【AI大模型】Elasticsearch9 + 通义大模型实现语义检索操作详解
Elasticsearch9 + 通义大模型实现语义检索操作详解
目录
一、前言
语义检索是指能够理解查询意图和文档含义的搜索技术,而不仅仅是关键词匹配。它通过自然语言处理(NLP)和机器学习技术理解查询和文档的语义上下文。ES9(Elasticsearch 9)是 Elasticsearch 搜索引擎的一个重要版本,它在语义检索(Semantic Search)方面引入了多项重要改进,使搜索更加智能化和语义化。本文将详细介绍 Elasticsearch 9 的语义检索特性、工作原理,并通过实际测试示例展示如何使用这些新功能。
二、Elasticsearch9 语义检索介绍
Elasticsearch 9.0 在语义搜索领域带来了重大升级,通过原生支持 semantic_text 字段类型、改进的查询方式以及与向量搜索的深度整合,为用户提供了更强大、更灵活的语义检索能力。

2.1 ES9 语义检索核心特性
ES9 语义检索具有如下核心特性:
-
原生向量搜索支持
-
内置向量数据库功能,无需额外插件
-
支持高效的近似最近邻(ANN)搜索
-
与传统的倒排索引无缝集成
-
-
改进文本嵌入集成
-
简化了嵌入模型(如BERT、GPT等)的集成流程
-
支持实时嵌入计算和索引
-
提供预训练模型的管理功能
-
-
混合检索模式
-
结合关键词搜索(BM25)和向量搜索的优势
-
可配置的混合评分机制
-
支持结果重排序(reranking)
-
-
增强NLP处理
-
内置更先进的文本分词和分析器
-
改进的同义词和语义扩展功能
-
更好的多语言支持
-
-
查询方式扩展
-
原生 semantic 查询:专为语义搜索设计的简洁查询语法
-
match 查询支持:现在 match 查询也可用于 semantic_text 字段,提供更熟悉的查询体验
-
knn 查询支持:可直接对 semantic_text 字段执行近似最近邻搜索
-
sparse_vector 查询:支持稀疏向量搜索技术
-
2.2 semantic_text 字段类型说明
ES 9 引入了 semantic_text 字段类型,这是一种专为语义搜索设计的字段类型,能够自动处理文本的向量化表示。与传统的 text 字段不同,semantic_text 字段在索引时会自动通过配置的推理模型将文本转换为向量表示,而无需用户手动处理向量转换过程。其关键优势如下:
-
开箱即用:
-
只需配置推理端点,无需手动管理向量转换过程
-
-
透明处理:
-
自动处理文本扩展和向量化,对用户完全透明
-
-
混合搜索:
-
可与传统关键词搜索(BM25)结合使用,提升搜索结果相关性
-
2.3 ES9 语义检索原理
