CogVLM- Visual Expert for Pretrained Language Models. NIPS 2024 CogVLM:预训练语言模型的视觉专家 论文阅读笔记
我们介绍CogVLM,一个强大的开源视觉语言基础模型。与流行的浅层对齐方法不同,后者将图像特征映射到语言模型的输入空间,CogVLM通过在注意力层和全局注意力层中引入可训练的视觉专家模块,弥合了预训练语言模型与图像编码器之间的差距。因此,CogVLM实现了视觉语言特征的深度融合,同时在自然语言处理任务上不牺牲任何性能。
CogVLM- Visual Expert for Pretrained Language Models.
作者:Weihan Wang, Qingsong Lv, Wenmeng;年份2024
撰写者:麦麦要早起
1 摘要:
我们介绍CogVLM,一个强大的开源视觉语言基础模型。与流行的浅层对齐方法不同,后者将图像特征映射到语言模型的输入空间,CogVLM通过在注意力层和全局注意力层中引入可训练的视觉专家模块,弥合了预训练语言模型与图像编码器之间的差距。因此,CogVLM实现了视觉语言特征的深度融合,同时在自然语言处理任务上不牺牲任何性能。CogVLM-17B在15个经典跨模态基准上实现了最先进性能,包括:1) 图像描述数据集:NoCaps、Flicker30k,2)VQA 数据集:OKVQA、ScienceQA,3) LVLM 基准:MM-Vet、MMBench、SEED-Bench、LLaVABench、POPE、MMMU、MathVista,4) 视觉定位数据集:RefCOCO、RefCOCO+、RefCOCOg、Visual7W。代码和检查点可在 GitHub 上获取。
2 主要贡献
- 我们提出CogVLM模型,该模型深度融合视觉与语言特征,同时保留预训练大型语言模型的全部能力。基于Vicuna-7B训练的CogVLM-17B,在17个经典跨模态基准测试中均达到最先进水平。
- 通过广泛的消融研究,我们验证了所提视觉专家模块的有效性以及深度融合的重要性。我们进一步探讨了多模态相关中的多个关键因素,包括视觉编码器的规模、注意力掩码的变体VLM中最具影响力的参数,以及引入自监督图像损失的必要性等。
- 我们已将CogVLM的权重和SFT阶段使用的数据集向公众开放。我们预计CogVLM的开源将显著推动视觉理解领域的科研与工业应用。
3 方法
本文就作者提出的CogVLM 模型架构,有四个核心组件组成用于实现视觉与语言的深度融合,下面就相关概念和基本知识予以介绍。
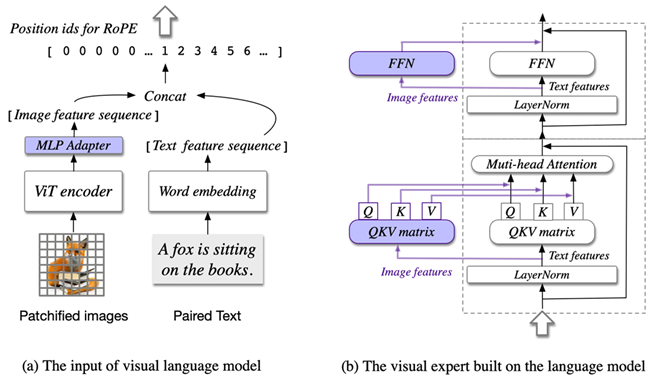
图1.CogVLM架构
3.1. 架构(四个核心组件)
3.1.1. ViT 编码器(视觉编码:使用EVA2-CLIP-E编码器)
EVA2-CLIP-E 被广泛用作多模态大模型(如 CogVLM 系列)的视觉编码器,使用预训练模型 EVA2-CLIP-E,移除 ViT 的最后一层(原用于对比学习的 [CLS] 聚合)。输出图像的 patch-level 特征 token。
模型性质:EVA2-CLIP-E 是一种视觉编码器(Vision Encoder),属于 CLIP(Contrastive Language-Image Pretraining) 系列的改进版本,由 BAAI(北京智源研究院)开发。它基于 EVA-02 架构,通过大规模对比学习实现图像与文本的跨模态对齐
