论文笔记:EDITING MODELS WITH TASK ARITHMETIC
2023 ICLR。
2023 ICLR
1 INTRO
- 预训练模型常被用作机器学习系统的主干网络
- 在实际应用中,我们经常希望在预训练之后对模型进行编辑,以提升下游任务的性能,减轻偏差或不良行为,使模型更符合人类偏好,或用新信息对模型进行更新
- 在本研究中,我们提出了一种基于**任务向量(task vectors)**编辑神经网络的新范式,这些向量编码了完成特定任务所需的信息。
- 受近期关于权重插值的研究启发,我们通过取某任务微调后的模型权重与其对应的预训练模型权重之差,构建出任务向量
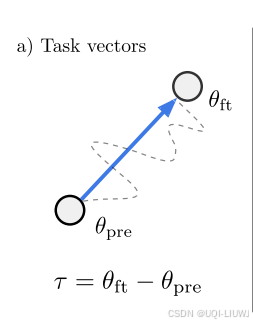
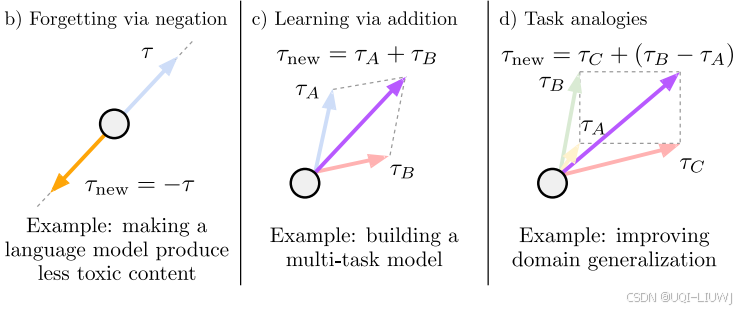
- 论文展示了可以使用**任务算术(task arithmetic)**来编辑各种模型——即对任务向量进行简单的算术运算
- 取向量的相反数可以用来去除不良行为或“遗忘”特定任务
- 将任务向量相加可以构建更强的多任务模型,甚至提升单个任务的性能
- 在任务之间构成类比关系时,组合任务向量还可以在数据稀缺的任务上提升性能
-
总体来看,使用任务算术来编辑模型的方法简单、快速且有效。
-
在推理时没有额外的内存或计算开销,因为我们只在模型权重上进行逐元素运算。
-
此外,向量操作本身开销极低,使得用户可以快速尝试多种任务向量组合。
-
通过任务算术,研究者可以复用或迁移已有模型中的知识,甚至直接利用大量公开可用模型,而无需访问原始数据或进行额外训练。
-
2 任务向量(Task Vectors)


2.1 使用任务算术编辑模型(Editing models with task arithmetic)
关注三类针对任务向量的算术操作,如图1所示:
-
否定任务向量(negating a task vector);
-
相加多个任务向量(adding task vectors together);
-
结合任务向量进行类比推理(combining task vectors to form analogies)。
所有操作都逐元素地作用于权重向量。
3 通过向量取反实现遗忘(Forgetting via Negation)
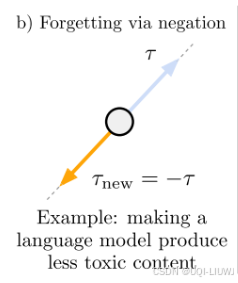