ES9 语义搜索基于文本扩展(text expansion)技术,其核心工作流程如下:
-
数据存储向量化:将写入索引的数据进行向量化存储
-
查询扩展:将用户查询输入通过推理模型扩展为包含相关术语的扩展查询
-
向量转换:将扩展后的查询转换为向量表示(密集或稀疏向量)
-
相似度计算:计算查询向量与文档向量的相似度
-
结果排序:根据相似度得分对结果进行排序
与传统基于关键词搜索相比,语义搜索能够理解查询的意图和上下文,而不仅是匹配字面词汇。例如,搜索"自新媒体运营"可以匹配到包含与新媒体语义相近的的文档,即使文档中没有出现新媒体这个词。
2.4 ES9 语义检索优势与使用场景
语义检索在实际应用中是独具优势的,具体来说:
-
更精准的搜索结果:理解用户查询的真实意图
-
自然语言查询:支持问答式搜索和复杂查询
-
推荐系统:基于内容相似性的推荐
-
跨语言搜索:不同语言间的语义匹配
ES9的语义检索功能特别适用于需要理解内容语义的场景,如知识库搜索、电子商务产品搜索、内容推荐系统等。结合大模型,可以让语义检索发挥更强的作用。
三、 Elasticsearch9 搭建过程
为了后面使用和验证Elasticsearch9的语义检索特性,需要搭建Es9,接下来介绍2种基于docker安装Elasticsearch9的方式。
3.1 环境说明
请提前准备下面的环境
- 云服务器或虚拟机,至少2C4G;
- docker环境,版本不要太低;
3.2 部署方式一
3.2.1 创建docker网络
使用下面的命令创建一个docker 网络
docker network create elastic
3.2.2 获取es9镜像
使用下面的命令拉取es9镜像
docker pull elasticsearch:9.0.1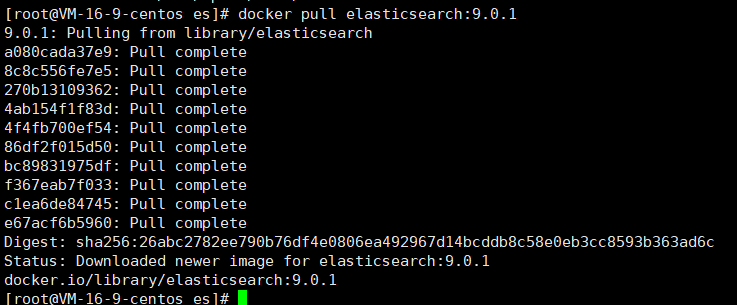
3.2.3 启动 es容器
使用下面的命令启动一个es容器
-
注意,如果你的服务器内存不足,建议启动容器的时候在参数中限制一下容器占用的内存大小
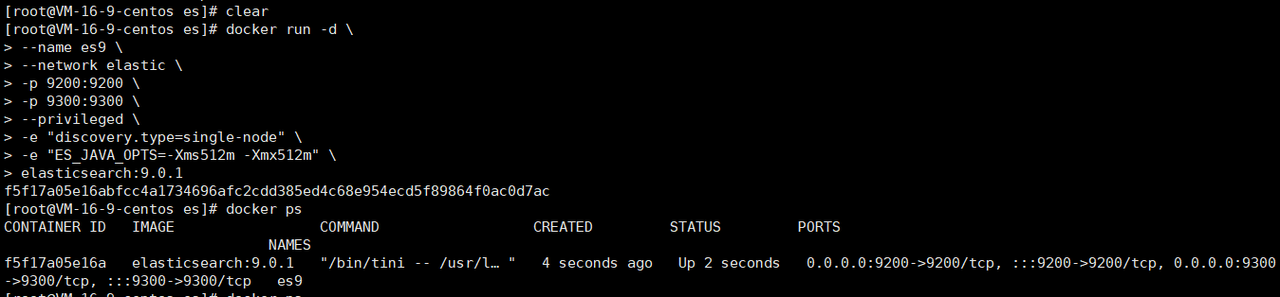
docker run -d \
--name es9 \
--network elastic \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:9.0.1容器启动成功后,使用docker ps 命令检查一下
3.2.4 启动kibana容器
为了后续操作es索引数据方便,这里使用es的可视化操作工具kibana,下面使用下面的命令启动kibana容器
docker run -d \
--name kibana_09 \
--network elastic \
-p 5601:5601 \
--privileged \
