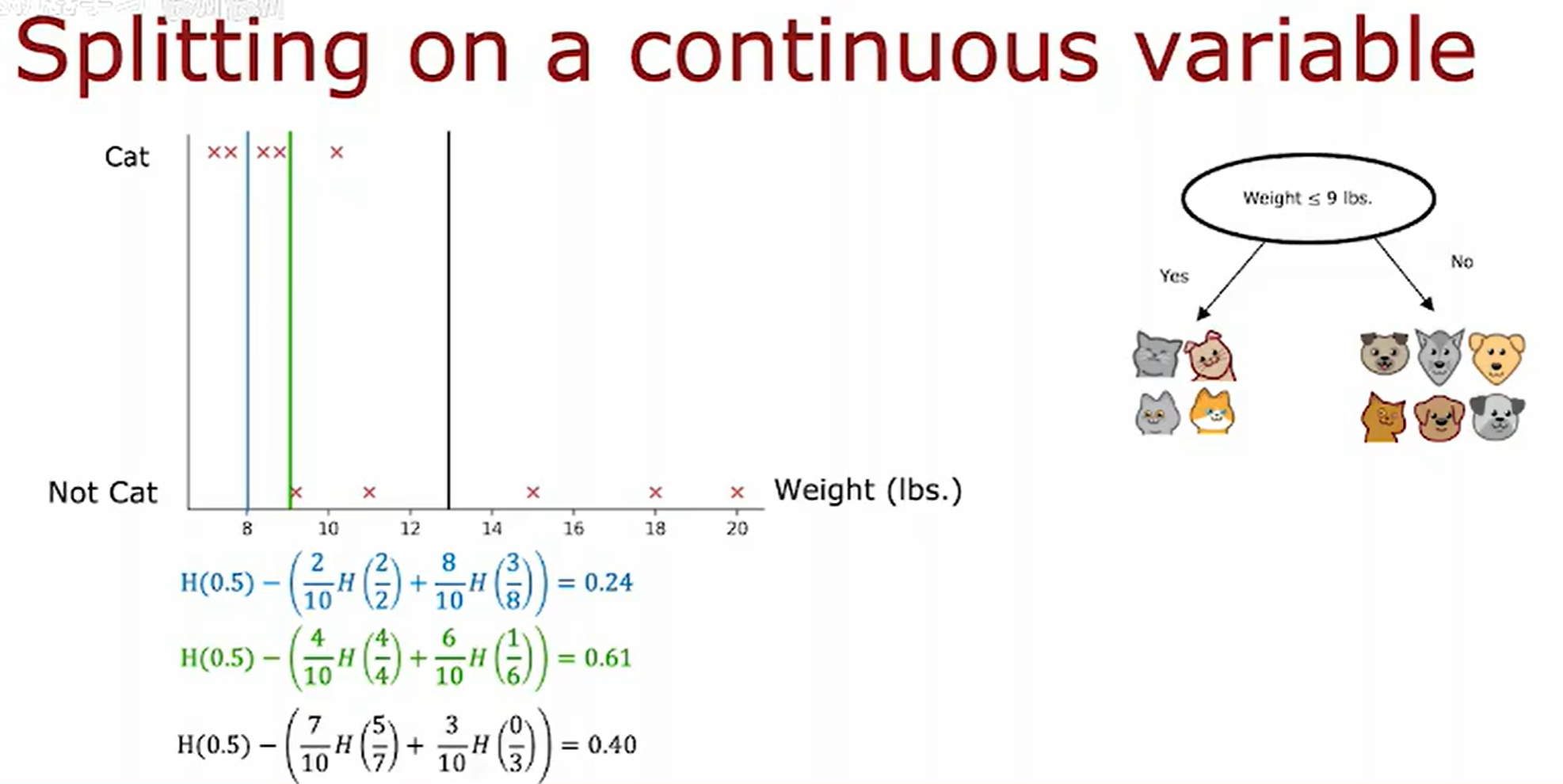
在决策树中处理连续值特征的核心方法是通过阈值划分将其离散化,具体步骤如下:
1. 连续特征的分裂方法
(1)排序与候选阈值生成
- 对连续特征的所有取值升序排序(如特征值为
[1.2, 3.4, 5.6, 7.8])。 - 生成候选分裂阈值:
- 通常取相邻值的中间点(如
(1.2+3.4)/2 = 2.3)。 - 若有
N个唯一值,则生成N-1个候选阈值。
- 通常取相邻值的中间点(如
(2)计算分裂增益
对每个候选阈值 t:
-
将样本划分为两部分:
- 左分支:特征值 ≤ t 的样本
- 右分支:特征值 > t 的样本
-
计算分裂后的信息增益(IG):
Gain = H parent − ( N left N H left + N right N H right ) \text{Gain} = H_{\text{parent}} - \left( \frac{N_{\text{left}}}{N} H_{\text{left}} + \frac{N_{\text{right}}}{N} H_{\text{right}} \right) Gain=Hparent−(NNleftHleft+NNrightHright)- 其中
H为熵或基尼不纯度,N为样本数。
- 其中
(3)选择最优分裂点
- 选择使增益最大的阈值
t*作为分裂点。
2. 优化与注意事项
(1)算法效率优化
- 排序预处理:只需在首次分裂时排序一次,后续递归使用子集。
- 近似算法:在大数据集中,可采样部分候选阈值(如分位数)加速计算(如 XGBoost 的
approx模式)。
(2)过拟合控制
- 限制连续特征的分裂粒度:
- 设置最小分裂样本数(
min_samples_split)。 - 限制最大深度(
max_depth)。
- 设置最小分裂样本数(
(3)与分类特征的区别
