基于深度学习的Turbo译码算法理论分析
摘要:本文探讨深度学习在Turbo译码中的应用,突破传统置信传播算法的局限。传统Turbo译码采用迭代SISO结构,依赖BCJR算法,存在计算复杂度高、收敛慢等问题。深度学习通过数据驱动方法,用CNN等模型拟合"软输入-软输出"的非线性映射,保留迭代结构但简化计算过程。文章详细介绍了训练样本构建流程,包括编码调制、信道传输和LLR转换,并提出基于CNN的译码器架构,包含卷积层、
目录
传统Turbo译码依赖迭代置信传播算法,存在收敛速度慢、参数调优复杂、硬件实现成本高等问题。随着深度学习在信号处理领域的渗透,基于深度学习的Turbo译码技术通过数据驱动与模型驱动的融合,实现了译码性能与效率的双重突破。
1.Turbo码与传统译码
传统Turbo译码采用“迭代软输入软输出(SISO)” 结构,两个分量译码器(DEC1、DEC2)交替工作,通过交换外信息实现性能提升。其结构如下图所示:
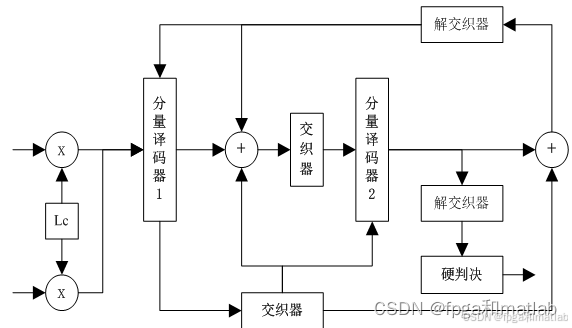
软输入:接收端收到受噪声污染的序列y=[yu, yv1, yv2] ,其中yu、yv1、yv2分别对应信息位和两个校验位的接收信号。
软输出:每个SISO译码器输出信息位的后验概率,并分离出“外信息”(仅包含本译码器通过校验关系获得的新信息,不含输入软信息)。
迭代过程:DEC1利用yu和yv1计算外信息,经解交织器后输入DEC2;DEC2利用yv2和输入外信息计算新的外信息,经交织器反馈给DEC1,重复迭代直至收敛。
硬判决:最终根据后验概率最大值输出硬判决序列u
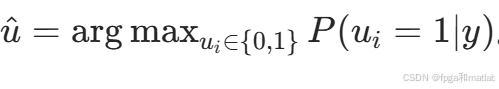
传统SISO译码器的核心是BCJR算法(或简化的MAX-LOG-MAP算法),其本质是基于格状图的概率递推,但存在计算复杂度高、迭代次数多(通常需8-16次)的问题。深度学习的引入,正是通过神经网络拟合译码器的非线性映射关系,简化计算并加速收敛。
2.基于深度学习的Turbo译码核心原理
深度学习Turbo译码的本质是用神经网络替代传统SISO译码器,或通过神经网络优化迭代过程中的外信息处理。
1.将Turbo译码的“软输入-软输出”映射建模为非线性函数 f:Y→P ,其中Y是接收信号的软信息空间, P是信息位的后验概率空间。
2.利用深度学习模型(如CNN、RNN、Transformer)学习该非线性函数,无需依赖格状图和复杂概率递推。
3.保留Turbo码的“迭代结构”,通过神经网络译码器交替输出外信息,实现性能提升;或通过端到端训练,直接学习从接收信号到原始信息的映射。
2.1 训练样本构建
1.信息序列生成:随机生成二进制信息序列u∈{0,1}L ,长度L可选取典型值(如L=1024、 L=2048),满足Turbo码编码的块长要求。为保证样本多样性,生成N个独立信息序列(N≥10^5 )。
2.对每个信息序列u进行编码:生成码序列c=[u,v^1 ,v^2 ] 。其中分量编码器采用RSC结构,以常用的约束长度K=3 、生成多项式G=(1,1+D+D^2)/(1+D^2),RSC编码器的状态转移方程为:

3.对码序列c进行BPSK调制:得到发送符号序列s=[s1,s2 ,...,s3L] 。将s通过AWGN信道传输,接收符号序列为:

4.将接收符号y转换为LLR形式的软信息:作为模型输入。对于信息位接收信号yu,其LLR为:

5.数据划分与标准化:将样本集按7:2:1比例划分为训练集、验证集、测试集。
2.2 深度学习译码器模型
我们采用基于CNN卷积神经网络的译码器结构:
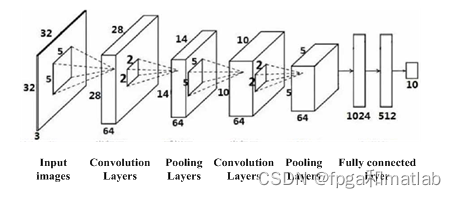
输入层:输入向量为预处理后的软信息xnorm∈R3L,为适配CNN的二维卷积操作,将其变为二维张量X∈RL×3 ,其中每行对应一个信息位的“信息位LLR+两个校验位LLR”,即:
![]()
卷积层:卷积操作的数学表达式为:

批归一化层:插入卷积层之间,加速训练收敛并缓解过拟合。对每层输入H^(l−1)的每个通道c′进行归一化:
全连接层:将卷积层提取的高维特征映射为信息位的外信息Le∈RL 。设卷积层最终输出特征为H 全连接层的数学表达式为:
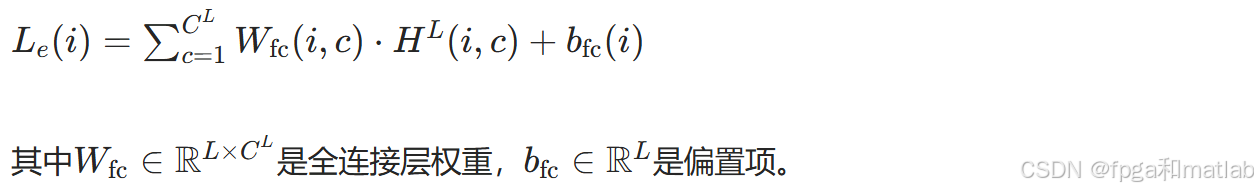
输出激活:外信息Le可正可负,无需激活函数约束;若模型直接输出后验LLRLp,也可保持线性输出,因LLR本身无取值范围限制。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 16
16 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)