《Linux 环境变量:读懂其作用、分类及自定义配置技巧》
提到 Linux 环境变量,很多新手都会觉得它高深莫测,仿佛是一道难以跨越的技术门槛。实际上,环境变量并非遥不可及,它就存在于我们日常的 Linux 操作中,比如执行echo $PATH查看路径,或是配置 JDK 时设置JAVA_HOME。了解环境变量,不仅能帮助我们更好地理解 Linux 系统的运行逻辑,还能让我们根据自身需求自定义系统环境,提升操作便利性!


前引:提到 Linux 环境变量,很多新手都会觉得它高深莫测,仿佛是一道难以跨越的技术门槛。实际上,环境变量并非遥不可及,它就存在于我们日常的 Linux 操作中,比如执行echo $PATH查看路径,或是配置 JDK 时设置JAVA_HOME。了解环境变量,不仅能帮助我们更好地理解 Linux 系统的运行逻辑,还能让我们根据自身需求自定义系统环境,提升操作便利性。本文将用通俗易懂的语言,带你走进 Linux 环境变量的世界,从它的基本作用、常见分类讲起,逐步教你掌握自定义配置的实用技巧,让你彻底告别对环境变量的 “陌生感”!
重点:【九】究极逻辑详解与逻辑图
目录
【一】环境变量介绍
环境变量:
是 Linux 系统中 “存储全局信息的变量”,供所有程序 / 命令调用
帮它们快速找到需要的资源,避免重复配置,即记录各种资源路径位置的变量
场景:我们执行各种指令,它需要环境变量去告诉它这个指令在哪里,不用我们写路径
【二】常见的环境变量名
各个环境变量名有自己的功能,可以利用 echo $环境变量名 进行查询各种信息
| 环境变量名 | 作用(记录的内容是哈) | 查看方法(终端敲命令) | 例如(你的系统可能不一样) |
|---|---|---|---|
PATH |
告诉系统 “去哪里找命令”(最核心!) | echo $PATH |
/usr/bin:/bin:/home/yourname/bin |
HOME |
你的 “家目录” 路径(cd ~ 就是去这里) |
echo $HOME |
/home/yourname(普通用户) |
USER |
当前登录的用户名(谁在用这个终端) | echo $USER |
zhangsan |
| SHELL | 当前Shell,它的值通常是/bin/bash | echo $SHELL |
