基于深度学习的卫星图像分类(Kaggle比赛实战)
本文介绍了在PyTorch框架下实现Kaggle卫星图像分类任务的完整流程。使用ResNet34模型对云层、沙漠、绿洲和水域四类卫星图像进行分类,准确率达96.53%。详细说明了环境配置(Python3.7/PyTorch1.12.1等)、数据预处理(包括图像增强技术)、模型构建与训练过程(20个epoch),并提供了测试脚本和可视化结果。特别分析了batch_size对训练的影响,以及各类别的准
目录
4.3.2 定义学习率、计算设备,构建ResNet34模型并定义优化器和损失函数
一、主题介绍:
在Pytorch框架下,实战Kaggle比赛:卫星图像分类(Satellite Remote Sensing Image -RSI-CB256),利用Pycharm调试运行代码。
二、环境配置要求:
python版本:3.7
pycharm版本:2020.3.5
pytorch版本:1.12.1
numpy版本:1.21.6
matplotlib版本:3.2.2
tqdm版本:4.65.0
把需要的包下载好,在你的有cuda或者cpu的pytorch环境中下载
三、主要步骤与涉及知识:
3.1 主要步骤:
- 启用pycharm,新建实验项目,选择编译环境
- 下载数据集
- 预处理数据集
- 定义网络
- 模型训练及预测
3.2 涉及知识:常见Anaconda终端命令的使用
1.Python编程语言
2.数据处理分析库pandas、科学计算库numpy,进度条库tqdm,画图库matplotlib,python机器学习库等使用,torch中nn、loss、optimizer模块使用
四、实验步骤:
4.1 数据下载
在pycharm中新建实验三项目,名为“deep_learning_experiments_3”,在该项目文件夹路径下下载项目数据。
方法 网址下载 Satellite Image Classification | Kaggle
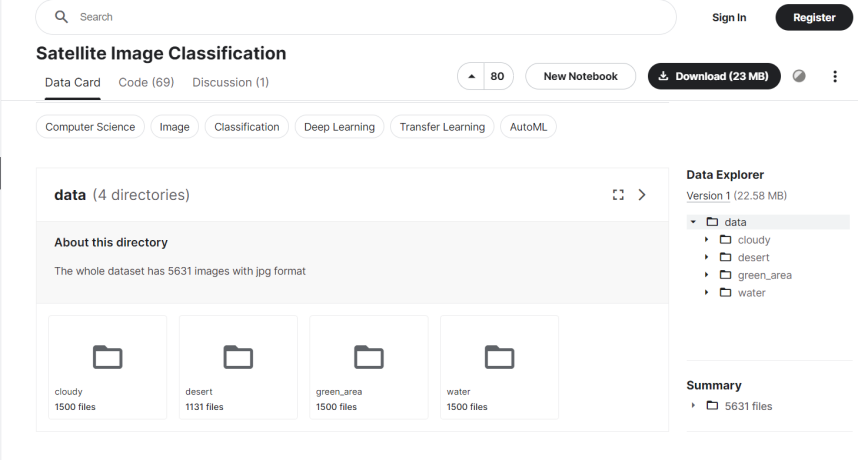
卫星图像分类数据集包含来自传感器和谷歌地图快照的大约5600张图像。它有属于4个不同类别的卫星图像。
cloudy:从卫星拍摄的1500张云图像。desert:从卫星拍摄的1131张沙漠图像。
green_area:主要是森林覆盖的卫星图像1500张图片。water:1500张湖泊和其他水体的卫星图像。

4.2 数据预处理
4.2.1 导入所需的PyTorch模块定义一些常量
import torch
from torch.utils.data import DataLoader, Subset
from torchvision import datasets, transforms
# 验证集比例
valid_split = 0.2
# 批量大小
batch_size = 64
# 数据根目录路径
root_dir = 'D:/pycharm projects/deep_learning_experiments/experiment_4/data'使用20%的数据进行验证,批大小为64,如果本地机器上训练面临OOM(内存不足)问题,那么降低批大小32或16。
batch_size(批次大小)是机器学习和深度学习训练中的一个核心超参数,用于控制每次迭代时模型处理的样本数量。简单来说,当你有一个包含 1000 张图片的训练集,若设置
batch_size=100,则模型会:
- 每次从训练集中取 100 张图片
- 计算这 100 张图片的总损失(通过前向传播)
- 根据根据总损失反向传播更新一次模型参数
- 重复这一过程,直到所有 1000 张图片都被处理完(即完成 1 个 epoch 的训练)
作用与影响:
内存占用:
batch_size越大,一次需要加载到内存(或 GPU 显存)的数据越多,可能导致内存不足(OOM 错误)。训练效率:较大的
batch_size可以利用 GPU 并行的并行计算能力加速训练(单次处理处理大批次数据的效率更高),但单次迭代的计算时间会更长。模型收敛:
- 过小的
batch_size(如batch_size=1,即随机梯度下降 SGD):训练波动大,收敛路径曲折,但可能更容易跳出局部最优。- 适中的
batch_size(如 32、64、128):在收敛稳定性和效率间取得平衡,是最常用的选择。- 过大的
batch_size:训练更稳定,但可能收敛到较差的局部最优,且需要更大的学习率配合。
4.2.2 训练集和测试集转换
#训练集数据增强,以及将图像数据类型转化为张量做归一化
train_transform = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5)), #kernel_size:高斯卷积核大小, sigma:标准差(min,max)
transforms.RandomRotation(degrees=(30, 70)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
#空间变换增强
#翻转 → 位置不变性
#旋转 → 方向不变性
#组合使用 → 强大的几何不变性
#外观变换增强
#高斯模糊 → 对图像质量的鲁棒性
#标准化增强效果可视化
假设原始图像经过这个流水线可能产生:
-
原图 → 清晰、正立的图像
-
增强1 → 水平翻转 + 轻微模糊
-
增强2 → 旋转45° + 垂直翻转
-
增强3 → 强烈模糊 + 旋转60°
4.2.3 定义数据加载器
# 加载数据集
dataset = datasets.ImageFolder(root_dir, transform=train_transform)
dataset_test = datasets.ImageFolder(root_dir, transform=valid_transform)
# 数据集信息
print(f"Classes: {dataset.classes}") # 输出类别名称
dataset_size = len(dataset)
valid_size = int(valid_split * dataset_size)
# 随机划分训练集和验证集
indices = torch.randperm(len(dataset)).tolist() # 随机打乱索引
dataset_train = Subset(dataset, indices[:-valid_size]) # 训练集:前80%
dataset_valid = Subset(dataset_test, indices[-valid_size:]) # 验证集:后20%
print(f"Total training images: {len(dataset_train)}")
print(f"Total valid_images: {len(dataset_valid)}")
train_loader = DataLoader(