- 连续特征:通过阈值比较生成二叉分支。
- 分类特征:通过类别归属生成多分支或独热编码(One-Hot)。
回归树 (Regression Trees)
回归树(Regression Tree)是决策树算法在连续型目标变量场景下的扩展,突破了传统决策树仅适用于分类任务(离散型目标变量)的局限性。
区别
| 维度 | 分类树(Classification Tree) | 回归树(Regression Tree) |
|---|---|---|
| 预测目标 | 离散类别(如"是/否") | 连续数值(如房价、温度) |
| 叶节点输出 | 类别标签(多数表决) | 数值均值(叶节点内样本的平均值) |
| 分裂准则 | 信息增益/基尼不纯度 | 方差减少(MSE、Friedman-MSE等) |
通过将特征的均值作为输出
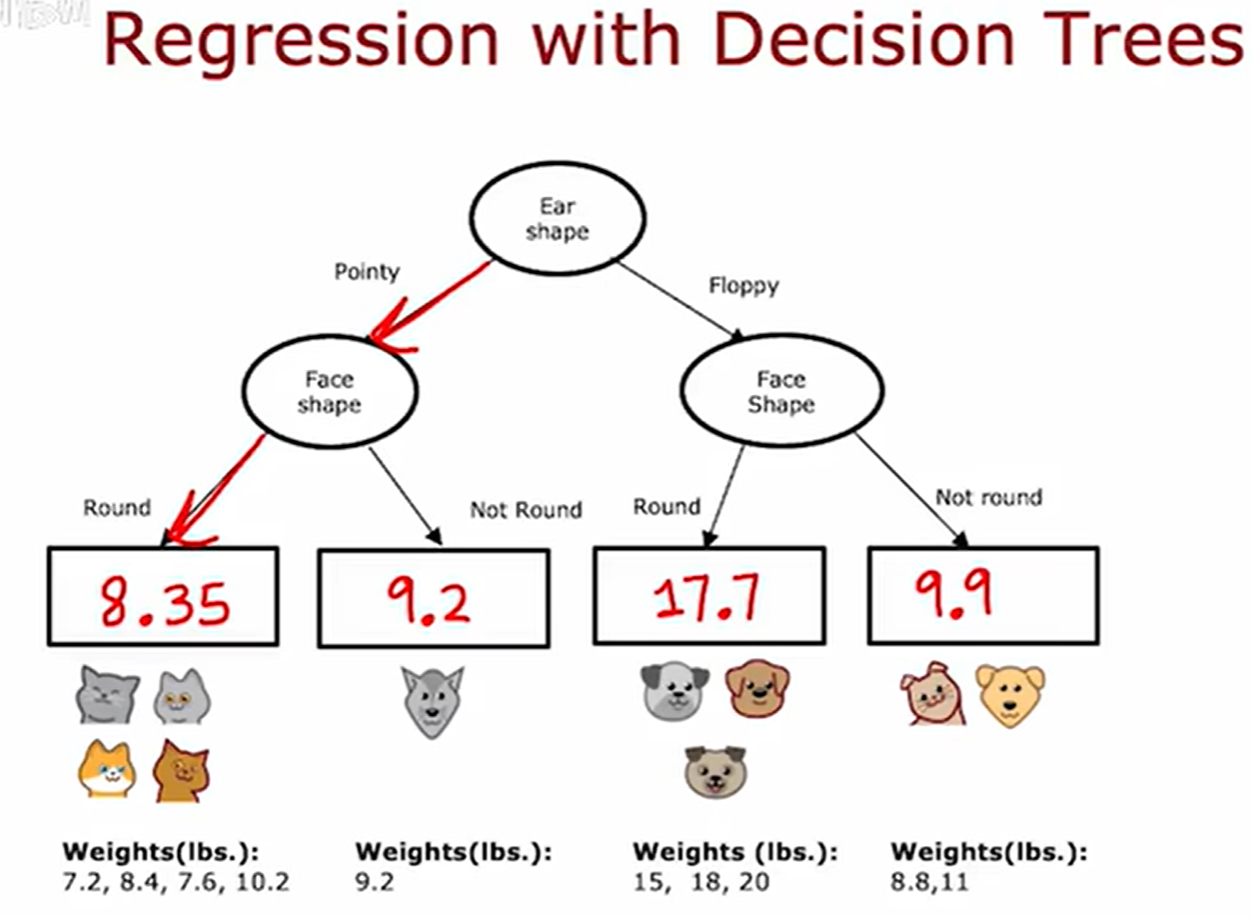
回归树通过计算连续特征的方差来进行信息增益的计算,而后通过信息增益来决定拆分。

树集成 (Tree Ensembles)
使用单个决策树的一个缺点是,它可能对微小的变化高度敏感。一个使算法变得不那么敏感或者更稳健的一个解决方案是建造不止一个决策树。
单个决策树的敏感问题

决策树算法对训练数据的局部变化可能较为敏感。在某些情况下,仅修改一个训练样本就可能导致信息增益最高的分裂特征从从耳朵形状 (Ear shape) 变成胡须 (Whiskers),从而生成拓扑结构完全不同的决策树。这种不稳定性源于算法对训练数据微小变化的高度响应性,是决策树模型方差较高的典型表现。
树集成简介
树集成:
- 组合多棵决策树,通过投票(分类)或平均(回归)得到最终结果。
- 主要方法:
- Bagging(如随机森林):并行训练多棵独立树,降低方差。
- Boosting(如XGBoost、AdaBoost):串行训练树,每一棵纠正前一棵的错误,降低偏差。
