实时音频通话过程中AI降噪的实现(windows/Android)
本文探讨了实时音频通话中3A算法(AEC、ANS、AGC)的重要性,并针对WebRTC原生3A算法在特定场景下的不足,提出了基于开源项目DFSMN-ANS和RNNoise的优化方案。作者详细介绍了将这两个项目集成到音视频SDK的过程,包括算法移植、推理框架适配(支持ONNX、NCNN、RKNN)以及灵活的接口设计。通过性能测试显示,优化后的方案在啸叫抑制和噪声消除方面表现优异,尤其在处理突发性噪声
一:背景
我们知道在实时音频通话的过程中语音的3A(AEC,ANS,AGC)极其重要,其中
AEC(声学回声消除)用于消除由扬声器播放的声音被麦克风再次拾取而产生的回声;ANS(自动噪声抑制)用于抑制背景噪声(如风扇声、键盘敲击声、街道噪音等),保留人声;AGC(自动增益控制)用于自动调整麦克风输入信号的音量,使其保持在一个合适的动态范围内。正是以上3A的共同作用,使得我们的实时语音通话的体验有了大幅度的提升。
如果你所在的公司没有一定的算法开发能力的话,几乎不可能重头开发出一套满足商业落地的3A算法SDK,不过不用担心,自从2011年google开源了WebRTC项目之后,其内部的GIPS引擎也顺便开源了,而GIPS引擎中有一个重要的组成部分语音的3A处理,这可是满足商业落地的,于是国内很多厂商基于这个3A处理模块,做了集成(没算法开发能力,比如一般中小规模公司),优化(有算法能力,比如大厂),大幅度改善了实时音频通话产品的体验。
但是随着技术的发展以及人们要求的提高,大家发现WebRTC中原生的语音3A在某些情况下效果不是很好,比如AEC过程中,double talk Case下的效果不理想,虽然后来的AEC升级版AEC3有优化,本人尝试使用过,效果还是不理想(可能是本人对AEC3算法参数那块没有理解得像对AEC那么透彻,导致参数设置有问题,等有时间继续投入看看,至少大量资料显示AEC3和AEC相比,double talk下的通话效果是有很大的提升的);再比如在ANS过程中,WebRTC中自带的噪声抑制对平稳噪声(如风扇声、空调声等)处理的比较好,对对于突发性、非平稳噪声(如键盘敲击、关门声、狗叫、婴儿哭声等),抑制能力较弱,容易残留噪声或误伤语音,而且对于两台通话的设备离得比较近的情况下产生的啸叫也抑制不了。
我们算法开发能力有限,但是工程能力足够用,于是也采用了WebRTC中自带的3A方案,正如上面所描述的缺陷,我们生产的硬件终端(android/Openharmony+rk芯片)在部署到现场的时候就出现了噪声消除效果不好,有些时候还有啸叫。噪声消除效果不好是因为有一台终端是放在护士站这样的场景下的,护士站周围的突发性,非平稳噪声特别多,另外离护士站比较近的一个病房里面也有一台终端,当它和护士站的终端通话的时候,尤其病房门打开的时候,会很容易产生啸叫。为了解决刚刚提到的两个问题(double talk不在其中),于是就着手调研测试评估大量开源技术方案,最后发现能够同时满足实时性和好效果的包含DFSMN-ANS和RNNoise两个开源项目,接下来我就和大家分享一下如何把这两个开源项目集成进我们自己的音视频SDK中的。
二:移植&开发AI-ANS sdk
2.1:dfsmn-ans的移植
首先在windows平台上面把python/pytorch的框架移植成visual studio c++/onnx框架,通过这一步可以先保证自己的c++/onnx的代码的正确性,如果有问题在visual studio里面调试查找问题也很方便(具体就是反复验证c++/onnx框架下和原生python/pytorch框架下的结果,直到结果一致),通过阅读python代码发现dfsmn-ans的工作流程简单明了,如下图:
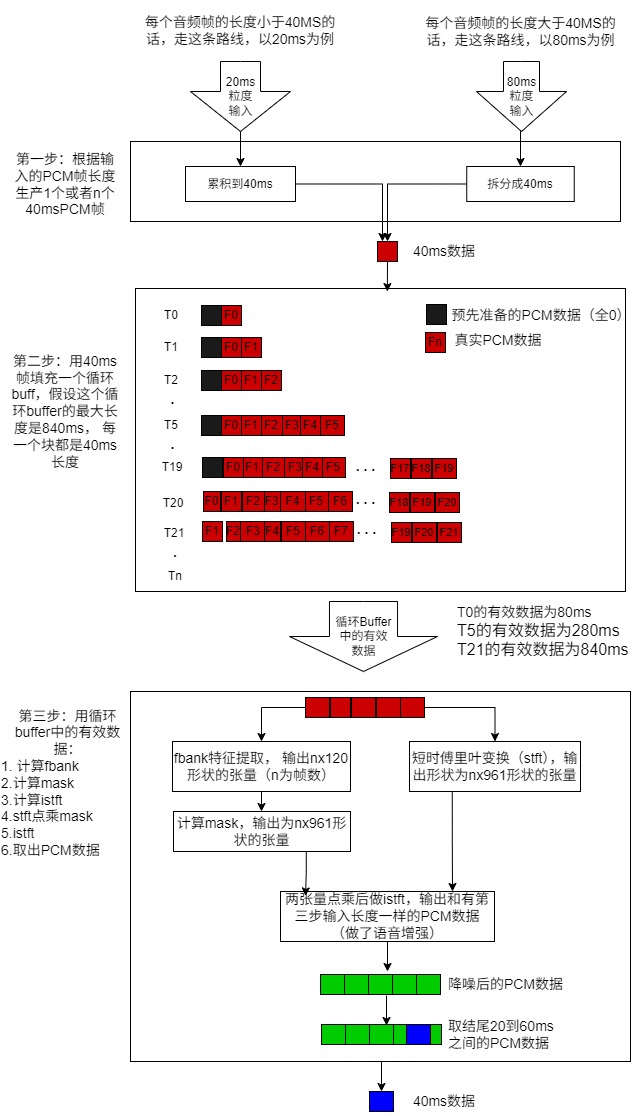
我们使用c/c++实现上面的流程就好了,这一步并不复杂,其中关于张量的说明大家复习一下基本的数学和信号处理知识就可以了,这里就不再赘述了。由于公司的终端类型比较多,有的CPU性能好,有的CPU性能差,有的有NPU,有的没有NPU,加上对性能的天然敏感,于是我在infer的过程中加入ncnn(官方说对算子做了CPU级的优化)和rknn(瑞芯微芯片中自带的神经网络计算单元)的推理支持,关于ncnn和rknn推理的技术细节,笔者有一篇文章有详细的说明:
https://blog.csdn.net/Cowboy1929/article/details/148260216?spm=1011.2124.3001.6209
2.2:rnnoise的移植
rnnoise本来就是c/c++的,所以直接把源拷贝到自己的工程里面,在windows上面或者android上面写好对应的编译文件就好了,这里就不赘述了。
2.3 开发AI-ANS Sdk
考虑到1. 终端性能的差异性,2. 算法的适用场景差异性, 3.编译sdk本身的工具链和调用者使用的工具链的差异性,我把接口设计的比较灵活而且以标准C的方式构建动态库,这样既能最大程度保证了以后不修改代码,也能在被集成的时候不会出现类似符号找不到的链接问题。主要的灵活配置如下:
A:算法配置:dfsmn或者rnnoise
B:推理框架的配置:onnx或ncnn或rknn
C:芯片型号的配置
D:上下文长度的配置:从80ms一直到840ms,40ms为粒度
对SDK本身线程模型的设计,以DFSMN为例,考虑到每次处理接口的调用都必须保证在40ms以内处理完成,所以内部就没有开任何子线程,如果接口保证不了处理时间在40ms以内,那就必须优化,否则就达不到实时处理的要求,RNNoise的处理时间同理也必须小于输入处理数据的长度,比如20ms数据输入,必须在20ms以内处理完成,否则就会造成累积延时。
对SDK的框架设计,比较简单,就是有一个算法的工厂模式加一个后端处理框架的工厂模式,这里就不再详细说明了,后端框架的集成分别使用对应的推理sdk就行了,android下我这么选的(onnx使用了onnxruntime-1.21.0版本,ncnn使用了ncnn-20250916-android-vulkan版本,rknn使用了 rknpu2-2.3.2版本),windows下我这么选的(onnx使用了onnxruntime-win-x64-gpu-1.17.0版本,ncnn使用了ncnn-20250916-windows-vs2022-shared版本),各推理sdk都有样例代码指导如何写推理代码,这里也不在赘述了,唯一我觉得都需要需要强调的是rknn对输入张量的动态shape支持的配置有少许麻烦,如果有需要可以直接在平台发消息给我,我会回复。
三:集成进音视频引擎SDK
公司现有的音视频引擎SDK是基于native webrtc开发的,所需要改造WebRTC和音视频引擎,改造方案如下图:
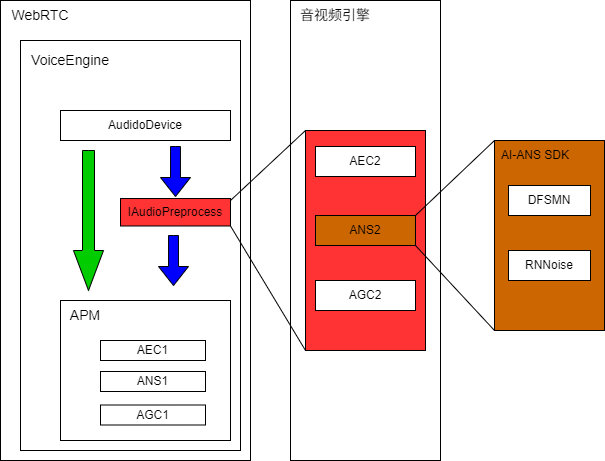
下面说明一下设计思路:
WebRTC里面AudioDevice和APM之间加入音频预处理接口,这个接口由外面实现(音视频引擎,注入设计模式),音视频引擎启动的时候把这个的实现注入到WebRTC内部,结合WebRTC本身对APM的配置接口,我们就能够灵活配置 AEC1,ANS1,AGC1 和 AEC2,ANG2, AGC2的各种组合,构造APM的各种pipeline;比如:
- AEC1--->ANS1--->AGC1
- ANS2--->AEC1--->ANS1--->AGC1
- AEC2--->ANS2--->AGC2
等等,这样设计的好处显而易见的:
- 没有改变WebRTC原来音频处理的流程
- 等以后有了更先进的AEC2或者AGC2算法出现了,可以直接在音视频引擎中集成
四:实际测试效果:
4.1性能测试(ms单位):
|
DFSMN |
RNNoise |
||||||||||
|
ttff |
fbank |
infer |
stft+mask |
istft |
cpu |
ttff |
process |
cpu |
|||
|
Win11 |
i9-12900H (2.50GHz) |
onnx |
21 |
3.5 |
2.0 |
0.5 |
0.5 |
忽略 |
2 |
1 |
忽略 |
|
ncnn |
28 |
1.5 |
|||||||||
|
Android11 |
rk3566 |
onnx |
42 |
10.38 |
19.0 |
1.0 |
1.3 |
28% |
23 |
24 |
38% |
|
ncnn |
48 |
16.0 |
76% |
||||||||
|
rknn |
35 |
8.0 |
21% |
||||||||
|
rk3399 |
onnx |
32 |
11 |
31 |
1.5 |
2.0 |
20% |
18 |
12 |
16% |
|
|
ncnn |
36 |
15 |
32% |
||||||||
|
rk3576 |
onnx |
49 |
9.6 |
27.0 |
1.5 |
1.5 |
16% |
38 |
6 |
8% |
|
|
ncnn |
48 |
10.0 |
40% |
||||||||
|
rknn |
49 |
3.7 |
9% |
||||||||
测试说明:
- 测试AI-SDK的时候输入PCM帧长度20ms(也就是50帧/妙),webrtc的粒度是10ms
- 对于DFSMN,除了rk3566上面上下文长度设置成240ms(大于这个值满足不了实时处理的要求)以外,其他平台都是使用的840ms。
- RNNoise的每次处理粒度是20ms,也就是每次输入20ms数据,都有20ms输出数据。
- 对于DFSMN,在使用ncnn的时候,采用的是在CPU上面推理,虽然看到耗时比onnx降低了,但其内部使用了并行处理,导致CPU消耗比onnx下更多
- 标红的是达不到实时处理要求的,标绿的都能满足实时处理要求而且CPU消耗也可以接受的
- DFSMN可以跟踪到每个细节的时间消耗(fbank-->infer-->stft&mask-->istft),而RNNoise对我来说就是一个黑盒子,我也没有再更深入的分析它里面的细分过程了,就给出了整体处理时间。
- ttff的意思是Time to First Frame,它和处理一帧需要的时间一起反应算法的性能指标。
4.2 效果测试
测试的视频我就不放了,这边直接给出简单的结果
啸叫抑制测试:两台设备正对着音频通话,DFSMN和RNNoise的啸叫抑制的效果都很好。
噪声抑制测试:两者对随机噪声的抑制效果都很优秀;DFSMN的远距离人声保留的比RNNoise好;DFSMN对语音中音色的保留比RNNoise好;RNNoise对噪声的消除比DFSMN干净;大家可以根据我的或者自己测试的结果,再结合实际的使用场景来选择哪种算法。
五:结语
感谢这些开源项目的作者,我们现在解决工程上的实际问题门槛大大降低了,文中如果有误欢迎大家指正、指导!文中虽然只涉及了windows和Android两种平台,推理框架也涉及了CPU的onnx、ncnn和NPU的rknn,但是由于作者使用纯c/c++实现了这个AI降噪SDK,所以移植到其他平台比如Openharmony、Linux、iOS,采用其他芯片上的推理框架也不是难事了。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)