dataset_train, batch_size=batch_size, shuffle=True # 训练时打乱
)
valid_loader = DataLoader(
dataset_valid, batch_size=batch_size, shuffle=False # 验证时不打乱
)4. 3 构建模型(ResNet34)
4.3.1 训练脚本train.py
导入所有库模块以及上面编写的模块,还有参数解析器,控制--epochs
import torch
import argparse
import torch.nn as nn
import torch.optim as optim
from model import build_model
from utils import save_model, save_plots
from datasets import train_loader, valid_loader, dataset
from tqdm.auto import tqdm
# 通过命令行控制训练轮数
parser = argparse.ArgumentParser()
parser.add_argument('-e', '--epochs', type=int, default=20,
help='number of epochs to train our network for')
args = vars(parser.parse_args())4.3.2 定义学习率、计算设备,构建ResNet34模型并定义优化器和损失函数
# 学习参数设置
#学习率: 0.001 (Adam优化器的常用值)
#设备: 自动检测GPU/CPU
lr = 0.001
epochs = args['epochs']
device = ('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Computation device: {device}\n")
# 构建模型
model = build_model(
pretrained=True, fine_tune=False, num_classes=len(dataset.classes)
).to(device)
#总参数量: 所有参数的数量
#可训练参数: 仅计算需要梯度的参数
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.\n")
# 优化器: Adam,适合大多数场景
optimizer = optim.Adam(model.parameters(), lr=lr)
# 损失函数: 交叉熵损失,用于多分类
criterion = nn.CrossEntropyLoss()4.3.3 训练与验证函数
4.3.3.1 训练函数
# 训练过程
def train(model, trainloader, optimizer, criterion):
model.train()
print('Training')
train_running_loss = 0.0
train_running_correct = 0
counter = 0
for i, data in tqdm(enumerate(trainloader), total=len(trainloader)):
counter += 1
image, labels = data
