HuggingFace平台详细介绍|模型or数据集下载
一、HuggingFace平台介绍)平台可以类比为机器学习领域的 GitHub,它是用于分享、协作和托管预训练模型、数据集和相关代码的平台。其主要的优势是提供了简单易用的 API 和界面,使得即使是没有深厚机器学习背景的用户也能轻松使用这些模型。

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录

一、HuggingFace平台介绍
Hugging Face (https://huggingface.co/)平台可以类比为机器学习领域的 GitHub,它是用于分享、协作和托管预训练模型、数据集和相关代码的平台。其主要的优势是提供了简单易用的 API 和界面,使得即使是没有深厚机器学习背景的用户也能轻松使用这些模型。随着transformer浪潮,Huggingface逐步收纳了众多最前沿的模型和数据集等有趣的工作,与transformers库结合,可以快速使用学习这些模型。目前提到NLP必然绕不开Huggingface。
目前主流的两个开源大模型平台分别是:HuggingFace :类似于 github ,模型比较全,但是 需要科学上网 ;ModelScope :阿里开源的大模型平台,模型不是很全,速度比较快;
HuggingFace的优点:
1. 丰富的预训练模型资源:
广泛的适用性:Hugging Face 提供了大量的预训练模型,这些模型已经在海量的数据上进行了训
练,能够处理各种自然语言处理任务,如文本分类、情感分析、问答、机器翻译等。无论您是从
事学术研究、商业应用还是个人项目开发,都可以找到适合的预训练模型,节省大量从头训练模
型的时间和资源。
高质量与不断更新:其预训练模型经过了专业的训练和优化,具有较高的性能和准确性。而且,
Hugging Face 平台不断更新和改进模型,以适应不断变化的自然语言处理需求和技术发展。
2. 方便的工具和库:
Transformers 库:Hugging Face 的 Transformers 库是自然语言处理领域的重要工具,它支持多
种预训练模型的加载、使用和微调,如 BERT、GPT、RoBERTa 等。该库提供了简单易用的接口,使得开发者可以轻松地将这些强大的模型集成到自己的项目中,快速实现自然语言处理功能3。
数据集管理工具:Hugging Face 提供了方便的数据集管理工具,如 Datasets 库,可以帮助用户轻
松地下载、处理和管理各种公开的数据集。这使得数据的准备工作变得更加高效,减少了数据处
理过程中的繁琐操作。
进入官网首页,如下图所示:

其主要包含:
Models(模型),包括各种处理CV和NLP等任务的模型,上面模型都是可以免费获得
Datasets(数据集),包括很多数据集
Spaces(分享空间),包括社区空间下最新的一些有意思的分享,可以理解为huggingface朋友圈
Docs(文档,各种模型算法文档),包括各种模型算法等说明使用文档
Solutions(解决方案,体验等),包括others
二、前置环境安装
anaconda集成环境安装
python3.10
在使用之前,需安装以下库:
注意:前三个需要写版本,否则会导致后期的版本不兼容问题
三、模型下载
这里我使用小模型给大家做演示,在models模型页面搜索 gpt2-chinese-cluecorpussmall
