Redis主从复制拓扑全解析:从单点备份到跨地域容灾,一文掌握高可用架构
三层决策模型真实性能数据拓扑结构最大读QPS故障恢复时间数据丢失风险一主一从8万手动(分钟级)高一主三从24万30秒中Sentinel15万5秒低异地多活20万+秒级接近零🚀行动指南:根据业务需求选择拓扑,在下一个项目中使用Sentinel实现自动故障转移!🌟扩展阅读Redis官方复制文档。
·
当你的Redis扛不住百万级流量时,单点架构已到尽头!主从复制拓扑是构建高可用Redis的基石!
一、为什么需要主从复制?🤔
单节点Redis的致命短板: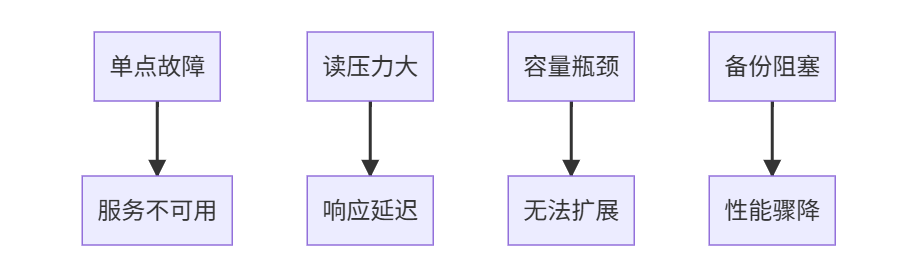
主从复制的核心价值:
- 📊 读写分离:主节点写,从节点读,吞吐量提升5倍+
- 🛡️ 数据冗余:多副本防止数据丢失
- ⚡ 故障转移:主节点宕机秒级切换
- 🌐 异地容灾:跨机房部署保障业务连续
二、主从复制核心原理 🧠
1. 初次同步流程
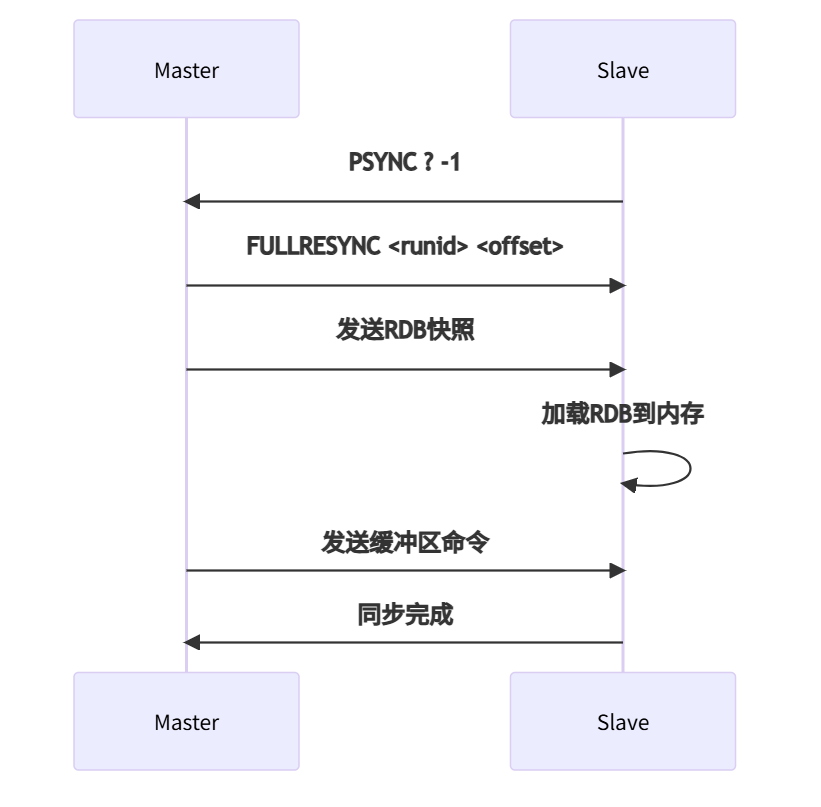
2. 增量同步机制

关键参数:
# redis.conf
repl-backlog-size 1gb # 缓冲区大小
repl-backlog-ttl 3600 # 超时时间
client-output-buffer-limit slave 512mb 128mb 60 # 输出缓冲区
三、六大主从拓扑结构详解 🏗️
1️⃣ 一主一从:基础备份方案
适用场景:
- 中小型业务
- 容灾备份需求
- 读写分离入门
配置命令:
# 在从节点执行
SLAVEOF 192.168.1.100 6379
优势:
- 部署简单
- 资源消耗低
劣势:
- 从节点故障导致读不可用
- 主节点压力未分散
2️⃣ 一主多从:读高并发方案
