《Linux 进阶必备:命名管道与日志制作:原理、实操、优化全流程(中篇)》
命名管道的 “伪文件特性”、日志制作的 “格式规范”、两者结合的 “联动逻辑”,往往让 Linux 学习者陷入碎片化理解。本文打破知识点割裂的问题,以 “原理→实操→优化” 为脉络,先讲透命名管道的工作机制,再逐步推进日志的制作、收集、分析全流程,搭配清晰的步骤拆解和代码示例,让你一文打通 Linux 命名管道与日志制作的知识体系!


前引:命名管道的 “伪文件特性”、日志制作的 “格式规范”、两者结合的 “联动逻辑”,往往让 Linux 学习者陷入碎片化理解。本文打破知识点割裂的问题,以 “原理→实操→优化” 为脉络,先讲透命名管道的工作机制,再逐步推进日志的制作、收集、分析全流程,搭配清晰的步骤拆解和代码示例,让你一文打通 Linux 命名管道与日志制作的知识体系!
目录
【一】命名管道
(1)介绍
在“初篇”我们学习了匿名管道,即不需要文件名、路径直接在内存中打开,“命名管道”那不就是有文件名、路径的打开方式,当然这样说认识不全,请继续向下查看!
(2)特性讲解
(1)文件存在形式
打开的文件有真实的路径、文件名
(2)通信范围
“命名管道”可以实现任意两个进程的通信,不依赖血缘关系
(3)创建方式
通过系统调用 mkfifo()或者指令 mkfifo 创建
(4)单向通信
即同一时间要么执行写端要么执行读端
(3)如何使用
(1)命令方式
执行命令:
mkfifo 管道名作用:创建一个管道,比如 mkfifo media(管道就是一个存储的文件缓冲区)
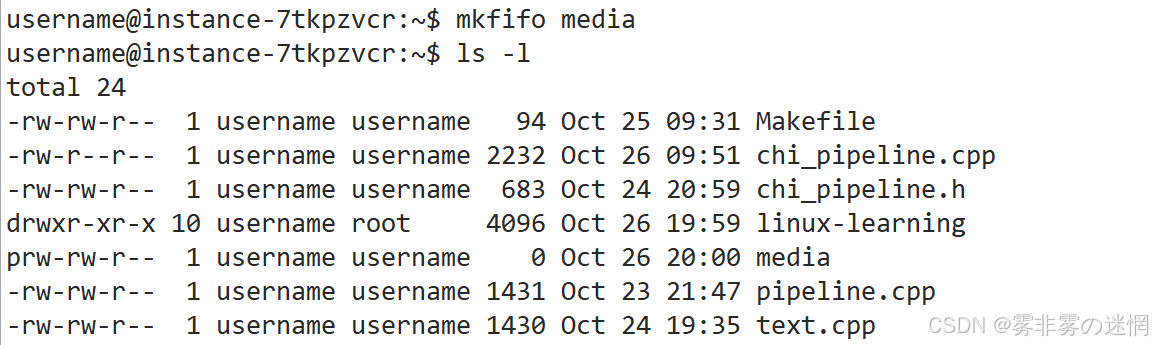
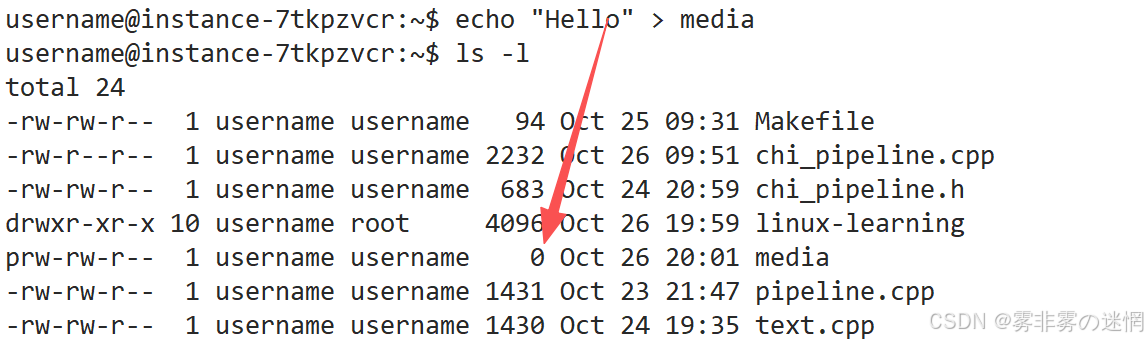
使用:比如跨进程执行管道读写操作

为什么管道的大小一直是0?