bin/bash |
例如:

【三】环境变量分类
环境变量也有作用范围,像上面的“常见环境变量名”属于全局变量,而根据分类也可分为局部变量
| 类型 | 作用范围(“能被谁看到”) | 通俗例子 |
|---|---|---|
| 局部变量 | 只在 “当前终端窗口” 生效,子窗口 / 其他程序看不到 | 你在终端临时定义的 name=zhangsan |
| 全局变量 | 所有终端窗口、子程序都能看到(全局生效) | PATH(命令路径)、HOME(你的家目录) |
【四】环境变量添加
如果我们后面需要自己添加环境变量,那么根据分类添加时需要注意是全局还是局部:
- 直接定义变量(比如
age=20):默认是 局部变量,只有当前终端能用,打开新终端就没了- 用
export声明(比如export age=20):变成 全局变量,新打开的子终端也能看到
例如:我们每次在执行编译好的可执行程序时,需要加前缀 ./ ,现在可以添加路径直接调用
(添加到系统的环境变量:环境变量名=$环境变量名 : 添加路径)
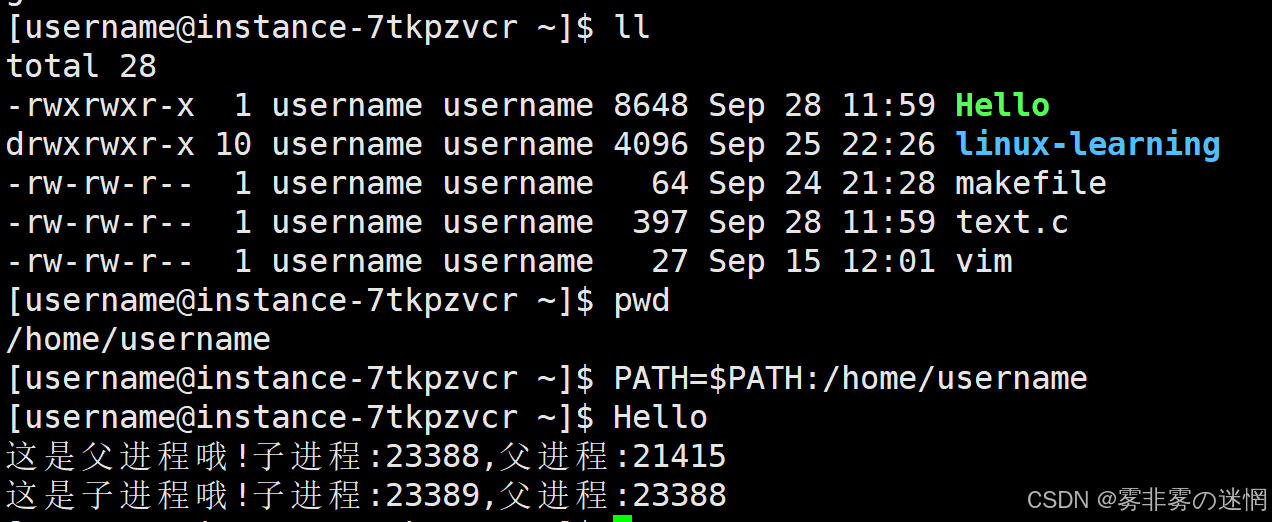
例如:我现在要添加一个全局变量,需要使用export声明

【五】环境变量查看
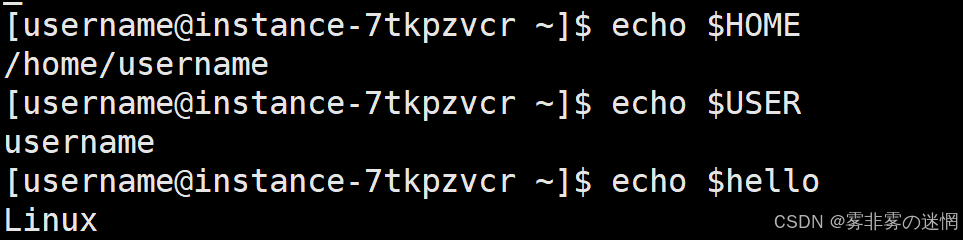
(1)可以使用 echo 查看已经存在的单个环境变量
例如:
(2)使用 env指令 查看所有环境变量
例如:
(3)使用 set 指令查看所有变量(含局部变量和函数)
(4)通过库函数 getenv()获取环境变量内容
#include <stdlib.h>
char *getenv(const char *name);例如:
打印单个的环境变量


【六】命令行参数
命令行参数:
命令行参数可以理解成 “给程序的‘额外指令’”,让程序知道 “要做什么、用什么数据、以什么方式做”。这里我们以main函数的命令行参数为例!
(1)argc与argv
argc:统计命令行参数的 “总数”
argv:存储命令行参数的 “字符串数组”,末尾是nullptr

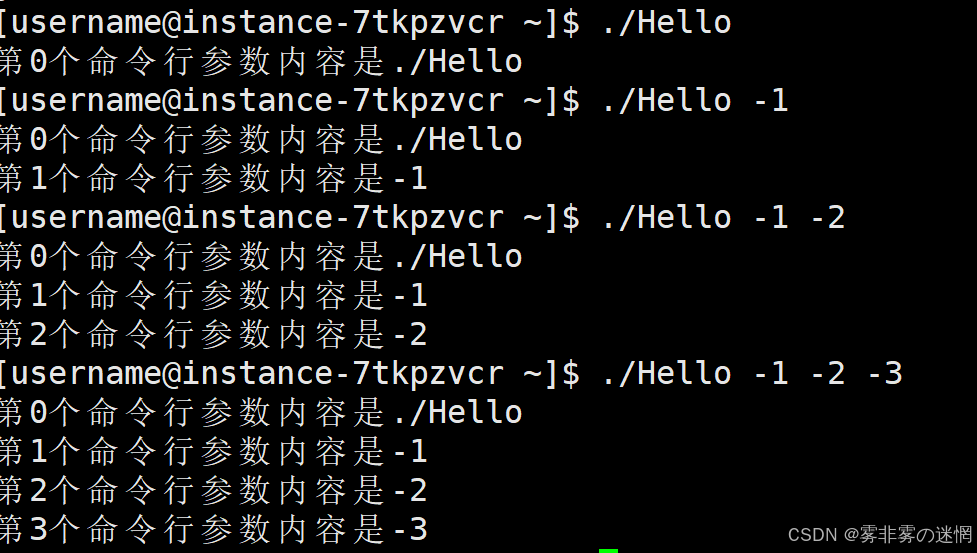
可以看到包括我们输入的 ./Hello 也是一个字符串,命令行参数从0开始,根据空格划分个数!
