深入Java 8 Stream:高效分类占比统计实战技巧
本文将通过具体的实战案例进行详细讲解。首先,我们会介绍如何使用 Stream 对数据进行分组,然后通过收集器对分组后的数据进行统计,最后计算出每种类型的占比。
目录
前言
在当今数据驱动的软件开发时代,数据的快速处理与分析能力是提升应用性能和用户体验的关键。Java 8 引入的 Stream API 为开发者提供了一种强大且优雅的方式来处理集合数据,它不仅简化了代码,还通过内置的并行处理能力大幅提升了性能。在众多应用场景中,分类占比统计是数据处理中一个常见的需求。无论是对用户行为数据进行分析,还是对业务数据进行分类汇总,快速准确地统计各类数据的占比都能为决策提供有力支持。本文将深入探讨如何利用 Java 8 Stream API 实现高效、简洁且易于维护的分类占比统计,帮助开发者在实战中快速掌握这一实用技巧。
在实际开发中,我们经常遇到需要对集合中的数据按照某种类型进行分类统计的场景。例如,在电商系统中,可能需要统计不同品类商品的销售占比;在用户管理系统中,可能需要统计不同地区用户的注册占比。传统的实现方式往往是通过循环遍历集合,使用多个变量来分别统计每种类型的数量,然后再计算占比。这种做法不仅代码冗长,而且在处理大规模数据时效率低下,容易出错。Java 8 Stream API 提供了一种全新的解决方案,它允许我们以声明式的方式处理数据,通过一系列的中间操作和终端操作,可以轻松地实现分类统计。Stream 的 `groupingBy` 方法可以方便地对数据进行分组,而 `collectors` 提供的各种收集器则可以方便地对分组后的数据进行进一步的统计和处理。通过合理使用这些特性,我们可以写出既简洁又高效的代码,快速完成分类占比统计的任务。
为了更好地理解如何使用 Java 8 Stream 实现分类占比统计,本文将通过具体的实战案例进行详细讲解。首先,我们会介绍如何使用 Stream 对数据进行分组,然后通过收集器对分组后的数据进行统计,最后计算出每种类型的占比。在实战案例中,我们将使用一个模拟的电商销售数据集,展示如何统计不同品类商品的销售占比。通过这个案例,读者将能够清晰地看到 Stream API 在处理分类占比统计问题时的优势,以及如何在实际项目中应用这些技巧。此外,我们还会探讨一些优化技巧,如如何利用并行 Stream 进一步提升性能,以及如何处理可能出现的异常情况,确保代码的健壮性。通过本文的介绍,相信读者能够掌握 Java 8 Stream 在分类占比统计方面的实战应用,将其应用到自己的项目中,提高数据处理的效率和质量。
一、需求描述
本节将重点对需求场景和排序需求进行介绍。
1、场景描述
在城市规划与资源管理中,我们面临着一个重要的数据分析需求:对不同机构设施类型的分布情况进行分类统计与分析。具体而言,系统中存储了大量关于各类机构设施的记录,包括设施类型、地理位置、服务范围等关键信息。管理部门希望能够快速了解各机构设施类型在城市中的占比情况,以便优化资源分配和城市规划布局。例如,通过统计可以发现哪些设施类型在城市中分布广泛,哪些设施类型相对稀缺,从而为政策制定和资源投入提供数据支持。随着城市的发展,数据量不断增加,传统的统计方式已难以满足快速响应的需求,因此需要一种高效、简洁且易于扩展的解决方案来应对这一挑战。
2、排序要求
在完成机构设施类型的分类占比统计后,为了更好地呈现数据并支持决策,还需要对统计结果进行排序。具体来说,管理部门希望按照机构设施类型占比的高低进行排序,以便快速识别出在城市中分布最广泛和最稀缺的设施类型。此外,还可能需要根据机构设施类型名称进行字母顺序排序,以方便在报告中进行展示。在排序过程中,需要确保排序的准确性和稳定性,避免因排序错误导致的决策失误。同时,考虑到数据量可能较大,排序算法的效率也至关重要。因此,我们需要在实现分类占比统计的基础上,进一步优化代码,使其能够支持高效的排序操作,确保整个数据处理流程的流畅性和高效性。
二、Java 1.8 实现
本节将详细介绍在Java1.8中如何使用Stream来进行机构设施的分类占比统计以及排序。通过本节大家能快速掌握如何使用Java来实现这个需求。
1、分类对象实现
为了模拟对分类对象的描述和占比统计,我们需要定义一个分类占比统计对象,核心代码如下,这个类中type用于对分类进行描述,而percentage则用于存储占比比例:
package org.yelang.pcwater.riskevaluation;
/**
* - 自定义类用于存储类型和占比
* @author 夜郎king
*/
public class TypePercentage {
private String type;
private double percentage;
public TypePercentage(String type, double percentage) {
this.type = type;
this.percentage = percentage;
}
public String getType() {
return type;
}
public double getPercentage() {
return percentage;
}
@Override
public String toString() {
return String.format("TypePercentage{type='%s', percentage=%.1f%%}", type, percentage * 100);
}
}2、Stream进行分组排序
通常在进行数据统计时,我们首先需要生成不同的机构设施类型,然后将这些数据添加到集合中,然后将集合作为入参传入方法中进行处理。因此我们定义一个方法首先来实现Stream的方式进行分布,核心代码如下:
/**
* 获取排序后的类型占比列表
*
* @param dataList 数据列表
* @return 按占比降序排序的类型占比列表
*/
public static List<TypePercentage> getSortedTypePercentages(List<Map<String, Object>> dataList) {
if (dataList == null || dataList.isEmpty()) {
return new ArrayList<>();
}
// 统计每个 type 出现的次数
Map<String, Long> typeCount = dataList.stream()
.filter(map -> map.containsKey("type") && map.get("type") != null)
.collect(Collectors.groupingBy(map -> {
// 将 Object 类型的 type 转换为 String
Object typeObj = map.get("type");
if (typeObj instanceof String) {
return (String) typeObj;
} else {
// 如果不是 String 类型,使用 toString() 方法转换
return typeObj.toString();
}
}, Collectors.counting()));
// 计算总数量
long total = typeCount.values().stream().mapToLong(Long::longValue).sum();
// 计算占比并创建对象,按占比降序排序
return typeCount.entrySet().stream().map(entry -> {
double percentage = (double) entry.getValue() / total;
return new TypePercentage(entry.getKey(), percentage);
}).sorted((tp1, tp2) -> Double.compare(tp2.getPercentage(), tp1.getPercentage())) // 降序排序
.collect(Collectors.toList());
}3、实例调用
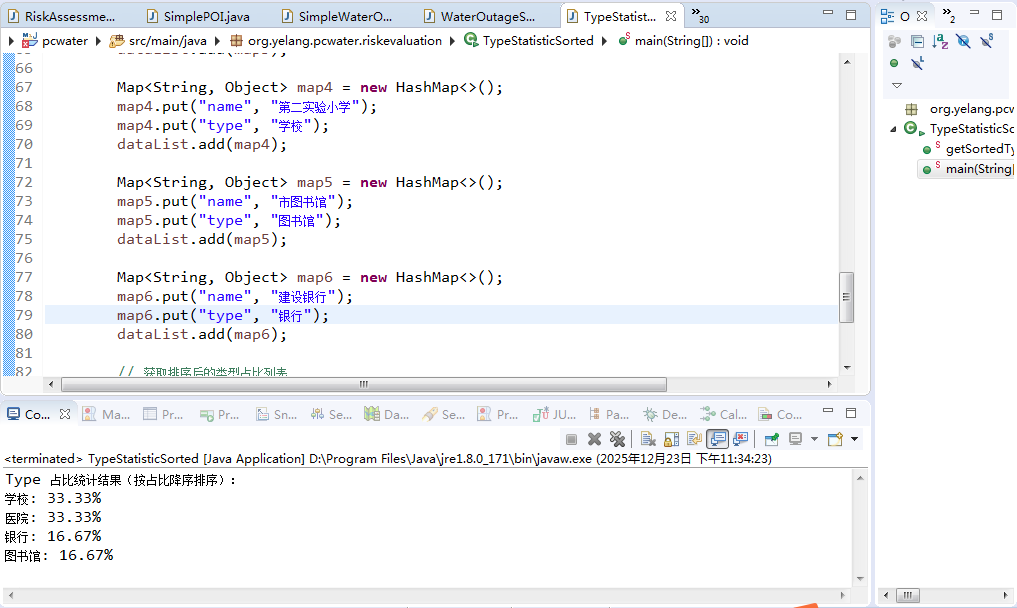
在准备调用方法之前,首先我们先来准备这些模拟的机构信息,模拟代码如下:
// 原始数据 - JDK 1.8 创建方式
List<Map<String, Object>> dataList = new ArrayList<>();
Map<String, Object> map1 = new HashMap<>();
map1.put("name", "市人民医院");
map1.put("type", "医院");
dataList.add(map1);
Map<String, Object> map2 = new HashMap<>();
map2.put("name", "幸福小学");
map2.put("type", "学校");
dataList.add(map2);
Map<String, Object> map3 = new HashMap<>();
map3.put("name", "市中心医院");
map3.put("type", "医院");
dataList.add(map3);
Map<String, Object> map4 = new HashMap<>();
map4.put("name", "第二实验小学");
map4.put("type", "学校");
dataList.add(map4);
Map<String, Object> map5 = new HashMap<>();
map5.put("name", "市图书馆");
map5.put("type", "图书馆");
dataList.add(map5);
Map<String, Object> map6 = new HashMap<>();
map6.put("name", "建设银行");
map6.put("type", "银行");
dataList.add(map6);然后调用前面的Stream分组排序方法,最后对返回的结果进行输出展示,调用代码如下:
// 获取排序后的类型占比列表
List<TypePercentage> result = getSortedTypePercentages(dataList);
// 输出结果
System.out.println("Type 占比统计结果(按占比降序排序):");
result.forEach(typePercentage -> {
System.out.printf("%s: %.2f%%\n", typePercentage.getType(), typePercentage.getPercentage() * 100);
});最后来看一下最终的输出结果:
Type 占比统计结果(按占比降序排序):
学校: 33.33%
医院: 33.33%
银行: 16.67%
图书馆: 16.67%通过以上的代码就可以实现按照分类来进行占比统计及排序,在一些统计业务中就可以进行灵活的统计实现。完整代码如下:
package org.yelang.pcwater.riskevaluation;
import java.util.*;
