YOLOV: Making Still Image Object Detectors Great at Video Object Detection——让静态图像目标检测器在视频目标检测中表现卓越
YOLOV: Making Still Image Object Detectors Great at Video Object Detection——让静态图像目标检测器在视频目标检测中表现卓越
YOLOV 论文研究内容层次化概括如下:
一、研究背景与痛点
-
任务:视频目标检测(VID)
• 单帧退化严重:运动模糊、遮挡、失焦等。
• 时序信息丰富:相邻帧可提供互补线索。 -
现状局限
• 主流方法基于两阶段检测器,精度高但推理慢。
• 单阶段检测器速度快,却缺乏区域级特征,难以直接利用已有的跨帧聚合模块。
二、核心问题
如何在不牺牲单阶段检测器速度的前提下,把时序信息有效地聚合进来,实现“既准又快”的视频目标检测。
三、解决思路(总览)
把传统两阶段流程“先提大量候选→再精修”的顺序颠倒:
-
先用单阶段检测器一次性给出高置信候选;
-
再对这些候选做跨帧特征聚合精炼。
四、具体技术模块
-
FSM(Feature Selection Module)
• 作用:从单阶段输出中挑 top-k + NMS → 高质量候选框及其特征。
• 技巧:冻结基线权重,仅微调少量层,避免破坏预训练。 -
FAM(Feature Aggregation Module)
• 组成 A:Affinity Attention
‑ 在传统 QK 注意力基础上,额外引入检测置信度(分类+IoU)做加权,缓解“同质化”退化问题。
• 组成 B:Average Pooling over References
‑ 对相似度高于阈值 τ 的参考特征再做一次平均池化,提升多样性,防止 softmax 过度集中。
五、实验验证
-
数据集:ImageNet VID + DET 同类别混合,训练采样 1/10 帧。
-
结果
• YOLOV-X 在 2080Ti 上 22.7 ms/帧 → 85.5% AP50;加后处理 28.7 ms → 87.5% AP50,优于所有同期方法。
• 消融实验:
‑ 全局采样 > 局部采样;
‑ a = 30 为速度与精度的最佳折中;
‑ τ = 0.75 为平均池化最优阈值;
‑ A.M. + A.P. 组合带来 7~8% AP50 提升。 -
通用性:将 FSM+FAM 插到 PPYOLOE、FCOS 等其它单阶段网络,均提升 5% 以上 AP50。
六、贡献总结
-
提出“先检测-后聚合”的单阶段视频检测新范式,显著降低计算量。
-
设计轻量级 FSM+FAM 模块,仅用微小开销实现大幅精度增益。
-
YOLOV 系列在 ImageNet VID 上同时取得 SOTA 精度与实时速度,代码开源。
这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

项目地址在这里,如下所示:
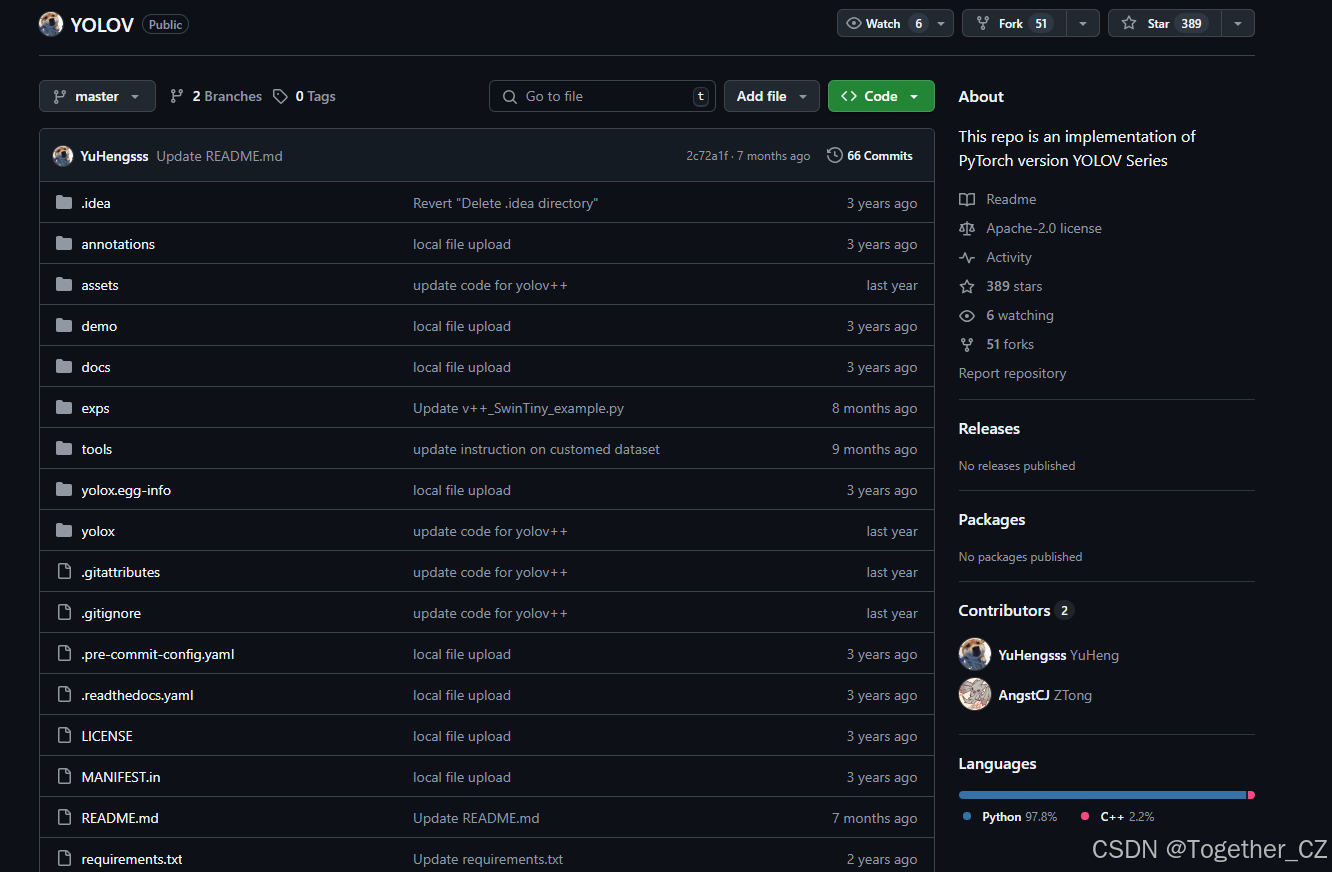
官方发布的预训练模型如下:
| Model | size | mAP@50val | Speed 2080Ti(batch size=1) (ms) |
Speed 3090(batch size=32) (ms) |
weights |
|---|---|---|---|---|---|
| YOLOX-s | 576 | 69.5 | 9.4 | 1.4 | |
| YOLOX-l | 576 | 76.1 | 14.8 | 4.2 | |
| YOLOX-x | 576 | 77.8 | 20.4 | - | |
| YOLOX-SwinTiny | 576 | 79.2 | 19.0 | 5.5 | |
| YOLOX-SwinBase | 576 | 86.5 | 24.9 | 11.8 | |
| YOLOX-FocalLarge | 576 | 89.7 | 42.2 | 25.7 | - |
| Model | size | mAP@50val | Speed 3090(batch size=32) (ms) |
weights | logs |
|---|---|---|---|---|---|
| YOLOV++ s | 576 | 78.7 | 5.3 | link | |
| YOLOV++ l | 576 | 84.2 | 7.6 | - | |
| YOLOV++ SwinTiny | 576 | 85.6 | 8.4 | link | |
| YOLOV++ SwinBase | 576 | 90.7 | 15.9 | link | |
| YOLOV++ FocalLarge | 576 | 92.9 | 27.6 | link | |
| YOLOV++ FocalLarge + Post | 576 | 93.2 | - | - |
