(YOLO前置知识点)神经网络、Pytorch、卷积神经网络CNN
本文系统讲解了神经网络、PyTorch和卷积神经网络(CNN)的核心知识与应用。首先指出仅掌握YOLO基础调用不足以为论文或毕设提供足够深度,必须理解CNN底层原理才能进行算法优化。文章详细解析了神经网络基础概念:从神经元、感知机到全连接网络,重点讲解了激活函数(sigmoid、Tanh、ReLU等)、前向传播、损失函数和反向传播机制。在CNN部分,阐述了其相比传统神经网络的优势,包括局部相关性处
一、为什么要学神经网络、Pytorch、卷积神经网络CNN
因为我发现B站所有的yolo的视频教学都止步于【数据准备】、【模型预测推理】、【模型训练】、【模型验证】就结束了,可能有的会再教一下opencv结合着实战
但是如果就这么几行简单的调用yolo模型能做一个毕设或者做一篇论文了吗?肯定是不可能的,傻子学两天都会了,就这么点工作量还没人家人工智能专业的期中小作业的工作量多。于是我查询了一下怎么进一步优化改进YOLO,终于给我发现很多博主会讲到YOLO底层代码的【模块沿用、模块缝合】的知识点


但是我听了之后有点懵,是因为YOLO的底层就是用卷积神经网络CNN搭建的,所以如果不懂这些内容根本就没办法进一步改进,因为我觉得应该开一篇笔记讲一下。
二、神经网络NN
其实我之前简单粗浅写过这相关的文章,可以自行去先了解一下,过一遍即可
《有监督学习》:
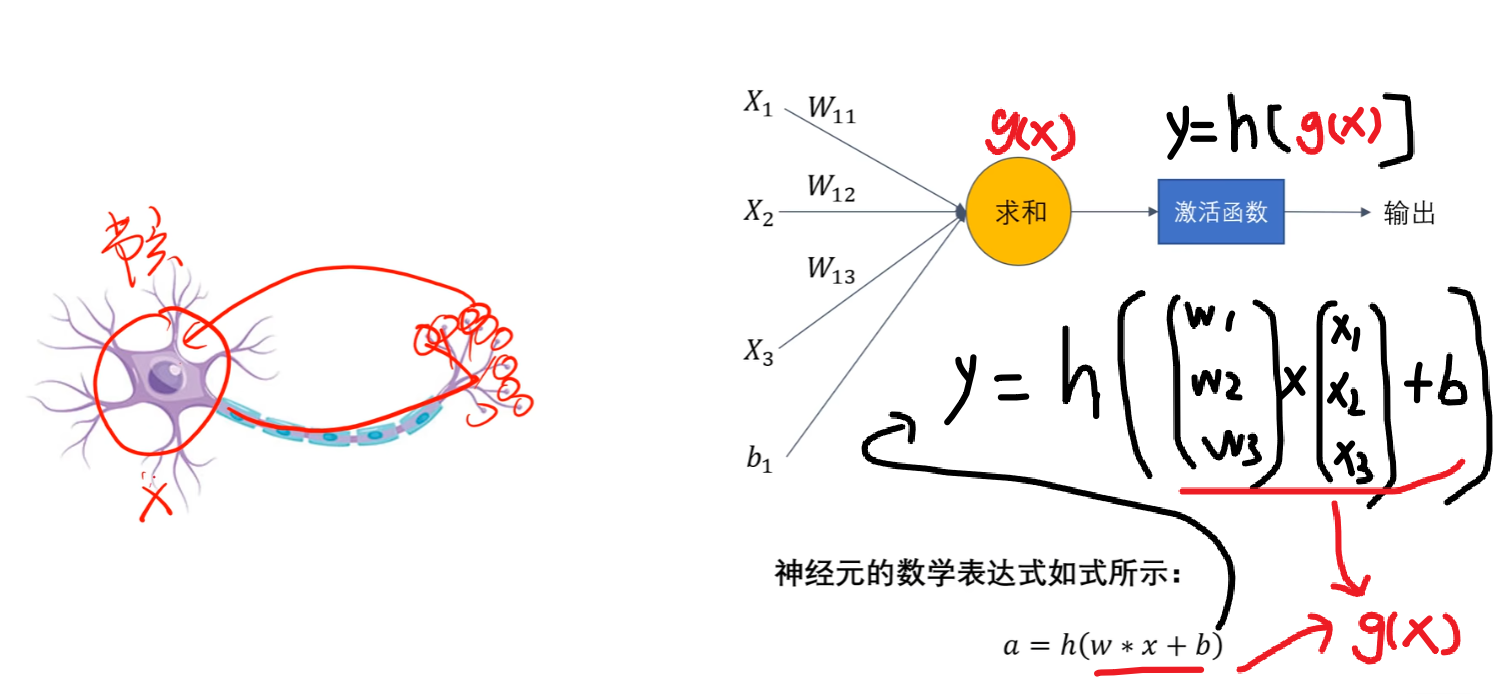
1、首先理解理解基础单位【神经元】——【感知机】
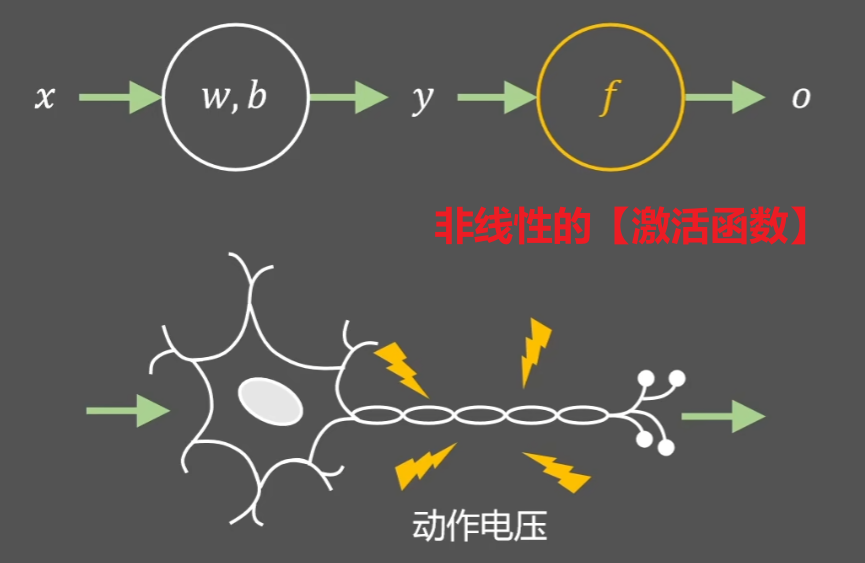
我的《人工智能学习前言》讲过,首先要让机器向人类一样思考,就要模仿人类的 “神经元” 一样设计一个 “感知机”,说简单点就是一个【y = f(x)】函数,只不过要用线性代数的概念去理解x、y,x通常是一个向量x=(x1, x2, x3, x4.......),还要加入参数w=(w1, w2, w3, w4......)、以及参数b一起计算,打比方:w1=0、w2=1表示是、否,x1、x2表示男、女,然后再设一个阈值b=0.5,那【w1x1+w2x2 - b = y】就可以根据【y是大于0还是小于0】知道是男是女了,这不就是一个求男女性别的感知机了嘛,这样的函数我们称为【拟合函数(预测函数)】
但是我们发现这样还是远不能够达到神经元的效果,因为无论怎么添加再多的参数,【拟合函数(预测函数)】始终是一个【线性函数】,如何才能理解【非线性的问题】呢?
