【分布式系统没有银弹】,Spring Boot + MySQL读写分离,MySQL + Redis 双写一致性
【分布式系统没有银弹】,Spring Boot + MySQL读写分离,MySQL + Redis 双写一致性
- 随着业务发展和数据的快速增长,单个数据库服务器已经很难满足业务需求,这个时候就必须考虑数据库集群的方式来提升性能。 —— 《从零开始学架构》,作者:李运华。
- 高性能数据库集群方式:
- ① 读写分离,本质是将访问压力分散到集群中的多个节点,但是没有分散存储压力。
- ② 分库分表,参见文章:SpringBoot整合Sharding-jdbc分库分表及ES搜索引擎解决无分片键查询
- CAP相关文章:
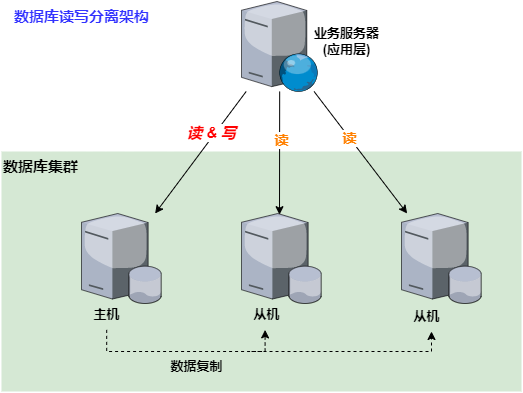
1. MySQL主从复制搭建(一主一从)
1.1 主库配置
# 1. 修改主库配置文件 /etc/my.cnf
[mysqld]
server-id=1 # 唯一ID
log-bin=mysql-bin # 启用二进制日志
binlog-format=mixed # 二进制日志格式
重启MySQL后执行:
# 2. 创建复制账号
CREATE USER 'repl'@'%' IDENTIFIED BY 'repl_password';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
# 3. 查看二进制日志坐标
SHOW MASTER STATUS;
# 记录File和Position,例如:File 'mysql-bin.000001', Position 154
1.2 从库配置
# 1. 修改从库配置文件 /etc/my.cnf
[mysqld]
server-id=2 # 必须与主库不同
relay-log=mysql-relay-bin # 中继日志
log-slave-updates=1 # 使从库也能作为其他从库的主库
重启MySQL后执行:
# 2. 配置主从连接
CHANGE MASTER TO
MASTER_HOST='主库IP',
MASTER_USER='repl',
MASTER_PASSWORD='repl_password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154;
# 3. 启动复制
START SLAVE;
# 4. 验证
SHOW SLAVE STATUS\G
# 确认Slave_IO_Running和Slave_SQL_Running都是Yes
💡 小贴士:主从复制需要确保网络通畅,主库防火墙开放3306端口,从库能访问主库的3306端口。
2. Spring Boot读写分离实现(Dynamic-Datasource)
当然,我们也可以 使用【Spring 的 AbstractRoutingDataSource】来动态路由数据源(自定义一个路由数据源,继承AbstractRoutingDataSource)。
2.1 添加Maven依赖(pom.xml)
<dependencies>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.2</version>
</dependency>
<!-- Dynamic-Datasource(核心) -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.6.1</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- 连接池(可选) -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>
</dependencies>
2.2 配置文件(application.yml)
spring:
datasource:
dynamic:
primary: master # 默认数据源
datasource:
master:
url: jdbc:mysql://主库IP:3306/db_name?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: master_password
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 10
minimum-idle: 5
slave:
url: jdbc:mysql://从库IP:3306/db_name?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: slave_password
