Spring-AI RAG 如何提高召回率?
在构建 RAG(检索增强生成)系统时,“召回率”(Recall)决定了系统能否从海量知识库中把“相关的资料”全都找出来。如果召回率低,哪怕你的大模型再厉害,也是“巧妇难为无米之炊”。本文针对RAG中如何提高召回率的理论 及落地实践进行详细讲解
💼 求职意向:本人目前正在积极寻找新的工作机会,欢迎各位大佬推荐或内推!🤝
📝 能力简述:详细的技术栈、项目经验及过往履历请见我的 Gitee 简历。同时,我也在持续更新技术博客,希望能通过分享与大家共同进步。
📄 我的简历:Gitee 简历链接
文章目录
在构建 RAG(检索增强生成)系统时,“召回率”(Recall)决定了系统能否从海量知识库中把“相关的资料”全都找出来。如果召回率低,哪怕你的大模型再厉害,也是“巧妇难为无米之炊”。
本文针对RAG中如何提高召回率的理论 及落地实践进行详细讲解
提高召回率策略
🧱 1. 夯实地基:数据预处理与索引优化
文档分块及检索策略
- 语义分块:利用算法或 LLM 识别段落、标题或完整的概念单元进行切分,确保每个“块”都言之有物。
- 父文档检索(Small-to-Big):既保证了检索的精准度,又保留了上下文的完整性,解决 “粒度悖论”
- 索引时,将文档切分为细粒度的“子块”(如句子)进行向量化;
- 检索时,虽然匹配的是子块,但返回其所属的完整“父文档”(如整个段落)
- 重叠窗口 (Overlapping) 与 边界优化
- 技巧:在切片时,让相邻的文本块有一定程度的重叠(例如 10%-20%)。
- 目的:防止关键信息正好落在两个切片的边界上,导致语义缺失。虽然这会增加索引量,但对于召回率的提升至关重要。
- 构建多维度索引
- 混合检索(关键词 + 向量):不要只依赖语义向量,目前ElasticSearch 8.x 与 Redis Search都提供了这样的功能
- 元数据过滤:为文档块打上丰富的标签(如时间、作者、章节)。在检索时,先通过元数据快速过滤掉无关范围的数据,再进行向量搜索,能显著提升效率和准确率
- 索引结构的优化
- 分层索引 (Hierarchical Indexing): 根据数据的时效性、重要性或来源建立不同的索引层,可以针对不同层设置不同的检索策略和阈值,避免“新旧混杂”导致的重要信息被淹没
🧠 2. 理解意图:查询转换与扩展
- 查询扩展(Query Expansion)
- 多查询召回:利用 LLM 扮演“头脑风暴师”,将用户的原始问题改写成多个不同角度、但语义相同的子问题(例如:同义词替换、补充背景、拆解问题)。然后用这组问题去并行检索,最后合并结果。这能极大覆盖用户可能的表达方式。
- HyDE(假设性文档嵌入):让 LLM 根据用户的问题,先生成一个“假设性的答案”,然后对这个假设答案进行向量化,并用它去检索知识库。这种方法能有效弥合用户提问方式与文档表述方式之间的“语义鸿沟”。
- 双向改写【Bidirectional Rewriting】策略
- 核心目标是解决用户**“怎么问”(Query)和知识库“怎么写”**(Document)之间的表达差异:通过 Query2Doc(查询转伪文档)及 Doc2Query(文档转伪查询)实现
- 不仅改写用户的查询,也可以在索引阶段对文档进行增强。例如,为每个文档片段生成一些用户可能会问的“代理问题”(Doc2Query),并将这些问题是视同文档内容一起索引。这样,当用户问出类似问题时,系统能更精准地命中答案。
🚀3. 混合与图谱增强
- 多模型集成(Ensemble Retriever)
- 不同的向量化模型(Embedding Model)擅长的领域不同。你可以同时使用多个模型(如一个擅长通用领域,一个擅长垂直领域)分别进行检索,然后将结果合并去重。虽然计算开销稍大,但召回率通常会有质的提升。
- 引入知识图谱(Graph RAG)
- 当你的知识库中存在复杂的实体关系,单纯的向量搜索很难捕捉这种跳跃关系。通过构建知识图谱,将实体和关系显式地存储起来,可以专门用于解决这种“多跳查询”的召回难题。
- 将非结构化的文本转化为结构化的知识图谱(KG)
- 召回机制:
- 语义检索:基于向量找“相似内容”。
- 图检索:基于实体关系找“关联内容”。
🏷️4. 分层/分域路由(Query Routing & Federation)
