《Linux生态下HTTP协议解析+进阶HTTPS证书:抓包、拆解与问题排查实战》
本文聚焦Linux应用层场景,跳出单纯的协议语法讲解,以“Linux系统特性”为锚点,从HTTP协议的核心定义出发,逐步拆解请求行、请求头、响应体等关键结构在Linux环境下的存储与处理逻辑,结合tcpdump抓包、Wireshark分析、nginx日志解读等实用工具,还原HTTP协议从发起请求到接收响应的完整链路,同时针对HTTP/1.1的长连接、HTTP/2的多路复用及HTTP/3的QUIC协


前引:本文聚焦Linux应用层场景,跳出单纯的协议语法讲解,以“Linux系统特性”为锚点,从HTTP协议的核心定义出发,逐步拆解请求行、请求头、响应体等关键结构在Linux环境下的存储与处理逻辑,结合tcpdump抓包、Wireshark分析、nginx日志解读等实用工具,还原HTTP协议从发起请求到接收响应的完整链路,同时针对HTTP/1.1的长连接、HTTP/2的多路复用及HTTP/3的QUIC协议在Linux中的适配差异进行对比分析,为开发者提供“原理理解+工具使用+问题排查”的全维度HTTP协议解析指南!
目录
【一】认识HTTP协议
操作系统的网络协议我们就不用想了......但是我们可以定制应用层的网络协议,就比如HTTP协议
就好比上篇文章的自定义协议“计算器”一样,只有双方遵守这个协议,才可以继续交给内核。
HTTP协议的特点:⼀个⽆连接、⽆状态的协议
即每次请求都需要建⽴新的连接, 且服务器不会保存客⼾端的状态信息
就比如一个原始的HTTP登录信息:

那你也可能看见这种登录信息:如果你看见的是不认识的符号,那肯定是被转化了,这些敏感信息不可以轻易的暴露!你可以用https://tool.chinaz.com/tools/urlencode.aspx工具进行互相转化:
https://mp.csdn.net/mp_blog/creation/editor?spm=1011.2415.3001.6217
【二】IP 端口与HTTP协议
以百度访问链接为例:https://bama.baidu.com/
前面我们学过,只要知道目标端口和IP就可以访问对方服务器,那么IP和端口与上面这种访问链接是什么关系?IP和端口其实是被封装在这种链接里面的,这也更加的人性化,它需要面向市场。也就是说,你可以通过IP+端口访问百度的服务器,也可以通过www.baidu.com访问。后者内置前者
【三】HTTP协议请求与响应格式
(1)HTTP报文结构
如下图所示的报文是对方客户端发送的完整报文,下面我们先看看结构再尝试捕获看看:
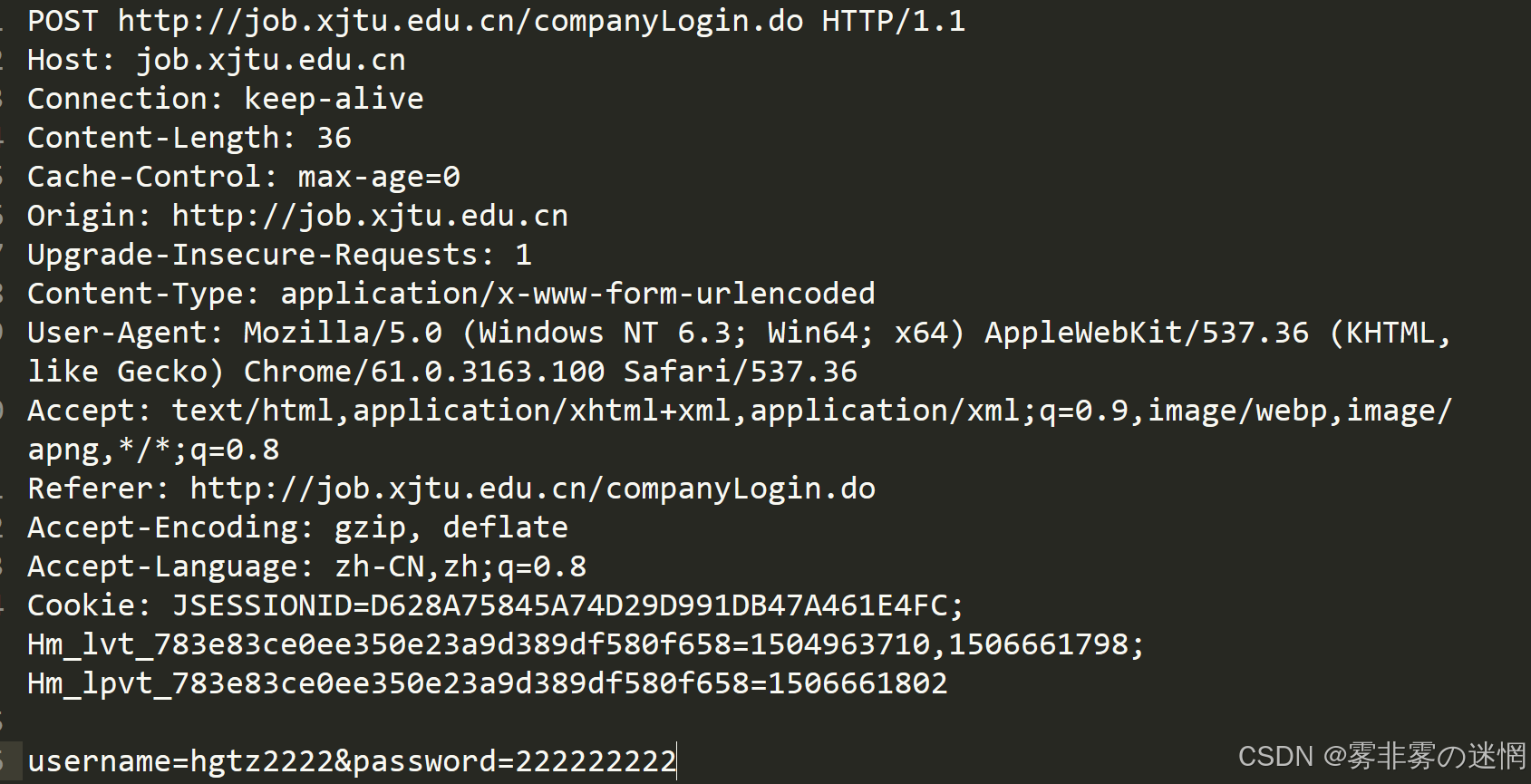
如图:HTTP报文请求结构图
第一部分是请求行:包含请求方法、URI 和 HTTP 版本,用空格分隔,最后以换行符结束
(对方的客户端地址、设备、HTTP版本、IP端口.....)