| Model | size | mAP@50val | Speed 2080Ti(batch size=1) (ms) |
weights |
|---|---|---|---|---|
| YOLOV-s | 576 | 77.3 | 11.3 | |
| YOLOV-l | 576 | 83.6 | 16.4 | |
| YOLOV-x | 576 | 85.5 | 22.7 | |
| YOLOV-x + post | 576 | 87.5 | - | - |
摘要
视频目标检测(VID)因物体外观变化剧烈以及某些帧出现严重退化而极具挑战。另一方面,相较于单张静态图像,视频中某一帧的检测可以借助其它帧的信息。因此,如何跨帧聚合特征成为 VID 问题的关键。现有的大多数聚合算法都是为两阶段检测器量身定制,然而两阶段检测器计算量大,难以实时。本文提出一种简单而高效的策略,在极小额外开销的前提下显著提升精度。具体地,不同于传统两阶段流程,我们在一阶段检测之后再选取重要区域,从而避免处理大量低质量候选。此外,我们评估目标帧与参考帧之间的关系,以指导特征聚合。大量实验和消融研究验证了我们设计的有效性,并表明在效果与效率两方面均优于现有最佳 VID 方法。基于 YOLOX 的模型在单张 2080Ti GPU 上于 ImageNet VID 数据集可达 87.5% AP50 且速度超过 30 FPS,极具大规模或实时应用潜力。
1 引言
目标检测是众多基于视觉的智能应用中的关键组成部分(Dalal 与 Triggs 2005;Felzenszwalb、McAllester 与 Ramanan 2008),其任务是在图像中同时定位并分类物体。得益于卷积神经网络(CNN)的强大能力(Krizhevsky、Sutskever 与 Hinton 2012),近年来涌现了大量基于 CNN 的目标检测模型,它们大致可分为两大类:单阶段(one-stage)和两阶段(two-stage)检测器。具体而言,两阶段检测器首先选取候选目标区域(即候选框),再对这些区域进行分类。以 Region-based CNN(R-CNN)系列(Girshick 等 2014;Girshick 2015;Ren 等 2015)为代表,后续研究(He 等 2016;Lin 等 2017a;Dai 等 2016;Cai 与 Vasconcelos 2018;He 等 2017;Liu 等 2018)不断丰富,显著提升了检测精度。得益于区域级特征,这些面向静态图像的检测器可以较容易地迁移到更复杂的任务,如分割和视频目标检测。然而,由于两阶段的本性,效率成为其实际应用中的瓶颈。

相比之下,单阶段检测器通过特征图的密集预测,直接同时完成定位与分类。YOLO 系列(Redmon 等 2016;Redmon 与 Farhadi 2017;Bochkovskiy、Wang 与 Liao 2020)和 SSD(Liu 等 2016)是该类方法的代表。由于无需类似两阶段方法中的区域候选框,单阶段检测器在速度上具有明显优势,适合实时需求场景。尽管早期精度相对较低,但后续设计(Lin 等 2017b;Ge 等 2021b,a;Tian 等 2019)已显著缩小了精度差距。

视频目标检测可以看作是静态图像目标检测的进阶版本。直观上,可以将视频序列逐帧送入静态图像检测器进行处理。然而,这种做法未利用帧间时序信息,而时序信息正是消除单帧歧义的关键。如图 1 所示,运动模糊、相机失焦、遮挡等退化在视频帧中频繁出现,显著增加了检测难度。例如,仅观察图 1 中的最后一帧,人类甚至难以判断物体的位置与类别。另一方面,视频序列比单幅静态图像提供更丰富的信息,即同一序列中的其他帧可能为当前帧的预测提供支持。因此,如何有效地聚合不同帧的时序线索,对提升精度至关重要。
文献中,帧聚合主要有两种方式:框级(box-level)和特征级(feature-level)。这两种技术路线从不同角度提升检测精度。框级方法将静态检测器的预测通过关联边界框形成轨迹管(tubelets),再在同一个 tubelets 内精炼结果。框级方法可视为后处理,灵活适用于单阶段和两阶段检测器。特征级方法则通过寻找并聚合参考帧中的相似特征来增强关键帧特征。两阶段方法通过区域提议网络(RPN)(Ren 等 2015)为候选框提供来自骨干特征图的显式表示,因此易于迁移到视频目标检测任务。因此,大多数视频目标检测器基于两阶段检测器。然而,由于聚合模块的存在,这些两阶段视频检测器进一步降低速度,难以满足实时需求。
与两阶段方法不同,单阶段检测器的特征图中,候选框由每个位置的特征隐式表示。尽管缺乏显式的物体表示,这些特征仍可通过聚合时序信息以提升视频目标检测表现。如前所述,单阶段方法通常比两阶段方法更快。基于上述考虑,一个自然的问题浮现:我们能否将类似区域级的设计引入单阶段检测器,同时保持其快速特性,从而构建一个既准确又快速的实用视频目标检测器?
