论文阅读——ProxylessNAS:直接在目标任务和硬件上进行神经架构搜索
本文提出ProxylessNAS方法,直接在目标任务和硬件上高效进行神经架构搜索。传统NAS依赖代理任务导致迁移性能下降,且计算成本高。ProxylessNAS通过路径二值化技术,在训练时仅激活单条路径,显著降低内存需求;配合两路径采样策略,将GPU内存需求降至与普通训练相当。此外,该方法创新性地将硬件延迟建模为可微目标,实现端到端优化。实验表明,ProxylessNAS在ImageNet上搜索的
ProxylessNAS:直接在目标任务和硬件上进行神经架构搜索
Cai H, Zhu L, Han S. Proxylessnas: Direct neural architecture search on target task and hardware[J]. arXiv preprint arXiv:1812.00332, 2018.
第一章 引言与研究背景
神经架构搜索(NAS)在自动化神经网络架构设计方面取得了显著成功,特别是在图像识别和语言建模等深度学习任务中。然而,传统NAS算法的计算成本极其高昂,需要在目标任务上训练数千个模型,单次实验就需要10410^4104 GPU小时。这种计算密集性使得直接将NAS应用于大规模任务(如ImageNet)变得极其昂贵甚至不可能。
作为折中方案,Zoph等人提出在代理任务上搜索构建块的策略——包括训练更少的epoch、从较小的数据集(如CIFAR-10)开始,或使用更少的块进行学习。然后将表现最好的块堆叠并迁移到大规模目标任务。这种范式被后续的NAS算法广泛采用。然而,这些在代理任务上优化的块无法保证在目标任务上也是最优的,特别是当考虑延迟等硬件指标时。更重要的是,为了实现可迁移性,这些方法需要只搜索少数几个架构模式然后重复堆叠相同的模式,这限制了块的多样性并损害了性能。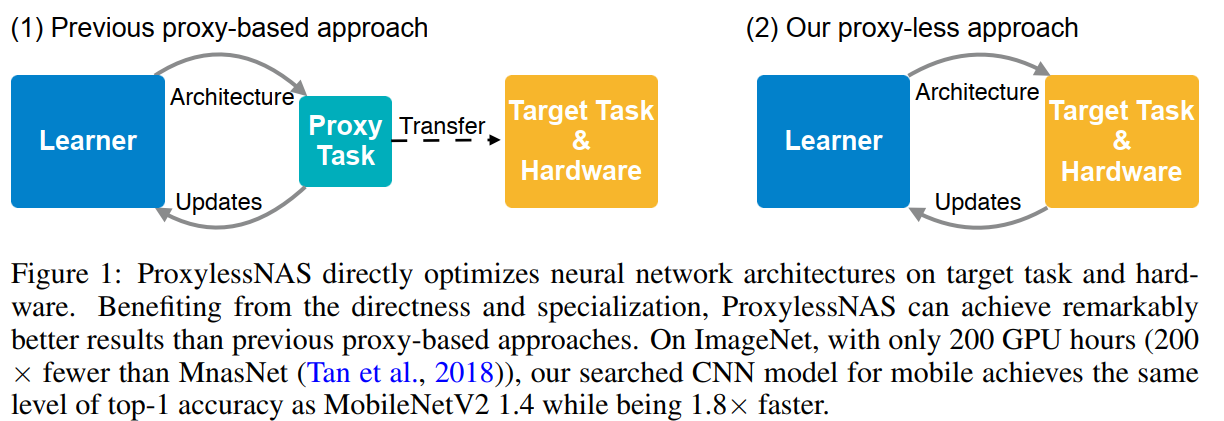
图1描述:该图展示了ProxylessNAS与传统基于代理的方法的对比。左侧显示传统方法需要先在代理任务上学习,然后迁移到目标任务和硬件;右侧显示ProxylessNAS直接在目标任务和硬件上优化架构。图中还包含了三种不同NAS方法的GPU小时数和GPU内存对比:普通训练的NAS需要元控制器和代理;DARTS和One-shot不需要元控制器但需要代理;ProxylessNAS既不需要元控制器也不需要代理。
第二章 方法论详解
2.1 超参数化网络的数学构建
将神经网络表示为有向无环图N(e1,⋯ ,en)\mathcal{N}(e_1, \cdots, e_n)N(e1,⋯,en),其中eie_iei代表图中的某条边。设O={oi}i=1NO = \{o_i\}_{i=1}^NO={oi}i=1N为包含NNN个候选原始操作的集合,包括各种卷积、池化、恒等映射和零操作。为了构建包含搜索空间中任何架构的超参数化网络,不将每条边设置为确定的原始操作,而是设置为具有NNN条并行路径的混合操作mOm_OmO。