第二部分是请求报头:由多个 Key:Value 键值对组成,每个键值对占一行,以换行符分隔
(K-V类的各种属性信息)
第三部分是空行:用一个换行符表示,用于分隔请求报头和请求正文
(用于将请求报头和请求正文区分)
第四部分是请求正文:存放实际要发送的数据,比如表单提交的参数等
(客户端发送的正文,比如:“你吃了吗”)
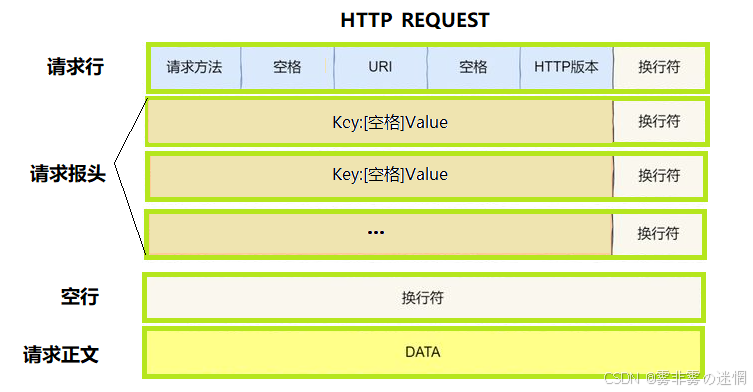
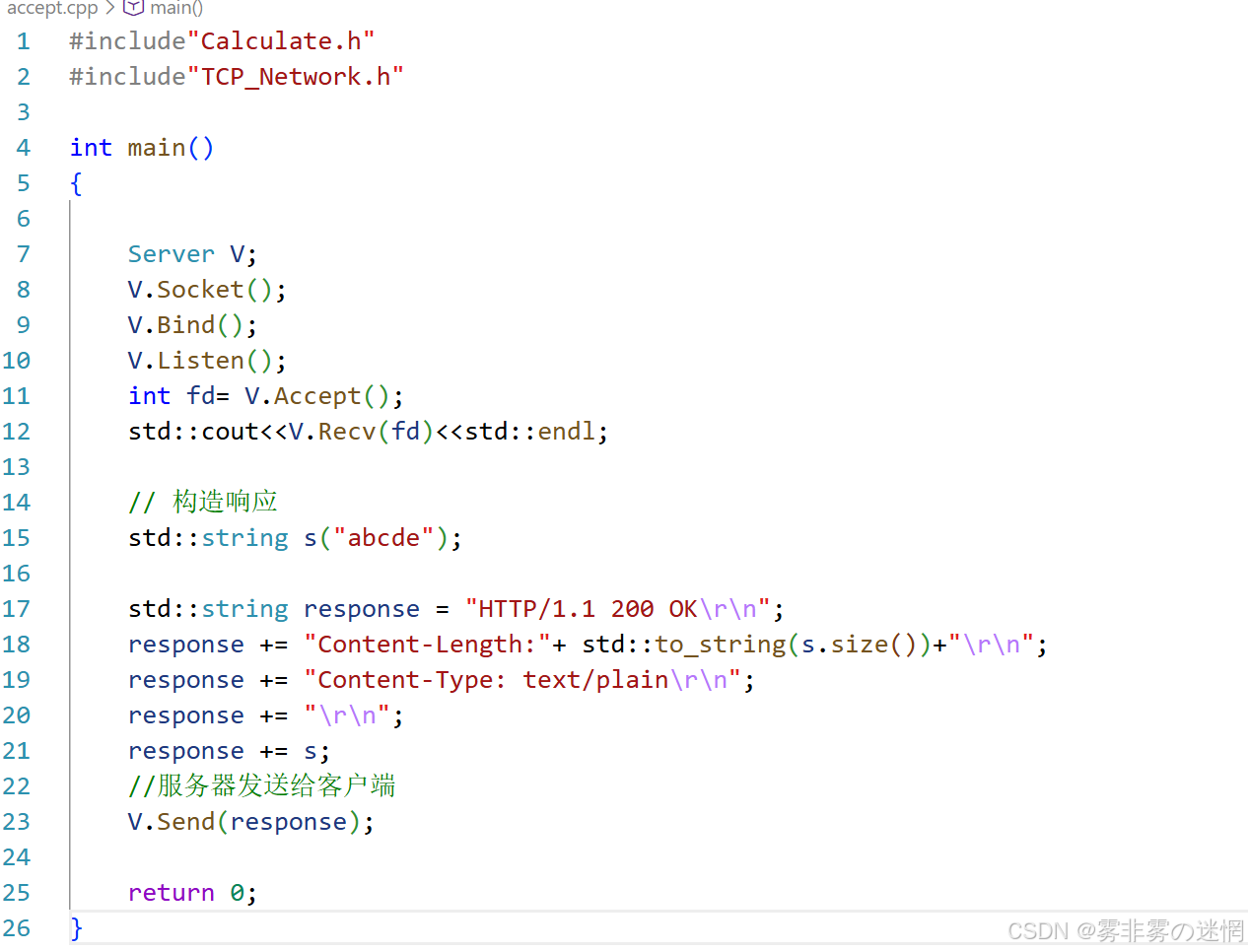
(2)HTTP报文捕获实现
可以明显的看到,HTTP报文结构都是"\r\n"即换行符结尾,所以我们可以用该符号来进行查找切割
获取思路:用find()每次找到第一个\r\n,这样就确定了第一层,随即用substr()截取,再用erase()移除第一层,开始第二轮查找,依次循环,就获取了每层的报文,拼接即可捕获
注意:由于TCP是流式传输,数据可能会分批,所以需要根据 \r\n 循环读取客户端内容
//报文捕获
void HTTP_Capture(int token)
{
//存储接收的原始数据
std::string media;
//存储截取的完整报文
std::string message;
//存储数组
char buffer[max_buffer] = {0};
// 循环读取报文
while (true)
{
ssize_t t = recv(token, buffer, sizeof(buffer)-1, 0);