贡献
本文通过设计一种简单而高效的策略,以聚合单阶段检测器生成的特征,来回答上述问题。我们以 YOLOX(Ge 等 2021b)为基础验证主要主张。为将参考帧特征与关键帧特征关联,我们提出一种特征相似度度量模块,以构建亲和矩阵并指导聚合。为进一步缓解余弦相似度的局限,我们在参考特征上定制了平均池化操作。这两项操作仅增加极小的计算量,却带来显著的精度提升。在提出的策略加持下,我们的模型——称为 YOLOV——可在 ImageNet VID 数据集上达到 85.5% 的 AP50,并在单张 2080Ti GPU 上实现 40+ FPS(如图 2 所示),无需任何额外技巧,在实用场景中极具吸引力。进一步引入后处理,精度可提升至 87.5% AP50,速度仍保持 30+ FPS。
2 相关工作
2.1 静态图像目标检测
得益于硬件、大规模数据集(Lin 等 2014;Krizhevsky、Sutskever 与 Hinton 2012)以及精巧网络结构(Simonyan 与 Zisserman 2015;He 等 2016;Xie 等 2017;Wang 等 2020)的发展,目标检测性能持续提升。现有检测器主要分为两阶段和单阶段两类。两阶段检测器的代表包括 RCNN(Girshick 等 2014)、Faster RCNN(Ren 等 2015)、R-FCN(Dai 等 2016)和 Mask RCNN(He 等 2017)。这类方法首先通过 RPN 选取候选区域,然后通过 RoIPooling(Ren 等 2015)或 RoIAlign(He 等 2017)等模块提取候选特征,最后通过额外的检测头进行边界框回归与分类。
成功的单阶段检测器包括 YOLO 系列(Redmon 等 2016;Redmon 与 Farhadi 2017;Bochkovskiy、Wang 与 Liao 2020;Ge 等 2021b)、SSD(Liu 等 2016)、RetinaNet(Lin 等 2017b)和 FCOS(Tian 等 2019)。与两阶段方法不同,单阶段检测器在特征图上进行密集预测,直接输出位置与类别概率,无需区域候选框,因此通常更快。然而,它们缺乏广泛用于视频目标检测特征聚合的显式区域级语义特征。本文尝试探索在单阶段检测器的特征图位置级特征上进行聚合的可行性。
2.2 视频目标检测
相比静态图像目标检测,视频帧中常出现退化。当关键帧受污染时,时序信息有助于提升检测。现有视频目标检测方法可分为两大分支:
一支聚焦于轨迹级后处理(Han 等 2016;Belhassen 等 2019;Sabater、Montesano 与 Murillo 2020)。这类方法通过将静态检测器在连续帧上的预测结果连接成物体轨迹管(tubelets),并据此精炼结果,每个框的最终分类分数根据整个 tubelets 进行调整。
