Apache IoTDB 触发器完全指南:从原理到实战的全方位解析
本文围绕 IoTDB 触发器展开全方位解析,先介绍其基于 Java 反射机制实现、支持动态注册卸载且无需重启服务器的特性,详解侦听模式(可指定特定或通配路径)、两类触发器(有状态依赖多数据、无状态仅依当前数据)及两种触发时机(数据持久化前后)。接着分步说明触发器编写,包括依赖配置、接口实现(生命周期与数据监听相关)及实例解析。还讲解了用 SQL 进行触发器注册、卸载、查询的操作及状态含义,强调注册


Apache IoTDB 触发器完全指南:从原理到实战的全方位解析
本文围绕 IoTDB 触发器展开全方位解析,先介绍其基于 Java 反射机制实现、支持动态注册卸载且无需重启服务器的特性,详解侦听模式(可指定特定或通配路径)、两类触发器(有状态依赖多数据、无状态仅依当前数据)及两种触发时机(数据持久化前后)。接着分步说明触发器编写,包括依赖配置、接口实现(生命周期与数据监听相关)及实例解析。还讲解了用 SQL 进行触发器注册、卸载、查询的操作及状态含义,强调注册时建议停写。最后列出关键注意事项(如只处理新数据、保证效率等)与核心配置项,助力读者全面掌握触发器用法以应对物联网时序数据实时响应需求。

在物联网数据管理场景中,实时响应时序数据变动是个常见需求——比如数据异常时自动告警,或者将关键数据同步到其他系统。IoTDB的触发器功能正好解决了这个问题,它能帮你监听时序数据的变化,再配上自定义逻辑,轻松实现告警、数据转发这些实用功能。接下来,咱们就从基础原理到实际操作,一步步把触发器的用法讲透,不管你是刚接触的新手,还是想深入应用的开发者,相信都能有所收获。
一、触发器基础:帮你搞懂核心概念
触发器的底层是靠Java反射机制实现的,你不用复杂配置,只要简单实现个Java接口,就能监听数据变动。而且IoTDB特别灵活,支持动态注册、卸载触发器,整个过程不用重启服务器,是不是很方便?
1.1 侦听模式:想监听完哪些数据,你说了算
用触发器的时候,你可以指定它监听哪些时间序列的数据变动。比如说,你可以让它只盯着root.sg.a这一条特定序列,也能让它监控符合root.**.a这种路径模式的所有序列——这里的**是通配符,能匹配多层路径。注册触发器时,通过SQL语句就能把这个路径模式定下来,完全按你的需求来。
1.2 触发器类型:选有状态还是无状态?
触发器分两类,不同类型适用场景不一样,注册时同样用SQL指定类型就行,咱们来具体看看:
-
有状态触发器:这类触发器的执行逻辑会依赖多条数据的前后关系。比如你要统计某段时间内数据的平均值,就需要把不同节点写入的数据汇总到同一个触发器实例里计算,这样才能保留上下文信息。在集群里,这种触发器的实例只在一个节点上存在,确保数据计算的连贯性。
-
无状态触发器:它的执行逻辑只和当前输入的数据有关,不用汇总其他节点的数据。像判断单条数据是否超出阈值这种场景,用它就很合适。集群里每个节点都会有一个无状态触发器的实例,处理起来更高效。
1.3 触发时机:数据写入前后,你选哪个节点?