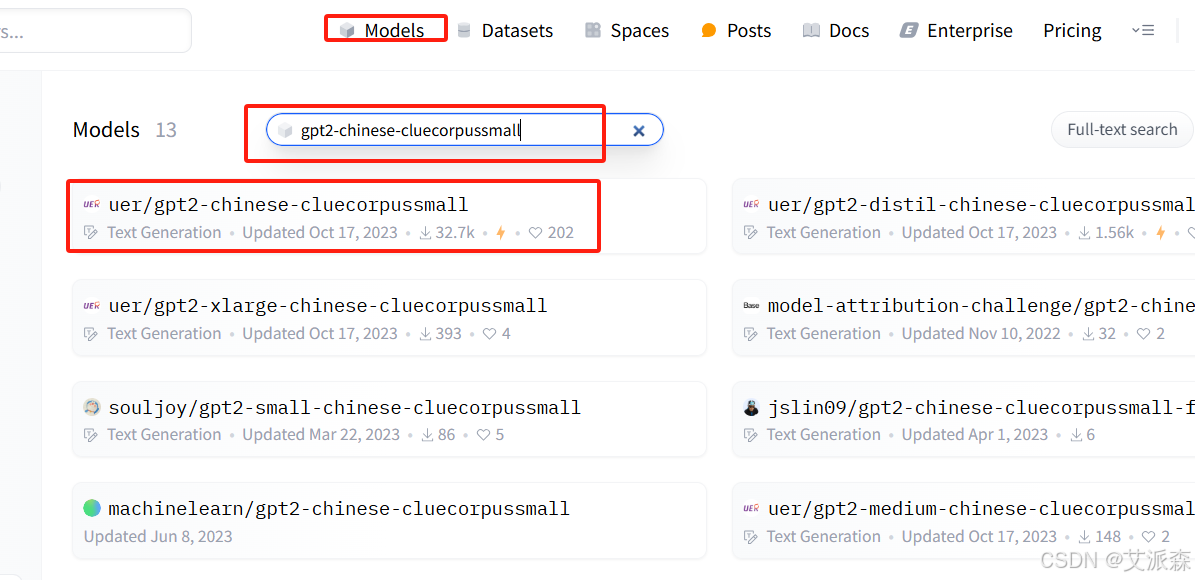
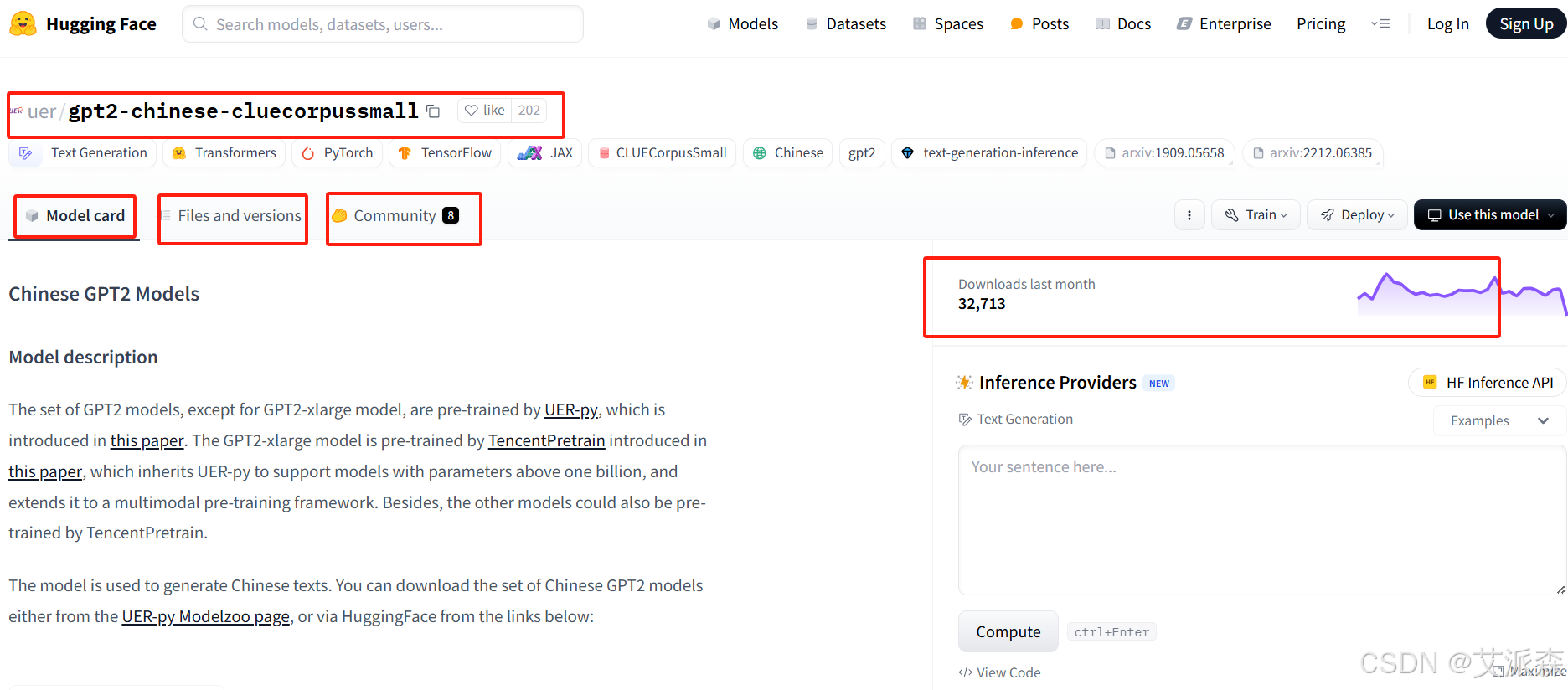
点进去之后可以看到该模型的介绍、文件代码、社区以及该模型的上个月下载量
下载到本地文件夹
首先复制模型的名字
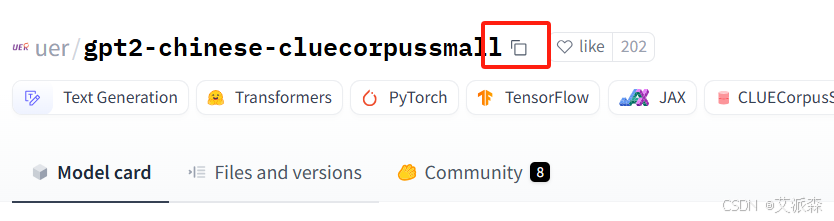
接着编写代码
import warnings
warnings.filterwarnings('ignore')
from transformers import AutoModel, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = r"D:\code\HugglingFace学习\model"
# 下载模型到本地
model = AutoModel.from_pretrained(model_name, cache_dir=cache_dir)
# 下载tokenizer分词器到本地
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
print("模型下载完成")代码中的model_name是复制模型的名字,cache_dir是模型下载的路径位置(绝对路径,自定义)
运行代码后如下图:
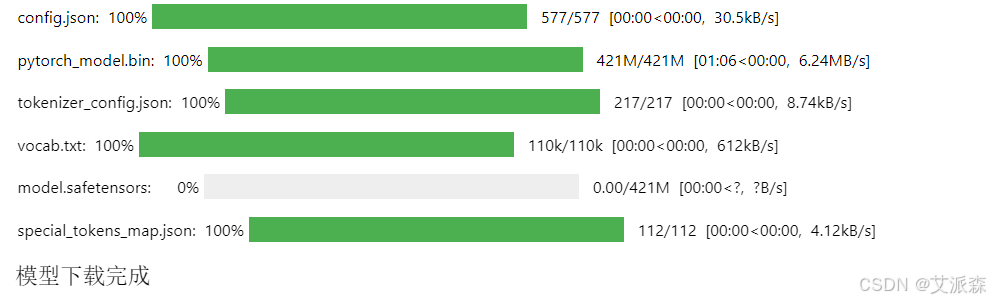
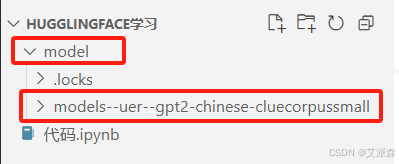
代码运行后会在同路径下生成一个model文件夹,里面存放的就是下载的模型文件。
四、模型加载测试
代码如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
# 使用绝对路径,否则会去先去huggingface下载
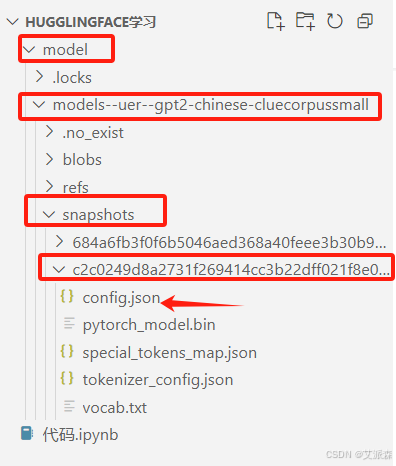
# 目录是包含config.json的目录
cache_dir = r"D:\code\HugglingFace学习\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3"
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(cache_dir)
tokenizer = AutoTokenizer.from_pretrained(cache_dir)
# 使用本地模型和分词器创建文本
generator = pipeline('text-generation', model=model, tokenizer=tokenizer,device="cpu")
output = generator("今天天气真好啊", max_length=50, num_return_sequences=1)
print(output)这里必须要注意模型的路径必须是绝对路径,同时该路径是包含config.json的目录
运行代码后结果如下:
[{'generated_text': '今天天气真好啊 于 是 就 到 这 里 去 玩 玩 了 。 有 种 说 不 出 的 感 觉 , 以 前 是 好 利 来 的 , 现 在 是 好 利 来 的 了 。 呵 呵 没 想'}]