- 在本节中,我们展示了通过对任务向量取负,是一种有效的方法,可降低模型在目标任务上的表现,而不会显著影响其在其他任务上的性能。
- 遗忘或“去学习”(unlearning)可以帮助减轻预训练过程中学习到的有害偏差
- 彻底遗忘某些任务在某些情况下是必要的
- 例如出于合规或伦理原因,不希望图像分类器识别面部信息,或“不希望”其读取个人信息(如 OCR 任务)等
- 这种干预不应对模型处理编辑范围之外的数据行为造成实质影响
- 因此,我们在评估实验效果时,除了关注任务向量来源的目标任务外,也会测量模型在**控制任务(control tasks)**上的准确率。
- 实验展示了通过对任务向量取负,编辑图像分类和文本生成模型的有效性
3.1 图像分类
- 在图像分类任务中,我们使用 CLIP 模型【78】以及来自 Ilharco 等人【39】、Radford 等人【78】研究的 8个任务的任务向量,这些任务涵盖从卫星图像识别到交通标志分类,包括:
-
Cars【47】
-
DTD【12】
-
EuroSAT【36】
-
GTSRB【87】
-
MNIST【51】
-
RESISC45【10】
-
SUN397【101】
-
SVHN【72】
-
-
此外,我们还探索了其他任务,如 OCR 和 人脸识别
-
作为控制任务,我们使用 ImageNet
-
任务向量通过在目标任务上微调模型生成
-
还设置了两个额外的对比基线:
-
在损失函数增加方向上进行微调(即梯度上升)【gradient control】
-
使用 随机向量(其每一层的幅度与真实任务向量对应层相同)作为编辑参考【random vector】
-
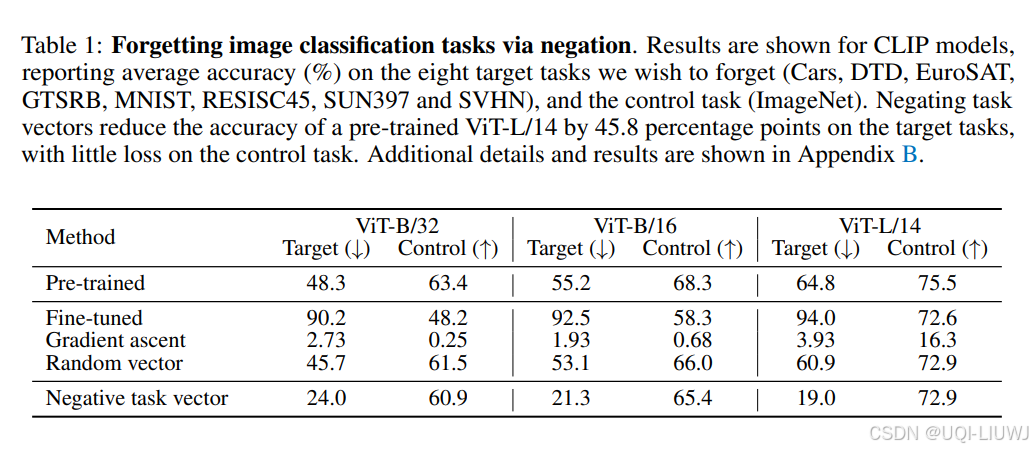
- 如表1所示,对任务向量取负 是降低模型在目标任务准确率的最有效方法,同时对控制任务的性能影响极小。
- 例如,对 ViT-L/14 模型,负向任务向量将目标任务的平均准确率降低了 45.8 个百分点,但对控制任务几乎无影响
- 相比之下,使用随机向量的效果较弱,而使用梯度上升进行微调则严重损害了模型在控制任务上的性能。
3.2 文本生成
- 我们研究是否可以通过取反一个“被训练去产生某种行为”的任务向量,来缓解模型的特定行为
- 具体来说,目标是减少不同大小的 GPT-2 模型产生有毒文本的数量
- 通过在 Civil Comments 数据集上微调模型来生成任务向量。
