基于TF-IDF完成《红楼梦》关键词提取(制作搜索引擎)
本文基于TF-IDF算法,完整实现了“关键词提取+章节搜索”的轻量级搜索引擎,核心亮点:配置化设计:所有参数集中管理,可快速适配其他文本数据集;中文优化:加载专属词库和停用词库,提升分词和关键词提取准确性;交互友好:支持多关键词搜索,提供清晰的结果反馈和退出机制。该方案无需复杂模型,计算高效,适合小型文本库的检索场景(如小说、论文集、文档库等)。
在文本检索场景中,如何快速从海量文本中定位包含目标信息的内容?关键词提取是核心环节之一。TF-IDF作为经典的文本特征提取算法,能有效量化词语在文本中的重要性,基于此我们可以搭建轻量级的文本搜索引擎。本文将以《红楼梦》文本为数据集,完整实现“关键词提取+章节检索”的搜索引擎,包含详细的原理讲解、代码解析和效果演示。
一、核心原理:TF-IDF为什么能做关键词提取?
TF-IDF全称为“词频-逆文档频率”(Term Frequency-Inverse Document Frequency),其核心思想是:一个词的重要性,与它在当前文档中出现的频率成正比,与它在整个语料库中出现的频率成反比。
1.1 两个核心指标
-
TF(词频):某词语在当前文档中出现的次数除以文档总词数,衡量词语在单篇文档中的密集程度。公式:TF = 某词在文档中出现次数 / 文档总词数
-
IDF(逆文档频率):衡量词语的“稀缺性”。语料库中包含该词语的文档数越少,IDF值越大,说明该词对文档的区分度越高。公式:IDF = log(总文档数 / (包含该词的文档数 + 1))(+1是为了避免分母为0)比如一些助词“的”,虽然出现在单篇文章中可能出现频率高,但是稀缺性很低,就不能作为关键词。
最终的TF-IDF值 = TF × IDF,值越高,代表该词语越能代表当前文档的核心主题,适合作为关键词。
1.2 为什么选择TF-IDF?
相比One-Hot编码等传统方法,TF-IDF的优势在于:
-
能自动过滤“的、是、在”等高频无意义停用词(这类词IDF值极低,TF-IDF值也低);
-
能突出文档的核心主题词,量化词语的重要性;
-
实现简单、计算高效,无需复杂的深度学习模型,适合轻量级检索场景。
二、实现思路:从文本处理到搜索引擎搭建
本次实现以《红楼梦》为数据集,目标是搭建一个“输入关键词返回对应章节”的搜索引擎。整体流程分为6个核心步骤:
-
文本预处理:将《红楼梦》全文按“卷 第”拆分,生成单章节文本文件;
-
词库配置:加载《红楼梦》专属词库(提升分词准确性)和中文停用词库;
-
语料库生成:对各章节文本进行分词、去停用词,生成TF-IDF可处理的语料;
-
TF-IDF计算:通过TF-IDF算法量化各章节词语的重要性,提取TOP关键词;
-
搜索接口设计:实现多关键词匹配逻辑,根据关键词定位包含所有关键词的章节;
-
交互式交互:提供命令行交互界面,支持用户输入关键词搜索、退出等操作。
三、核心代码解析:逐模块拆解实现细节
以下结合完整代码,逐模块解析关键实现逻辑,所有代码已做中文注释和编码优化,可直接运行。
3.1 环境准备与配置项管理
首先导入依赖库,通过CONFIG字典集中管理配置项,便于后续修改;同时配置系统编码,解决中文输出乱码问题。
import os
import re
import sys
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 配置项(集中管理,便于修改)
CONFIG = {
"input_txt": "红楼梦.txt",
"output_folder": "分卷",
"custom_dict": "红楼梦词库.txt",
"stopwords_path": "StopwordsCN.txt",
"corpus_output": "红楼梦_corpus.txt",
"top_keywords_num": 10 # 每个章节提取的TOP关键词数量
}
关键说明:
-
依赖库:jieba用于中文分词,sklearn的TfidfVectorizer用于快速计算TF-IDF;
-