image = image.to(device)
labels = labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(image)
# 计算损失
loss = criterion(outputs, labels)
train_running_loss += loss.item()
# 计算准确率
_, preds = torch.max(outputs.data, 1)
train_running_correct += (preds == labels).sum().item()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 统计一批次的损失率和准确率
epoch_loss = train_running_loss / counter
epoch_acc = 100. * (train_running_correct / len(trainloader.dataset))
return epoch_loss, epoch_acc在每个epoch之后,该函数返回该epoch的损失和准确度。
epoch(轮次)是深度学习训练中的核心概念,指模型完整遍历一次所有训练数据的过程,可以理解为 “训练一轮”。简单来说,假设你有 1000 张训练图片,无论
batch_size(批次大小)是多少,只要模型把这 1000 张图片全部处理完一次,就算完成了 1 个epoch。比如之前的代码设置了20个epoch,就意味着模型要把 4502 张训练图完整训练 20 遍。
4.3.3.2 验证函数
def validate(model, testloader, criterion, class_names):
# 设置为评估模式(禁用dropout和batchnorm的随机性)
model.eval()
print('验证中...')
# 累计损失值
valid_running_loss = 0.0
# 累计正确预测数量
valid_running_correct = 0
# 批次计数器
counter = 0
# 初始化列表来跟踪每个类别的准确率
# class_correct: 每个类别的正确预测数
# class_total: 每个类别的总样本数
class_correct = list(0. for i in range(len(class_names)))
class_total = list(0. for i in range(len(class_names)))
# 禁用梯度计算以节省内存和加速计算
with torch.no_grad():
# 遍历验证集中的所有批次
for i, data in tqdm(enumerate(testloader), total=len(testloader)):
counter += 1
# 获取图像数据和标签
image, labels = data
# 将数据转移到指定设备(GPU或CPU)
image = image.to(device)
labels = labels.to(device)
# 前向传播:通过模型获取预测输出
outputs = model(image)
# 计算损失值
loss = criterion(outputs, labels)
# 累加损失值
valid_running_loss += loss.item()
