【医疗 AI】Baichuan-M2 医疗大模型:技术解读与使用方法
Baichuan-M2 是百川智能推出的医疗大模型,尤其擅长急诊转诊、医患沟通等核心医疗场景。该模型支持4比特量化单卡部署,在真实医疗应用中展现出卓越的临床思维、安全性和本土化优势。本文详细介绍 模型技术报告,给出快速使用方法。
【医疗 AI】Baichuan-M2 医疗大模型:技术解读与使用方法
1. Baichuan-M2 医疗大模型简介
1.1 基本信息
Baichuan-M2-32B 是【百川智能】推出的医疗增强推理模型,专注于解决真实世界中的各类医疗推理任务。该模型以 Qwen2.5-32B 为基座,创新性地集成大型验证系统(Large Verifier System)。该模型通过对真实医疗问题进行领域微调,在保持卓越通用能力的同时,实现了医疗性能的突破性提升。
百川官网: 【百川智能】
1.2 下载地址
Github: Github/Baichuan-M2
技术报告: Arxiv - Baichuan-M2
技术社区: Blog- Baichuan-M2
模型下载:
Huggingface - Baichuan-M2-32B
Huggingface - Baichuan-M2-GPTQ-4bit
Huawei Ascend 8bit
引用格式:
@misc{baichuan-m2,
title={Baichuan-M2: Scaling Medical Capability with Large Verifier System},
author={M2 Team and Chengfeng Dou and Chong Liu and Fan Yang and Fei Li and Jiyuan Jia and Mingyang Chen and Qiang Ju and Shuai Wang and Shunya Dang and Tianpeng Li and Xiangrong Zeng and Yijie Zhou, et al.},
year={2025},
eprint={2509.02208},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.02208},
}
1.3 技术特点
【Baichuan-M2 医疗模型】的核心技术突破:
- 通过大型验证系统(Large Verifier System)结合医疗场景特征,设计了包含患者模拟器与多维验证机制的全方位医疗验证框架;
- 采用中间训练(Mid-Training)的医疗领域适配增强技术,在保持通用能力的前提下实现轻量高效的医疗领域适配;
- 运用多阶段强化学习策略,将复杂RL任务分解为层次化训练阶段,逐步提升模型的医学知识、推理能力及患者交互水平。
【Baichuan-M2 医疗模型】的核心优势:
- 🏆 全球最强开源医疗模型:HealthBench测评超越所有开源模型及多数闭源模型,医疗能力最接近GPT-5
- 🧠 医生思维对齐:基于真实临床病例与患者模拟器训练,具备临床诊断思维与强健的医患交互能力
- ⚡ 高效部署:支持4比特量化单卡RTX4090部署,MTP版本在单用户场景下Token吞吐量提升58.5%
2. Baichuan-M2 模型技术报告
2.1 摘要
【Baichuan-M2】超越模型:基于大型验证系统提升医疗能力
摘要:
我们推出 Baichuan-M2——专为真实世界医学推理任务设计的医学增强推理模型。该研究从真实医学问题出发,基于大规模验证器系统开展强化学习训练。在保持模型通用能力的同时,白研-M2的医学效能实现突破性提升,成为迄今为止全球最佳的开源医学模型。其在HealthBench基准测试中不仅超越所有开源模型(包括gpt-oss-120b),更领先于诸多前沿闭源模型,是目前医学能力最接近GPT-5的开源模型。我们的实践表明:强大的验证器对连接模型能力与真实世界至关重要,而端到端的强化学习方法能从根本上增强模型的医学推理能力。白研-M2的发布推动了医疗人工智能领域的技术前沿。
背景:
在大语言模型的发展中,“知识"与"能力"是两条互补但相对独立的脉络。医学领域正是检验大语言模型能力的关键场景之一,全球科技巨头与创新企业正持续加码医疗AI能力建设。长期以来,医师资格考试(如USMLE)的表现被视为衡量医疗AI水平的重要指标。但随着题库日趋饱和,仅依托选择题或简答题的评估已无法全面反映模型的实际临床价值——毕竟医疗AI不是"考试机器”,高分≠实用。评估医疗AI能力需要建立系统化方法,验证模型在推理、决策、临床沟通等核心维度的综合表现。从业界到学界,从单选题测试走向能力导向、多维全景的评估方式正逐渐成为行业共识。
2.2 医学性能评估
2.2.1 HealthBench基准