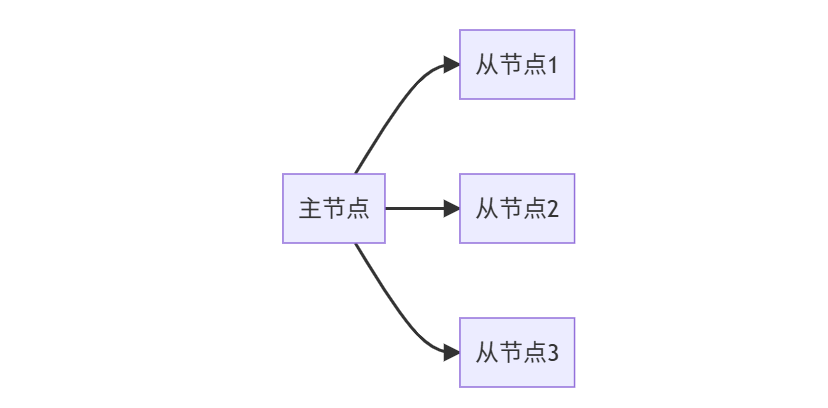
适用场景:
- 读密集型应用(如资讯网站)
- 多客户端共享读负载
- 多机房读服务
性能提升:
| 从节点数 | 读QPS上限 | 网络带宽 |
|---|---|---|
| 1 | 5万 | 100Mbps |
| 3 | 15万 | 300Mbps |
| 5 | 25万+ | 500Mbps |
代码示例(负载均衡):
from redis import Redis
from random import choice
slaves = [
Redis(host='slave1', port=6379),
Redis(host='slave2', port=6379),
Redis(host='slave3', port=6379)
]
def read_data(key):
"""随机选择从节点读取"""
slave = choice(slaves)
return slave.get(key)
3️⃣ 树状主从:超大集群方案
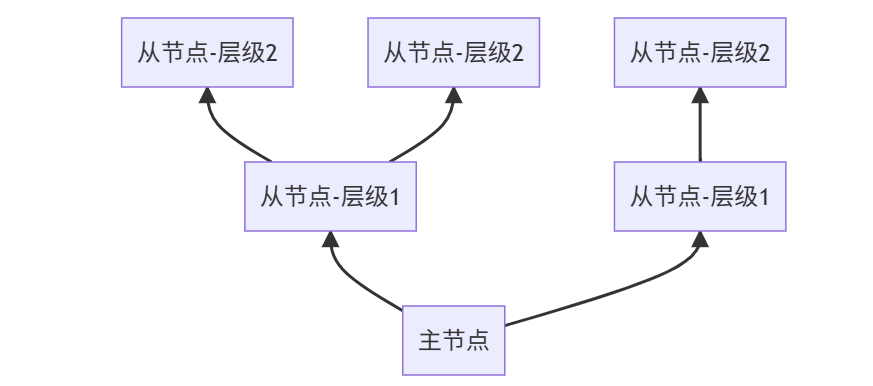
适用场景:
- 超大规模集群(100+节点)
- 跨地域部署
- 网络带宽受限环境
优势:
- 减少主节点网络压力
- 分层扩展无上限
配置命令:
# 二级从节点连接一级从节点
SLAVEOF 192.168.1.101 6379
4️⃣ 双主互备:金融级方案
适用场景:
- 金融交易系统
- 双向数据同步需求
- 零数据丢失场景
实现方案:
# 使用Redis-Shark双向同步工具
./redis-shark -m 192.168.1.100:6379 -s 192.168.1.200:6379
⚠️ 警告:需解决数据冲突!
