π∗0.6——通过RL框架RECAP微调流式VLA π0.6:先基于示教数据做离线RL预训练,再SFT,最后在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预)
前言
今25年11.18上午,一朋友在我组建的「七月具身:π0和π0.5复现微调群」群内说:pi0.6发布了,我当时还表示PI公司牛啊

另一朋友说:“感觉现在都转向强化学习了呀”,其实
- 一方面,远的,早在ChatGPT于22年年底火爆全球后,便通过RLHF这一范式向所有人证明了,RL是一条相当于有前途、潜力的方向,是康庄大道
——
更不用说,今年年初deepseek R1-zero,直接摒弃掉ChatGPT三阶段训练范式(SFT-RM-PPO)中最开始的SFT,直接RL训练(规则奖励建模 然后没有critic的GRPO迭代)
此举,首次公开研究验证LLM的推理能力,可以纯粹通过RL激励,而无需SFT - 二方面,如此文《πRL——首个在线RL微调流式VLA π0/π0.5的框架:通过Flow-Noise和Flow-SDE实现精确对数似然估计,全面提升性能》开头所说的
今年8月底,我便预言道:vla + RL的结合,基本是趋势了,再加之如下图所示的「hil-serl」这类真机RL框架的成功
加速了vla + RL的结合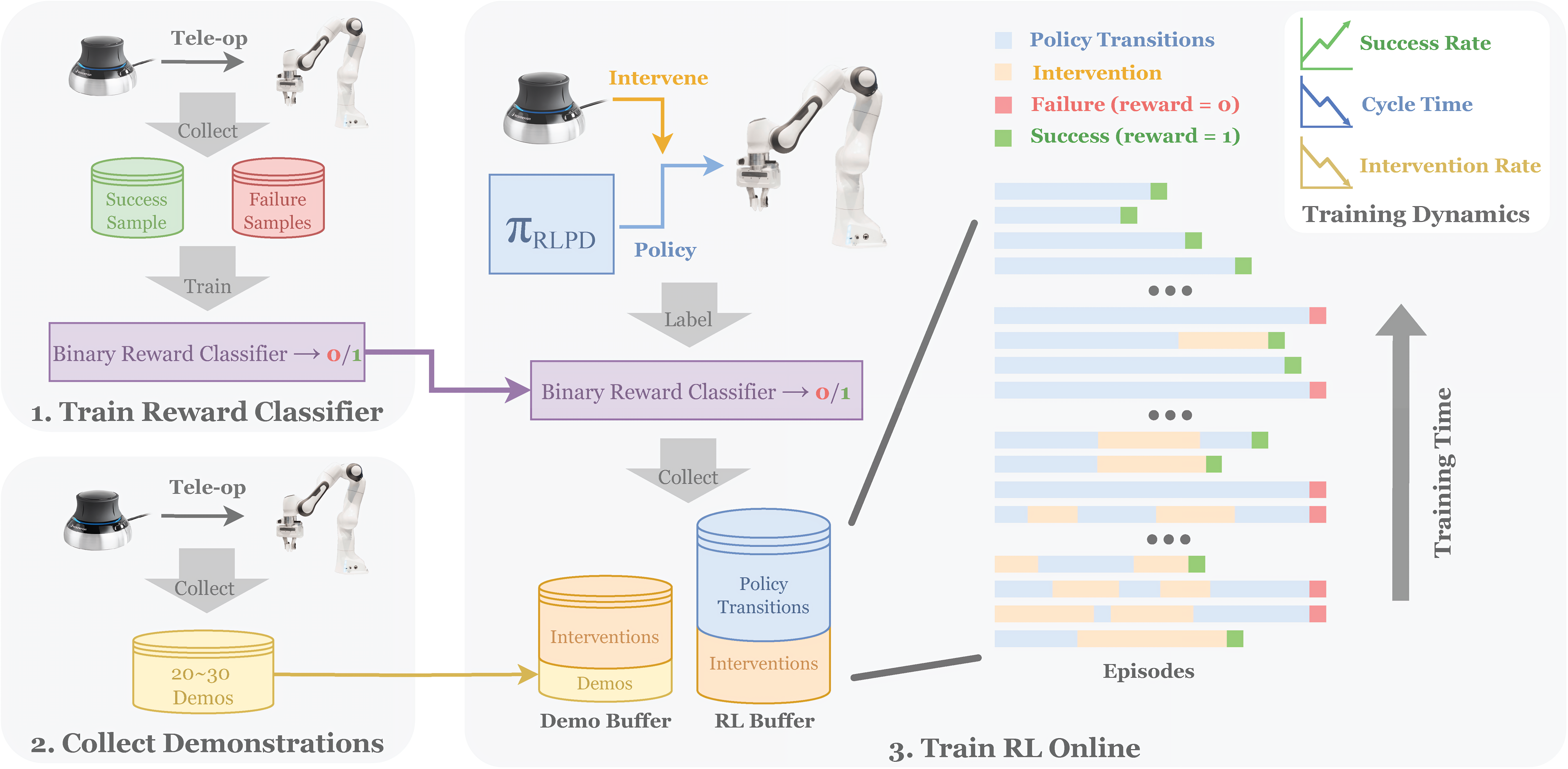
再顺带
- 如果你对RL还不熟,则可看看此文《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》,在万千资料中 该文会让你眼前一亮的
- 此外,我在解读过程中补充了大量的解释说明、技术细节(很多技术细节 都可以作为我司和同行们 招人的面试题),如果你只是想大概了解一下背后相关的技术,那不一定非得抠细节
如果你想抠细节,则可能需要你耐着性子 慢慢看,避免图快
第一部分 π∗0.6:能够从经验中学习的 VLA
1.1 引言、相关工作、预备知识
1.1.1 引言
如π∗0.6原论文所说,尽管人类在习得新技能方面具有非凡的灵活性,但要真正掌握一项技能,无一例外都需要从反复尝试中学习
随着通用机器人基础模型的出现,比如VLA可以通过prompts为通用型机器人灵活地指定任务,但就像人一样,这些模型要想真正掌握一项技能,就需要不断练习。这意味着不仅
- 要利用示范数据
示范数据类似离线数据下的示范 - 还要利用自主收集的经验数据
自主经验数据 类似真机与真实环境交互所产生的数据
使策略能够纠正在实际部署中真正发生的错误,将速度和鲁棒性提升到超过人类远程操控的水平
通过自主练习进行学习的理论基础,已经由RL[1-Reinforcementlearning: An introduction]形式化提出并为人所知数十年
然而,要在一个通用且可扩展的机器人学习系统中将这些原理落地实现,仍然面临重大挑战:
- 需要为大规模模型设计既可扩展又稳定的RL 方法
- 处理来自不同策略的异构数据
- 并且在真实世界中搭建具备奖励反馈的 RL 训练流程——在这种环境下,奖励信号可能含糊不清或具有随机性
对此,PI公司提出了RECAP(RL with Experience and Corrections via Advantage-conditioned Policies),该方法使VLA 模型能够在训练流水线的所有阶段(从预训练一直到在来自自主执行的数据上进行训练)中纳入奖励反馈
RECAP 旨在通过一种通用方案来解决这一问题,该方案结合了示范数据、自主经验以及专家干预
- 其从通用的训练方案出发,为了构建一个通用的 VLA 并在来自许多不同机器人平台的多样数据上进行训练,RECAP 首先使用离线 RL对 VLA 进行预训练
- 随后再利用在部署过程中收集到的数据进行额外训练(即后训练)
在这些部署过程中,机器人会根据每次试验结果获得(稀疏的)奖励反馈,并且可能会收到额外的专家干预以纠正错误
具体而言
- RECAP的训练过程遵循离线强化学习[2,3-Offline reinforcement learning: Tutorial, review,and perspectives on open problems]的范式:
第一步,作者训练一个价值函数,用来评估任务朝向成功完成的推进程度
By conditioning the policy on an improvement indicator based on this advantage [4], we can obtain an improved policy
————
说的更直白点,模型在看视频中人类做任务的过程中,价值函数会一步步预判距离最终成功状态的进度得分(有点像过程中的奖励),通过让价值函数不断预判的越发准确,最终选出前30%最有希望完美成功的一系列好的动作(这类好的动作便具备超越常规预期且得分在前30%的优势值)
至于为何是30%,别急,下文会解释说明的 - RECAP预训练好了之后,便可以使用RECAP 来为复杂任务训练策略,例如折叠多样的衣物、组装纸箱或制作意式浓缩咖啡饮品
————
这些新数据会不断加入任务数据池,随后 Recap 会对全部数据重新训练价值函数(即RL后训练中依然会用到价值函数),价值函数越训练越强,对“成功距离”的判断也越准确
更新后的价值函数再计算所有动作的 advantage(优势),并作为额外输入反哺给策略模型,使 π*0.6 能够从好动作中学习、从坏动作中避开,策略自然越来越强
下图图1展示了RECAP的高层次流程概览
RECAP使得可以通过奖励反馈和干预来训练 VLA。该系统以一个预训练的、包含优势条件化advantage conditioning的 VLA 开始(相当于离线RL),使模型能够有效地从真实世界经验中学习。针对每项任务,部署模型,并收集自主rollouts和在线人工纠正
随后,在这些在线数据上微调价值函数,从而提升其对动作如何影响性能的评估准确性。对VLA进行微调并基于更新后的优势估计进行条件化,反过来又能改进策略行为
比如作者在图2 中展示了其中一些任务「π∗0.6 trained with RECAP can make espresso drinks, assemble cardboard boxes, and fold diverse and realisticlaundry with a high success rate」

- 第一阶段,首先通过离线RL,在多任务和多机器人多样化数据集上对π∗0.6 模型进行预训练
——
π∗0.6 是π0.6 模型面向RL 的一个改编版本,而π0.6是在π0.5 [5] 基础上的改进,增加了更大的主干网络和更丰富的条件多样性[6]
π∗0.6 相当于增加了在二值化优势值上进行条件建模的能力(即集成优势函数),从而可以引入价值函数来改进策略 - 第二阶段,在预训练之后,π∗0.6 通过“演示数据”对π∗0.6 模型进行下游任务微调(即SFT),然后执行一次或多次基于机器人在线采集数据的迭代,以通过RL 改进模型
After pre-training π∗0.6 finetunes the π∗0.6 model to a down stream task with demonstrations, and then performs one or more iterationsof on-robot data collection to improve the model with RL. - 第三阶段,再之后,使用RECAP 在自主经验上训练π∗0.6(并结合专家纠错,循环迭代),在一些最难的任务上可以将吞吐量提高一倍以上,并且可以将失败率降低2× 或更多
最终,这使得π∗0.6 在鲁棒性方面达到了实际可用的水平:比如能够让其连续制作意式浓缩咖啡饮品达13 小时,在一个新的家庭环境中连续两个多小时不断折叠新的衣物物品,并组装在工厂中用于真实包装的纸箱
1.1.2 相关工作
首先,基于模仿学习训练的策略已知容易产生累积性错误[7],并且其性能最多只能与演示数据持平
说白了,VLA控制机器人时,它会像任何模型一样犯一些小错误——例如,抓取器位置错误、抓取失败或碰倒物体。由于机器人是在与真实的物理环境交互,这些错误会导致与训练数据中的情况略有不同,机器人更有可能犯下更大的错误,从而导致误差累积。小错误可以修复,但累积误差会导致失败
亦如此文《一文通透ACT——斯坦福ALOHA团队推出的动作分块算法:基于CVAE一次生成K个动作且做时间集成》所说的
1.1.2 行为克隆(Behavioral cloning, BC)中为何要引入ACT
- 模仿学习使机器人能够直接从专家处学习。行为克隆(Behavioral cloning, BC)是最简单的模仿学习算法之一,将模仿学习视为从观测到动作的监督学习问题
行为克隆(BC)的一个主要缺陷是累积误差,即前一个时间步的错误会逐步积累,导致机器人偏离其训练分布,从而进入难以恢复的状态 [47,64]- 这一问题在精细操作场景中尤为突出 [29]。缓解累积误差的一种方法是允许额外的基于策略的交互和专家纠正,例如DAgger [47] 及其变体 [30,40,24]
..
