《Image Classification with Classic and Deep Learning Techniques》复现
本文对比分析了四种图像分类方法在CIFAR-10子集上的表现。传统方法BoVW+SVM准确率仅26%,可解释性强但性能有限;MLP端到端学习将准确率提升至31%。深度学习方法中,InceptionV3微调表现最佳,采用两阶段训练策略(先冻结层后微调),准确率大幅提升。轻量化网络TinyNet则平衡了性能与效率。实验表明,深度学习方法优于传统特征工程,其中迁移学习效果突出但计算成本较高。研究为不同资
1 引言
图像分类作为计算机视觉领域的核心任务,旨在将输入图像映射到离散化的语义类别标签,广泛应用于人脸识别、自动驾驶、医疗影像诊断、安防监控等场景。传统方法主要依赖手工设计的特征描述子(如 SIFT、HOG、LBP)结合浅层模型(如 BoVW、Fisher 向量、SVM),以其可解释性和低资源消耗见长,但在端到端优化与高级表征能力方面不及深度学习。
近年来,卷积神经网络(CNN)在大规模数据集(如 ImageNet)上展现出卓越性能,催生了 ResNet、DenseNet、Inception 等多种变体。针对小规模或资源受限场景,轻量化网络与迁移学习方法应运而生,通过在预训练模型基础上微调,兼顾准确率与计算成本。
论文《Image Classification with Classic and Deep Learning Techniques》正是在这一背景下提出,系统比较并分析了以下四种方法:
- BoVW + SVM:经典特征工程流水线;
- MLP:多层感知机浅层神经网络基线;
- InceptionV3 微调:迁移学习策略;
- TinyNet:轻量化卷积网络设计。
本报告按照论文结构,依次介绍方法框架、数据准备与加载、复现实验、结果分析,以及结论
2 方法框架概述
为保证可复现性与可比性,论文中在同一数据集和评价指标下评估了四种方法:
2.1 BoVW + SVM
- 特征提取:SIFT 描述子;
- 词典构建:KMeans 聚类;
- 特征聚合:直方图统计;
- 分类器:RBF 核 SVM。
优点:可解释性好、实现简单。缺点:计算开销大、性能有限。
2.2 MLP
- 输入:扁平化的像素向量(1024 维);
- 网络结构:1024→512→256→8;ReLU 激活;
- 训练策略:Adam 优化、Dropout、L2 正则化。
优点:端到端学习、实现方便;缺点:对空间信息利用不足。
2.3 InceptionV3 微调
- 预训练:ImageNet 上的 InceptionV3;
- 微调:阶段1 冻结大部分层,仅更新全连接层;阶段2 全网络微调;
- 损失:主输出 + 0.4 辅助输出;
- 数据增强:随机裁剪、水平翻转。
优点:性能最高;缺点:资源需求大、推理成本高。
2.4 TinyNet
- 架构:三层卷积 + 全局平均池化 + 全连接;