按理说向管道写入内容,管道大小会发生改变,但是并没有:
因为管道起临时文件缓冲区作用,只是执行两个进程的通信,命名管道并不是向磁盘写入
(2)系统调用接口
注意:管道的使用必须同时打开读写端:匿名管道在 pipe()时同时打开读写端
命名管道需要手动控制休眠满足同时打开条件
函数原型:
#include <sys/stat.h> // 必须包含的头文件
#include <sys/types.h> // 辅助头文件
int mkfifo(const char *pathname, mode_t mode);第一个参数:指定要创建的命名管道的路径和文件名(类似指令版的“media”)
第二个参数:创建管道的权限设置(和文件权限类似,比如0666)
返回值:
成功:返回0
失败:返回-1,并且会设置errno(错误码)
使用:(注意:管道的读端和写端都是两个文件,因此需要都执行编译才可正常读写)
我们知道文件操作基本都是通过文件下标描述符 fd 来完成的,因此需要先获取 fd ,然后操作
例如:open()获取文件描述符->用write()执行写入->用read()执行读取
让 Write.cpp 通过命名管道 media 与 Read.cpp 执行通信
头文件:
#pragma once
#include<iostream>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#include <string.h>
#define Permission 0666Write.cpp:
#include"Media.h"
int main()
{
//创建命名管道
int d =mkfifo("media",Permission);
if(d==-1)
{
perror("mkfifo");
return 1;
}
//std::cout<<"创建成功"<<std::endl;
//打开命名管道
int fd =open("media",O_WRONLY);
if(fd==-1)
{
perror("open");
return 1;
}
//std::cout<<"打开成功"<<std::endl;
//写入命名管道
const char* ptr="Hello Linux";
ssize_t count =write(fd,ptr,strlen(ptr));
if(count==-1)
{
perror("write");
return 1;
}
//std::cout<<"写入成功"<<std::endl;
//关闭命名管道
close(fd);
return 0;
}Read.cpp:
#include"Media.h"
#define Read_Max 20
int main()
{
//打开命名管道
int fd =open("media",O_RDONLY);
if(fd==-1)
{
perror("open");
return 1;
}
//读取命名管道
char buff[Read_Max]={0};
ssize_t count =read(fd,buff,Read_Max);
if(count==-1)
{
perror("read");
return 1;
}
std::cout<<"我从管道读取到了:"<<buff<<std::endl;
//关闭命名管道
close(fd);
return 0;
}makefile:
Complie:Read.cpp Write.cpp
g++ -o Read Read.cpp -std=c++11
g++ -o Write Write.cpp -std=c++11
Execute:
./Write & sleep 1
./Read
#必须同时打开
all:Complie Execute
.PHONY:
clean:
rm -f Read Write media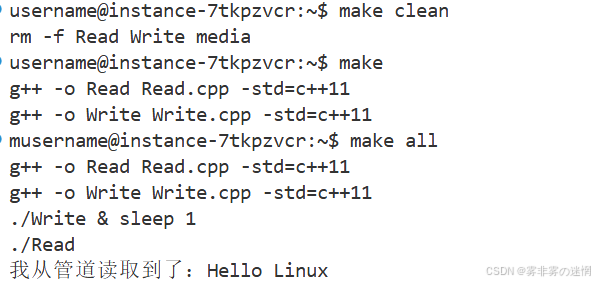
【二】简易日志
我们的函数调用一般通过判断返回值来判断该函数是否执行成功,一般是通过 perror 来打印错误
今天我们学习一种新的打印方式:将错误日志化处理(打印日志时间、等级、错误类型......)