if (t > 0)
{
//追加实际接收的数据到media
media.append(buffer, t);
//清空缓冲区
memset(buffer, 0, sizeof(buffer));
// 处理media里的所有\r\n
while (true)
{
//找到每层
size_t sz = media.find("\r\n");
if (sz == std::string::npos)
{
//说明没有读取完
break;
}
//截取包含\r\n的行,追加到message
message += media.substr(0, sz + 2);
// 移除media里已处理的部分
media.erase(0, sz + 2);
}
}
else if (t == 0)
{
break; // 对方关闭连接
}
else
{
std::cout << "读取错误,退出捕获" << std::endl;=
break;
}
}
// 打印最终捕获的完整报文
std::cout << "捕获报文:" << std::endl;
std::cout << message << std::endl;
}例如:用浏览器访问IP端口,再退出,即可查看(因为 recv 是阻塞的等待)
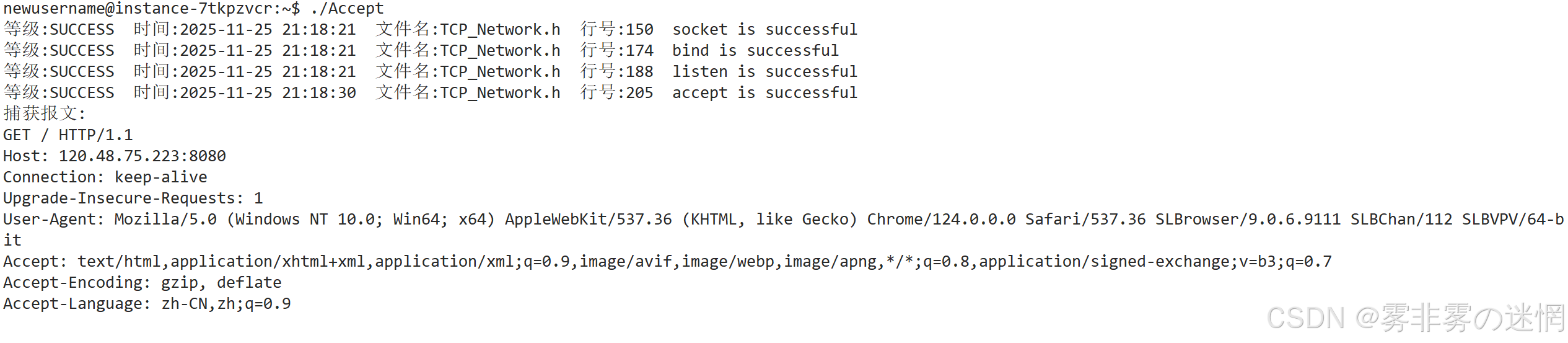
【四】状态码
状态码的位置:状态码在服务端的响应报文里,即服务器发给客户端的内容中
什么是状态码:状态码你可以理解为服务端告诉客户端本次访问的情况
如何查看状态码?