# 计算准确率:获取预测类别(最大概率的索引)
_, preds = torch.max(outputs.data, 1)
# 累加正确预测的数量
valid_running_correct += (preds == labels).sum().item()
# 计算每个类别的准确率
# 获取每个样本的预测是否正确(布尔张量)
correct = (preds == labels).squeeze()
# 遍历当前批次中的每个样本
for i in range(len(preds)):
# 获取当前样本的真实标签
label = labels[i]
# 如果预测正确,则对应类别的正确数加1
class_correct[label] += correct[i].item()
# 对应类别的总样本数加1
class_total[label] += 1
# 计算整个epoch的平均损失(总损失除以批次数量)
epoch_loss = valid_running_loss / counter
# 计算整体准确率(正确预测数除以总样本数,转换为百分比)
epoch_acc = 100. * (valid_running_correct / len(testloader.dataset))
# 打印每个类别的准确率
print('\n')
for i in range(len(class_names)):
# 计算并打印每个类别的准确率
print(f"类别 {class_names[i]} 的准确率: {100 * class_correct[i] / class_total[i]:.3f}%")
print('\n')
# 返回平均损失和整体准确率
return epoch_loss, epoch_acc4.3.4 训练循环
# 初始化列表来跟踪损失和准确率
# train_loss: 训练损失列表
# valid_loss: 验证损失列表
# train_acc: 训练准确率列表
# valid_acc: 验证准确率列表
train_loss, valid_loss = [], []
train_acc, valid_acc = [], []
# 开始训练循环
for epoch in range(epochs):
# 打印当前训练轮次信息
print(f"[INFO]: 第 {epoch+1} 轮 / 共 {epochs} 轮")
# 训练一个epoch并获取训练损失和准确率
train_epoch_loss, train_epoch_acc = train(model, train_loader,
optimizer, criterion)
# 验证一个epoch并获取验证损失和准确率
valid_epoch_loss, valid_epoch_acc = validate(model, valid_loader,
criterion, dataset.classes)
# 将当前epoch的结果添加到列表中
train_loss.append(train_epoch_loss)
valid_loss.append(valid_epoch_loss)
train_acc.append(train_epoch_acc)
valid_acc.append(valid_epoch_acc)
# 打印当前epoch的训练和验证结果
print(f"训练损失: {train_epoch_loss:.3f}, 训练准确率: {train_epoch_acc:.3f}%")