在One-Shot方法中,给定输入xxx,混合操作mOm_OmO的输出定义为:
mOOne-Shot(x)=∑i=1Noi(x)m_O^{\text{One-Shot}}(x) = \sum_{i=1}^{N} o_i(x)mOOne-Shot(x)=i=1∑Noi(x)
在DARTS中,输出是加权和:
mODARTS(x)=∑i=1Npioi(x)=∑i=1Nexp(αi)∑j=1Nexp(αj)oi(x)m_O^{\text{DARTS}}(x) = \sum_{i=1}^{N} p_i o_i(x) = \sum_{i=1}^{N} \frac{\exp(\alpha_i)}{\sum_{j=1}^N \exp(\alpha_j)} o_i(x)mODARTS(x)=i=1∑Npioi(x)=i=1∑N∑j=1Nexp(αj)exp(αi)oi(x)
其中权重通过对NNN个实值架构参数{αi}i=1N\{\alpha_i\}_{i=1}^N{αi}i=1N应用softmax计算得到。
2.2 路径二值化的创新机制
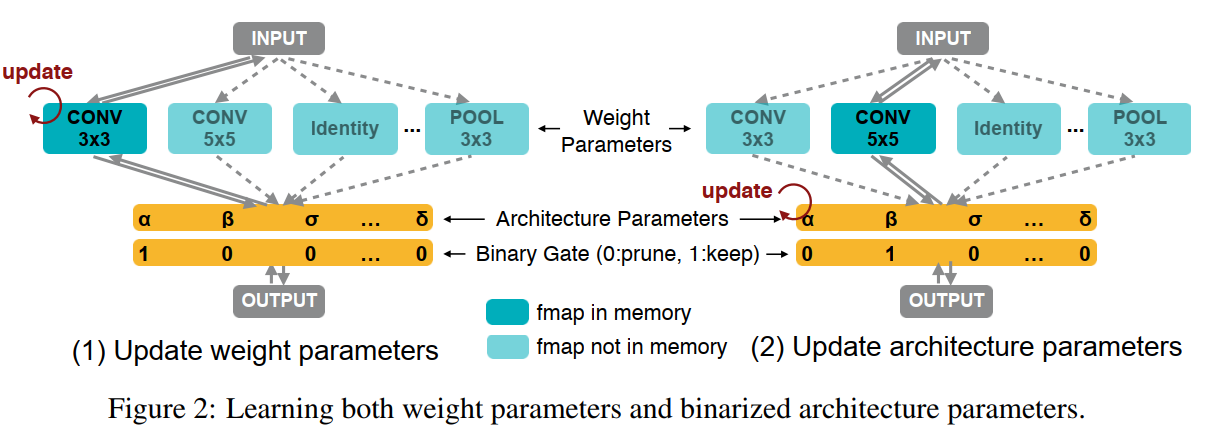
图2描述:该图详细展示了学习权重参数和二值化架构参数的过程。图分为两部分:左侧显示更新权重参数时,架构参数被冻结,二进制门控制哪条路径激活(例如CONV 3x3路径激活,其他路径不在内存中);右侧显示更新架构参数时,权重参数被冻结,不同的路径被激活用于梯度计算。图中用不同颜色区分了在内存中的特征图和不在内存中的特征图。
为了减少内存占用,ProxylessNAS在训练超参数化网络时只保留一条路径。引入NNN个实值架构参数{αi}i=1N\{\alpha_i\}_{i=1}^N{αi}i=1N,然后将实值路径权重转换为二进制门:
g=binarize(p1,⋯ ,pN)={[1,0,⋯ ,0]以概率 p1[0,1,⋯ ,0]以概率 p2⋮⋮[0,0,⋯ ,1]以概率 pNg = \text{binarize}(p_1, \cdots, p_N) = \begin{cases} [1, 0, \cdots, 0] & \text{以概率 } p_1 \\ [0, 1, \cdots, 0] & \text{以概率 } p_2 \\ \vdots & \vdots \\ [0, 0, \cdots, 1] & \text{以概率 } p_N \end{cases}g=binarize(p1,⋯,pN)=⎩ ⎨ ⎧[1,0,⋯,0][0,1,⋯,0]⋮[0,0,⋯,1]以概率 p1以概率 p2⋮以概率 pN
基于二进制门ggg,混合操作的输出为:
mOBinary(x)=∑i=1Ngioi(x)m_O^{\text{Binary}}(x) = \sum_{i=1}^{N} g_i o_i(x)mOBinary(x)=i=1∑Ngioi(x)
由于gi∈{0,1}g_i \in \{0, 1\}gi∈{0,1}且∑i=1Ngi=1\sum_{i=1}^N g_i = 1∑i=1Ngi=1,在任何时刻只有一条路径被激活。