另一支则致力于增强关键帧特征,期望通过利用(选定)参考帧的特征来缓解退化。这些方法大致可分为基于光流的(Zhu 等 2017a, 2018)、基于注意力的(Wu 等 2019;Deng 等 2019;Chen 等 2020;Gong 等 2021;Sun 等 2021)和基于跟踪的(Feichtenhofer、Pinz 与 Zisserman 2017;Zhang 等 2018b)方法。Deep feature flow(Zhu 等 2017b)首次引入光流进行图像级特征对齐,FGFA(Zhu 等 2017a)沿运动路径聚合特征。考虑到图像级特征聚合的计算成本,研究者提出了多种基于注意力的方法。代表性方法 SELSA(Wu 等 2019)根据区域级特征间的语义相似性提出长程特征聚合方案。受静态图像检测中 Relation Networks(Hu 等 2018)关系模块启发,RDN(Deng 等 2019)捕获物体在空间与时序上下文中的关系。MEGA(Chen 等 2020)设计了记忆增强的全局-局部聚合模块,以更好地建模物体间关系。TROIA(Gong 等 2021)利用 ROI-Align 进行细粒度特征聚合,HVR-Net(Han 等 2020)融合视频内与视频间候选关系以进一步提升性能。MBMBA(Sun 等 2021)通过引入记忆库扩大参考特征集。QueryProp(He 等 2022)注意到视频目标检测器计算成本高,尝试通过轻量级查询传播模块加速。除注意力方法外,D&T(Feichtenhofer、Pinz 与 Zisserman 2017)试图以跟踪方式解决视频目标检测,通过构建不同帧特征的相关图。尽管这些方法提升了检测精度,但大多基于两阶段检测器,因此在推理速度上相对较慢。
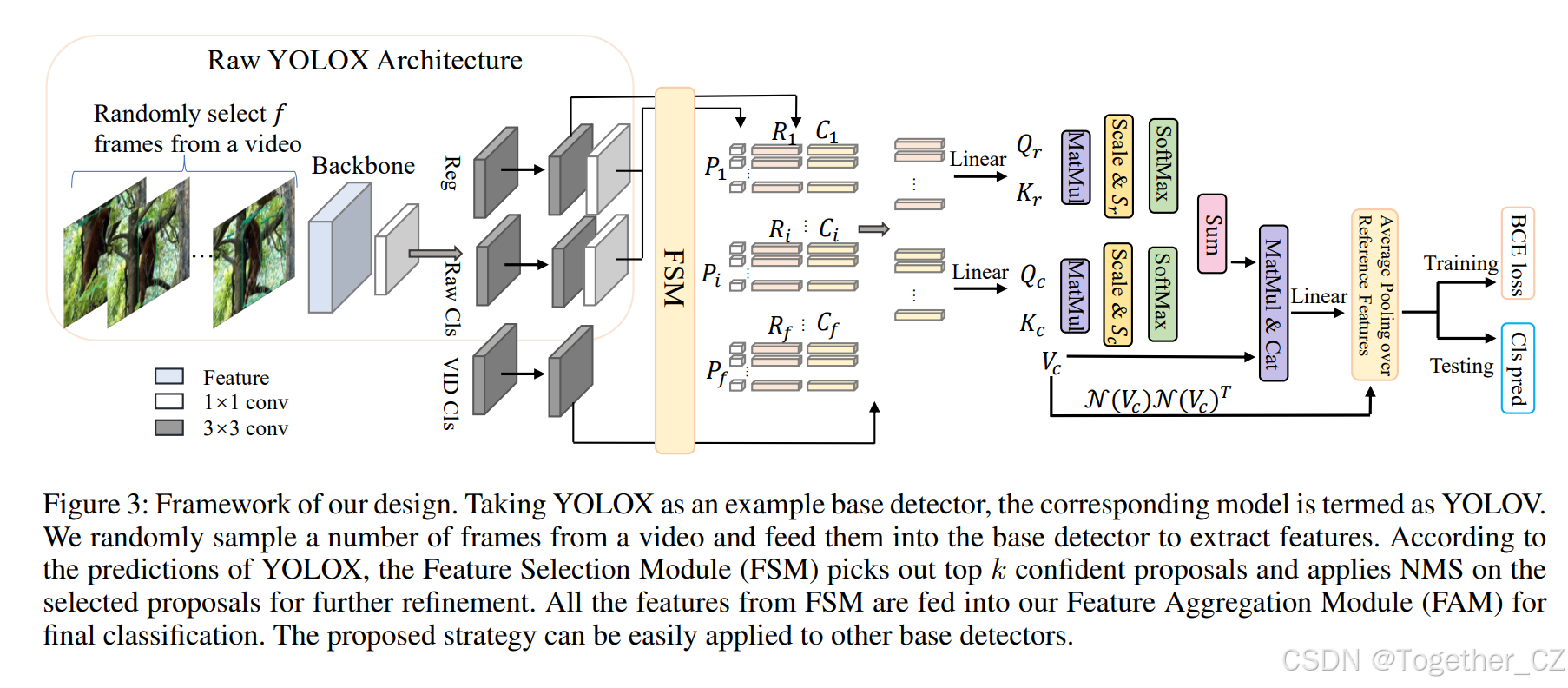
3 方法论
考虑到视频的特性(既有多种退化,又蕴含丰富时序信息),与其逐帧独立处理,不如为目标帧(关键帧)主动寻求来自其他帧的支持信息,这对提升视频目标检测精度至关重要。近期工作(Deng 等 2019;Chen 等 2020;Wu 等 2019;He 等 2022)已取得显著精度提升,证实了时序聚合的重要性。然而,现有方法大多基于两阶段框架,如前所述,其推理速度较慢。为缓解这一局限,我们把区域/特征选择阶段放在单阶段检测器的预测头之后。本节以 YOLOX 为基线展开论述,整体框架见图 3。回顾传统两阶段流程:1) 先生成大量候选区域作为提议;2) 再判断每个提议是否为物体及其类别。计算瓶颈主要源于处理大量低置信候选。如图 3 所示,我们的流程同样包含两阶段,区别在于第一阶段为预测(已剔除大量低置信区域),第二阶段可视为区域级精炼(通过跨帧聚合利用其他帧信息)。该设计同时享有单阶段检测器的高效率与时序聚合带来的精度提升。值得强调的是,这一微小改动带来显著性能跃升。该策略可推广至 FCOS(Tian 等 2019)、PPYOLOE(Xu 等 2022)等多种基线检测器。