print(f"验证损失: {valid_epoch_loss:.3f}, 验证准确率: {valid_epoch_acc:.3f}%")
print('-'*50) # 打印分隔线
# 保存训练好的模型权重(每个epoch都保存)
save_model(epochs, model, optimizer, criterion)
# 训练完成后保存损失和准确率图表
save_plots(train_acc, valid_acc, train_loss, valid_loss)
print('训练完成')4.3.5 模型测试
4.3.5.1 测试参数设置
# 导入必要的库
import torch # PyTorch深度学习框架
import cv2 # OpenCV计算机视觉库,用于图像处理
import torchvision.transforms as transforms # PyTorch图像变换模块
import argparse # 命令行参数解析库
# 构建参数解析器
# 创建ArgumentParser对象,用于处理命令行参数
parser = argparse.ArgumentParser()
# 添加输入参数
# -i 或 --input: 指定输入图像路径,默认值为'input/test_data/cloudy.jpeg'
parser.add_argument('-i', '--input',
default='input/test_data/cloudy.jpeg',
help='输入图像的路径')
# 解析输入参数并将其转换为字典格式
args = vars(parser.parse_args())
# 计算设备设置
# 指定使用CPU进行计算(如果需要GPU可改为'cuda')
device = 'cpu'4.3.5.2加载模型处理转换
对于预处理只需要将图像转换为 PIL 图像格式,调整其大小,将其转换为张量,然后应用归一化。
# 定义所有类别标签的列表
# 对应模型的4个输出类别:多云、沙漠、绿地、水域
labels = ['cloudy', 'desert', 'green_area', 'water']
# 初始化模型并加载训练好的权重
# pretrained=False: 不加载预训练权重
# fine_tune=False: 不进行微调
# num_classes=4: 设置输出类别数为4
model = build_model(
pretrained=False, fine_tune=False, num_classes=4
).to(device) # 将模型移动到指定设备(CPU)
print('[INFO]: 正在加载自定义训练权重...')
# 加载训练好的模型检查点文件
# map_location=device: 确保权重加载到正确的设备上
checkpoint = torch.load('outputs/model.pth', map_location=device)
# 将训练好的权重加载到模型中
model.load_state_dict(checkpoint['model_state_dict'])
# 将模型设置为评估模式(禁用dropout和batchnorm的随机性)
model.eval()
# 定义图像预处理变换流程
transform = transforms.Compose([
transforms.ToPILImage(), # 将numpy数组或tensor转换为PIL图像