如果我们再叠加一个【非线性的函数】,像我们高中学过的 “套娃函数” 一样:y = h( g(x) ),那会得到一个更加接近神经元的函数,这个【后面叠加的h(x)】就称作【激活函数】!!!

2、全连接神经网络
有了“神经元”,我们就可以通过叠加多层【拟合函数】和【激活函数】组合成一个庞大的神经网络了,一个宏观全连接神经网络的大致里截图如下所示,包含了【输入层】、【隐藏层】、【输出层】
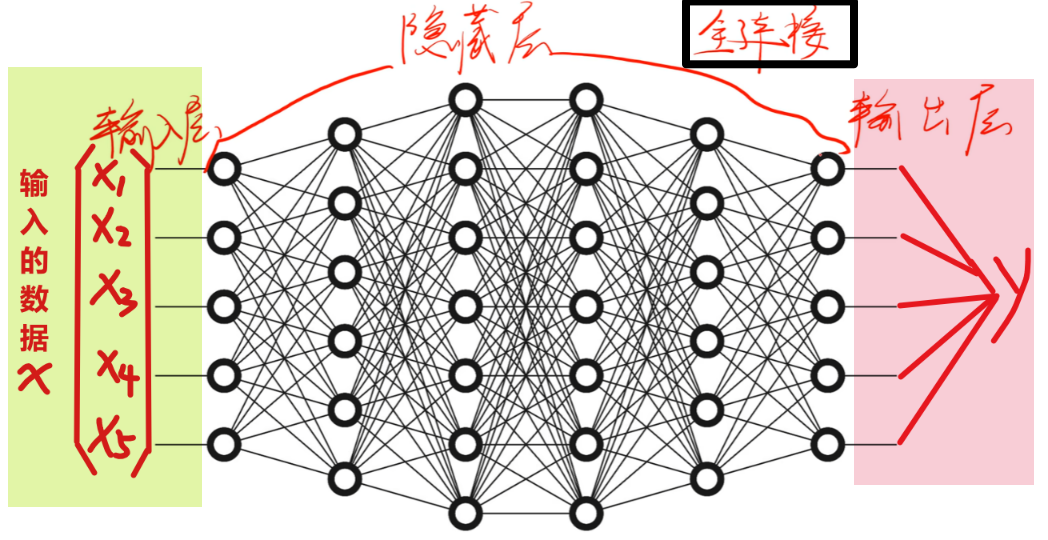
其中下图里隐藏层每一个绿色的就是【神经元:线性拟合函数+非线性激活函数】,加上一层一层的参数w、b,共同组成一个神经网络,比如:
- 第一层【拟合函数】是【Z1=W1x+b1】、【激活函数】是【A1=σ1(Z1)】
- 第二层【拟合函数】是【Z2=W2A1+b2】、【激活函数】是【A2=σ2(Z2)】
- 还有最后【输出层】也有【Z3=W3A2+b3】、【A3=σ3(Z3)】
- 最终整个式子是【y = σ3( W3⋅σ2 ( W2⋅σ1 ( W1x+b1 ) +b2 ) +b3 )】
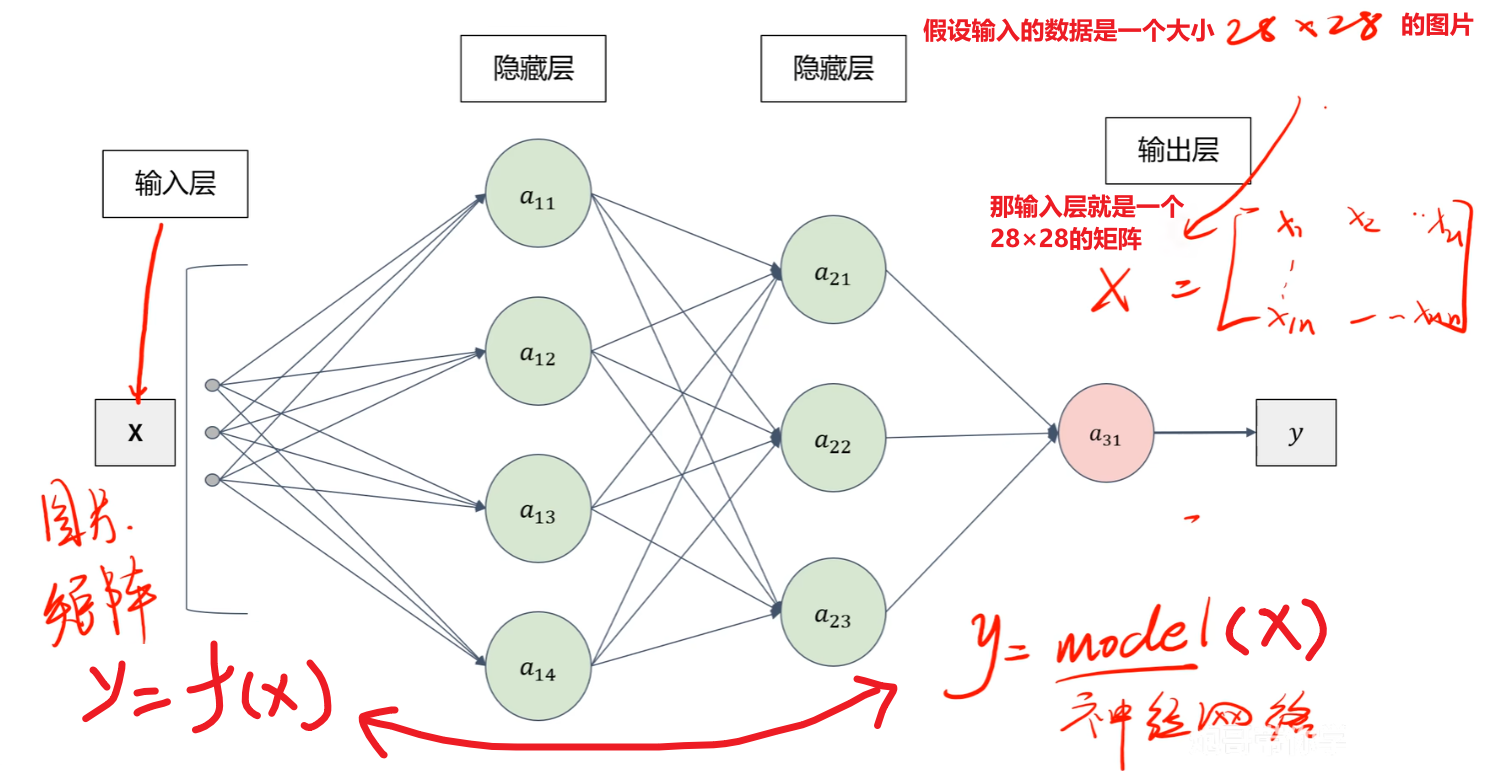
3、激活函数(简单理解,别钻牛角尖!!!)