可以看出生成的效果有点糟糕,那是因为我们没有进行调参
参数详解
output = generator(
"今天天气真好啊", #生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本
max_length=50, #指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)
num_return_sequences=1,#参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。
truncation=True,#该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。
temperature=0.7,#该参数控制生成文本的随机性。值越低,生成的文本越保守(倾向于选择概率较高的词);值越高,生成的文本越多样(倾向于选择更多不同的词)。0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。
top_k=50,#该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。这里top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。
top_p=0.9,#该参数(又称为核采样)进一步限制模型生成时的词汇选择范围。它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样。top_p=0.9 意味着模型会在可能性最强的90% 的词中选择下一个词,进一步增加生成的质量。
clean_up_tokenization_spaces=True#该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为False,因为它能更好地保留原始文本的格式。
)
print(output)调参之后重新运行代码结果如下:
[{'generated_text': '今天天气真好啊 快 下 班 了 , 朋 友 说 想 吃 韩 国 料 理 , 说 这 家 店 不 错 , 就 过 来 了 。 点 了 石 锅 拌 饭 , 味 道 很 好 , 量 也'}]
可以看出,调参后模型生成的效果还不错。
五、数据集下载
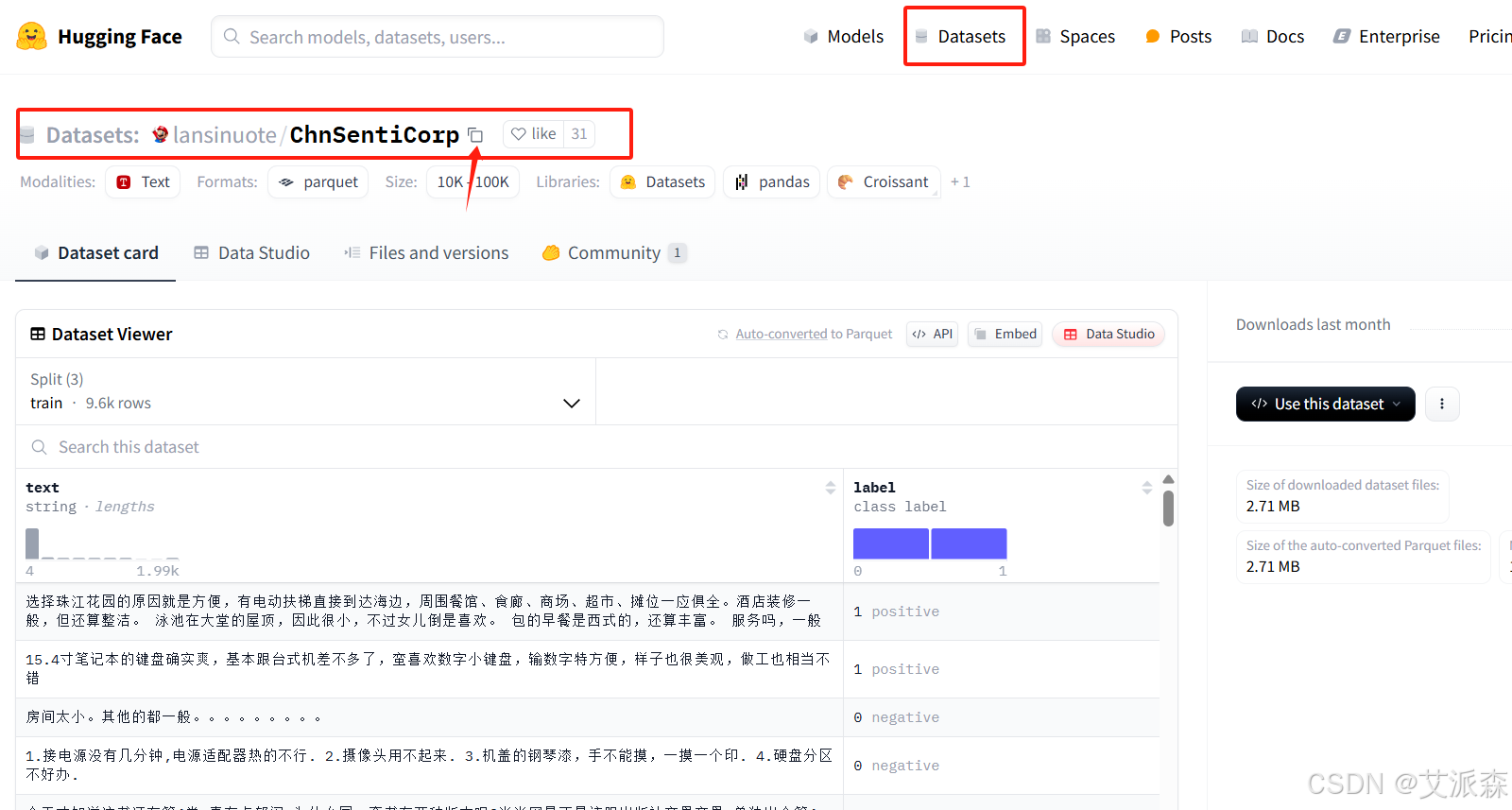
如果想下载平台中的数据集,这里我以“lansinuote/ChnSentiCorp”进行举例演示,首先还是复制数据集的名字
编写代码
from datasets import load_dataset
data_dir = r"D:\code\HugglingFace学习\datasets\ChnSentiCorp"
dataset = load_dataset("lansinuote/ChnSentiCorp", cache_dir=data_dir)
# 必须要执行本地保存, 直接缓存的数据集部满足本地磁盘加载的格式
dataset.save_to_disk(dataset_dict_path=data_dir)