通过判断用户意图,动态选择检索策略,不同类型的问题采用不同的检索策略
如
- 实体查询:直接走关键词检索或数据库查询,不走向量。
- 事实/分析查询:走向量检索 + 知识图谱
- 长尾/模糊查询:降低关键词检索的阈值,或者走 HyDE。
落地时在检索前加一个“意图分类器”(可以是一个轻量级的 LLM 判断),根据分类结果决定走哪个“召回通道”
⚙️ 5. 领域适配与微调(Fine-tuning Embedding)
通用的向量化模型(如 BGE、qwen3-embedding)在特定垂直领域(如医疗、法律、金融)表现可能不佳,针对此场景,则需要对向量化模型进行微调:
- 收集特定业务领域内的“问题-文档”对作为训练集
- 微调后的模型能更好地理解行业黑话、缩写和特定概念,从而显著提升语义匹配的召回率。
工业级 RAG 的“组合拳”架构
在实际落地中,一个高召回率的 RAG 系统通常是这样的架构:
- 预处理:通过“意图分类器”让不同的问题走不同的召回通道
- 检索层(多路召回)
- 关键词检索:处理全文匹配,使用精确或前缀匹配
- 向量检索:处理语义匹配,结合 Small-to-Big、Multi-Query
- 知识图谱检索:处理关系推理
- 融合层:使用 RRF 或重排序(Reranker)对多路召回的结果进行合并和精排
- 生成层:大模型基于精排后的上下文生成答案
策略对比
| 策略名称 | 核心思想 | 适用场景 | 优点 |
|---|---|---|---|
| 混合检索 | 全文检索 + 向量语义检索+关系检索 | 通用场景,包含大量专有名词/编号 | 兼顾精准匹配与模糊语义,最稳妥 |
| Small-to-Big | 子块索引,父块召回 | 长文档、结构化文档 | 解决精度与上下文完整性的矛盾 |
| 查询扩展 | LLM生成多角度子问题 | 用户提问模糊、简短 | 极大提升覆盖度,减少漏网之鱼 |
| HyDE | 用“假设答案”找“真实文档” | 零样本学习、冷启动场景 | 弥合语义鸿沟,适合开放域问答 |
理论到实践的映射
提高召回率不仅仅是“多拿几条数据”那么简单,而是要通过语义理解、反馈机制和推理链条,去弥合用户提问与知识库表达之间的鸿沟。
| 理论名称 | 核心解决的问题 | 对应的工程/落地手段 |
|---|---|---|
| 伪相关反馈 (PRF) | 查询词太少,表达不充分 | Query Expansion, HyDE |
| 多跳推理 (Multi-Hop) | 答案分散在多个文档中 | Step-back Prompting, Sub-question Decomposition |
| 分布式语义 (Distributional) | 字面词不匹配,但意思一样 | Fine-tuned Embedding, Cross-Modal Search |
| 级联排序 (Cascade) | 既要快,又要准,还要全 | BM25 + Vector (Hybrid), Reranker |
| 知识蒸馏 (Distillation) | 好模型太慢,没法线上用 | Fine-tuning Embedding 模型 |
附录
HyDE: Hypothetical Document Embeddings
HyDE(Hypothetical Document Embeddings,假设文档嵌入)是 RAG(检索增强生成)领域中一种非常巧妙且有效的技术:解决了语义鸿沟”,像是给检索系统配了一个专业翻译官。
核心思想:
- 首先让大模型根据用户问题生成一个“假设性的答案”
- 然后拿这个“答案”去向量库中匹配真实、相关的文档。
- 生成最终答案(Final Answer):将检索到的真实文档、原始的用户问题,以及刚才生成的假设答案(可选)一并交给大模型,让它基于真实资料进行最终的回答生成。
优势
- 自动术语对齐
- 解决冷启动问题:对于长尾查询(很少有人问的问题),HyDE 能通过生成假设文档,找到那些虽然没被问过,但语义相关的冷门知识
- 降低幻觉风险:虽然中间步骤用了“假答案”,但最终生成答案时,大模型是看着“真文档”来写的,所以并不会增加最终结果的幻觉,反而因为有了真实资料支撑,答案更靠谱
缺点
- 增加延迟 和 计算成本
- 假设答案的误导