前面在神经元那简单提了一下【激活函数】,这里要稍微细讲一下,因为首先我们不可能拆解【隐藏层里的众多神经元】,我们能做的只是优化这个【激活函数】,其次卷积神经网络和yolo里会大量提到这个【激活函数】,它必然是算法优化改进的核心、突破点!
最常见的几个激活函数就是:【sigmoid函数】、【Tanh函数】、【relu函数】、【Leaky ReLU函数】,人工智能专业的应该再熟悉不过,这里简单讲一下,非科班生讲解有不对还望谅解
1)sigmoid函数
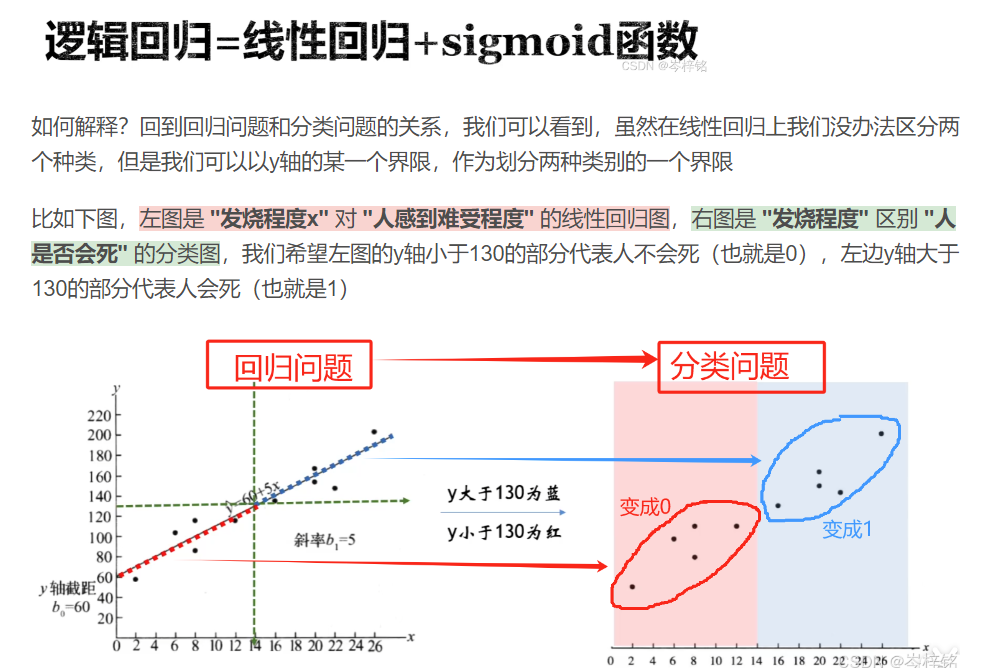
这个激活函数是专门服务于【逻辑回归】的,也就是【分类任务】