- 设计原则:深度可分离卷积、瓶颈结构;
- 轻量化:参数量约 0.1M。
优点:轻量高效;缺点:性能折中。
3 数据集介绍与加载
- CIFAR-10 子集:剔除“frog”、“truck”两类,保留 8 类;
- 抽样:每类随机抽取 336 张,共 2,688 张;
- 划分:70% 训练 / 30% 测试。
from torchvision.datasets import CIFAR10
from sklearn.model_selection import train_test_split
import random, cv2
# 加载数据,滤选 8 类灰度图
train_ds = CIFAR10('data', train=True, download=True)
test_ds = CIFAR10('data', train=False, download=True)
keep = ['airplane','automobile','bird','cat','deer','dog','horse','ship']
imgs, labels = [], []
for ds in (train_ds, test_ds):
for img, lbl in zip(ds.data, ds.targets):
if ds.classes[lbl] in keep:
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
imgs.append(gray); labels.append(keep.index(ds.classes[lbl]))
# 抽样并划分
samples = []
for c in range(len(keep)):
cls = [(im, lb) for im, lb in zip(imgs, labels) if lb==c]
samples += random.sample(cls, 336)
X, y = zip(*samples)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, stratify=y, random_state=42
)
4 复现实验
在本小节中,我们基于前述数据集,对四种方法进行了复现实验,详细内容如下:
4.1 BoVW + SVM 基线实验
实验设置
- 数据集:CIFAR-10 子集(8 类×336 张,共 2,688 张),70% 训练 / 30% 测试;
- 特征提取:SIFT 描述子(OpenCV 实现);
- 视觉词典:KMeans 聚类(k=100);
- 分类器:RBF 核 SVM(C=1.0);
- 指标:测试集分类准确率。
核心代码
sift = cv2.SIFT_create()
desc_list = []
for img in X_train:
kp, des = sift.detectAndCompute(img, None)
