为什么工业物联网项目偏爱 Apache IoTDB?时序数据管理视角
在工业物联网(IIoT)加速落地的当下,设备每秒产生的温度、压力、振动等时序数据呈爆炸式增长。传统关系型数据库因写入性能不足、存储成本高企,难以应对TB级日增量与毫秒级查询需求;部分通用时序数据库又因未适配工业场景的层级化设备结构,导致数据管理混乱。而Apache IoTDB作为一款由清华大学主导的开源时序数据库,凭借对工业场景的深度优化,已成为工业物联网时序数据管理的核心选择。
前言
在工业物联网(IIoT)加速落地的当下,设备每秒产生的温度、压力、振动等时序数据呈爆炸式增长。传统关系型数据库因写入性能不足、存储成本高企,难以应对TB级日增量与毫秒级查询需求;部分通用时序数据库又因未适配工业场景的层级化设备结构,导致数据管理混乱。而Apache IoTDB作为一款由清华大学主导的开源时序数据库,凭借对工业场景的深度优化,已成为工业物联网时序数据管理的核心选择。

文章目录
一、直击工业痛点:时序数据的核心挑战与IoTDB的应对
工业场景下的时序数据,与互联网监控等场景存在本质差异,这也催生了独特的技术挑战,而IoTDB从设计之初便针对性突破。
1.1 工业时序数据的三大核心特征
- 写入模式特殊:数万台设备实时上报数据,呈现“写多读少、只增不删”的特点,传统数据库的事务机制完全冗余。
- 数据规模庞大:单工厂每日数据量可达TB级,年度轻松突破PB级,存储成本成为项目关键约束。
- 查询需求复杂:需支持“按车间汇总能耗”“查设备近7天温度平均值”等层级化、时间范围类查询,普通数据库聚合性能不足。
1.2 IoTDB的针对性设计
面对上述挑战,IoTDB通过两大创新实现突破:一是树形层级数据模型,将“集团-工厂-车间-设备-测点”的物理结构直接映射为数据路径(如root.factory01.line01.device001.temp),避免跨表关联;二是TsFile专属存储引擎,采用列式存储与RLE、Gorilla等编码算法,压缩比最高可达31:1,远优于InfluxDB的8:1与TimescaleDB的5:1,大幅降低存储成本。
二、技术硬实力:IoTDB的三大核心优势
在工业场景的长期实践中,IoTDB形成了区别于通用时序数据库的独特技术竞争力,核心体现在性能、架构与生态三方面。

2.1 极致性能:满足工业级吞吐与延迟需求
根据TPCx-IoT基准测试,IoTDB的写入吞吐可达363万点/秒,是InfluxDB(52万点/秒)的7倍;查询延迟稳定在2ms级别,远低于InfluxDB的45ms与TimescaleDB的120ms。这一性能表现,足以支撑十万级设备同时上报数据,且能快速响应产线实时监控的查询需求。
同时,其对齐时间序列特性进一步优化性能:同一设备的多个测点(如温度、压力)按时间戳对齐存储,避免时间戳重复写入,写入效率提升30%以上,完美适配工业设备“批量上报多维度数据”的场景。
2.2 端边云协同:覆盖工业全场景部署
工业数据存在“设备端产生、边缘端预处理、云端分析”的流动路径,IoTDB的端边云协同架构可无缝覆盖这一全链路:
- 设备端:轻量版仅需64MB内存,即可实现数据本地缓存与过滤,避免无效数据占用带宽;
- 边缘端:1-8GB内存即可部署,支持断网续传与区域级数据聚合(如车间能耗统计),降低云端压力;
- 云端:分布式集群支持PB级数据存储与全局分析,还可集成AI模型实现故障预测(如宝武钢铁用其提前48小时预警设备故障)。
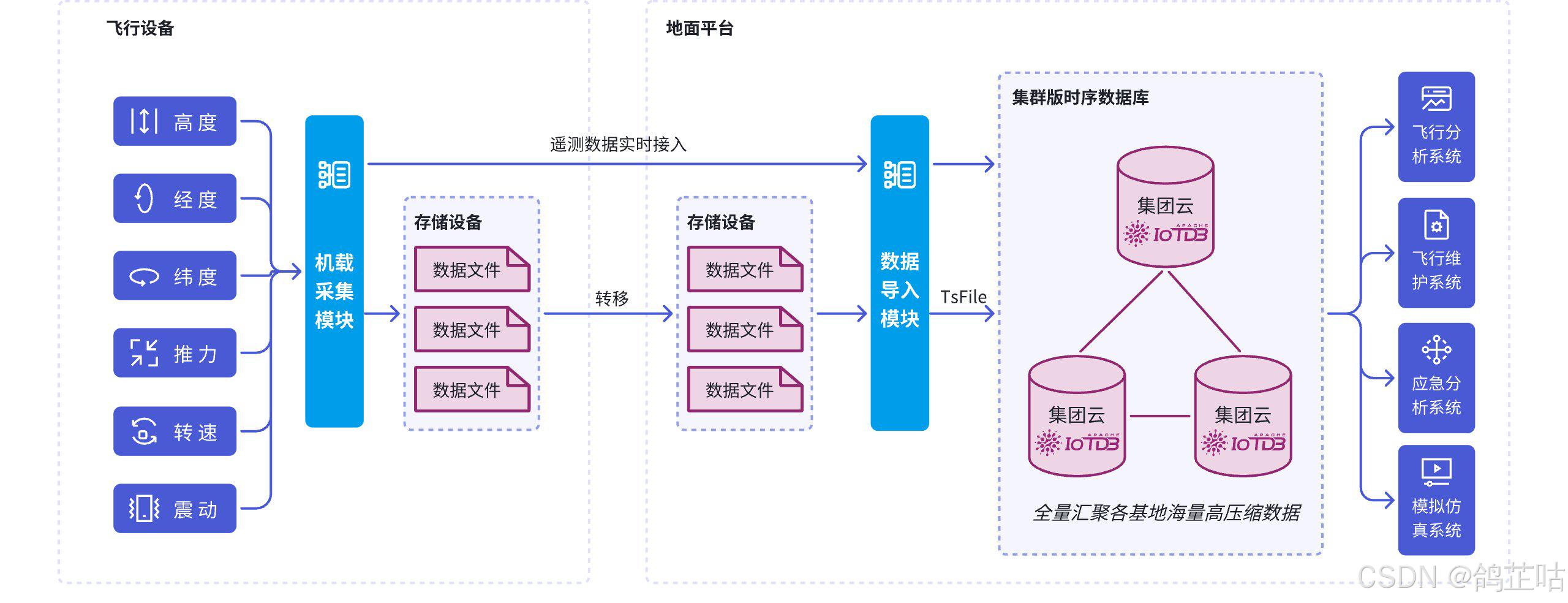
科技进步驱动航空航天数字化智能化转型,企业通过全周期数据管
理整合实时遥测与试飞数据,实现关键系统精准监测,推动设计优
化与安全管控。IoTDB以国产自研技术优势,通过高效低流量同
步、离线迁移、灵活部署及低资源占用特性,为行业构建可靠数据
底座,支撑技术创新与可持续发展。
2.3 生态无缝集成:降低工业数字化迁移成本