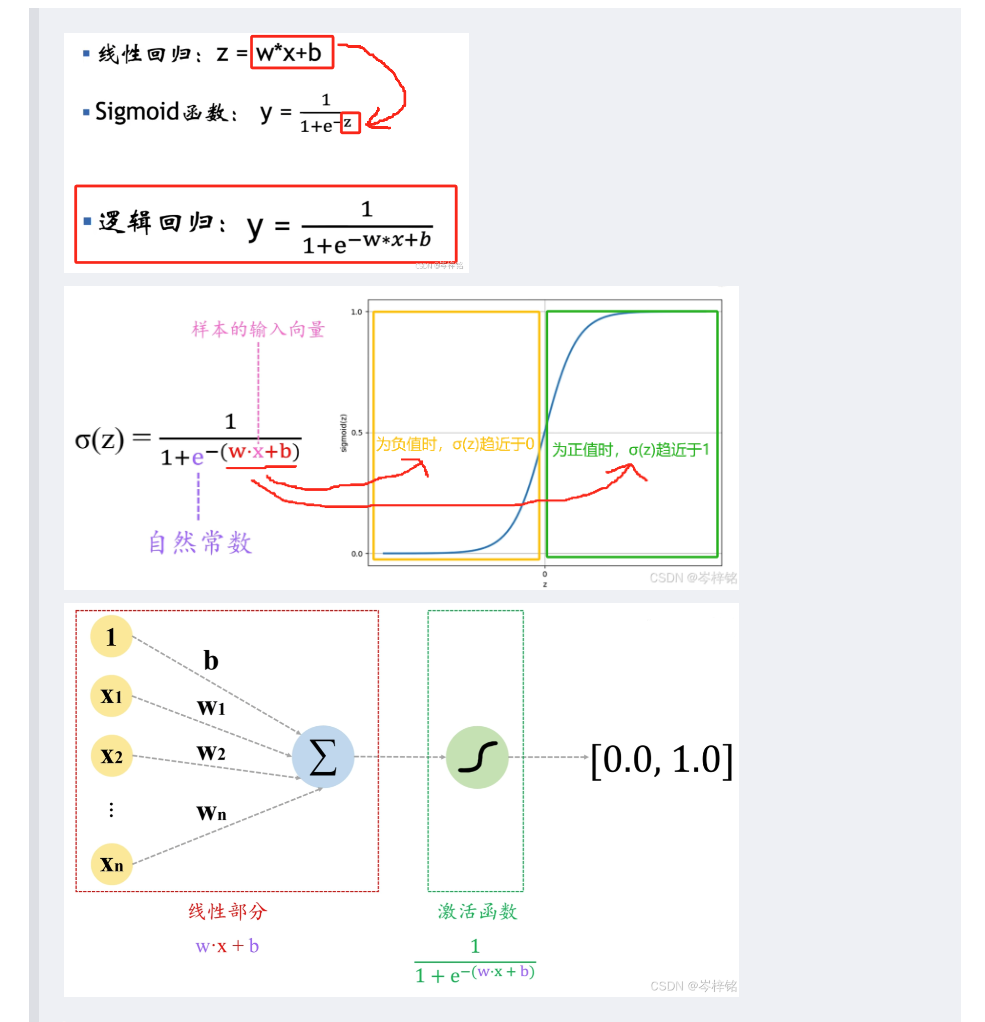
sigmoid函数通常写为:【σ(Z)】或【sig(Z)】,显而易见 Z=f(x) 就是线性的拟合函数嘛
- 函数表达式是:
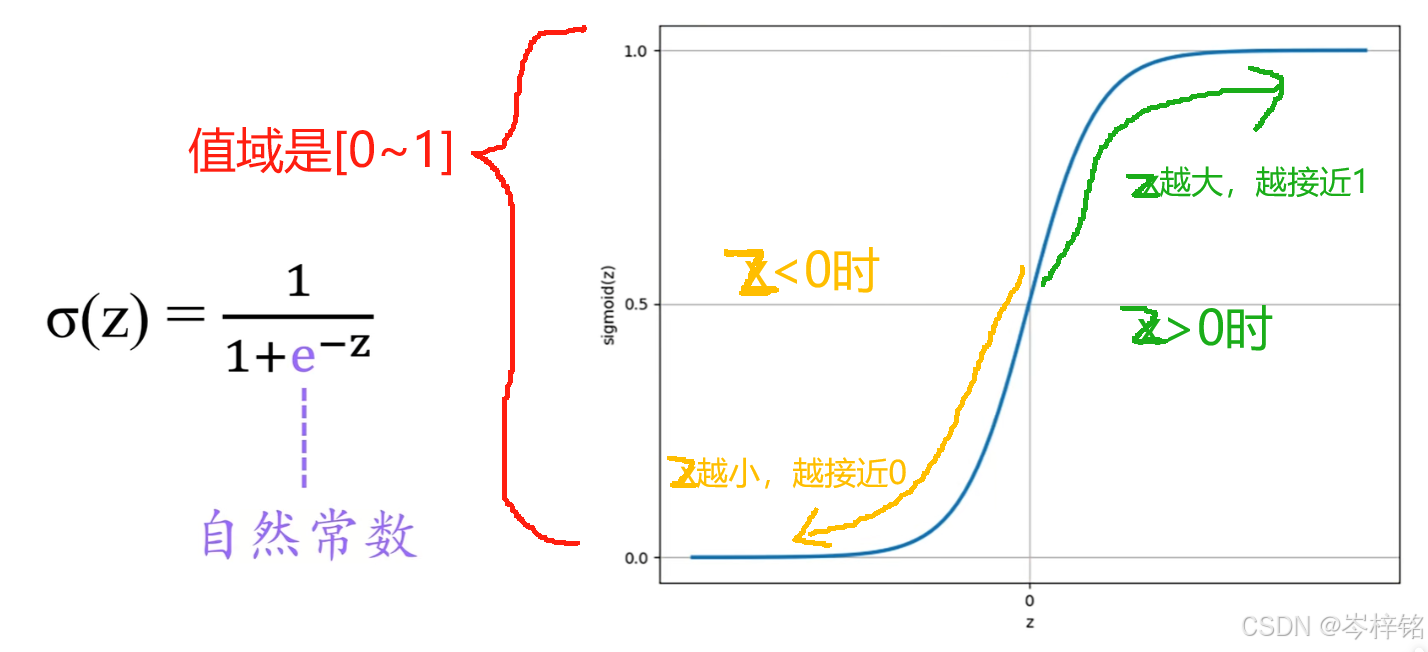
- 函数图像是:
- 值域在 [0 ~ 1] 之间
- z越大,e^-z越趋近于0,分母就越趋近于1,整体函数值就越趋近于1;
- z越小,e^-z越趋近于无穷,分母就越趋近于无穷,整体函数值就越趋近于0;
那么整体函数就是
当我们把【线性拟合函数】套入【sigmoid激活函数】里后,就能根据线性的变化,得到一个在0~1之间的曲线函数,从而根据小于0.5、还是大于0.5来判定 “是” 或 “否”
