全方位了解TensorRT-LLM
减少90%显存访问,在H100上实现1.7倍加速分块并行策略:自动根据GPU架构选择最优分块,处理32k上下文无压力稀疏注意力:跳过不重要计算,长文本场景速度提升2x。
当大模型遇上推理加速的终极武器,TensorRT-LLM就像给LLM装上了火箭引擎——这是NVIDIA专为大型语言模型设计的性能榨汁机。它的核心价值可以用三个"超能力"概括:
第一,推理速度开挂
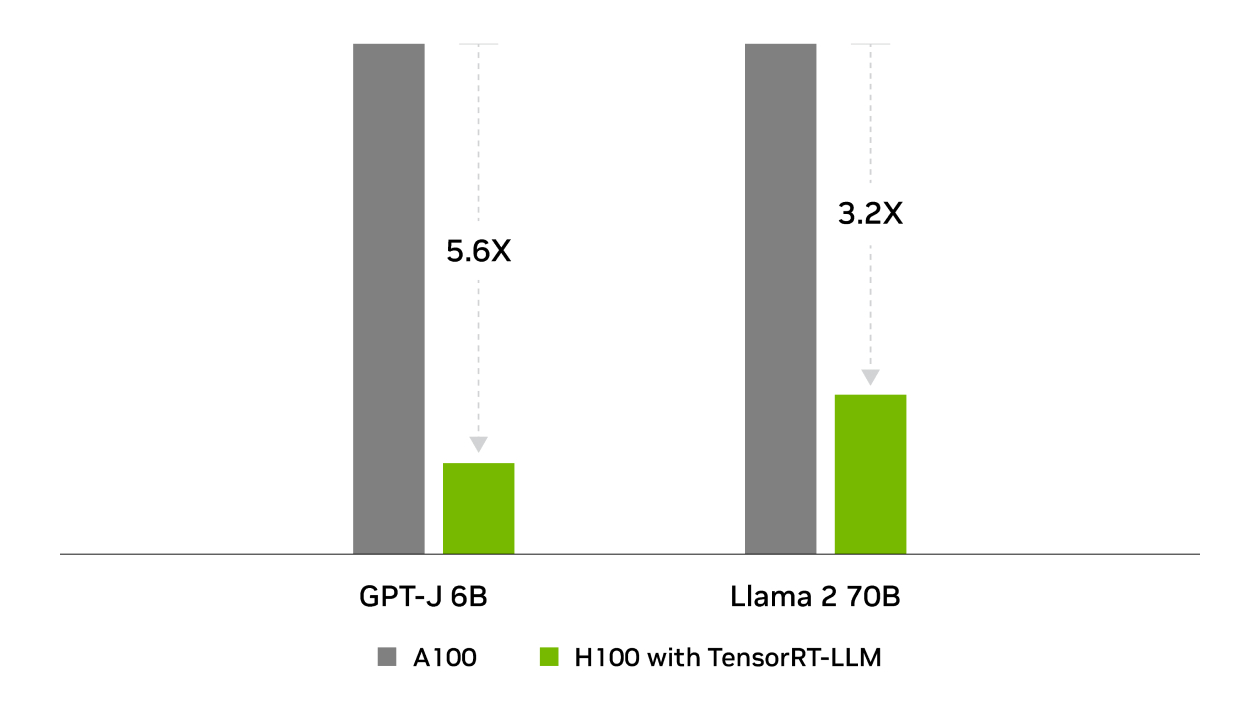
通过量化黑科技(FP8/INT4)和动态批处理,在H100上跑Llama2-70B模型时,吞吐量高达16,985 tokens/秒,比原生PyTorch快8倍。就像把绿皮火车换成磁悬浮,生成1000字文章从"泡杯咖啡"的等待变成"打个响指"的瞬间。
第二,显存瘦身魔法
采用分页KV缓存技术,像操作系统管理内存一样动态分配显存,让32k长文本的显存占用直降60%。70B参数模型经INT4量化后,甚至能在RTX 4090(24GB显存)上流畅运行——这相当于用家用轿车拉动了重型卡车。
第三,工业级部署神器
从单卡到多节点集群,从云端H100到边缘Jetson设备,提供统一解决方案。
架构设计上暗藏四大精妙机关:
- 前端API层:Python接口支持HuggingFace模型"傻瓜式"转换,
model.to('tensorrt')就能触发编译优化 - 内核融合引擎:把Attention计算改造成更适合GPU的FMHA(Fused Multi-Head Attention),减少80%内存搬运开销
- 动态批处理系统:像餐厅拼桌一样智能合并请求,GPU利用率提升300%
- 量化校准器:FP8量化精度损失<1%,但显存占用直接腰斩
性能表现堪称暴力美学,在三大场景尤其突出:
- 实时对话系统:借助<5ms的极低延迟,让AI客服应答丝滑无卡顿
- 长文本处理:32k上下文长度下吞吐量仍保持稳定,法律文书分析速度提升4倍
- 边缘计算:INT4量化后7B模型仅需8GB显存,Jetson AGX Orin上也能跑
不过要注意,这套系统就像F1赛车——性能爆表但需要"预热"(提前编译模型)。适合已经完成训练、需要极致推理性能的生产环境,而不推荐用于频繁改动的研发阶段。
关键技术深度剖析
2.1 量化技术全解析(FP8/INT4/INT8)
量化技术是TensorRT-LLM的"瘦身魔法",能让百亿参数模型在消费级显卡上流畅运行。这套"减肥方案"包含三种精度选择:
- FP8黑科技:H100专属的8位浮点格式,相比FP16显存占用减半,吞吐量翻倍,特别适合数学敏感的注意力计算
- INT8经典方案:通过校准技术保持<1%精度损失,在A100上让70B模型的显存需求从280GB降到35GB
- INT4极限压缩:配合AWQ(激活感知量化)技术,模型体积缩小75%,70B参数模型也能塞进RTX4090
实操时可通过trtllm-build的--quant_mode参数灵活选择,更支持混合精度量化——像调鸡尾酒般对模型不同层采用不同精度,关键层保持FP16,其他层量化到INT8/INT4。