工业场景的技术栈往往包含Spark/Flink(流批处理)、Grafana(可视化)、MQTT(设备通信)等工具,IoTDB提供原生连接器,可直接对接这些组件,无需二次开发:
- 数据接入:支持MQTT、Kafka等协议,设备数据可直接写入;
- 分析处理:与Spark、Flink深度集成,可直接读取TsFile文件进行离线分析与实时计算;
- 可视化:通过Grafana插件快速搭建产线监控仪表盘,实现数据“即查即显”。
三、实战指南:10分钟完成IoTDB POC验证
对于工业技术团队而言,快速验证数据库是否适配业务场景至关重要。以下是基于Docker的极简POC流程,可快速测试IoTDB的核心能力。
3.1 环境准备:1分钟启动服务
通过Docker命令即可快速部署IoTDB服务与客户端,无需复杂配置:
# 启动IoTDB服务
docker run -d --name iotdb-server -p 6667:6667 -p 8181:8181 -v iotdb-data:/iotdb/data apache/iotdb:latest
# 进入CLI客户端(默认账号root/root)
docker exec -it iotdb-server /iotdb/sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
3.2 核心功能测试:3步验证关键能力
-
Step 1:创建层级数据模型
用Schema模板批量定义同类型设备的测点结构(如产线设备的温度、压力、振动测点),避免重复操作:-- 创建存储组(类似数据库) CREATE DATABASE root.industrial; -- 创建设备模板 CREATE SCHEMA TEMPLATE device_template ( temperature FLOAT encoding=RLE, pressure FLOAT encoding=RLE, vibration FLOAT encoding=RLE ); -- 应用模板到设备(如车间01的设备001) SET SCHEMA TEMPLATE device_template TO root.industrial.factory01.line01.device001; -
Step 2:批量写入数据
采用对齐写入方式,一次性写入多组时间序列数据,模拟设备实时上报场景:INSERT INTO root.industrial.factory01.line01.device001 (timestamp, temperature, pressure, vibration) ALIGNED VALUES (now(), 25.6, 1.2, 0.03), (now()+1000, 25.8, 1.1, 0.04), (now()+2000, 26.1, 1.3, 0.02); -
Step 3:执行工业级查询
测试层级聚合、时间范围查询等核心能力,验证是否满足业务需求:-- 1. 查询设备近1小时温度、压力数据 SELECT temperature, pressure FROM root.industrial.factory01.line01.device001 WHERE time >= now() - 1h; -- 2. 按10分钟窗口聚合设备温度平均值 SELECT AVG(temperature) FROM root.industrial.factory01.line01.device001 WHERE time >= now() - 1h GROUP BY ([now()-1h, now()), 10m); -- 3. 按车间层级汇总温度平均值(集团-工厂-车间为前3级,LEVEL=3代表车间) SELECT AVG(temperature) FROM root.industrial.** GROUP BY LEVEL = 3;