# 冲突解决策略(时间戳优先)
def resolve_conflict(key, value1, value2):
ts1 = extract_timestamp(value1)
ts2 = extract_timestamp(value2)
return value1 if ts1 > ts2 else value2
5️⃣ 异地多活:全球业务方案
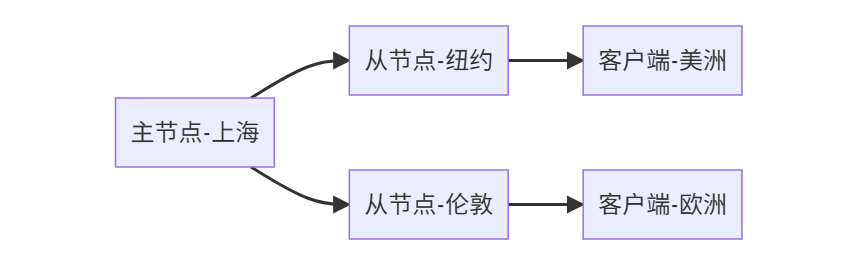
延迟优化:
| 线路 | 上海→纽约 | 上海→伦敦 |
|---|---|---|
| 光纤直连 | 130ms | 110ms |
| 普通网络 | 280ms+ | 250ms+ |
配置技巧:
# 调整复制超时
repl-timeout 60 # 默认60秒,跨洲可增大
6️⃣ 级联故障转移:Sentinel集群
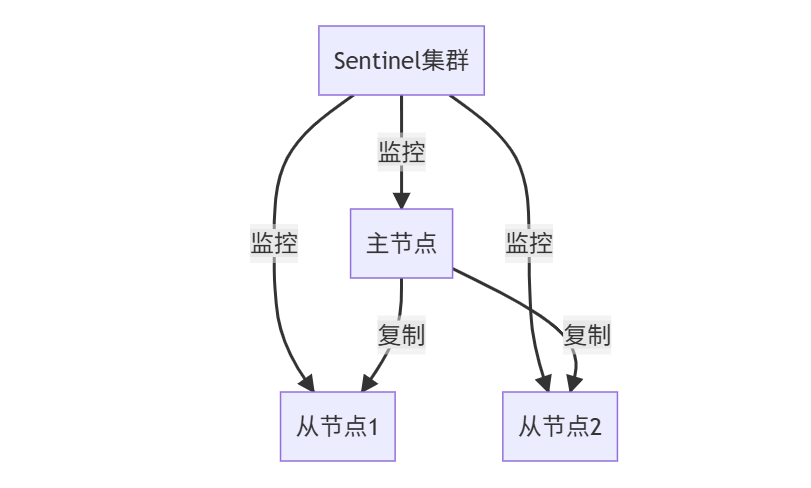
自动故障转移流程: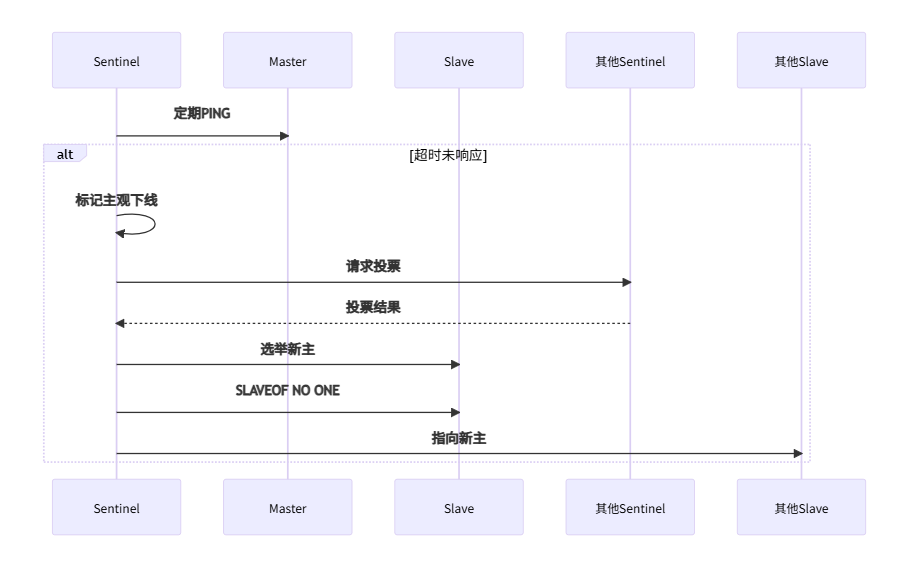
四、拓扑结构对比决策表 📊
| 拓扑类型 | 适用规模 | 读写分离 | 故障恢复 | 部署复杂度 | 典型场景 |
|---|---|---|---|---|---|
| 一主一从 | 1-5万QPS | ★★☆ | 手动 | ★☆☆ | 博客系统 |
| 一主多从 | 5-20万QPS | ★★★ | 半自动 | ★★☆ | 电商大促 |
| 树状主从 | 20万+QPS | ★★★ | 困难 | ★★★ | 全球社交应用 |
| 双主互备 | 金融级 | 不适用 | 自动 | ★★★★ | 支付系统 |