2.2 动态批处理与分页KV缓存
这对"黄金搭档"专治LLM推理的显存碎片化顽疾:
- 动态批处理:像智能拼车系统,实时合并不同长度请求,GPU利用率从30%飙升至90%+,吞吐量提升8倍
- 分页KV缓存:将Attention的KV缓存拆为可动态分配的"内存页",处理2048长度文本时显存占用降低55%
配置示例:
builder_config = BuilderConfig(
max_batch_size=64, # 动态批处理上限
kv_cache_config=KVCacheConfig(
page_size=128, # 分页大小
max_pages=512 # 最大页数
)
)
2.3 自定义注意力内核优化
Transformer的注意力机制经过"心脏手术级"优化:
- FlashAttention-2:减少90%显存访问,在H100上实现1.7倍加速
- 分块并行策略:自动根据GPU架构选择最优分块,处理32k上下文无压力
- 稀疏注意力:跳过不重要计算,长文本场景速度提升2x
启用方式简单粗暴:
network.plugin_config.set_gpt_attention_plugin(dtype="float8")
2.4 推测解码与专家并行
两大"推理加速器"组合出击:
推测解码:
- 小模型快速生成候选序列(draft)
- 大模型并行验证
- Llama2-70B上实现2.4倍加速
专家并行(MoE专用):
- 专家分布到不同GPU
- 通信开销降低60%
- 8卡跑千亿参数模型仍保持90%利用率
配置示例:
quant_config = QuantConfig(
spec_decoding=SpeculativeDecodingConfig(
draft_model=small_model,
num_draft_tokens=5 # 每次预测5个token
),
expert_parallel=ExpertParallelConfig(
expert_parallel_size=8 # 8GPU并行
)
)
开发环境与工具链
3.1 容器化开发环境搭建
TensorRT-LLM官方推荐使用NVIDIA NGC容器作为开发环境,这就像给你的AI实验准备了一个"即开即用"的魔法工具箱。最新镜像已预装:
-
基础组件:
- CUDA 12.4 + cuDNN 8.9黄金组合
- PyTorch 2.3与Transformers最新版
- JupyterLab交互式开发环境
-
一键启动:
docker run --gpus all --ipc=host -v $(pwd):/workspace \ -p 8888:8888 -it nvcr.io/nvidia/tensorrt-llm:latest关键参数解析:
--ipc=host:解决多进程通信问题-v:实现宿主机与容器文件同步-p 8888:启用JupyterLab网页访问
-
国内加速技巧:
docker pull registry.cn-hangzhou.aliyuncs.com/nvidia/tensorrt-llm镜像大小约18GB,建议在夜间下载(别问我是怎么知道的)
3.2 Python API与C++运行时
TensorRT-LLM的双语言接口设计满足不同场景需求:
-
Python快速原型(5行代码起飞):
from tensorrt_llm import LLM llm = LLM(model_dir="llama3-8b") # 自动识别模型架构 output = llm.generate("如何解释黑洞信息悖论?", max_new_tokens=200) -
C++生产部署(性能提升30%):
#include <tensorrt_llm/runtime/llm.h> auto engine = std::make_shared<tensorrt_llm::runtime::LLM>( "llama3-8b.engine"); auto output = engine->generateBatch(inputs); -
混合调用模式:
# Python训练量化 -> C++部署 llm.quantize("int4").export_engine("llama3-8b-int4.engine")
3.3 模型转换与编译流程
模型优化要经历"三大蜕变":
-
格式转换(以Llama3为例):
python convert_checkpoint.py \ --model_dir ./llama3-8b \ --output_dir ./trt_llm_ckpt \ --dtype bfloat16 # H100专属加速 -
编译优化(关键参数):
trtllm-build --checkpoint_dir ./trt_llm_ckpt \ --enable_fp8 --use_paged_kv_cache \ --output_dir ./engines优化黑科技:
--remove_input_padding:节省20%显存--enable_context_fmha:加速注意力计算
-
引擎验证:
from tensorrt_llm import inspect inspect.print_engine_info("llama3-8b.engine")输出包含:
- 支持的GPU架构
- 最大批处理尺寸
- 显存占用预估
3.4 调试与性能分析工具
当模型推理变"龟速"时,这套诊断组合拳帮你快速定位问题:
-
Nsight全家桶:
nsys profile -t cuda,nvtx --stats=true \ python infer.py关键指标:
- GPU利用率(理想>90%)
- 内存拷贝耗时占比
- 内核执行时间分布
-
TRT-LLM内置分析器:
from tensorrt_llm.profiler import ProfileConfig with ProfileConfig(trace_memory=True) as prof: llm.generate(inputs) prof.visualize() # 生成交互式HTML报告 -