transforms.Resize(224), # 调整图像大小为224x224像素
transforms.ToTensor(), # 将PIL图像转换为tensor,并归一化到[0,1]
transforms.Normalize( # 标准化处理,使用ImageNet数据集的均值和标准差
mean=[0.485, 0.456, 0.406], # RGB通道的均值
std=[0.229, 0.224, 0.225] # RGB通道的标准差
)
])4.3.5.3 读取图像与前馈
# 读取并预处理输入图像
# 使用OpenCV读取图像文件
image = cv2.imread(args['input'])
# 从文件路径中提取真实类别(ground truth)
# 例如:'input/test_data/cloudy.jpeg' -> 'cloudy'
gt_class = args['input'].split('/')[-1].split('.')[0]
# 保存原始图像的副本用于后续显示
orig_image = image.copy()
# 将图像从BGR格式转换为RGB格式(OpenCV默认使用BGR,但模型需要RGB)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 对图像应用预处理变换(调整大小、标准化等)
image = transform(image)
# 添加批次维度(将3D张量[H,W,C]转换为4D张量[1,H,W,C])
# 因为模型期望输入具有批次维度
image = torch.unsqueeze(image, 0)
# 在不计算梯度的情况下进行推理(节省内存和计算资源)
with torch.no_grad():
# 将图像数据移动到设备并通过模型进行前向传播
outputs = model(image.to(device))
# 获取模型输出的最高概率类别
# torch.topk返回前k个最大值和对应的索引,这里k=1表示取最高概率
output_label = torch.topk(outputs, 1)
# 将预测的索引转换为对应的类别名称
pred_class = labels[int(output_label.indices)]
# 在原始图像上添加真实类别文本(绿色)
cv2.putText(orig_image,
f"GT: {gt_class}", # 显示真实类别
(10, 25), # 文本位置坐标(x,y)
cv2.FONT_HERSHEY_SIMPLEX, # 字体类型
1, # 字体大小
(0, 255, 0), # 字体颜色(绿色)
2, # 字体粗细
cv2.LINE_AA # 抗锯齿线型
)
# 在原始图像上添加预测类别文本(红色)
cv2.putText(orig_image,
f"Pred: {pred_class}", # 显示预测类别
(10, 55), # 文本位置坐标(x,y),在真实类别下方
cv2.FONT_HERSHEY_SIMPLEX, # 字体类型
1, # 字体大小
(0, 0, 255), # 字体颜色(红色)
2, # 字体粗细
cv2.LINE_AA # 抗锯齿线型
)
# 在控制台打印真实类别和预测类别
print(f"真实类别: {gt_class}, 预测类别: {pred_class}")
# 显示带有标注的结果图像
cv2.imshow('Result', orig_image)
