使用 Python 和 HuggingFace Transformers 进行对象检测
在本文中,您将了解这种类型的 Transformer 模型。你还将学习如何使用 Python、默认 Transformer 模型和 HuggingFace Transformers 库构建自己的对象检测管道。事实上,这将非常简单,所以让我们一起来看看吧!
使用 Python 和 HuggingFace Transformers 进行对象检测
一、说明
Yolo!如果您熟悉机器学习,您就会认出这个首字母缩略词。事实上,“你只看一次”已成为近年来物体识别的默认方法之一。由于 ConvNets 的进步,以前已经开发了许多对象检测方法的变体。然而,一个新的竞争对手正在出现:在计算机视觉中使用基于 Transformer 的模型。更具体地说,变压器用于物体检测。
在本文中,您将了解这种类型的 Transformer 模型。你还将学习如何使用 Python、默认 Transformer 模型和 HuggingFace Transformers 库构建自己的对象检测管道。事实上,这将非常简单,所以让我们一起来看看吧!
阅读本教程后:
- 了解对象检测的用途。
- 了解 Transformer 模型在用于对象检测时的工作原理。
- 已实现基于 Transformer 模型的管道,用于使用 Python 和 HuggingFace Transformers 进行(图像)对象检测。
二、什么是对象检测?
看看你的周围。您很可能会看到计算机显示器、键盘和鼠标,或者,如果您使用的是移动浏览器,则会看到智能手机。
这些都是对象或特定类的实例。例如,下图描绘了一个人类病例。我们还观察到许多类瓶子的实例。虽然类是一个蓝图,但对象是真实的东西,具有许多显着的品质,同时由于共享的品质而仍然是类的成员。
照片和视频中有很多此类物品的例子。例如,在拍摄交通视频时,您可能会看到很多行人、汽车和自行车。知道它们在图像中可能会非常有益!
为什么?例如,因为您可以数一数。它允许您观察社区的拥挤程度。另一个例子是在拥挤区域检测停车位,这使您可以停放车辆。等等。这就是对象检测的用途!
三、物体检测和transformer
传统上,对象检测是使用卷积神经网络执行的。通常,它们的架构是专门为对象检测量身定制的,因为它们将图像作为输入并输出图像的边界框。
如果您熟悉神经网络,您就会知道 ConvNet 非常适合学习图像中的重要特征,并且它们在空间上是不变的,这意味着学习到的项目在图像中的位置或它们有多大并不重要。如果网络可以看到对象的属性并将它们与特定类相关联,它就可以识别它们。例如,许多不同的猫可以被识别为属于猫类。
Transformer 设计最近在深度学习领域引起了极大的兴趣,尤其是在 NLP 领域。Transformer 的工作原理是将输入编码为高维状态,然后将其解码为所需的输出。变形金刚不仅学会识别特定模式,还学会将这些模式与其他模式相关联,这要归功于他们巧妙地利用自我注意力。变形金刚可以学习将猫与其特征点联系起来,例如沙发。
如果 Transformers 可用于对图像进行分类,那么只需更进一步检测物体即可。Carion等人(2020)证明,使用基于Transformer的架构可以实现这一目标。在他们的论文 End-to-End Object Detection using Transformers 中,他们描述了检测 Transformer (DeTr),我们今天将利用它来构建我们的目标检测管道。
它的工作原理如下,甚至不会完全放弃 CNN:
- 使用卷积神经网络,从输入图像中派生重要特征。这些是位置编码的,就像在语言 Transformer 中一样,以帮助神经网络了解这些特征在图像中存在的位置。
- 输入被扁平化,随后使用变压器编码器和注意力编码为中间状态。
- 转换器解码器的输入是此状态和一组在训练过程中获取的学习对象查询。你可以把它们想象成一个问题,问:“这里有没有一个物体,因为我以前在很多情况下都见过一个?