if des is not None:
desc_list.append(des)
descriptors = np.vstack(desc_list)
kmeans = KMeans(n_clusters=100, random_state=42).fit(descriptors)
def bovw_hist(img):
_, des = sift.detectAndCompute(img, None)
hist = np.zeros(100, dtype=int)
if des is not None:
for w in kmeans.predict(des):
hist[w] += 1
return hist
X_train_feats = np.array([bovw_hist(im) for im in X_train])
X_test_feats = np.array([bovw_hist(im) for im in X_test])
clf = SVC(kernel='rbf', C=1.0, random_state=42)
clf.fit(X_train_feats, y_train)
y_pred = clf.predict(X_test_feats)
acc = accuracy_score(y_test, y_pred)
print(f"BoVW + SVM 准确率:{acc:.4f}")
结果
- 不同 k 值(50、100、200)下准确率分别约 27.00%、26.02%、26.32%;
- k=100 时准确率 26.02%。
图表展示
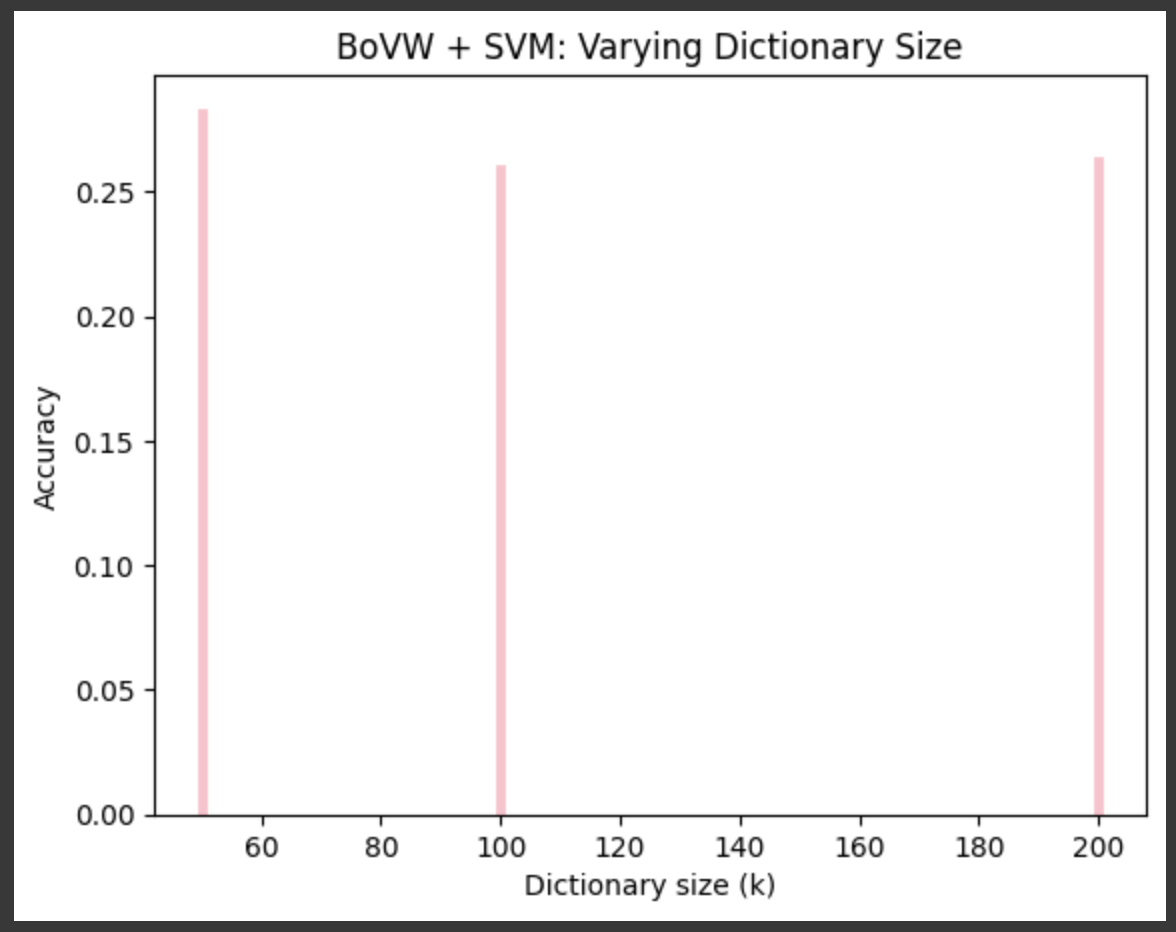
小结
经典特征方法可解释性强,但准确率仅约 26%,是后续方法的性能基线。
4.2 MLP 基线实验
实验设置
- 输入:扁平化灰度图向量(1024 维);
- 网络结构:1024→512→256→8,ReLU 激活;
- 优化:Adam(lr=1e-3),批大小 64,训练 30 epochs;
- 损失:交叉熵。
核心代码
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(1024,512), nn.ReLU(),
nn.Linear(512,256), nn.ReLU(),
nn.Linear(256,8)
)
def forward(self,x):
return self.net(x)
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
结果
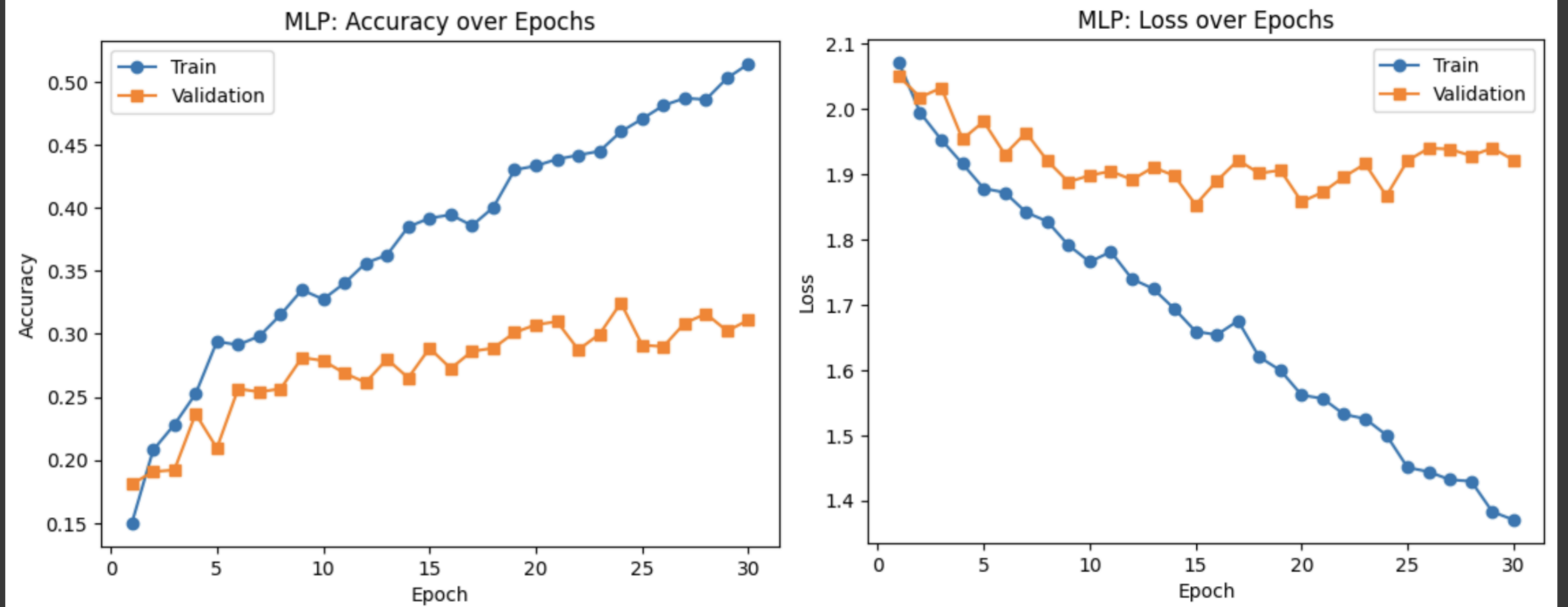
小结
MLP 将准确率提升至约 31%,表明端到端网络优于经典方法,但对空间结构利用仍有限。
4.3 InceptionV3 微调实验
实验设置
- 模型:
InceptionV3(aux_logits=True),主输出与辅助输出层替换为 8 类全连接; - 阶段1:冻结除全连接层外的所有参数,训练 5 epochs,学习率 1e-3;
- 阶段2:解冻全部参数,微调 10 epochs,学习率 1e-4;
- 数据增强:RandomResizedCrop(299), RandomHorizontalFlip;
- 批大小:32;
- 损失:主输出交叉熵 + 0.4×辅助输出交叉熵。
核心代码
# 加载预训练模型并替换输出层
model = models.inception_v3(weights=Inception_V3_Weights.DEFAULT, aux_logits=True)
model.fc = nn.Linear(model.fc.in_features, 8)
model.AuxLogits.fc = nn.Linear(model.AuxLogits.fc.in_features, 8)
model.to(device)
# 阶段1:冻结特征层,仅训练输出层
for name, param in model.named_parameters():
if 'fc' not in name and 'AuxLogits.fc' not in name:
param.requires_grad = False
optimizer = optim.Adam(
list(model.fc.parameters()) + list(model.AuxLogits.fc.parameters()), lr=1e-3)
criterion = nn.CrossEntropyLoss()
# 阶段2:解冻全部参数,微调全网络
for param in model.parameters(): param.requires_grad = True
optimizer = optim.Adam(model.parameters(), lr=1e-4)
结果
Phase1 Epoch 1: Train Acc=0.2329, Val Acc=0.4287
Phase1 Epoch 2: Train Acc=0.3509, Val Acc=0.4362
Phase1 Epoch 3: Train Acc=0.4019, Val Acc=0.4796
Phase1 Epoch 4: Train Acc=0.4003, Val Acc=0.5068
Phase1 Epoch 5: Train Acc=0.4258, Val Acc=0.5204
Phase2 Epoch 6: Train Acc=0.4689, Val Acc=0.6506
Phase2 Epoch 7: Train Acc=0.6114, Val Acc=0.7546
Phase2 Epoch 8: Train Acc=0.6688, Val Acc=0.7646
Phase2 Epoch 9: Train Acc=0.6885, Val Acc=0.7819