(1)可变参数
在使用日志化前我们需要先学习“可变参数”:即接收的参数随着传参的多少而发生变化
这种特性靠 “可变参数” 实现。它的核心是通过一组宏来管理不确定数量的参数列表
要使用可变参数,必须包含头文件
<stdarg.h>,它提供了 4 个关键 “工具”:
va_list:参数列表的 “容器”,用来存储可变参数的列表va_start:初始化参数列表,让va_list指向第一个可变参数va_arg:获取下一个参数,并指定参数的类型(如int、double等)va_end:清理参数列表,释放资源
例如:(求和为例)第一个参数 n 代表需要计算的参数个数,比如n=3,你就传(3,20,10,200)
下面va_list s,中的 s 理解为一个存储有效参数的容器
//以求和为例
int Add(int n,...)
{
//保留最终结果
int end=0;
//存储可变参数
va_list s;
//初始化参数列表
va_start(s,n);
//通过va_arg获取下一个参数
for(int i=0;i<n;i++)
{
end+= va_arg(s,int);
}
//清理参数列表
va_end(s);
return end;
}(2)制作日志
日志的内容以下面比较基础的信息为例:
- 日志等级:区分调试(DEBUG)、信息(INFO)、错误(ERROR)等类型
- 日志时间:精确到 “年 - 月 - 日 时:分: 秒”
- 日志位置:发生错误的文件信息
- 日志原因:自定义的错误描述(支持可变参数,类似
printf格式)
(1)定义日志等级
我们采用宏定义对应的日志等级,自己可以逐渐丰富:
#define LOG_LEVEL_DEBUG "DEBUG"
#define LOG_LEVEL_INFO "INFO"
#define LOG_LEVEL_ERROR "ERROR"(2)制作日志时间
认识结构体 tm 和时间戳:
在C语言中,有一个专门获取时间的核心结构体:struct tm,头文件<time.h>
struct tm
{
int tm_sec; // 秒(0-59)
int tm_min; // 分(0-59)
int tm_hour; // 时(0-23)
int tm_mday; // 日(1-31)
int tm_mon; // 月(0-11,0代表1月)
int tm_year; // 年(当前年份 - 1900,比如2025年则是125)
int tm_wday; // 星期(0-6,0代表周日)
int tm_yday; // 年内第几天(0-365)
int tm_isdst; // 夏令时标记(正数为夏令时,0为非夏令时,负数表示未知)
};上面的时间格式核心结构体 tm 类似一个中间转化,我们还需要时间戳来获取转化对象:
time_t now = time(NULL); // NULL表示获取当前时间戳
struct tm* tm_now = localtime(&now); // 转换为本地时间的struct tm随后就可以使用结构体 tm 来转化 时间戳 ,变得更加人性化了:
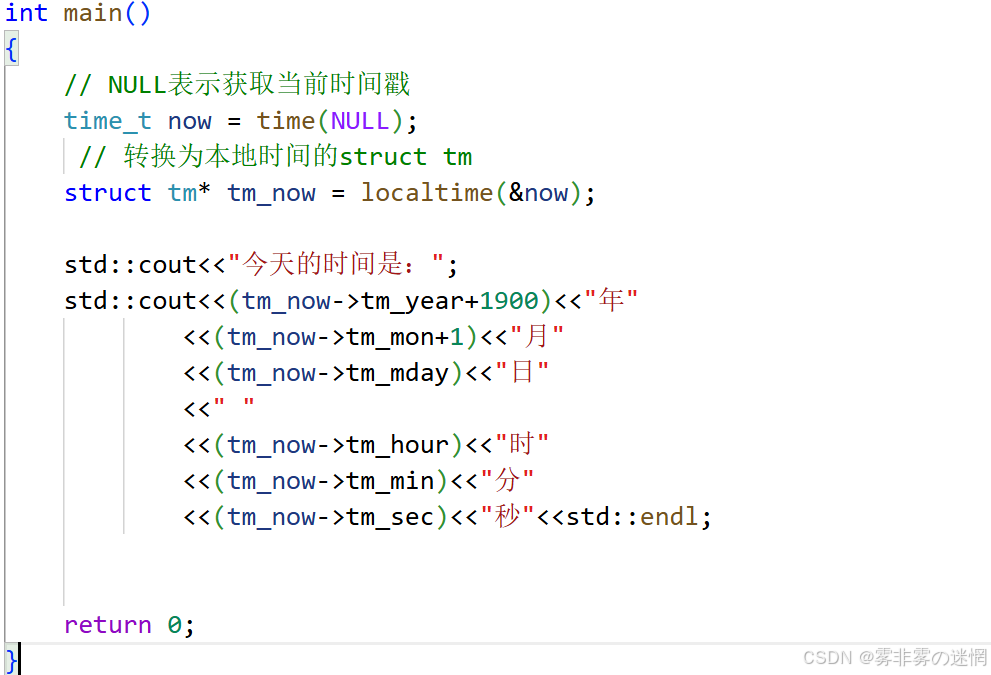
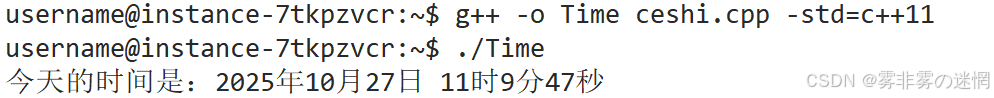
格式化输入:
然后我们利用 strftime 输出格式化的字符串到 buff 数组里面:
const char* Time()
{
// NULL表示获取当前时间戳
time_t now = time(NULL);
// 转换为本地时间的struct tm
struct tm* tm_now = localtime(&now);
//格式版
static char buff[32]={0};
strftime(buff, sizeof(buff), "%Y-%m-%d %H:%M:%S", tm_now);