我们的设计
从人类认知角度看,识别过程通常先在时序上关联相关实例,并在累积足够可信线索后确定其类别,随后将结果广播给置信度较低的实例。Transformer 中的多头注意力机制(Vaswani 等 2017)恰好契合此思路,具备长程建模能力。给定序列 Z,将查询、键、值矩阵分别记为 Q、K、V,则自注意力计算为
SA(Z) = softmax(A) V,其中 A = QKᵀ / √d,
d 为 Q(与 K)特征维度。并行堆叠 m 个自注意力即得多头注意力:
MSA(Z) = concat(SA₁(Z), SA₂(Z), …, SAₘ(Z))。
现代两阶段视频检测器通常通过 RPN(Ren 等 2015)获取用于特征聚合的候选区域。以 RelationNet(Hu 等 2018)为例,其首次将多头注意力引入静态目标检测,将一系列提议作为输入,并应用 ROI-Pooling 或 ROI-Align 提取区域特征。然而,单阶段检测器直接对特征图进行密集预测,若将区域级特征聚合简单迁移到整张特征图,计算开销巨大。为此,我们提出一种有效策略,先筛选适用于多头注意力的特征。
FSM:特征选择模块
由于大多数预测置信度较低,单阶段检测器的检测头天然适合从特征图中筛选高质量候选。借鉴 RPN 流程,我们先按置信度取 top-k(如 750)预测,再经 NMS 保留固定数量 a(如 30)个预测,以消除冗余。随后收集这些预测对应的特征,用于后续精炼。实践中发现,若直接聚合分类分支收集的特征并回传聚合特征的分类损失,训练会不稳定:聚合模块权重随机初始化,若从头微调全网络,将破坏预训练权重。为此,我们冻结基础检测器除检测头线性投影层外的全部权重,并在模型颈部新增两个 3×3 卷积层构成“视频目标分类分支”,生成用于聚合的特征。随后将来自视频分类分支与回归分支的收集特征输入特征聚合模块。
FAM:特征聚合模块
记 F = {C₁, C₂, …, C_f ; R₁, R₂, …, R_f} 为 FSM 选出的特征集,其中 C_i ∈ ℝ^{dq×a}、R_i ∈ ℝ^{dq×a} 分别表示第 i 帧在视频分类分支与回归分支的特征,dq 为每个 RoI 的特征维度,f 为相关帧数目。广义余弦相似度是计算特征间相似度或注意力权重最常用的度量(Wu 等 2019;Shvets、Liu 与 Berg 2019;Deng 等 2019)。单纯依赖余弦相似度会选出与目标最相似的特征,但当目标存在退化时,这些参考提议很可能具有相同退化,我们称此现象为同质化问题。
首先回顾我们方法中的原始 QK 注意力。类似 Vaswani 等(2017),构建查询、键、值矩阵并输入多头注意力。例如,Qc、Qr 分别由所有相关帧中分类分支与回归分支特征堆叠而成:
Qc = LP([C₁, C₂, …, C_f]ᵀ) ∈ ℝ^{fa×d},
Qr = LP([R₁, R₂, …, R_f]ᵀ) ∈ ℝ^{fa×d},
LP(·) 为将 dq 维特征投影到 d 维的线性映射,其余类似。通过缩放点积注意力得到
Ac = Qc Kcᵀ / √d,Ar = Qr Krᵀ / √d。
为解决同质化问题,我们进一步引入原始检测器预测的置信度 P ∈ ℝ^{2×fa} = {P₁, P₂, …, P_f},其中每个 P_i 包含分类得分与 IoU 得分。为将这些得分融入注意力权重,我们将 P 的两行分别重复 fa 次构建矩阵 Sr、Sc ∈ ℝ^{fa×fa}。于是,分类与回归分支的自注意力变为
SAc(C) = softmax(Sc ∘ Ac) Vc,
SAr(R) = softmax(Sr ∘ Ar) Vc,
其中 ∘ 表示 Hadamard 积。该操作使注意力不仅考虑查询与键的相似度,也关注键的质量。由于主要目标是精炼分类,SAc(C) 与 SAr(R) 共享同一值矩阵 Vc。实验表明,将原始 QK 方式替换为式(3)(称为亲和方式)可显著提升视频检测器性能。此外,我们将 Vc 与式(3)输出拼接,以更好保留初始表示:
SA(F) = concat(SAc(C) + SAr(R), Vc)。
由于长时序范围内位置信息帮助有限(Chen 等 2020),未嵌入位置信息。
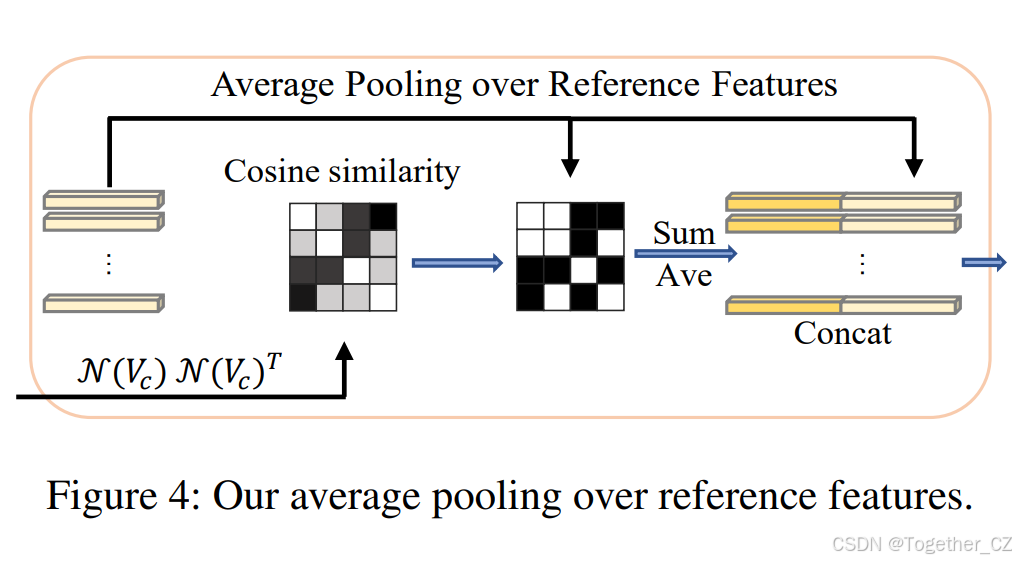
此外,考虑到 softmax 特性,少数参考可能占据大部分权重,导致低权重参考被忽略,限制了参考特征的多样性。为此,我们引入参考特征平均池化(A.P.):选取相似度高于阈值 τ 的所有参考,对其特征进行平均池化。此处相似度通过 N(Vc)N(Vc)ᵀ 计算,N(·) 表示层归一化,确保数值范围一致,消除尺度差异。平均池化后的特征与关键特征共同输入一线性投影层,完成最终分类。流程如图 4 所示。
4 实验验证
实现细节
与先前工作一致,我们使用 YOLOX 官方提供的 COCO 预训练权重来初始化基线检测器。参照 (Zhu et al. 2017a; Wu et al. 2019; Gong et al. 2021),我们把 ImageNet VID 中的视频与 ImageNet DET 中同类别的视频合并作为训练数据。具体而言,ImageNet VID(Russakovsky et al. 2015)包含 3,862 段训练视频和 555 段验证视频,共 30 个类别,是 ImageNet DET 200 个基本类别 (Russakovsky et al. 2015) 的子集。考虑到视频帧存在冗余,我们在 VID 训练集中随机采样 1/10 的帧,而非使用全部。基线检测器在 2 张 GPU 上以 SGD 训练 7 个 epoch,batch size 设为 16。学习率采用 YOLOX 的 cosine schedule,1 个 epoch warmup,最后 2 个 epoch 关闭强数据增强。