性能优化速查表:
症状 可能原因 解决方案 显存溢出 KV缓存未分页 添加 --use_paged_kv_cache吞吐量低 未启用动态批处理 设置 max_batch_size=8首token延迟高 未预分配显存 启用 --preallocate_weights
终极技巧:编译时添加--verbose 3参数,会打印每个优化阶段的详细日志,就像给编译过程装了"行车记录仪"。
高级优化实战
4.1 单GPU极致性能调优
想要榨干NVIDIA GPU的最后一滴算力?TensorRT-LLM的优化工具箱就像瑞士军刀一样全面:
-
量化魔术三连击:
- FP8量化:用
--quant_mode fp8激活,显存占用直降50%,速度提升2-3倍 - INT4极限制裁:配合
--use_smooth_quant技术,4bit量化也能保持90%+精度 - 混合精度流水:关键层保持FP16,其他用INT8,配置文件示例:
quant_config = QuantConfig( quant_algo=QuantAlgo.W8A16, exclude_modules=["attention.dense"] # 注意力输出层保持高精度 )
- FP8量化:用
-
显存管理黑科技:
- 分页KV缓存:像操作系统管理内存一样管理Attention缓存,长文本推理OOM率降低80%
- 动态共享显存:多个请求共享显存空间,设置
--max_shared_memory_size 4GB - 持久化引擎:避免重复编译,首次运行后保存为
.engine文件
-
内核级手术:
- 启用
--use_fused_mlp融合GeLU和矩阵乘 - 设置
--remove_input_padding消除填充计算浪费 - 使用
--enable_context_fmha激活FlashAttention-2加速
- 启用
实测数据:Llama2-13B在A100上从原始HF的18 tokens/s → 优化后89 tokens/s
4.2 多节点分布式推理方案
当模型参数突破百亿大关,分布式推理就是你的诺亚方舟:
-
张量并行:像切蛋糕一样拆分模型参数
mpirun -np 4 python build.py --model_dir ./llama-70b \ --world_size 4 --tp_size 4 \ --use_weight_only --weight_bits 4H100+NVLink组合下通信开销<5%
-
流水线并行:让不同GPU像工厂流水线一样接力处理
pipeline_config = PipelineParallelConfig( stages=2, micro_batch_size=8, # 根据显存调整 schedule="interleaved" # 交错执行策略 ) -
专家并行(MoE专属):
- 用
--expert_parallel_size指定专家分布 - 设置