kibana:9.0.1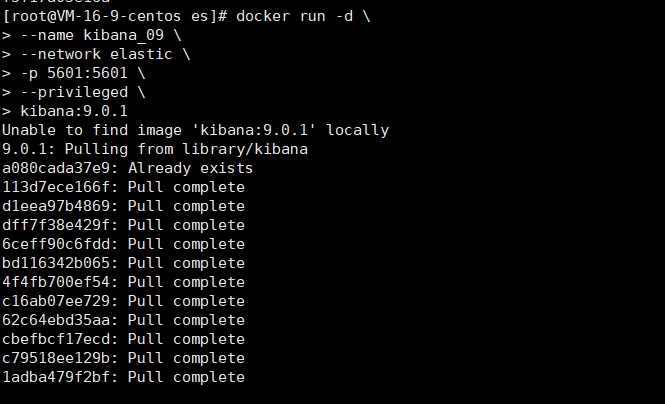
使用docker ps命令检查是否启动成功

3.2.5 创建es访问账户和密码
为了确保es的数据安全,默认情况下,es开启了数据安全访问测试,在yml配置文件中可以看到
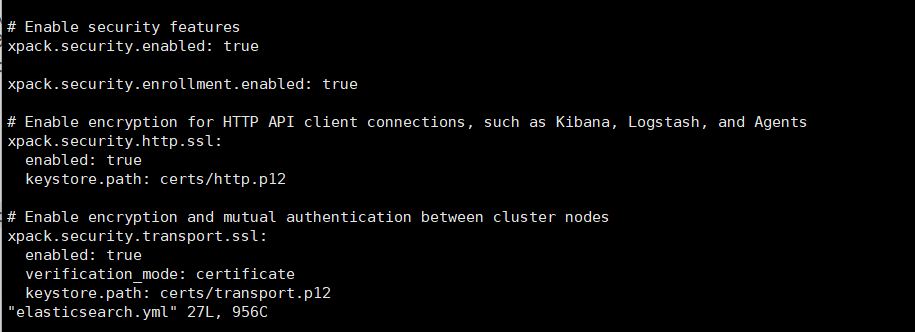
使用下面的命令创建一个账户和密码,输入命令之后,在最后会随机生成一个密码,注意妥善保管
docker exec -it es9 /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic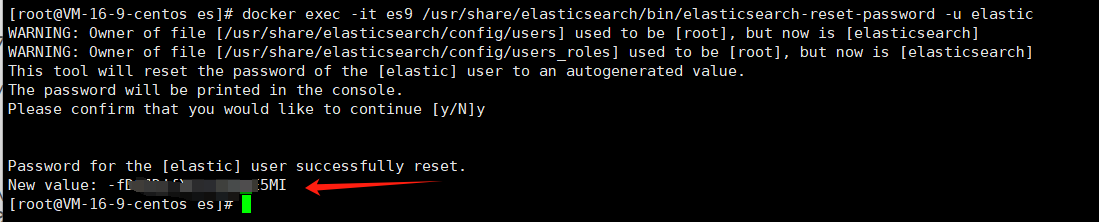
3.2.6 为kibana创建访问es 的token令牌
还记得在使用kibana操作es的时候,在kibana中需要设置连接es的IP,端口等信息,在这里需要为kibana设置一个访问的token令牌,参考下面的命令
docker exec -it es9 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana执行之后稍等一会,就会生成一长串token字符串,后续在kibana访问的时候会用到,请注意妥善保管

3.2.6 生成访问kibana的验证码
这么做的目的还是为了访问数据的安全考虑,执行下面的命令,生成验证码
docker exec kibana_09 /usr/share/kibana/bin/kibana-verification-code
3.2.7 访问kibana
输入 IP:5601 ,访问kibana控制台
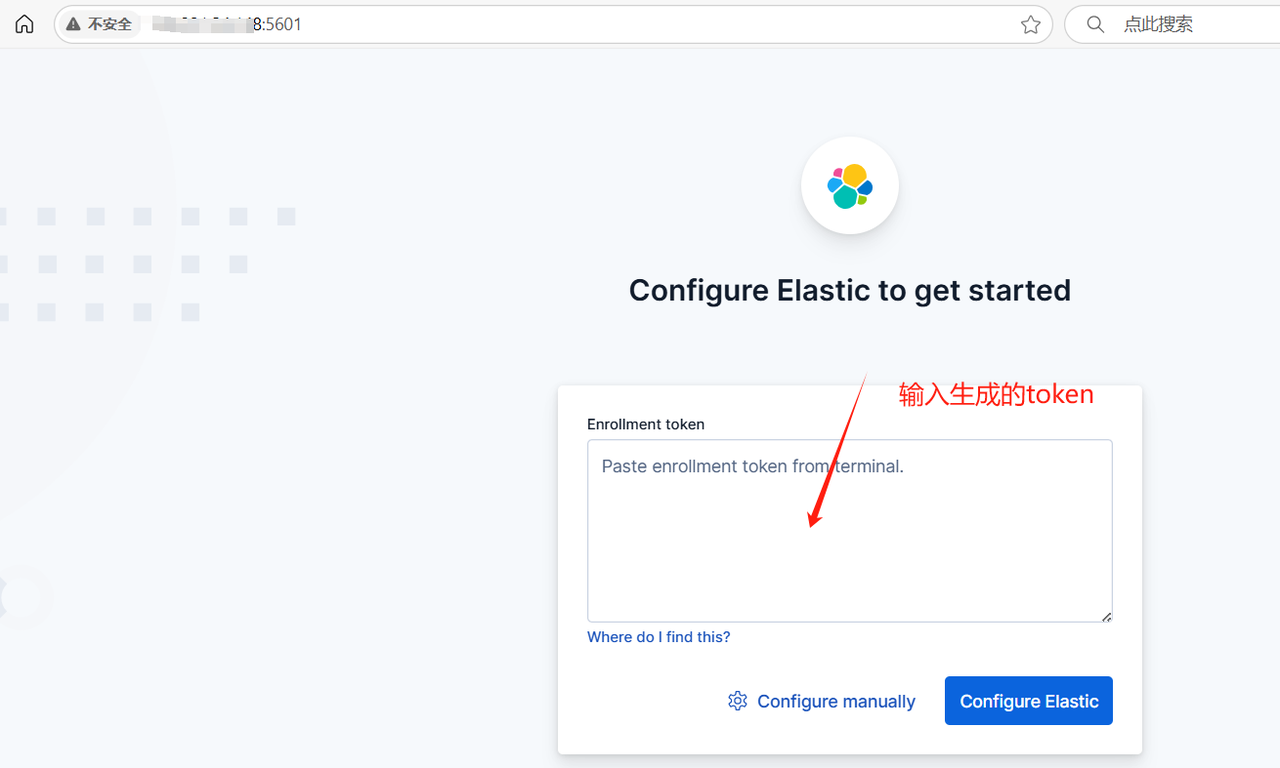
将前面生成的token粘贴到输入框,跳转到下面的界面后,再将生成的验证码输入进去
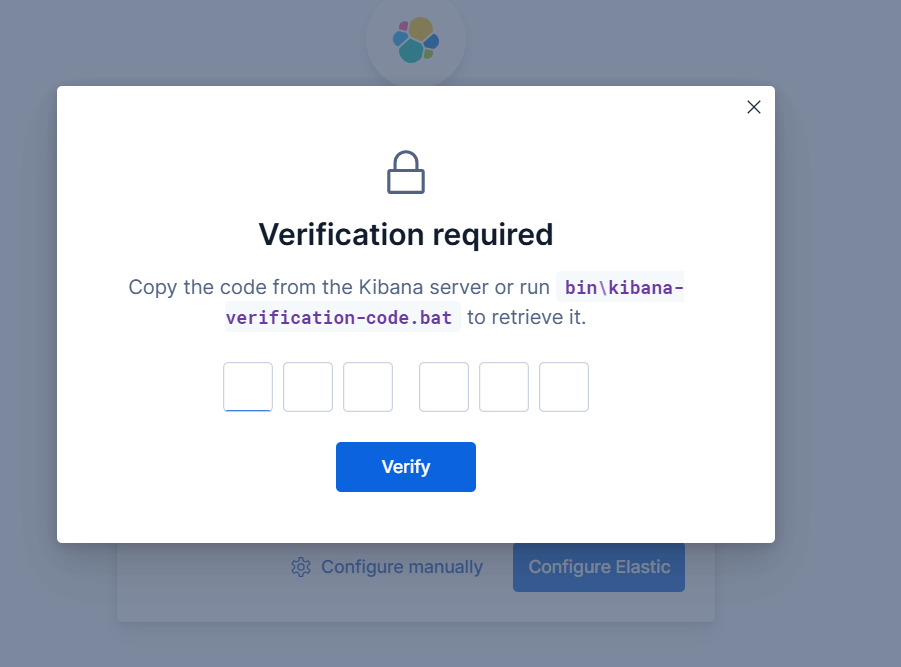
验证成功后,跳转到下面的页面进行初始化相关的设置
初始化完成后跳转到下面的登录界面,输入前面设置的账户和密码进行登录
登录成功后,就来到下面熟悉的界面了
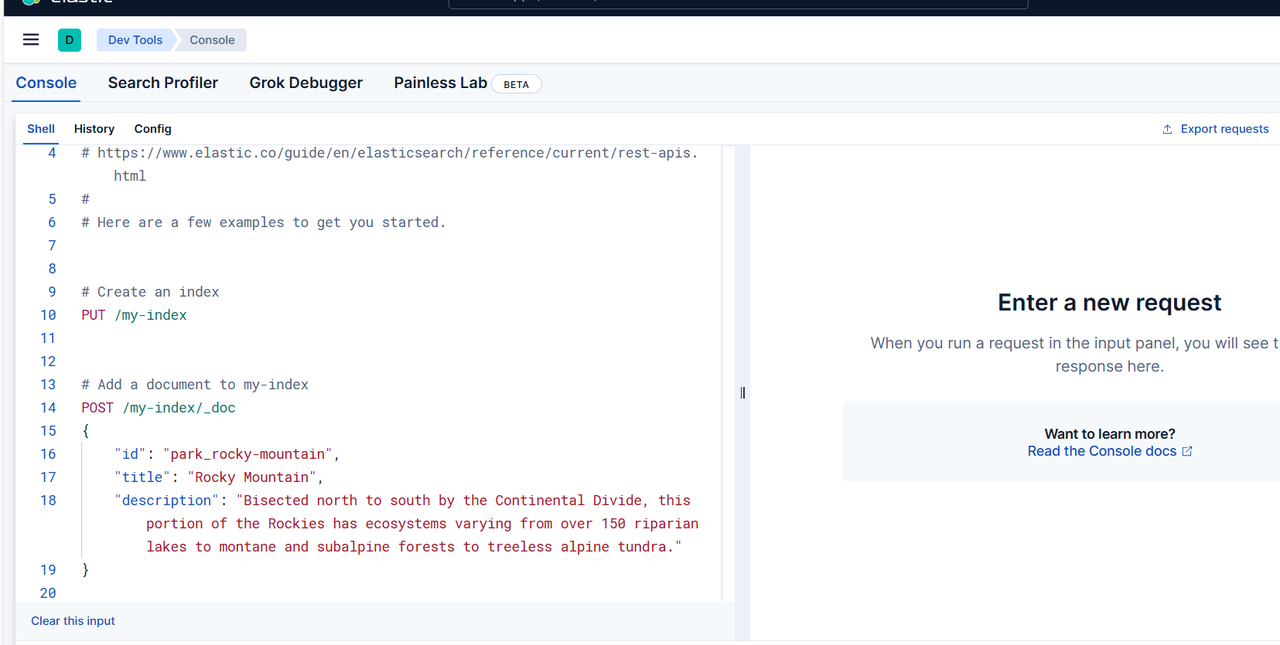
点击左侧的Dev Tools菜单,就到了熟悉的界面,在这个界面就可以操作ES相关的命令了
3.3 部署方式二
下面介绍第二种部署方式
3.3.1 初次启动es容器
使用下面的命令启动容器
docker run -d \
--name es9 \
--network elastic \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:9.0.1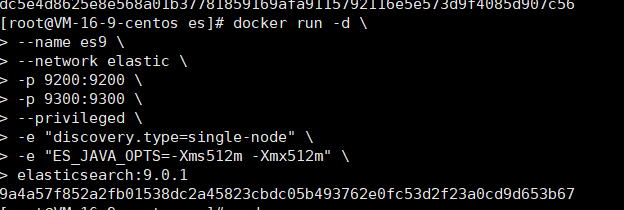