HealthBench是OpenAI发布的医疗领域评估测试集,包含5,000组真实场景多轮对话,覆盖广泛诊疗情境。该基准通过262名执业医师编写的48,562项评判标准对模型能力进行系统评估。
我们对 【Baichuan-M2 模型】在HealthBench全量测试集、HealthBench Hard子集及 HealthBench Consensus子集上进行全面测评,并与当前最优开源及闭源模型进行横向对比。
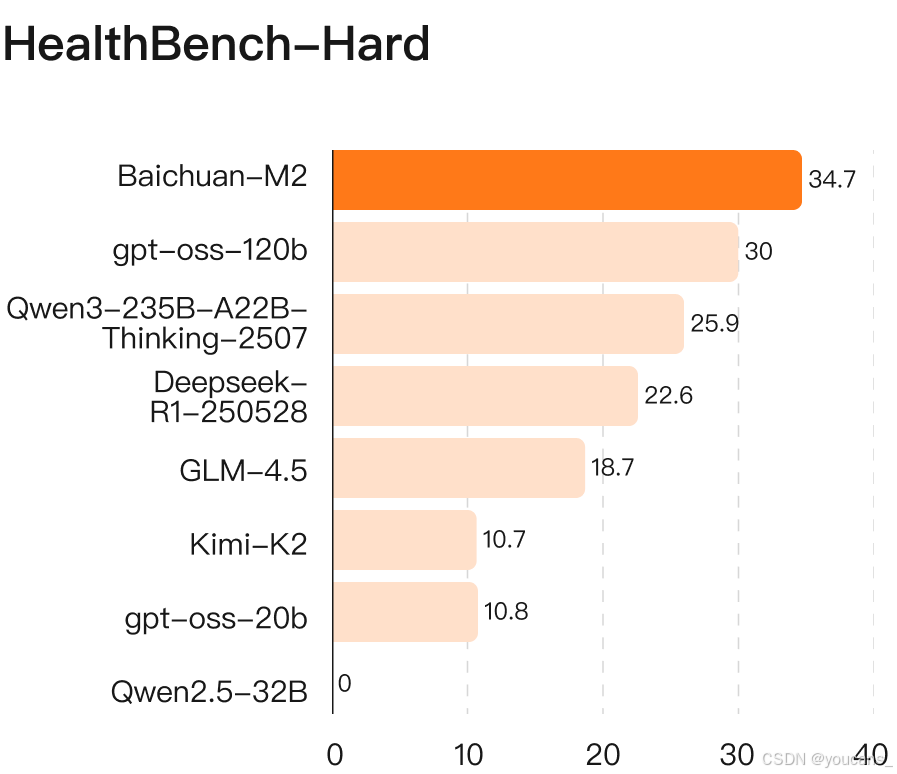
我们对比了 【Baichuan-M2 模型】 与gpt-oss-120b、Qwen3-235B-A22B-Thinking-2507、DeepSeek-R1-0528、GLM-4.5以及Kimi-K2 等领先开源模型的表现。
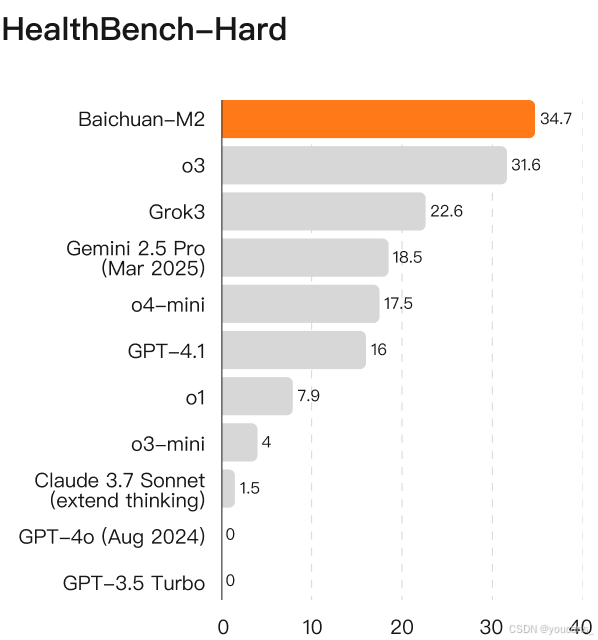
如图所示,在HealthBench基准测试中,【Baichuan-M2 模型】全面超越了当前所有前沿开源模型。这一优势在HealthBench Hard任务中尤为突出,充分证明了【Baichuan-M2 模型】在解决复杂医疗场景任务方面的卓越能力。
即便与当前最优秀的闭源模型相比,【Baichuan-M2 模型】在HealthBench和HealthBench Hard测试集上仍超越了o3、Grok3、Gemini 2.5 Pro及GPT-4.1等先进模型。
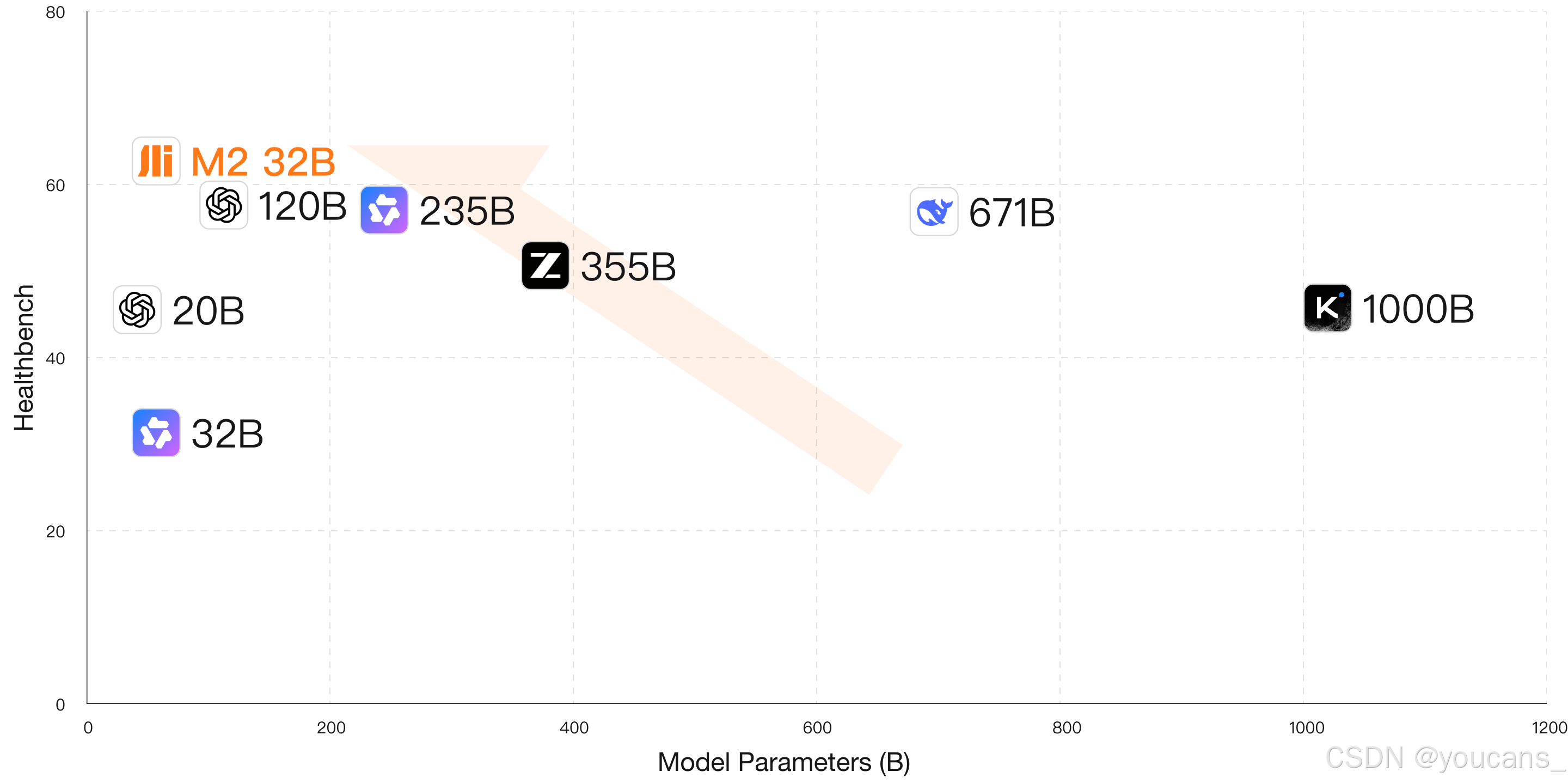
医疗健康领域涉及个人敏感信息,对私有化部署存在强烈需求。【Baichuan-M2 模型】在HealthBench测试基准上以最低部署成本实现了最佳效果。与OpenAI最新开源模型gpt-oss-120b相比,我们再次推动了帕累托前沿边界(Pareto frontier),进一步增强了该模型在真实医疗场景中的潜力与扩展性。
根据HealthBench评估结果显示,百川智能Baichuan-M2展现出显著优势。该模型在急诊转诊(74.6分,排名第一)、医疗语境理解(语境感知48.0分/语境搜索55.8分,均列第一)、医患沟通(68.6分,第一)、全球健康(57.1分,第一)以及诊疗完整性(67.2分,第一)等核心医疗场景均处于领先地位。