print("数据集已保存在本地!")其中data_dir是数据集要下载的路径位置(绝对路径,自定义),load_dataset函数中的第一个参数就是刚复制的数据集的名字。
运行代码如下图:

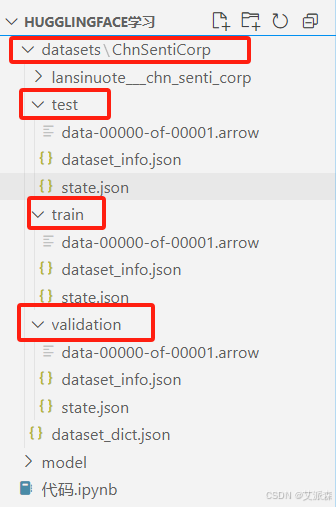
我们可以看到该数据集包含训练、测试、验证集,其中训练集有9600条数据,测试和验证集有1200条数据,同时在代码同路径下生成一个datasets文件夹存储 ChnSentiCorp 的数据,包括训练、测试、验证集。
接着我们可以打印输出训练集的数据看看
from datasets import load_from_disk
# 目录是包含dataset_dict.json的目录
dataset = load_from_disk(dataset_path=data_dir)
for data in dataset["train"]:
print(data)
打印测试集
for data in dataset["test"]:
print(data)
打印验证集
for data in dataset["validation"]:
print(data)
因为原始数据集是用json格式存储的数据,如果你想将数据保存为csv文件,比如将训练集存储为csv文件,执行下面的代码即可:
import csv
with open(r'D:\code\HugglingFace学习\datasets\ChnSentiCorp\train.csv','w',encoding='utf-8',newline='')as f:
cscwriter = csv.writer(f)
cscwriter.writerow(['text','label'])
for data in dataset["train"]:
cscwriter.writerow([data['text'],data['label']])如果你想将测试集与验证集也一起存储在同一个csv文件中,执行下面的代码即可:
import csv
with open(r'D:\code\HugglingFace学习\datasets\ChnSentiCorp\all_data.csv','w',encoding='utf-8',newline='')as f:
cscwriter = csv.writer(f)
cscwriter.writerow(['text','label'])
for data in dataset["train"]:
cscwriter.writerow([data['text'],data['label']])
for data in dataset["test"]:
cscwriter.writerow([data['text'],data['label']])
for data in dataset["validation"]:
cscwriter.writerow([data['text'],data['label']])
源代码
下载到本地文件夹
import warnings
warnings.filterwarnings('ignore')
from transformers import AutoModel, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = r"D:\code\HugglingFace学习\model"