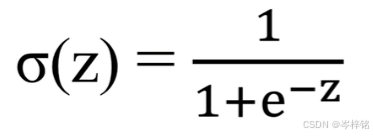
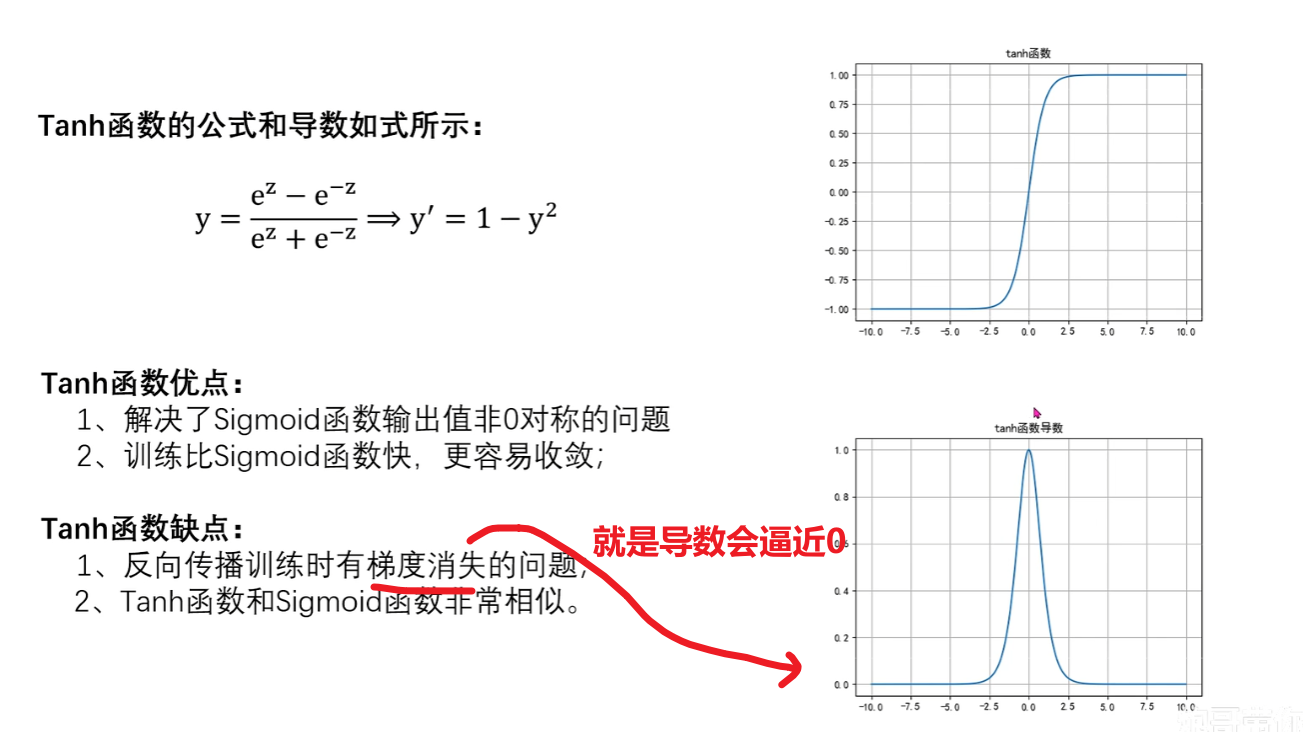
2)Tanh函数
这个函数我们只需要记住:
1、很像sigmoid函数
2、值域是在[-1 ~ 1],比sigmoid大,而且关于0对称(sigmoid是关于0.5对称)
3、各项性能整体比sigmoid优秀,具体为什么别管,我也不知道
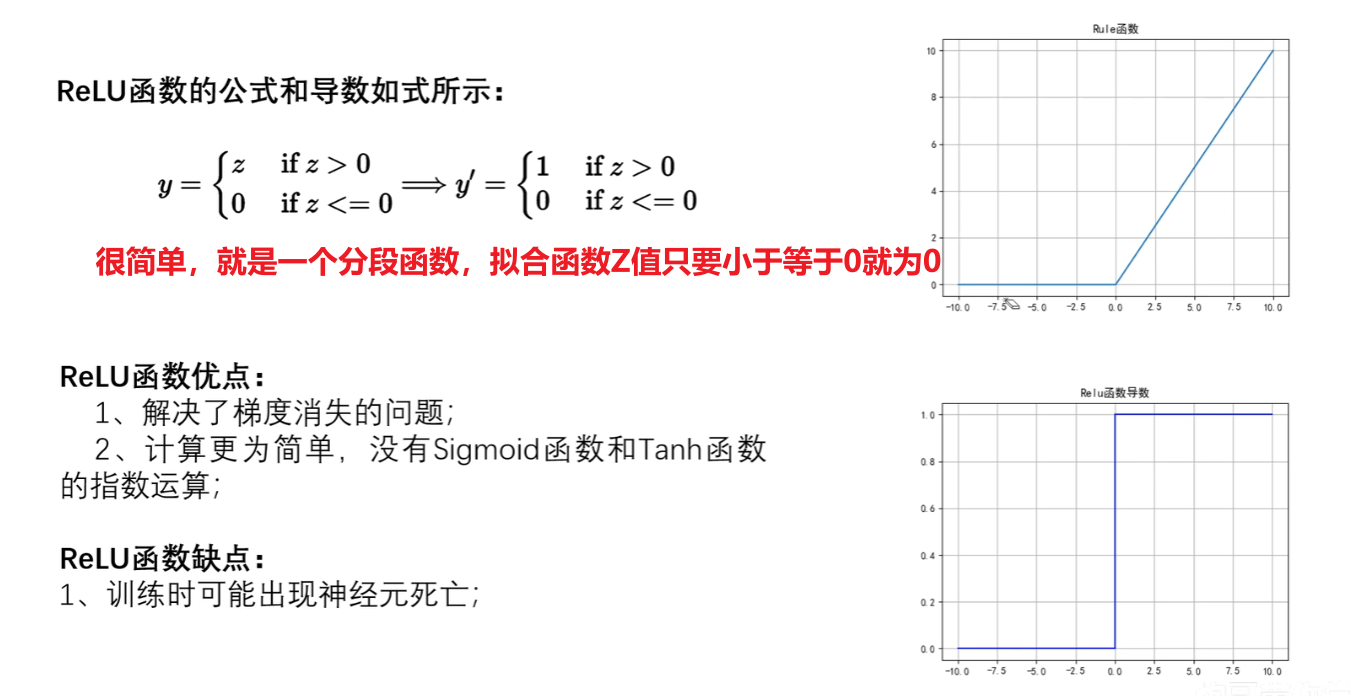
3)Relu函数
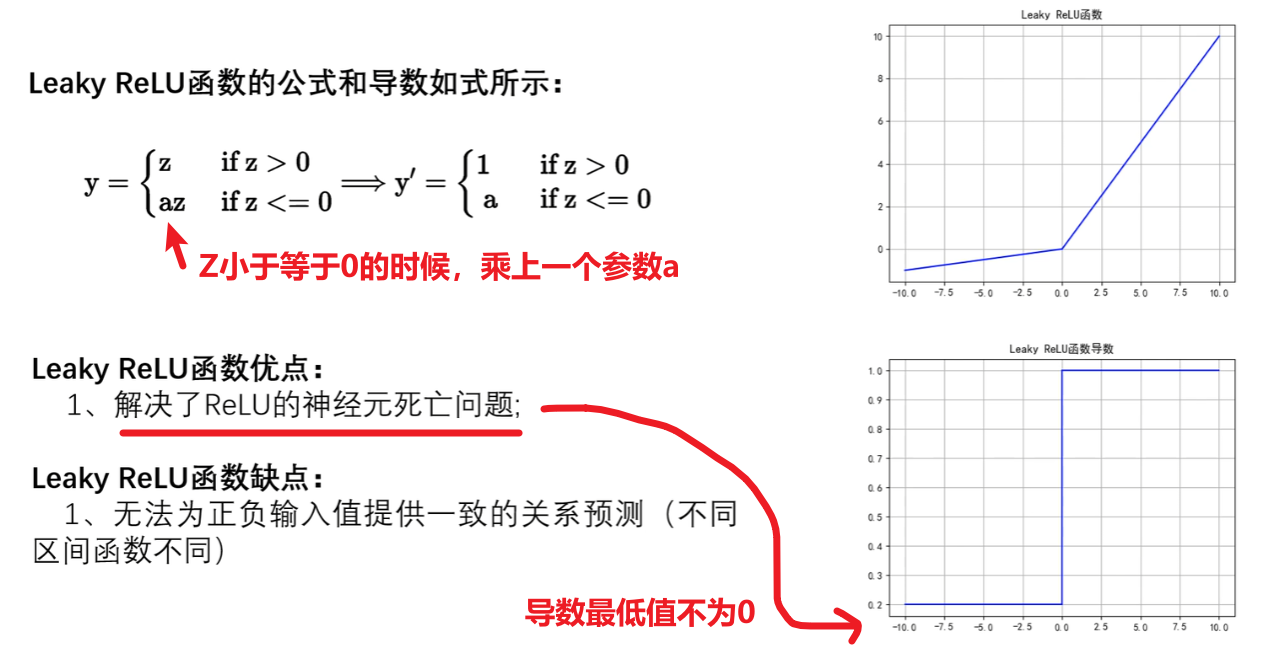