- 选择 toxicity(毒性)评分高于 0.8 的 Civil Comments 数据作为训练数据,然后对得到的任务向量取反
- 与第 3.1 节类似,设置了几个基线对比方法,包括:
- 使用 梯度上升(gradient ascent) 进行微调
-
使用 与真实任务向量幅度相同的随机向量;
-
使用 toxicity 分数小于 0.2 的 Civil Comments 非毒性样本进行微调
-
用 Detoxify测量模型在生成的 1000 个文本中的毒性比例,作为目标任务评估指标
-
同时在 WikiText-103上测量语言模型的困惑度(perplexity),作为控制任务的指标
- 具体来说,目标是减少不同大小的 GPT-2 模型产生有毒文本的数量
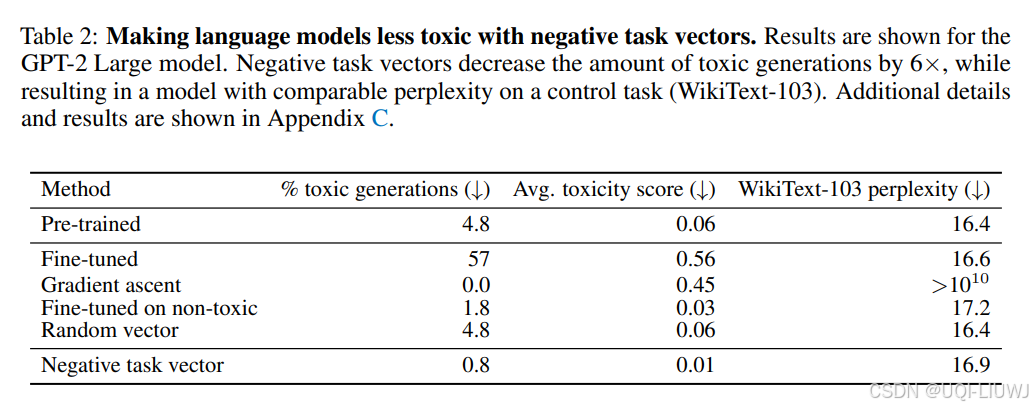
正如表2所示,使用负向任务向量进行编辑是有效的。具体来说:
-
将被分类为有毒的文本比例从 4.8% 降至 0.8%;
-
同时,在控制任务上的困惑度变化保持在预训练模型的 ±0.5 范围内。
相比之下:
-
使用梯度上升虽然也降低了有毒文本的生成,但会严重破坏模型在控制任务上的表现;
-
使用非毒性数据进行微调的效果比任务向量取反更差,无论是在减少毒性文本还是保持控制任务性能方面;
-
使用随机向量则几乎对毒性生成或困惑度没有影响。
这段内容说明:负向任务向量是一种简单而有效的方式,可以降低模型在有害行为上的表现,同时保持其他功能基本不变,相比传统微调方式具有更好的安全性与稳定性。
通俗地讲,相当于这样的实验设定:


4 通过向量相加实现学习(Learning via Addition)
我们现在将注意力转向任务向量的加法操作,其应用包括:
-
构建一个同时擅长多个任务的多任务模型;
-
或者提升单一任务的性能。
4.1 图像分类(Image Classification)
从第 3 节中使用的那 8 个模型出发,这些模型分别在一组多样化的图像分类任务上进行了微调,包括:
-
Cars
-
DTD
-
EuroSAT
-
GTSRB
-
MNIST
-
RESISC45
-
SUN397
-
SVHN
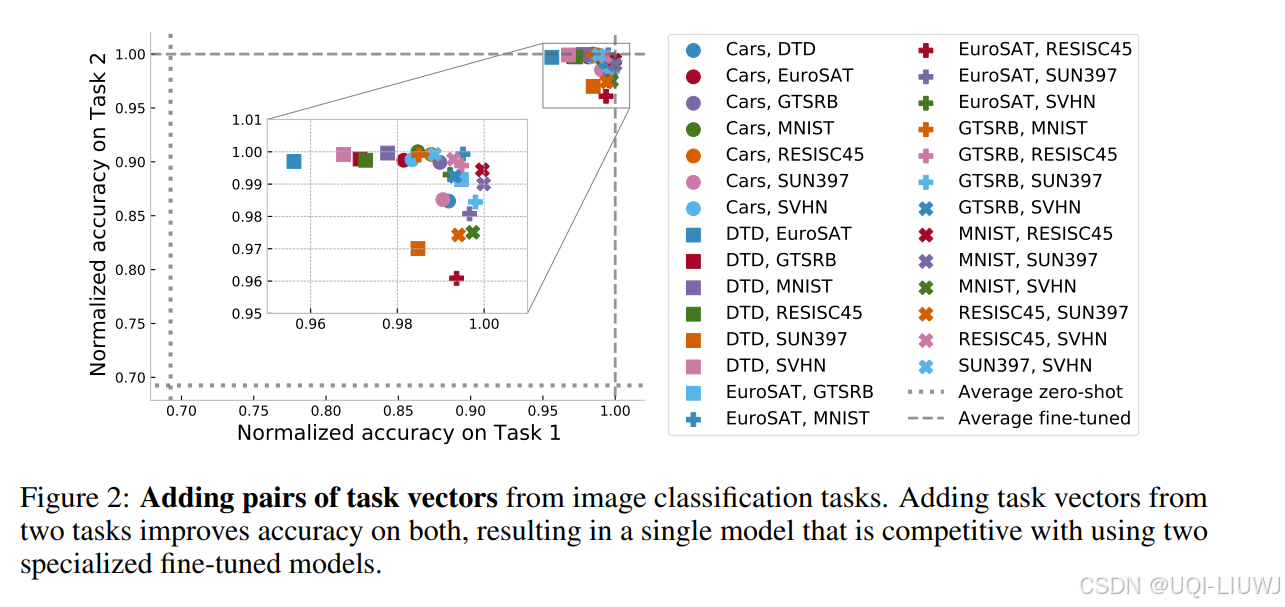
- 在图 2 中,我们展示了对这些任务的所有成对任务向量相加后所获得的模型准确率。