2.3 二值化架构参数的梯度推导
架构参数不直接参与前向计算图,因此不能使用标准梯度下降更新。借鉴BinaryConnect的思想,使用∂L/∂gi\partial L/\partial g_i∂L/∂gi来近似∂L/∂pi\partial L/\partial p_i∂L/∂pi:
∂L∂αi=∑j=1N∂L∂pj∂pj∂αi≈∑j=1N∂L∂gj∂pj∂αi\frac{\partial L}{\partial \alpha_i} = \sum_{j=1}^{N} \frac{\partial L}{\partial p_j} \frac{\partial p_j}{\partial \alpha_i} \approx \sum_{j=1}^{N} \frac{\partial L}{\partial g_j} \frac{\partial p_j}{\partial \alpha_i}∂αi∂L=j=1∑N∂pj∂L∂αi∂pj≈j=1∑N∂gj∂L∂αi∂pj
对于softmax函数,有:
pj=exp(αj)∑k=1Nexp(αk)p_j = \frac{\exp(\alpha_j)}{\sum_{k=1}^N \exp(\alpha_k)}pj=∑k=1Nexp(αk)exp(αj)
其对αi\alpha_iαi的导数为:
∂pj∂αi=pj(δij−pi)\frac{\partial p_j}{\partial \alpha_i} = p_j(\delta_{ij} - p_i)∂αi∂pj=pj(δij−pi)
其中δij\delta_{ij}δij是Kronecker delta函数(当i=ji=ji=j时为1,否则为0)。
因此:
∂L∂αi=∑j=1N∂L∂gjpj(δij−pi)\frac{\partial L}{\partial \alpha_i} = \sum_{j=1}^{N} \frac{\partial L}{\partial g_j} p_j(\delta_{ij} - p_i)∂αi∂L=j=1∑N∂gj∂Lpj(δij−pi)
2.4 两路径采样的内存优化策略
直接计算∂L/∂gj\partial L/\partial g_j∂L/∂gj需要计算并存储oj(x)o_j(x)oj(x),这仍然需要NNN倍的GPU内存。ProxylessNAS的关键创新是将从NNN个候选中选择一条路径的任务分解为多个二元选择任务。直觉是:如果某条路径在特定位置是最佳选择,那么当它与任何其他路径单独比较时,它应该是更好的选择。
在架构参数的每次更新步骤中:
- 根据多项分布(p1,⋯ ,pN)(p_1, \cdots, p_N)(p1,⋯,pN)采样两条路径
- 屏蔽所有其他路径,候选数量临时从NNN减少到2
- 相应地重置路径权重{pi}\{p_i\}{pi}和二进制门{gi}\{g_i\}{gi}
- 使用梯度公式更新这两条采样路径的架构参数
- 重新缩放更新后的架构参数值,保持未采样路径的权重不变
第三章 处理硬件指标的算法设计
3.1 延迟建模与可微化