配置项:包含输入文本路径、分章节输出文件夹、专属词库等,后续若换其他文本(如《三国演义》),仅需修改配置项即可;
3.2 文本预处理:拆分章节
观察红楼梦文本数据,发现每一回的结构都有“卷 第”的格式: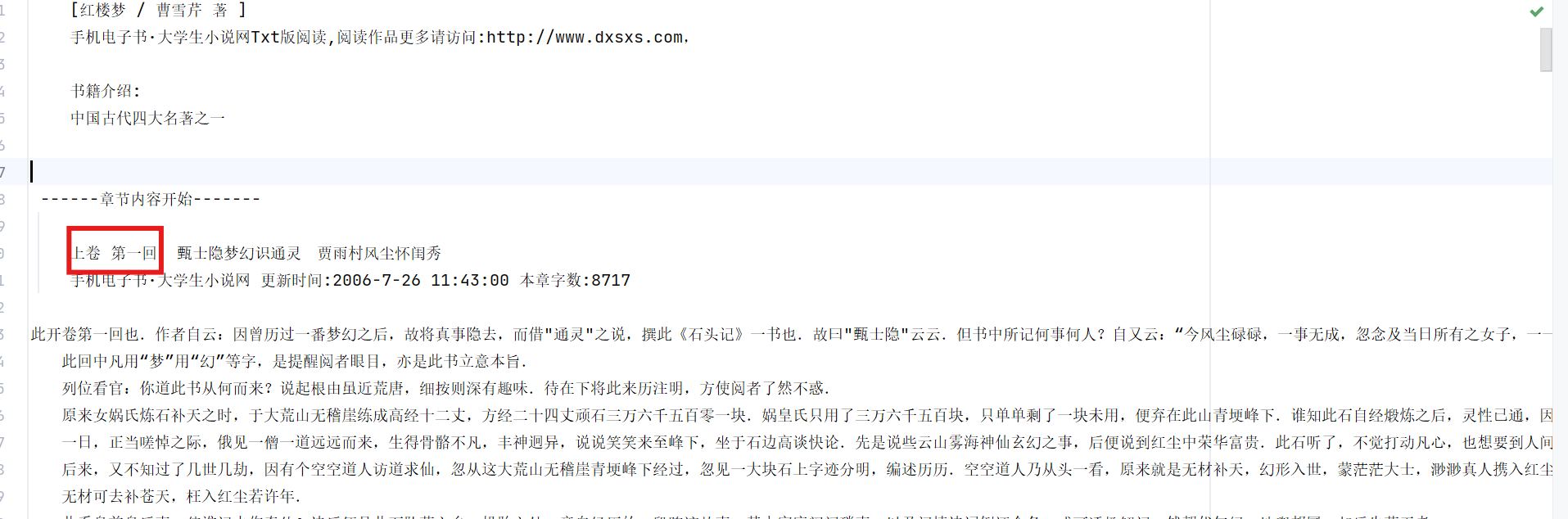
通过正则匹配“卷 第”关键词,将《红楼梦》全文拆分为单章节文本文件,保存到“分卷”文件夹,为后续按章节提取关键词做准备。
def split_chapters():
"""按"卷 第"拆分红楼梦为分卷文件夹下的单章txt"""
os.makedirs(CONFIG["output_folder"], exist_ok=True)
current_chapter = None
with open(CONFIG["input_txt"], "r", encoding="utf-8") as f:
for line in f:
line_clean = line.strip()
if "卷 第" in line_clean:
# 关闭上一章文件
if current_chapter:
current_chapter.close()
# 生成合法文件名并打开新文件(替换非法字符)
safe_name = re.sub(r"[\\/:*?\"<>|]", "_", line_clean) + ".txt"
chapter_path = os.path.join(CONFIG["output_folder"], safe_name)
current_chapter = open(chapter_path, "w", encoding="utf-8")
current_chapter.write(line)
elif current_chapter:
current_chapter.write(line)
if current_chapter:
current_chapter.close()
print("✅ 分章节完成,文件已保存至「分卷」文件夹")关键逻辑:
-
os.makedirs(..., exist_ok=True):创建输出文件夹,若已存在则不报错;
-
正则替换非法字符:Windows文件名不允许包含\、/、:等字符,用re.sub替换为下划线,避免创建文件失败;
-
逐行写入:遇到“卷 第”时新建文件,否则持续写入当前章节,确保章节拆分准确。
运行结果: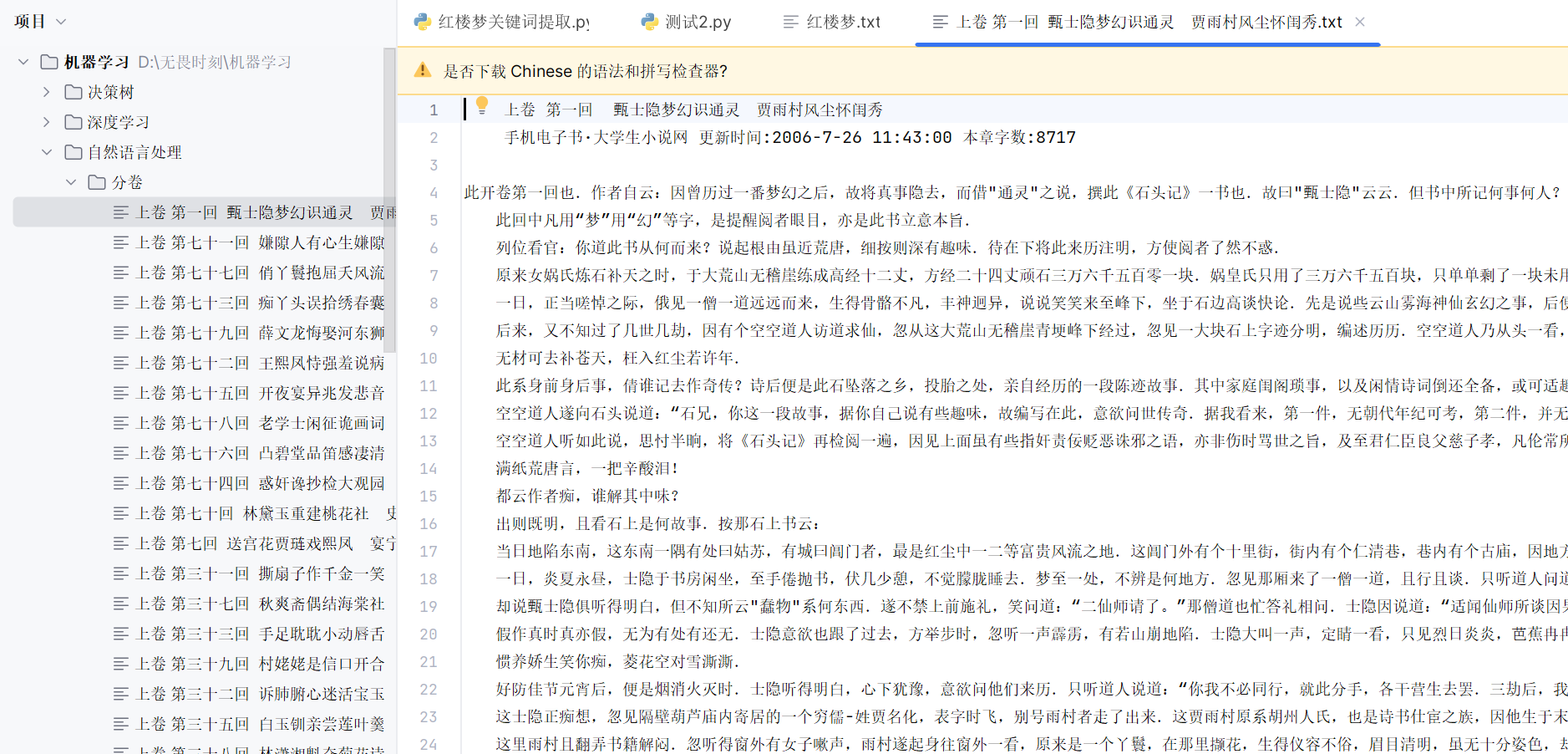
3.3 词库加载:提升分词准确性
加载《红楼梦》专属词库(如“贾宝玉”“林黛玉”“大观园”等专有名词)和中文停用词库(过滤无意义词汇),提升分词和关键词提取的准确性。
def load_dict_and_stopwords():
"""加载jieba自定义词库 + 停用词集合"""
# 加载专属词库
if os.path.exists(CONFIG["custom_dict"]):
jieba.load_userdict(CONFIG["custom_dict"])
print(f"✅ 加载专属词库:{CONFIG['custom_dict']}")
else:
print(f"⚠️ 未找到专属词库:{CONFIG['custom_dict']},使用默认分词")
# 加载停用词(转集合提升查询效率)
stopwords = set()
if os.path.exists(CONFIG["stopwords_path"]):
with open(CONFIG["stopwords_path"], "r", encoding="utf-8") as f:
stopwords = {line.strip() for line in f if line.strip()}
print(f"✅ 加载停用词库,共{len(stopwords)}个停用词")
else:
print(f"⚠️ 未找到停用词库:{CONFIG['stopwords_path']},不过滤停用词")
return stopwords关键说明:
-
专属词库:jieba默认分词可能将“贾宝玉”拆分为“贾”“宝玉”,加载专属词库后可正确识别专有名词;