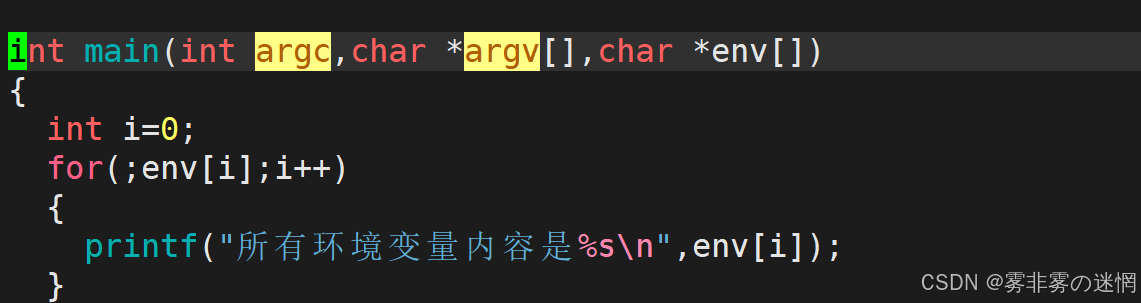
(2)env
env(或envp):存储环境变量的 “字符串数组”,末尾是nullptr
因此我们可以利用env来打印环境变量:
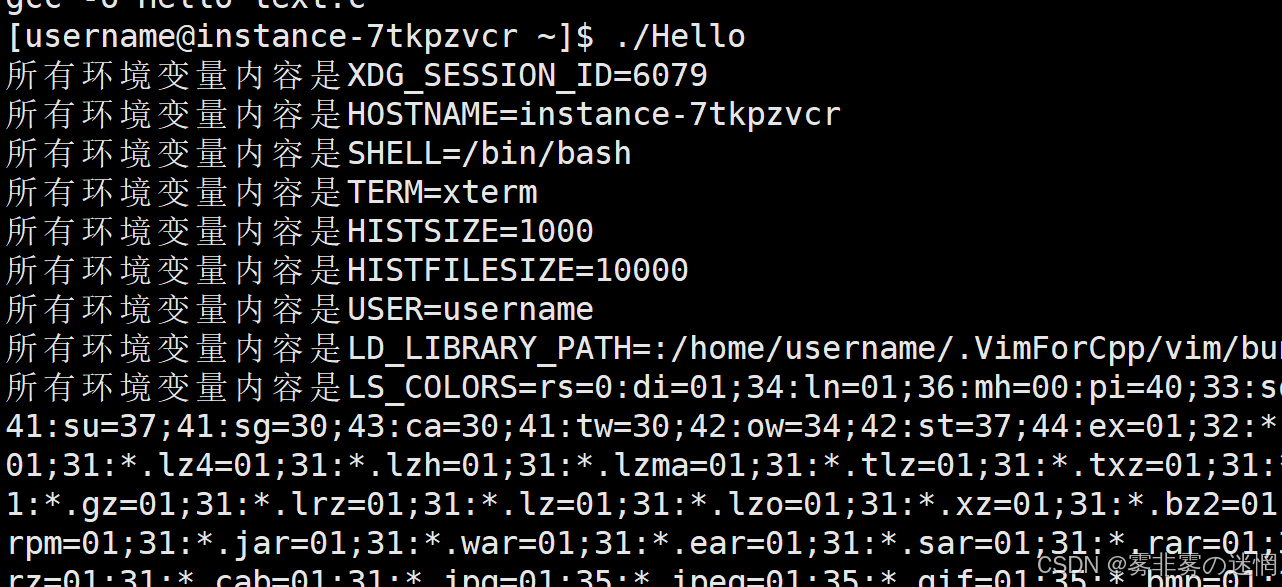
【七】进程的启动
进程启动时,会被传两张表:命令行参数表 和 环境变量表。给这个进程提供各种路径和更多选项
每个进程都有专属的 “当前工作目录”。当我们用 fork 函数创建自己的子进程之后,子进程可以在子进程的代码分支中调用 chdir 函数修改工作目录,而子进程的修改不影响父进程,二者是独立的
【八】进程地址空间
什么是进程地址空间?进程的产生到结束中间的过程是如何的?为方便理解,由现象->出概念!