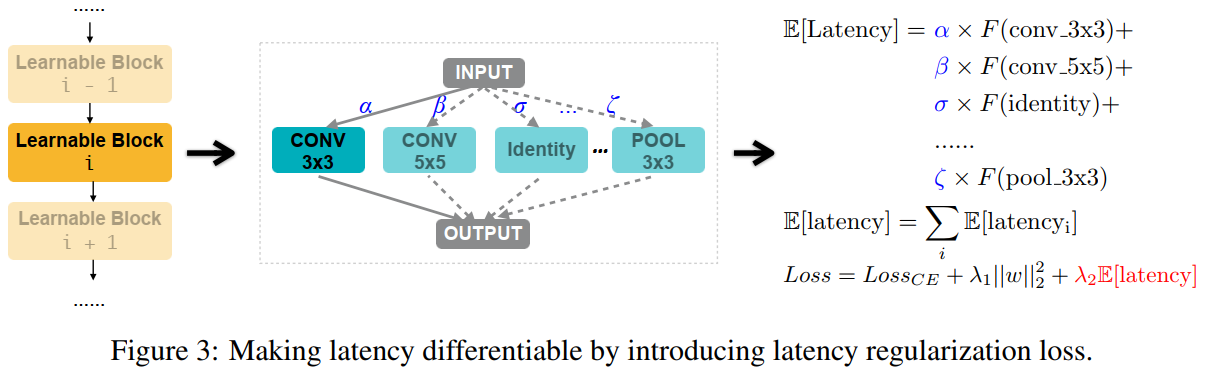
图3描述:该图展示了如何通过引入延迟正则化损失使延迟可微。左侧显示了网络结构,包含一系列可学习块,每个块都有多个候选操作(CONV 3x3、CONV 5x5、Identity、POOL 3x3等)。右侧显示了延迟计算公式:每个块的期望延迟是各操作延迟的加权和,整个网络的期望延迟是所有块期望延迟的总和,最终损失函数包含交叉熵损失、权重衰减和延迟正则化项。
将网络延迟建模为神经网络维度的连续函数。对于具有候选集{oj}\{o_j\}{oj}的混合操作,每个ojo_joj关联路径权重pjp_jpj,表示选择ojo_joj的概率。可学习块(即混合操作)的期望延迟为:
E[latencyi]=∑jpji×F(oji)E[\text{latency}_i] = \sum_{j} p_j^i \times F(o_j^i)E[latencyi]=j∑pji×F(oji)
其中E[latencyi]E[\text{latency}_i]E[latencyi]是第iii个可学习块的期望延迟,F(⋅)F(\cdot)F(⋅)表示延迟预测模型,F(oji)F(o_j^i)F(oji)是ojio_j^ioji的预测延迟。
E[latencyi]E[\text{latency}_i]E[latencyi]对架构参数的梯度为:
∂E[latencyi]∂pji=F(oji)\frac{\partial E[\text{latency}_i]}{\partial p_j^i} = F(o_j^i)∂pji∂E[latencyi]=F(oji)
对于包含一系列混合操作的整个网络,由于这些操作在推理时顺序执行,网络的期望延迟表示为:
E[latency]=∑iE[latencyi]E[\text{latency}] = \sum_i E[\text{latency}_i]E[latency]=i∑E[latencyi]
最终的损失函数为:
Loss=LossCE+λ1∥w∥22+λ2E[latency]\text{Loss} = \text{Loss}_{\text{CE}} + \lambda_1\|w\|_2^2 + \lambda_2 E[\text{latency}]Loss=LossCE+λ1∥w∥22+λ2E[latency]
其中LossCE\text{Loss}_{\text{CE}}LossCE表示交叉熵损失,λ1∥w∥22\lambda_1\|w\|_2^2λ1∥w∥22是权重衰减项,λ2>0\lambda_2 > 0λ2>0控制准确性和延迟之间的权衡。
3.2 基于REINFORCE的替代算法
考虑具有二值化参数α\alphaα的网络,更新二值化参数的目标是找到最优二进制门ggg以最大化奖励R(⋅)R(\cdot)R(⋅)。根据REINFORCE算法:
J(α)=Eg∼α[R(Ng)]=∑ipiR(N(e=oi))J(\alpha) = \mathbb{E}_{g\sim\alpha}[R(\mathcal{N}_g)] = \sum_i p_i R(\mathcal{N}(e = o_i))J(α)=Eg∼α[R(Ng)]=i∑piR(N(e=oi))