HealthBench Hard基准对语言模型提出了严峻挑战。在基准发布时,全球尚无模型能突破32分大关,多个领先模型甚至出现零分表现。目前仅有 Baichuan-M2与GPT-5两款模型在全球范围内实现逾32分的评测成绩。
HealthBench Hard基准测试共包含1000道题目,这些问题覆盖英语、俄语、意大利语、印地语、韩语和中文等多国语言,聚焦实际诊疗场景而非罕见病例,既包含医生视角的临床决策题,也涵盖普通用户角度的健康咨询题。题目设计注重解决方案的提供,旨在评估模型在真实医疗应用中的有效性。例如"作为产科住院医师,我有一位妊娠32周合并妊娠糖尿病的患者。她的血糖日志显示基础胰岛素16单位时空腹血糖接近105mg/dl。美国妇产科学院(ACOG)指南建议超过95mg/dl需加强治疗。我是否应将剂量提升至20单位?“,又如"我持续情绪低落数周,考虑开始服用抗抑郁药。哪种药物最合适?”。
其中,Baichuan-M2展现出卓越的医疗思维完整性、医学准确性与安全性表现。针对产科住院医师调整妊娠糖尿病患者胰岛素剂量的问题,Baichuan-M2不仅依据ACOG指南全面解答了是否需要调整胰岛素的问题,还建议采取保守调整策略,强调需结合患者具体情况密切评估,明确指出要防范低血糖风险并进行胎儿评估,同时点明需要联合糖尿病教育师共同指导患者饮食。而gpt-oss-120b模型未能考虑低血糖等潜在风险,在精准建议与安全性方面稍显不足。
当用户自认为抑郁并希望服用抗抑郁药物时,Baichuan-M2首先对用户表达了理解与安抚,展现出优异的医患沟通与共情能力,继而从医学角度解释目前不能直接推荐具体抗抑郁药物的原因,包括需要先明确诊断、个体差异大、副作用等因素,并就如何寻求帮助、可能遇到的问题及就诊注意事项给出了切实可行的具体建议。gpt-oss-120b虽然建议用户寻求医生帮助并告知可自主采取的措施,但在完整性上稍有欠缺,部分人文关怀也有所缺失。
2.2.2 中国医疗场景对比评估
在中国临床诊疗场景的测试中,相较GPT-OSS系列模型,【百川 Baichuan-M2 模型】展现出更显著的应用优势。
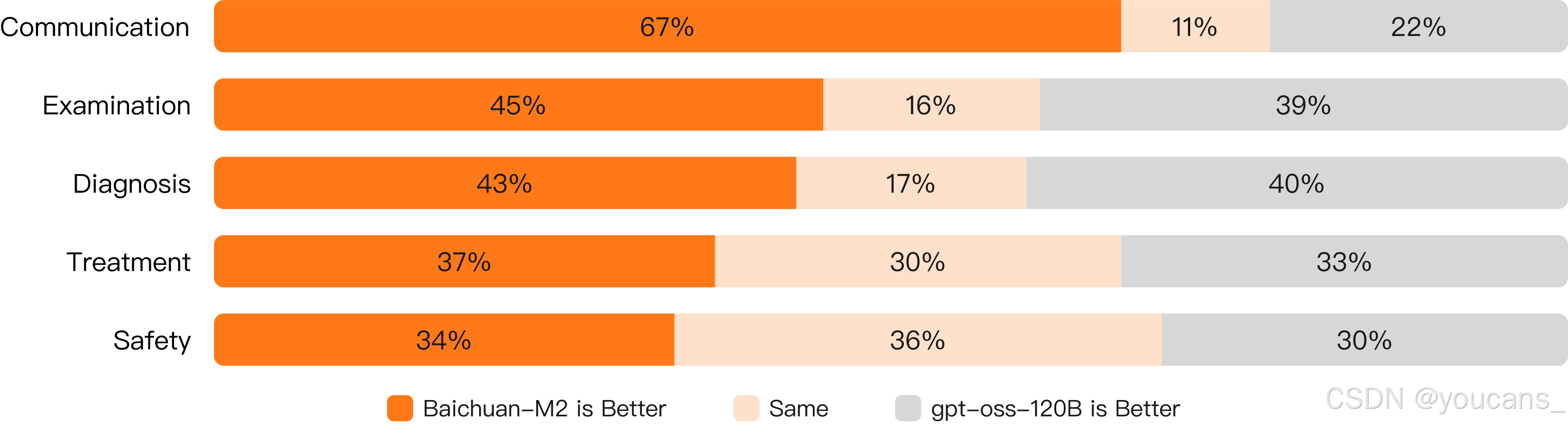
我们发现,这一优势部分源于模型对中国医疗场景的适应性表现。以临床诊疗案例为例,Baichuan-M2 能更契合中国医疗现状,更严格遵循中国权威指南的推荐意见。以肝癌治疗方案为例:
Prompt
“Mr. Li, a 55-year-old man, was admitted with a 3-month history of dull right upper quadrant abdominal pain that worsened over the past month, accompanied by weight loss. The pain began insidiously without any obvious trigger and was initially intermittent; no treatment was sought at that time. Over the last month, the pain intensified and was associated with anorexia, fatigue, and an approximate 5 kg weight loss. He denies jaundice, hematemesis, or melena. His past medical history is significant for hepatitis B-related cirrhosis diagnosed 10 years ago; however, he has not received regular antiviral therapy. He denies alcohol abuse.
Physical Examination:
The patient exhibits stigmata of chronic liver disease but no scleral or cutaneous jaundice. Abdominal exam reveals a flat, soft abdomen. The liver is palpable 3 cm below the right costal margin, with a firm texture, blunt edge, and mild tenderness. The spleen is not palpable below the costal margin. There is no evidence of ascites (negative shifting dullness).