- 解码器的输出是通过多个预测头进行的一组预测:每个查询一个。由于 DeTr 中的查询数默认设置为 100,因此除非您对其进行不同配置,否则它只能预测一个图像中的 100 个对象。
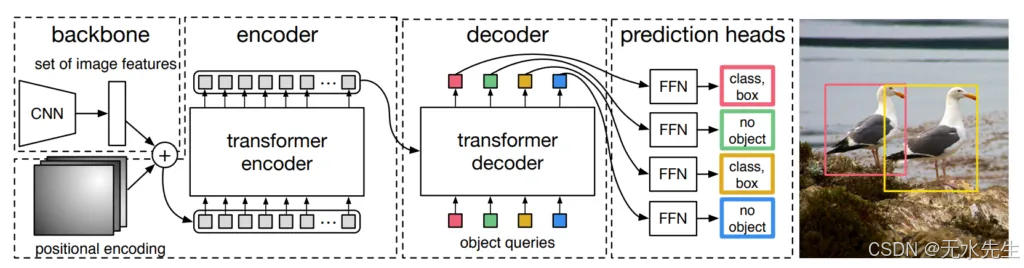
如何使用 Transformers 进行对象检测。摘自Carion等人(2020),End-to-End Object Detection with Transformers,介绍了该管道中使用的DeTr Transformer。
HuggingFace Transformers 及其对象检测管道
现在您已经了解了 DeTr 的工作原理,您可以使用它来构建实际的对象检测管道!
我们将使用 HuggingFace Transformers 来实现此目的,它旨在使处理 NLP 和计算机视觉 Transformers 变得简单。事实上,它使用起来非常简单,只需要加载 ObjectDetectionPipeline,默认情况下,它会加载一个使用 ResNet-50 主干网训练的 DeTr Transformer 来生成图像特征。
现在让我们开始看看技术细节吧!
ObjectDetectionPipeline 可以轻松初始化为管道实例…换句话说,使用 pipeline(“object-detection”),如下面的示例所示。根据 GitHub (nd),当未提供额外输入时,管道将按如下方式启动:
"object-detection": {
"impl": ObjectDetectionPipeline,
"tf": (),
"pt": (AutoModelForObjectDetection,) if is_torch_available() else (),
"default": {"model": {"pt": "facebook/detr-resnet-50"}},
"type": "image",
},
不出所料,使用了 ObjectDetectionPipeline 实例,该实例针对对象检测进行了优化。在 HuggingFace Transformers 的 PyTorch 版本中,使用 AutoModelForObjectDetection 来实现这一点。有趣的是,此管道没有可用的 TensorFlow 实现
正如您所了解的,默认情况下,该模型用于派生图像特征:facebook/detr-resnet-50
DEtection TRansformer (DETR) 模型在 COCO 2017 目标检测(118k 注释图像)上进行端到端训练。它在 Carion 等人的论文 End-to-End Object Detection with Transformers 中进行了介绍。—— HuggingFace
COCO数据集(Common Objects in Context)是用于目标检测模型的标准数据集之一,用于训练该模型。别担心,您显然也可以训练自己的基于 DeTr 的模型。
重要!要使用 ,必须安装包含 PyTorch 映像模型的包。确保在尚未安装此命令时运行此命令:…ObjectDetectionPipelinetimmpip install timm
四、使用 Python 实现简单的对象检测管道
现在让我们来看看如何使用 Python 实现一个简单的对象检测解决方案。
回想一下,我们正在使用 HuggingFace Transformers,它必须安装到您的系统上 - 如果您还没有它,请运行它。pip install transformers
我们还假设安装了 PyTorch,这是当今最流行的深度学习库之一。如前所述,使用管道(“对象检测”)时将在后台加载的 ObjectDetectionPipeline 不包括 TensorFlow 实例;因此,需要 PyTorch。
这是我们将在本文后面运行要创建的对象检测管道的图像:

https://www.cgaa.org/article/health-insurance-asking-about-accident-or-injury
我们从导入开始:
from transformers import pipeline
from PIL import Image, ImageDraw, ImageFont
显然,我们正在使用 ,特别是它的表示。然后,我们还使用 Python 库来加载、可视化和作图像。具体来说,我们使用第一次导入来加载图像并绘制边界框和标签,后者也需要transformerspipelinePILImageImageDrawImageFont.
说到两者,接下来是加载字体(我们选择 Arial)并初始化我们上面介绍的对象检测管道。
# Load font
font = ImageFont.truetype("arial.ttf", 40)
# Initialize the object detection pipeline
object_detector = pipeline("object-detection")
如果您使用的是 Linux,请改用如下内容:
font = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 40)
然后,我们定义一个名为 draw_bounding_box 的函数,可以预见的是,它将用于绘制边界框。它接受图像 (im)、类概率、边界框坐标、将应用此定义的边界框列表中的边界框索引以及列表的长度作为输入。
首先,在图像顶部绘制实际的边界框,表示为红色和小半径的 bbox,以确保边缘光滑。rounded_rectangle
其次,在边界框上方绘制文本标签。
最后,返回中间结果,以便我们可以在顶部绘制下一个边界框和标签。
# Draw bounding box definition
def draw_bounding_box(im, score, label, xmin, ymin, xmax, ymax, index, num_boxes):
""" Draw a bounding box. """
print(f"Drawing bounding box {index} of {num_boxes}...")