(1)前引
首先我们用 fork 函数来产出一个子进程,然后更改父\子进程的数据,看看是什么现象:
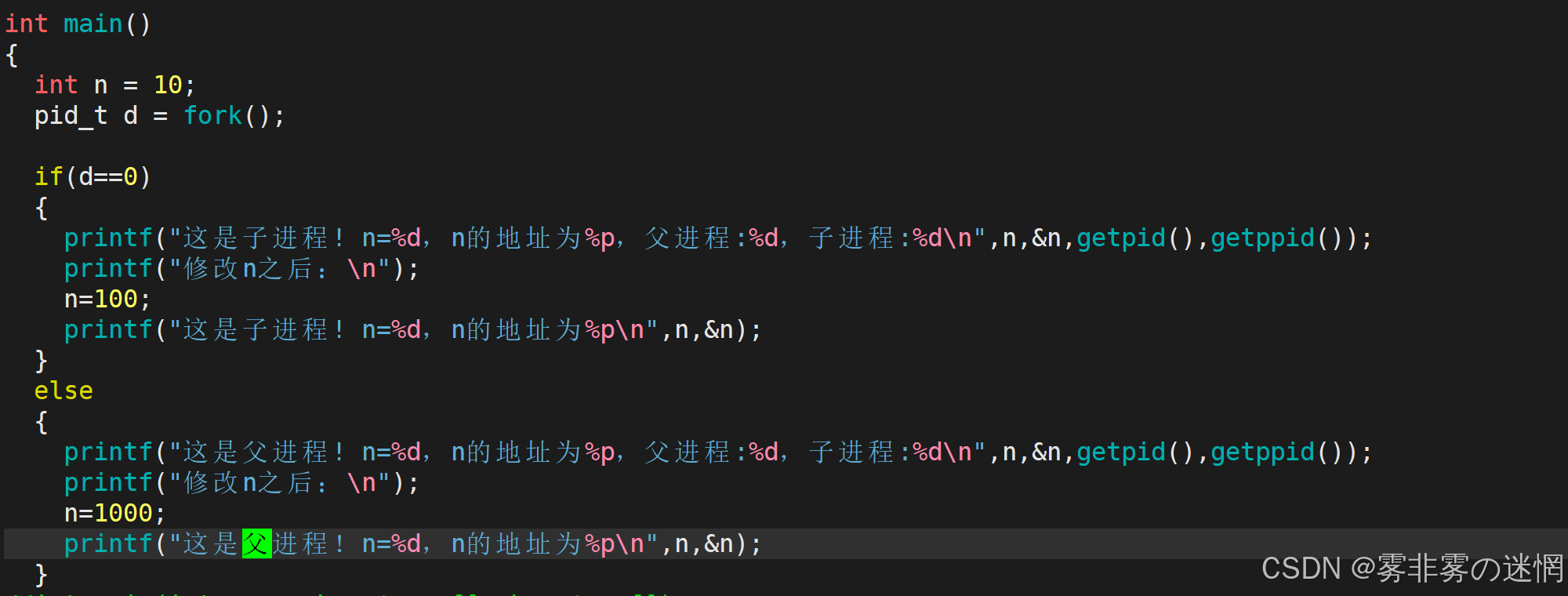
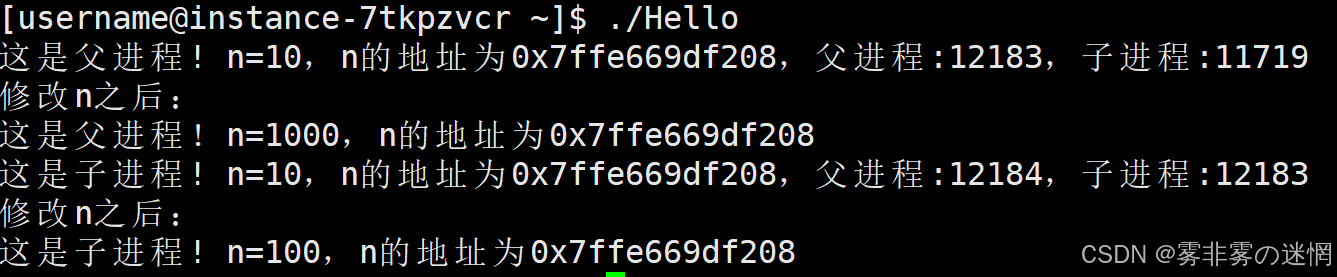
可以看到虽然 n 的修改可以看出各个进程是独立的数据,但是注意 n 的地址每次都是相同的!
可以确认这里的 n地址 绝对不是物理地址,引入新概念:这里n地址属于虚拟地址(或线性地址)
(2)原理讲解
当一个进程被创建的时候,之前对它的解释是:进程=PCB数据结构对象+代码数据,即:
但是今天要更加完善一些,需要引入且完善对进程的了解!