目前触发器支持两种触发时机,后续还会增加更多选项,同样在注册时用SQL指定:
-
BEFORE INSERT:数据持久化到数据库之前触发。不过要注意,现在的触发器还不能做数据清洗,不会改动要持久化的数据本身,它主要是在数据落地前做一些判断或预处理。
-
AFTER INSERT:数据成功持久化后触发。如果你的需求是数据保存完成后再做操作,比如同步到其他系统,那选这个时机就对了。
二、动手写触发器:从依赖到代码实现
要实现触发器功能,得自己写个Java类,下面咱们一步步来,把每个环节讲清楚。
2.1 先搞定依赖:别让环境拖后腿
写触发器逻辑时,得用到指定的依赖。如果你用Maven管理项目,直接从Maven库里找对应的依赖就行,关键是要选和你服务器版本一致的依赖版本,不然可能会出兼容性问题。具体的依赖配置如下:
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>iotdb-server</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
2.2 接口详解:知道要实现哪些方法
写触发器,本质上是实现org.apache.iotdb.trigger.api.Trigger这个接口。先看看这个接口里都有哪些方法:
import org.apache.iotdb.trigger.api.enums.FailureStrategy;
import org.apache.iotdb.tsfile.write.record.Tablet;
public interface Trigger {
/**
* 这个方法主要在调用{@link Trigger#onCreate(TriggerAttributes)}之前,用来验证{@link TriggerAttributes}的合法性。
*
* @param attributes TriggerAttributes
* @throws Exception 验证过程中可能抛出的异常
*/
default void validate(TriggerAttributes attributes) throws Exception {}
/**
* 验证通过后,创建触发器时会调用这个方法。
*
* @param attributes TriggerAttributes
* @throws Exception 创建过程中可能抛出的异常
*/
default void onCreate(TriggerAttributes attributes) throws Exception {}
/**
* 卸载触发器时会调用这个方法。
*
* @throws Exception 卸载过程中可能抛出的异常
*/
default void onDrop() throws Exception {}
/**
* 重启DataNode时,已经注册的触发器会被恢复,恢复过程中会调用这个方法。
*
* @throws Exception 恢复过程中可能抛出的异常
*/
default void restore() throws Exception {}
/**
* 重写这个方法可以设置期望的FailureStrategy,默认策略是{@link FailureStrategy#OPTIMISTIC}。
*
* @return {@link FailureStrategy}
*/
default FailureStrategy getFailureStrategy() {
return FailureStrategy.OPTIMISTIC;
}
/**
* @param tablet 数据结构详情可参考{@link Tablet},插入的数据会被组装成Tablet,你可以基于Tablet定义处理逻辑。
* @return 触发成功返回true
* @throws Exception 触发过程中可能抛出的异常
*/
default boolean fire(Tablet tablet) throws Exception {
return true;
}
}
这个接口里的方法主要分两类:生命周期相关和数据变动监听相关。而且所有方法都不是必须实现的,你用不上的方法不用管,它不会影响数据操作。下面咱们逐个拆解这些方法,搞清楚它们各自的作用。
生命周期相关接口:触发器“从生到死”的关键方法
这部分方法主要负责触发器在创建、卸载、恢复等阶段的操作,具体如下表:
| 接口定义 | 详细描述 |
|---|---|
| default void validate(TriggerAttributes attributes) throws Exception {} | 用CREATE TRIGGER语句创建触发器时,你可以给触发器指定参数,这个方法就是用来验证这些参数对不对的。比如参数格式是否正确、必填参数有没有缺失,都靠它来检查。 |
| default void onCreate(TriggerAttributes attributes) throws Exception {} | 执行CREATE TRIGGER语句创建好触发器后,这个方法会被调用一次——每个触发器实例的生命周期里,它只跑这一次。它的作用可不小:一方面能帮你解析SQL里定义的自定义属性,另一方面还能创建或申请资源,比如建立和外部系统的连接、打开需要读写的文件等。 |
| default void onDrop() throws Exception {} | 用DROP TRIGGER语句卸载触发器时,这个方法就会被调用,同样每个实例生命周期只执行一次。它主要用来做资源释放的工作,比如断开之前建立的外部连接、关闭打开的文件,还能把触发器计算的结果持久化保存起来,避免数据丢失。 |
| default void restore() throws Exception {} | 重启DataNode的时候,集群会恢复节点上已经注册的触发器实例,这时候就会给该节点上的有状态触发器调用一次这个方法。另外,如果有状态触发器所在的DataNode宕机了,集群会在其他可用的DataNode上恢复这个触发器实例,这个过程中也会调用它。你可以在这个方法里自定义恢复逻辑,比如把之前保存的状态数据加载回来,让触发器接着之前的状态工作。 |
数据变动监听相关接口:触发器怎么响应数据变化?