将特征聚合模块接入基线检测器后,我们在单张 2080Ti GPU 上继续微调 150 K 步,batch size 仍为 16。其中前 15 K 步为 warmup,其余步数使用 cosine 学习率。仅对 YOLOX 预测头的线性投影层、新增的视频目标分类分支以及多头注意力部分进行微调。训练特征聚合模块时,帧数 f 设为 16,NMS 阈值 0.75 用于粗粒度特征选择;生成最终检测框时,NMS 阈值改为 0.5 以保留更多高置信候选。训练阶段,图像尺寸在 352×352 到 672×672 之间以 32 为步长随机缩放;测试阶段统一缩放到 576×576。
评价指标为 AP50 与推理速度,分别衡量精度与效率。除特殊说明外,所有模型均在 2080Ti GPU 上以 FP16 精度测试。
消融实验
-
参考帧采样策略
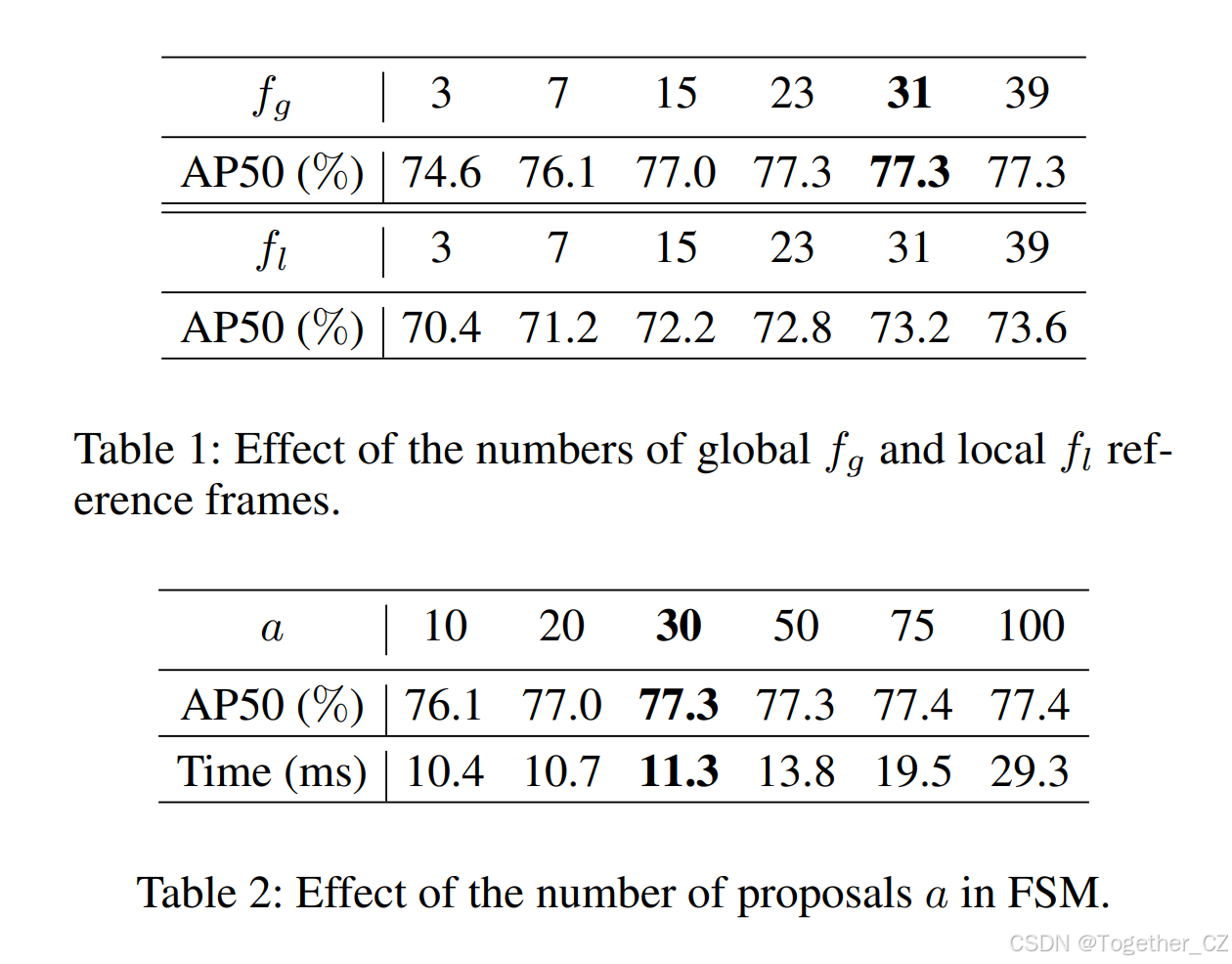
对视频目标检测器而言,研究帧采样策略以平衡精度与效率至关重要。已有两阶段方法 (Wu et al. 2019; Gong et al. 2021; Chen et al. 2020) 讨论了全局与局部两种采样方案:全局采样(fg)从整段视频中随机选帧;局部采样(fl)取关键帧前后连续若干帧。表 1 展示了不同 fg 与 fl 设置下的结果:仅 3 帧全局采样已优于 39 帧局部采样,与 (Wu et al. 2019; Gong et al. 2021) 的结论一致。权衡后,后续实验默认采用 fg = 31 的全局采样。 -
单帧候选提议数量
在 FSM 中,我们将每帧保留的最高置信候选数 a 从 10 调至 100。表 2 显示,随着 a 增大,精度持续提升并在 75 左右饱和。由于自注意力复杂度为 O(n²),候选过多会显著增加耗时。权衡后取 a = 30,远低于两阶段方法 RDN (Deng et al. 2019) 使用的 75。 -
参考特征平均池化阈值
表 3 给出不同阈值 τ 的影响:τ = 0(全部参与平均池化)时 AP50 仅 73.1%;τ 提高到 [0.75, 0.85] 区间,精度稳定在 77.3%;τ = 1 时退化为仅复制 SA(F),精度降至 76.9%。动态阈值是未来工作,后续实验默认 τ = 0.75。 -
FAM 有效性验证
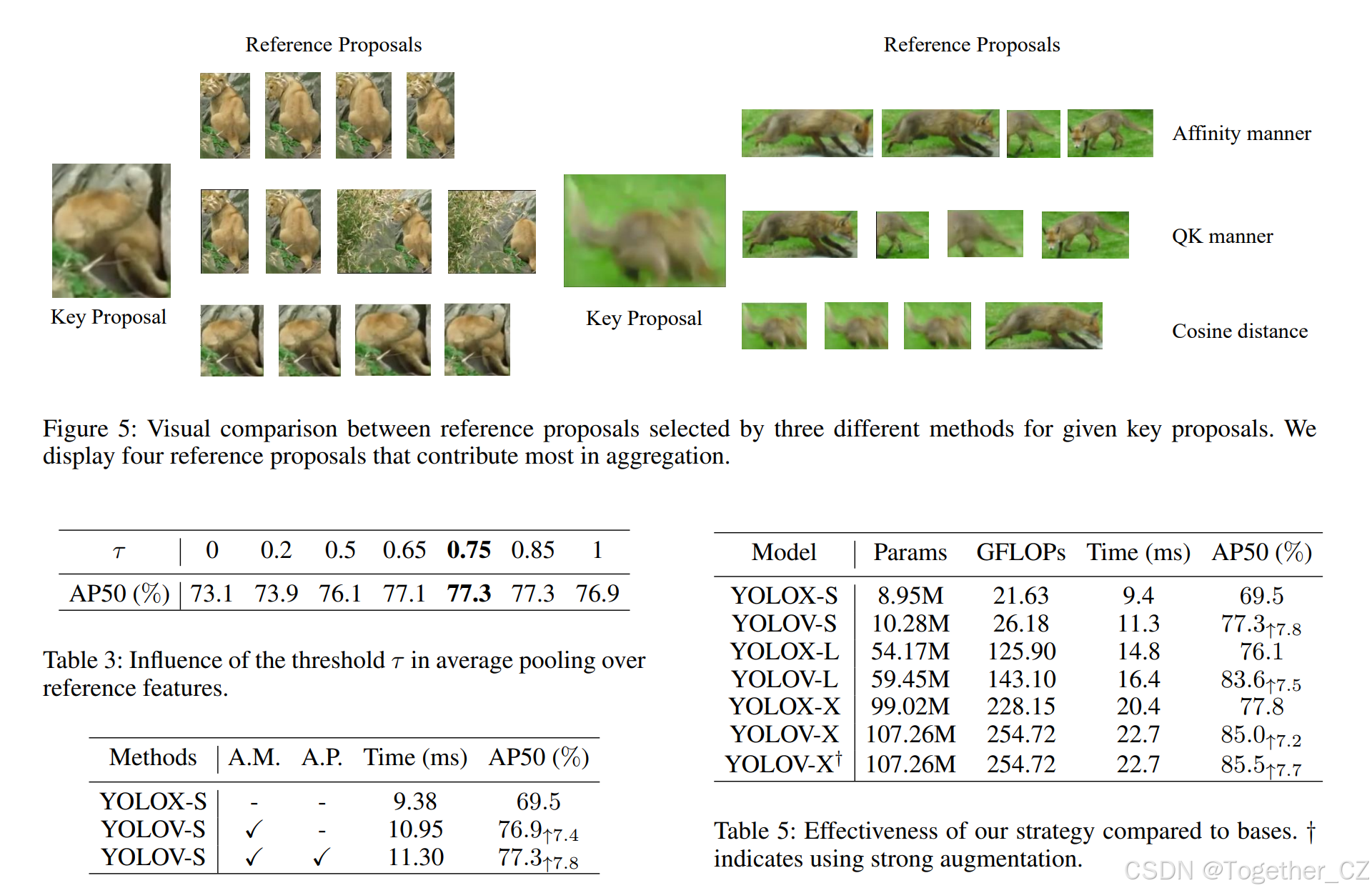