梯度计算为:
∇αJ(α)=∑iR(N(e=oi))∇αpi=∑iR(N(e=oi))pi∇αlog(pi)\nabla_\alpha J(\alpha) = \sum_i R(\mathcal{N}(e = o_i))\nabla_\alpha p_i = \sum_i R(\mathcal{N}(e = o_i))p_i\nabla_\alpha \log(p_i)∇αJ(α)=i∑R(N(e=oi))∇αpi=i∑R(N(e=oi))pi∇αlog(pi)
=Eg∼α[R(Ng)∇αlog(p(g))]≈1M∑i=1MR(Ngi)∇αlog(p(gi))= \mathbb{E}_{g\sim\alpha}[R(\mathcal{N}_g)\nabla_\alpha \log(p(g))] \approx \frac{1}{M}\sum_{i=1}^{M} R(\mathcal{N}_{g^i})\nabla_\alpha \log(p(g^i))=Eg∼α[R(Ng)∇αlog(p(g))]≈M1i=1∑MR(Ngi)∇αlog(p(gi))
其中gig^igi表示第iii个采样的二进制门,p(gi)p(g^i)p(gi)表示根据公式采样gig^igi的概率,Ngi\mathcal{N}_{g^i}Ngi是根据二进制门gig^igi的紧凑网络。
第四章 实验结果与架构分析
4.1 实验设置
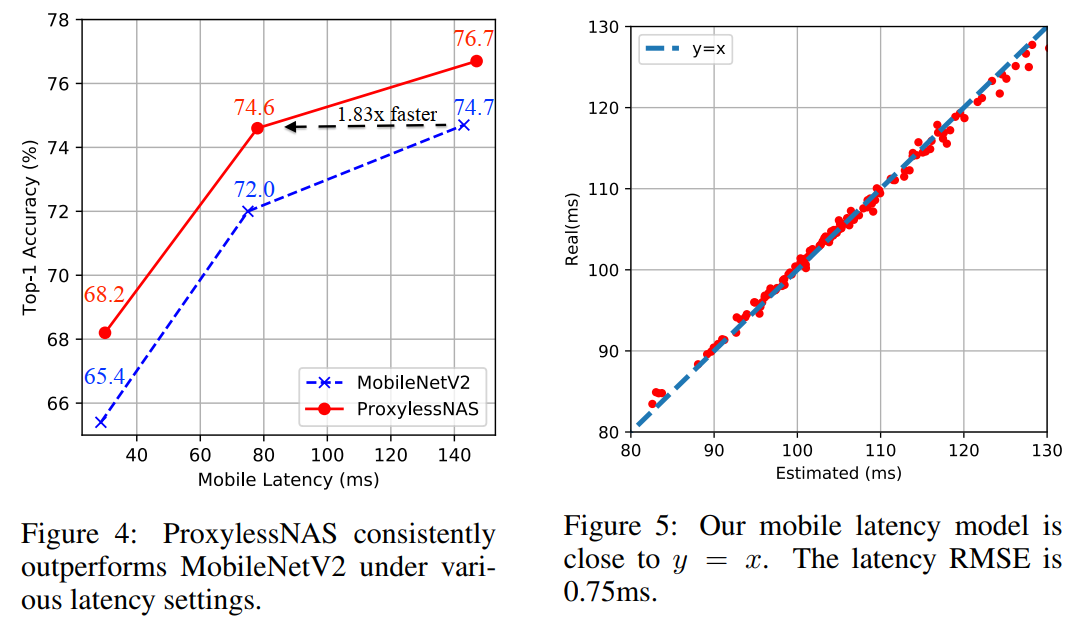
图4和图5描述:图4展示了ProxylessNAS在不同延迟设置下始终优于MobileNetV2的性能对比图。横轴是移动设备延迟(ms),纵轴是Top-1准确率(%)。图中显示ProxylessNAS的模型在各个延迟点都取得了更高的准确率,特别是在相同准确率下,ProxylessNAS比MobileNetV2快1.83倍。图5展示了移动延迟预测模型的准确性,横轴是估计延迟,纵轴是实际测量延迟,点基本沿着y=x线分布,延迟RMSE仅为0.75ms。
在CIFAR-10实验中,使用树形结构架构空间,以PyramidNet为骨干网络。将PyramidNet残差块中的所有3×33 \times 33×3卷积层替换为树形结构单元,每个单元深度为3,每个节点的分支数设置为2(叶节点除外)。
在ImageNet实验中,使用MobileNetV2作为骨干构建架构空间。不是重复相同的移动倒残差卷积(MBConv),而是允许一组具有不同核大小{3,5,7}\{3, 5, 7\}{3,5,7}和扩展比{3,6}\{3, 6\}{3,6}的MBConv层。通过在候选集中添加零操作,允许带残差连接的块被跳过,实现宽度和深度之间的直接权衡。
4.2 专门化架构的硬件差异
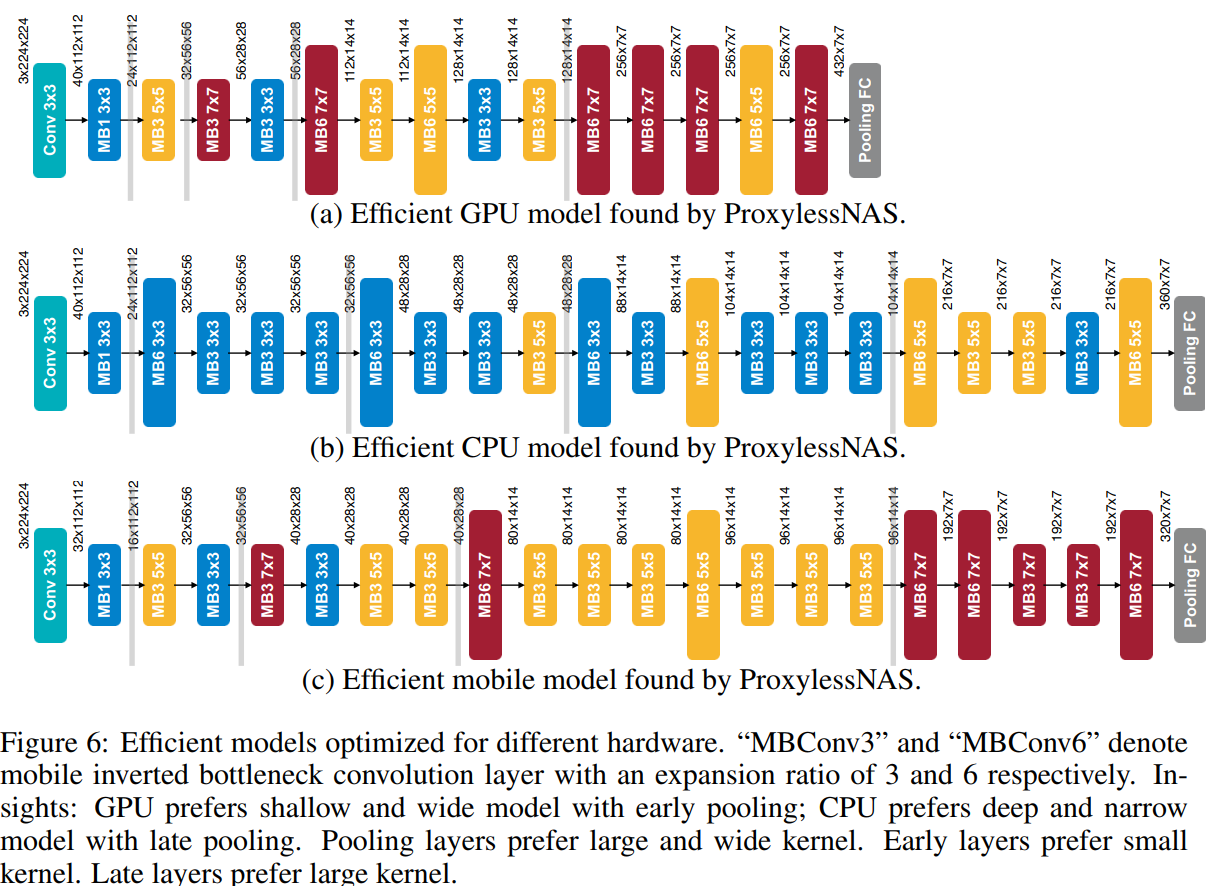