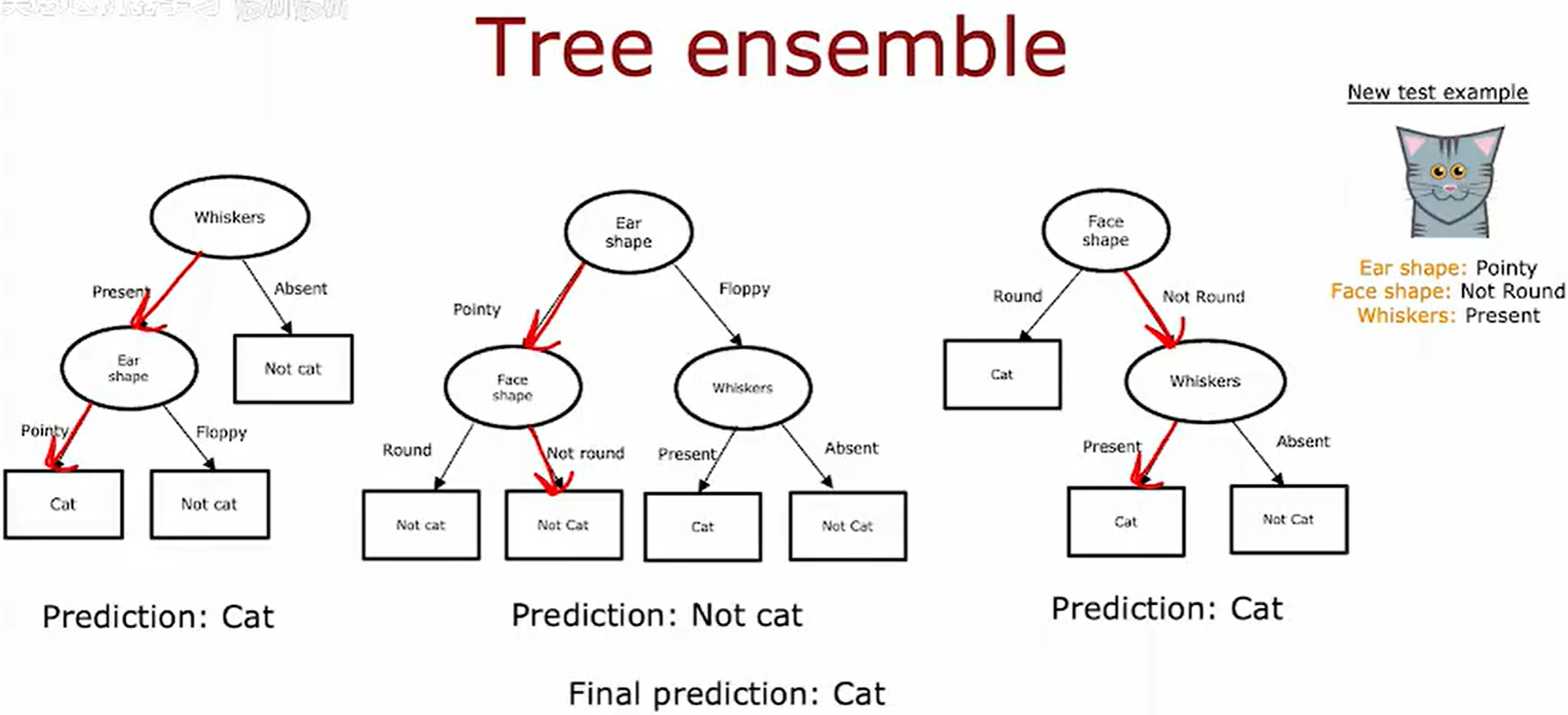
投票最终分类预测结果为猫
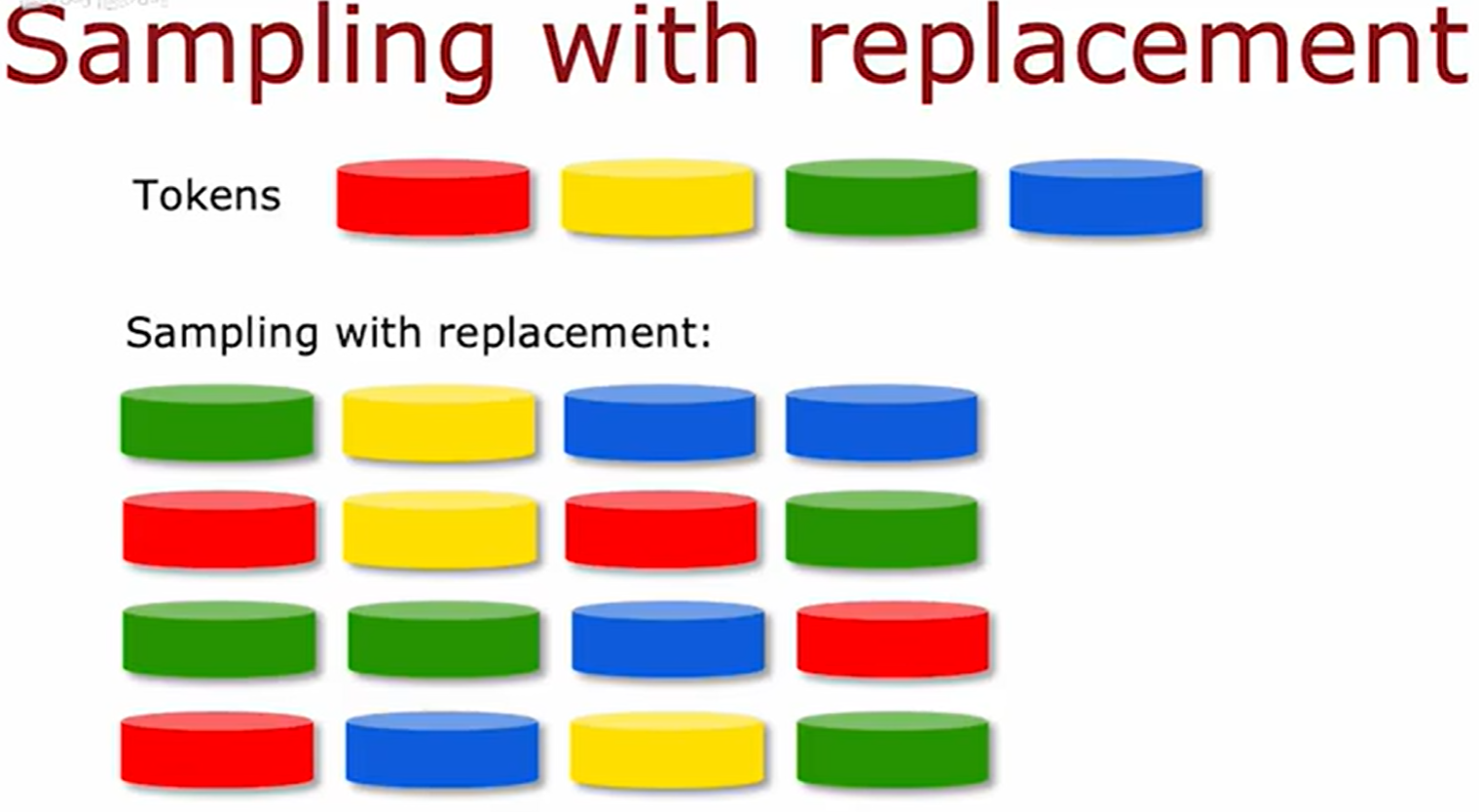
有放回抽样 (Sampling with replacement)
为了构建一个树集成模型,采用有放回抽样的技术,来创建新的训练集的方法,这些训练集既有点类似,但和原始训练集大不相同。
有放回抽样在构建树的集成方法中的应用如下:
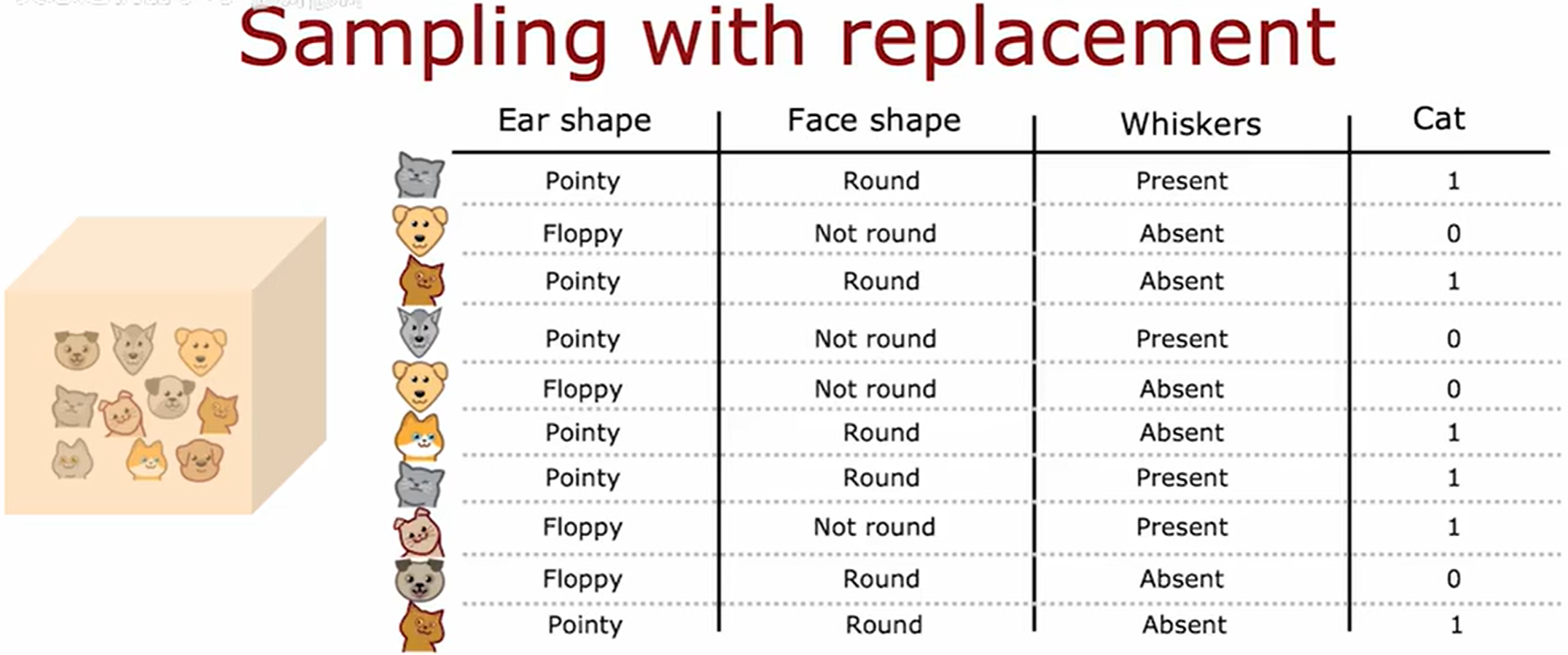
通过抽取获得训练样例,这个训练集中并不包含原始的10个训练例子的全部,甚至有些重复的。
随机森林算法 (Random forest algorithm)
随机森林(Random Forest)是一种强大的集成学习算法,它通过构建多棵决策树并结合它们的预测结果,显著提升了模型的泛化能力和鲁棒性,通常比单一决策树表现更优。
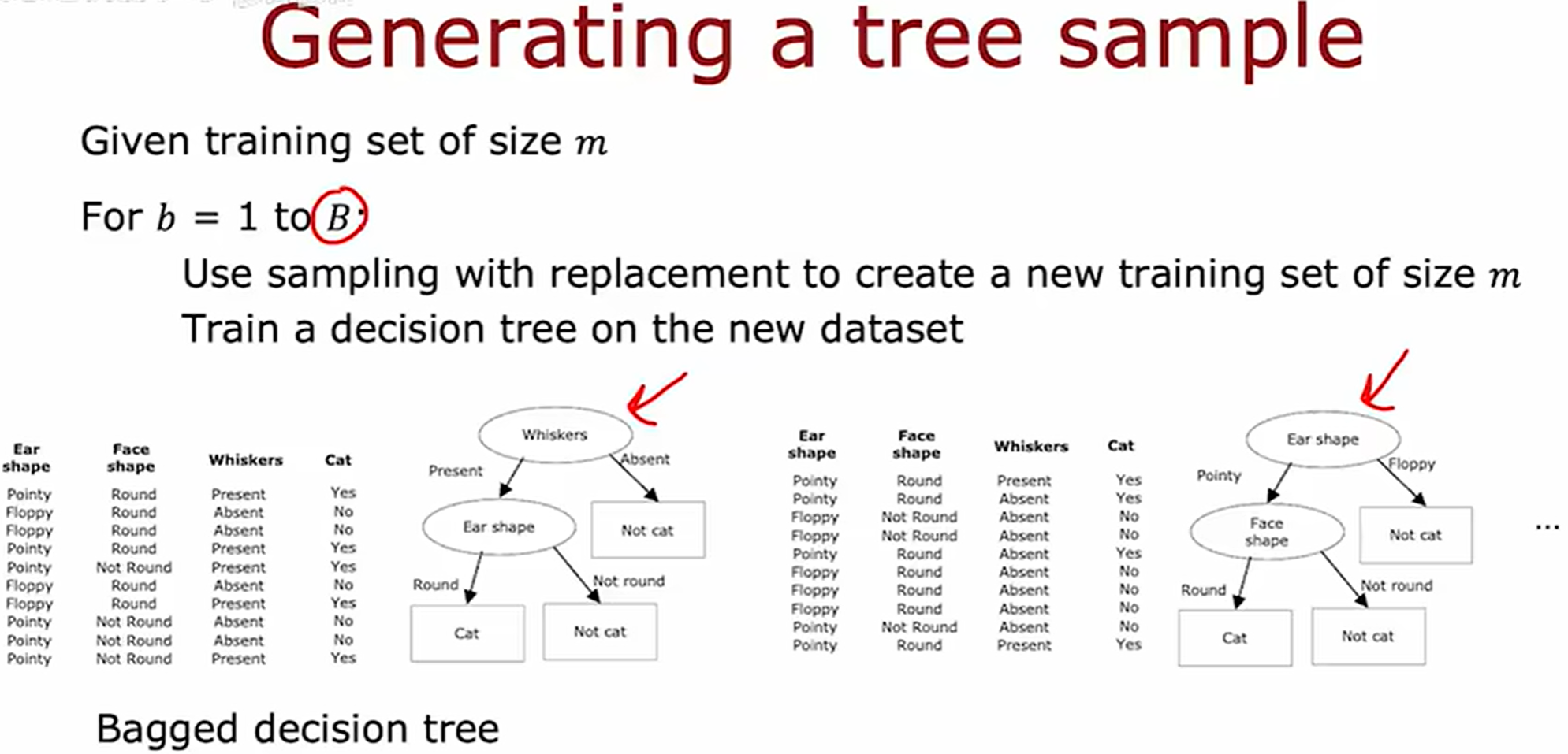
构建袋装决策树(Bagged Decision Trees)时,我们首先通过有放回抽样(自助采样)从原始训练集中生成多个不同的训练子集。对于每一个新的训练子集,我们都会训练一个独立的决策树。袋装决策树是一种强大的集成学习方法,通过聚合这些独立决策树的预测结果(分类任务通常采用多数投票,回归任务通常采用平均),能够显著提高模型的稳定性和预测准确性。“袋装 (Bagged)” 一词来源于其全称 Bootstrap Aggregating。值得注意的是,袋装决策树是更高级的集成学习算法——**随机森林(Random Forest)**的基础。

在决策树的每个节点进行特征选择时,如果共有 n 个可用特征,算法会随机选取 k 个特征(k < n),并仅从这 k 个特征的子集中选择最优分裂特征。这种方法通过引入随机性,能有效增加模型的多样性,降低过拟合风险,于是就形成了随机森林算法。