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 15
minimum-idle: 8
strategy:
# 读写分离策略:读操作走从库,写操作走主库
# 可选:round_robin(轮询)、random(随机)等
datasource:
master: slave
2.3 代码实现
a. 定义数据源枚举
public enum DataSourceType {
MASTER, // 主库:写操作 【注意】:这里的注释其实是有问题的,具体的看下面的第3章节——【分布式架构中的一致性问题】
SLAVE // 从库:读操作
}
b. 数据源上下文管理器
public class DataSourceContextHolder {
private static final ThreadLocal<DataSourceType> CONTEXT_HOLDER = new ThreadLocal<>();
public static void setDataSourceType(DataSourceType dataSourceType) {
CONTEXT_HOLDER.set(dataSourceType);
}
public static DataSourceType getDataSourceType() {
return CONTEXT_HOLDER.get() == null ? DataSourceType.MASTER : CONTEXT_HOLDER.get();
}
public static void clearDataSourceType() {
CONTEXT_HOLDER.remove();
}
}
c. 使用AOP标注读写操作
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataSource {
DataSourceType value() default DataSourceType.MASTER;
}
d. AOP切面实现
@Aspect
@Component
public class DataSourceAspect {
@Before("@annotation(dataSource)")
public void before(JoinPoint point, DataSource dataSource) {
DataSourceType type = dataSource.value();
DataSourceContextHolder.setDataSourceType(type);
}
@After("@annotation(dataSource)")
public void after(JoinPoint point, DataSource dataSource) {
DataSourceContextHolder.clearDataSourceType();
}
}
e. 在Service层使用
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
// 写操作:默认走主库(也可以显式指定)
@DataSource(DataSourceType.MASTER)
public void createOrder(Order order) {
orderMapper.insert(order);
}
// 读操作:默认走从库
@DataSource(DataSourceType.SLAVE)
public Order getOrderById(Long id) {
return orderMapper.selectById(id);
}
}

3. 分布式架构中的一致性问题
3.1 MySQL读写分离的一致性困境
3.1.1 问题—主从复制延迟
- 在MySQL读写分离架构中,一开始我们的设想是这样的:
- 写操作 → 主库
- 读操作 → 从库
- 问题:MySQL主从数据同步存在延迟,通常几毫秒到几秒,如果有大量数据同步,延迟1分钟也是有可能的。主从复制延迟会带来的【问题】:如果业务服务(应用层)将数据写入数据库master(主库)后立刻(1秒内)进行读取,由于我们一开始的设定是 读操作访问的是slave(从库),但是现在master还没有将数据复制到slave,也就意味着,这个时候slave从库是读取不到最新数据的,从而可能会导致业务上出现问题。比如,用户刚刚注册完立即登录,应用层则可能会提示 “你还没有注册”,但是,用户刚才明明已经注册成功了。
3.1.2 方案—按业务需求强制路由