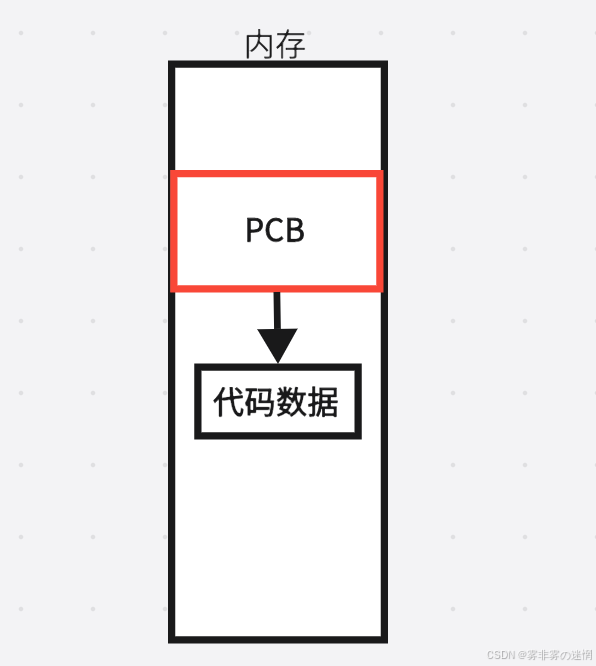
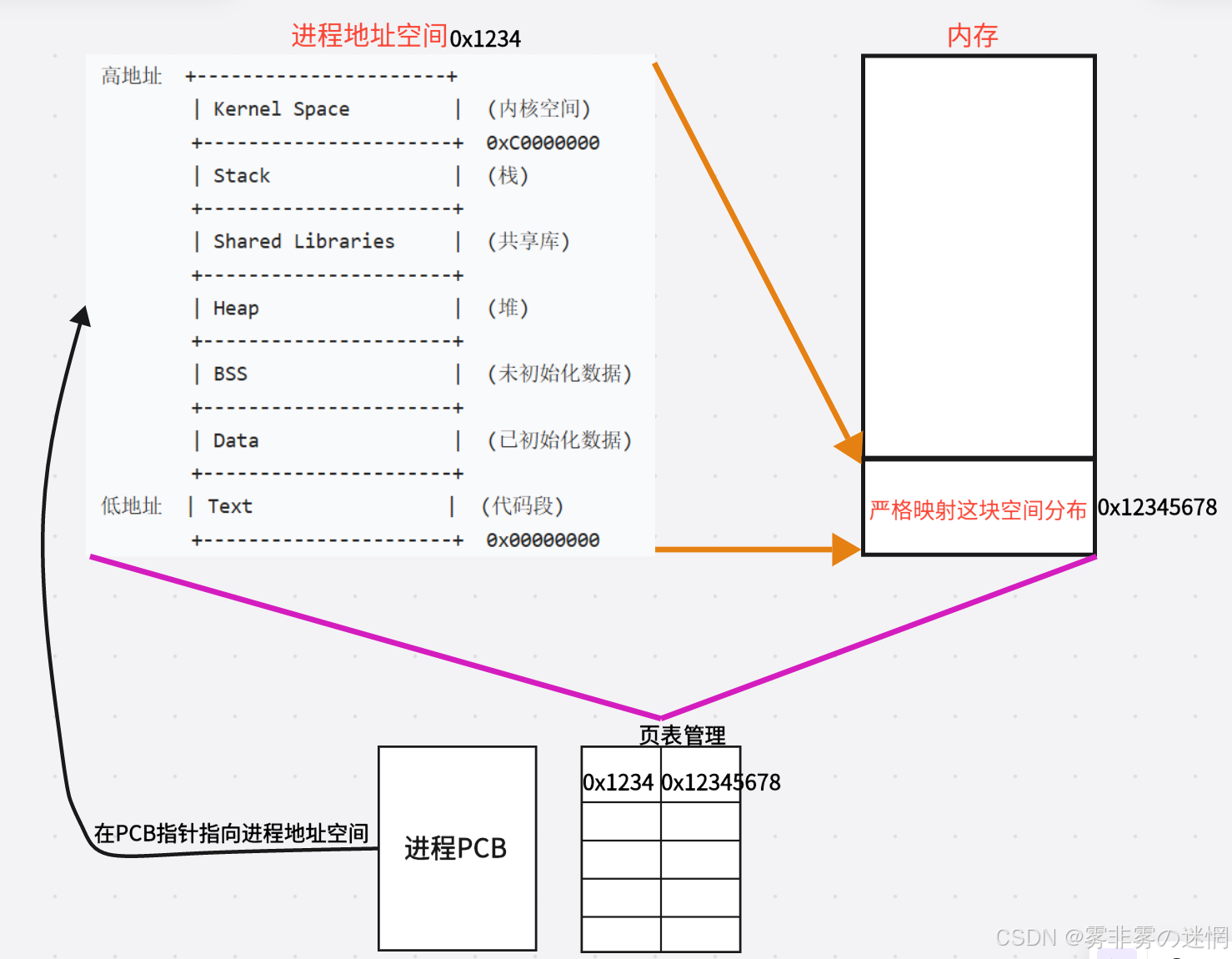
在进程的PCB被操作系统创建出来同时:
(1)会产生一个进程地址空间,由PCB内的指针指向它
进程地址空间:进程地址空间理解为一个真正物理内存的投影,来映射该进程物理内存分布
(既然是映射,那么物理内存的分布也回直接映射在虚拟内存)
作用:隔离:进程之间互不干扰,一个进程崩溃不会影响系统和其他进程
(防止该进程出现问题影响真正的物理内存,进而影响其它进程)
简化编程:程序员不用关心真实物理内存布局,只用关心虚拟地址
(不用管物理内存如何分布,只需要知道“有”这个地方就行)
(2)进程地址空间和真正的物理内存共同存在一个页表(Linux 使用页表) 来管理映射)里面, 左边和右边各自放自己的地址,Linux会通过页表存储的地址来拿到物理/进程地址空间