本文的目标是通过超越仅依赖离线示范的模仿学习,提升视觉-语言-动作策略的可靠性与执行速度
- 已有的相关研究通过在线干预提升了机器人操作策略的性能[8–11]
对于文献11,参见此文《RaC——挂衬衫且打包外卖盒:如果机器人将失败,则人类让其先回退后纠正,以减缓IL中的误差累积(让数据的增长对任务促进的效率更高)》
——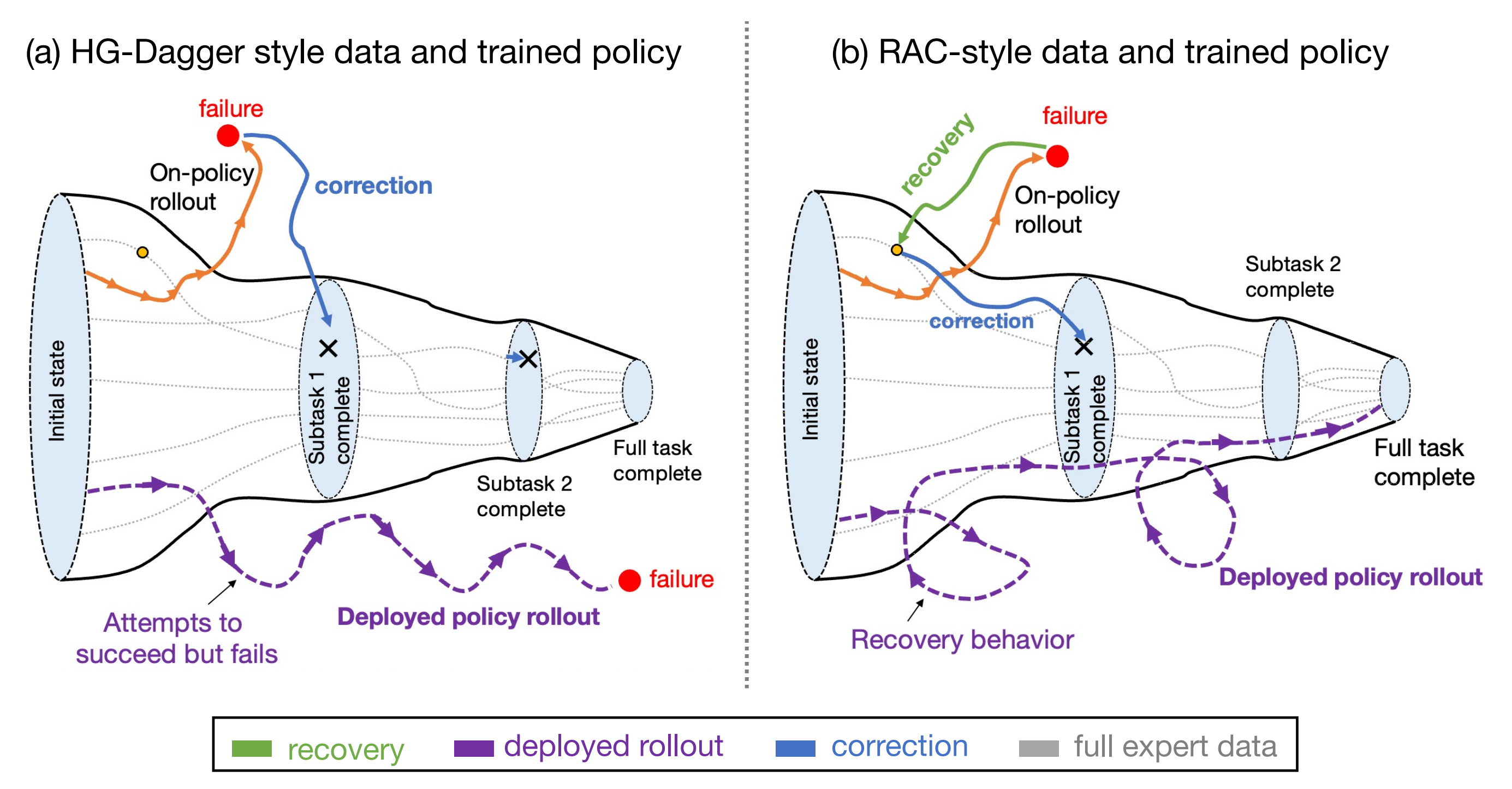
而作者采用了一种被称为“human-gated DAgger”的干预方法[10,12]
与这些方法不同,π∗0.6同时利用专家干预数据和完全自主采集的经验,构建了一个融合多种数据来源的RL框架 - 已有大量研究针对利用强化学习自主改进机器人操作策略[13–21]

包括基于扩散的策略方法[22–24,其中文献23是Diffusion Policy Policy Optimization]、多任务场景下的方法[25,26],以及使用预训练多任务策略的方法[27–29]
有别于这些研究,作者重点探讨如何将真实世界中的强化学习扩展到大规模 VLA 策略上,以应对长时程、细粒度的操作任务
其次,许多近期工作研究了如何通过强化学习RL改进基础 VLA 模型
- 其中,一些工作直接将近端策略优化(PPO)算法及其变体应用于VLA微调『30–34,其中文献31是vla-rl,文献33是πRL,详见此文《πRL——首个在线RL微调流式VLA π0/π0.5的框架:通过Flow-Noise和Flow-SDE实现精确对数似然估计,全面提升性能》』
但这些方法难以高效且可扩展地应用到真实世界的强化学习场景 - 另一类研究则着眼于在预训练VLA模型基础上进行强化学习微调,这包括通过强化学习
35-Improving vision-language-action model with online reinforcement learning,即清华等相关团队于25年1月份提出的iRe-VLA,详见此文《iRe-VLA——RL微调VLA:先SFT、后在线RL,最后结合“离线演示和在线成功数据”对VLA做SFT(含GRAPE的详解)》
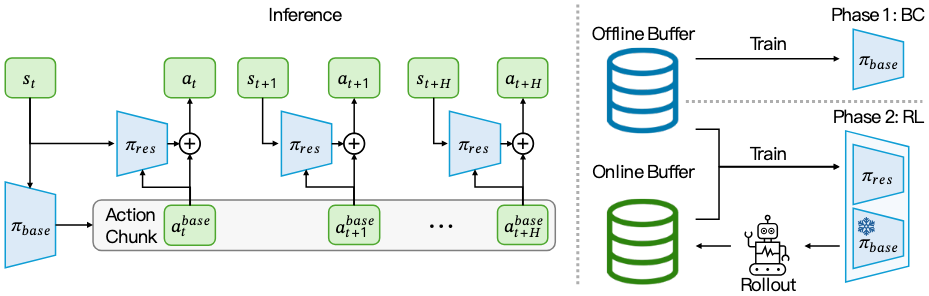
36-Self-improving vision-language-action models with data gen-eration via residual rl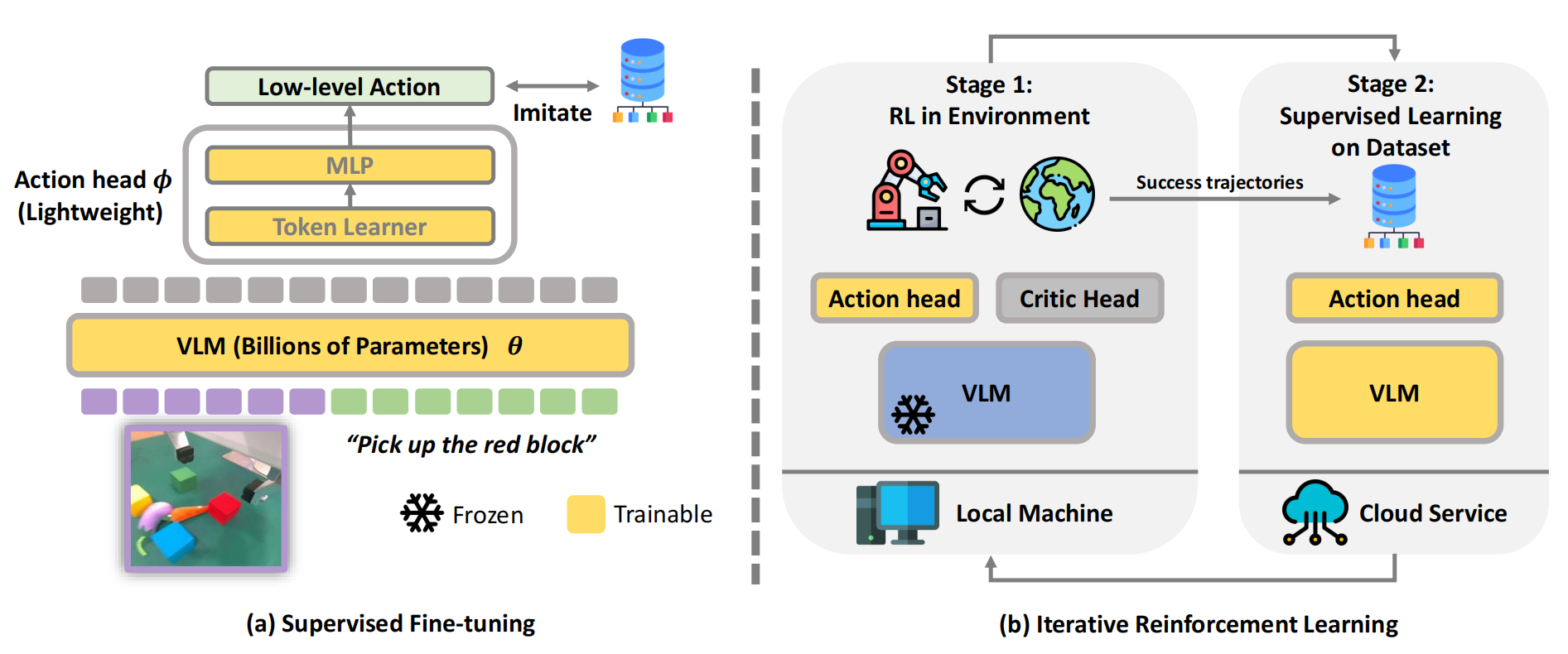
[37-Conrft: A reinforcedfine-tuning method for vla models via consistency policy]
————
此外,一些研究还探索了如何将学习到的行为蒸馏回VLA模型,实现端到端的迭代改进[35,36,38,42]
关于文献42-Rldg: Robotic generalist policy distillation via reinforce-ment learning,参见此文《知识蒸馏RLDG:先基于精密任务训练RL策略(HIL-SERL),得到的RL数据去微调OpenVLA,最终效果超越人类演示数据》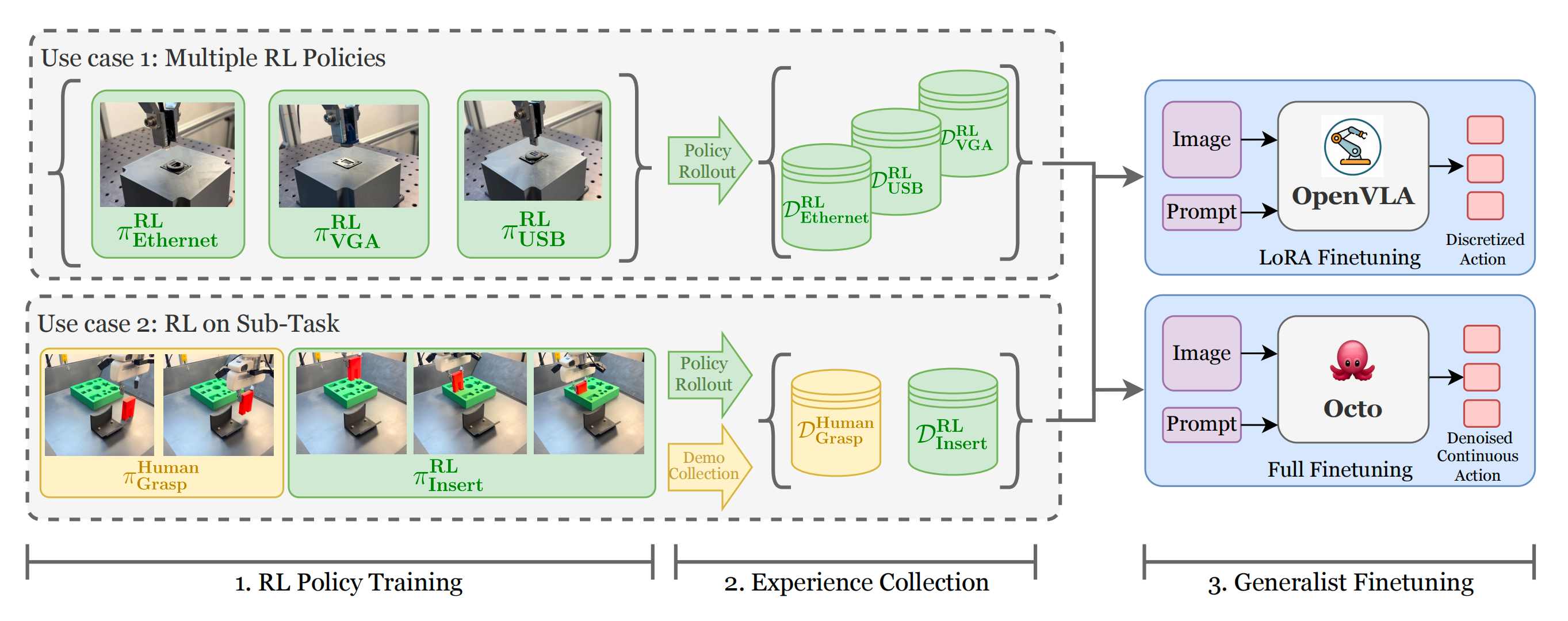
以往的相关工作通常采用离散动作或简单的高斯连续动作分布。一个关键区别在于,作者通过(迭代)离线强化学习,用表达能力极强的流匹配VLA模型对整个VLA进行端到端训练
这得益于一种简单且可扩展的优势条件化策略提取方法,使得在大型 VLA 模型上使用策略梯度风格目标的复杂度大大降低。在对比实验中,作者展示了该方法显著优于更传统的基于策略梯度的策略提取方案
在方法论上,与RECAP更为接近的是,一些先前的研究已经在真实机器人上集成了价值函数与端到端的VLA强化学习训练 [43–46]
- 例如,Huang 等人 [43-Co-RFT: Efficient Fine-tuning of Vision-Language-Action Models through Chunked Offline Reinforcement Learning]
将校准过的 Q-learning 应用于:用于抓取任务的离线示范数据集,而不包含在线改进阶段
Zhang 等人 [44-即GRAPE: Generalizing Robot Policy via Preference Alignment]使用直接偏好优化(DPO)在源自人类偏好的基础上优化抓取-放置技能,并利用 VLA 的在线 rollout - 最后,Zhai 等人 [45-即A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning ]
和
Ghasemipour 等人 [46-即Self-Improving Embodied Foundation Models]
分别使用带有基于完成时间价值函数的 PPO 和REINFORCE 来训练 VLA,用于移动碗、展开垫子以及在桌面上推动物体等任务
与这些前人工作相比,作者提出了一种迭代式的VLA离线强化学习框架,具有多项优势
- 首先,π∗0.6支持高容量的diffusion式和 flow-based 的 VLA,而这不同于以往工作中研究的离散动作模型
- 其次,π∗0.6通过引入优势条件(advantage conditioning)策略提取方法,避免了对策略依赖型PPO或REINFORCE的需求,从而能够利用所有历史(无论是离策略还是离线)数据
- 最后,π∗0.6的评估场景涵盖了复杂的、灵巧的、时间跨度较长的任务,在处理可变形物体、液体以及多阶段任务时,吞吐量提高了约2倍
总之,先前的工作已经探索了在奖励、价值和优势[47–56,其中55是Advantage-conditioned diffusion: Offline rl via general-ization]上对策略进行条件化的思想,其中包括使用classifier-free guidance [4] 的方法
作者将这一方法扩展应用于大规模通用 VLA 策略的预训练和微调 [5],并结合多种数据源(包括演示、干预以及自主策略演化),以学习真实的机器人操作任务
近期研究还探讨了如何有效地训练多任务、以语言为条件的奖励函数 [57–63] 和价值函数 [45,64,65]。在这些工作的基础上,作者同样训练了一个语言条件化的分布式价值函数,从而能够在以优势为条件的 VLA 训练框架中估计状态-动作优势
1.1.3 预备知识
首先,对于强化学习
考虑标准的RL 设置,其中智能体由策略给出,根据观测
选择动作
。作者将轨迹定义为
轨迹上的分布由策略
和随机动力学
产生「可以假设观测
构成一个有效的马尔可夫状态」:
- 奖励函数被定义为
,作者将其简写为
以简化符号
其中为终止奖励,可以将累积回报(或收益)定义为
PS,这里作者没有使用折扣因子,当然也可以容易地添加 - 强化学习的目标是最大化累积回报(或收益),即通过学习一个最大化
的策略
策略π 的价值函数被定义为 - 随后可以计算某一动作
的优势值,即
这对应于一个n 步估计
其次,对于正则化强化学习
在强化学习中,人们通常不是直接最大化,而是使用正则化,优化一种在保持接近某个参考策略
的同时,又能最大化回报的策略[66-70]
具体而言,当希望在同一批数据上进行多步梯度更新时,此时 通常对应于收集训练数据时的行为策略(比如在下文涉及到RL在线后训练时,便会通过
与环境交互,先收集一批经验数据)
PS,这个其实本质就是PPO,策略迭代时,尽可能不要脱离参考策略(或经验收集策略)
太远
- 对于PPO的介绍,详见本文开头前言中提到的此文《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》的4.4节
- 对于通过旧策略与环境交互 而采集经验数据的完整流程,则可以参见下面这两篇文章
这个可以通过如下目标函数形式化:
其中表示某种散度度量
- 当
为KL 散度时,有一个众所周知的结果:
是
的解,其拉格朗日乘子为
[67-70]
- 该优势条件下的策略提取方法基于一个密切相关但但不太为人所知的结果
如果定义策略
————
其中表示任一动作
在某单调递增函数
下相较于
有提升的概率
那么保证会优于
[4, 71]
将在下文(对应于原文的第四节B 部分)中利用该性质推导该策略提取方法
利用上述定义,随后可以通过求解如下最小化问题,从 的闭式定义中得到一个参数化的策略:
1.2 RECAP训练的三个关键:数据收集、价值函数训练、优势条件训练
RECAP本质基于经验的RL(RL with experience)及通过优势条件化策略进行纠正的VLA方法,其训练(不论是预训练,还是后训练)包括以下步骤,这些步骤可以重复一次或多次,以改进基础的 VLA 模型:
- 数据收集:示教数据做预训练,自主和人工纠错数据做后训练
在该任务上运行VLA,为每个episode 标注任务结果标签(这些标签决定奖励),并(在RL后训练中)根据需要提供人工干预,用于为早期迭代中的错误提供修正示例
注意,相当于对于预训练来说,数据仅仅是示教数据
但对于后训练来说,数据收集分为两种,一种是自主运行,一种是人工干预
怎么个人工干预法呢,其实类似HIL-SERL,研究人员让机器人先上岗工作,当它在自主执行任务时犯了错(比如抓歪了、卡住了),人类专家会立即接管机器人,通过远程操作来纠正这个错误,并展示如何从这个错误中恢复过来
一举避免误差累积!