下图为传统版本的VIT模型,摘自李宏毅机器学习网课:(模型使用摘走了传统VIT最后一层,使用CLS可以去判断每个patch的图像类别)
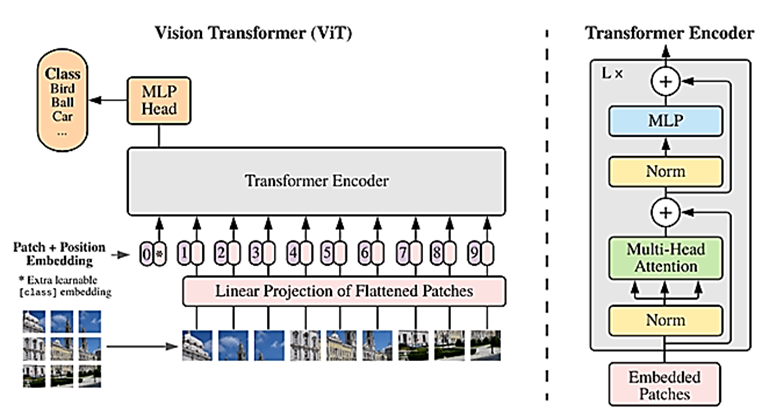
图2.传统的VIT
这张图展示了Vision Transformer (ViT) 的架构和工作原理。以下是逐步解释:
输入处理:输入图像被分割成多个小块(patches),每个小块被展平(flattened)并通过线性投影层转换为嵌入向量(embedded patches)。为了保留位置信息,每个小块的嵌入向量会添加位置嵌入(position embedding)。额外添加一个可学习的分类嵌入(class embedding,记为[class]),用于后续的分类任务。
Transformer Encoder:这些嵌入向量被输入到Transformer Encoder中,Encoder包含多层(L×)的处理单元。每层包括多头注意力机制(Multi-Head Attention)和多层感知机(MLP),中间通过归一化层(Norm)连接。多头注意力机制帮助模型关注图像不同部分之间的关系,MLP进一步处理特征。
输出处理:Transformer Encoder的输出经过归一化(Norm)后,[class]嵌入被提取出来。
[class]嵌入通过MLP Head进行处理,最终输出分类结果(如Bird、Car、Ball等)。
3.1.2. MLP 适配器
一个 两层的 MLP(采用 SwiGLU 激活)。将 ViT 输出映射到语言模型输入空间(维度一致)。所有图像 token 共享同一个位置编码(position ID),这样可以:避免序列过长(图像可能产生数百 token)防止因位置偏移导致文本 token 只关注图像的“靠近部分”
SwiGLU激活函数
SwiGLU(Swish-Gated Linear Unit)是一种结合了Swish激活函数和门控线性单元(GLU)的混合激活函数,近年来被广泛应用于Transformer架构及大型语言模型(如LLaMA、PALM等)中。
数学定义
![]()
(a=xW_1+b_1 )和(b=xW_2+b_2 ) 是两个线性变换的输出。
(Swish(x)=x⋅sigmoid(βx)),通常取(β=1),此时等价于SiLU激活函数。
(⊗)表示逐元素乘积(Hadamard积)。
核心特性
门控机制:通过Swish激活的权重动态调节信息流,过滤不重要信息;
平滑性:Swish的连续可导性缓解了ReLU的梯度消失问题;
非单调性:允许模型捕捉更复杂的非线性模式;
参数效率:相比传统FFN(ReLU + 线性层),SwiGLU通过门控减少冗余计算。
3.1.3. 预训练大语言模型(LLM)
CogVLM 可兼容任意 GPT 架构的大语言模型。实验中采用 Vicuna-1.5-7B(32层transformer layer)。所有 attention 操作使用 causal mask,包括图文之间的注意力。