我们画出整个关系图,如下:
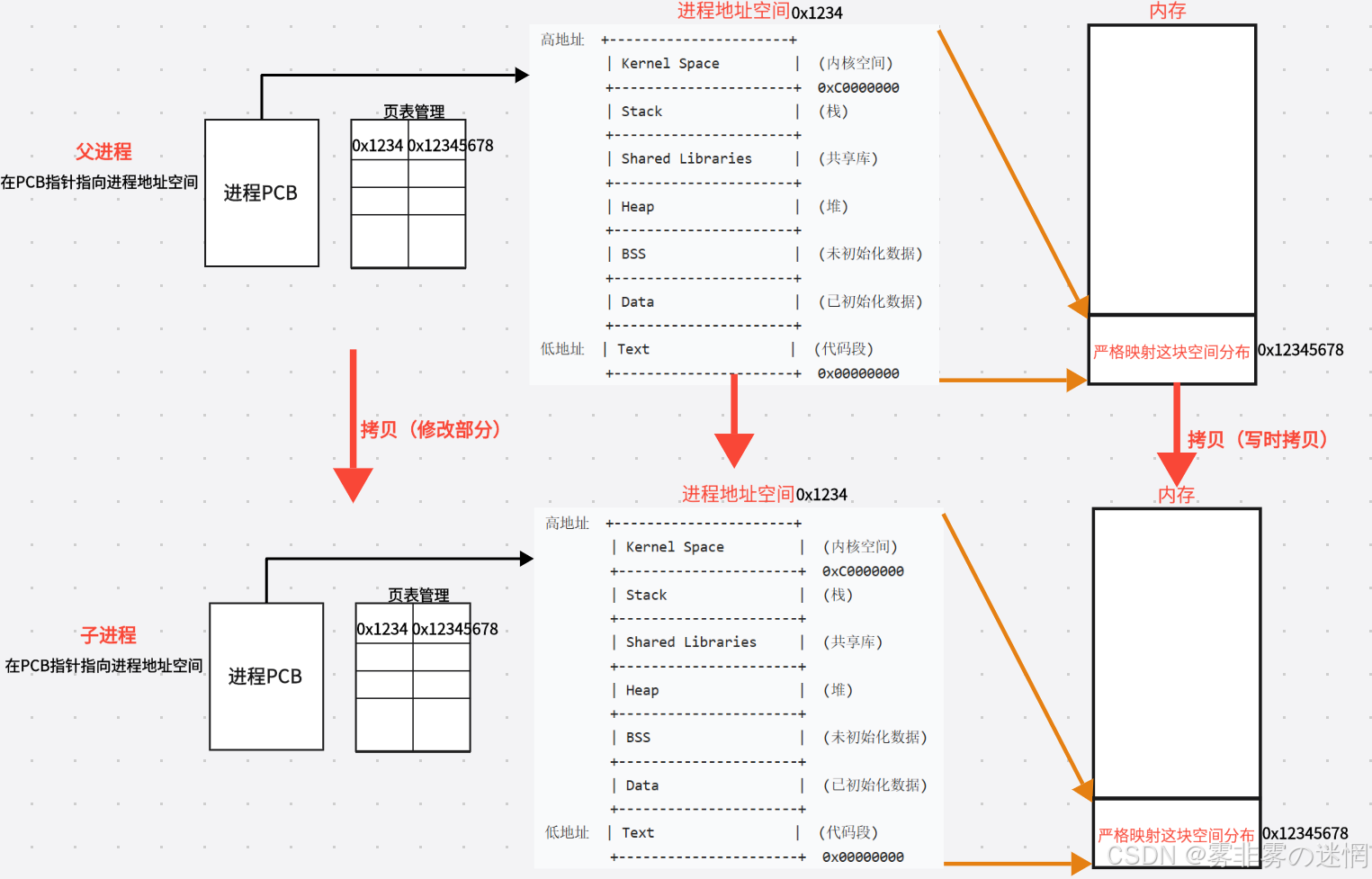
(3)创建子进程
创建子进程时,子进程会拷贝父进程的进程地址空间和物理内存,如果子进程需要更改数据,再在物理内存上单独开一块空间达到互相独立的数据(写时拷贝):
(4)页表
我们先看下面几个概念,结合图片理解:
(1)进程先访问的是虚拟地址(进程自己的真实物理映射地址)但数据实际存在物理内存(真实 的硬件内存空间)里面
(2)CPU 要 “翻译” 虚拟地址时,得先找到页表在哪里。cr3 寄存器就是 CPU 里的一个特殊 “指 针”,它存储着当前进程页表的起始地址
(3)页表:用来放进程地址空间和物理内存各个范围分布的地址,同时标注这块区域的权限和资 源状态(比如0和1)