因为我们需要用服务端伪造信息结构发给客户端,因为服务端返回的响应不符合 HTTP 协议规范导致不是有效的HTTP响应,可以将以下内容发送给客户端,用curl获取响应:curl -i http://IP:端口
// 构造响应
std::string response = "HTTP/1.1 200 OK\r\n";
response += "Content-Length: 12\r\n";
response += "Content-Type: text/plain\r\n";
response += "\r\n";
response += "Request Received";
// 发送响应到客户端
send(token, response.c_str(), response.size(), 0);如图:200就是状态码,表示服务端返回给客户端内容,其它的状态码大家可以自由查看!
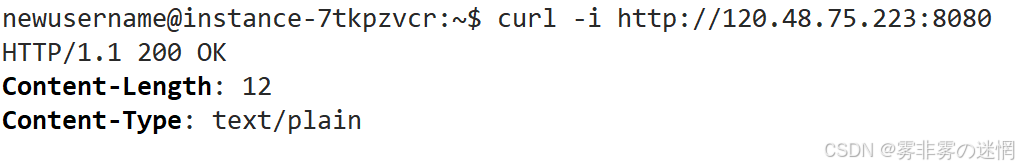
(1)重定向
HTTP状态码重定向有两种:301永久重定向和302临时重定向,下面我们分开理解:
301-永久重定向:
理解:客户端这次访问的地址已经永久更换到其它地方
动作:在这种情况下,服务器会在响应中添加⼀个Location头部,⽤于指定资源的新位置。这个 Location 头部包含了新的URL地址,浏览器会⾃动重定向到该地址,例如:

302-临时重定向:
理解:客户端这次访问的地址已经临时更换到其它地方
动作:服务器也会在响应中添加⼀个Location头部来指定资源的新位置。浏览器会暂时使⽤新的 URL进⾏后续的请求,但不会缓存这个重定向,依然先访问旧地址再访问新地址,例如:

(2)带路径访问服务器资源
首先我们借助AI完成一个简单的HTML文件:当通过浏览器访问时将页面响应出来,例如:
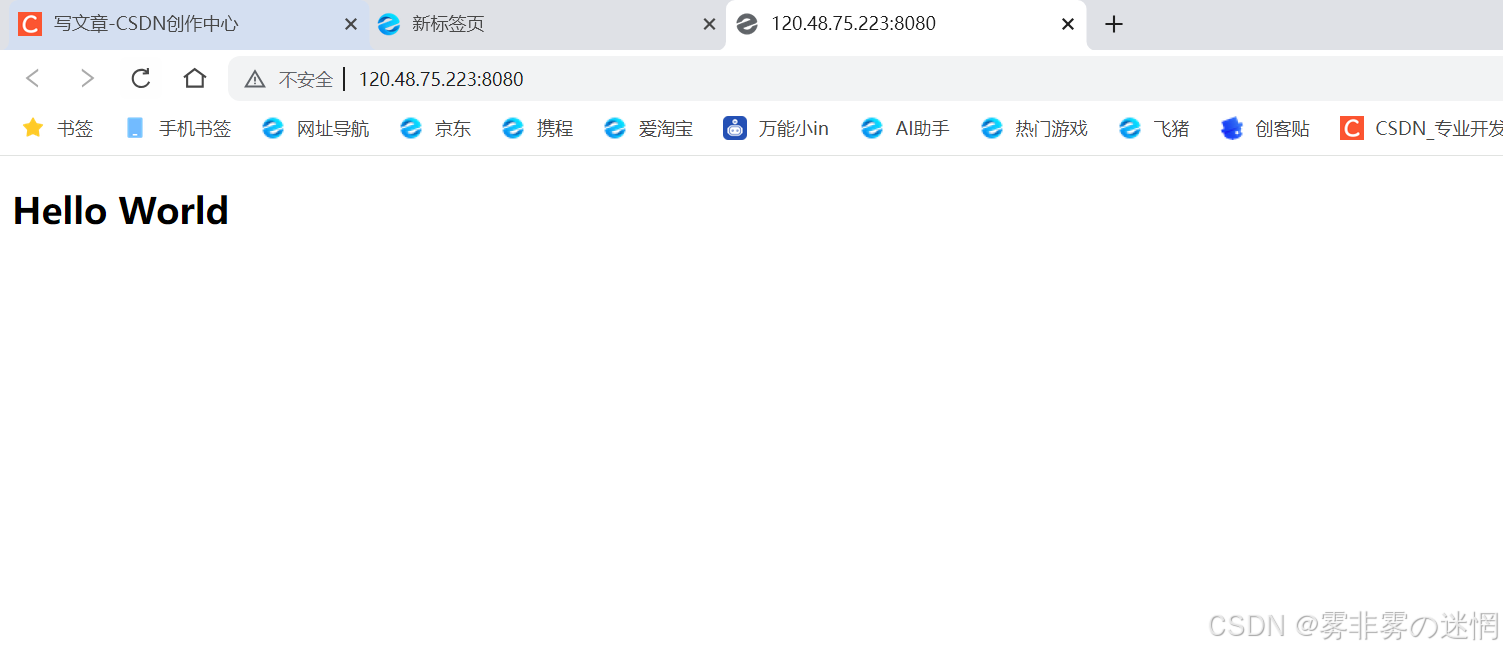
现在我们来理解带路径访问服务器资源,比如:http://120.48.75.223:8080/路径
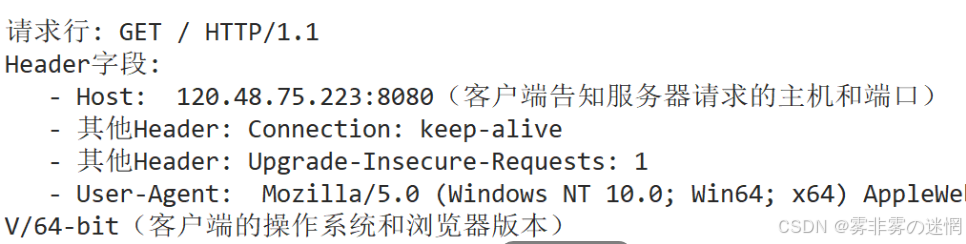
就比如上面的:GET / HTTP/1.1,其中的 / 就代表根目录路径
再比如:GET /about HTTP/1.1,其中的 /abaout 就代表根目录下的...文件
那么具体的思路是怎么样的呢?