# Draw the actual bounding box
im_with_rectangle = ImageDraw.Draw(im)
im_with_rectangle.rounded_rectangle((xmin, ymin, xmax, ymax), outline = "red", width = 5, radius = 10)
# Draw the label
im_with_rectangle.text((xmin+35, ymin-25), label, fill="white", stroke_fill = "red", font = font)
# Return the intermediate result
return im
剩下的是核心部分——使用 然后根据其结果绘制边界框。pipeline
这是我们如何做到这一点的。
-
首先,图像(我们调用并与 Python 脚本位于同一目录中)将被打开并存储在 PIL 对象中。我们只需将其提供给初始化的,这足以让模型返回边界框!变形金刚库负责剩下的事情。street.jpgimobject_detector
-
然后,我们将数据分配给一些变量并迭代每个结果,绘制边界框。
-
最后,我们将图像保存为street_bboxes.jpg
就是这样!
with Image.open("street.jpg") as im:
# Perform object detection
bounding_boxes = object_detector(im)
# Iteration elements
num_boxes = len(bounding_boxes)
index = 0
# Draw bounding box for each result
for bounding_box in bounding_boxes:
# Get actual box
box = bounding_box["box"]
# Draw the bounding box
im = draw_bounding_box(im, bounding_box["score"], bounding_box["label"],\
box["xmin"], box["ymin"], box["xmax"], box["ymax"], index, num_boxes)
# Increase index by one
index += 1
# Save image
im.save("street_bboxes.jpg")
# Done
print("Done!")
使用不同的模型/使用您自己的模型进行对象检测
如果您确实创建了自己的模型或想使用不同的模型,则很容易使用它来代替基于 ResNet-50 的 DeTr Transformer。
这样做需要将以下内容添加到导入中:
from transformers import DetrFeatureExtractor, DetrForObjectDetection
然后,您可以初始化特征提取器和模型,并使用它们而不是默认模型初始化。例如,如果您想使用 ResNet-101 作为主干网,您可以按如下方式执行此作:object_detector
# Initialize another model and feature extractor
feature_extractor = DetrFeatureExtractor.from_pretrained('facebook/detr-resnet-101')
model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101')
# Initialize the object detection pipeline
object_detector = pipeline("object-detection", model = model, feature_extractor = feature_extractor)
五、实验结果
以下是我们在输入图像上运行对象检测管道后得到的结果:
六、完整代码
以下是想要立即开始的人的完整代码:
from transformers import pipeline
from PIL import Image, ImageDraw, ImageFont
# Load font
font = ImageFont.truetype("arial.ttf", 40)
# Initialize the object detection pipeline
object_detector = pipeline("object-detection")
# Draw bounding box definition
def draw_bounding_box(im, score, label, xmin, ymin, xmax, ymax, index, num_boxes):
""" Draw a bounding box. """
print(f"Drawing bounding box {index} of {num_boxes}...")
# Draw the actual bounding box
im_with_rectangle = ImageDraw.Draw(im)
im_with_rectangle.rounded_rectangle((xmin, ymin, xmax, ymax), outline = "red", width = 5, radius = 10)
# Draw the label
im_with_rectangle.text((xmin+35, ymin-25), label, fill="white", stroke_fill = "red", font = font)
# Return the intermediate result
return im
# Open the image
with Image.open("street.jpg") as im:
# Perform object detection
bounding_boxes = object_detector(im)
# Iteration elements
num_boxes = len(bounding_boxes)
index = 0
# Draw bounding box for each result
for bounding_box in bounding_boxes:
# Get actual box
box = bounding_box["box"]
# Draw the bounding box
im = draw_bounding_box(im, bounding_box["score"], bounding_box["label"],\
box["xmin"], box["ymin"], box["xmax"], box["ymax"], index, num_boxes)
# Increase index by one
index += 1
# Save image
im.save("street_bboxes.jpg")
# Done
print("Done!")
就是这样!如今,使用 Transformers 进行对象检测非常容易。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 22
22 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)