数据变动时,触发器是靠fire方法来响应的,而数据会以Tablet的形式传给这个方法。你可以通过Tablet获取对应序列的元数据(比如序列名称、数据类型)和具体数据,然后实现自己的处理逻辑。如果触发成功,这个方法要返回true;要是返回false或者抛出异常,就会被认定为触发失败,这时候会根据监听策略来处理。
这里有个关键点要理解:执行一次INSERT操作时,IoTDB会先检查每条时间序列有没有对应的触发器(也就是监听该路径模式的触发器),然后把符合同一个触发器监听模式的所有时间序列数据,组装成一个新的Tablet传给这个触发器的fire方法。简单说,这个过程可以理解成从Map<PartialPath, List<Trigger>>(路径到触发器列表的映射)转变成Map<Trigger, Tablet>(触发器到对应Tablet的映射)。
另外要注意,目前IoTDB不会保证触发器的触发顺序,所以你的处理逻辑里别依赖触发器的执行先后哦。
咱们举个例子帮你更直观理解:
假设现在有三个触发器,触发时机都是BEFORE INSERT:
- 触发器
Trigger1监听路径模式:root.sg.* - 触发器
Trigger2监听路径模式:root.sg.a - 触发器
Trigger3监听路径模式:root.sg.b
执行写入语句:insert into root.sg(time, a, b) values (1, 1, 1);
这时候,序列root.sg.a会匹配Trigger1和Trigger2,序列root.sg.b会匹配Trigger1和Trigger3。所以会出现这样的情况:
root.sg.a和root.sg.b的数据会组装成一个新的tablet1,在指定触发时机调用Trigger1.fire(tablet1)root.sg.a的数据会组装成tablet2,调用Trigger2.fire(tablet2)root.sg.b的数据会组装成tablet3,调用Trigger3.fire(tablet3)
监听策略接口:触发失败了怎么办?
触发失败时,具体怎么处理,就看getFailureStrategy方法设置的策略了。这个方法返回的是org.apache.iotdb.trigger.api.enums.FailureStrategy,目前有乐观和悲观两种策略可选:
-
乐观策略:这是默认策略。如果某个触发器触发失败了,不会影响后面其他触发器的触发,也不会干扰数据写入流程。简单说,就是不对失败涉及的序列做额外处理,只打日志记录失败情况,最后会告诉用户数据写入成功,但触发器触发部分失败了。适合对数据写入成功率要求高,触发失败影响不大的场景。
-
悲观策略:要是某个触发器触发失败,后面所有触发流程都会停下来。而且如果这个触发器的触发时机是
BEFORE INSERT,那数据写入也会直接终止,返回写入失败。适合触发逻辑必须成功,否则数据不能写入的场景。
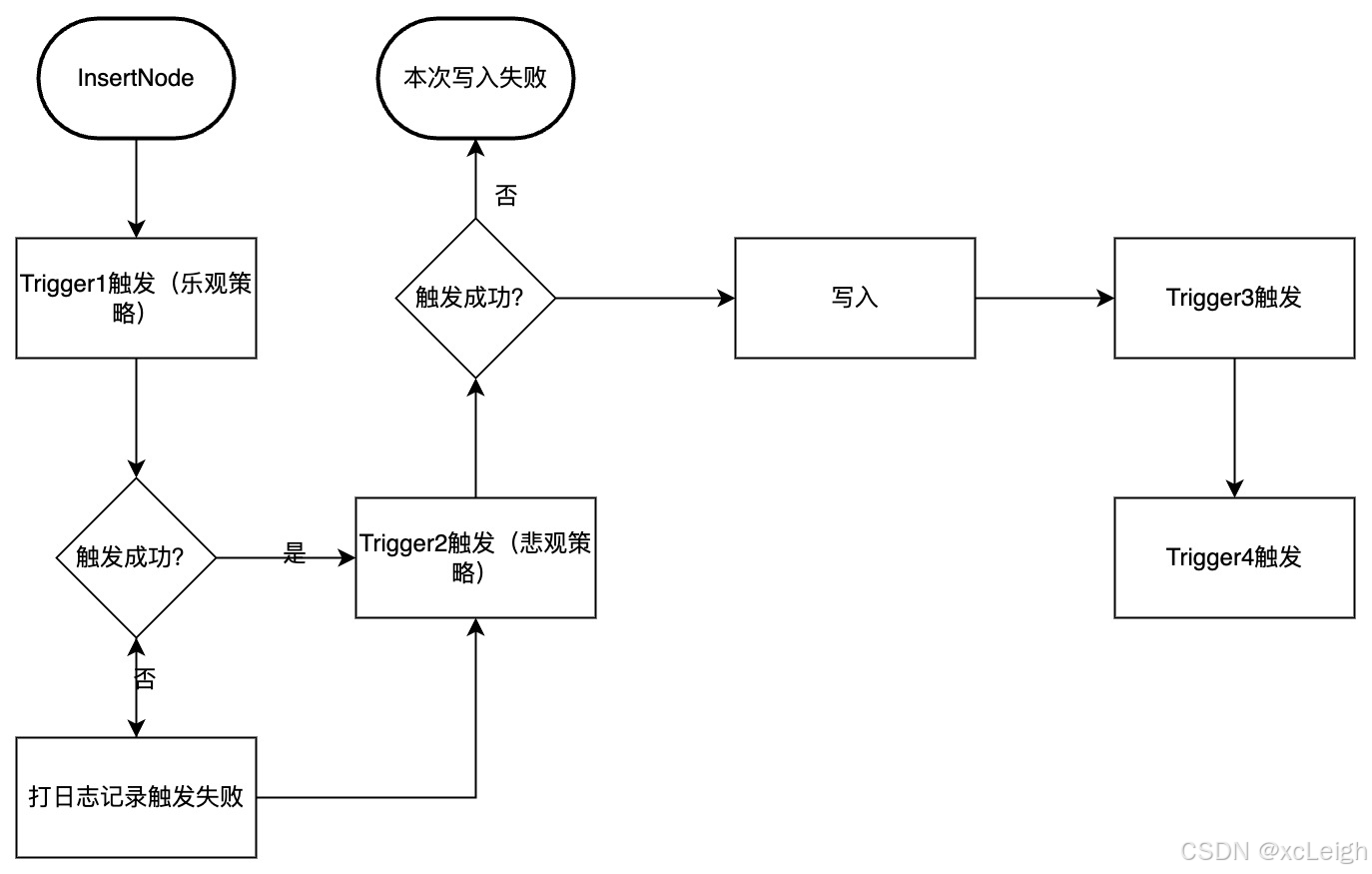
给你画个流程帮你理解:假设Trigger1用乐观策略,Trigger2用悲观策略,它们的触发时机都是BEFORE INSERT;Trigger3和Trigger4触发时机是AFTER INSERT。正常情况下,数据写入前会先触发Trigger1,不管它成功还是失败,都会接着触发Trigger2;但如果Trigger2失败了,后面的Trigger3和Trigger4就不会触发了,而且因为Trigger2是BEFORE INSERT时机,数据也写不进去。
2.3 实例参考:看个真实例子怎么写
如果你用Maven,推荐你看看官方的示例项目trigger-example,能帮你更快上手,项目地址在这里(实际使用时替换成真实地址)。后续官方还会加更多示例,值得关注。
下面给你看一个示例项目的代码,咱们逐行解释关键部分,帮你理解怎么写触发器:
/*
* 版权归Apache软件基金会(ASF)所有
* 基于一个或多个贡献者许可协议。本文档包含的版权信息可用于了解版权归属。
* ASF根据Apache许可证2.0版(以下简称“许可证”)向你授予使用本文件的权利;
* 除非符合许可证的规定,否则不得使用本文件。你可以从以下地址获取许可证副本:
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* 除非适用法律要求或书面同意,否则根据许可证分发的软件按“原样”分发,
* 不附带任何明示或暗示的担保或条件。请参阅许可证,了解特定语言下
* 有关权限和限制的详细规定。
*/
package org.apache.iotdb.trigger;
// 导入需要用到的类:AlertManager相关的配置、事件和处理器,还有触发器核心接口和数据结构类
import org.apache.iotdb.db.engine.trigger.sink.alertmanager.AlertManagerConfiguration;
import org.apache.iotdb.db.engine.trigger.sink.alertmanager.AlertManagerEvent;
import org.apache.iotdb.db.engine.trigger.sink.alertmanager.AlertManagerHandler;
import org.apache.iotdb.trigger.api.Trigger;
import org.apache.iotdb.trigger.api.TriggerAttributes;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
// 自定义触发器类,实现Trigger接口
public class ClusterAlertingExample implements Trigger {
// 创建日志对象,用来记录触发过程中的关键信息
private static final Logger LOGGER = LoggerFactory.getLogger(ClusterAlertingExample.class);
// 创建AlertManager处理器实例,用来和AlertManager交互发送告警
private final AlertManagerHandler alertManagerHandler = new AlertManagerHandler();
// 配置AlertManager的连接地址,这里指定为本地的9093端口的API地址
private final AlertManagerConfiguration alertManagerConfiguration =
new AlertManagerConfiguration("http://127.0.0.1:9093/api/v2/alerts");
// 定义告警名称
private String alertname;
// 用HashMap存储告警的标签信息(比如序列名、数值、严重级别)
private final HashMap<String, String> labels = new HashMap<>();
// 用HashMap存储告警的注释信息(比如告警摘要、描述)
private final HashMap<String, String> annotations = new HashMap<>();
// 重写onCreate方法,创建触发器时初始化配置和资源
@Override
public void onCreate(TriggerAttributes attributes) throws Exception {
// 设置告警名称为"alert_test"
alertname = "alert_test";
// 给标签赋值:指定监听的序列是root.ln.wf01.wt01.temperature,数值和严重级别先留空
labels.put("series", "root.ln.wf01.wt01.temperature");
labels.put("value", "");
labels.put("severity", "");
// 设置注释:摘要为"high temperature",描述用占位符展示告警名、序列名和数值
annotations.put("summary", "high temperature");
annotations.put("description", "{{.alertname}}: {{.series}} is {{.value}}");
// 打开AlertManager连接,初始化处理器