-
停用词集合:将停用词存入set(查询时间复杂度O(1)),比list(O(n))更高效,过滤“的、了、是”等无意义词。
3.4 语料库生成:分词与清洗
对拆分后的章节文本进行清洗、分词、去停用词,生成TF-IDF算法所需的语料库(corpus)——即每个章节对应的“关键词列表字符串”。
def generate_corpus(stopwords):
"""处理分卷内容,生成TF-IDF可用的corpus(分词+去停用词)"""
# 获取并排序分卷下的所有章节文件
chapter_files = [
os.path.join(CONFIG["output_folder"], f)
for f in os.listdir(CONFIG["output_folder"])
if f.endswith(".txt")
]
chapter_files.sort() # 按章节顺序排序
corpus = []
for file_path in chapter_files:
# 读取文件并跳过前3行无效内容(可根据实际文本调整)
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
content = "".join(lines[3:]) if len(lines) > 3 else ""
# 文本清洗 + 分词 + 过滤停用词
content = re.sub(r"\s+", " ", content).strip() # 替换多余空格
words = jieba.lcut(content) # 精确分词
filtered_words = [w for w in words if w not in stopwords and w.strip()]
# 生成corpus行(用空格连接关键词,符合TfidfVectorizer输入格式)
corpus.append(" ".join(filtered_words))
# 打印进度(兼容编码)
chap_name = os.path.basename(file_path)
print(f"✅ 处理完成:{chap_name.encode('utf-8', 'replace').decode('utf-8')},有效词汇数:{len(filtered_words)}")
return corpus, chapter_files # 返回语料库和章节文件路径列表关键逻辑:
-
文件排序:确保章节顺序与原文一致,避免后续关键词提取混乱;
-
跳过无效内容:部分文本前几行可能是版权信息或目录,跳过可提升语料质量;

-
语料格式:TfidfVectorizer要求输入为“每个样本一行(即每一回的内容分词作为一行),词语用空格分隔”的字符串列表,因此用" ".join(filtered_words)格式化。
3.5 TF-IDF计算与关键词提取
使用sklearn的TfidfVectorizer计算各章节的TF-IDF矩阵,然后根据TF-IDF值提取每个章节的TOP N关键词。
def get_top_keywords(tfidf_vec, tfidf_matrix, chapter_files):
"""提取每个章节的TOP关键词并打印/返回"""
# 获取特征词(所有分词结果,即TF-IDF计算的词汇集合)
feature_names = tfidf_vec.get_feature_names_out()
# 章节名称列表(去掉文件后缀)
chapter_names = [os.path.splitext(os.path.basename(f))[0] for f in chapter_files]
top_keywords_dict = {} # 存储{章节名: [关键词列表]}
print("\n========== 各章节TOP关键词 ==========")
for idx, (chapter_name, row) in enumerate(zip(chapter_names, tfidf_matrix)):
# 将稀疏矩阵转为数组,获取每个词的TF-IDF值
tfidf_scores = row.toarray()[0]