4)Leaky ReLU函数
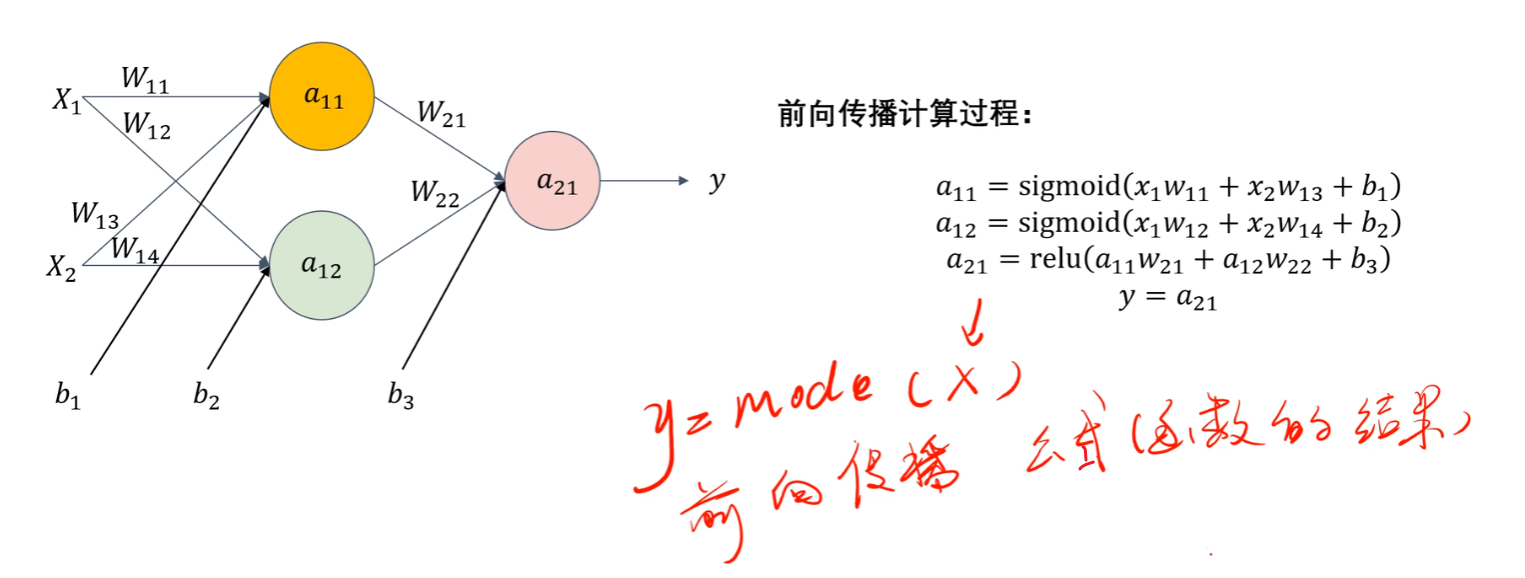
4、前向传播
有了上面的知识点后,我们就可以知道啥是【前向传播】了,简单说:【前向传播】就是 “输入数据→用前面层的输出当当前层的输入→逐层算到输出” 的过程,每一步都要做 “线性计算 + 激活函数” 的运算。知道这么个意思就够了
5、损失函数
学过高数的可以把它理解为【泰勒公式】里的 误差项O(x) ,泰勒公式就是通过不断的求导拟合,求出一个最接近原始的函数式,但是无论怎么接近都会有误差,而想要越接近,那就尽可能要让这个误差越小