- 关键业务 【读写操作】全部指向 master主库,非关键业务 采用读写分离。由此也可以明白一个道理 —— “不要读死书!”,不要一看到 “读写分离” 就下意识的认为 “读只能走从库”。
- 比如,对于一个用户管理系统来说,注册 + 登录 的业务读写操作全部访问主库;用户的介绍、爱好、评论等业务,可以采用读写分离,因为即使用户改了自己的自我介绍,在查询时看到的却还是旧数据,这种业务影响相比较不能登录就小很多了。
- 此时的读写分离架构图如下:
// 根据业务语义决定读主库还是从库
public class ReadWriteSplittingService {
// 场景1:允许读旧数据 -> 读从库(最终一致)。比如,商品列表、文章内容、用户资料(非关键)
public Product getProductForDisplay(Long productId) {
// 商品展示页:可以接受几秒延迟
return slaveDb.query("SELECT * FROM products WHERE id = ?", productId);
}
// 场景2:必须读新数据 -> 读主库(强一致)。比如,账户余额、订单状态
public Order getOrderForPayment(Long orderId) {
// 支付确认页:必须是最新状态
return masterDb.query("SELECT * FROM orders WHERE id = ?", orderId);
}
}
3.1.3 实现建议
- 80%的读请求可以走从库:大多数展示型数据不要求强一致。
- 20%的关键读请求走主库:涉及金钱、状态变更的关键路径。
- 使用多层次缓存:Redis缓存可以缓解一致性问题。
- 监控复制延迟:当从库延迟过大时,自动降级读主库。
3.3 经典「读写一致性」问题
在分布式系统理论中,读写分离属于:
- 读写一致性(Read-After-Write Consistency):用户写入数据后,应该能立即读到刚写入的数据。
- 因果一致性(Causal Consistency):有因果关系的数据操作,应该按顺序被观察到。
3.3.1 与CAP理论的关系
- 读写分离架构本质上是一种 AP(可用性优先)设计:
- 可用性(A):读请求可以分发到多个从库,提高整体读吞吐量。
- 分区容错性(P):主从之间可以容忍网络延迟或短暂中断。
- 一致性(C):牺牲了强一致性,获得最终一致性。
3.3.2 「PACELC理论」中的典型场景
在正常情况下(无网络分区):
- 如果我们选择低延迟(L):让所有读请求走从库,获取最快的响应时间。
- 如果我们选择一致性(C):让部分读请求走主库,确保读到最新数据。
3.4 承认现实:分布式系统没有完美一致性(没有银弹)
3.4.1 核心要点
-
在微服务架构中,查询操作 得到 旧数据【是 设计使然,是权衡的结果,不是错误】。这是【PACELC理论】中 “当P不发生时,我们权衡L和C” 的体现。数据不一致本身不是问题,有问题的是业务能否接受这种不一致。
-
不用担心【得到旧数据】,这是设计的一部分。关键是要确保数据在短时间内(如几百毫秒)会达到一致,这是分布式系统中合理的设计选择。
-
读写分离确实带来了一致性问题:这是分布式系统设计的必然代价。
-
没有银弹,只有权衡:
- 要 性能(低延迟、高吞吐) → 多读从库,接受旧数据。
- 要 一致性(强一致) → 读主库,牺牲性能。
-
分布式系统中 【一致性权衡】 的 核心思想 —— 业务需求驱动设计,而非追求理论上的 “完美一致性”。 :
if (业务可以接受旧数据) { 读从库; // 如:商品展示、文章阅读 } else if (业务必须最新数据) { 读主库; // 如:余额查询、支付确认 } else { 采用折中方案; // 如:会话一致性、延迟路由 }
3.4.2 重要原则
分布式系统中的一致性,不是「有或没有」的问题,而是「在多大程度上」和「以什么代价」的问题。
在实际工程中,我们需要根据业务的 一致性需求 和 性能需求 来设计读写分离策略的。
4. Redis和MQ整合方案分析
- 项目引入
redis和mq,针对【热门数据】的查询可以从redis查询,代码层面往MySQL主库执行增删改操作后往mq发送一条消息,然后由消费者将增删改的数据同步到redis中,当然这样的方案只适合少量的增删改操作,不适合大批量的增删改。 - 引入Redis又会有新的问题:MySQL + Redis 双写一致性问题。
4.1 MySQL + Redis 双写一致性
4.1.1 双写一致性问题描述
-