如果共有 n 个可用特征(其中 n 是一个较大的数,例如几十或上百),通常会从 n 个特征中随机选取 k = n k = \sqrt{n} k=n(即 n 的平方根,取整数)个特征构成候选子集,并仅在该子集中选择最优分裂特征。
随机森林算法通过结合**自助采样(Bootstrap Sampling)技术生成不同的训练子集,并引入特征随机选择(Random Feature Subsets)机制来增强模型结构的多样性。这种双重随机性的设计使得算法能够构建并集成(Ensemble)**大量具有显著差异的决策树。最终的预测结果通过对这些决策树的预测进行平均(回归任务)或投票(分类任务)得到。这种集成策略有效地探索并平滑了训练数据中的微小扰动,这意味着即使训练集发生细微的变化,整体随机森林算法的输出结果通常也具有很高的稳定性,不易受到显著影响。
XGBoost 提升决策树算法
提升树 (Boosted trees)
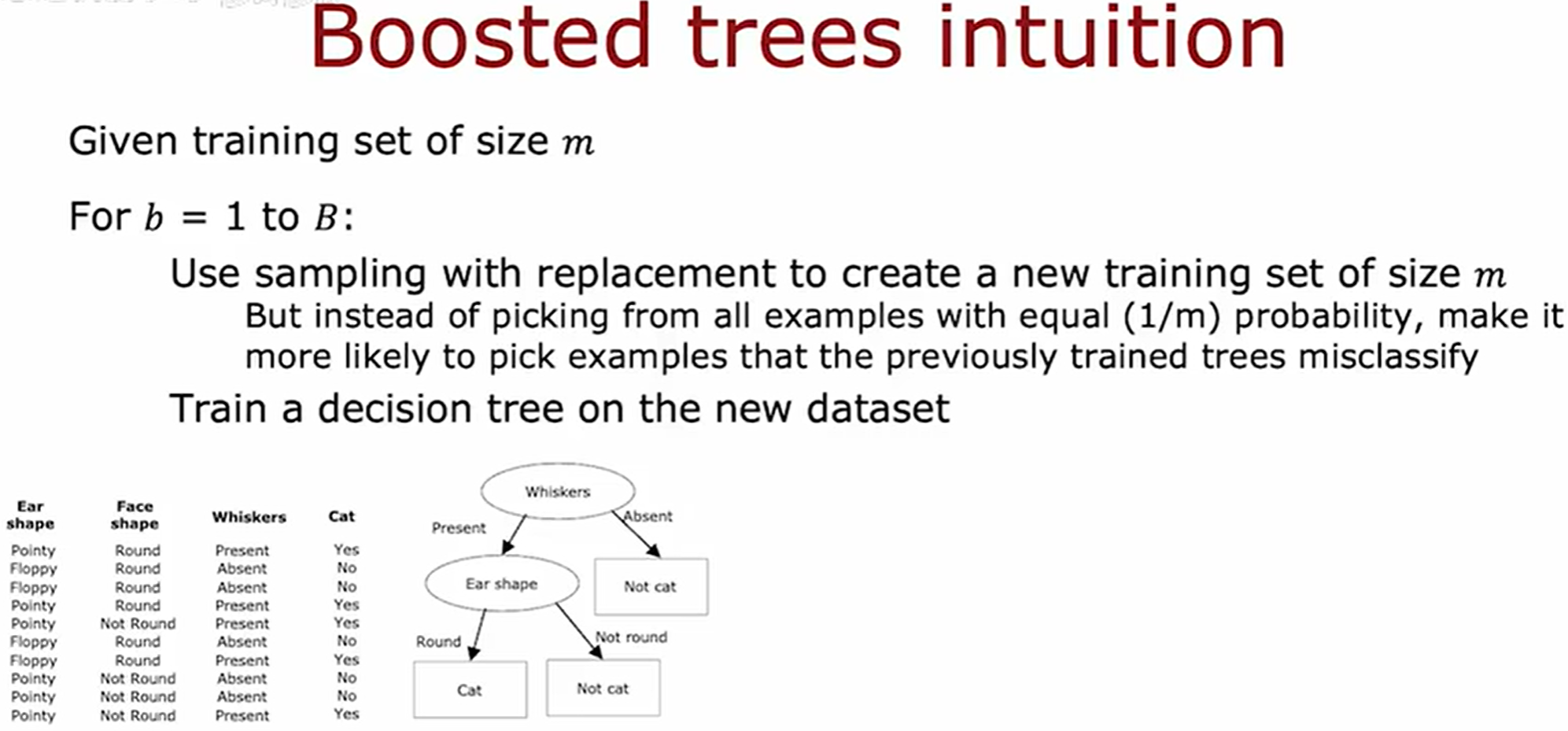
随机森林:每棵决策树训练时,随机抽取样本(每个样本被抽中的概率相同),所有树相互独立,最后投票决定结果。
Boosted trees 提升树
- 重点关注错误
✅ Boosted Tree 的核心思想是迭代修正错误。每一轮训练的新树会更关注前一棵树预测错误的样本(通过调整样本权重或梯度方向),而非完全随机学习。 - 逐步优化(Sequential Training)
✅ 提升树是顺序训练的(一棵接一棵),每棵树尝试修正前一棵树的残差(错误),这与随机森林(Bagging)的独立训练有本质区别。 - 非随机性学习
✅ 提升方法(如AdaBoost、Gradient Boosting)通过自适应调整样本权重或拟合残差,让后续模型专注于难样本,而非随机抽样。

上述为提升树的构造过程,第 b - 1 棵决策树构建成功后,会将其用于原始数据集中进行预测正确性的对比,预测错误的将会更有概率成为用于构建第 b 棵决策树的新的训练集。