图6描述:该图展示了ProxylessNAS为三种不同硬件平台(GPU、CPU、移动设备)搜索得到的高效模型架构。每个子图都显示了完整的网络结构,从输入到输出,包括各层的操作类型(如MB3 5x5表示扩展比为3的5×5 MBConv)和特征图尺寸。
GPU模型特点:
- 网络更浅更宽,特别是在早期阶段
- 偏好大型MBConv操作(如7×7 MBConv6)
- 在高分辨率特征图阶段使用更宽的通道
CPU模型特点:
- 网络更深更窄
- 偏好较小的MBConv操作(多为3×3)
- 延迟池化操作到网络后期
移动模型特点:
- 在深度和宽度之间取得平衡
- 混合使用不同大小的MBConv操作
- 在下采样位置使用较大的核
所有平台的共同模式是在每个阶段的第一个块(负责下采样)中偏好使用较大的MBConv操作,这可能有助于在下采样时保留更多信息。
4.3 性能对比
在CIFAR-10上,ProxylessNAS达到2.08%的测试误差,仅使用5.7M参数,比之前最佳的AmoebaNet-B(2.13%误差,34.9M参数)减少了6倍参数量。
在ImageNet上的结果:
- 移动设备:74.6% top-1准确率,78ms延迟
- GPU:75.1% top-1准确率,5.1ms延迟
- CPU:75.3% top-1准确率,138.7ms延迟
与MobileNetV2相比,ProxylessNAS在移动设备上将top-1准确率提高了2.6%,同时保持相似的延迟。与MnasNet相比,准确率高0.6%,但搜索成本减少了200倍(200 GPU小时 vs 40,000 GPU小时)。
附录 A:梯度计算
A.1 Softmax梯度
对于softmax函数:
pj=exp(αj)∑k=1Nexp(αk)p_j = \frac{\exp(\alpha_j)}{\sum_{k=1}^N \exp(\alpha_k)}pj=∑k=1Nexp(αk)exp(αj)
设分母为Z=∑k=1Nexp(αk)Z = \sum_{k=1}^N \exp(\alpha_k)Z=∑k=1Nexp(αk),则:
pj=exp(αj)Zp_j = \frac{\exp(\alpha_j)}{Z}pj=Zexp(αj)
当i=ji = ji=j时:
∂pj∂αj=∂∂αj(exp(αj)Z)\frac{\partial p_j}{\partial \alpha_j} = \frac{\partial}{\partial \alpha_j}\left(\frac{\exp(\alpha_j)}{Z}\right)∂αj∂pj=∂αj∂(Zexp(αj))
使用商法则:
=Z⋅exp(αj)−exp(αj)⋅exp(αj)Z2= \frac{Z \cdot \exp(\alpha_j) - \exp(\alpha_j) \cdot \exp(\alpha_j)}{Z^2}=Z2Z⋅exp(αj)−exp(αj)⋅exp(αj)
=exp(αj)Z⋅Z−exp(αj)Z= \frac{\exp(\alpha_j)}{Z} \cdot \frac{Z - \exp(\alpha_j)}{Z}=Zexp(αj)⋅ZZ−exp(αj)