- 价值函数训练:给每个状态打分
使用到目前为止收集的所有数据来训练一个大型的、多任务的价值函数,称之为,该函数可以检测失败,并评估完成任务所需时间的期望值(即判断任务完成的预期时间)
——
更深入讲,价值函数不是评断该动作做的错还是对,毕竟有时一个任务最终能否成功,光看前几步 不一定看得出来,可能到了第6步才失败,但导致失败的不一定是第6步,而是前几步没有做好 但偏偏前几步还没到最后成功与否的临界点
再比如,机械臂弄咖啡时,如果机器人以错误的方式拿起意式浓缩咖啡机的滤篮,它可能会难以将其插入。可失败的根源并非在于最后的插入环节,而是在最初的抓取动作 不对
故,正确的信用分配方法(credit assignment method)应当将抓取动作认定为失误,即便失败是在那之后 才显现出来的
所以,那到底怎么判定某一步动作到底好不好呢,那就放长远,即当前距离成功还有多远 - 优势条件训练:各个前后动作分数的差值,这个差值就是优势分数,在RL中,当然追求优势值为正了
为了利用该价值函数改进VLA 策略,作者引入一个基于从该价值函数导出的优势值构造的最优性指示器
we include an optimality indicator based on advantage values derived from this value function in the VLA prefix.
总之,该“优势条件”方法提供了一种简单且有效的方式,用于利用次优数据从价值函数中提取更优的策略
this “advantage conditioned” recipe provides a simple and effective wayto extract a more optimal policy from our value functionwith suboptimal data
图1 展示了训练过程的整体结构,而图3 则更详细地说明了价值函数和策略结构的具体细节
- 在 RECAP 训练期间,π∗0.6 VLA 与价值函数之间的交互
- π∗0.6 VLA 使用预训练的视觉语言模型(VLM)骨干网络,该VLA的训练遵循 KI 配方『73-Knowledge insulating vision-language-action models:
Train fast, run fast, generalize better,详见此文《π0.5的KI改进版(已部分开源)——知识隔离:让VLM在不受动作专家负反馈的同时,输出离散动作token,并根据反馈做微调,而非冻结VLM》』在预训练阶段对多个数据源进行下一个token,并使用具有停止梯度的流匹配动作专家
且VLA 以从单独的价值函数获得的二值化优势指标为条件,该价值函数由预训练但规模较小的 VLM 模型初始化
The VLA is conditioned on a binarized advantage indicator, obtained from a separate value function initialized from a pre-trained but smaller VLM model

总之
- 预训练阶段包括在整个预训练数据集上执行上述第(2-价值函数训练) 和第(3-优势条件训练) 步,该数据集由来自众多任务和多种不同机器人、长达数万小时的示教数据组成
Our pre-training phase consists of performing steps (2) and (3) above on our entirepre-training dataset, which consists of tens of thousands of hours of demonstrations from numerous tasks and a variety ofdifferent robots - 随后,执行第(1)、(2) 和(3) 步一次或多次,以利用自主收集的数据进一步改进VLA
Then, we perform steps (1), (2), and (3) oneor more times to further improve the VLA with autonomously collected data.
————
最后,再强调一点,RECAP这套流程(训练三阶段),是可以反复执行的
接下来,将在下文描述价值函数训练和策略训练步骤,然后再(对应于原论文第五节)介绍训练π∗0.6 的具体实现方法
1.2.1 分布式价值函数训练:评估当前的“任务进度”
为解决信用分配难题,作者设计了分布式价值函数,核心作用是实时评估当前状态的 “任务完成潜力”
而为了训练一个在预训练或后训练阶段中,针对任意任务都能充当可靠评判者的价值函数「To train a value function that can act as a reliable criticfor any task in our pre-training or post-training stages」
- 首先,对于输入
作者用多任务分布式价值函数来表示
和语言指令
映射为B 个离散价值区间上的分布
在作者的实现中,该价值函数使用与VLA 策略相同的架构,但使用了更小的VLM 主干网络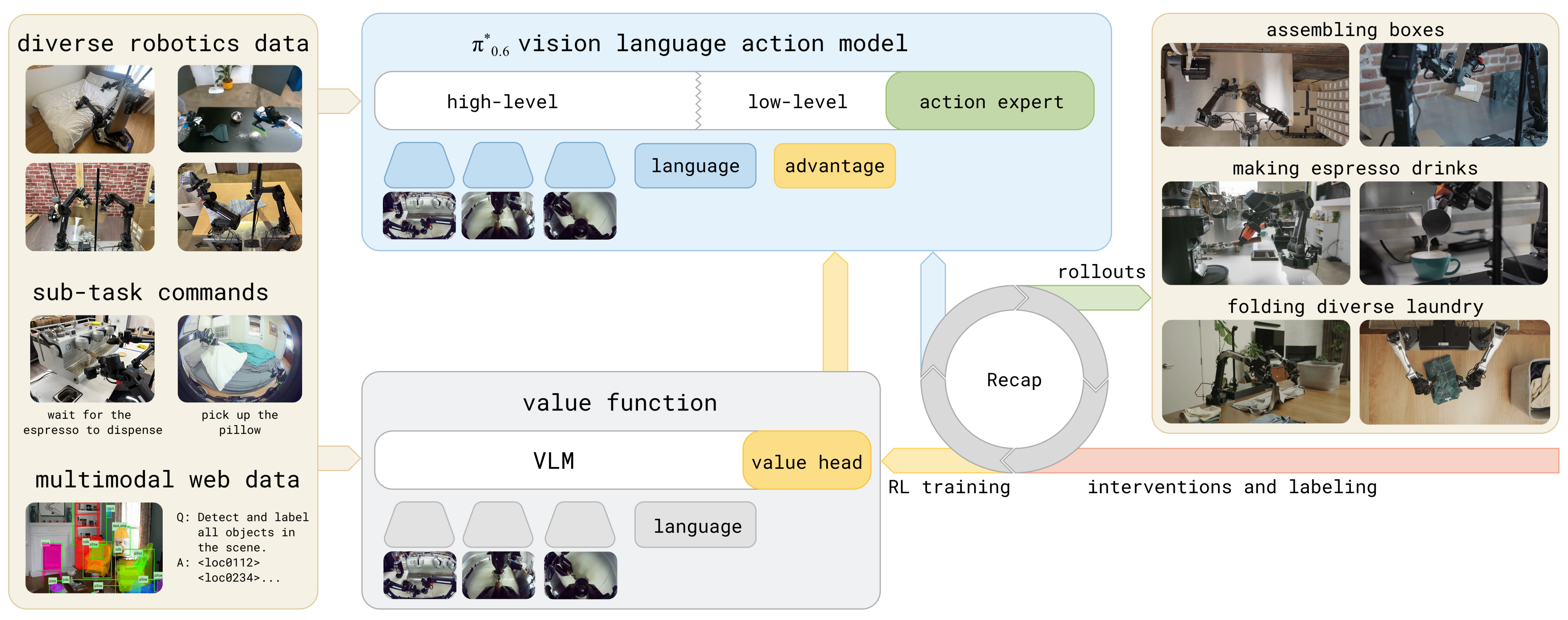
- 其次,对于输出
用表示从时间步
到末尾轨迹
的经验回报
作者通过先将经验回报值离散化为
个区间——用
表示离散化后的回报
- 最后,对于训练方式
则是对当前数据集中的轨迹最小化交叉熵
,来训练
,即(定义为公式1)
这是一个用于数据集
最终可以通过使用,从学得的价值分布中提取连续的价值函数(从而得到优势),其中
表示与区间
对应的价值
- 在预训练阶段,数据集
During the pre-training phase,the dataset D corresponds to the human demonstrations, and the value function captures the expected return for the taskand metadata we condition on - 而在随后的迭代中,它则倾向于演示(离线)回报和所学习策略(在线)回报的加权组合
while on subsequent iterations,it skews toward a weighted combination of the return of the demonstrations and the learned policy.
虽然这种基于当前策略的估算方法不如更传统的离策略Q函数估算器最优,但作者发现其结构简单且高度可靠,同时仍能够在模仿学习的基础上实现显著提升
故该方法在未来工作中可以扩展以支持离策略估算器(off-policy estimators)
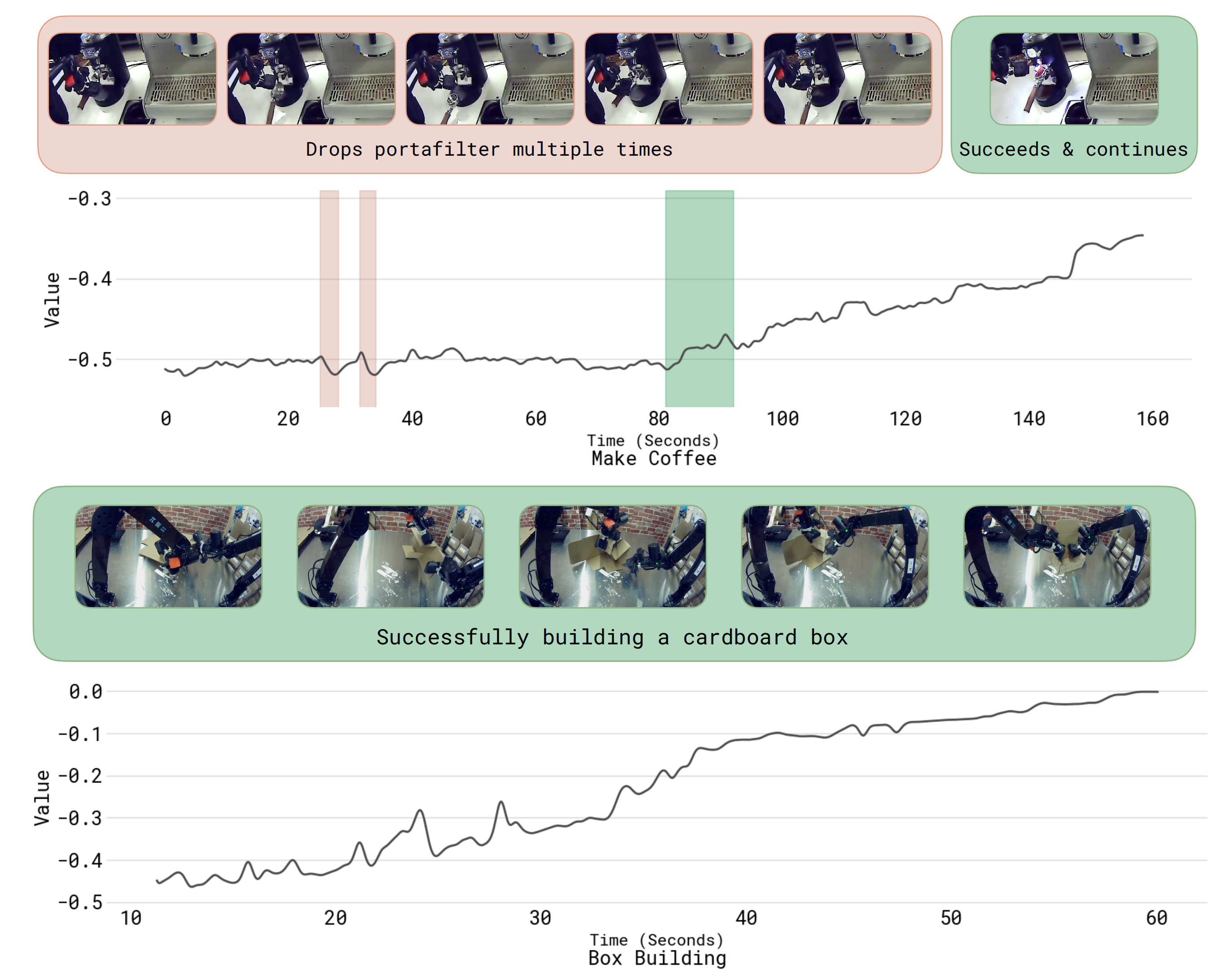
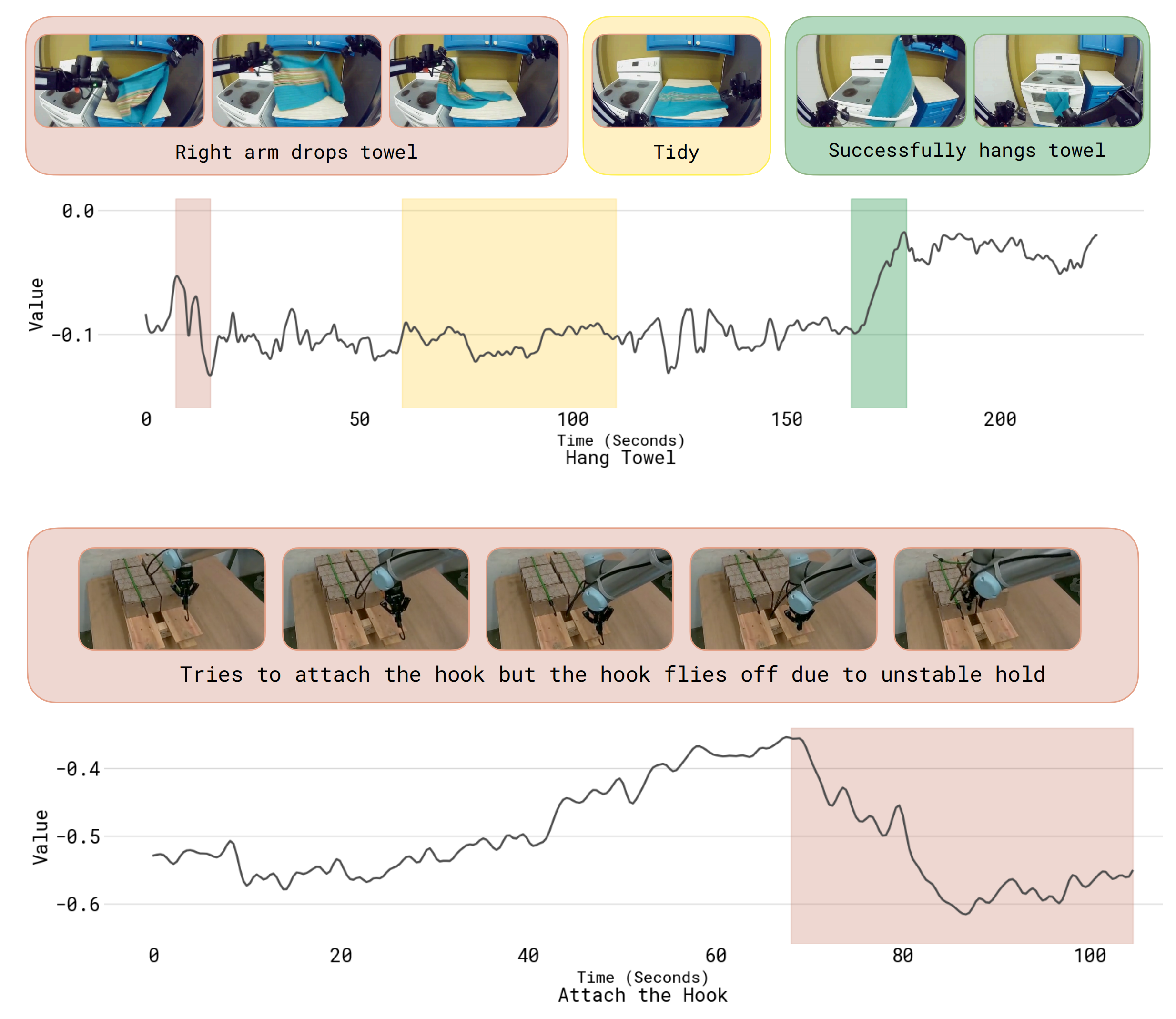
图13展示了作者训练得到的价值函数在五个不同任务上的额外可视化结果,包括他们
- 用来评估策略的任务(制作浓缩咖啡、装配盒子)
- 以及更广泛的任务(挂毛巾、安装挂钩)
其中价值函数变化最显著的部分已被高亮显示:
- 红色表示价值函数下降的位置
- 绿色表示价值函数上升的位置
- 黄色表示数值波动的位置
1.2.2 基于优势条件的策略提取:给每个状态打分,判定某个动作是接近目标还是偏离目标
一旦得到了价值函数,便需要一种方法利用该价值函数来训练一个改进的策略。这被称为策略提取。在作者的设定中,一个有效的策略提取方法需要满足若干标准
- 首先,它需要能够有效利用多样的离策略数据,这些数据包括初始演示、专家干预,以及来自最新策略和较旧策略的自主交互回合(相当于此时的优势值 需要cover住预训练、与后训练)
这一点与离线强化学习(offline RL)方法[2,3]所面临的挑战密切相关 - 其次,它需要具有良好的可扩展性,并且易于应用到大规模 VLA 模型上,包括使用流匹配flow matching或扩散diffusion来生成动作的模型
- 最后,它还必须能够有效利用优质(近最优)和劣质(次优)数据,这一点对于通过自主经验提升策略至关重要
即把所有数据(不管是好动作、差动作,还是专家纠正的动作)都拿来训练 VLA 模型,同时把 “这步是高优势(好)的动作”、“这步是低优势(差)的动作” 的标注,也给到模型做训练
训练完后,模型已经清楚 “哪些动作能帮它更快成功”,从而在实际执行时,优先选择 “高优势” 的动作 即可
在现有的策略提取方法中
- 策略梯度方法(包括正则化策略梯度和重参数梯度)或许是应用最广泛的[66-即PPO,74- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor]
——
但这些方法很难应用于flow matching模型,因为这类模型并不容易提供可处理的对数似然,从而难以扩展到现代VLA架构(详见原论文第VI节的对比)
————
我补充说明下,对于这点,可以参见此文《πRL——首个在线RL微调流式VLA π0/π0.5的框架:通过Flow-Noise和Flow-SDE实现精确对数似然估计,全面提升性能》 - 另一种选择是使用加权回归方法,例如AWR [68-即Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning,75,76],这类方法在隐式地对行为策略进行正则化的同时,仅采用一个简单的(重要性加权的)监督学习目标
然而,这些方法会丢弃或显著降低相当一部分数据的权重,实际上实现了一种带过滤的模仿技术
相反,作者采用advantage conditioning[48-Reward-conditioned policies] 的一种变体
- 其中策略在全部数据上通过监督学习进行训练,但额外接收一个输入,用优势值来指示该动作的最优程度——where the policy is trained on all of the data with supervised learning,but with an additional input indicating how optimal the actionis based on the advantage.