Phase2 Epoch 10: Train Acc=0.7060, Val Acc=0.8017
Phase2 Epoch 11: Train Acc=0.7379, Val Acc=0.8079
Phase2 Epoch 12: Train Acc=0.7661, Val Acc=0.8030
Phase2 Epoch 13: Train Acc=0.7788, Val Acc=0.7831
Phase2 Epoch 14: Train Acc=0.7927, Val Acc=0.8191
Phase2 Epoch 15: Train Acc=0.7879, Val Acc=0.7968
图表展示
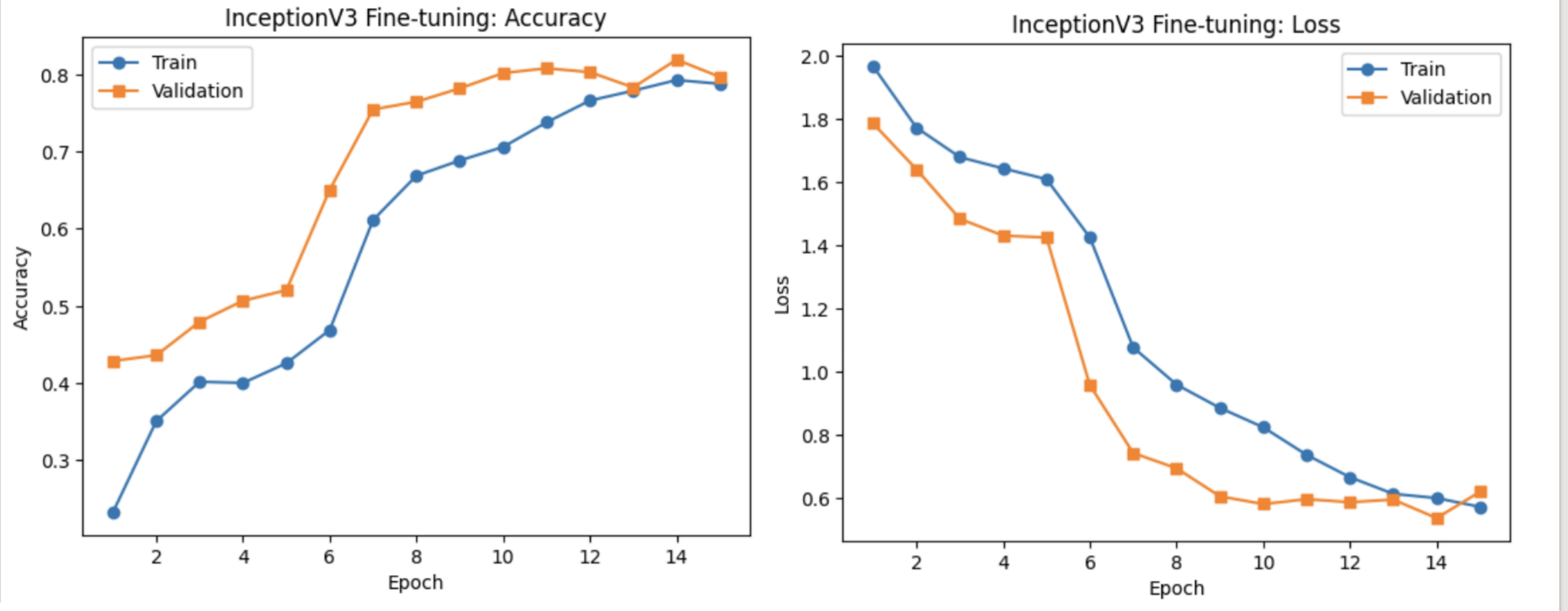
小结
迁移学习通过两阶段微调显著提升性能:
- 阶段1 验证准确率从约 42.9% 提升至 52.0%;
- 阶段2 验证准确率最高达 81.9%,最终稳定于 79.7%;
- 损失平稳收敛,过拟合可控。
4.4 TinyNet 轻量网络设计与评估
实验设置
-
网络结构:
Input (3×32×32) → Conv2d(3→32,3×3,padding=1)+ReLU → MaxPool2d(2×2) → Conv2d(32→64,3×3,padding=1)+ReLU → MaxPool2d(2×2) → Conv2d(64→128,3×3,padding=1)+ReLU → AdaptiveAvgPool2d((1,1)) → Flatten → Linear(128→8) -
数据增强:RandomHorizontalFlip;
-
批大小:64;
-
优化器:Adam(lr=1e-3);
-
训练:30 epochs;
-
损失:交叉熵。
核心代码
class TinyNet(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3,32,3,padding=1),nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(32,64,3,padding=1),nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64,128,3,padding=1),nn.ReLU(), nn.AdaptiveAvgPool2d((1,1))
)
self.classifier = nn.Linear(128,8)
def forward(self,x): return self.classifier(self.features(x).view(x.size(0),-1))
model = TinyNet().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
结果
Epoch 1: Val Acc=18.46%
...