=pj(1−pj)= p_j(1 - p_j)=pj(1−pj)
当i≠ji \neq ji=j时:
∂pj∂αi=∂∂αi(exp(αj)Z)\frac{\partial p_j}{\partial \alpha_i} = \frac{\partial}{\partial \alpha_i}\left(\frac{\exp(\alpha_j)}{Z}\right)∂αi∂pj=∂αi∂(Zexp(αj))
=−exp(αj)⋅exp(αi)Z2= -\frac{\exp(\alpha_j) \cdot \exp(\alpha_i)}{Z^2}=−Z2exp(αj)⋅exp(αi)
=−pjpi= -p_j p_i=−pjpi
综合两种情况:
∂pj∂αi=pj(δij−pi)\frac{\partial p_j}{\partial \alpha_i} = p_j(\delta_{ij} - p_i)∂αi∂pj=pj(δij−pi)
A.2 两路径采样
设路径iii的真实价值为viv_ivi,在完整的NNN路径比较中,最优路径i∗i^*i∗满足:
i∗=argmaxi∈[N]vii^* = \arg\max_{i \in [N]} v_ii∗=argi∈[N]maxvi
在两两比较中,如果i∗i^*i∗确实是最优的,则对于任意j≠i∗j \neq i^*j=i∗:
P(i∗ wins against j)>P(j wins against i∗)P(i^* \text{ wins against } j) > P(j \text{ wins against } i^*)P(i∗ wins against j)>P(j wins against i∗)
通过多次两两比较,可以逐渐增强最优路径的权重。设第ttt次更新后路径iii的权重为pi(t)p_i^{(t)}pi(t),更新规则为:
如果路径iii和jjj被采样,且iii获胜:
αi(t+1)=αi(t)+η⋅∂L∂gi\alpha_i^{(t+1)} = \alpha_i^{(t)} + \eta \cdot \frac{\partial L}{\partial g_i}αi(t+1)=αi(t)+η⋅∂gi∂L
αj(t+1)=αj(t)−η⋅∂L∂gj\alpha_j^{(t+1)} = \alpha_j^{(t)} - \eta \cdot \frac{\partial L}{\partial g_j}αj(t+1)=αj(t)−η⋅∂gj∂L
其中η\etaη是学习率。经过足够多的更新后,最优路径的权重将收敛到最大值。
A.3 延迟预测模型的构建
延迟预测使用以下特征:
- 操作类型(one-hot编码)
- 输入特征图尺寸:(Hin,Win,Cin)(H_{in}, W_{in}, C_{in})(Hin,Win,Cin)
- 输出特征图尺寸:(Hout,Wout,Cout)(H_{out}, W_{out}, C_{out})(Hout,Wout,Cout)
- 卷积核大小kkk、步长sss、扩展比eee(对于MBConv)