- 这与文献中一系列方法密切相关,这些方法主张根据由结果轨迹(the resulting trajectory)计算得到的某个函数对策略进行条件化
47-Reinforcement learning upside down: Don’t predict rewards — just map them to actions
50-When does returnconditioned supervised learning work for offline reinforcement learning?
事实上,该方法中的具体表达方式与CFGRL [4-Diffusion guidance is a controllable policy improvement operator] 最为相关
- 在1.1.3节所述的方法基础上,即引用如下
可以应用贝叶斯法则对策略的概率进行重写,即改进为- 将其应用到本文的设定中,并加入语言条件后,便可以获得上文1.1.3节(对应于原论文第三节)中描述的改进正则化策略
其中
表示某动作
的另一种封闭形式(定义为公式2)
至于,如果对于特殊情况,
————
为方便大家更好的理解,我再做下补充说明
首先,根据上文1.1.3节,有,且其中
——
但根据上面的第一点,可知该可以改进为
故把改进后的
- 如此,如果训练策略使其能够同时表示
和
,那么就可以在不显式表示改进概率
的情况下 表示
这一原理与classifier-free guidance 中的方法类似- 在该方法中,扩散模型被训练为同时对带有和不带有条件变量的数据进行建模[4]
且假设改进指示变量服从一个delta分布
带有任务相关的改进阈值。该阈值使得能够控制最优性指标,并最大限度地减少在训练后寻找衰减因子
然后,策略目标对应于最小化以下负对数似然(定义为公式3,其中 为指示变量):
- 优势值
来自上一节中的价值函数,
是一个权衡超参数
- 第一项
,是标准的行为克隆BC
第二项是优势条件化项
- 当训练时,在训练时,如果某条数据的动作优势
很高(大于阈值
设为 True
这意味着模型学会了:当时,便应该输出那些高优势的动作
实际上,数据集
包含了迄今为止收集到的所有数据,包括所有演示和自主任务尝试,因此参考策略
- 为了包含人工修正,作者发现对于在自主执行过程中由人类提供的修正动作,强制令
如果假设人类专家总是提供良好的纠正动作,这种选择是合理的- 正如将在下文(对应于原论文第V节)讨论的那样,在实际应用中,VLA 模型同时产生离散和连续的输出,连续分布通过流匹配进行表示
因此,实际的训练目标将离散值的似然性与连续值的流匹配目标结合起来在实际操作中,作者首先在整个预训练数据集上预训练一个模型,用于表示
,然后针对每个任务通过使用on-policy rollouts(以及可选的专家纠正干预),进行方法的一次或多次迭代
1.2.3 方法概述:先RL预训练,后SFT、最后RL后训练
在Algorithm1中提供了完整方法的概述

如本节开头所述,该方法可以通过应用三个子程序来完全定义:
- 通过自主 rollouts 收集数据(可选由专家进行纠正性干预)
- 根据公式1训练价值函数
- 有了价值函数
,便可以计算某个动作
的优势
如果,说明动作
,说明动作
RECAP 的核心思想是:不需要复杂的梯度回传,只需要在训练时把“优势”作为一个输入条件喂给模型
继而根据公式3训练策略
不同步骤之间唯一变化的是每个子程序所使用的数据来源:预训练阶段使用所有以往的演示数据,而每项技能专员的训练过程则有所不同:使用了额外的自主数据(即RL后训练阶段)
在实际操作中,专家模型是在预训练模型的基础上进行微调的,而最终的通用模型则是从零开始训练的。该方法的更多细节详见附录F
如原论文附录F所说,对于优势估计而言
- 在预训练阶段,作者将优势估计计算为
其为每个回合设置,这是一种方差更高的优势估计
——
采用这种优势计算方法,因为它允许在预训练时仅通过一次对价值函数的推理调用,就能动态计算出优势值
作者的实证结果显示,当策略在预训练阶段以来自不同任务的大量数据进行训练时,这种优势估计方法效果良好
——————
这在 RL 中被称为蒙特卡洛估计 Monte Carlo Estimation,直接用整局的真实总得分,减去当前状态的预期得分
可能里面有同学会疑问,为何不用时序差分呢?
实际上,如果在该预训练阶段用时序差分(去查步的价值),那么对于每一帧数据,算法都必须在庞大的价值网络
中跑两次前向推理(一次算
,一次算
)。这会让原本就极其昂贵的 GPU 训练成本直接翻倍
时序差分不用,代价是什么?
代价是极高的方差(Higher Variance) 。一局任务长达几千步,只用最后的结果来给第一步打分,这中间充满了偶然性。
但论文敢这么做,是因为离线预训练的数据量极其巨大。在海量大数据的冲刷下,神经网络极其强大的拟合能力会自动把这些高方差的噪音给平均掉(大数定律),最终依然能学到正确的趋势- 后训练阶段,作者使用
来估计优势函数,其中是在同一路径上向前N 步采样得到的观测
作者使用N = 50 步前视来计算该优势
————
这在 RL 中被称为 N 步时序差分 N-step Temporal Difference,用接下来的 50 步真实得分,加上第 50 步的价值网络预测分,再减去当前预期
在真实的工厂或展厅里,你一天撑死只能收集几百到上千条真机运行或人工接管的轨迹 。 在小样本下,如果还用全局计算,那极高的方差会让模型完全找不到北(比如前 100 步走得极好,第 101 步因为反光失败了,全局计算会把前 100 步的全盘否定)优势条件丢弃法:在训练过程中,有30%的概率随机丢弃对优势指示器的条件依赖。作者采用这种丢弃机制,是为了能够在推理阶段直接从有条件或无条件策略中采样,并在测试时使用CFG进行策略改进『详见下文的「1.3.2 从π0.6到π∗0.6与优势条件化(包含使用CFG在测试时进行策略改进)」』;此外,这一方法实际上替代了损失乘子α的作用
此外,对于优势阈值:每个任务的优势阈值
- 在预训练期间,作者为每个任务选择一个阈值,使大约前30 % 的示范数据具有正优势(基于一组随机抽取的10k 数据点计算)
- 在微调期间(准确的讲是RL后训练期间),作者通常将阈值设置为每次迭代中大约前40 % 的评估回滚具有正优势
但也有个特例:对于“叠 T 恤和短裤 ”这种通过人类基础演示已经达到极高的成功率,但动作很慢的任务,为了逼模型学得更快,系统极其严苛地把及格线(阈值)拔高到前10%——即只让约 前10% 的数据拿到正向标签
1.3 基于RECAP的π∗0.6的实现、模型与系统细节
如原论文所述,π∗0.6基于π0.6 VLA,后者是π0.5 VLA [5] 的进化版本,并在伴随的模型卡[6] 中详细说明了一些改进
- π∗0.6 还额外加入了对二值化优势指示器
- 模型结构如图3 所示,作者同时训练一个价值函数和 VLA——按照上文「1.2.1 分布式价值函数训练:给 “任务进度” 精准打分」一节所述的方法,该价值函数同样是由VLM 初始化的
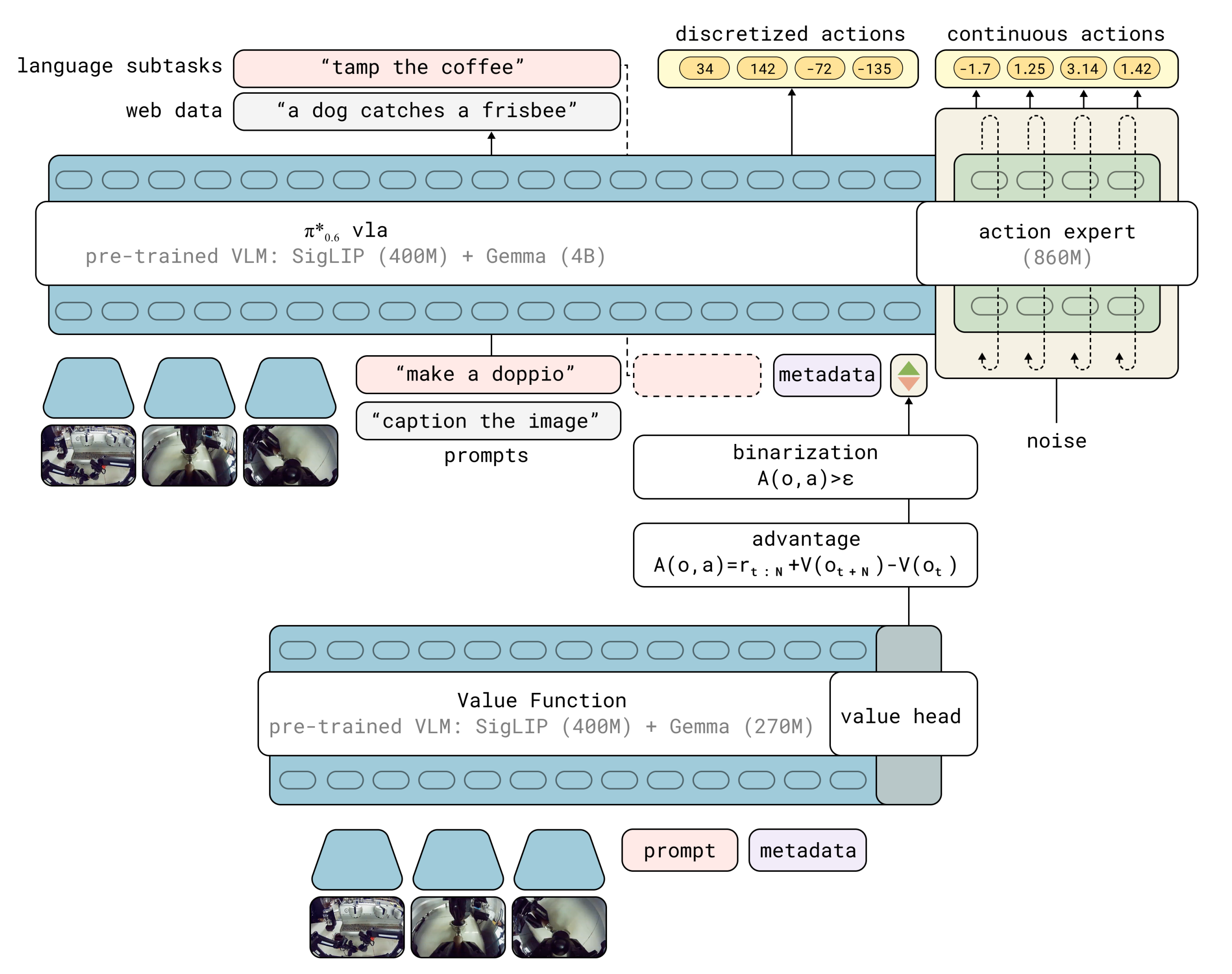
之后用RECAP 训练该价值函数和VLA,得到最终模型,称之为π∗0.6
接下来,首先详细说明模型的设计,以及如何将其扩展为使用来自价值函数的优势值,然后描述奖励函数和值函数,接着阐述实现中的训练和数据收集过程
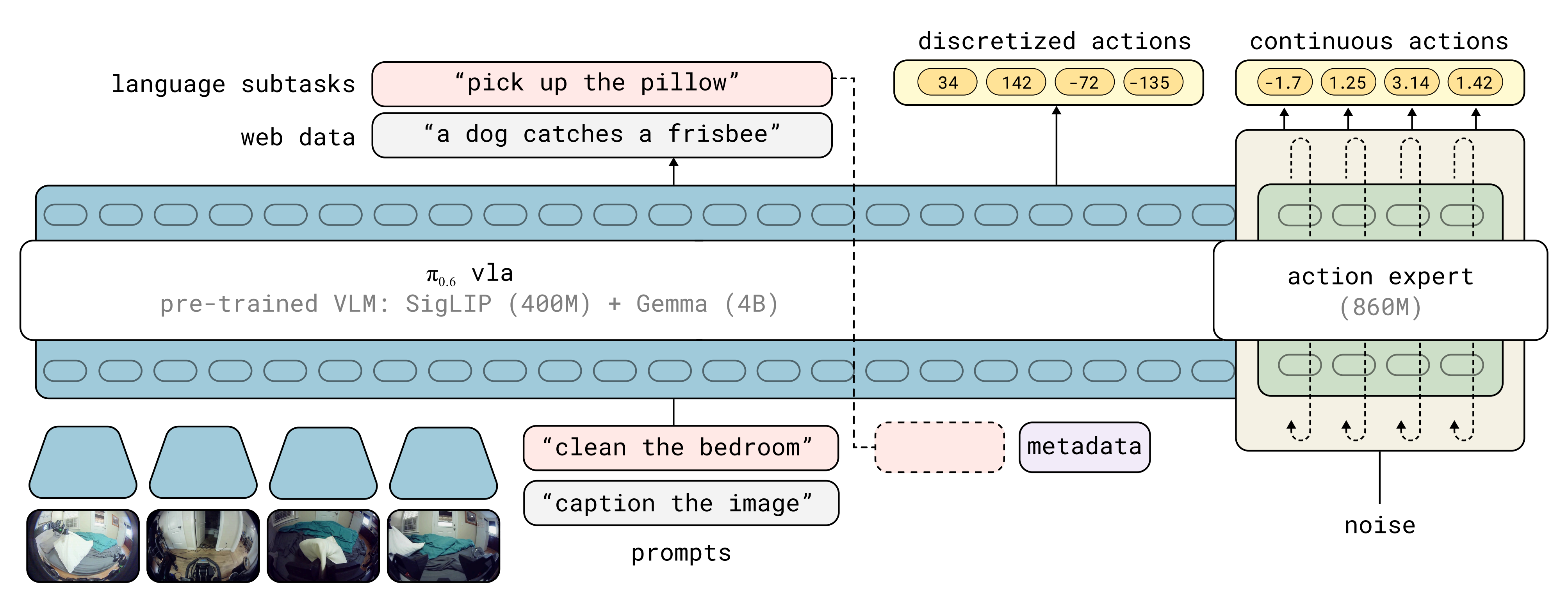
1.3.1 π0.6模型
π0.6 模型[6] 是从π0.5 模型推导而来
- π0.6 保留了π0.5 的分层设计,提供高层次的子任务预测和低层次的动作生成,可通过流匹配灵活地表示分块的动作分布,并生成用于高层策略推理的中间文本
- π0.5 采用了知识隔离(KI)训练过程[73],在连续动作和离散化的tokens「包括通过FAST[77]离散化的动作」上对整个模型进行端到端训练,同时使用停止梯度来防止流匹配动作专家影响模型的其余部分
π*0.6 的预训练同时使用机器人数据和来自网络的视觉-语言联合训练数据「Pre-training uses both robot data and vision-language co-training data from the web.」
其本质是
- 训练机器人大脑的:少量互联网上的图文共训数据(该部分少量数据核心是训练模型对子任务的预测能力)
- 以及训练机器人小脑和手的:人类遥操各种机器人干各种活的示教数据(如上文1.2节开头所说的:which consists of tens of thousands ofhours of demonstrations from numerous tasks and a variety ofdifferent robots)
且π0.6 在多个方面优于π0.5:
- 预训练数据集通过来自多个机器人平台的额外数据进行了扩充
π0.6 在很大程度上继承了π0.5 中使用的训练数据构成,包括内部收集的跨形态数据和外部数据源、多样化的在家庭环境中收集的移动和非移动数据、高级子任务预测、多模态网络数据集(包括边界框和关键点预测)
π0.6 由于多样化的训练数据和丰富的元数据条件,无需特定任务微调即可在各项任务上实现显著更强的性能 - 基础VLM 是Gemma 3 [78] 4B模型
- 动作专家的参数量增加到860M
一组专门用于动作生成并通过flow matching 训练的权重集(860M parameters)
具体而言,类似于π0 [1] 和π0.5,π0.6 架构基于流匹配和离散分词输出生成动作块
- 视觉-语言主干网络初始化自Gemma3 4B 模型[6],并且 “动作专家” 具有与主干相同数量的层,参数量约为860M
在预训练期间,模型最多接收四张分辨率为448 × 448 的图像作为输入,分别对应一个基础相机、最多两个手腕相机,以及(针对移动操作机器人)一个可选的后向相机
经过视觉编码器后的图像token 与分词后的语言提示和分词后的本体感觉状态拼接在一起
且在所有图像token 之间保持双向注意力(如同π0.5 所做),但在文本token 之间使用因果注意力。输入动作专家的动作token 采用双向注意力- 模型采用知识隔离方法[3]进行训练:视觉-语言主干预测FAST 动作token [5] 及协同训练样本,如多模态网络数据
动作专家预测连续动作,动作专家的梯度不会传递回主要的视觉-语言模型主干
除了语言指令外,π0.6 还可以选择性地在提示中添加调节元数据,进一步影响任务的执行方式
在5 步去噪和3 个相机输入的情况下,π0.6 在单个H100GPU 上生成一个动作块耗时63 ms