return buff;
}(3)日志核心输出
//日志核心输出 等级 文件名 行号 错误原因(用可变参数可以完整的打印错误信息)
void log_message(const char* level,const char* file,const char* line,const char* because,...)
{
// 存储格式化后的错误原因
char msg_buf[1024] = {0};
//存储可变参数
va_list s;
//初始化参数列表
va_start(s,because);
//将核心信息统一存到数组
vsnprintf(msg_buf, sizeof(msg_buf), because, s);
//为什么没有用Va_arg:通过 vsnprintf 等函数间接处理时:类型由 “格式字符串” 隐式指定
//清理列表
va_end(s);
std::cout<<"等级:"<<level<<" "<<"时间:"<<Time()<<" "<<"文件名:"<<file<<" "<<"行号:"<<line<<" "<<"错误原因:"<<msg_buf<<std::endl;
}效果:

为什么“because”是接收错误原因,还要采用可变参数专门处理?
你可以理解为“because”采用可变参数就可以像 printf 那样通过占位符格式化输出,例如:


(3)简易日志代码及优化
日志等级:
//日志等级
#define LOG_LEVEL_DEBUG "DEBUG"
#define LOG_LEVEL_INFO "INFO"
#define LOG_LEVEL_ERROR "ERROR"日志时间:
//日志时间
const char* Time()
{
// NULL表示获取当前时间戳
time_t now = time(NULL);
// 转换为本地时间的struct tm
struct tm* tm_now = localtime(&now);
//格式版
static char buff[32]={0};
strftime(buff, sizeof(buff), "%Y-%m-%d %H:%M:%S", tm_now);
return buff;
}日志核心输出:
(注意:这里将 line 参数类型改为 int ,因为我们可以使用宏__FILE__和__LINE__自动获取文件 名和当前的行号)
//日志核心输出 等级 文件名 行号 错误原因(用可变参数可以完整的打印错误信息)
void log_message(const char* level,const char* file,int line,const char* because,...)
{
// 存储格式化后的错误原因
char msg_buf[1024] = {0};
//存储可变参数
va_list s;
//初始化参数列表
va_start(s,because);
//将核心信息统一存到数组
vsnprintf(msg_buf, sizeof(msg_buf), because, s);
//为什么没有用Va_arg:通过 vsnprintf 等函数间接处理时:类型由 “格式字符串” 隐式指定
//清理列表
va_end(s);
std::cout<<"等级:"<<level<<" "<<"时间:"<<Time()<<" "<<"文件名:"<<file<<" "<<"行号:"<<line<<" "<<msg_buf<<std::endl;
}效果展示:(后续可以使用宏封装二次简洁代码,小编很懒!就不继续深入了........)




助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 89
89 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)