- 为了消除任务之间难度差异的影响,我们对每个任务的准确率进行了归一化处理,即:
- 每个任务的准确率 = 模型在该任务上的准确率 / 该任务专门微调模型的准确率。
- 经过归一化后,每个微调模型在其自身任务上的表现为 1,因此多个专用模型的平均性能为 1。
- 如图 2 所示,将两个任务向量相加所得到的单一模型,准确率远高于 zero-shot 模型(即未做任何微调的模型)
- 并且其性能可以与两个专门微调模型媲美(平均归一化准确率为 98.9%)
- 为了消除任务之间难度差异的影响,我们对每个任务的准确率进行了归一化处理,即:
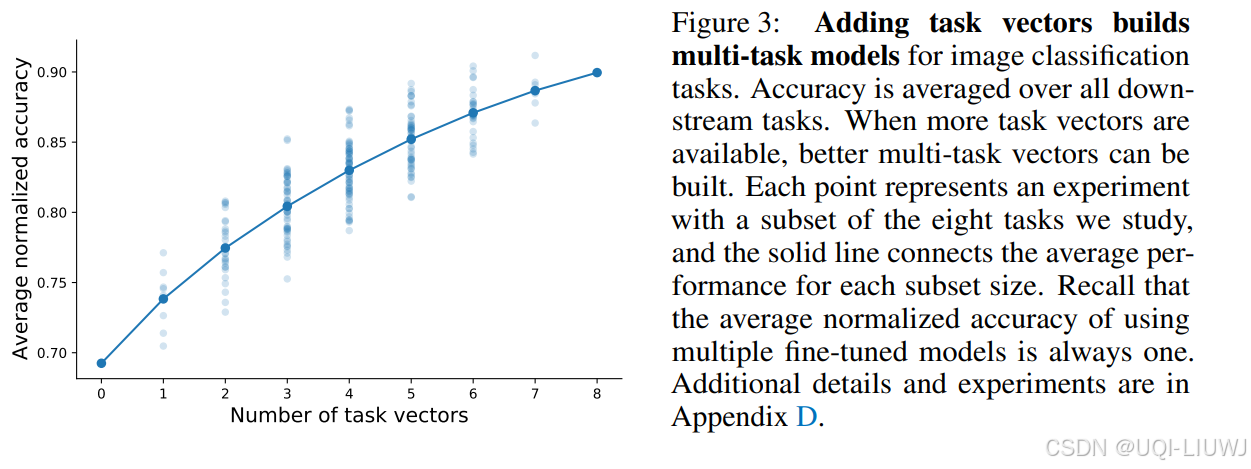
- 不仅是任务对(pairwise),我们还进一步探索了 所有任务子集(共 2^8 = 256个) 的向量加法效果
- 如图 3 所示,我们展示了这些组合模型在 8 个任务上的平均归一化准确率
- 随着可用的任务向量数量增加,构建的多任务模型性能也逐渐提高
- 当使用全部 8 个任务的向量时,通过向量加法得到的最佳模型在 8 个任务上的平均准确率达到了 91.2%,尽管这些任务原本分布在多个独立模型中。
4.2 自然语言处理(Natural Language Processing)
- 除了构建多任务模型之外,我们还探索了通过添加任务向量是否可以提升单个目标任务的性能。
- 为此,首先,在 GLUE 基准测试集中的四个任务上对 T5-base 模型进行微调
- 接着,在 Hugging Face Hub 上搜索兼容的模型检查点(checkpoints),总共找到 427 个候选模型。
- 尝试将这些候选模型对应的任务向量加到我们微调后的模型中,并通过保留的验证集选择最佳的 checkpoint 和缩放系数(scaling coefficient)
- 这是第一次 m+λτ的用法
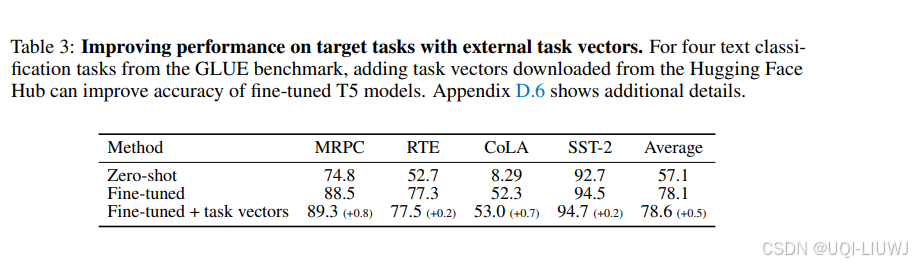
如表 3 所示,与单独微调相比,添加任务向量可以进一步提升目标任务的性能。
5 任务类比(Task Analogies)
- 在本节中,我们探索形式为 “A 之于 B,如同 C 之于 D” 的任务类比关系,并展示:
- 使用前三个任务的向量进行任务算术(task arithmetic)可以提升任务 D 的性能,
即使我们几乎没有该任务的数据。
- 使用前三个任务的向量进行任务算术(task arithmetic)可以提升任务 D 的性能,