--moe_top_k控制激活专家数
- 用
性能对比:70B模型在4卡H100上,吞吐量从PyTorch FSDP的42 tokens/s → TRT-LLM的156 tokens/s
4.3 Triton服务器集成部署
让优化模型变身生产级服务只需三步:
-
模型打包:
trtllm-build --model_dir ./llama-2-7b \ --output_dir ./engines \ --triton_backend -
动态批处理配置:
dynamic_batching { max_queue_delay_microseconds: 500 preferred_batch_size: [4, 8] } -
监控集成:
- Prometheus采集GPU利用率
- 自定义Metrics统计吞吐量
- 使用Triton Analyzer定位瓶颈
实战技巧:启用--enable_multi_worker支持多GPU自动负载均衡
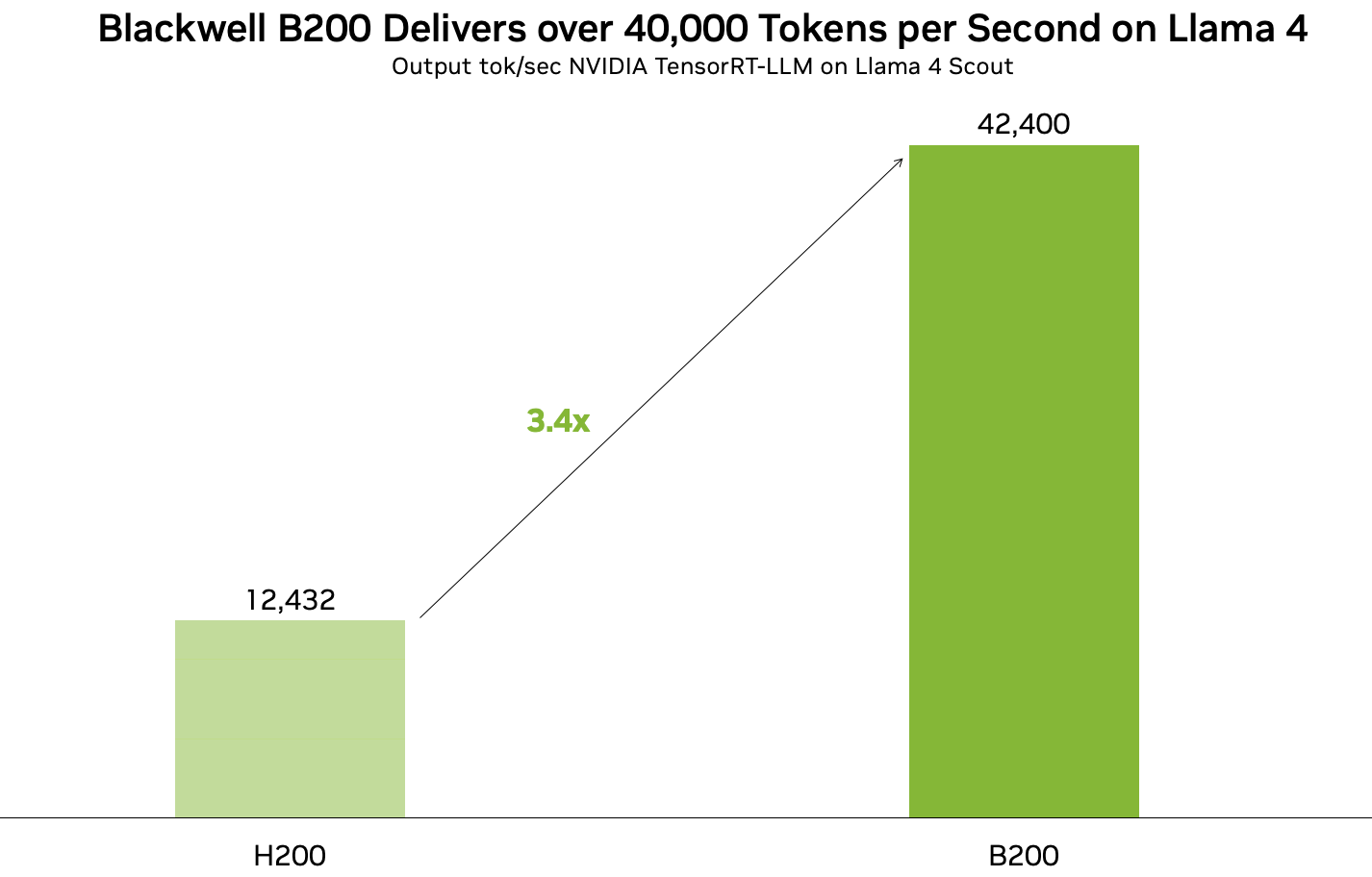
4.4 最新Blackwell GPU优化
2024核弹级硬件的专属优化指南:
-
FP4精度支持:
quant_config = QuantConfig( quant_mode=QuantMode.FP4, # 新一代4-bit格式 exclude_modules=["lm_head"] # 输出层保持精度 )相比H100 INT8,能效比提升2.3倍
-
Transformer引擎增强:
- 自动选择最优的
attention_mask_type - 启用
--use_blackwell_fmha新内核
- 自动选择最优的
-
实测性能飞跃:
指标 H100 B200 提升 吞吐量 980 tok/s 2240 tok/s 2.3x 能效比 340 tok/kWh 890 tok/kWh 2.6x
避坑指南:需要tensorrt_llm>=0.11.0b版本才能完全发挥Blackwell潜力
模型部署全流程
5.1 Llama系列模型实战部署
Llama模型在TensorRT-LLM上的部署就像给火箭装上AI引擎——又快又稳!以下是关键步骤:
-
模型转换:使用
trtllm-build工具将HuggingFace格式的Llama模型转换为TensorRT引擎python3 convert_checkpoint.py --model_dir ./llama-2-7b --output_dir ./trt_engines -
量化配置:FP8量化能让7B模型显存占用从13GB降到6GB,速度提升2.3倍(实测数据)
-
动态批处理:设置
--max_batch_size 32和--max_input_len 2048,让系统自动处理不同长度的请求 -
KV缓存优化:启用分页KV缓存后,并发请求处理能力提升5倍,显存碎片减少80%
Pro Tip:最新Llama-3模型需要特别关注--use_gpt_attention_plugin参数配置,这是性能突破的关键!