再进一步而言,该模型可以表示为
其中
- 输入包括
包含摄像头图像、机器人的构型configuration
至于,即包括整体任务提示
(例如,“为我做一杯浓缩咖啡”),以及额外的语言输入
,这些输入提供元数据,进一步调节任务的执行方式
- 输出包括
模型生成的动作片段:,其由关节角度和50 Hz 下的夹爪命令构成,使用一个单独的” 动作专家”,但可以关注模型其余部分的激活
模型还生成离散化的符号输出,即为下一个预测子任务的文本表示(如“拿起咖啡杯”),用于高层决策
由于动作是在
当然,在推理阶段子任务预测的频率低于动作生成
在训练过程中,模型还会使用FAST tokenizer [77],作为KI 方案[73] 的一部分,预测动作片段的分词表示,作者将这些离散化动作记为
动作专家并不接收这些离散动作作为输入,因此离散动作和连续动作是独立预测的。类似π0.5
这导致最终的训练对数似然由,变为
由于首先预测子任务,因此可以根据如下方式对该对数似然进行分解
1.3.2 从π0.6到π∗0.6与优势条件化(包含使用CFG在测试时进行策略改进)
为了在策略中纳入关于优势的信息,作者扩展模型输入,使其包含一个额外的改进指示符作为额外的文本输入,当时,输入“Advantage: positive”,否则输入“Advantage: negative”
- 优势指示器出现在训练序列中
The advantage indicator appearsin the training sequence after ˆℓ but before the (discretized andcontinuous) actions, such that only the action log-likelihoodsare affected.
对数似然的连续部分无法被精确计算,而是通过flow matching loss[79] 进行训练 - 在某些假设下,可以在flow matching和扩散之间建立紧密的类比,而后者又可以被解释为对数似然的下界[80], 因此可以粗略地将「离散动作的对数似然与连续动作上的flow matching loss 之和」视为整体动作似然的下界——定义为公式4
————
其中,表示加噪动作,其中
是flow matching 的时间索引,
表示扩散专家模型的连续输出
是一个损失加权项(该项可以选择依赖噪声)。损失的全部细节在附录C 中提供
在训练过程中,作者随机省略指示符,而不是调整损失乘数
,这样可以直接从
的策略中采样(这对应于在公式(2) 中设置β = 1),或者同时使用有条件和无条件模型来实现无分类器引导(CFG),这使得推理时可以取
。详细信息见附录E
如原论文附录C所说,为了从公式4推导对数似然,作者首先可以注意到,完整的模型似然可以分解为自回归项和扩散项
其中
- 第一项通过流匹配进行建模
- 第二项是离散动作
的自回归似然
- 第三项对应于自回归文本似然
自回归似然可以用常规方法进行估算,即对真实标签的交叉熵损失进行评估。对于
- 然而,可以参考之前的工作『82-FPO,详见此文《FPO——流匹配策略梯度:避开复杂的对数似然计算,通过「最大化基于条件流匹配损失计算优势加权比率」做策略优化,兼容PPO-CLIP》』,将一步扩散过程视为具有如下似然的高斯分布:
其中且
- 由此,作者可以按照
80- Understanding diffusion objectives as the elbo with simple data augmentation
82- Flow matching policy gradients
形成对似然性的证据下界(Evidence Lower Bound, ELBO)——实质上对η 和ω 进行了边缘化,其结果为
其中是一个依赖于噪声的加权项,
是一个与
关于该推导,参见[80],其中还在附录D.3 中推导了在选取该加权项时流匹配与扩散之间的关系- 最后,将下界与文本输出
此外,如原论文附录『E. 使用CFG在测试时进行策略改进,其中β > 1』所示,在训练之后,可以通过在Eq.(2) 中设置β > 1
选择进一步加强用于评估的策略。正如先前工作[4-Diffusion guidance is a controllable policy
improvement operator] 所示,可以在无需额外训练的情况下恢复这个加强的策略,因为它被学习到的策略和
隐式地定义
- 具体来说,在训练之后可以形成如下近似
现在可以认识到,扩散模型有效地学习了似然函数的梯度,即它分别表示和
- 由此,按照Frans 等人[4] 的方法,可以看到,如果按照梯度运行流匹配推断
实际上是在从期望的衰减分布中采样
- 作者注意到,正如主文中所述,参数β 与作者在训练过程中引入的优势阈值
- 且作者发现,在训练后对分布进行锐化并将β 设为较高值,会导致动作分布被推至其学习到的支持边界(这可能导致过于激进的动作)
因此作者主要依赖
1.3.3 奖励定义(包含稀疏奖励的设置)与价值函数训练
由于作者的目标是开发一种通用且具有广泛适用性的方法,从经验中训练 VLA(但值得注意的是,这套稀疏奖励的设置在RL预训练和RL后训练中 都用到了),因此作者采用一种通用的稀疏奖励定义,使其基本上可以应用于任何任务
- 对于每个 episode,都会获得一个标签,用于指示该 episode 是否成功,且从其每个episode的成功标签中获取奖励,使得价值函数对应于成功完成episode之前的(负)步数
『We derive the reward from his episode-level success label such that the value function corresponds to the (negative) number of steps until successful completion of the episode』 - 这等价于如下的奖励函数,其中T 对应于该幕中的最后一步,而
是一个较大的常数,被选取用来确保失败的episode具有较低的价值:
通过该奖励函数,作者训练价值函数,使其在成功轨迹上预测距离成功尚剩余步数的相反数,并在失败轨迹上输出一个较大的负值
实际操作中,作者将预测的数值归一化到(−1,0)之间。由于在各种任务上进行训练,而这些任务的典型长度差异很大,因此会根据每个任务的最大回合长度对数值进行归一化
这里再解释说明下为何如此设置:过程持续扣血,成功立刻止血
- 为什么平时每走一步都是 -1?(倒逼完美效率)
如果平时是 0,最后成功是 1。模型可能会觉得:“反正中间不扣分,我在桌面上先挥舞三下机械臂,再去抓包裹,最后只要抓到了就能拿 1 分。”这会导致动作拖沓、啰嗦
————
而“每走一步给 -1”的设定,相当于给机器人戴上了一个“倒计时紧箍咒”:
如果它用了 10 步完成任务(成功时给 0),这回合的总收益是:-9 分
如果它磨磨蹭蹭用了 50 步才完成,总收益是:-49 分
在RL中,模型的目标永远是追求总收益最大化(即尽可能接近 0)。这就会逼着模型去寻找那条“绝对最短、最丝滑、没有任何多余废动作”的完美路径。这与之前总结的“选出前 30% 完美成功的动作”在数学目标上是完全对齐的- 为什么成功的那一步奖励是 0?
因为在这个“全员扣分”的体系里,0 已经是最高荣誉(不再继续扣分了)。只要你成功了,扣分机制立刻停止,这就起到了强烈鼓励“早点成功”的作用- 为什么失败给一个巨大的负常数惩罚?
假设每走一步扣 1 分,回合最大步数限制(T)是 100 步。如果机器人走到一半放弃了(失败),如果不给巨大惩罚,它可能走到第 10 步就故意让包裹掉落结束回合,结算只扣 -10 分
相比于对比如果花 50 步才成功的情况(扣 -49 分),系统反而会认为“早点失败”比“艰难成功”更划算,这就彻底乱套了
————
所以,失败必须给一个极大的负常数(比如 -1000)。这样模型就会明白:哪怕我磨叽了 99 步才勉强成功(扣 -98 分),也比干脆失败(扣 -1000 分)要好得多
此外,价值函数接收与π∗0.6 VLA 相同的语言输入,并采用相同的架构设计,使用一个较小的670M 参数的VLM 主干网络,该主干网络同样从Gemma 3 初始化,详见图3
为防止过拟合,作者还在一个由多模态网页数据构成的小型混合数据集上对价值函数进行联合训练。图4 展示了价值函数在一些成功和失败轨迹示例上的可视化结果「更多的可视化内容见附录B中的图13」
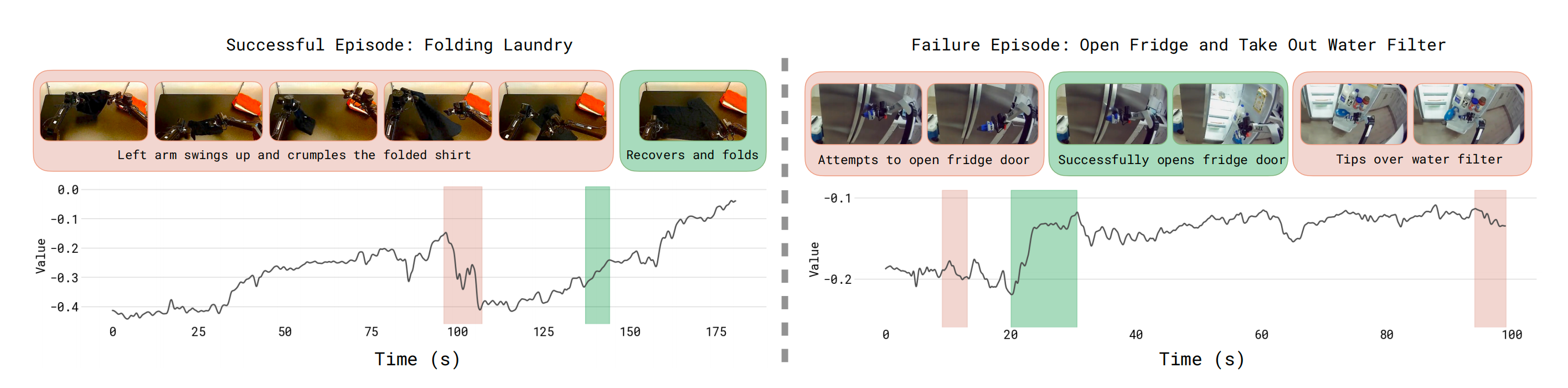
- 作者训练了一个多任务价值函数,用于预测达到成功所需的步数,并通过任务的最大长度进行归一化,使其落在 (−1, 0) 区间,其中 0 对应成功完
- 作者将价值函数的输出应用于一个成功完成的折叠任务(左),以及预训练数据集中一个操控任务未成功的示例(右)
红色部分表示价值下降,绿色部分表示价值上升;上方图片显示了该片段对应的帧。可视化结果表明,价值函数能够准确识别出任务过程中的错误,以及任务推进的速度
1.3.4 总结:预训练、数据采集、经验学习(先RL预训练、后SFT、最后RL后训练)
模型在预训练阶段所使用的数据混合大体上遵循π0.5[5] 采用的方案,包含来自网页的视觉-语言数据、子任务的预测,以及在来自许多不同机器人、各种任务上的低层动作预测(作者注意到,在预训练之后,π∗0.6 能够执行的任务远不少)
- 第一,在预训练期间,用的数据相当于是海量打分数据
首先,在相同的数据集上训练价值函数value function,预测每个任务成功完成所需步骤数的相反数
然后估计“用于确定基于优势的改进指示器
作者将
然后,在VLA 训练期间在线运行价值函数,以估计每个样本的
————
如1.3.1节(对应于原论文第V-A节)所述,
由于为价值函数使用了相对较小的VLM 骨干网络(670M),在VLA 训练过程中对价值函数进行在线推理只会带来极小的额外开销
为了方便大家更好的理解π*0.6中的RL离线预训练,顺带也是对上文相关内容的总结、归纳,故我非常有必要强调一下π*0.6中的RL离线预训练数据的格式,到底是什么样子
首先,论文明确指出,预训练阶段的数据混合Data mixture很大程度上遵循了
的配方 。它包含了:
网络图文数据(vision-language data from the web) 。
多机器人底层动作数据(prediction of low-level actions on a variety of tasks from many different robots)
其次,在强化学习的定义下,一条示教轨迹被定义为
。在预训练
模型时,模型在时间步