我们在讨论 MySQL 和 Redis 的双写一致性问题时。首先,我们需要明确一点:在分布式系统中,由于网络延迟、分区、以及各个组件的特点,要实现跨组件的【强一致性】是非常困难的,而且往往需要牺牲性能。MySQL 和 Redis 是两个不同的数据存储系统,Redis通常用作缓存,而MySQL是持久化数据库。
-
为什么不能保证强一致性?
- 当我们同时写MySQL和Redis时,无法保证两个写操作是原子性的(即要么都成功,要么都失败)。因为这是两个独立的系统,没有分布式事务的保证。
- 即使我们采用先写MySQL,再写Redis(或者反之)的顺序,也存在中间步骤失败的可能性,导致数据不一致。
- 另外,在高并发场景下,多个线程或进程同时读写MySQL和Redis,顺序无法保证,也会导致不一致。
- 技术层面的根本原因:
// 即使最简单的双写,也无法保证【原子性】 public void updateUser(String id, User newUser) { // 步骤1:更新MySQL(成功) mysql.update(newUser); // ⚠️ 这里可能失败:网络超时、Redis宕机、程序异常 // 步骤2:更新Redis(失败) redis.update(newUser); // 失败! // 结果:MySQL是新数据,Redis是旧数据 } -
核心结论:
- MySQL和Redis之间无法实现绝对的强一致性,只能达到【最终一致性】。最终一致性 指的是:在系统【经过一段时间(这段时间内就是数据不一致的窗口期)】后,数据副本之间最终会达到一致的状态。
- 数据不一致本身不是问题,问题是业务能否接受这种不一致。
MySQL + Redis 双写一致性的3种方案:
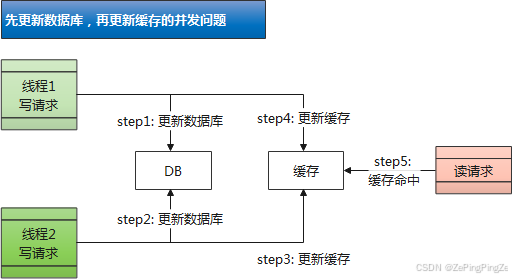
4.1.2 先更新数据库,再更新缓存
- 安全问题:
- 在并发场景下,写请求中的更新缓存可能会引发数据的不一致问题。
- 举栗子:存在两个线程的写请求。
- 线程1 的写请求更新数据库(step1);
- 线程2 的写请求更新数据库(step2);
- 由于网络抖动等原因,线程1 更新缓存(step3)可能会晚于 线程2(step4)。
- 导致的问题:最终写入数据库的值来自线程2的新值,写入缓存的结果来自线程1的旧值。也就是,缓存落后于数据库。
- 如果此时再有读请求命中缓存(step5),那读取到的就是旧值了。
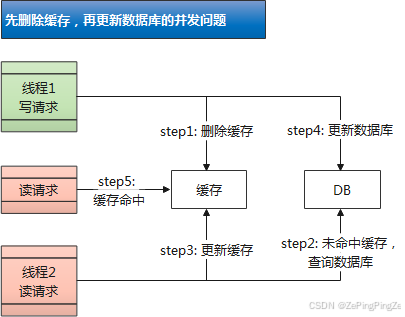
4.1.3 先删除缓存,再更新数据库
- 假设先删除缓存,再更新数据库。在并发场景下,存在如下问题:
- 线程1的写请求先删除了缓存(step1);
- 线程2的读请求由于上一步缓存删除导致缓存未命中,接着去查询数据库(step2);
- 但是通常情况下写请求比读请求慢,此时,线程1更新数据库的操作可能会晚于线程2查询数据库后更新缓存的操作(step4 晚于 step3)。
- 导致的问题:最终写入缓存的结果来自线程2中查询到的旧值,写入数据库的结果来自线程1的新值。也就是,缓存落后于数据库。
- 如果此时再有读请求命中缓存(step5),那读取到的就是旧值了。
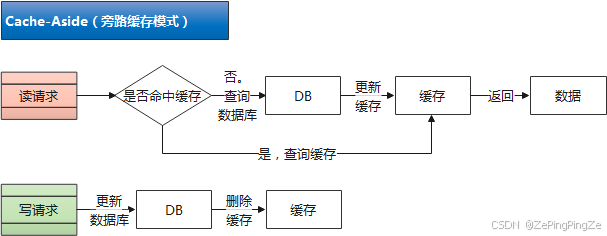
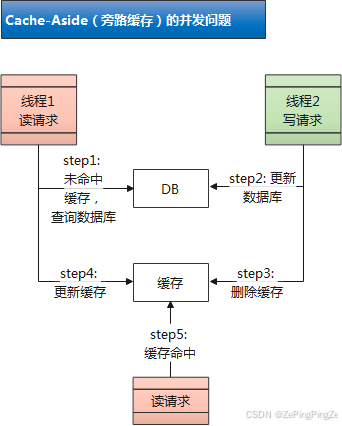
4.1.4 Cache-Aside
1. Cache-Aside(旁路缓存模式)
- 在读请求中:如果缓存命中,则直接返回缓存中的数据;如果缓存未命中,则查询数据库并将查询结果更新到缓存中,然后返回查询结果。
- 在写请求中:先更新数据库,再删除缓存。
2. Cache-Aside 的并发问题
- 线程A(读)缓存未命中,查询数据库(旧值V1)
- 线程B(写)更新数据库为新值V2,删除缓存
- 线程A 将查询到的旧值V1写入缓存
- 结果:缓存中是V1(旧值),数据库是V2(新值)
- 现实中这种情况发生概率低。出现这样的场景,需要的条件:
- ① 读写并发;
- ② 读请求缓存未命中;
- ③ 读请求查询数据库比写请求更新数据库早,同时读请求更新缓存比写请求删除缓存晚。
- 要同时满足这些条件是很少见的,出现的可能性极小。
3. 方案一:Cache-Aside + 延迟双删
public void updateData(Data newData) {
// 1. 先删除缓存
cache.delete(newData.getId());
// 2. 更新数据库
db.update(newData);
// 3. 延迟一段时间(比如500ms)再删一次
schedule(() -> {
cache.delete(newData.getId());
}, 500, TimeUnit.MILLISECONDS);
}
4. 方案二:引入MQ消息队列