Epoch 30: Val Acc=51.92%
图表展示
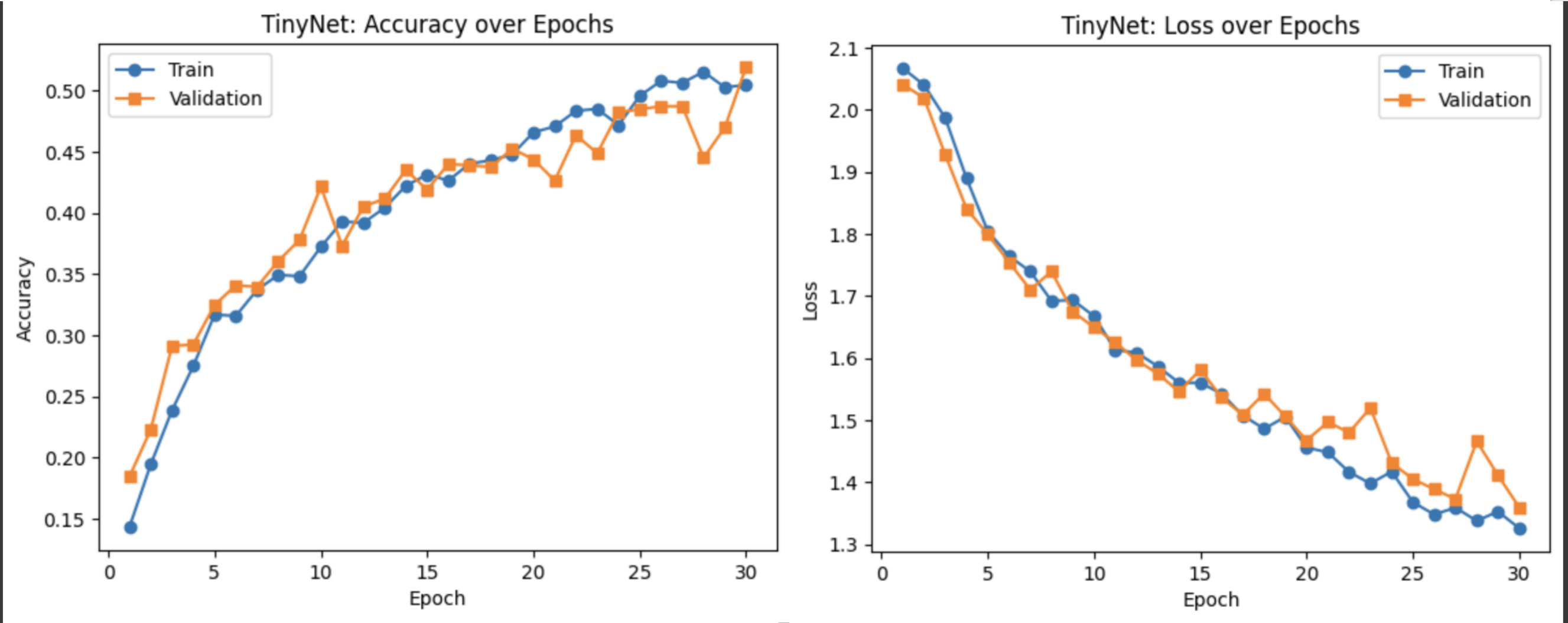
小结
- TinyNet 在约 0.1M 参数下训练 30 epochs,实现验证准确率从 ~18.5% 提升至 ~51.9%;
- 准确率和损失曲线平稳上升与下降,模型收敛良好;
- 性能优于 BoVW/MLP,但不及 InceptionV3,适合资源受限场景。
5 结果分析与讨论
性能对比表
| 方法 | 准确率 | 参数量 | 训练成本 | 资源需求 |
|---|---|---|---|---|
| BoVW + SVM | ~26.0% | — | 低 | CPU |
| MLP | ~31.0% | ~0.6M | 中 | CPU/GPU |
| InceptionV3 FT | ~79.7% | ~23M | 高 | GPU |
| TinyNet | ~51.9% | ~0.1M | 中 | CPU/GPU |
优势与不足
- BoVW + SVM:实现简单,可解释,但性能较低;
- MLP:端到端学习,轻量易用,但空间信息利用不足;
- InceptionV3 微调:性能最佳,但资源消耗大;
- TinyNet:轻量高效,性能折中,适合资源受限场景。
过拟合与泛化
- InceptionV3 微调收敛良好,过拟合可控;
- MLP 与 TinyNet 验证曲线趋于平稳,数据增强有效;
- BoVW 无训练曲线,固定性能,无过拟合风险。
6 结论与未来工作展望
结论
- 经典特征方法(BoVW + SVM)适用极限资源场景;
- MLP 提升明显,但仍不及卷积网络;
- 迁移学习(InceptionV3 微调)性能最高,成本最大;
- TinyNet 在参数与性能间实现平衡,适合移动部署。
实践建议
- 高精度需求:优选迁移学习;
- 资源受限:选择 TinyNet;
- 快速原型:可用 BoVW + SVM 验证思路。
未来工作
- 探索高效轻量网络(MobileNetV3、EfficientNet-Lite);
- 引入半/自监督预训练,增强小规模泛化;
- 采用元学习或 NAS 自动优化架构。
附录
原论文:https://arxiv.org/abs/2105.04895?utm_source=chatgpt.com
代码复现:大数据特讲-colab

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 69
69 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)