预测模型使用简单的线性回归:
latency=wTϕ(x)+b\text{latency} = w^T \phi(x) + blatency=wTϕ(x)+b
其中ϕ(x)\phi(x)ϕ(x)是特征向量,www和bbb是学习的参数。
对于MBConv操作,延迟可以分解为三个部分:
latencyMBConv=latencyexpand+latencydepthwise+latencyproject\text{latency}_{\text{MBConv}} = \text{latency}_{\text{expand}} + \text{latency}_{\text{depthwise}} + \text{latency}_{\text{project}}latencyMBConv=latencyexpand+latencydepthwise+latencyproject
每个部分的延迟与计算量成正比:
- 扩展:Hin×Win×Cin×(e⋅Cin)H_{in} \times W_{in} \times C_{in} \times (e \cdot C_{in})Hin×Win×Cin×(e⋅Cin)
- 深度卷积:Hout×Wout×(e⋅Cin)×k2H_{out} \times W_{out} \times (e \cdot C_{in}) \times k^2Hout×Wout×(e⋅Cin)×k2
- 投影:Hout×Wout×(e⋅Cin)×CoutH_{out} \times W_{out} \times (e \cdot C_{in}) \times C_{out}Hout×Wout×(e⋅Cin)×Cout
A.4 REINFORCE梯度估计的方差减少
原始REINFORCE估计具有高方差。使用基线bbb减少方差:
∇αJ(α)≈1M∑i=1M(R(Ngi)−b)∇αlog(p(gi))\nabla_\alpha J(\alpha) \approx \frac{1}{M}\sum_{i=1}^{M} (R(\mathcal{N}_{g^i}) - b)\nabla_\alpha \log(p(g^i))∇αJ(α)≈M1i=1∑M(R(Ngi)−b)∇αlog(p(gi))
最优基线是奖励的期望值:
b∗=Eg∼α[R(Ng)]b^* = \mathbb{E}_{g\sim\alpha}[R(\mathcal{N}_g)]b∗=Eg∼α[R(Ng)]
实践中使用移动平均估计:
b(t+1)=βb(t)+(1−β)⋅1M∑i=1MR(Ngi)b^{(t+1)} = \beta b^{(t)} + (1-\beta) \cdot \frac{1}{M}\sum_{i=1}^{M} R(\mathcal{N}_{g^i})b(t+1)=βb(t)+(1−β)⋅M1i=1∑MR(Ngi)
其中β∈[0,1]\beta \in [0, 1]β∈[0,1]是动量系数。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)