# 按TF-IDF值降序排序,取TOP N(过滤TF-IDF为0的词)
top_indices = tfidf_scores.argsort()[-CONFIG["top_keywords_num"]:][::-1]
top_keywords = [feature_names[i] for i in top_indices if tfidf_scores[i] > 0]
top_keywords_dict[chapter_name] = top_keywords
# 打印结果
print(f"\n📖 {chapter_name} TOP{CONFIG['top_keywords_num']}关键词:")
print(" | ".join(top_keywords))
return top_keywords_dict, chapter_names关键说明:
-
稀疏矩阵处理:TF-IDF矩阵是稀疏矩阵(多数词语在某章节中不出现,TF-IDF值为0),用toarray()转为稠密数组便于处理;
-
argsort()排序:先获取TF-IDF值的索引,按降序排列后取最后N个(即TOP N),再逆序转为正序;
-
结果存储:用字典存储章节名与关键词的映射,便于后续查看和复用。
3.6 搜索接口实现:关键词匹配章节
设计两个核心函数:search_keyword(核心匹配逻辑)和interactive_search(交互式交互界面),支持多关键词搜索(需同时包含所有关键词)。
def search_keyword(keyword_list, corpus, chapter_names):
"""
搜索关键词接口:输入关键词列表,返回同时包含所有关键词的章节名
:param keyword_list: 要搜索的关键词列表(空格分隔后的结果)
:param corpus: 语料库列表
:param chapter_names: 章节名称列表
:return: 匹配的章节名列表
"""
matched_chapters = []
for idx, (chap_content, chap_name) in enumerate(zip(corpus, chapter_names)):
chap_words = chap_content.split() # 拆分当前章节的词汇列表
# 检查所有关键词是否都在当前章节中(多关键词同时匹配)
if all(kw in chap_words for kw in keyword_list):
matched_chapters.append(chap_name)
return matched_chapters
def interactive_search(corpus, chapter_names):
"""交互式搜索接口(命令行):支持空格分隔的多关键词搜索"""
print("\n========== 关键词搜索接口 ==========")
print("💡 输入关键词(空格分隔多个关键词)即可搜索对应章节,输入'q'或'退出'结束程序")
while True:
keyword_input = input("\n请输入要搜索的关键词(空格分隔):").strip()
if keyword_input.lower() in ["q", "退出"]:
print("👋 搜索程序结束")
break
# 将输入按空格拆分为关键词列表(过滤空字符串)
keyword_list = [kw.strip() for kw in keyword_input.split() if kw.strip()]
if not keyword_list:
print("⚠️ 请输入有效关键词")
continue
# 执行多关键词搜索
matched_chapters = search_keyword(keyword_list, corpus, chapter_names)
if matched_chapters:
print(f"\n✅ 找到包含「{' '.join(keyword_list)}」的章节(共{len(matched_chapters)}个):")