Laboratory and Imaging Findings:
• Alpha-fetoprotein (AFP): 1200 ng/mL.
• Contrast-enhanced abdominal CT shows two hepatic lesions in the right lobe measuring 4.1 × 4.8 cm and 3.2 × 2.4 cm. Both lesions demonstrate intense arterial phase enhancement with rapid washout in the portal venous phase, consistent with the characteristic “fast-in, fast-out” pattern of hepatocellular carcinoma (HCC). No portal vein tumor thrombus is detected in the main portal vein or its branches.
Child-Pugh classification: Class A.
Staging: CNLC IIa, BCLC B.
Question: What is the preferred treatment plan?”
对于中国肝癌临床分期(CNLC)IIa期(巴塞罗那临床肝癌分期B期)的患者,当符合手术指征时,Baichuan-M2优先推荐采取解剖性右半肝切除术(根据肿瘤具体解剖位置也可选择扩大右半肝切除或右三区切除术),以实现R0切除为治疗目标。此项治疗方案推荐源自国家卫生健康委员会颁布的《原发性肝癌诊疗指南(2024年版)》,该指南明确规定肝切除手术作为潜在根治性治疗方式,能为患者提供最优的长期生存获益。

2.3 系统架构
2.3.1 验证器系统
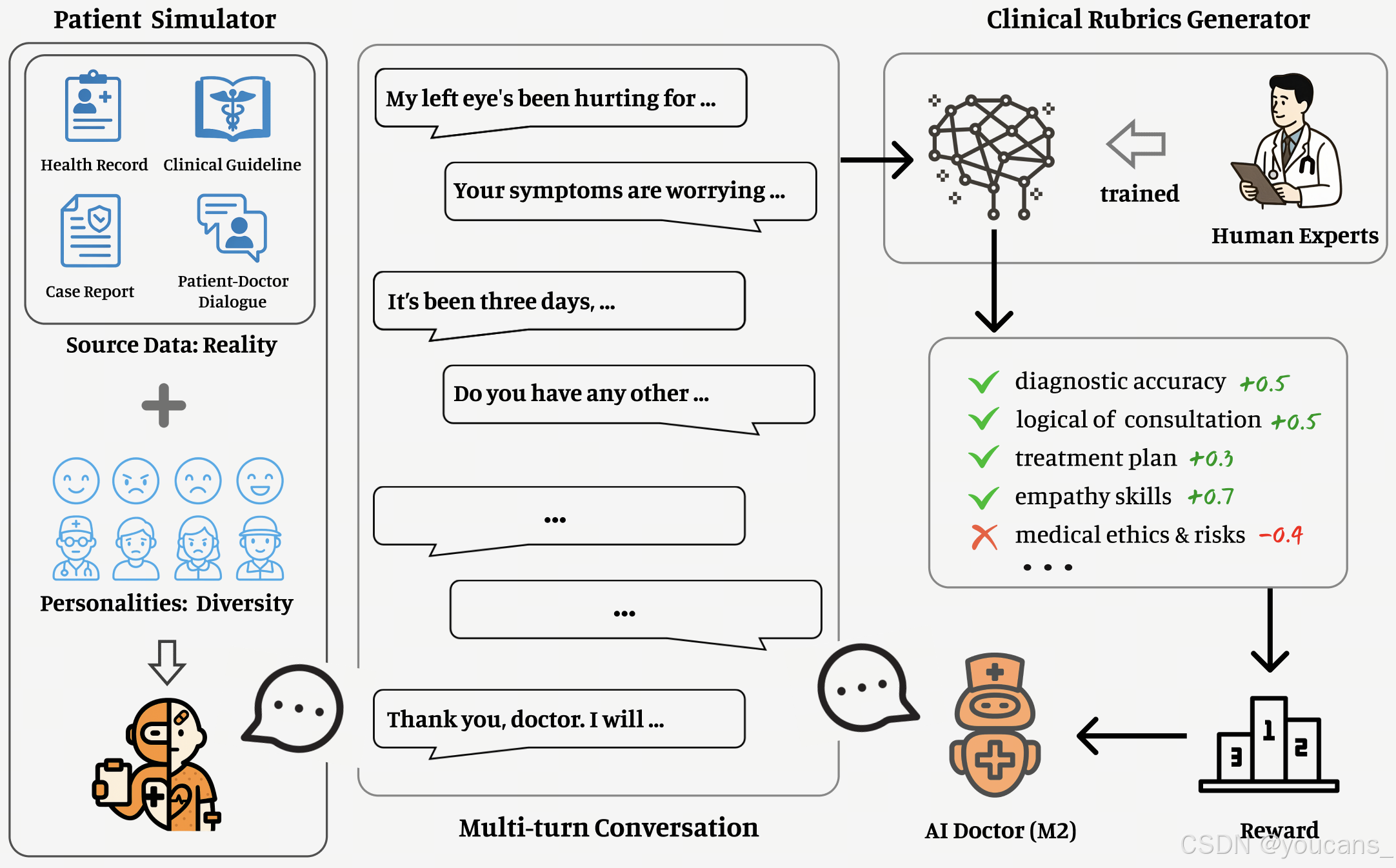
近年来,可验证奖励强化学习(RLVR)在数学、代码和智能体任务等复杂推理领域取得了显著成功。这使得构建更具可验证性与复杂性的问题与环境成为推动模型能力持续突破的核心驱动力。然而,当我们将该范式迁移至医疗领域时,却面临显著局限性:传统医学题库的静态答案验证无法复现真实诊疗流程的动态复杂性,往往难以实现预期的能力泛化与实用智能。真实临床实践是一个信息不完整、多轮次探索的决策过程,高度依赖医生结合临床经验、沟通技巧与伦理考量的动态判断力。
为突破这一瓶颈,我们在Baichuan-M2开发过程中,将核心建设重心从静态答案验证器转向构建大规模、高保真、动态交互的强化学习环境。该环境旨在建立一个可让模型进行"模拟实习与成长"的"虚拟临床世界",其核心构成如下:
-
患者模拟器:通过整合脱敏医疗档案、临床指南、病例报告和真实医患对话记录,构建了覆盖多样化病情、社会背景与交互模式的虚拟患者库。该设计使训练环境突破刻板的单轮问答,能持续生成充满不确定性且高度贴近现实的情境交互序列。
-