【输入端格式】
- 状态观察值
(Observations):格式被严格定义为
其中,包含来自多个摄像头的相机图像(camera images
)
包含机器人的本体配置(robot's configuration
)
注:在他们具体的实验双臂机器人设置中,观察值包括关节和夹爪位置,以及来自三个相机的图像:一个底座相机和两个腕部相机- 语言输入
(Language Input):格式被定义为
其中,是总体的任务prompt,例如“给我做一杯浓缩咖啡”
- 优势指示器
(Advantage Indicator): 这是π0.6 相比基础模型新增的极其关键的文本输入格式。
为了将优势信息融入策略,模型输入被扩展,包含了一个作为额外文本输入的改进指示器improvement indicator
当优势值为正时,输入文本 "Advantage: positive"
否则,输入文本 "Advantage: negative"【输出端格式】
- 高级离散子任务
(Tokenized discrete outputs):
模型会生成分词后的离散输出- 连续动作块
(Action chunks):
这是底层的物理控制信号。格式为 50 Hz 的关节角度和夹爪控制指令(joint angles and gripper commands at 50 Hz)- 离散化动作块
(Discretized actions):
在训练期间,模型还会使用 FAST 分词器(FAST tokenizer)预测动作块的token化表示(tokenized representation of the action chunk)【用于 RL 的标签格式】
- 稀疏奖励
(Sparse Reward):
对于每个回合(episode),系统会获取一个指示该回合是否成功的标签(label indicating whether that episode was successful)
奖励函数基于此成功标签得出:除了成功结束的那一步奖励为 0,以及失败结束的那一步给一个巨大的负常数惩罚外,其余每走一步的奖励都是 -1
- 如之前所说,阈值被设定为价值函数预测值的 30% 分位数
换句话说,系统会故意拉高及格线,确保在这个极其庞大的历史数据库中,只有大约 前30% 表现最好的演示数据能跨过及格线,被贴上正向优势(Advantage: positive)的标签
- 第二,在预训练之后,作者开始针对目标任务的策略改进循环,先是SFT(相当于用的少量满分数据)
即用目标任务对π∗0.6 进行微调。在这个阶段将指示变量
这样得到初始策略
在
但是,从数据内容和标签分配的角度来看,SFT 阶段的数据长得非常纯粹,它具有以下几个极其鲜明的特征:
- 数据来源:特定目标任务的“专属小灶”示教数据
离线 RL 预训练用的是海量、多机器人的通用大杂烩数据
而在 SFT 阶段,系统会针对当前要执行的特定下游任务(比如专门为了“冲浓缩咖啡”或者“折叠多样化衣物”),单独拿出一批该任务专属的演示数据demonstration data
这批数据是纯粹的高质量人类遥操作示教数据,里面还没有混入机器人自己瞎摸索的经验数据- 最核心的灵魂差异:强制“全员满分”(优势指标全设为 True)
这是 SFT 阶段数据与其他两个 RL 阶段数据最大的不同点
a) 在离线 RL 预训练中,裁判(价值函数)会给数据算分,算出 前30% 的优等生打上 Advantage: positive 的标签
b) 但在 SFT 阶段,所有的动作根本不需要裁判去打分评估。研究人员将这批目标任务演示数据中所有的优势指标
论文指出,将优势值全部固定为 True,在数学层面上就完全等同于进行了标准的监督微调- 数据规模:精细且小巧
相比于预训练阶段数万小时的海量数据,SFT 阶段的数据量要小得多。它仅仅是为了让预训练好的通用大模型“熟悉”一下当前这个特定任务的操作流程和环境布置
————
总结一下 SFT 阶段的数据画像:
它是一批纯正的、专门针对某项具体任务的人类遥操作示教数据,并且里面的每一个微小动作,都被系统闭着眼睛贴上了“完美(Advantage: positive)”的满分标签大模型吃透这批“全员满分”的小灶数据后,就得到了一个能勉强下地干活的初始策略
,然后才会被派到真实环境里去开启“在线 RL 收集经验”阶段
- 第三,用其收集额外数据并加入到
虽然有些episode是完全自主收集的,但有些则由专家远程操作员进行监控,专家可以介入以提供修正
这些纠正可以展示策略如何避免灾难性失败,或如何从错误中恢复(相当于是实战纠错打分数据)
——
然而请注意,仅靠纠正不太可能解决所有问题:在自主执行过程中进行干预是一种具有干扰性的事件,即便是专家级人类操作者也无法保证干预的一致质量,也难以改善行为的一些细微方面,例如整体速度
因此,这些纠正更多是用于修复重大错误并克服探索方面的挑战,而并不能单独提供最优监督,这与理论[7] 形成对比
————
回忆1.1.2(对应于原论文IV-B)节,作者强制对所有纠正令
在数据收集之后,作者在截至目前为止为该任务收集的所有数据上微调价值函数,然后使用更新后的指标
注意!! 接下来,针对上面最后一个阶段的RL后训练阶段,有两个问题值得帮大家强调下
第一,那π*0.6中的RL后训练的数据 又长什么样呢
在
、关节角度
但如果从数据的来源、构成和标签分配来看,RL 后训练阶段的数据形态发生了极其显著的变化。
根据论文,这批用于特定任务(如装配纸箱、叠衣服)在线 RL 后训练的经验数据,主要呈现出以下几种特殊面貌:
- 数据的来源与构成:自主摸索 + 人类接管
在线 RL 阶段的数据(加入到特定任务数据集中)不再是纯粹的人类示教,而是由当前策略(例如
)在真实机器人上实时跑出来的轨迹。这些轨迹具体分为两类:
i) 完全自主运行回合(Autonomous rollouts)
机器人根据自己的神经网络权重,从头到尾独立执行任务的数据 。这些数据里充满了机器人自己的“肌肉记忆”,包含成功的尝试,也包含大量笨拙、超时甚至失败的操作
ii) 带专家干预的回合(Expert interventions / Corrections)
机器人在自主执行时,人类专家在一旁监控 。如果机器人犯了严重错误或陷入僵局,专家会切入遥操作进行纠正
因此,这一整条轨迹中,既有机器人自己生成的动作,也穿插了人类为了救场而输入的动作- 极其特殊的优势标签
在离线预训练中,所有动作的分数都是裁判(价值函数)算出来的。而在 RL 后训练阶段,为了处理上述这种“人机混杂”的数据,系统对文本条件输入 Advantage: positive/negative 采取了双轨制的打分策略:
a) 对于机器人的自主动作:依然交由微调后的价值函数来评估 。算出的优势值如果大于该任务设定的及格线
——及格线设在能让当前迭代收集到的评估数据中,大约 前40% 的动作获得正向优势的位置(叠T恤和短裤除外 其是前10%的阈值),则
b) 对于人类专家的干预动作Corrections:系统会强制将这些动作的
这是基于一个合理的工程假设:人类专家提供的纠正动作永远是高质量且能带来提升的- 结果标签依然依赖人工标注
尽管是“自主”收集经验,但每跑完一个回合(Episode),依然需要人工给出任务结果的标签(Task outcome labels)
人类标注员会判断这整个回合是成功还是失败 。
系统拿到这个人工给定的成功/失败定性标签后,再套用那个稀疏奖励公式(成功的步数惩罚为 0,失败的步数给极大负常数),将其转化为后续用于微调价值函数的量化奖励信号
第二,价值函数和策略都是从预训练的检查点开始微调,而不是从上一轮迭代得到的策略和价值函数开始
作者发现这样做有助于在多次迭代中避免漂移,尽管持续从上一轮模型进行微调也有可能取得不错的结果(though it may be possible to also obtain good results by consistently fine tuning from the last model)
包括论文中的 Algorithm 1,在代表多轮在线 RL 迭代的循环(to
)中,明确写着:
-
训练价值函数
时,是从
开始训练的
-
训练策略
时,是从
开始训练的
即这里的或
顺带,原则上,可以根据需要将该过程重复进行多次迭代,不过在实践中作者发现,即便只进行一次迭代,往往也能显著提升结果
我July帮大家强调一下,价值函数和策略都是从预训练的检查点
此,相当于跟ChatGPT三阶段训练『详见此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》』中,RLHF的逻辑不一样
因为RLHF的逻辑是,每采集一批经验数据后,策略会不断的在上一轮策略的基础上,继续迭代
————
以下是具体的差异对比和背后的原因:
- RECAP 的逻辑:不断扩充题库,每次都从头“开卷考试”
在论文的算法流程(Algorithm 1)中,RECAP 是一个迭代式离线强化学习(Iterated Offline RL)框架
数据池(轮)收集到的新经验数据(无论是机器人自主运行的还是人工干预的),都会被添加到特定任务的整体数据集中
每次都从通用底座(
————
为什么要这样做? 论文明确提到,这样做是为了“避免在多次迭代中发生偏移(avoiding drift)”
在机器人领域,如果模型一直在自己生成的狭窄数据分布上连续微调,很容易产生“灾难性遗忘”,把预训练时学到的通用常识(比如基础的物理规律或抓取姿势)给忘掉
每次都从通用底座重新出发,相当于每次都带着最完整的世界观去学习最新的经验- 标准 RLHF (PPO) 的逻辑:接力赛跑,边跑边调
ChatGPT 在 Stage 3 使用的经典 PPO(Proximal Policy Optimization)算法,是一个同策略On-policy算法
参数连续更新: 策略模型在环境(奖励模型)中采样一批数据后,会直接在当前模型的权重上计算梯度并更新
数据用完即弃: 更新完权重后,这批经验数据通常会被丢弃。模型再用更新后的自己去收集下一批新数据,继续迭代
————
差异点: 它是典型的“在上一轮策略的基础上继续迭代”。如果 PPO 跑得太远,往往会通过添加一个与 SFT 模型的 KL 散度惩罚项,来强行用一根“橡皮筋”把它拉住,防止它跑偏(Reward Hacking)所以,最终,作者虽然采用了回到
可能马上便有同学疑问了,既然需要不断收集更大的数据 来RL训练策略,可每次重新训练,又回到最初的预训练checkpoint
那等最后收集到最多的数据,一次性来RL训练 不就ok了么
反正中间一次次的数据 训练出来的策略,又不作为下一轮策略迭代的起始点,起始点都是预训练checkpoint————