3.3.2 拷贝容器内部的文件
将容器内部的文件拷贝出来后面使用
docker cp es9:/usr/share/elasticsearch/data /usr/local/soft/es
docker cp es9:/usr/share/elasticsearch/plugins /usr/local/soft/es
docker cp es9:/usr/share/elasticsearch/config /usr/local/soft/es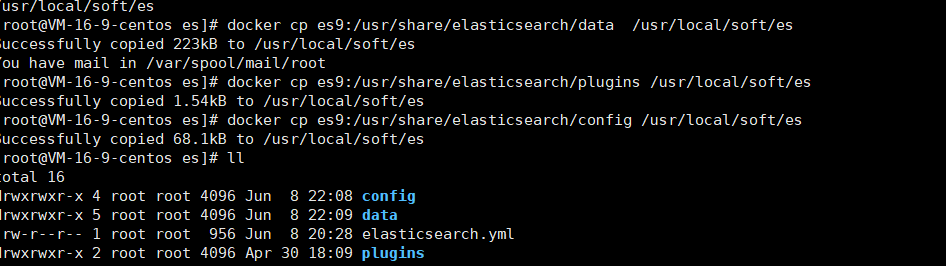
3.3.3 文件授权
后续会用到
chmod 777 -R config/ data/ plugins/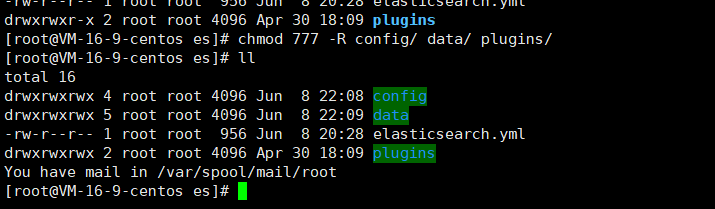
3.3.4 移除镜像
使用下面的命令移除镜像
docker stop es9 && docker rm es9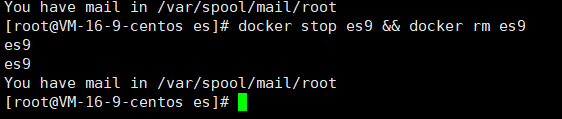
3.3.5 重启es容器
执行下面的命令重启es
docker run -d \
--name es9 \
--network elastic \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /usr/local/soft/es/data:/usr/share/elasticsearch/data \
-v /usr/local/soft/es/plugins:/usr/share/elasticsearch/plugins \
-v /usr/local/soft/es/config:/usr/share/elasticsearch/config \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:9.0.1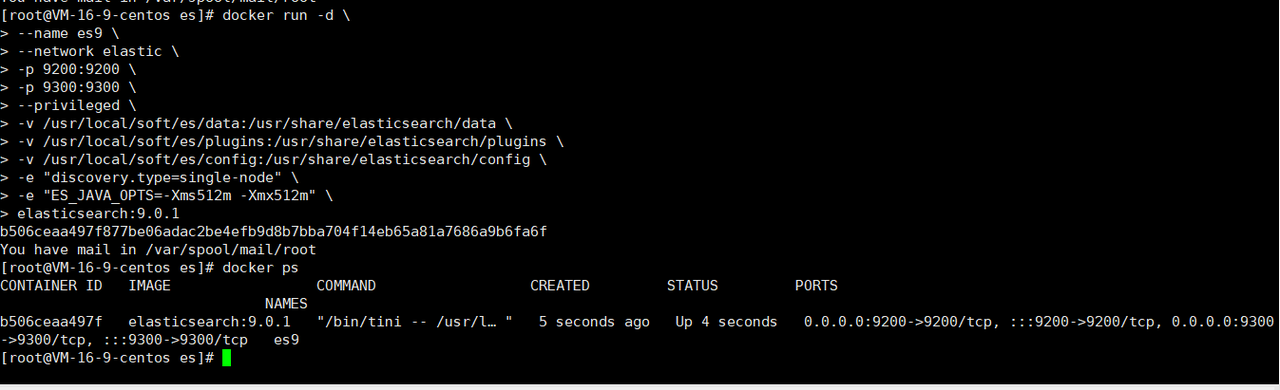
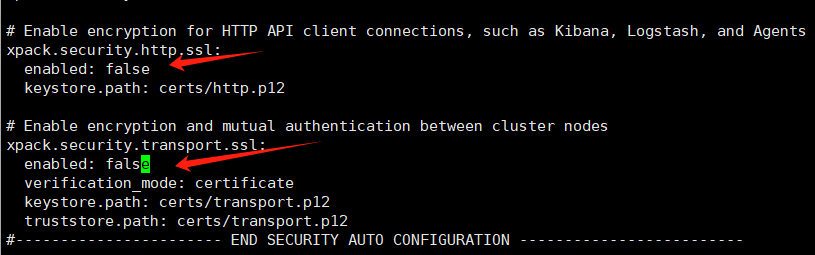
3.3.6 修改es配置参数
在挂载目录中修改yml配置,调整下面的参数,调整完毕后注意重启es容器
3.3.7 启动kibana容器
使用下面的命令启动kibana容器
docker run -d \
--name kibana \
--network elastic \
-p 5601:5601 \
--privileged \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
kibana:9.0.1
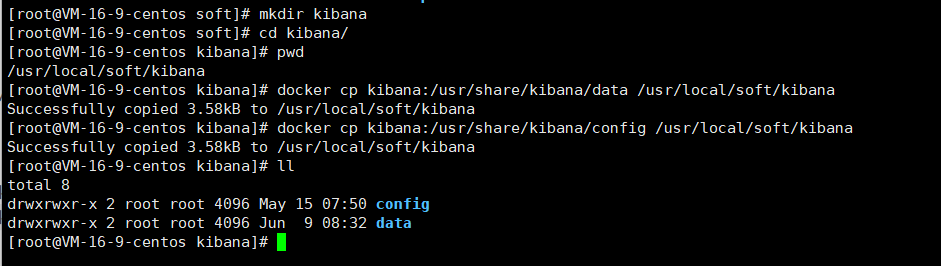
3.3.8 拷贝容器内的文件
将容器内的文件拷贝出来