# 等待按键操作(0表示无限等待)
cv2.waitKey(0)
# 将结果图像保存到outputs目录
# 文件名格式:outputs/真实类别.png
cv2.imwrite(f"outputs/{gt_class}.png", orig_image)4.4 训练测试终端命令
4.4.1 训练命令
python train.py --epochs 1004.4.2 测试命令
python inference.py --input test_data/cloudy.jpg或者直接点运行也可以
运行中……
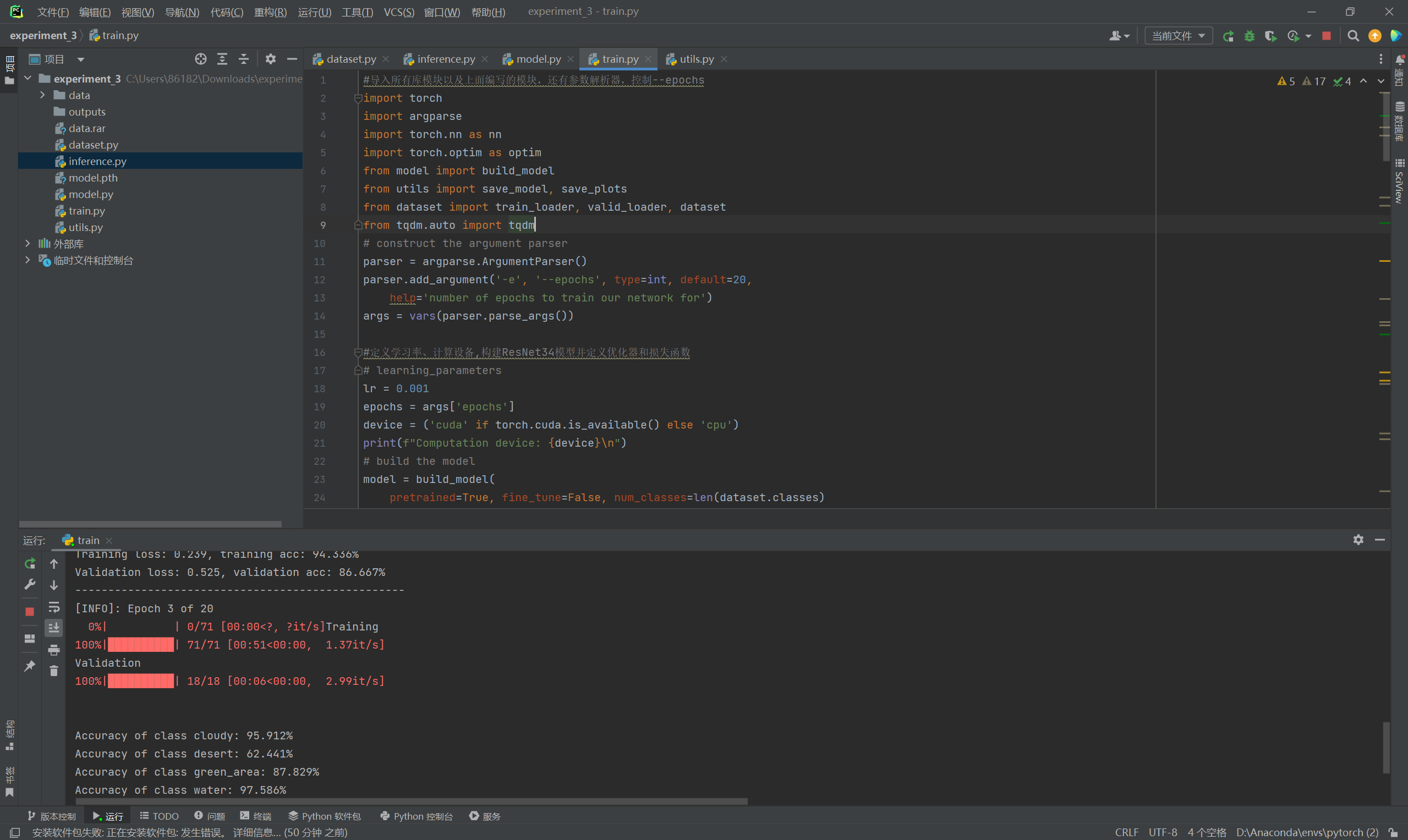
最终结果展示:
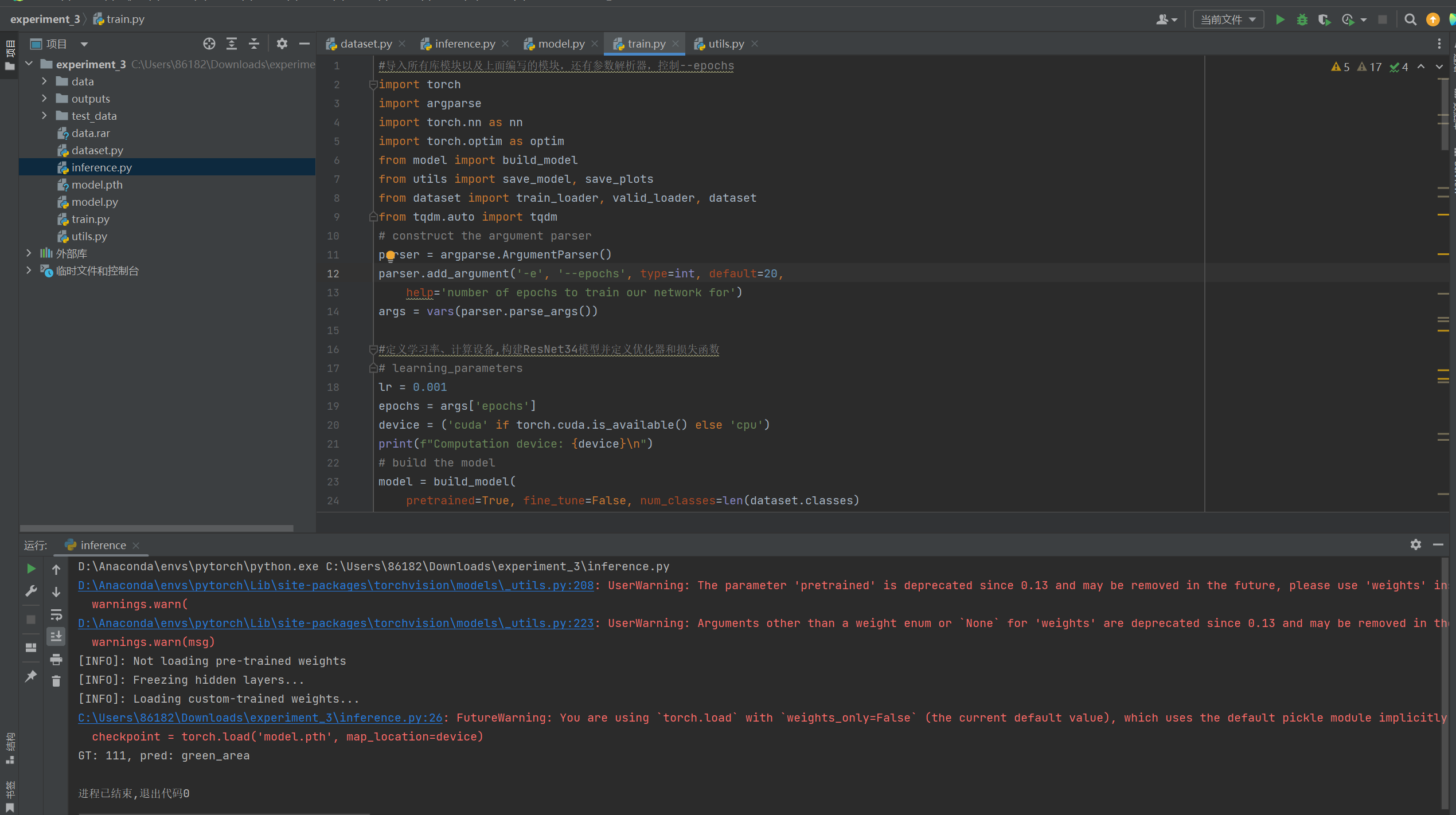
再运行下inference.py文件验证下:
随便放个图片:

验证结果完全正确!!!是绿洲图像

又测试了下cloudy的,也完全正确:

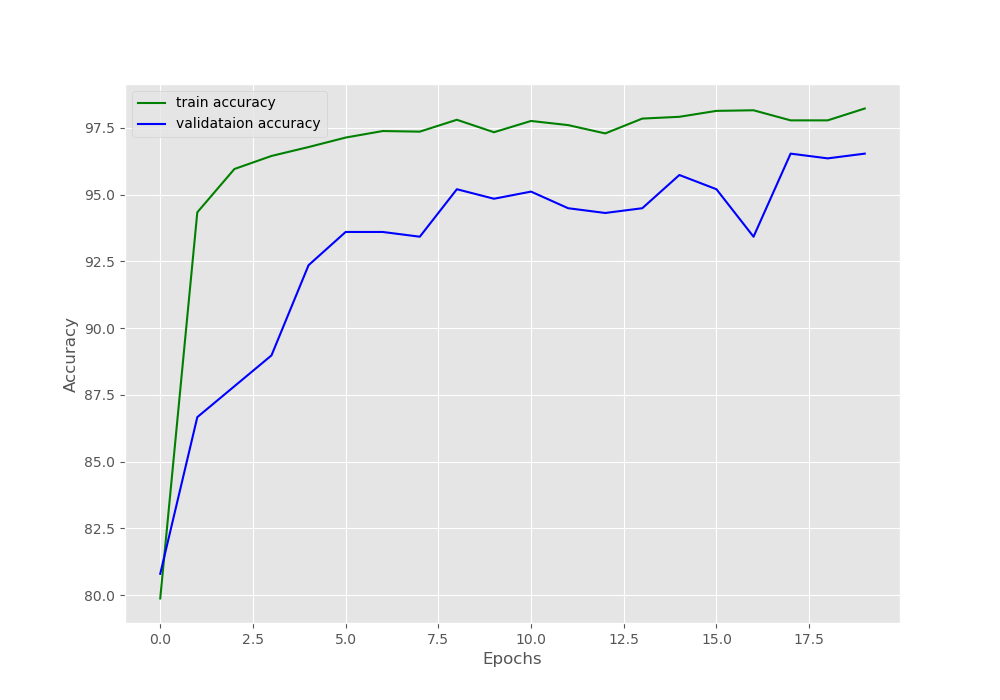
下面的是准确率和损失率变化图像,很直观的展示:
准确率:随着训练轮数的增加准确率显著上升!!!且训练集和验证集的准确率最终逐渐趋于一致
损失率:训练集和验证集的损失率显著下降,最终训练集的损失率降低到了0.05左右
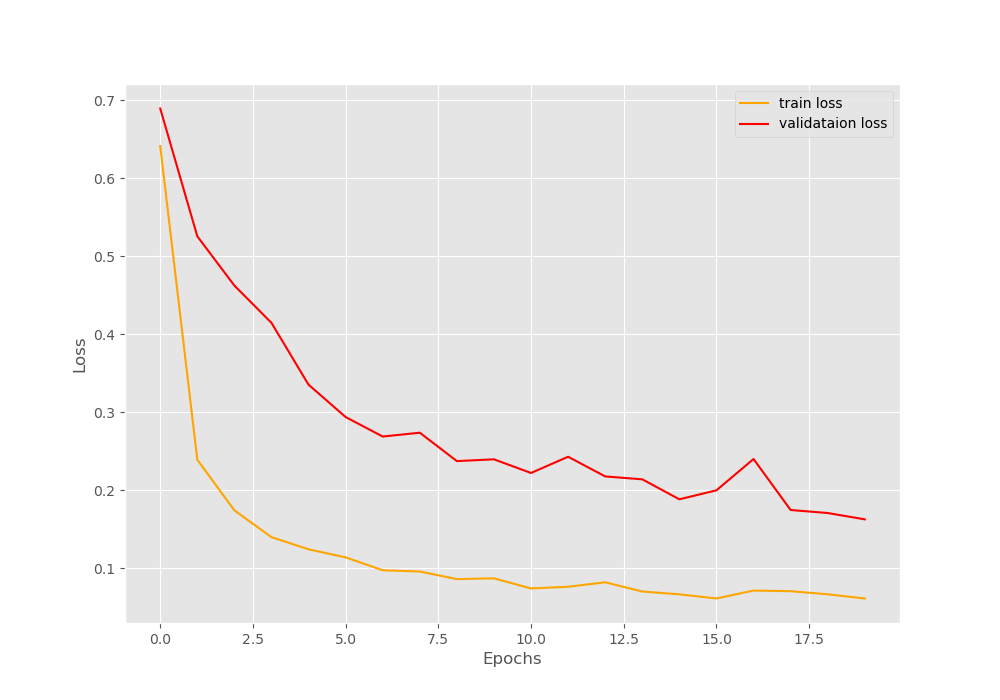
五、训练总结
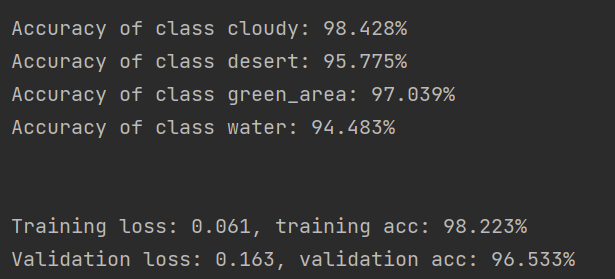
5.1 最终性能指标
-
验证准确率: 96.53%
-
训练准确率: 98.22%
-
验证损失: 0.163
-
训练损失: 0.061
5.2 各类别准确率进展
| 类别 | 第1轮 | 第20轮 | 提升幅度 |
|---|---|---|---|
| cloudy | 87.42% | 98.43% | +11.01% |
| desert | 49.30% | 95.78% | +46.48% |
| green_area | 79.28% | 97.04% | +17.76% |
| water | 98.28% | 94.48% | -3.80% |
5.3关键观察
5.3.1 优秀表现
-
desert类巨大进步 :从49%提升到96%,说明模型成功学会了识别沙漠特征
-
整体性能卓越 :96.53%的验证准确率非常优秀
-
训练稳定 :损失持续下降,没有明显过拟合
-
收敛良好 :最后几轮性能稳定在高水平
5.3.2 需要注意
-
water类轻微下降 :从98%降到94%,但仍保持高水平
-
训练时间波动 : 某些epoch训练时间较长(可能受系统资源影响)
5.4 训练动态分析
5.4.1关键转折点
-
第5轮: desert类突破78%,整体准确率超过92%
-
第9轮: 首次达到95%+验证准确率
-
第18轮: 达到峰值96.53%,desert类突破96%
5.4.2 收敛情况
最后5轮性能稳定在95-96.5%之间,说明模型已经充分训练。
这还只是考虑性能和速度将epoch设置在了20的情况下,如果训练次数设置在32/64,效果应该会更好(根据你的电脑性能决定)~~~
求大佬们的三连~~~代码和数据我都打包放在资源里啦~~~

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 79
79 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)