import java.util.stream.Collectors;
/**
* - 影响人群分布统计
* @author 夜郎king
*
*/
public class TypeStatisticSorted {
/**
* 获取排序后的类型占比列表
*
* @param dataList 数据列表
* @return 按占比降序排序的类型占比列表
*/
public static List<TypePercentage> getSortedTypePercentages(List<Map<String, Object>> dataList) {
if (dataList == null || dataList.isEmpty()) {
return new ArrayList<>();
}
// 统计每个 type 出现的次数
Map<String, Long> typeCount = dataList.stream()
.filter(map -> map.containsKey("type") && map.get("type") != null)
.collect(Collectors.groupingBy(map -> {
// 将 Object 类型的 type 转换为 String
Object typeObj = map.get("type");
if (typeObj instanceof String) {
return (String) typeObj;
} else {
// 如果不是 String 类型,使用 toString() 方法转换
return typeObj.toString();
}
}, Collectors.counting()));
// 计算总数量
long total = typeCount.values().stream().mapToLong(Long::longValue).sum();
// 计算占比并创建对象,按占比降序排序
return typeCount.entrySet().stream().map(entry -> {
double percentage = (double) entry.getValue() / total;
return new TypePercentage(entry.getKey(), percentage);
}).sorted((tp1, tp2) -> Double.compare(tp2.getPercentage(), tp1.getPercentage())) // 降序排序
.collect(Collectors.toList());
}
public static void main(String[] args) {
// 原始数据 - JDK 1.8 创建方式
List<Map<String, Object>> dataList = new ArrayList<>();
Map<String, Object> map1 = new HashMap<>();
map1.put("name", "市人民医院");
map1.put("type", "医院");
dataList.add(map1);
Map<String, Object> map2 = new HashMap<>();
map2.put("name", "幸福小学");
map2.put("type", "学校");
dataList.add(map2);
Map<String, Object> map3 = new HashMap<>();
map3.put("name", "市中心医院");
map3.put("type", "医院");
dataList.add(map3);
Map<String, Object> map4 = new HashMap<>();
map4.put("name", "第二实验小学");
map4.put("type", "学校");
dataList.add(map4);
Map<String, Object> map5 = new HashMap<>();
map5.put("name", "市图书馆");
map5.put("type", "图书馆");
dataList.add(map5);
Map<String, Object> map6 = new HashMap<>();
map6.put("name", "建设银行");
map6.put("type", "银行");
dataList.add(map6);
// 获取排序后的类型占比列表
List<TypePercentage> result = getSortedTypePercentages(dataList);
// 输出结果
System.out.println("Type 占比统计结果(按占比降序排序):");
result.forEach(typePercentage -> {
System.out.printf("%s: %.2f%%\n", typePercentage.getType(), typePercentage.getPercentage() * 100);
});
}
}三、总结
以上就是本文的主要内容,本文将通过具体的实战案例进行详细讲解。首先,我们会介绍如何使用 Stream 对数据进行分组,然后通过收集器对分组后的数据进行统计,最后计算出每种类型的占比。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 50
50 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)