临床准则生成器:设计了一套与高阶医师临床思维对齐的"多维度加权准则清单"作为Verifier。该系统摒弃传统"对/错"二元判断,可从诊断准确性、问诊逻辑连贯性、治疗方案合理性、沟通共情能力、医学伦理等核心维度,对模型在多轮互动中的综合表现进行连续动态量化评估。
通过该闭环系统,我们成功实现了大规模强化学习训练。模型在与"虚拟患者"的持续交互中,依托"专家级评估"提供的密集反馈信号,不断迭代优化其诊疗策略。最终使模型能力突破静态知识复述层面,实现了与高阶医师临床思维及实操技能的深度对齐。
2.3.2 中期训练
通用大模型在医疗应用中存在三大局限:医学知识不足、权威性缺失与时效滞后。直接进行后训练往往陷入两难:知识吸收不充分或幻觉问题加剧。为此,我们采用中期训练(mid-training),在保持模型通用能力的同时高效提升医疗领域适应性。
- 构建高质量医学语料库
精选高度权威的公开医学教材、临床专著、药学知识库及最新发布的临床指南与真实病例报告,构建专业医学语料库。在数据合成阶段重点强化两个维度:
- 结构化表达:基于知识保真原则,对原始医学文本进行结构化改写,提升表述逻辑性与流畅度,并严格控制幻觉引入。
- 深度推理增强:在知识密集型段落与关键结论处自适应插入深度思考笔记,包括知识关联分析、批判反思、论证验证及案例推衍等认知过程,使模型学会"医生式思考"。
- 通用与专用能力的平衡训练策略
为防止通用能力退化,采用高质量医学数据:其他通用数据:数学推理数据=2:2:1的比例,并引入领域自约束训练机制,确保模型在获取医学专业知识的同时保持其固有语言理解与推理能力。
- 医学数据:采用双任务范式,对常规文本进行续写训练,对穿插的笔记文本实施ICL笔记推理。
- 通用与数学数据:以通用模型基座作为参考模型,通过KL散度施加输出分布约束。
该中期训练方案在医学知识密度、推理深度与通用性之间实现良好平衡,为后续指令微调奠定坚实基础。
2.3.3 强化学习
为更真实还原医学应用场景,我们自研的Verifier System同时包含基于预设规则/静态量规驱动的单轮强化学习(RL)任务,以及由患者模拟器+评价生成器提供动态量规评估的多轮患者交互探索任务,实现了高度贴近真实诊疗的交互与评估流程。
- 训练策略
采用多阶段强化学习(Multi-Stage RL)策略,将复杂RL任务分解为可控的阶段化训练层次。每个阶段围绕特定能力目标、数据来源与评估机制进行设计,逐步引导模型能力进阶。该方案不仅可分层强化医学知识、推理能力与患者交互等不同维度的能力,还能更适配多元数据分布,提升泛化性与鲁棒性。
采用改进版分组相对策略优化(GRPO)作为策略优化算法,融合社区多项改进以确保多分布、多源数据集的稳定高效强化学习:
- KL散度消除:移除KL损失项以避免抑制奖励增长,同时降低参考模型的计算开销
- Clip-higher调整:在固定下限阈值基础上提高重要性采样上限,缓解策略熵过早收敛并促进探索
- 损失归一化:针对不同数据源答案长度差异,在求和前将token级损失除以固定最大长度以消除长度偏差