表 4 显示,仅使用亲和方式 (A.M.) 的 YOLOV-S 相对 YOLOX-S (69.5% AP50) 提升 7.4%;同时加入 A.M. 与平均池化 (A.P.) 的完整 YOLOV-S 达到 77.3% AP50,仅比仅用 A.M. 增加约 2 ms。表 5 进一步展示在 YOLOX-L 与 YOLOX-X 上的结果,† 表示微调时启用强增强(MixUp、Mosaic)。YOLOV 相对各基线均提升 7% 以上 AP50。图 5 给出狮子罕见姿态与狐狸运动模糊两个示例,直观展示 FAM 优越性:余弦相似度选出的参考框与关键框退化一致;QK 方式有所缓解,但仍次于亲和方式。引入置信度后,我们的方法能选出更优参考框,显著提升精度。
与最新方法比较
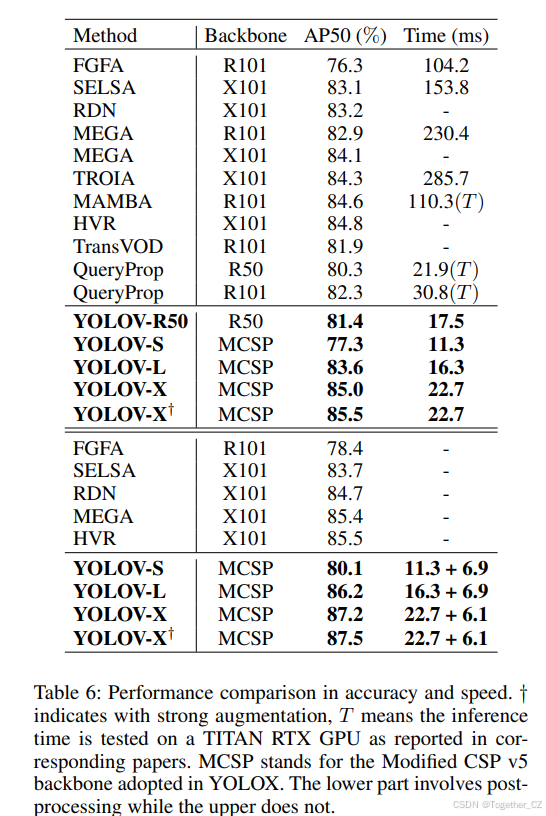
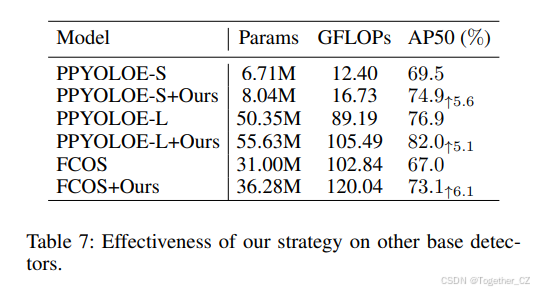
表 6 汇总了 FGFA (Zhu et al. 2017a)、SELSA (Wu et al. 2019)、RDN (Deng et al. 2019)、MEGA (Chen et al. 2020)、TROIA (Gong et al. 2021)、MAMBA (Sun et al. 2021)、HVR (Han et al. 2020)、TransVOD (He et al. 2021)、QueryProp (He et al. 2022) 等方法。我们的方法单帧耗时 21.1 ms 即可达 85.5% AP50;结合 REPP 后处理 (Sabater et al. 2020) 再花 6 ms,可提升至 87.5% AP50。推理效率远高于其他方法。为排除仅因更强骨干带来的提升,我们也给出 ResNet-50 结果。表 6 上半部分为无后处理结果,YOLOV 在精度与效率上均领先;下半部分为有后处理结果,后处理耗时在 i7-8700K CPU 上测得。
推广至其他基线检测器
为验证策略的通用性,我们将其应用于 PPYOLOE (Xu et al. 2022) 与 FCOS (Tian et al. 2019)。PPYOLOE 在各 FPN 层级通道数不同,我们将其检测头各尺度通道统一降至最小值以实现多尺度聚合;FCOS 原使用 5 级 FPN,针对 ImageNet VID 改为 3 级,最大下采样 32。其余训练超参与 YOLOX 保持一致。表 7 显示,我们的策略在两种基线上均能带来 5% 以上 AP50 提升;进一步搜索更适配的超参有望获得更好结果。
5 结论
本文提出了一种兼顾效率与精度的实用视频目标检测器。通过设计特征聚合模块以利用时序信息,并将区域选择移至单阶段预测之后,显著降低了计算开销。大量实验与消融研究验证了策略的有效性,性能超越现有最佳方法。核心思想简洁通用,有望启发后续研究并拓宽视频目标检测的应用场景。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)