alertManagerHandler.open(alertManagerConfiguration);
}
// 重写onDrop方法,卸载触发器时释放资源
@Override
public void onDrop() throws IOException {
// 关闭AlertManager连接,避免资源泄漏
alertManagerHandler.close();
}
// 重写fire方法,数据变动时执行告警逻辑
@Override
public boolean fire(Tablet tablet) throws Exception {
// 从Tablet中获取测量值的 schema 列表,里面包含数据类型、序列名等元信息
List<MeasurementSchema> measurementSchemaList = tablet.getSchemas();
// 遍历schema列表,处理每条序列的数据
for (int i = 0, n = measurementSchemaList.size(); i < n; i++) {
// 只处理数据类型是DOUBLE(浮点型)的列
if (measurementSchemaList.get(i).getType().equals(TSDataType.DOUBLE)) {
// 从Tablet中获取当前列的DOUBLE类型数据数组
double[] values = (double[]) tablet.values[i];
// 遍历每个数据值,判断是否需要触发告警
for (double value : values) {
// 如果数值大于100.0,触发严重级别为critical的告警
if (value > 100.0) {
LOGGER.info("trigger value > 100");
// 更新标签中的数值和严重级别
labels.put("value", String.valueOf(value));
labels.put("severity", "critical");
// 创建告警事件,包含告警名、标签和注释
AlertManagerEvent alertManagerEvent =
new AlertManagerEvent(alertname, labels, annotations);
// 通过处理器发送告警事件到AlertManager
alertManagerHandler.onEvent(alertManagerEvent);
}
// 如果数值大于50.0但不超过100.0,触发严重级别为warning的告警
else if (value > 50.0) {
LOGGER.info("trigger value > 50");
labels.put("value", String.valueOf(value));
labels.put("severity", "warning");
AlertManagerEvent alertManagerEvent =
new AlertManagerEvent(alertname, labels, annotations);
alertManagerHandler.onEvent(alertManagerEvent);
}
}
}
}
// 返回true,表示触发成功
return true;
}
}
这个例子是个告警触发器,核心逻辑是监听root.ln.wf01.wt01.temperature序列的浮点型数据,当数值超过50时发警告告警,超过100时发严重告警,还会把告警信息发送到本地的AlertManager服务。你可以参考这个思路,改成符合自己业务需求的触发器。
三、触发器管理:注册、卸载、查询全攻略
触发器的管理很简单,用SQL语句就能完成注册、卸载和查询操作。不过有个小建议:注册触发器的时候最好先停止数据写入,避免出现部分节点触发、部分节点不触发的情况,具体原因后面会说。
3.1 注册触发器:一步步教你把触发器用起来
触发器可以注册在任意路径模式上,只要序列符合这个模式,数据变动时触发器的对应方法就会被调用。注册流程分三步,咱们一步一步来:
- 写触发器类:按照前面“编写触发器”的说明,实现一个完整的