这里的核心盲区在于:中间训练出来的策略,虽然没有交出它的“大脑权重”作为下一轮的起点,但它交出了自己的“身体”去打工——它被派去作为下一轮环境交互的“操作员(Actor)”收集数据去了这正是强化学习中“迭代式数据收集”的精髓。我们可以从以下几个维度来解开这个反常识的设定:
- 为什么不能“一次性收集完所有数据”?
如果你只用最初代的模型(经过 SFT 的)去一次性收集 1000 条数据,会发生什么?
一直犯低级错误: 初代模型可能非常笨,比如在“装配纸箱”任务中,它可能连第一步“把纸板拿起来”都做不好
数据质量极差: 哪怕你收集了 1000 条数据,这 1000 条全都是在第一步就失败的录像,或者全都需要人类专家在第一步就疯狂介入救场
无法探索深水区: 你的数据集里根本没有“纸箱折到一半该怎么处理”的高阶经验,因为初代模型根本活不到那一步- 中间策略
根据论文的 Algorithm 1(算法 1),在第
第一轮迭代后:学会了怎么拿纸板
用
数据的进化: 这时候存入大数据库的数据,就包含了高级的成功经验和更深层次的纠错经验
依此类推: 每一轮派出去的“打工人(策略模型)”都比上一轮更聪明,它们能走到任务的更深处,踩到原本碰不到的坑,从而把更高质量、更多样化的长尾场景数据带回大本营总结:权重重置了,但“认知(数据)”升级了
- 所以,RECAP 的逻辑是:每次微调回到原点(Checkpoint): 是为了保证模型不忘初心(不丢失预训练时的通用物理常识和多任务泛化能力,防止 Drift 偏移)
- 每次迭代必不可少: 是为了让越来越聪明的模型去采集越来越高质量、越来越复杂的经验数据
再追根究底下,既然策略Policy和价值函数Value Function为何是回到预训练的初始权重Checkpoint重新开始微调
那为何不是从“
————
确实,根据论文的算法伪代码(Algorithm 1),在第之所以选择“越过” SFT 模型直接回到最原始的预训练底座,主要有以下几个核心原因:
- 防止模型过度偏移(Avoiding Drift)
作者在文中直接解释了,价值函数和策略都从预训练检查点重新微调,是为了“避免在多次迭代中发生偏移”
SFT 本质上已经让模型往特定任务的分布“收敛”了一次
————
如果从 SFT 模型开始,再叠加多轮新数据的持续微调,模型就像是在一个越来越窄的胡同里越走越深
这很容易导致灾难性遗忘,让它丢掉最初在
回到- SFT 的“教材”并没有被丢掉
这里隐藏着一个数据流转的细节:RECAP 的目标任务数据集
在迭代开始前,数据集
迭代开始后,新收集的自主运行数据和专家干预数据,是被添加进这个
因此,在后续的每一轮训练中,模型面对的
既然 SFT 的教材都在里面,而且带着统一的优势分数标签,从
第二部分 实验评估
在作者的实验评估中,作者使用 RECAP 来训练 π0.6模型,所用的是一组具有现实意义的任务:
- 制作意式浓缩咖啡饮品
- 折叠各类洗衣物
- 以及组装纸箱
每个任务都需要多个步骤,持续时间在 5 到 15 分钟之间,涉及复杂的操作行为(受约束的用力操作、液体倒注、操控布料和纸板等),并且要求快速执行以实现高吞吐量
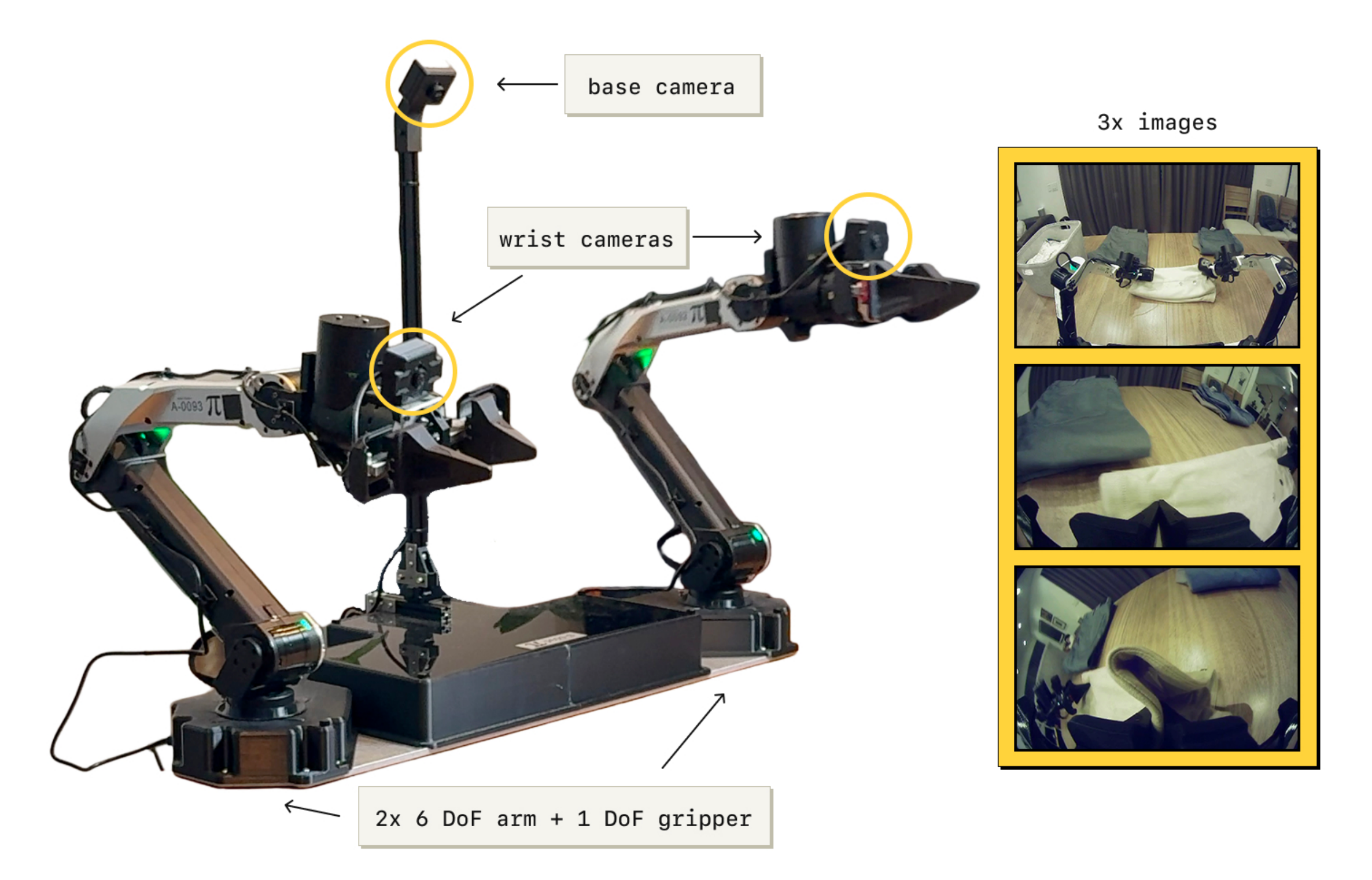
下图图 5 中展示了实验中使用的机器人平台
2.1 评估任务、对比与消融实验
2.1.1 评估任务
定量评估和对比实验涵盖三大类任务,每一类都有若干具体的任务变体:叠衣服、煮咖啡和组装盒子。按原论文所说的,相关示意图见图6
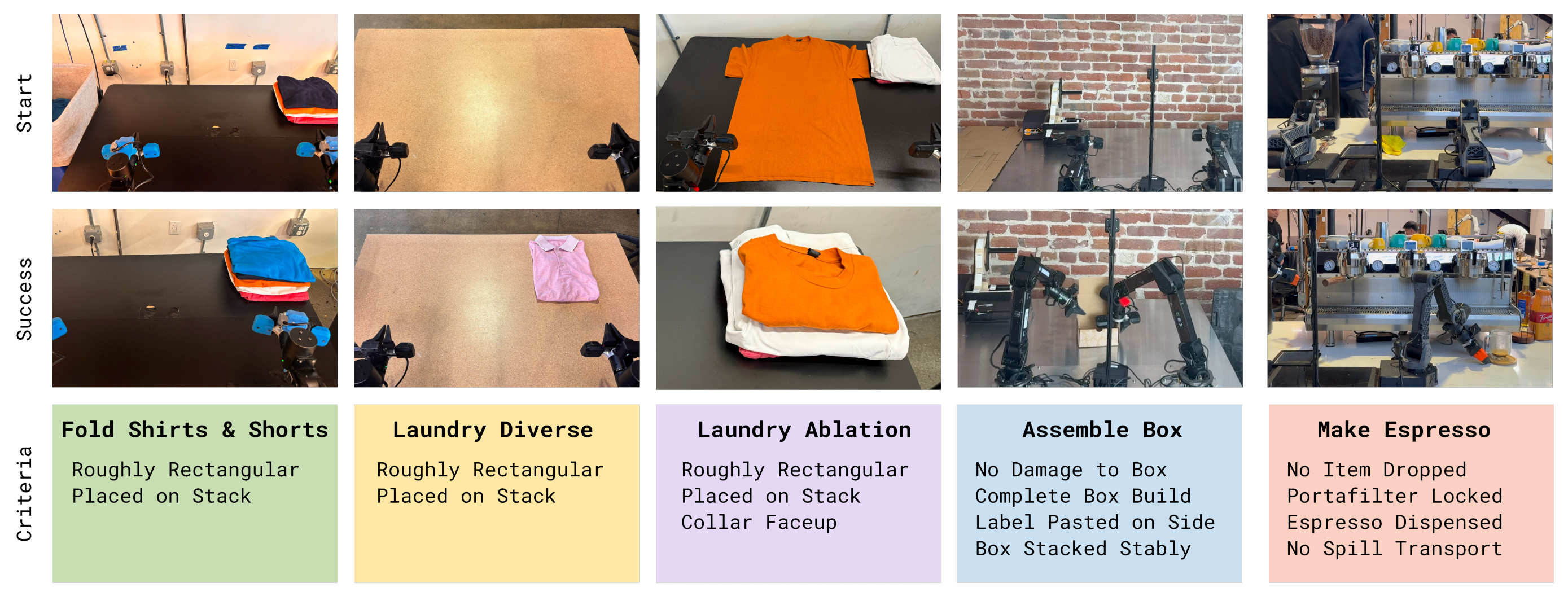
- 洗衣(T 恤和短裤)
这是 π0 论文 [81] 中的标准叠衣任务。该任务包括:从一个具有可变初始条件的篮子中取出一件 T 恤或一条短裤,将其摊平并折叠
若在 200 秒内成功将一件衣物折叠好并堆放在桌面右上角,则视为成功 - 洗衣(多种物品)
这一多样化的洗衣任务需要折叠种类更加丰富的物品,共涉及 11 种物品类型,包括毛巾、纽扣衬衫、毛衣、牛仔裤、T 恤、短裤、POLO 衫、裙子、长袖上衣、袜子和内衣
————
为了在实验中获得方差较小的度量指标,作者在其中最具挑战性的物品之一——纽扣衬衫——上评估性能
然而,策略是在所有物品上进行训练的,附带的视频展示了各种衣物的实验结果
成功被定义为:在 500 秒内将目标物品正确折叠并放置到桌面上的叠放堆中 - 洗衣任务(针对性失败消除)
在作者的消融实验中,洗衣折叠任务的最终版本采用了结构化程度更高的设置:任务仅涉及从一个固定的、摊平的初始状态开始折叠一件橙色 T 恤
作者极为重视任务成功,设置了严格的成功标准:要求在 200 秒内正确完成折叠,并且始终保证衣领朝上
作者发现,该任务非常有助于评估 RECAP 是否能够通过强化学习移除特定的不良行为(在本例中,即把衣领折成朝下而不是朝上) - 咖啡(双份意式浓缩)
作者在一个具有挑战性的长时程制作咖啡任务上评估我们的策略,该任务是使用一台商用意式浓缩咖啡机
尽管咖啡策略可以制作多种饮品(拿铁、冰美式、意式浓缩等),甚至还能用毛巾清洁咖啡机,但在定量实验中,作者专注于双份意式浓缩咖啡这一任务
————
该任务包括拿起手柄(portafilter),将其放到磨豆机上并将咖啡豆研磨进手柄中,对研磨好的咖啡粉进行填压,将手柄锁入意式咖啡机,把杯子拿到位,萃取完整一份双份意式浓缩咖啡,然后上饮
成功的度量标准是:在 200秒内完成所有步骤,且不出现关键性错误(例如把手柄掉在地上或将咖啡洒出) - 纸箱组装
作者在真实世界的工厂部署场景下,对他们的策略在包装箱组装问题上的表现进行评估。装箱组装包括从一张压平的纸板开始将纸箱折叠成型,在其上贴上标签,并将箱子放置在周转箱中的适当位置
————
出于定量实验的目的,作者关注任务的所有阶段,并将总体成功定义为:在600秒内将一张压平的纸板变为一个已组装完毕并堆放好的纸箱
对于数据集构成:作者对所有任务均采用Algorithm1中描述的数据集聚合策略。然而,每个任务的性质各不相同:每个任务的情节长度不同,Iteration 0模型在各任务上的表现也有差异,并且有一个任务(装箱组装)是在部署场景下异地执行的。因此,作者初始拥有的示范数据量不同,并为迭代改进收集了不同量的经验数据
- 对于洗衣任务(T恤和短裤),作者仅使用自主评估数据——没有专家修正。随着推动模型性能,使其在速度方面与专家数据采集者更加接近,提供修正变得更加困难
对于该任务,作者在4 个机器人工作站收集了300 个实验用于评估性能- 对于多样化的叠衣任务,作者收集了450个评估实验和287 个修正实验。对于失效模式移除消融实验,作者同时收集自主数据和策略修正数据
总共收集了∼1000 个自主实验和280 + 378 个修正实验,分布在3 台机器人上- 对于组装盒子任务,作者直接在部署场景中收集数据,每轮使用3 台机器人,收集600 个演示实验和360 个修正实验
- 对于咖啡任务,作者进行了一轮实验,收集了429 个修正实验以及414 个自主实验
2.1.2 对比与消融实验
作者将RECAP与多个基线方法进行了对比:
- 预训练的π0.5 [5]
该基线不使用RL,也不利用RECAP - 预训练的π0.6 [6]
它不包含优势指示器 - 使用RL 预训练的π∗0.6,但无RL后训练
它与其价值函数一起通过RL 进行预训练,并且包含了如1.3.4节(对应于原论文第V-D 节)所述的优势指示器 - π∗0.6 离线RL + SFT,相当于也无RL后训练,但有SFT
该模型通过使用目标任务的示范数据对基础π∗0.6 预训练checkpoint进行微调来训练。这种微调称为”SFT”,因为对于所有示范,其advantage 值都被固定为True
————
作者发现,这种将离线RL 预训练的π∗0.6模型与高质量SFT 相结合的方法优于标准SFT(未进行离线RL预训练),并且为基于机器人实时数据的RL提供了一个良好的起点 - π∗0.6(最终的方法)
这是最终使用RECAP 在目标任务上训练的模型,包括自主rollouts和专家纠正
默认情况下,作者使用β = 1 时进行评估。在一些实验中,作者也会考虑使用CFG 进行推理,这对应于β > 1
且作者还考虑了文献中两种替代的策略提取方法,以对比作者的优势条件方法。这两种方法都使用与RECAP相同的机器人本体数据,但采用了不同的策略学习方法:
- AWR
从相同的预训练模型π0.6(不带优势条件化,即with out advantage conditionin)出发,作者基于从他们的价值函数中提取的优势,采用优势加权回归[68]进行微调 - PPO
作者实现了DPPO/FPO[23,82]的一个变体,在其中作者基于单步扩散目标计算似然,并且按照 SPO [83]中的做法使用另一种 PPO 约束的定义(详见附录D)
如原论文附录D所示,作者实现了一种与 DPPO 和 FPO [23,82] 相关的PPO [66] 变体,并将其用作额外的基线。为了以高效的计算方式同时训练模型的自回归部分以及基于扩散的动作专家,作者基于单步扩散目标计算似然
- 具体而言,作者使用类似于上文「1.3.2 从π0.6到π∗0.6与优势条件化」最后公式9的似然下界,但不包含改进指示器
将其分解为自回归项和流匹配项,表达为公式10
这类似于 FPO 『82-详见此文《FPO——流匹配策略梯度:避开复杂的对数似然计算,通过「最大化基于条件流匹配损失计算优势加权比率」做策略优化,兼容PPO-CLIP》』 中使用的扩散似然下界。作者将其与 PPO 风格的损失结合,分别分为扩散项和自回归项- 在初步实验中,作者发现,在他们的设置下,使用标准的 PPO 剪切目标函数时,很难对动作专家(其通过无界扩散头对动作进行建模)施加信任域约束
这很可能部分源于算法属于“离线”范式,无法每隔几个梯度步骤就从真实机器人收集新数据
——
然为使训练过程更加稳定,作者发现采用遵循 SPO [83] 的另一种 PPO约束定义是有效的
最终得到的损失函数如下
其中和
分别是用于自回归和流匹配模型部分的信赖域参数。作者采用这种变体,从π0.6检查点开始在评估数据上进行训练
2.2 定量结果:对「策略提升率、多轮迭代的必要性、优势条件策略提取方法」等4个方面的全面评估
评估中使用了两个指标:吞吐量和成功率
- 吞吐量衡量每小时成功完成任务的次数,因此能够将速度和成功率综合为一个具有实际应用意义的量
- 成功率表示任务成功的比例,并根据人工标注的数据得出。标注人员被要求以多个质量指标对该episode进行评估,并将这些质量指标汇总为一个成功标签
2.2.1 RECAP 对策略提升了多少
第一方面,1) RECAP 对策略提升了多少?