// 1. 写服务
public void updateData(Data newData) {
// 1. 更新数据库(带事务)
transactionTemplate.execute(() -> {
db.update(newData);
// 2. 发送删除缓存消息
// 这里又会引入新的问题:因为 spring事务无法管理 mq发送消息成功还是失败。
// 也就是说,会出现:① 数据库提交成功,消息发送失败;② 消息发送成功,数据库事务提交失败(网络抖动、连接断开等原因)
mq.send("cache_delete", newData.getId());
});
}
// 2. 独立的缓存服务(消费者)
@Consumer(topic = "cache_delete")
public void handleCacheDelete(Long dataId) {
try {
// 删除缓存
cache.delete(dataId);
// 可选:延迟再删一次(应对并发读的脏数据)
schedule(() -> cache.delete(dataId), 300);
} catch (Exception e) {
// 失败重试(消息队列保证)
throw e;
}
}
- 优点:
- 解耦:缓存操作独立于业务服务。
- 可靠:消息队列保证至少一次投递。
- 缓冲:削峰填谷,避免缓存雪崩。
- 缺点:
- 复杂度增加。
- 延迟:消息处理需要时间。
- 可能重复删除(需要mq消息消费者服务进行幂等处理),参见文章:浅谈接口幂等性、MQ消费幂等性
4.2 Redis问题-缓存穿透、缓存击穿
public Object getData(String key) {
// 1. 检查布隆过滤器,防止缓存穿透
if (!bloomFilter.mightContain(key)) {
// 一定不存在,直接返回空,拦截!
return null;
}
// 2. 查询缓存
Object value = redis.get(key);
if (value != null) {
return value;
}
// 3. 获取分布式锁,防止缓存击穿 (可选,如果确定系统中没有热点数据,则不需要)
RLock lock = redisson.getLock("LOCK:" + key);
lock.lock();
try {
// 双重检查
value = redis.get(key);
if (value != null) {
return value;
}
// 4. 查询数据库
value = db.query(key);
if (value != null) {
// 写入缓存
redis.setex(key, ttl, value);
} else {
// 即使数据库为空,因为布隆过滤器说“可能存在”,说明是误判或数据刚被删。
// 为了防止后续同样请求再次穿透,可以缓存一个短时间的空值。
redis.setex(key, 60, "NULL"); // 缓存空对象
}
return value;
} finally {
lock.unlock();
}
}
4.3 问题与建议⚠️
-
不适合大批量操作:大批量增删改会导致MQ消息量过大,处理延迟高。建议:
- 对于大批量操作,使用批量同步(如Redis的pipeline)而不是MQ。
- 或者使用定时任务定期同步热点数据。
-
消息可靠性:需要考虑MQ消息丢失、重复消费问题:
- 使用RocketMQ/RabbitMQ的事务消息。
- 添加消息重试机制。
- MQ消费者 添加
幂等性处理,参见文章:浅谈接口幂等性、MQ消费幂等性。
-
更适合的场景:
- 用户信息、商品详情等 高频查询 数据。
- 但
不适用于订单状态、交易流水等高一致性要求的数据。
5. 总结
-
读写分离:使用Dynamic-Datasource,配置简单,社区支持好,比Sharding-JDBC更轻量
-
Redis+MQ方案:
- 适合
热点数据的缓存更新。 不适用于大批量操作。- 建议对需要缓存的数据做分类,只对高频查询的数据使用MQ同步。
- 适合
-
建议:
- 在查询方法上使用
@DataSource(DataSourceType.SLAVE)显式指定,避免默认路由错误。 - 对于复杂查询,可以考虑在MyBatis中使用
@Select指定数据源。 - 监控主从延迟,避免从库数据不一致。
- 在查询方法上使用
🌟 小技巧:在开发阶段,可以在配置中添加
dynamic.datasource.log=true,这样能打印出实际使用的数据源,方便排查问题。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)