Trigger类,比如前面例子里的org.apache.iotdb.trigger.ClusterAlertingExample。 - 打JAR包:把写好的项目打包成JAR包,这是后续注册的基础。
- 执行SQL注册:用
CREATE TRIGGER语句注册触发器,注册过程中会调用一次触发器的validate和onCreate方法,和前面讲的接口功能一致。
注册SQL语法详解
完整的SQL语法是这样的:
// 创建触发器的SQL语法
createTrigger
: CREATE triggerType TRIGGER triggerName=identifier triggerEventClause ON pathPattern AS className=STRING_LITERAL uriClause? triggerAttributeClause?
;
// 触发器类型:无状态(STATELESS)或有状态(STATEFUL)
triggerType
: STATELESS | STATEFUL
;
// 触发时机:写入前(BEFORE)或写入后(AFTER)
triggerEventClause
: (BEFORE | AFTER) INSERT
;
// URI子句:可选,指定JAR包的下载地址
uriClause
: USING URI uri
;
// URI:字符串格式的地址
uri
: STRING_LITERAL
;
// 属性子句:可选,指定触发器的参数
triggerAttributeClause
: WITH LR_BRACKET triggerAttribute (COMMA triggerAttribute)* RR_BRACKET
;
// 单个属性:键值对形式
triggerAttribute
: key=attributeKey operator_eq value=attributeValue
;
咱们把每个部分拆解开,结合前面讲的知识,帮你理解怎么用:
- triggerName:触发器的ID,这个ID在全局是唯一的,用来区分不同触发器,而且大小写敏感。比如你给触发器起名
triggerTest,那后续卸载、查询都要用到这个名字。 - triggerType:触发器类型,选
STATELESS(无状态)还是STATEFUL(有状态),根据你的业务场景定,前面已经讲过两种类型的区别了。 - triggerEventClause:触发时机,目前只有
BEFORE INSERT(写入前)和AFTER INSERT(写入后)两种可选。 - pathPattern:触发器监听的路径模式,可以用
*和**通配符。比如root.sg.**表示监听root.sg下所有层级的序列。 - className:触发器实现类的全类名,比如前面例子里的
org.apache.iotdb.trigger.ClusterAlertingExample,必须写对,不然找不到对应的类。 - uriClause:这是可选的。如果不写,就默认DBA已经把需要的JAR包放到每个DataNode节点的
trigger_root_dir目录下(这个目录是配置项,默认在IOTDB_HOME/ext/trigger);如果写了,IoTDB会自动下载这个URI对应的JAR包,然后分发到各个DataNode的trigger_root_dir/install目录下。 - triggerAttributeClause:也是可选的,用来给触发器实例设置参数,格式是键值对。比如你想给触发器传
name和limit两个参数,就可以在这部分指定。
注册示例:看个实际的SQL怎么写
下面是个完整的注册SQL例子,咱们结合例子再讲一遍:
CREATE STATELESS TRIGGER triggerTest
BEFORE INSERT
ON root.sg.**
AS 'org.apache.iotdb.trigger.ClusterAlertingExample'
USING URI 'http://jar/ClusterAlertingExample.jar'
WITH (
"name" = "trigger",
"limit" = "100"
)
这个SQL创建了一个叫triggerTest的触发器,具体配置是:
- 类型:无状态(
STATELESS) - 触发时机:写入前(
BEFORE INSERT) - 监听路径:
root.sg.**(root.sg下所有序列) - 实现类:
org.apache.iotdb.trigger.ClusterAlertingExample - JAR包地址:
http://jar/ClusterAlertingExample.jar(IoTDB会自动下载分发) - 参数:
name为trigger,limit为100(这些参数在onCreate方法里能通过TriggerAttributes获取)
3.2 卸载触发器:不用了就及时清理
卸载触发器很简单,只要指定触发器的ID就行,用DROP TRIGGER语句。卸载过程中会调用一次触发器的onDrop方法,释放资源。
卸载SQL语法
// 卸载触发器的SQL语法
dropTrigger
: DROP TRIGGER triggerName=identifier
;
卸载示例
比如要卸载前面注册的triggerTest1触发器,执行下面的SQL就行:
DROP TRIGGER triggerTest1
执行后,这个触发器就从集群里被移除了,不会再监听数据变动。
3.3 查询触发器:看看集群里有哪些触发器
想知道集群里已经注册了哪些触发器,用SHOW TRIGGERS语句就能查到,结果会包含触发器的详细信息。
查询结果说明
查询返回的结果集格式如下:
| 列名 | 说明 |
|---|---|
| TriggerName | 触发器ID,也就是注册时的triggerName |
| Event | 触发时机,值为BEFORE_INSERT或AFTER_INSERT |
| Type | 触发器类型,值为STATELESS(无状态)或STATEFUL(有状态) |
| State | 触发器状态,后面会详细讲各个状态的含义 |
| PathPattern | 监听的路径模式 |
| ClassName | 实现类的全类名 |
| NodeId | 节点ID,无状态触发器显示ALL(所有节点都有实例),有状态触发器显示对应的DataNode ID(只有一个节点有实例) |
通过这个查询结果,你能清楚了解每个触发器的配置和当前状态,方便管理。
3.4 触发器状态:搞懂每个状态代表什么
在触发器注册和卸载的过程中,集群会维护它的状态,不同状态代表不同的阶段,而且有些状态下不建议进行数据写入,咱们来具体看看:
| 状态 | 描述 | 是否建议写入 |
|---|---|---|
| INACTIVE | 执行CREATE TRIGGER的中间状态。这时候集群刚在ConfigNode上记录了触发器的信息,但还没在任何DataNode上激活它——简单说就是触发器还没准备好。 |
否 |
| ACTIVE | 执行CREATE TRIGGER成功后的状态。这时候集群所有DataNode上的触发器都已经可用了,能正常监听数据变动。 |
是 |
| DROPPING | 执行DROP TRIGGER的中间状态。集群正在卸载这个触发器,可能还在释放资源,这时候触发器已经不能正常工作了。 |
否 |
| TRANSFERRING | 集群正在迁移触发器实例的位置。比如有状态触发器所在节点宕机了,集群正在把它迁移到其他节点,迁移过程中触发器暂时不可用。 | 否 |
知道这些状态后,你就能根据状态判断触发器是否能用,以及什么时候适合进行数据写入操作了。
四、避坑指南:这些注意事项一定要记住
用触发器的时候,有些细节如果没注意,可能会出问题,咱们把这些关键注意事项列出来,帮你避开坑:
-
触发器只处理新数据:触发器从注册成功那一刻开始生效,不会处理之前已经存在的历史数据。也就是说,只有注册后发生的写入请求,才会被触发器监听。所以如果你的需求是处理历史数据,那得另外想办法。
-
保证触发器效率很重要:目前触发器是同步触发的,也就是说数据写入过程中会等待触发器执行完成。如果你的触发器逻辑太复杂、执行太慢,会直接拖慢整个数据写入的性能。而且你自己要保证触发器内部的并发安全性,避免多线程情况下出现数据错误。
-
别注册太多触发器:触发器的信息会全量保存在ConfigNode里,而且每个DataNode都会有一份副本。如果注册的触发器太多,会占用不少存储和内存资源,还可能影响集群的整体性能。所以只注册真正需要的触发器就好。
-