XGBoost 的特点

在各种实现提升的方法中,目前最广泛使用的是 XGBoost (eXtreme Gradient Boosting)【极端梯度提升】,这是一个非常快速且高效的开源提升树实现。
XGBoost是一种高效的梯度提升树实现,通过正则化(L1/L2)防止过拟合,并提供了默认的分裂与停止条件。其创新性包括动态样本权重调整(基于梯度统计)和特征子采样,避免了传统Bagging中重复生成训练集的开销。此外,工程优化(如并行化、稀疏处理)进一步提升了计算效率。
【注意:XGBoost 未使用有放回抽样,实际上会为不同的训练样本分配不同的权重,所以实际上不需要生成大量随机选择的训练集,这使得它比使用有有放回抽样程序更高效一些。】
XGBoost 的使用
XGBoost 的实现细节相当复杂,许多从业者会直接使用实现 XGBoost 的开源库 xgboost。


XGBoost 的实现细节
XGBoost(eXtreme Gradient Boosting)是一种高效、灵活的梯度提升框架,其在传统Gradient Boosting基础上引入了多项优化。以下是其核心实现细节的系统
1. 目标函数设计:正则化损失
XGBoost的核心是优化以下目标函数:
L ( ϕ ) = ∑ i = 1 n l ( y i , y ^ i ) + ∑ k = 1 K Ω ( f k ) \mathcal{L}(\phi) = \sum_{i=1}^n l(y_i, \hat{y}_i) + \sum_{k=1}^K \Omega(f_k) L(ϕ)=i=1∑nl(yi,y^i)+k=1∑KΩ(fk)
-
第一项:训练损失(如MSE、Logloss)
-
第二项:正则化项,控制模型复杂度:
Ω ( f k ) = γ T + 1 2 λ ∥ w ∥ 2 + α ∥ w ∥ 1 \Omega(f_k) = \gamma T + \frac{1}{2}\lambda \|w\|^2 + \alpha \|w\|_1 Ω(fk)=γT+21λ∥w∥2+α∥w∥1- T T T:叶子节点数(控制树深度)
- w w w:叶子权重(L2/L1正则化防止过拟合)
2. 梯度提升与泰勒展开
-
传统Gradient Boosting:仅使用一阶梯度(负梯度方向)。
-
XGBoost创新:使用二阶泰勒展开近似损失函数,更精准地更新模型:
L ( t ) ≈ ∑ i = 1 n [ l ( y i , y ^ i ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) \mathcal{L}^{(t)} \approx \sum_{i=1}^n \left[ l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i) \right] + \Omega(f_t) L(t)≈i=1∑n[l(yi,y^i(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)- g i = ∂ y ^ ( t − 1 ) l ( y i , y ^ ( t − 1 ) ) g_i = \partial_{\hat{y}^{(t-1)}} l(y_i, \hat{y}^{(t-1)}) gi=∂y^(t−1)l(yi,y^(t−1)):一阶导数
- h i = ∂ y ^ ( t − 1 ) 2 l ( y i , y ^ ( t − 1 ) ) h_i = \partial^2_{\hat{y}^{(t-1)}} l(y_i, \hat{y}^{(t-1)}) hi=∂y^(t−1)2l(yi,y^(t−1)):二阶导数(Hessian)
二阶信息可更准确地确定步长,加速收敛。
3. 树结构的贪婪生成算法
1) 分裂节点选择