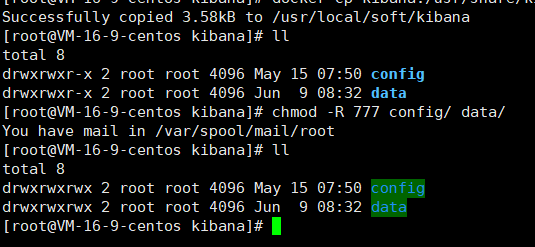
3.3.9 文件目录授权
为确保后续访问权限,给文件做下授权
然后移除容器
docker stop kibana && docker rm kibana
3.3.10 创建kibana账户
创建为kibana创建新账户,用于访问elasticsearch,容器内 /usr/share/elasticsearch/bin 目录下
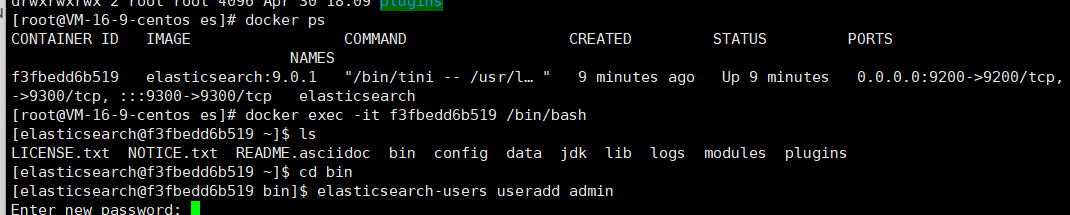
对账户授权(123456)

3.3.11 修改容器外挂载目录中的kibana.yml
在yml中新增下面的配置
xpack.screenshotting.browser.chromium.disableSandbox: true
elasticsearch.username: admin
elasticsearch.password: 123456
3.3.12 重启kibana容器
使用下面的命令重启容器
docker run -d \
--name kibana \
--network elastic \
-p 5601:5601 \
--privileged \
-v /usr/local/soft/kibana/data:/usr/share/kibana/data \
-v /usr/local/soft/kibana/config:/usr/share/kibana/config \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
kibana:9.0.1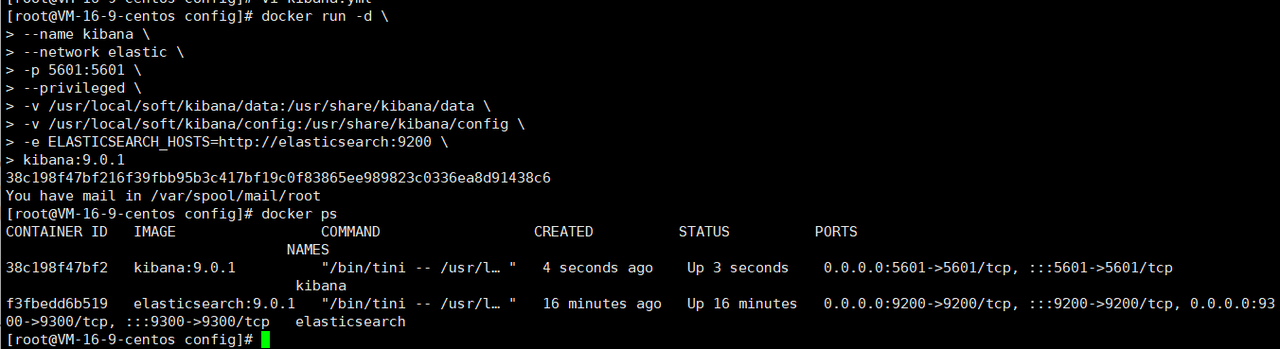
四、ES9 英文语义检索操作过程
Elasticsearch 提供了开箱即用的 ELSER(Elastic Learned Sparse Encoder)模型,适合英文语义搜索。对于中文,可以使用阿里云的稀疏向量模型。
4.1 英文语义检索操作案例
4.1.1 创建索引
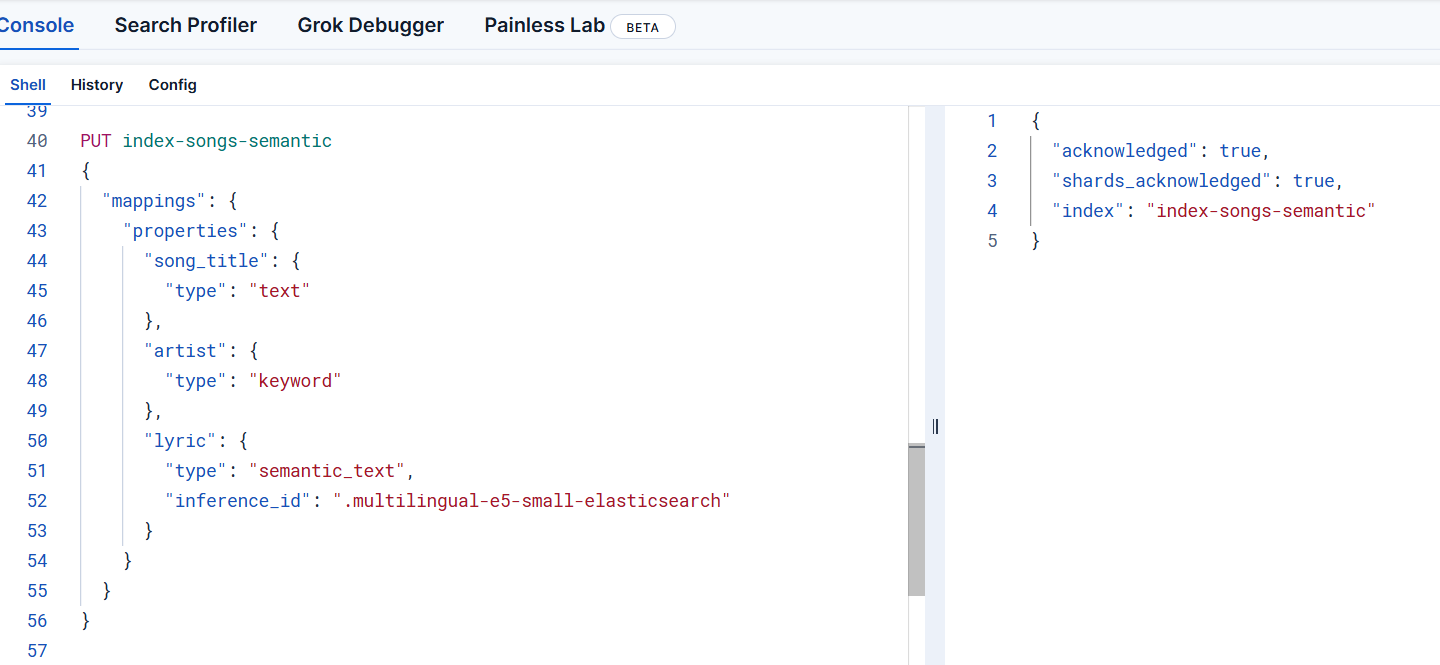
执行下面的命令创建一个索引
PUT index-songs-semantic
{
"mappings": {
"properties": {
"song_title": {
"type": "text"
},
"artist": {
"type": "keyword"
},
"lyric": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
}
}看到右侧的执行成功说明索引已创建
如果后续待检索的文档中有中文,可以使用阿里云的大模型,参考下面的命令设置
- 需要提前配置好与阿里云向量模型的授权,后文中会有说明