对于机器学习,我们判断误差的方法就是我们前面学YOLO的时候,用真实标注到的label,来跟模型训练后的结果做对比,不断地优化损失函数来达到一个最合适的模型
;
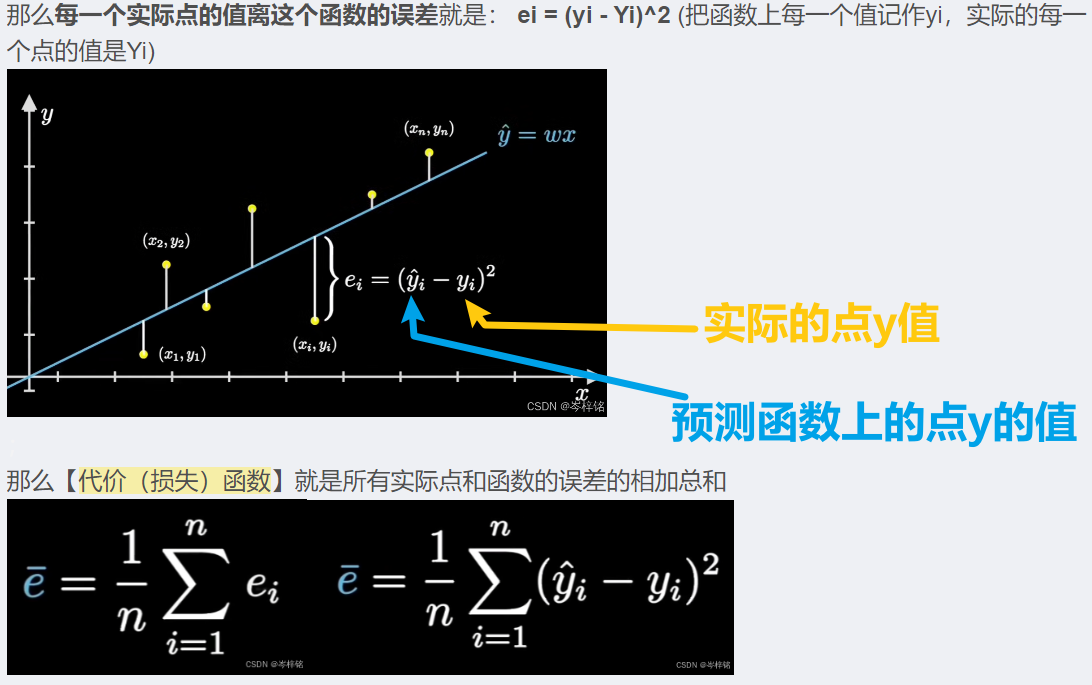
具体公式叫:【均方误差公式】
简单理解就是求【模型函数每个点 和 实际点 之间的差别的平均和】,考虑到负数正数相加会出现0的情况,所以采用平方的形式来把负数变成正数,整体所有的值都平方
我的链接文章有详细讲为什么这么计算,不想看的话记一下下面这个图就行了
注意:左边右边的式子是一样的,只是一个乘了1/2而且没有化解开,右边是化解开的,所以在论文中看到不同的损失函数不用怀疑,无非都是下面左右两种式子的一种