Vicuna 的工作流程如图所示。最初,研究人员从 ShareGPT.com(一个专门用于用户分享 ChatGPT 对话内容的在线平台)中收集了大约 70,000 个对话样本,并对 Alpaca 提供的原始训练脚本进行了显著的改进和优化,以更好地应对多轮对话的复杂性以及处理长序列数据的挑战。这些改进使得模型在面对连续性较强的对话场景时能够表现出更高的适应性和准确性。整个模型的完整微调训练过程在一天的时间内顺利完成,依托了配备 8 卡 A100 GPU 的强大计算资源,并结合 PyTorch FSDP(Fully Sharded Data Parallel)技术,确保了高效的分布式训练和资源利用。为了能够向公众提供一个直观且实用的演示服务,Vicuna 团队精心设计并搭建了一个轻量级的分布式服务系统。与此同时,他们针对八个不同的问题类别(例如角色扮演、编码任务以及数学问题等)精心设计并生成了 80 个多样化且具有代表性的问题样本,并利用先进的 GPT-4 模型对 Vicuna 的输出结果进行了全面而细致的初步质量评估。通过这种方式,团队能够更客观地衡量模型的性能和可靠性。为了进一步比较两个不同模型的表现,研究人员将每种模型针对同一问题的回答整合成一个单一的提示内容,随后将这些提示内容提交给 GPT-4 进行评估。最终,由 GPT-4 基于其判断标准来确定哪个模型在响应质量上更胜一筹,从而为模型的优化和改进提供了宝贵的参考数据。
3.1.4. 视觉专家模块(Visual Expert Module)
对原有的语言模型,不变动其整体transformer架构,对每一层 Transformer 都引入一个 视觉专家模块,包括:一组可训练的 QKV 权重,一组可训练的 FFN 前馈网络。
权重结构与原语言模型相同,并从中初始化。图像 token 使用视觉专家的 QKV/FFN,文本 token 使用原 LLM 的参数(冻结)。
实现方式:
图文 token 分开计算 Q、K、V,然后拼接进行 cross-modal attention:
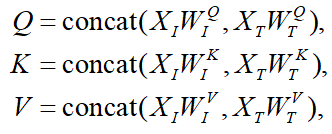
FFN 层也是图文分别处理,再拼接:
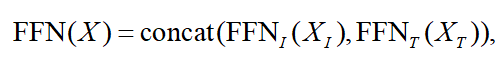
最后计算attention :
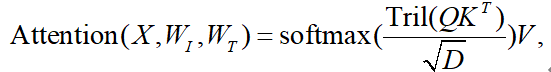
这一部分是本文创新最关键的点,他在不变动语言模型的情况下(在语言模型性能不变前提下),让图像和文本融合,达到了相比之前Q-former方法更好的性能。
3.2 预训练流程
CogVLM 采用两阶段训练策略,在大规模公开图文数据上进行视觉-语言对齐和语义理解建模。
数据集(Data)
图文对预训练数据:共计约 15 亿张图像,来源:LAION-2B、COYO-700M,经过清洗:去除失效链接、NSFW、不良内容、政治倾向、长宽比过极端的图片(>6 或 <1/6)
视觉指代数据(Visual Grounding, 4000 万张):每张图像中的 名词都关联对应的边界框(bounding box) 使用 spaCy 提取名词, 使用 GLIPv2 预测其边界框
数据来源:从 LAION-115M 中筛选出质量高的样本,确保 75% 图像至少有两个框
训练流程(Training)
阶段一:图像描述任务(Image Captioning)
- 任务目标:预测文本中的下一个 token(语言建模)
- 数据量:使用前述的 15 亿图文对
- 训练轮数:120,000 步
- batch size:8192
阶段二:图文混合训练(Caption + Referring Expression)
- 任务混合:
- 图像描述(继续)
- Referring Expression Comprehension (REC):给定物体描述,预测边界框
- 格式为类 VQA 问答
- 示例:
- Qestion: "Where is the object?"