PUT alibaba_sparse
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": "alibabacloud_ai_search_sparse"
}
}
}
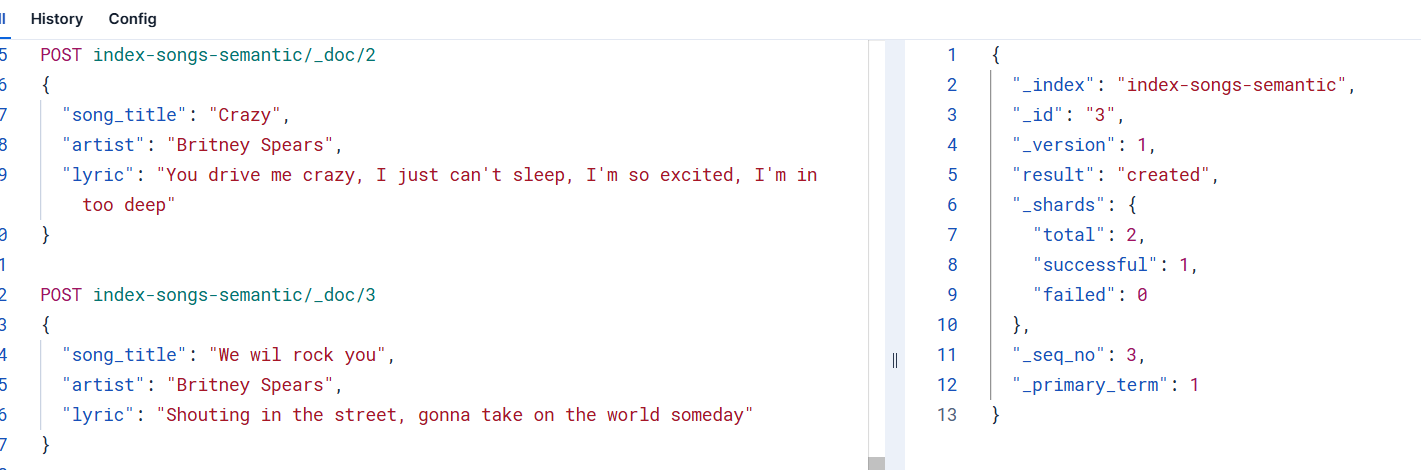
}4.1.2 索引添加数据
为上述创建的索引增加几条数据
POST index-songs-semantic/_doc/1
{
"song_title": "...Baby One More Time",
"artist": "Britney Spears",
"lyric": "When I'm with you, I lose my mind, give me a sign"
}
POST index-songs-semantic/_doc/2
{
"song_title": "Crazy",
"artist": "Britney Spears",
"lyric": "You drive me crazy, I just can't sleep, I'm so excited, I'm in too deep"
}
POST index-songs-semantic/_doc/3
{
"song_title": "We wil rock you",
"artist": "Britney Spears",
"lyric": "Shouting in the street, gonna take on the world someday"
}依次点击将3条数据添加进去
注意,如果在为索引添加数据过程中出现403的license错误,请执行下面的命令
POST /_license/start_trial?acknowledge=true请注意,acknowledge=true 参数是必需的,因为它确认了你理解此许可证将在30天后到期。此外,每个主要版本只能激活一次试用期。如果您的集群已经激活过试用期,则需要等到新的主要版本发布或者通过官方渠道申请延长试用期。
4.1.3 执行语义搜索
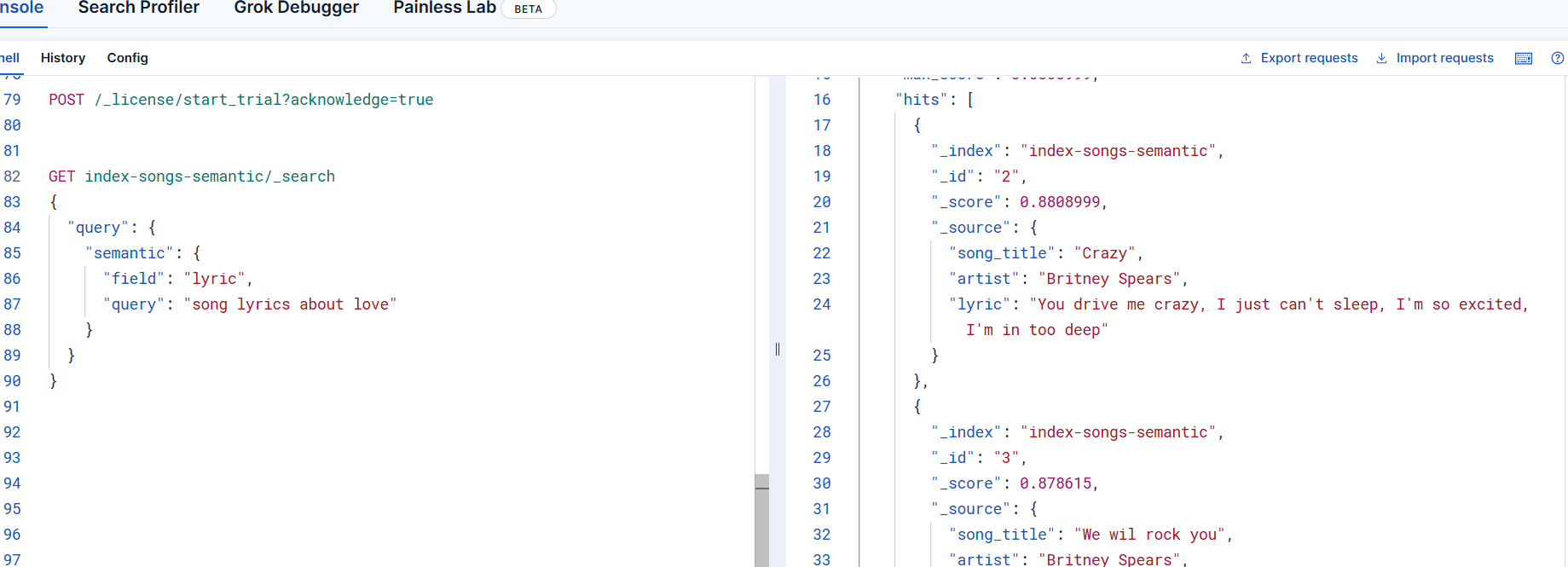
使用 semantic 查询:
-
简单来说,语义搜索就是,你输入一个与文档中的意思差不多的文本,能够给你搜索出来
GET index-songs-semantic/_search
{
"query": {
"semantic": {
"field": "lyric",
"query": "song lyrics about love"
}
}
}使用上面的语句在kibana中执行,可以看到,能够按照评分高低将符合条件的文档检索出来
match 查询(9.0新特性):