注册时建议停写:注册触发器不是原子操作,过程中可能出现集群里部分节点已经注册好触发器,部分节点还没注册成功的情况。这时候如果有数据写入,就会出现有的节点触发了触发器,有的没触发,导致数据处理不一致。所以建议注册的时候先停止写入,等注册完成再恢复。
-
警惕OOM风险:触发器是作为进程内程序执行的,如果你的触发器写得不好,比如内存泄漏、一次性加载太多数据,导致内存占用过高,IoTDB没办法监控触发器的内存使用,很可能会出现OOM(内存溢出)问题,影响整个IoTDB服务。所以写触发器时一定要注意内存控制。
-
有状态触发器要做好恢复:持有有状态触发器实例的节点宕机后,集群会尝试在其他节点上恢复这个实例,恢复过程中会调用一次
restore方法。你得在这个方法里实现状态恢复的逻辑,比如把之前保存的计算结果、上下文信息加载回来,不然触发器恢复后会丢失之前的状态,影响后续计算。 -
JAR包大小有限制:触发器的JAR包不能太大,必须小于
min(config_node_ratis_log_appender_buffer_size_max, 2G)。其中config_node_ratis_log_appender_buffer_size_max是个配置项,具体含义可以看IoTDB的配置项说明。如果JAR包超了,注册的时候会失败。 -
避免类名冲突:不同JAR包里最好不要有全类名一样但功能不同的类。比如
trigger1.jar和trigger2.jar里都有org.apache.iotdb.trigger.example.AlertListener这个类,而且实现的功能不一样。那创建触发器用到这个类的时候,系统会随机加载其中一个JAR包里的类,结果就是触发器执行的逻辑不对,还可能出现各种奇怪的问题。
五、配置参数:了解关键的配置项
最后,咱们再讲讲和触发器相关的两个关键配置项,帮你更好地管理触发器:
| 配置项 | 含义 |
|---|---|
| trigger_lib_dir | 用来保存触发器JAR包的目录位置。默认是IOTDB_HOME/ext/trigger,你也可以根据自己的需求修改这个路径。不过要注意,修改后得确保所有DataNode节点的这个目录都能访问到对应的JAR包,不然触发器可能加载失败。 |
| stateful_trigger_retry_num_when_not_found | 有状态触发器触发时,如果找不到对应的触发器实例,系统会重试的次数。比如有状态触发器刚迁移完,实例还没准备好,这时候触发就会找不到实例,系统会按照这个配置的次数重试,避免因为临时问题导致触发失败。 |
这些配置项可以在IoTDB的配置文件里修改,修改后要重启相关服务才能生效。
到这里,IoTDB触发器的所有关键内容就讲完了。从基础概念到代码实现,再到管理和避坑,相信你已经对触发器有了全面的了解。实际使用时,结合自己的业务场景,多动手试试,很快就能熟练掌握触发器的用法,让它帮你更好地处理物联网时序数据的实时响应需求。
🌐 附:IoTDB的各大版本
📄 Apache IoTDB 是一款工业物联网时序数据库管理系统,采用端边云协同的轻量化架构,支持一体化的物联网时序数据收集、存储、管理与分析 ,具有多协议兼容、超高压缩比、高通量读写、工业级稳定、极简运维等特点。
| 版本 | IoTDB 二进制包 | IoTDB 源代码 | 发布说明 |
|---|---|---|---|
| 2.0.5 | - All-in-one - AINode - SHA512 - ASC |
- 源代码 - SHA512 - ASC |
release notes |
| 1.3.5 | - All-in-one - AINode - SHA512 - ASC |
- 源代码 - SHA512 - ASC |
release notes |
| 0.13.4 | - All-in-one - Grafana 连接器 - Grafana 插件 - SHA512 - ASC |
- 源代码 - SHA512 - ASC |
release notes |
✨ 去获取:https://archive.apache.org/dist/iotdb/
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 203
203 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)