与传统RAG的区别
| 维度 | 传统 RAG (Naive RAG) | HyDE (增强 RAG) |
|---|---|---|
| 检索依据 | 原始问题(Query) | 假设文档(Hypothetical Document) |
| 向量特征 | 通常是短文本,口语化,噪声多 | 通常是长文本,书面化,语义丰富 |
| 适用场景 | 查询明确、术语标准时 | 查询模糊、口语化、或需要专业术语匹配时 |
| 召回能力 | 容易受词汇不匹配影响 | 能通过“意译”找到深层相关的文档 |
双向改写(Bidirectional Rewriting)策略对比
| 维度 | Query2Doc (查询转伪文档) | Doc2Query (文档转伪查询) |
|---|---|---|
| 执行时机 | 检索时 (Runtime) | 建库时 (Indexing Time) |
| 主要目的 | 弥合用户口语与文档书面语的差距 | 增加文档的召回入口,解决词汇不匹配 |
| 计算开销 | 每次检索都要调用 LLM,有延迟 | 一次性成本,对线上检索速度无影响 |
| 主要风险 | 生成的伪文档若偏离主题,会导致检索失败 | 生成的伪查询若过多,会增加索引体积和噪声 |
| 典型场景 | 开放域问答、用户提问非常随意时 | 企业知识库、FAQ 系统、专业术语较多时 |
RRF(Reciprocal Rank Fusion,倒数排序融合)
RRF 是一种 “裁判”算法。当你同时使用了多种检索方式去查找资料时,RRF 负责把这几组不同的“成绩单”合并成一份最终的排名表,确保最相关的文档排在最前面。
RRF 的核心思想非常直观:在多个检索系统中都排名靠前的文档,才是好文档。
计算公式:
R R F score ( d ) = ∑ i = 1 n 1 k + r a n k i ( d ) RRF_{\text{score}}(d) = \sum_{i=1}^{n} \frac{1}{k + rank_i(d)} RRFscore(d)=i=1∑nk+ranki(d)1
- 倒数(Reciprocal):排名越靠前( rank数字越小), 1/rank 的值越大。这意味着第一名的权重远高于第一百名。
- 融合(Fusion):同一个文档如果在 A 列表排第 1,在 B 列表排第 5,它的分数就是两者的加权和。
- 常数 k :为了避免分母为 0 或者让第一名的分数过高而压死其他文档,加入了一个偏移量 k 。 k 值越大,算法越保守; k 值越小,算法越看重第一名。
实践经验
- 对于未出现的文档:如果一个文档只在 A 列表出现,不在 B 列表出现,它的 rankrank 不能设为无穷大(否则分数为 0),通常设为 列表长度 + 1 或者一个很大的固定值。
- k的推荐值为 60,在大多数场景下, k=60 能在“重视高排名文档”和“不过度压制低排名文档”之间取得很好的平衡
- 去重与标识:RRF 的前提是“同一个文档”。在实际中,BM25 可能召回的是“段落 A”,向量检索召回的也是“段落 A”,但它们的 ID 可能不同。 需要建立稳定的去重机制:如
source_url, chunk_content_hash作为唯一键去重 - Top-N 截断:通常每路检索(BM25 和 Vector)先各自取出 Top-50 或 Top-100 的结果,然后只对这几百个文档做 RRF 融合,最后再取 Top-K(如 Top-10)送给大模型
优势与劣势
| 优点 | 缺点 |
|---|---|
| 无需分数归一化:只看排名,不管是什么检索算法,拿来就能融合。 | 增加延迟:需要并行跑多路检索,增加了 P99 延迟。 |
| 零样本有效:不需要针对特定领域进行训练或调参,开箱即用。 | 忽略原始分数:只用了排名信息,丢失了原始模型给出的细粒度相关性信号。 |
| 鲁棒性强:通过“多系统共识”过滤掉了单路检索的噪声。 | 去重要求高:如果文档 ID 不统一,融合效果会大打折扣。 |
RRF 与 Rerank的区别
RERANK需要专门的轻量级的 Transformer 模型,如Qwen3-Reranker-0.6B
Rerank (重排序) 是一种基于模型的精排技术。
Rerank的优点及缺点:
- 优点:准! 它能发现那些向量距离近但语义不相关的“漏网之鱼”,能把真正语义相关的文档(哪怕向量距离稍远)排到前面。
- 缺点:计算成本高(模型推理慢),增加了系统延迟。
在实际的工业级 RAG 落地中,RRF 和 Rerank 往往不是“二选一”,而是“配合使用”,组成一个高效的漏斗
| 维度 | RRF (倒数排序融合) | Rerank (重排序) |
|---|---|---|
| 本质 | 规则/算法 (基于位置的数学公式) | 模型/AI (基于语义理解的深度学习模型) |
| 输入 | 多个已有的排序列表 (如 BM25 列表 + 向量列表) | 原始的查询 (Query) + 待排序的文档列表 |
| 决策依据 | 排名位置 (Position)。不看具体分数,只看排第几。 | 语义相关性 (Semantic Relevance)。理解 Query 和 Doc 的内容匹配度。 |
| 计算开销 | 极低 (简单的数学加法和除法) | 高 (需要调用大模型或专门的 Rerank 模型进行推理) |
| 主要作用 | 融合 (Fusion):解决多路召回的结果合并问题。 | 精排 (Refinement):解决单路或混合结果的精准度问题。 |
| 是否需要训练 | 不需要,开箱即用。 | 需要预训练好的 Rerank 模型 (如 BGE-Reranker, Cohere)。 |
BM25(Best Matching 25)
BM25(Best Matching 25)是信息检索领域中最经典、最稳健的算法之一
在 RAG(检索增强生成)系统中,BM25 依然是不可或缺的“基石”,常被用于与向量检索结合,以保证关键词和实体的精准召回
BM25 是一种用来计算 “用户查询(Query)” 与 “文档(Document)” 之间相关度的打分函数。
核心思想: BM25 的核心逻辑建立在三个直觉非常强的假设之上
- 词频(TF):一个词在文档中出现的次数越多,该文档与这个词的相关性可能越高
- 逆文档频率(IDF),如搜索“量子纠缠”通常能精准定位到特定文档
- 文档长度归一化:短文档通常更容易获得高词频,长文档则相对吃亏。
- 逻辑:BM25 会惩罚过长的文档,奖励较短且精炼的文档,以保证公平
无论是 Elasticsearch 还是 RedisSearch,它们在进行全文检索(Full-Text Search)时,底层计算相关性分数(Scoring)的核心逻辑都是基于 BM25 或其高度优化的变体。
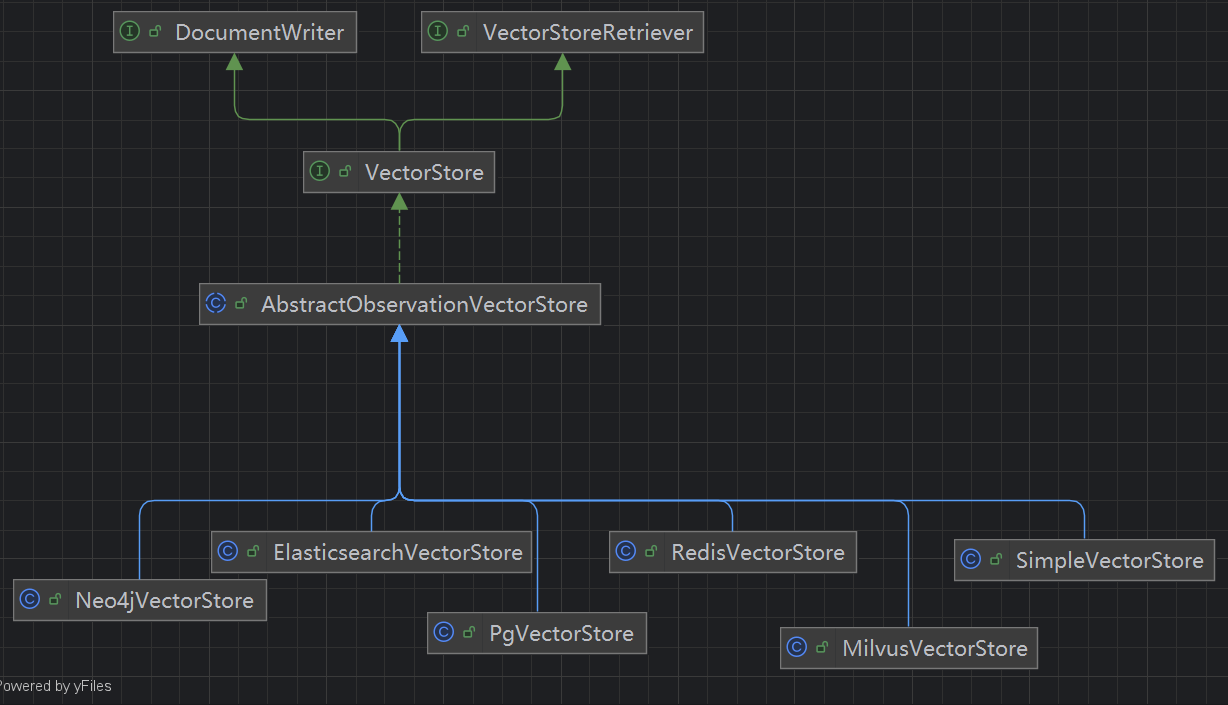
Spring AI中的召回策略
基础召回策略 (Base Retrieval)
VectorStoreDocumentRetriever
最原子的召回单元,通常作为组合策略的组成部分
- 实现类:
VectorStoreDocumentRetriever - 原理:
- 最标准的 RAG 召回,将查询向量化后在向量数据库中进行近似最近邻搜索(ANN)
- 通过Filter.Expression实现关键词召回
- 配置:可以通过 topK(int k) 设置返回的候选文档数量
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("genre", "fairytale")
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("What is the main character of the story?"));
智能预处理召回策略 (Pre-Retrieval Processing)
在查询前先对用户问题进行预处理
- 查询重写 (Query Rewrite)
- 实现类:
RewriteQueryTransformer - 策略:利用 LLM 将用户口语化的、模糊的提问,重写为更适合数据库检索的标准语句或包含同义词的语句。
- 实现类:
- 查询压缩 (Query Compression)
- 实现类:
CompressionQueryTransformer - 策略:在多轮对话中,用户的查询可能包含大量冗余历史信息。该策略利用 LLM 提炼核心意图,去除噪声,避免“语义污染”导致召回失败。
- 实现类:
- 查询转换
- 实现类:
TranslationQueryTransformer - 策略:使用大型语言模型将查询翻译为用于生成文档嵌入的嵌入模型所支持的目标语言。如果查询已经是目标语言,它将原样返回。如果查询的语言未知,它也会原样返回。
- 实现类:
- 查询扩展
- 实现类:
MultiQueryExpander - 策略:使用大型语言模型将查询扩展为多个语义不同的变体,以捕获不同的透视图,这对于检索其他上下文信息和增加查找相关结果的机会非常有用
- 实现类:
Query query = Query.builder()
.text("And what is its second largest city?")
.history(new UserMessage("What is the capital of Denmark?"),
new AssistantMessage("Copenhagen is the capital of Denmark."))
.build();
QueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);
组合与混合召回策略 (Hybrid & Ensemble)
- 混合检索 (Hybrid Search / Multi-Source Retrieval)
- 实现类:
HybridElasticsearchRetriever(在 Spring AI Alibaba 或自定义实现中常见) - 策略:同时执行向量检索和关键词检索。
- 融合方式:
- 并集去重:将两路结果合并,去重后返回。
- 打分融合 (Score Fusion):结合 Spring AI 的评分机制,对不同来源的文档分数进行归一化或加权求和。
- 实现类:
- 多路召回 (Multi-Query Retrieval)
- 实现类:通常利用
MultiQueryRetrieverAdvisor、MultiQueryExpander实现 (在 Spring AI Alibaba 或自定义实现中常见) - 策略:针对用户的一个问题,生成多个查询变体(如同义词、扩展词),并行检索后再合并结果。
- Spring AI 特性:Spring AI 支持通过
ChatClient调用 LLM 来生成这些查询变体,从而扩大检索的覆盖面。
- 实现类:通常利用
HyDeRetriever: 实现HyDE的召回策略
后处理精排召回策略 (Post-Retrieval Processing)
虽然严格意义上这属于“排序”阶段,但在 Spring AI 的 RAG 流程中,它直接影响最终“召回”给生成器的文档质量:
ConcatenationDocumentJoiner
通过将基于多个查询和从多个数据源检索到的文档连接到单个文档集合中,将它们组合在一起。如果有重复的文件,则保留第一次出现的文件。每份文件的分数按原样保存。结果是一个唯一文档的列表,按照它们的分数降序排序- 重排序 (Re-Ranking)
- 实现类:
RetrievalRerankAdvisor(Spring AI Alibaba 提供) 或自定义的DocumentPostProcessor。 - 策略:
- 原理:先粗粒度召回 Top-N(如 50 个)文档,然后调用专门的重排序模型(Rerank Model)对这 N 个文档进行精细的相关性打分。
- 作用:将真正相关的文档(可能在粗排中排名靠后)提升到前面,并过滤掉不相关的文档。
- 注意:
- Spring AI 通过
DocumentPostProcessor接口定义了后处理相关的接口,但目前更倾向于通过 Advisor 或专门的 Service 来实现这一逻辑。 DocumentPostProcessor用于根据查询对检索到的文档进行后处理,解决诸如“中间丢失”、模型的上下文长度限制以及减少检索信息中的噪声和冗余的需求等挑战
- Spring AI 通过
- 实现类:
Query Augmentation
用于提供必要上下文信息让大模型回答用户查询
QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build();

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)