- 简单来说,使用es9的语义检索功能,像之前那样使用es的查询语法即可
五、ES9 中文语义检索操作过程
接下来通过案例操作演示下ES9的中文语义检索完整的操作过程。
5.1 配置向量模型
在文章开头谈到ES9的语义检索原理时,其中一个非常重要的点就是数据存储在es的时候,其内部有一个数据向量化的过程,即向量化后的数据才能在后续的检索中,借助语义检索查出来,因此在这里,我们先选择阿里云的文本向量大模型,结合es9一起来完成对于中文语义检索的过程。
5.1.1 获取向量模型和apikey
进入阿里云平台获取文本向量模型,并获取apikey,平台访问入口:智能开放搜索 OpenSearch 控制台
1)找到文本向量模型
如下,在服务广场找到下面的文本向量化模型,后续将会使用这个模型
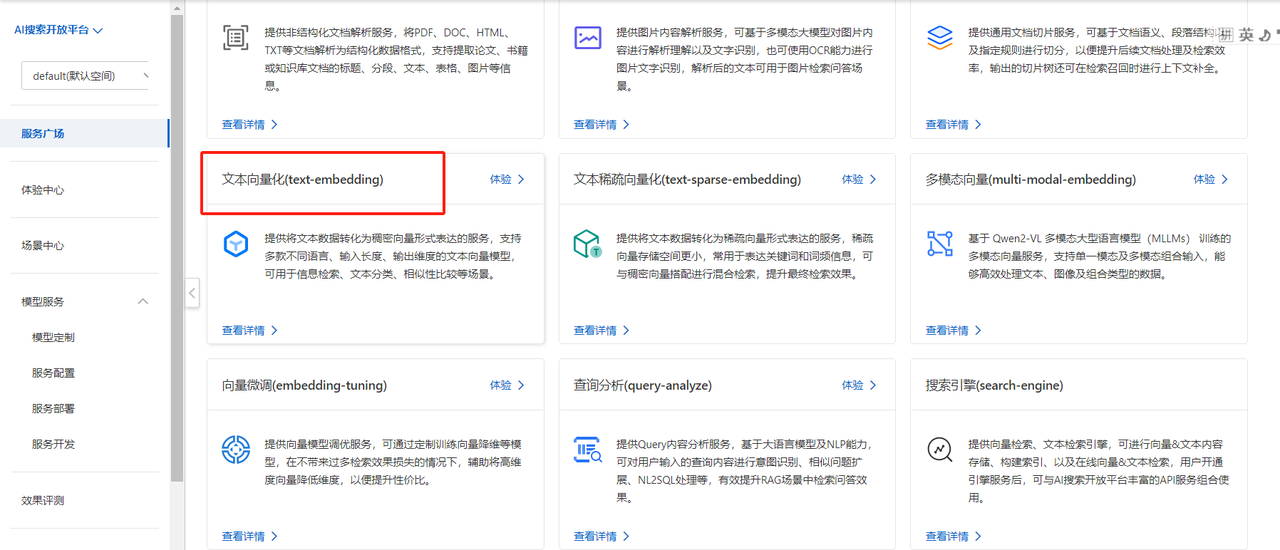
点击查看详情,可以看到里面提供针对实际业务中多种场景下的具体服务信息,在后文的配置中使用哪一个,只需要拷贝对应的服务ID即可。

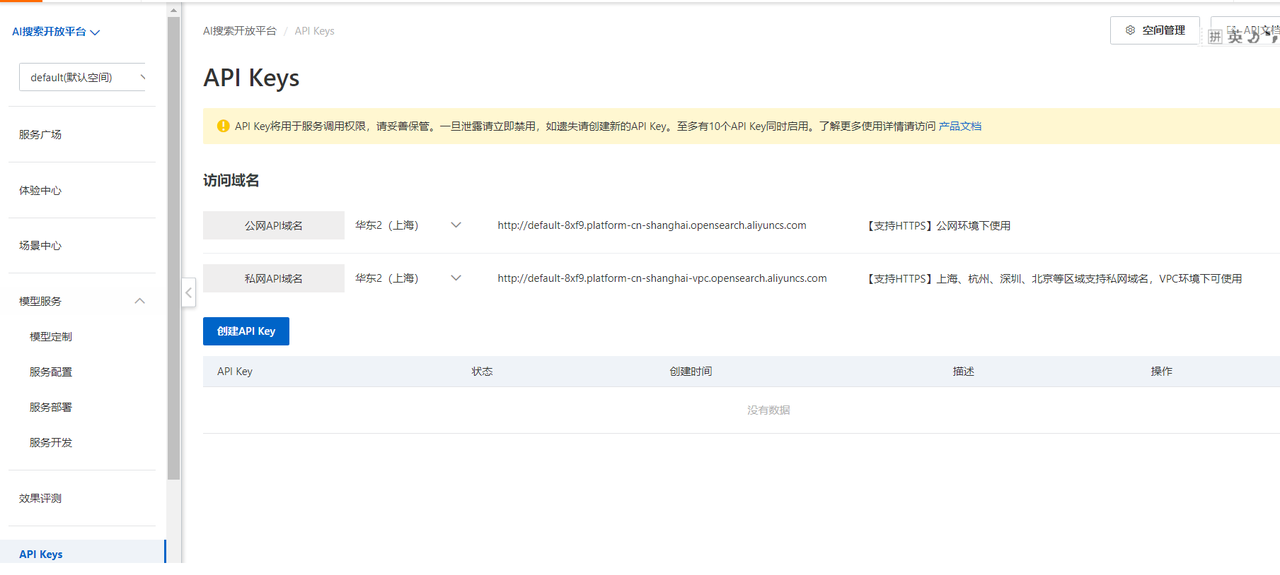
2)创建apikey
初次进来需要手动创建一个apikey
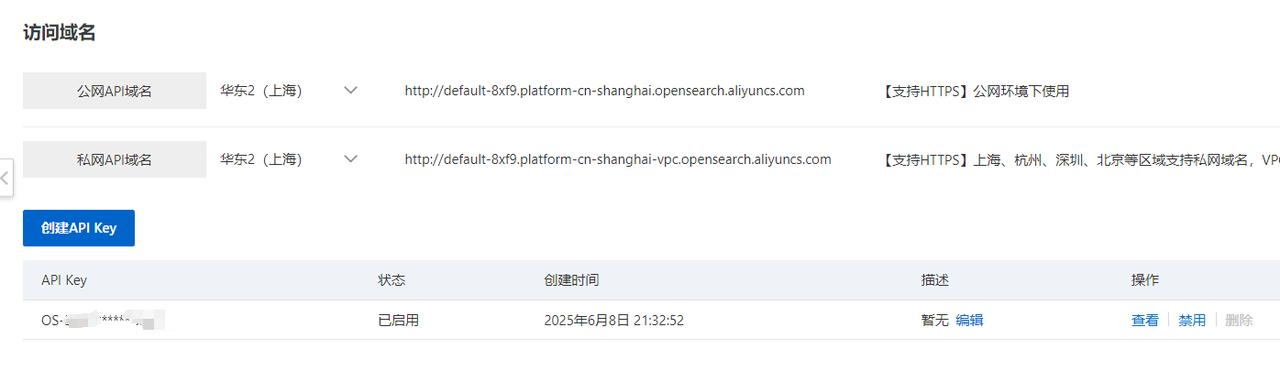
5.1.2 注册推理API访问入口
如何才能让后续写入es的索引数据与AI大模型进行联动呢?首先需要通过es的API进行服务注册,即打通ES与AI大模型交互,在kibana中执行下面的命令
PUT _inference/text_embedding/text_embedding_v1
{
"service":"alibabacloud-ai-search",
"service_settings":{
"api_key":"你的apikey",
"service_id":"ops-text-embedding-001",
"host":"default-8xf9.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace":"default"
}
}看到下面的界面创建成功

5.2 创建索引并增加数据
5.2.1 添加索引
使用下面的语句创建一个索引
PUT poetry
{
"mappings": {
"properties": {
"author": {
"type": "keyword"
},
"title": {
"type": "text"
},
"content": {
"type": "semantic_text",
"inference_id": "text_embedding_v1"
}
}
}
}
5.2.2 增加几条数据
使用下面的语句增加几条数据
POST poetry/_doc/1
{
"author": "杜甫",