为回答这个问题,作者在图7 和图8 中展示了主要的量化结果
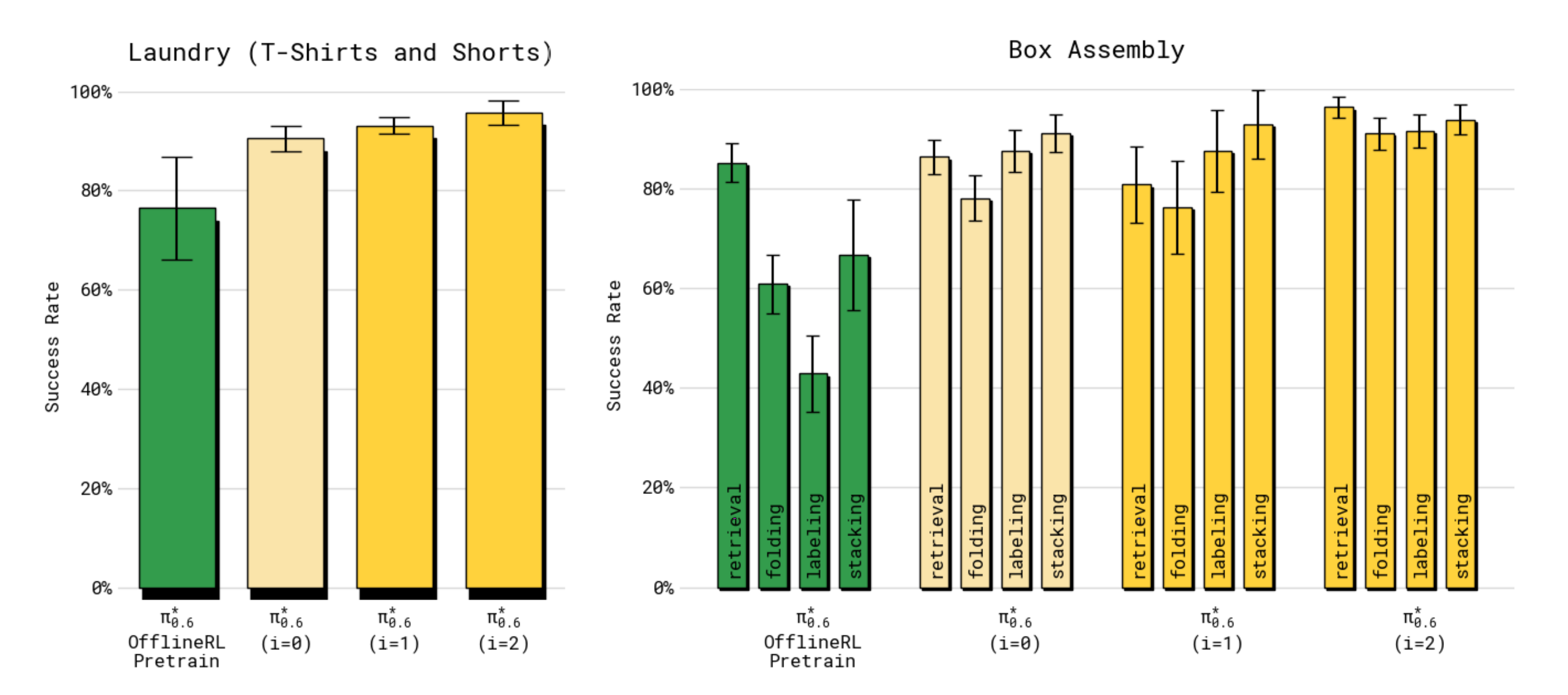
- 在所有任务中,最终的π∗0.6 模型都显著优于基础(SFT)π0.6 模型、RL(离线)预训练π∗0.6 模型、以及离线RL + SFT 的π∗0.6 模型
————
在包含机器人上收集的数据后(即从离线RL+SFT 到最终π∗0.6 模型,说白了,就是包含机器人与环境的自主交互,且必要时人工干预),多样化洗衣折叠任务和浓缩咖啡任务的吞吐量提高了两倍以上,失败率大约降低了一半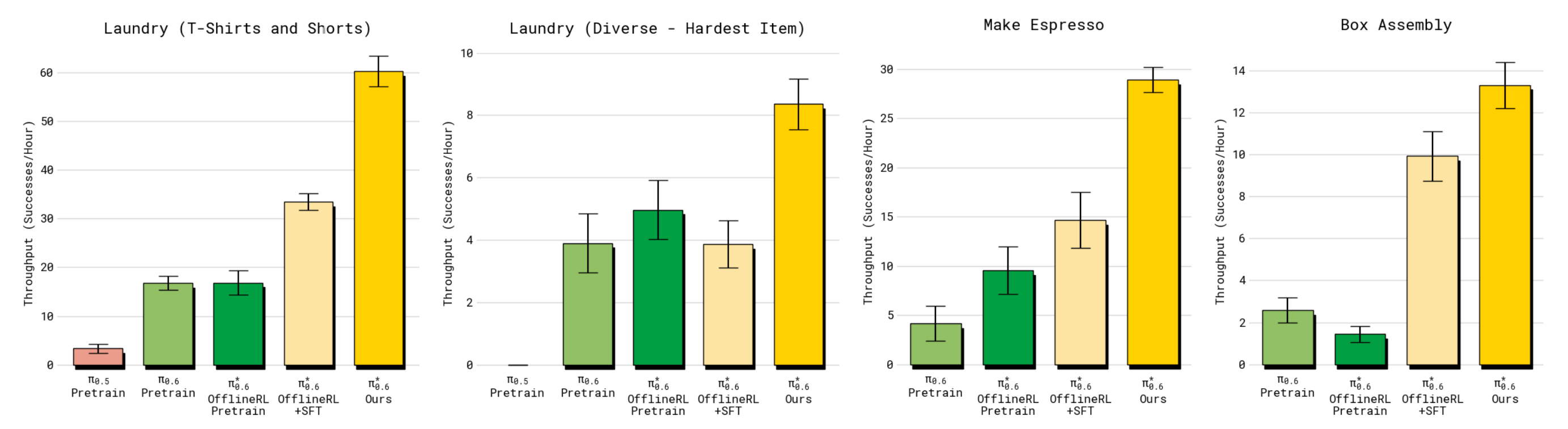
- 在更简单的洗衣任务(T 恤和短裤)中,SFT 阶段之后成功率已经接近最大值,但最终模型的吞吐量仍然有显著提升
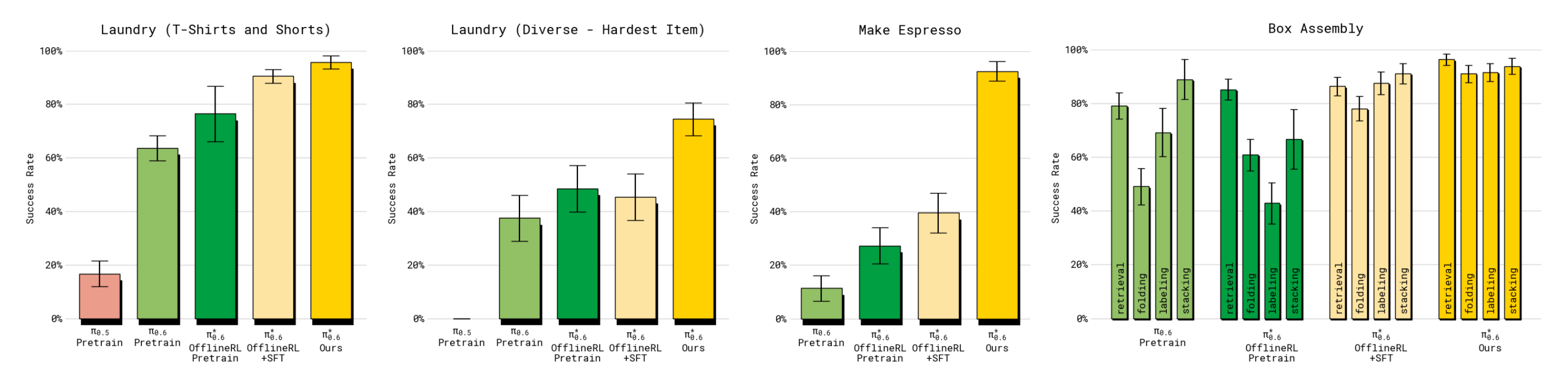
在除多样化洗衣任务之外的所有任务上,最终的π∗0.6 模型的成功率都在90 %+ 范围内。这使得它在实际环境中具有可用性,例如在办公室制作意式浓缩咖啡饮品或在工厂组装纸箱,正如附带的视频所展示的那样
- 对于箱子组装任务,图8(右)展示了该任务四个阶段的成功率分解:拾取纸箱板、构建纸箱、给纸箱贴标签,以及将其放置在箱子中一个空闲的位置
- 与其他模型相比,π∗0.6 在所有阶段都达到了更高的成功率。这些阶段中大多数失败的原因是策略耗尽了时间。附带的视频展示了每个任务运行数小时的延时拍摄
2.2.2 RECAP 对 π∗0.6 的提升有多大
第二方面,在多次迭代中,RECAP 对 π∗0.6 的提升有多大
接下来阐述,通过多轮数据收集和训练,RECAP训练流程如何提升策略表现
作者主要研究 T 恤与短裤折叠任务以及箱体组装任务
- 对于 T 恤折叠任务,仅使用通过自主评估(无人工纠正)收集的数据,在两次迭代中进行策略改进,以评估他们的方法在仅依赖强化学习(RL)的情况下能够在多大程度上改进策略
每次迭代在四台机器人上收集 300条轨迹 - 对于箱体组装,则同时使用自主试验和带有专家远程操作员干预的试验,每次迭代包括 600次自主试验和 360 次带干预的试验
在图9 中绘制了不同迭代次数下的吞吐量,对比了RECAP 的两次迭代,分别用i = 1, i = 2 表示。最后一次迭代,标记为(Ours),对应于前一节中展示的这些任务的总体最佳结果

- 作者还对比了初始数据收集策略,该策略使用了离线RL 预训练的π∗0.6 模型并通过SFT进行微调
对于这两个任务,π∗0.6 在两次迭代中都取得了提升 - 此外,作者还在图10 中展示了随迭代次数变化的成功率『洗衣任务很快达到最大成功率(但其吞吐量仍如图9所示持续提升),而箱子组装任务的成功率则持续提升』
2.2.3 RECAP 中的优势条件策略提取方法与其他方法相比如何?
第三方面,3) RECAP 中的优势条件策略提取方法与其他方法相比如何?
- 作者将第四节B 部分「1.2.2 基于优势条件的策略提取:给每个状态打分,判定某个动作是接近目标还是偏离目标」介绍的优势条件策略提取方法与文献中的其他方法进行了比较:AWR 和PPO
- 在任务上,作者使用T 恤与短裤任务进行对比。为了确保对比的可控性,作者使用了与训练最终模型相同的数据进行比较。这为基线方法提供了略微的优势,因为它们能够访问在运行RECAP 时收集到的更高质量数据
结果如图11 所示「不同策略提取方法的对比。RECAP应用于π∗在洗衣任务中,0.6相比AWR和PPO实现了迄今为止最高的吞吐量」
具体而言,虽然AWR 和PPO 都能够取得合理的结果,但它们都远远逊色于作者的方法,并且难以在离线RL + SFT π∗0.6 模型的基础上取得提升
- 对于PPO,不得不使用较小的信任域约束(η = 0.01) 以在该离策略环境下稳定训练,虽然这样可以保证训练稳定,但该方法并未实现良好的性能
- AWR 可以达到合理的成功率,但导致策略执行速度更慢,吞吐量较低
2.2.4 RECAP 能否在相对较少的数据下显著改变策略行为并消除一个失败模式?
第四方面,4)RECAP 能否在相对较少的数据下显著改变策略行为并消除一个失败模式?
虽然前面的实验主要关注于策略性能的整体端到端评估,但也可以聚焦于某个特定的失败模式,来考察使用RECAP 进行RL 训练是否能够从策略中消除某个具体错误
- 为回答这一问题,作者使用了带有严格成功标准的洗衣任务版本,该标准要求策略将T恤折叠并且衣领居中且朝上。每个回合都以特定的对抗性条件初始化,即T 恤被平铺在桌面上,使得基线离线RL + SFT 策略经常无法正确折叠
- 正如图12 所示,在该设置下应用RECAP 进行两轮迭代(每轮收集600 条轨迹),最终得到的策略有97 % 的成功率,并且速度很快
——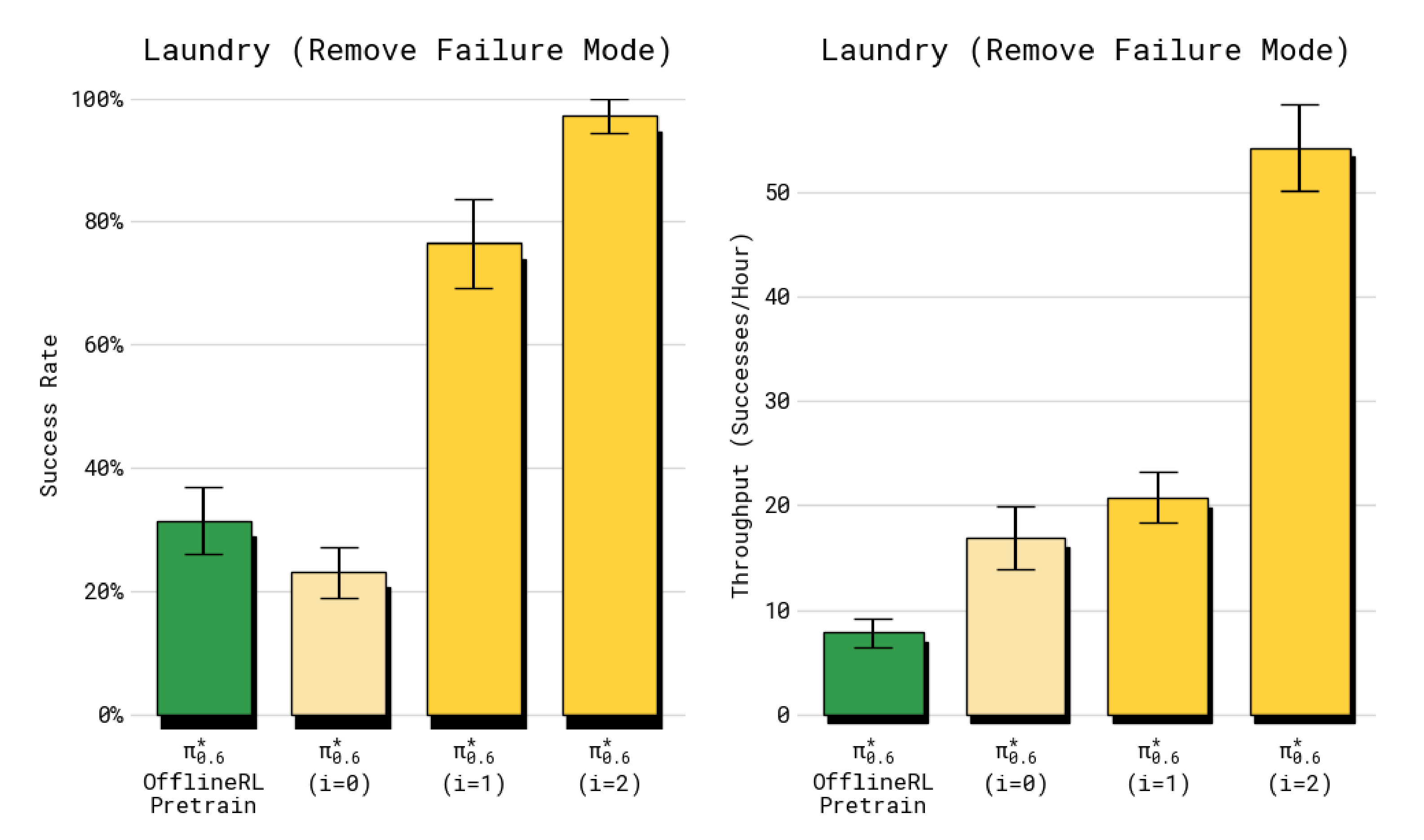
因此,作者得出结论:RECAP 能够有效消除特定的失败模式,即使完全通过RL 学习而没有任何干预数据或额外演示
2.3 目前的局限与改进方向
如原论文最后所说,针对RECAP系统,有多个改进方向
- 首先,系统尚未实现完全自动化:它依赖于人工标注和人为干预来提供奖励反馈、操作干预以及回合重置
已有多项相关研究探索了自动化这些环节的方法[84,85],而VLA(视觉语言代理)为实现更自动化的数据采集提供了新途径,例如通过利用高层策略[86]来推理如何重置场景 - 其次,系统在探索方面相对简单,主要采用贪婪策略,依赖策略的随机性和人工干预来发现新的解决方案
当初始模仿学习策略已经能够做出合理动作时,这种方式是可以接受的,但通过更先进的探索方法仍有很大提升空间 - 最后,RECAP采用“离线”迭代更新(即收集一批数据,重新训练模型,并重复该过程),而不是运行完全在线的RL循环——当然 其中,策略和值函数会随着数据的收集实时更新
————
作者声称,他们之所以做出这个选择,是出于便利性的考虑,但将该方法扩展为完全并发的在线RL框架,是未来值得探索的方向
更广泛地说,利用强化学习训练VLA或许是实现其在现实应用中达到足够性能水平的最直接途径
当然了,作者也说,针对VLA的强化学习面临诸多挑战,包括高容量模型的大规模强化学习训练难度、样本复杂性、自主性以及延迟反馈等问题
尽管为小规模系统或“虚拟”领域(如大型语言模型)设计的现有强化学习框架可以作为良好的起点,但要使强化学习成为VLA训练的可行工具,还需要更多研究
后记(含重大修订记录)
π*0.6里面的细节还是多啊,更何况一旦涉及到RL,细节便少不了,比如少不了数学推导/公式,不过,十多年如一日,我尽可能让推导/公式 更好懂
以下是大的修订记录
- 26年除夕
昨天下午和今天上午,针对本文第一部分的内容,全部做了修订,以精准化描述,^_^
2.19,把本文的标题 足够精准化了下,即为
π∗0.6——通过RL框架RECAP微调流式VLA π0.6:先基于演示数据做离线RL预训练,再在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预) - 26年3.3(元宵节),刚再在本文的1.3.4节中强调了很多重要细节,比如
1 ChatGPT中第三阶段ppo训练时,每一轮策略的迭代起始于上一轮迭代的策略
2 但π*0.6中的RL后训练迭代的策略都起始于同一个checkpoint
且标题又改成了
π∗0.6——通过RL框架RECAP微调流式VLA π0.6:先基于演示数据做离线RL预训练,再SFT,最后在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预)
26年3.4,把本文第二部分的内容也大部分 修订了下
26年3.5,把几个优势阈值相关的内容(最开始的RL预训练 30%;随后的SFT恒为true;最后的RL后训练 40%、一个特例10%,及人工纠正恒为true),修订了下 - 26年3.12,修订《1.3.3 奖励定义(包含稀疏奖励的设置)与价值函数训练》中关于“稀疏奖励设置”的内容
- ..

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 38
38 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)