for i, chap in enumerate(matched_chapters, 1):
print(f" {i}. {chap}")
else:
print(f"\n❌ 未找到包含「{' '.join(keyword_list)}」的章节")关键逻辑:
-
多关键词匹配:用all()函数判断“所有关键词是否都在当前章节的词汇列表中”,确保搜索准确性;
-
交互式交互:循环接收用户输入,支持“退出”指令,输入为空时给出提示,提升用户体验;
-
编码兼容:打印章节名时用encode-decode处理,避免特殊字符导致的乱码。
3.7 主函数:串联所有流程
主函数按“检查输入文件→拆分章节→加载词库→生成语料→计算TF-IDF→提取关键词→启动搜索”的顺序串联所有模块,确保流程顺畅。
if __name__ == "__main__":
# 异常处理:检查输入文件是否存在
if not os.path.exists(CONFIG["input_txt"]):
print(f"❌ 错误:未找到输入文件 {CONFIG['input_txt']}")
sys.exit(1)
# 主执行流程
split_chapters()
stopwords = load_dict_and_stopwords()
corpus, chapter_files = generate_corpus(stopwords)
save_corpus(corpus) # 保存语料库(可选,便于后续复用)
# TF-IDF计算
tfidf_vec = TfidfVectorizer()
tfidf_matrix = tfidf_vec.fit_transform(corpus)
# 打印结果概览
print("\n========== 基础结果概览 ==========")
print(f"📚 总章节数:{len(corpus)}")
print(f"📝 第一回前50字符:{corpus[0][:50]}..." if corpus else "❌ 无有效内容")
print(f"🔢 TF-IDF矩阵形状:{tfidf_matrix.shape}") # (章节数, 总词汇数)
# 1. 提取各章节TOP关键词
top_keywords_dict, chapter_names = get_top_keywords(tfidf_vec, tfidf_matrix, chapter_files)
# 2. 启动交互式搜索接口
interactive_search(corpus, chapter_names)四、效果演示:实际运行测试
将《红楼梦.txt》《红楼梦词库.txt》《StopwordsCN.txt》放在代码同级目录,运行代码后查看效果。
运行结果:

五、总结与拓展方向
5.1 总结
本文基于TF-IDF算法,完整实现了“关键词提取+章节搜索”的轻量级搜索引擎,核心亮点:
-
配置化设计:所有参数集中管理,可快速适配其他文本数据集;
-
中文优化:加载专属词库和停用词库,提升分词和关键词提取准确性;
-
交互友好:支持多关键词搜索,提供清晰的结果反馈和退出机制。
该方案无需复杂模型,计算高效,适合小型文本库的检索场景(如小说、论文集、文档库等)。
5.2 拓展方向
若要提升搜索引擎的性能和功能,可从以下方向优化:
-
语义增强:结合词向量(如Word2Vec、BERT)替代传统分词,支持同义词搜索(如“黛玉”和“林妹妹”);
-
模糊匹配:添加拼音匹配、错别字容错(如“宝五”匹配“宝玉”),提升搜索灵活性;
-
结果排序:按关键词TF-IDF值排序,返回相关性更高的章节;
-
Web化部署:用Flask/Django搭建Web接口,支持浏览器访问,提升易用性;
-
批量处理:支持批量输入关键词,导出搜索结果到Excel,适配批量检索需求。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 41
41 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)