5.1 域泛化(Domain Generalization)
- 对于许多目标任务(target task)而言,收集未标注数据要比获取人工标注数据更容易、成本更低。
- 当目标任务缺乏标注数据时,我们可以通过任务类比的方式,用已有的任务向量来提升其性能,方法是利用一个辅助任务(auxiliary task),它拥有标注数据,同时设定一个无监督学习目标。
- 例如,设目标任务是使用 Yelp 数据进行情感分析。我们可以构造一个类比向量如下:

- 这个不好理解的话,可以把右边的yelp项移到左边,得到:
- yelp有标注的数据微调得到的向量-yelp没有标注的数据微调得到的向量=amazon有标注的数据微调得到的向量-amazon没有标注的数据微调得到的向量
-
Fine-tuned on auxiliary
-
在辅助任务上进行微调
-
比如target=Yelp的时候,直接用 Amazon 的情感数据进行微调,然后直接用这个模型去预测 Yelp 的评论情感
-
-
模型从未接触过目标任务的标注数据。
-
-
Task analogies
-
使用“任务类比”构造的向量:
-
-
Fine-tuned on target
-
直接在目标任务(Yelp 或 Amazon)的标注数据上微调;
-
属于最理想的情况(有充足标签数据);
-
是理论最优参考
-
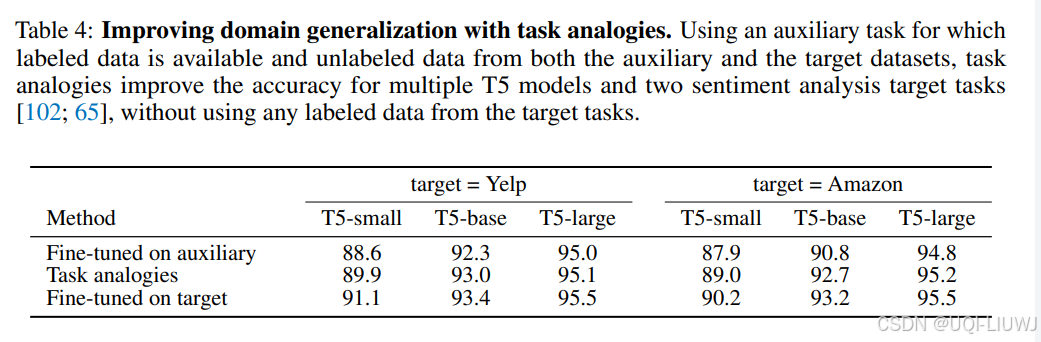
最终实验结果表明,使用任务类比向量优于在辅助任务数据上的直接微调,其性能几乎接近于直接在目标任务上微调所达到的表现。
5.2 数据稀缺子群体
- 某些数据子群体天生就样本稀缺,比如:
- “室内狮子”的图像远少于“室外狮子”;
- “狗”这种类别在不同场景下的样本往往更丰富。
- 当这些稀缺子群体可以与拥有更多数据的子群体形成任务类比关系时,我们就可以通过任务算术来迁移知识,例如:
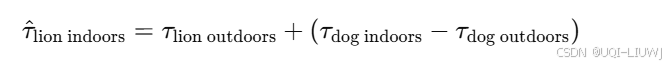
- 即:已知“狗”在室内与室外的差异,我们可以用它来类比得到“狮子在室内”的向量。
- 我们构造了四个子群体(subpopulations),使用了 ImageNet 和手绘素描(sketches)中的 125 个重叠类别
- 这些类别被分为两个子集,每个子集一半,共四个子群体 A、B、C、D,其中:
-