| 异地多活 | 跨国业务 | ★★★ | 自动 | ★★★★ | 国际游戏平台 |
| Sentinel | 1-10万QPS | ★★★ | 全自动 | ★★☆ | 中小高可用集群 |
五、实战:搭建树状主从集群 🌲
1. 环境准备
| 角色 | IP | 端口 |
|---|---|---|
| 主节点 | 192.168.1.100 | 6379 |
| 一级从节点 | 192.168.1.101 | 6379 |
| 二级从节点 | 192.168.1.102 | 6379 |
2. 配置主从关系
# 在一级从节点(101)执行
redis-cli -h 192.168.1.101 SLAVEOF 192.168.1.100 6379
# 在二级从节点(102)执行
redis-cli -h 192.168.1.102 SLAVEOF 192.168.1.101 6379
3. 验证拓扑状态
# 查看主节点信息
redis-cli -h 192.168.1.100 INFO replication
# 输出:
# connected_slaves:2
# slave0:ip=192.168.1.101,port=6379,state=online
# slave1:ip=192.168.1.102,port=6379,state=online
六、五大避坑指南 ⚠️
1. 复制风暴问题
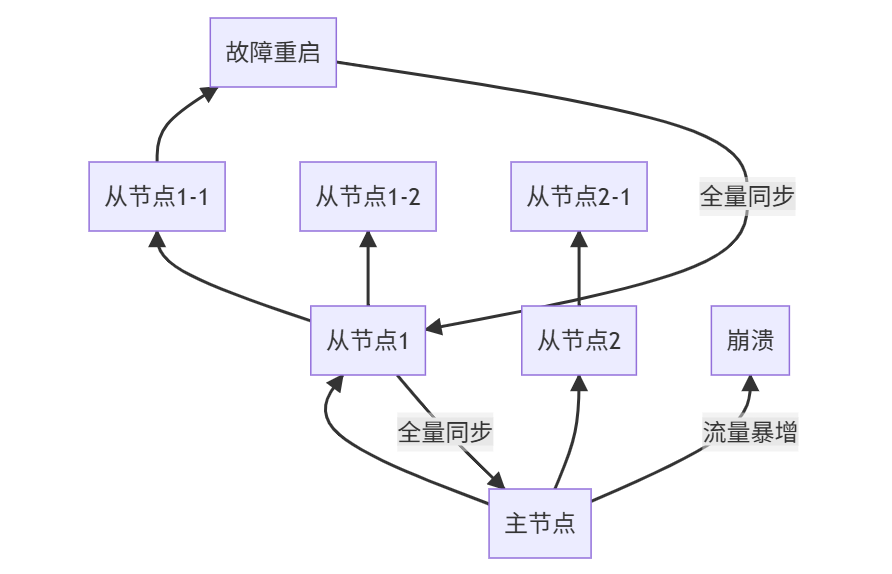
解决方案:
- 设置不同复制周期
- 树状结构控制深度
2. 主从数据不一致
检测命令:
# 对比主从数据差异
redis-cli -h master DEBUG DIGEST | grep CRC