我们知道这个路径肯定是客户端带给服务端的,就比如:http://120.48.75.223:8080/路径
路径解析思路:这个路径是在报文里面的,所以服务端需要先捕获报文,再从报文中提取这 个路径,再在HTML响应内容中替换对应路径下的内容即可
具体实现思路:通过HTTP_Calculate()返回响应的报文,再用find查找连续两个空格的索引,再用substr截取对应的路径内容,就提取到了路径,最后再通过打开HTML文件就锁定了路径资源

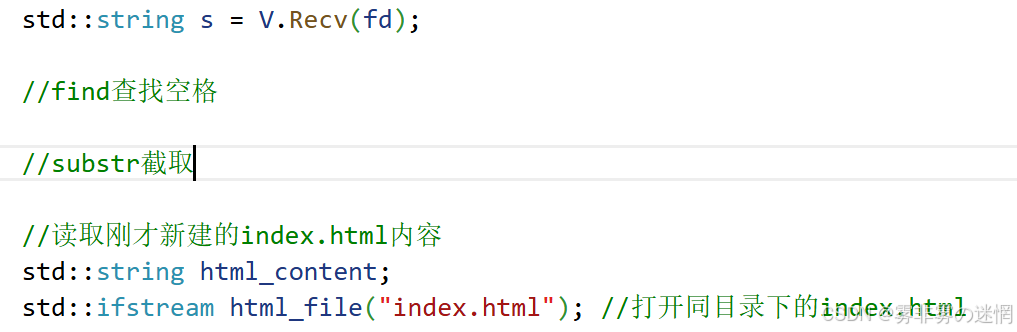
【五】HTTP报文结构
报文通常具有如下结构,我们先认识,再来讲解:

现在我们通过浏览器访问在xshell已经搭建的服务器,我们先设置发送的内容,再查看报文:
我们借助AI快速调整一下报文解析结构,打印服务器接收的报文如下:

【六】HTTPS协议
简单直达重点:HTTPS就是在HTTP中做了一个数据加密层,如图原理:数据在传输中需要被加密
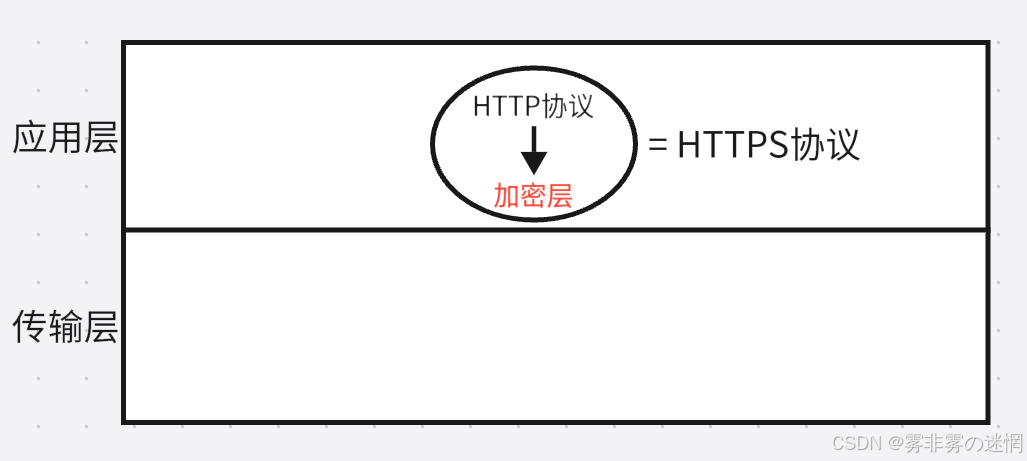
所以我们只需要搞懂“加密层”,那HTTPS协议就自然明白了!