-
增益(Gain)计算:
分裂后目标函数的减少量决定是否分裂:
Gain = 1 2 [ ( ∑ i ∈ I L g i ) 2 ∑ i ∈ I L h i + λ + ( ∑ i ∈ I R g i ) 2 ∑ i ∈ I R h i + λ − ( ∑ i ∈ I g i ) 2 ∑ i ∈ I h i + λ ] − γ \text{Gain} = \frac{1}{2} \left[ \frac{(\sum_{i \in I_L} g_i)^2}{\sum_{i \in I_L} h_i + \lambda} + \frac{(\sum_{i \in I_R} g_i)^2}{\sum_{i \in I_R} h_i + \lambda} - \frac{(\sum_{i \in I} g_i)^2}{\sum_{i \in I} h_i + \lambda} \right] - \gamma Gain=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ihi+λ(∑i∈Igi)2]−γ- I L , I R I_L, I_R IL,IR:分裂后的左右子节点样本集
- γ \gamma γ:分裂阈值(若Gain < γ \gamma γ 则停止分裂,防止过拟合)
2) 分裂查找优化
- 精确贪心算法:遍历所有特征的所有可能分裂点(计算量大,适合小数据集)。
- 近似算法:
- 按特征分位数分桶(如
histogram),仅检查桶边界作为候选分裂点。 - 支持全局(Global)和局部(Local)分桶策略,平衡精度与效率。
- 按特征分位数分桶(如
3) 稀疏感知分裂
- 自动处理缺失值:
为缺失值默认分配到一个方向(左或右),基于增益最大化决定。
4. 工程优化:速度与内存
1) 列块(Column Block)
- 特征预排序:将数据按特征值排序后存储为压缩列(CSC格式),使分裂查找可复用。