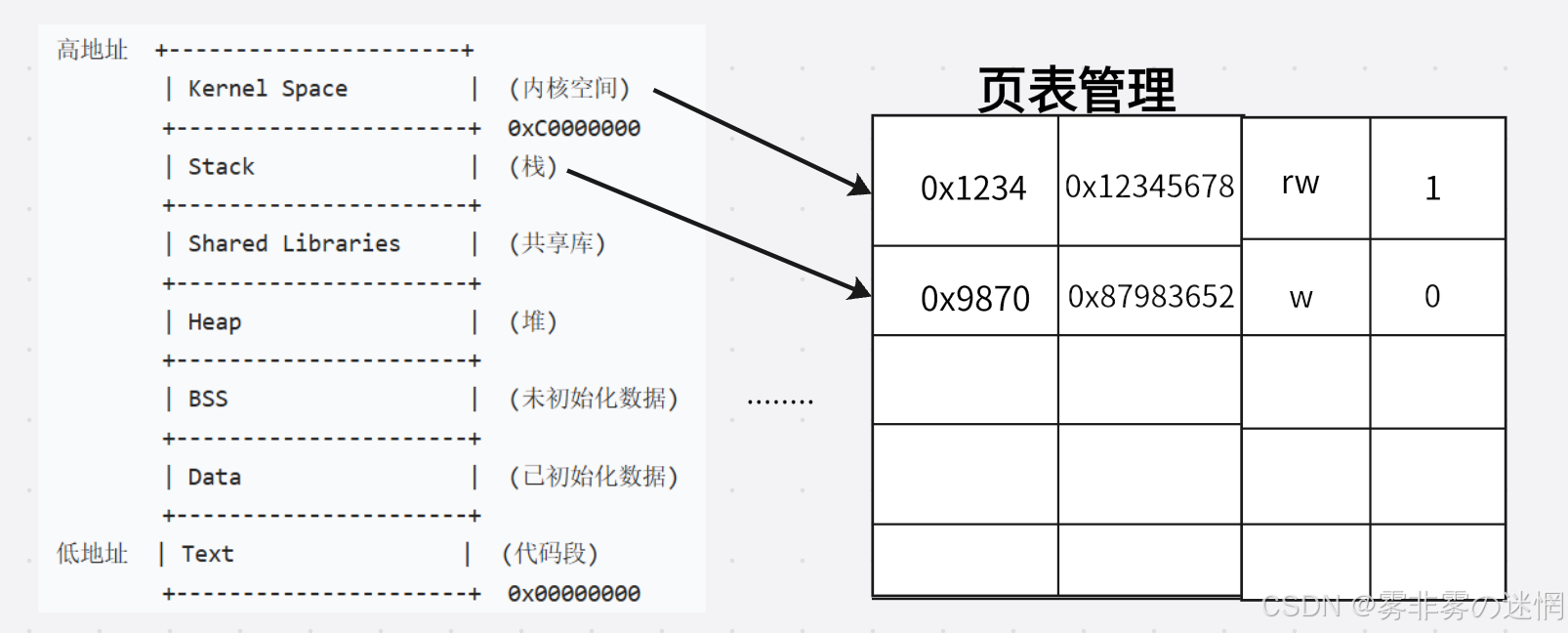
(4)进程要访问某个虚拟地址(比如执行一段代码、读取一个变量)时:
进程的代码数据不会全部加载到内存,而是按需加载,每次加载一部分(内存空间有限)
CPU通过查询 cr3 指针找到页表中对应的这块资源状态,如果为0(表示缺乏)会告诉操作 系统需要去磁盘取这块资源,随后操作系统更新页表
【九】究极逻辑详解
产生PCB:当一个进程被创建时,首先形成的是PCB(task_struct结构对象)
产生进程地址空间和物理内存:同时在PCB里面有一个指针指向了这个进程的进程地址空间(即虚拟内存,本质类似PCB,也是一个结构对象),这个虚拟内存是这个进程在真实物理内存的映射,包含了物理内存的严格区域、范围划分等信息
产生页表:操作系统从进程地址空间中提取该进程的物理地址,同时为该进程生成页表,用来放置对应各个区域的虚、物理地址和权限、状态信息