3.3 性能测试:用工具量化吞吐
通过IoTDB Benchmark工具可快速测试写入与查询性能,只需3步:
# 1. 克隆工具仓库
git clone https://github.com/thulab/iot-benchmark.git && cd iot-benchmark
# 2. 配置测试参数(如设备数量、写入速率,修改conf/iotdb-benchmark.properties)
# 3. 启动性能测试
./benchmark.sh
四、行业实践:IoTDB在三大工业场景的落地
IoTDB已在工业设备监控、智慧能源、车联网等核心场景规模化应用,其设计与业务需求的匹配度得到充分验证。
4.1 工业设备监控:从“被动维修”到“预测性维护”
在制造业场景中,IoTDB的层级数据模型可直接映射“工厂-车间-产线-设备”结构,通过实时存储设备振动、温度等数据,结合AI算法实现故障预警。某汽车零部件厂商应用后,设备故障率降低25%,维修成本减少30%。
核心实践点:
- 用Schema模板批量管理同类型设备,减少80%的配置工作量;
- 设置TTL策略(如1年),自动清理过期的历史监控数据,降低存储成本。
4.2 智慧能源:从“粗放计量”到“精细管理”
在电力、燃气等能源领域,IoTDB可高效存储计量数据与设备运行数据,支持从“设备级”到“区域级”的多层级能耗聚合。某省级电力公司用其管理5000+变电站数据,能耗统计效率提升6倍,负荷预测准确率达92%。
核心实践点:
- 采用冷热数据分层存储,近期热数据存SSD保证查询速度,远期冷数据存HDD降低成本;
- 用窗口函数计算负荷曲线,支撑电网调度决策。
4.3 车联网:支撑百万级车辆实时数据接入
每辆车每小时产生数百条GPS、OBD数据,IoTDB的高并发写入能力可支撑百万级车辆同时上报,且支持“按时间+地理位置”的组合查询(如“查询某区域内车辆近1小时的平均速度”)。某车企车联网平台应用后,数据接入延迟控制在50ms内,查询响应时间<100ms。
核心实践点:
- 用分区路由机制,按车辆所属区域拆分数据,提升写入并行度;
- 对GPS轨迹数据采用特殊压缩算法,存储成本降低60%。

五、选型建议:何时优先选择IoTDB?
并非所有工业场景都需选择IoTDB,以下三类场景是其最佳适配范围:
- 设备具有层级结构:如“集团-工厂-车间-设备”的制造企业、“区域-变电站-线路-电表”的能源企业,IoTDB的树形模型可避免数据碎片化;
- 需端边云协同:设备部署在偏远地区(如油田、风电场),存在断网风险,需边缘端本地缓存、云端统一管理;
- 对成本敏感:数据量庞大(日增量TB级),需高压缩比(≥10:1)降低存储成本,同时要求低硬件投入实现高吞吐。
若仅需小规模设备监控(<1万台)、无层级需求,也可考虑InfluxDB社区版等轻量方案;但当设备规模超10万台、需工业级稳定性与扩展性时,IoTDB是更优选择。
六、总结:工业时序数据管理的“最优解”之一
在工业数字化转型中,时序数据库是连接设备与业务决策的关键基础设施。Apache IoTDB凭借对工业场景的深度理解,通过树形数据模型、端边云协同架构、高压缩比存储三大核心创新,解决了“写入慢、存储贵、查询繁”的工业痛点。
无论是中小制造企业的设备监控,还是大型能源公司的全域数据管理,IoTDB都能提供从“快速POC”到“规模化部署”的全流程支持。随着工业互联网的深入发展,IoTDB有望成为更多企业时序数据管理的“标配”。
相关资源:
- 社区版下载:https://iotdb.apache.org/zh/Download/
- 企业版咨询(含集群管理、技术支持):https://timecho.com

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 101
101 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)