"title": "春望",
"content": "国破山河在,城春草木深。感时花溅泪,恨别鸟惊心。"
}
POST poetry/_doc/2
{
"author": "李白",
"title": "静夜思",
"content": "床前明月光,疑是地上霜。举头望明月,低头思故乡。"
}
POST poetry/_doc/3
{
"author": "王维",
"title": "相思",
"content": "红豆生南国,春来发几枝。愿君多采撷,此物最相思。"
}
es的语义检索在数据进行存储的时候,看到的是为索引增加了一些数据,其实底层还增加了数据向量化的操作过程
5.3 语义检索效果模拟
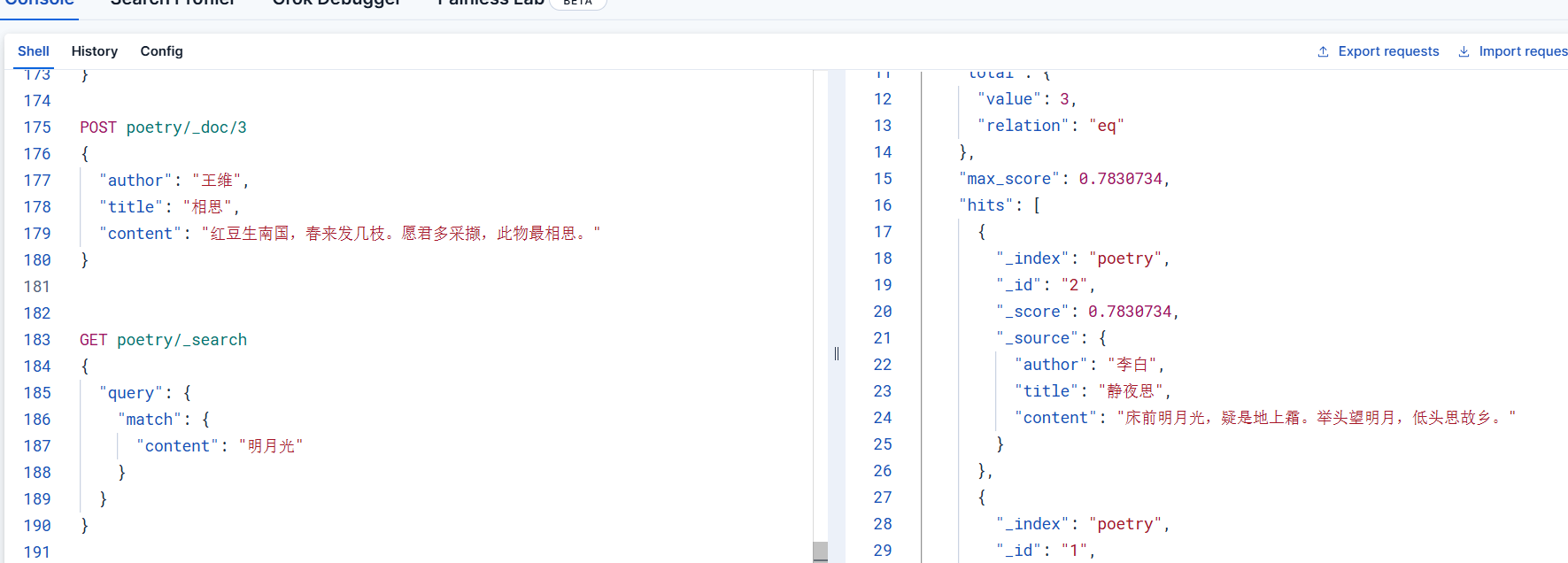
通过上一步操作之后,数据不仅存储到索引,而且也被向量化了,实际在进行检索的时候,仍然是使用es常规的检索语法即可,首先进行正常的检索,我们使用关键字检索
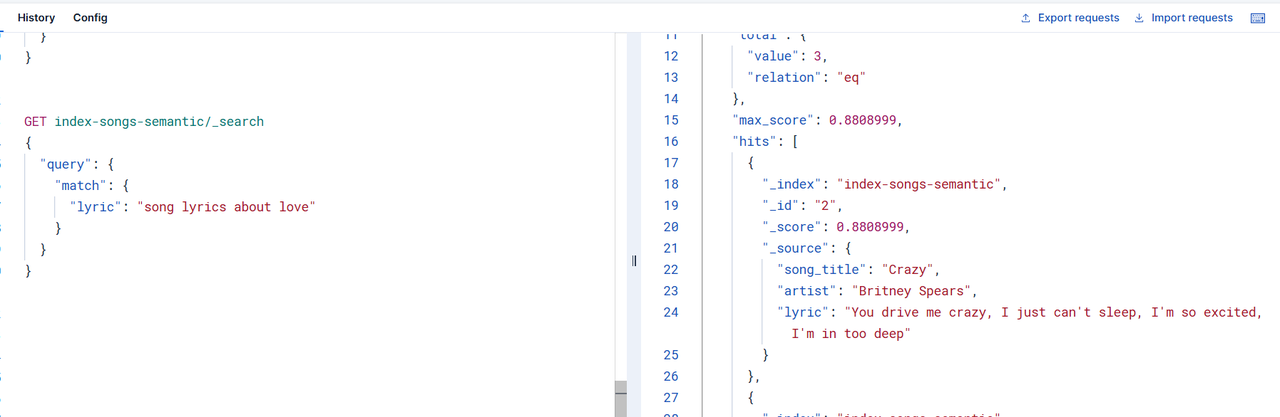
GET poetry/_search
{
"query": {
"match": {
"content": "明月光"
}
}
}通过检索的结果,可以看到能够按照预期将相似度最高的排在最前面
然后在使用下面的语句,这一句是根据文档中的第一条数据推断出来的近似语句
- 细心的同学可以发现,这里直接使用了es大家熟悉的match语法
GET poetry/_search
{
"query": {
"match": {
"content": "描述家国大义诗句有哪些"
}
}
}点击查询之后,神奇的现象出现了,能够正确的将语义最相似的第一条诗句返回
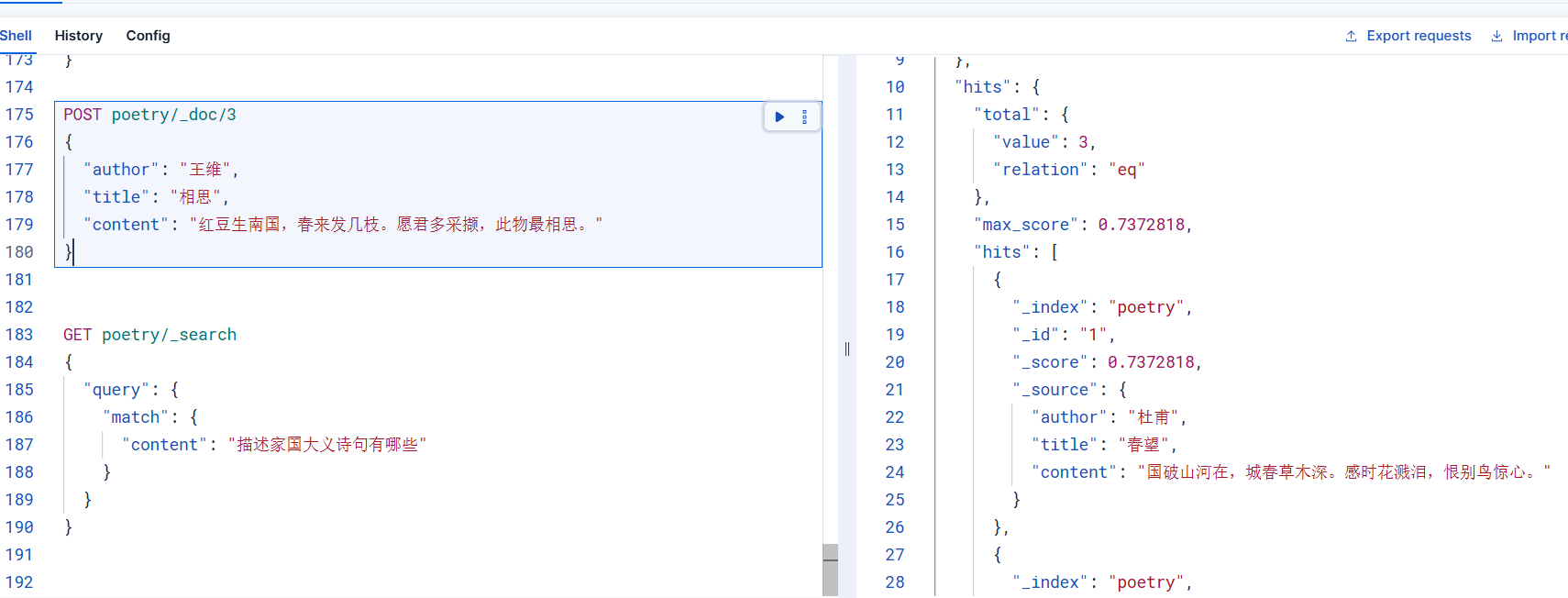
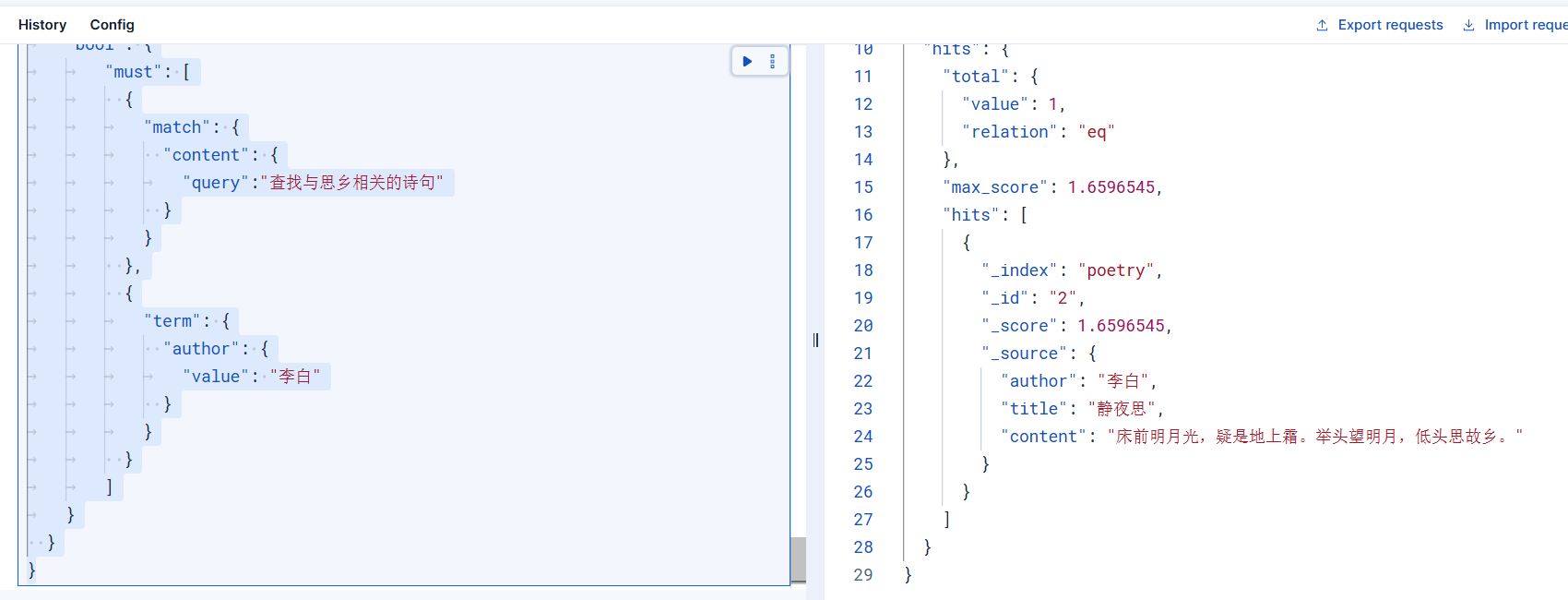
更近一步,使用es进行多条件查询时候,语义检索仍然有效,比如在下面的组合条件查询中,我们限定了两个条件,通过查询结果来看,语义检索仍然可以得到正确的返回结果
POST poetry/_search
{
"size": 20,
"query": {
"bool": {
"must": [
{
"match": {
"content": {
"query":"查找与思乡相关的诗句"
}
}
},
{
"term": {
"author": {
"value": "李白"
}
}
}
]
}
}
}检索结果如下
六、写在文末
本文通过较大的篇幅详细介绍了es9的语义检索功能,搭配向量大模型,可以在实际业务中发挥很重要的作用,有兴趣的同学可以基于此继续深入研究,本篇到此结束,感谢观看。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)