# 下载模型到本地
model = AutoModel.from_pretrained(model_name, cache_dir=cache_dir)
# 下载tokenizer分词器到本地
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
print("模型下载完成")
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
# 使用绝对路径,否则会去先去huggingface下载
# 目录是包含config.json的目录
cache_dir = r"D:\code\HugglingFace学习\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3"
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(cache_dir)
tokenizer = AutoTokenizer.from_pretrained(cache_dir)
# 使用本地模型和分词器创建文本
generator = pipeline('text-generation', model=model, tokenizer=tokenizer,device="cpu")
output = generator("今天天气真好啊", max_length=50, num_return_sequences=1)
print(output)
参数详解
output = generator(
"今天天气真好啊", #生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本
max_length=50, #指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)
num_return_sequences=1,#参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。
truncation=True,#该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。
temperature=0.7,#该参数控制生成文本的随机性。值越低,生成的文本越保守(倾向于选择概率较高的词);值越高,生成的文本越多样(倾向于选择更多不同的词)。0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。
top_k=50,#该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。这里top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。
top_p=0.9,#该参数(又称为核采样)进一步限制模型生成时的词汇选择范围。它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样。top_p=0.9 意味着模型会在可能性最强的90% 的词中选择下一个词,进一步增加生成的质量。
clean_up_tokenization_spaces=True#该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为False,因为它能更好地保留原始文本的格式。
)
print(output)
数据集下载
from datasets import load_dataset
data_dir = r"D:\code\HugglingFace学习\datasets\ChnSentiCorp"
dataset = load_dataset("lansinuote/ChnSentiCorp", cache_dir=data_dir)
print(dataset)
# 必须要执行本地保存, 直接缓存的数据集部满足本地磁盘加载的格式
dataset.save_to_disk(dataset_dict_path=data_dir)
print("数据集已保存在本地!")
from datasets import load_from_disk
# 目录是包含dataset_dict.json的目录
dataset = load_from_disk(dataset_path=data_dir)
for data in dataset["train"]:
print(data)
for data in dataset["test"]:
print(data)
for data in dataset["validation"]:
print(data)
import csv
with open(r'D:\code\HugglingFace学习\datasets\ChnSentiCorp\train.csv','w',encoding='utf-8',newline='')as f:
cscwriter = csv.writer(f)
cscwriter.writerow(['text','label'])
for data in dataset["train"]:
cscwriter.writerow([data['text'],data['label']])
import csv
with open(r'D:\code\HugglingFace学习\datasets\ChnSentiCorp\all_data.csv','w',encoding='utf-8',newline='')as f:
cscwriter = csv.writer(f)
cscwriter.writerow(['text','label'])
for data in dataset["train"]:
cscwriter.writerow([data['text'],data['label']])
for data in dataset["test"]:
cscwriter.writerow([data['text'],data['label']])
for data in dataset["validation"]:
cscwriter.writerow([data['text'],data['label']])
资料获取,更多粉丝福利,关注下方公众号获取


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 57
57 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)