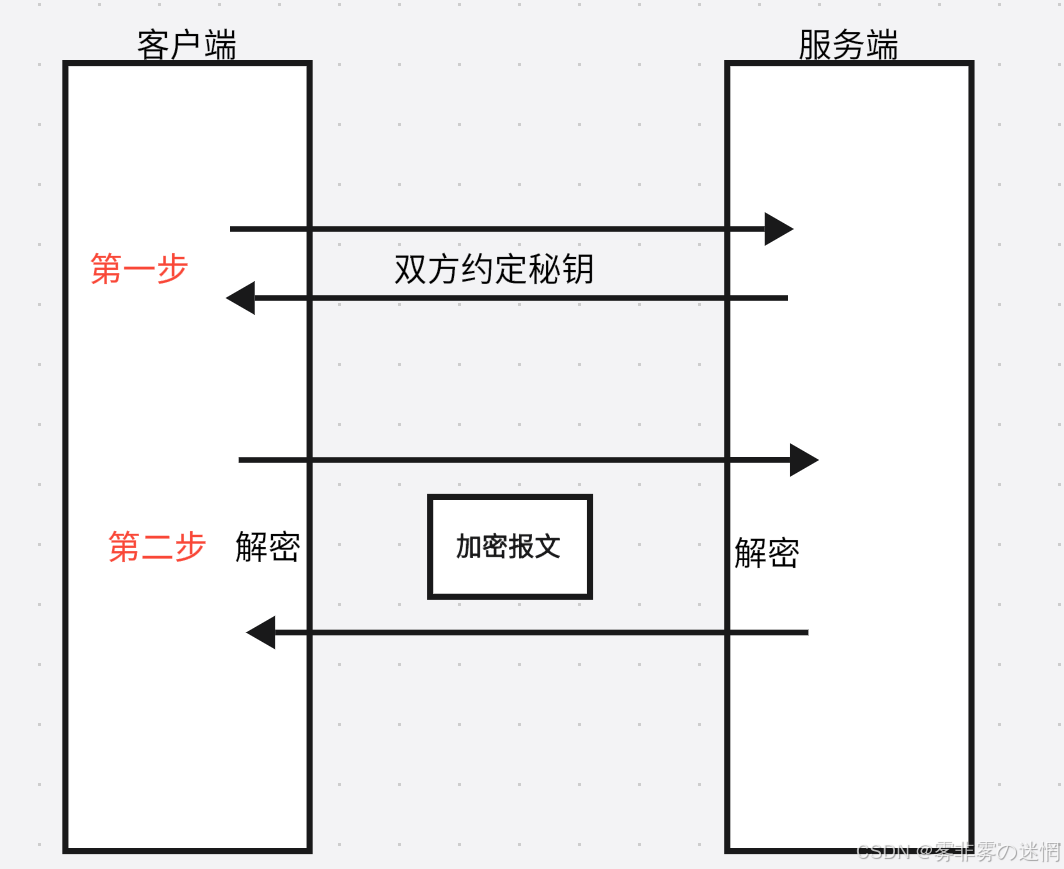
(1)对称加密
含义:同⼀个密钥可以同时⽤作信息的加密和解密
传输方式:双方共同商议一个秘钥,后面将报文先经过配套的加密处理,再用协商的秘钥进行解密
传输特点:(1)效率高(2)过程简单(3)中间秘钥协商过程不能被第三方知道
(2)非对称加密
非对称加密有单方的也有双方的,无非就是几套秘钥(公钥+私钥)的区别,本质都是以下内容:
含义:双方各自含有一套秘钥(公钥、私钥),满足公钥加密,需要用配套的私钥进行解密
传输方式:双方各自交换公钥,后面将报文先经过配套的公钥处理,再用各自的私钥进行解密
传输特点:(1)效率低(2)过程复杂(3)更安全(4)中间秘钥协商过程不能被第三方知道
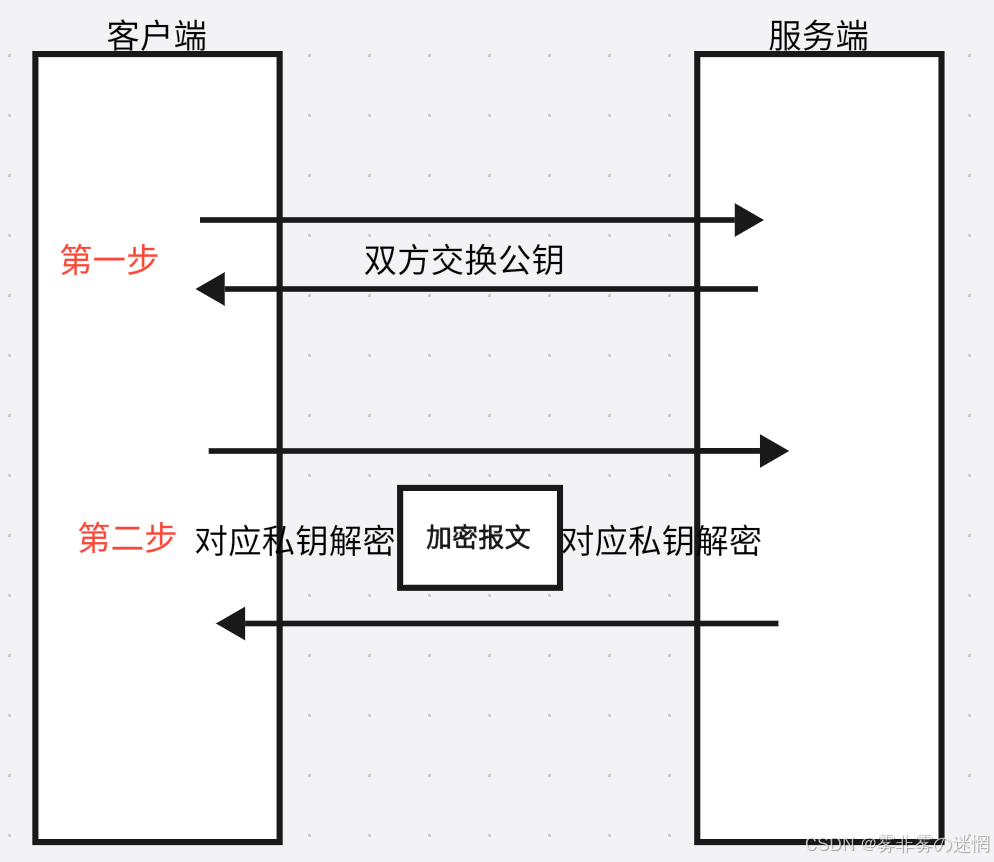
(3)对称+非对称加密
含义:只有服务器有一套钥匙(公钥+私钥),客户端拿到之后再给服务器新的对称秘钥通信
传输方式:服务器持一套秘钥,将公钥给客户端,客户端生成一个对称秘钥,再用刚才拿到的公 钥对对称秘钥加密传给服务端,后面双方用客户端的对称秘钥通信
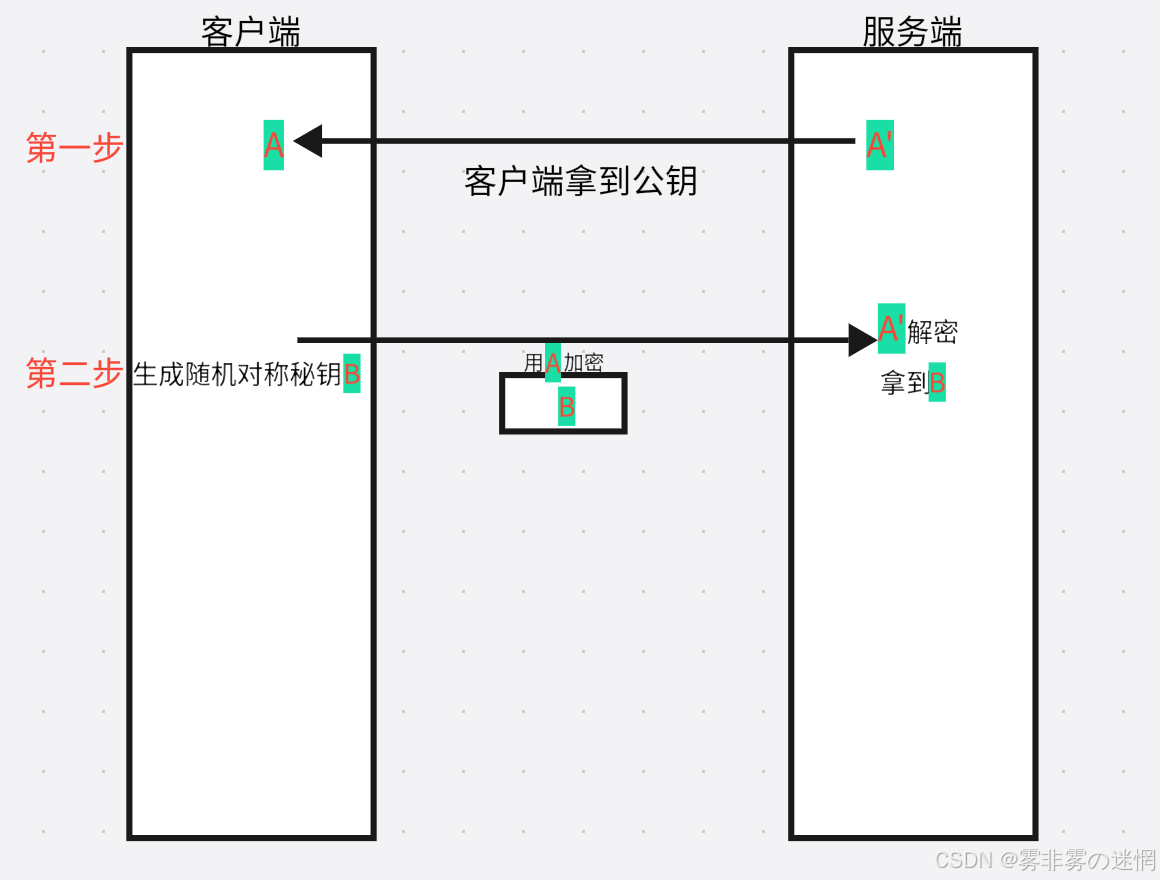