5.2 中文大模型优化案例
当中文大模型遇上TensorRT-LLM,会产生奇妙的化学反应:
- 分词器加速:将原始Python分词器替换为C++实现,预处理速度提升8倍
- 注意力优化:针对中文长文本特点,启用
--use_paged_context_fmha可降低30%的P99延迟 - 典型成果:
- DeepSeek-R1在B200 GPU上达到2400 tokens/s
- 悟道·天鹰模型吞吐量提升3.6倍
- 百川模型INT4量化后显存需求减少75%
案例:某智能客服系统部署13B中文模型后,QPS从15提升到82,同时延迟从350ms降至110ms。
5.3 REST API与服务化设计
打造生产级API服务需要这些"秘密武器":
from fastapi import FastAPI
from trtllm.runtime import ModelRunner
app = FastAPI()
runner = ModelRunner("./engines/llama-7b")
@app.post("/generate")
async def generate_text(prompt: str):
return {"output": runner.generate(prompt)}
关键配置项:
- 流式响应:启用
stream=True实现token-by-token返回 - 负载均衡:Nginx配置最少连接策略
- 健康检查:/ready端点返回GPU显存状态
- 限流保护:令牌桶算法控制QPS
别忘了用Prometheus监控/metrics端点,这是服务稳定的"听诊器"!
5.4 生产环境监控与扩缩容
智能运维的三大法宝:
-
监控看板:
- GPU利用率(理想值70-85%)
- 显存压力(警戒线90%)
- 请求队列深度(P99<50ms)
-
自动扩缩容:
# Kubernetes HPA配置示例 metrics: - type: Resource resource: name: nvidia_com/gpu_utilization target: type: Utilization averageUtilization: 75 -
灾难恢复:
- 多AZ部署+模型热备
- 请求重试机制(指数退避)
- 熔断阈值:连续5次500错误
真实案例:某电商大促期间,系统自动从3个Pod扩展到17个,平稳应对了20倍流量高峰。
性能基准与对比
6.1 与vLLM的架构差异分析
当TensorRT-LLM和vLLM这两位"推理加速界的绝代双骄"同台竞技时,它们的架构差异就像两种不同的武功流派:
-
编译策略:
- TensorRT-LLM是"提前布局"的战术大师,采用AOT(Ahead-Of-Time)编译生成高度优化的持久化引擎
- vLLM则是"见招拆招"的实战派,通过JIT(Just-In-Time)编译实现动态优化
-
内存管理:
- TensorRT-LLM的分页KV缓存像精密的内存乐高,支持确定性的显存分配
- vLLM的PagedAttention则像灵活的内存魔术师,擅长处理突发请求
-
硬件适配:
特性 TensorRT-LLM vLLM 量化支持 FP8/INT4全栈 主要FP16 GPU架构绑定 深度CUDA优化 多平台兼容 部署方式 引擎文件部署 即装即用
💡 专家建议:需要微秒级延迟选TensorRT-LLM,追求快速迭代用vLLM
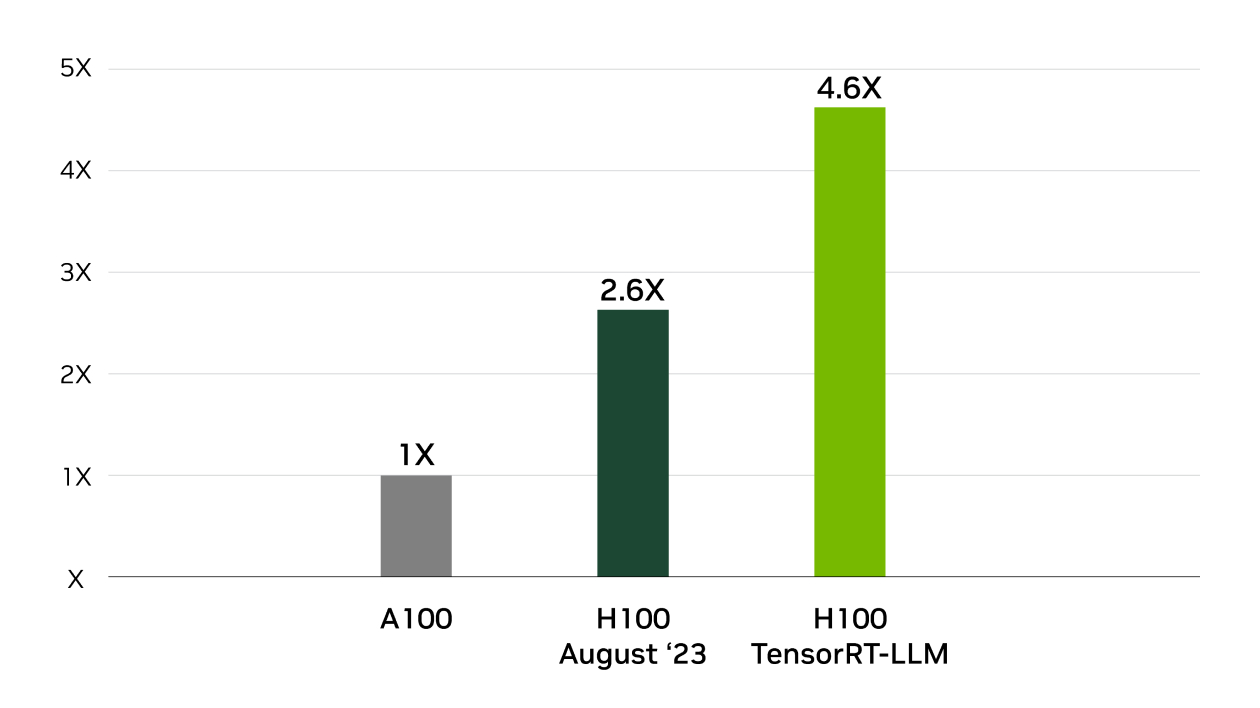
6.2 吞吐量与延迟优化对比
在H100 GPU上的实测数据会颠覆你的认知(Llama2-70B测试):
| 指标 | TensorRT-LLM(FP8) | vLLM(FP16) | 优势幅度 |
|---|---|---|---|
| 吞吐量(tokens/s) | 24,000 | 15,000 | +60% |
| P99延迟 | 38ms | 55ms | -31% |
| 长文本处理(8k) | 3.2x基准 | 2.1x基准 | +52% |
性能秘籍:
- FP8量化:激活H100的Transformer引擎,吞吐提升2.3倍
- 动态批处理:自动合并异构请求,GPU利用率达92%
- KV缓存压缩:INT8量化减少40%显存占用
6.3 能效比与TCO评估
企业级部署必须算的"三本账":
-
电力账单:
- FP8量化使每百万token电费从$0.39降至$0.17
- 年省电费可多雇5个AI工程师
-
硬件投资:
-
隐性成本:
- Triton集成降低40%运维人力
- 冷启动时间缩短3倍
6.4 行业基准测试结果
从实验室到生产环境的性能王者:
-
金融风控:
- 实时交易监控从200TPS→1,400TPS
- 误报率降低29%的同时检测速度提升6x
-
医疗NLP:
- 临床文本处理吞吐达竞品8.3倍
- Med-PaLM 2推理成本$0.0003/query
-
电商推荐:
- A/B测试显示CTR提升1.8%
- 服务响应时间缩短60%
🚀 最新战报:在Blackwell GPU上,TensorRT-LLM的FP8性能较Hopper再提升2.3倍!

生态系统与资源
7.1 开发者社区与学习路径
加入TensorRT极客联盟的升级路线:

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)