cr3管理:cr3是CPU的控制寄存器,来指向当前进程的页表,通过cr3,CPU才可以访问到页表
当更新进程时,只需要完成PCB的描述+更换cr3指向(更新页表)即可!思维图如下:
进程的运行:当进程需要调/修改某个资源时,CPU会通过 cr3 指针访问页表查看该资源空间对应 的状态,如果缺乏会让操作系统去磁盘加载,或者权限不允许,则会结束该次请求
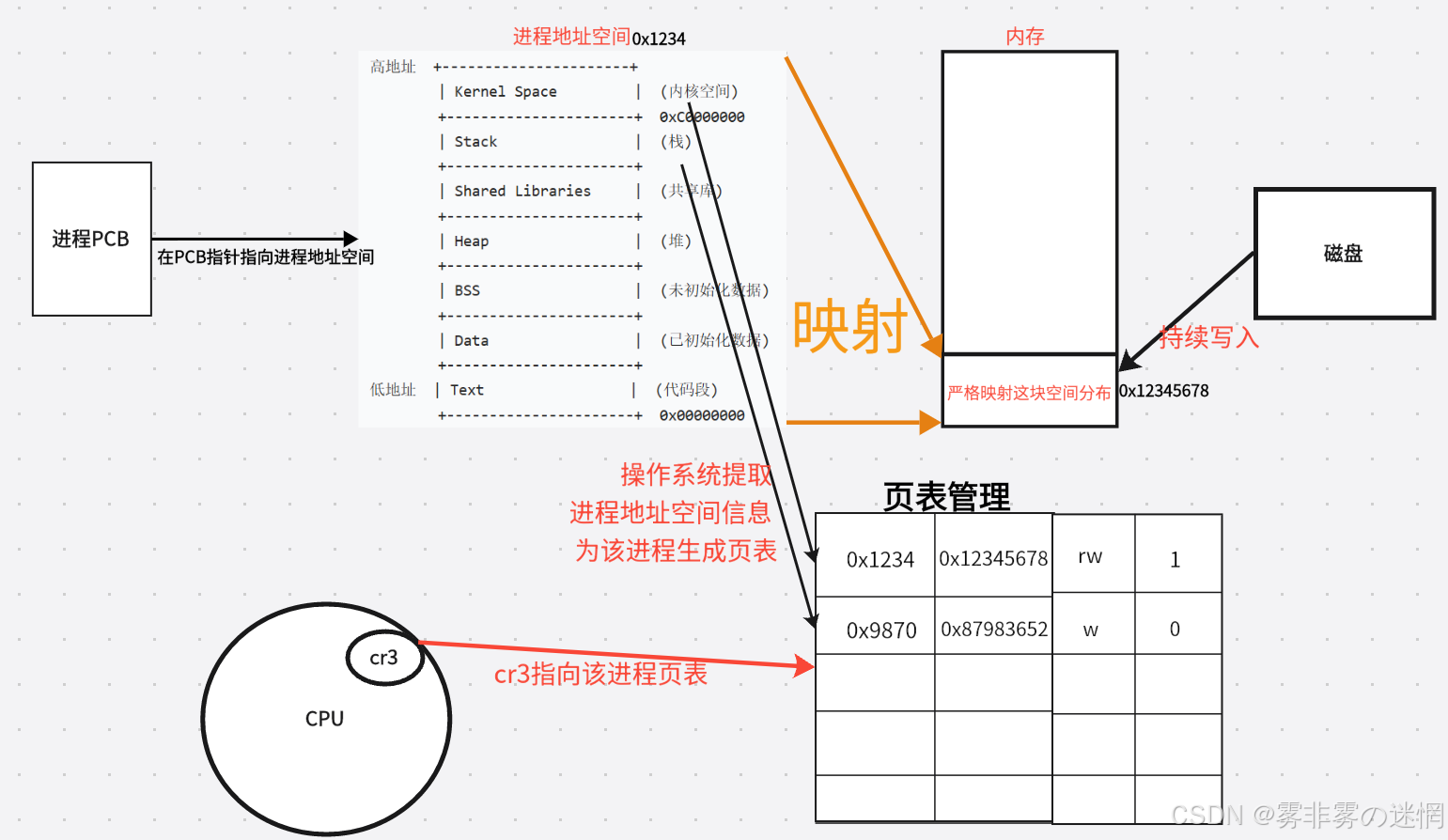
进程 = 内核PCB + 代码数据 + 进程地址空间 + 页表


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 91
91 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)