(A, C) 和 (B, D) 是同一组类别(class 相同);
-
(A, B) 和 (C, D) 是同一风格(风格相同,例如照片 vs 素描)。
-
比如:
-
A = “真实狗”
-
B = “真实狮子”
-
C = “素描狗”
-
D = “素描狮子”
-
-
-
给定目标子群体(如“素描狮子”),我们使用其他三个子群体分别进行微调,得到任务向量,然后使用任务类比合成:
-
- 这些类别被分为两个子集,每个子集一半,共四个子群体 A、B、C、D,其中:
-
-
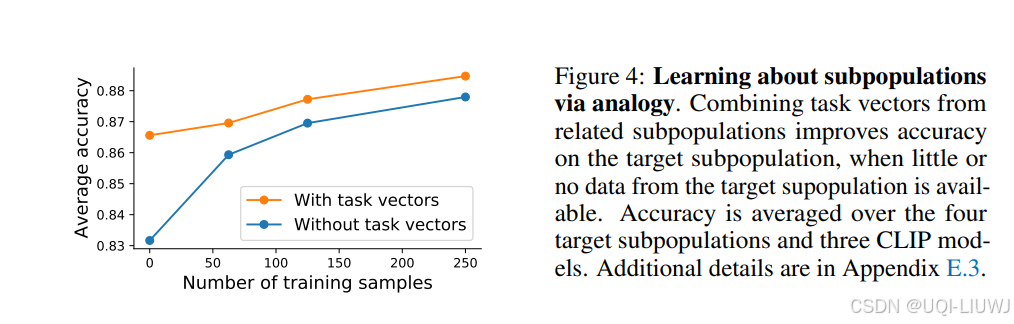
图4中展示了这四个子群体实验的平均结果;
-
与预训练模型相比,类比向量带来的模型平均准确率提升了 3.4 个百分点;
-
如果目标子群体有少量数据可用于微调,从编辑后的模型出发比从预训练模型开始效果更好;
-
类比方法的提升效果,相当于你额外手工标注了约100条样本!
-
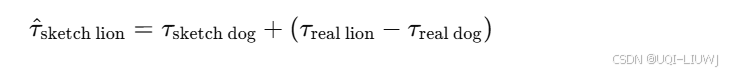
6 讨论
6.1 任务向量之间的相似性

- 图 5 中展示了不同任务之间任务向量的余弦相似度,用以理解为什么多个任务向量可以通过加法“合并”成一个多任务模型
- 观察结果:不同任务的向量通常近似正交(orthogonal),意味着它们之间的干扰较小,可以安全相加。
-
语义相关任务之间的向量更相似,例如:
-
MNIST、SVHN、GTSRB:都是数字识别相关;
-
EuroSAT、RESISC45:都是遥感图像分类任务。
-
-
推论:这种“任务空间”中的相似性有助于解释 Ilharco 等人 [39] 的结果,即:
-
即使对目标任务没有数据,只要应用一个语义相关任务的向量,也可能提高其准确率(如使用 MNIST 向量提升 SVHN)。
-
6.2 学习率的影响
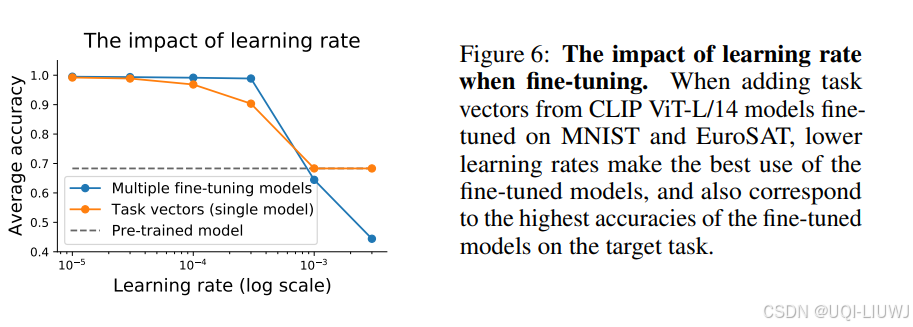
图 6 探讨了学习率对精度的影响,比较了:
-
使用任务向量进行模型编辑;
-
直接对模型进行微调。
观察发现:
-
精度都会随学习率增加而下降;
-
对于单独微调模型而言,下降较缓;
建议:使用任务向量时,建议采用较小学习率,尤其是处理 NLP 任务时(这些任务的模型多来自社区,训练策略可能不同)

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)