redis-cli -h slave DEBUG DIGEST | grep CRC
3. 脑裂问题
配置参数:
min-slaves-to-write 1 # 至少1个从节点
min-slaves-max-lag 10 # 从节点延迟≤10秒
4. 无限同步循环
优化方案:
repl-diskless-sync yes # 无盘复制
repl-diskless-sync-delay 5 # 等待更多从节点
5. 从节点只读限制
解除写限制(危险!):
# 在从节点执行
CONFIG SET slave-read-only no
七、未来演进:从主从到集群 🚀
当主从架构无法满足时:
迁移时机:
- 数据量 > 500GB
- 写入QPS > 10万
- 需要自动分片
结语:架构选型黄金法则 🏆
三层决策模型:
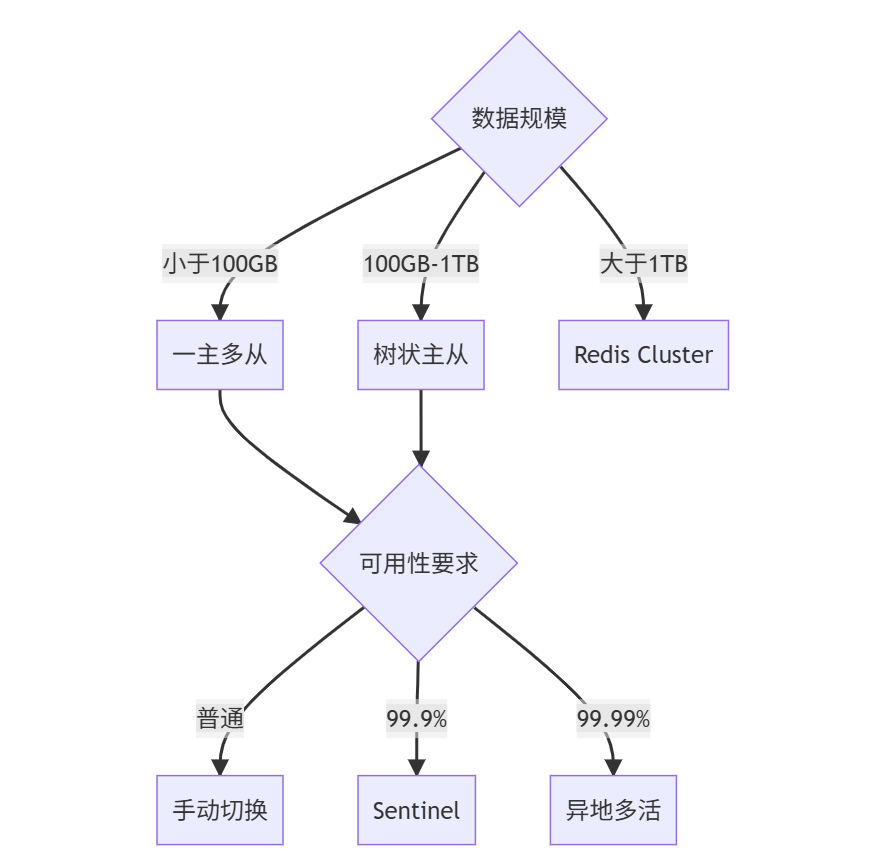
真实性能数据(基于32核128G环境):
| 拓扑结构 | 最大读QPS | 故障恢复时间 | 数据丢失风险 |
|---|---|---|---|
| 一主一从 | 8万 | 手动(分钟级) | 高 |
| 一主三从 | 24万 | 30秒 | 中 |
| Sentinel | 15万 | 5秒 | 低 |
| 异地多活 | 20万+ | 秒级 | 接近零 |
🚀 行动指南:根据业务需求选择拓扑,在下一个项目中使用Sentinel实现自动故障转移!
🌟 扩展阅读:

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 74
74 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)