传输特点:(1)效率低(2)过程复杂(3)更安全(4)中间人如果把A开始直接替换就破解 了,所以关键是这个A不能被改,而加密的内容只能由服务端私钥解密
(4)终极方案:CA证书+对称+非对称
该方案主要是CA证书的申请过程,对称+非对称我们在上面已经讲清楚流程了:
(1)CA证书获取
服务端在使用HTTPS前需要向CA机构申请一份“身份证”——CA证书,下面是易懂的获取流程:
(1)先准备申请材料:(申请人、公司地址这些基本身份信息)和自己的公钥(私钥自己保管)
(2)将申请材料交给CA机构进行审核
(3)审核期间,CA机构会给该份材料形成数字签名:
CA机构对证书数据进行哈希散列: ![]() ,作用是防止数据被更改
,作用是防止数据被更改
CA机构再用自己的私钥进行加密,形成数字签名(这个CA秘钥相当于CA盖章,无法模仿)
(4)再将审核通过的证书交给对应服务端,作为对应的“身份证”
(2)CV证书使用
服务端和客户端建立连接的时候,客户端拿到服务端的CA证书,在系统中拿到该证书的公钥对服务端发来的证书进行解密,通过相同的哈希运算得到散列值hash1,对比系统中的证书散列值hash2,如果二者相等,说明服务端是可信的,可以进行下一步通信内容