- 并行化:在特征级别并行计算增益(多线程处理不同特征)。
2) 缓存感知访问
- 缓存优化:为梯度统计量( g i , h i g_i, h_i gi,hi)预加载到CPU缓存,减少内存读取延迟。
3) 核外计算(Out-of-Core)
- 数据分块(Block)存储于磁盘,通过异步IO和压缩处理超大数据集。
5. 其他关键技术
1) 正则化策略
- Shrinkage(学习率):每棵树乘以学习率 η \eta η(如0.1),抑制单棵树影响,防止过拟合。
- 行/列抽样:训练时随机采样部分样本(行)或特征(列),类似随机森林。
2) 自定义损失函数
- 用户可自定义损失函数(需提供一阶、二阶导数),支持多样化任务(如排序、泊松回归)。
3) 内置交叉验证
- 支持每轮迭代后计算验证集指标,早停(Early Stopping)避免过拟合。
6. 与传统GBDT的对比
| 特性 | XGBoost | 传统GBDT |
|---|---|---|
| 损失函数 | 二阶泰勒展开 + 正则化 | 仅一阶梯度 |
| 缺失值处理 | 自动稀疏感知分裂 | 需手动填充 |
| 并行化 | 特征级别并行 | 无 |
| 速度 | 快(工程优化+近似算法) | 慢(精确贪心) |
| 过拟合控制 | L1/L2正则化 + 早停 + 子采样 | 主要依赖树深度 |
使用决策树的时机

决策树及树集成方法
- 在表格(结构化)数据上表现良好
- 不推荐用于非结构化数据(如图像、音频、文本)
- 运行速度快
- 小型决策树可能具备人类可解释性
神经网络
- 适用于所有数据类型,包括表格(结构化)数据和非结构化数据
- 可能比决策树运行速度慢
- 支持迁移学习
- 当构建由多个模型协同工作的系统时,串联多个神经网络可能更简便

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)