- Answer: "[[x0,y0,x1,y1]]",坐标为归一化整数 [000–999]
- 损失计算:仅对 Answer 中 token 执行 next-token loss
- 训练轮数:60,000 步
- batch size:1024
- 最后 30,000 步图像分辨率从 224×224 提升为 490×490(提升定位精度)
4 实验
为全面验证 CogVLM 模型的多模态理解与生成能力,作者在一系列标准基准数据集上开展了系统性实验。实验主要聚焦于以下四大方向:图像描述、图文问答、多模态综合评估以及视觉指代任务,展示了模型在通用性与多样任务下的鲁棒性能。
首先,在图像描述(Image Captioning)任务中,CogVLM 在 NoCaps、COCO、Flickr30K 以及 TextCaps 等多个数据集上进行了评估。该任务的目标是生成能够准确描述图像主要内容的自然语言文本。CogVLM 在所有测试集上均取得了领先的 CIDEr 分数,优于此前如 SimVLM、BLIP-2、PaLI 等代表性模型。这一结果表明 CogVLM 在文本生成质量和视觉语义理解方面具有强大的能力。
其次,在视觉问答(Visual Question Answering, VQA)任务中,CogVLM 的表现同样出色。通过对 VQAv2、OKVQA 和 ScienceQA 等经典问答数据集的评估,CogVLM 展现出对图像中复杂语义信息的理解能力,尤其在 ScienceQA 等需要背景知识和推理的任务中表现尤为突出。相比其他基于 Vicuna 或 LLaMA 的多模态模型,如 InstructBLIP、LLaVA 和 Qwen-VL,CogVLM 在多个指标上均取得了更优结果,凸显其在语言与视觉信息深度融合方面的优势。
第三,作者在一系列多模态评估基准(LVLM Benchmarks)上对 CogVLM 进行了多维度的性能测试。这些基准包括 MM-Vet、SEED-Bench、MMBench、LLaVA-Bench、POPE、MMMU 和 MathVista 等,涵盖了图像分类、对象识别与定位、视觉常识问答、OCR、数学推理等任务。CogVLM 在多个基准上取得了当前最佳(state-of-the-art)性能,展现出其作为通用多模态模型的强大泛化能力。尤其是在 MathVista 和 MMMU 等高难度推理数据集上,CogVLM 远超其他同时期模型,验证了其对跨模态复杂语义的处理潜力。
最后,在视觉指代(Visual Grounding)任务上,CogVLM 也取得了优异结果。该类任务要求模型能将文本中的实体(如“左边的男人”“蓝色的包”)正确地与图像中的区域进行对齐。评估采用了多个标准数据集,如 Visual7W、RefCOCO、RefCOCO+ 和 RefCOCOg。CogVLM 在这些数据集上的表现显示其对细粒度图文关系的建模能力较强,尤其在模糊或复杂指代情况下也能保持稳定性能。
总体而言,CogVLM 通过统一的模型架构与视觉专家模块设计,实现了在图文深度对齐、跨模态推理和指代理解方面的全面突破。实验证明该模型不仅在常规任务上取得了领先,还具备良好的迁移与泛化能力,具备成为下一代通用多模态基础模型的潜力。
5 总结
CogVLM 在多项主流多模态任务上进行了全面实验,涵盖图像描述、图文问答、视觉指代和多模态推理等方向。在图像描述任务中,CogVLM 在 COCO、NoCaps 等数据集上取得了最高 CIDEr 分数,展示出优秀的图像内容理解与语言生成能力。在视觉问答方面,模型在 VQAv2、OKVQA 和 ScienceQA 等多种问答形式下表现稳健,尤其在需要推理能力的任务中明显优于同类模型。进一步地,CogVLM 在一系列多模态评估基准(如 MM-Vet、MMBench、MathVista 等)中取得全面领先,表明其具备处理复杂跨模态任务的能力。最后,在视觉指代任务中,CogVLM 能准确将文本短语与图像区域对齐,体现出其对图文深度对齐的建模能力。总体来看,CogVLM 实验结果充分验证了其作为通用型视觉语言模型的优越性能与强大泛化能力。
6 个人评价
- 它不仅在架构设计上兼顾了视觉与语言的深度融合,还通过引入视觉专家模块,实现了更精细的特征对齐与交互。设计精巧,不伤害语言模型性能。
- 采用大规模图文对预训练配合视觉指代监督,有效增强了模型的泛化能力与实用性。从实验结果来看,无论是图像描述、问答推理还是视觉定位,CogVLM 都展现出领先的性能,充分体现了其作为通用型多模态基础模型的潜力。
- 这是一篇在方法创新与实验效果上都非常扎实的工作,对后续多模态模型的设计具有较强的参考价值。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)