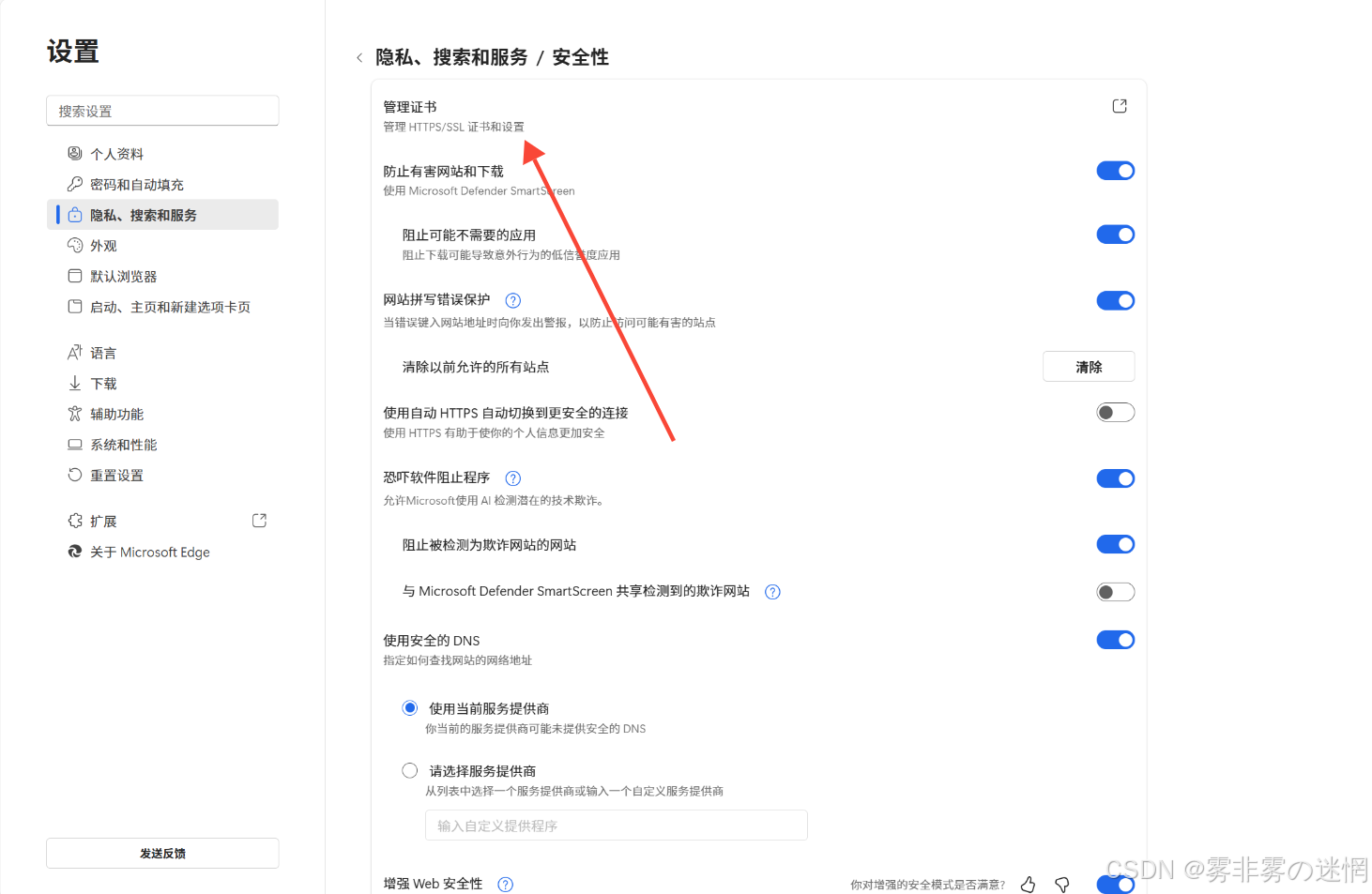
可以在浏览器的设置->安全中查看该浏览器信任的证书:
(3)逻辑梳理
(1)证书中的公钥也就是服务端的,需要服务端的私钥才能解析数据
(2)证书中的CA的私钥相当于是“盖章”,第三方无法在第二份证书中用CA的秘钥“盖章”
(3)通过这样保证服务器给客户端的公钥是合格的,客户端才能继续用该公钥加密对称秘钥给服务端.服务端拿到之后,再用私钥进行解析,拿到客户端给的对称秘钥,双方再用对称秘钥进行通信
究其作用:保证客户端拿到的公钥只能是目标服务器给的
(4)涉及问题
中间人可能篡改证书吗?
答案是不可能的,因为证书是被CA秘钥盖了章的,你如果改了,那就会和官方的证书中的散列值对不上,只有同时具备两个条件证书才是可信的:(1)散列值一样(2)有CA的盖章,即CA秘钥
中间人掉包整个证书?
答案是不可能的,因为中间人没有CA的私钥,无法对证书进行“盖章”


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 40
40 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)