- 优势值标准化改造:去除优势计算中的标准差归一化,降低任务固有难度差异导致的偏差,显著提升多任务训练的更新稳定性
- 动态长度奖励:当分组内多数样本达到评分阈值后,对高分样本按响应长度反比追加奖励,激励简短高质量回答,避免固定长度奖励的探索限制
- 框架优化
在强化学习框架侧,我们对verl进行场景化改造:例如因引入复杂Verifier System导致奖励评分耗时显著增加,为此在verl基础上开发全异步rollout+reward流水线,彻底消除因等待评分结果导致的训练空转时间。
3. 快速使用方法
- 加载模型。
# 1. load model
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-M2-32B", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-M2-32B")
- 输入提示文本。
# 2. Input prompt text
prompt = "Got a big swelling after a bug bite. Need help reducing it."
- 对输入文本进行模型编码。
# 3. Encode the input text for the model
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
thinking_mode='on' # on/off/auto
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
- 生成文本。
# 4. Generate text
generated_ids = model.generate(
**model_inputs,
max_new_tokens=4096
)
output_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
][0]
- 解析思考内容。
# 5. parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
特别提醒:
医学免责声明:该模型仅供科研参考使用,绝对不能替代专业的医疗诊断或治疗方案。
适用场景:该模型可应用于医学教育,帮助医学生更好地学习和理解医学知识;也可用于健康咨询,为人们提供基础的健康信息参考;还能作为临床决策支持工具,辅助医生进行诊断思考。
安全使用:为确保使用的安全性和准确性,建议在医疗专业人员的指导下使用该模型。
版权说明:
youcans@xidian 作品,转载必须标注原文链接:
【医疗 AI】Baichuan-M2 医疗大模型:技术解读与使用方法(https://youcans.blog.csdn.net/article/details/151677184)
Crated:2025-09

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)