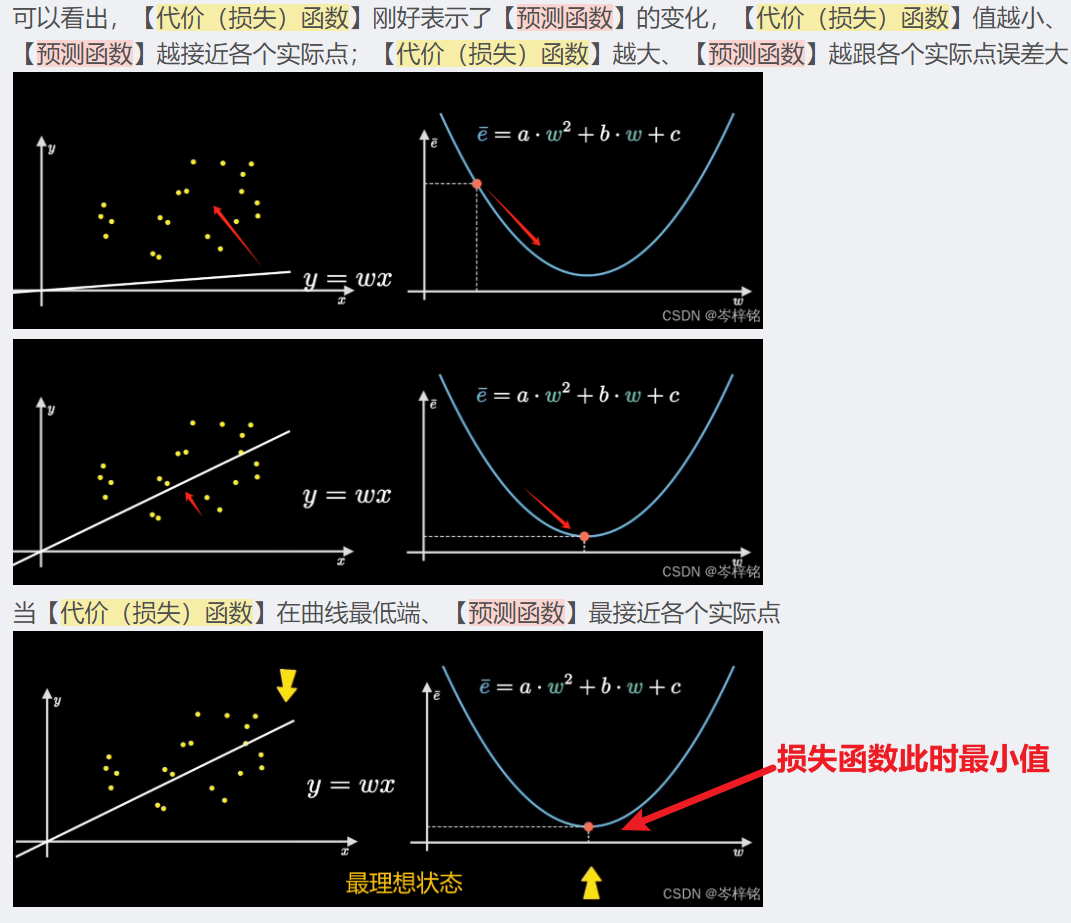
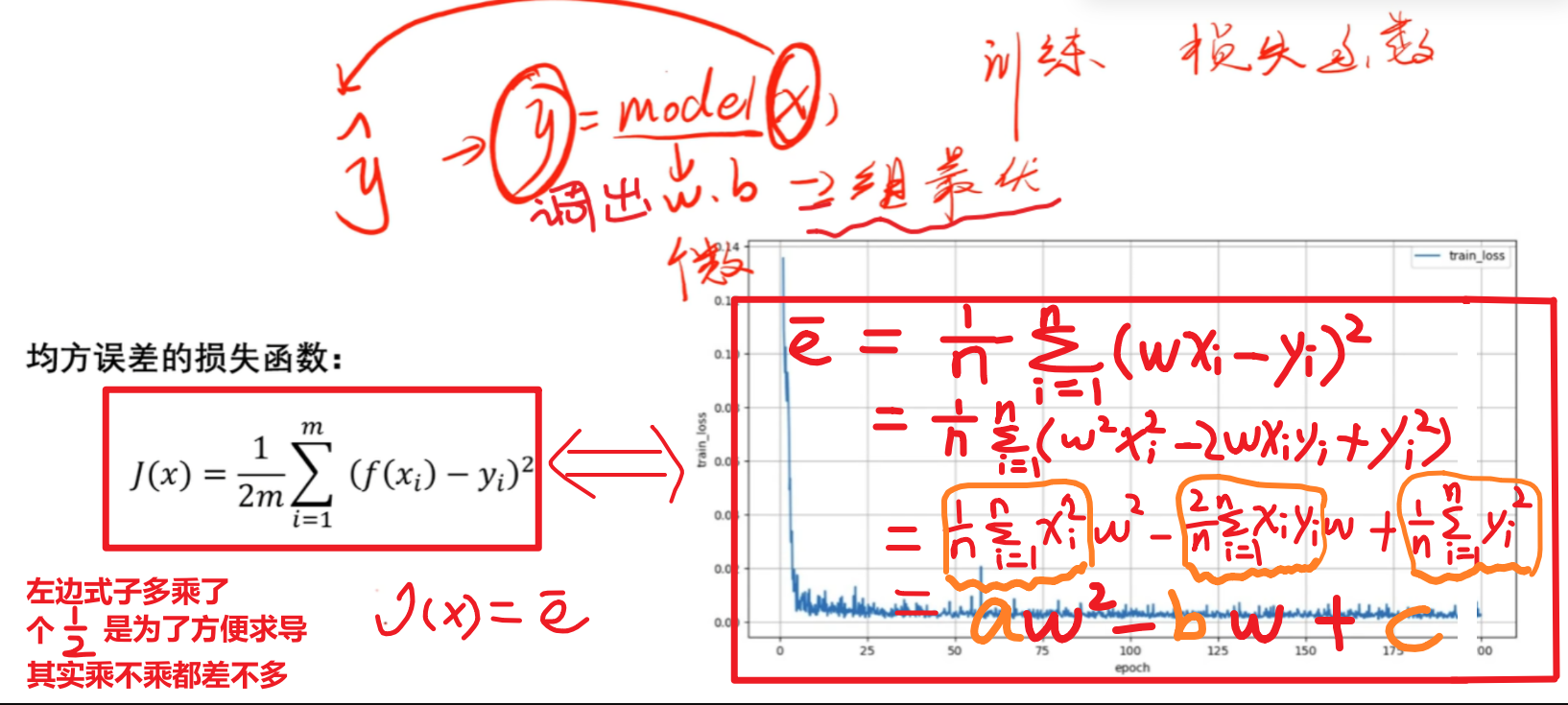
6、梯度下降法
依旧是我链接那篇文章讲过的,很基础的东西
;
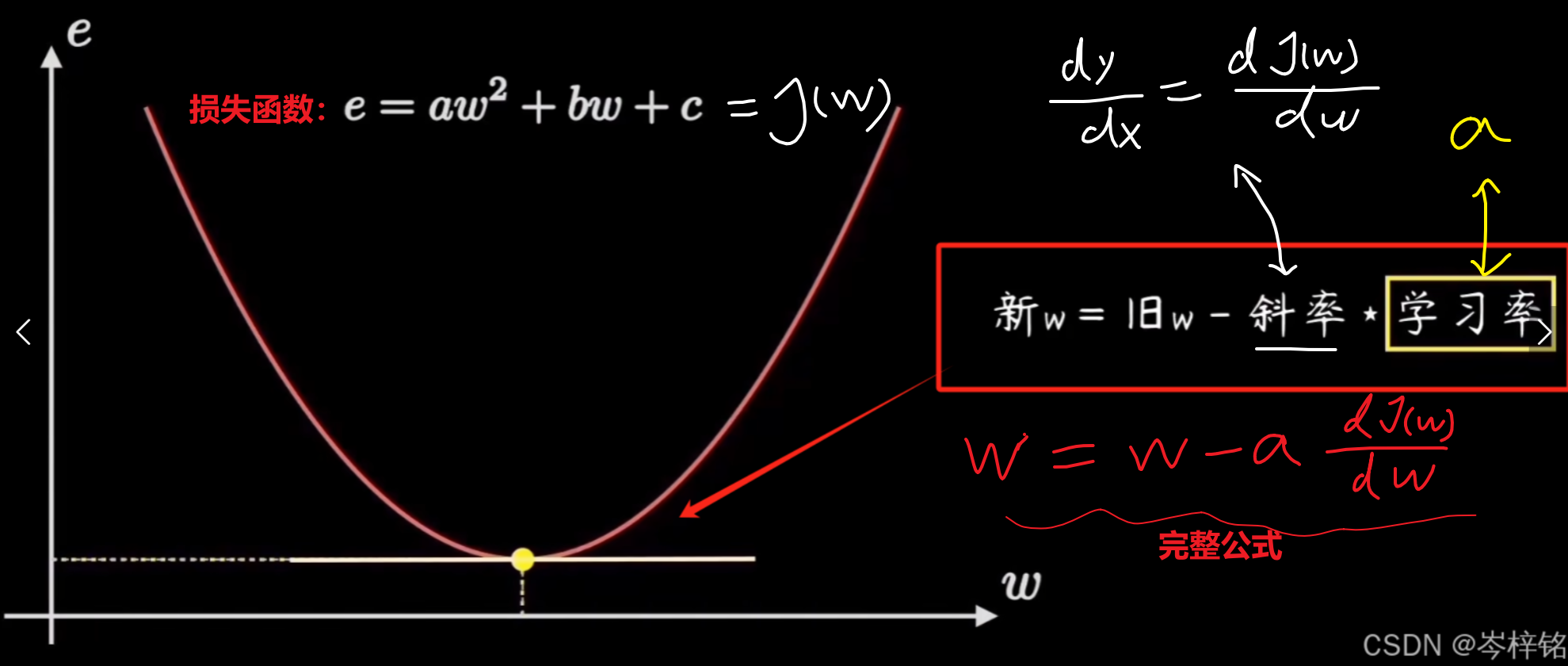
所以归根结底,完整的梯度下降算法公式就是下图这样
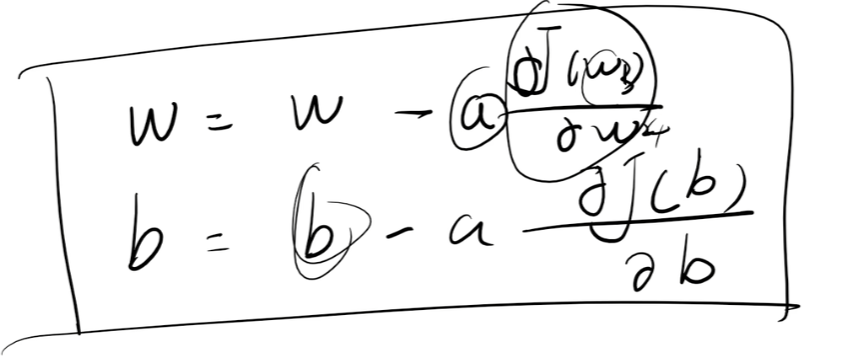
对于参数b也是一样的调整公式:
记住我的这个总结:
- 因为我们要求出完美的激活函数,就需要一个完美的损失函数
- 而损失函数怎么才能达到完美没人知道,也没有公式一步得到,所以只能调整损失函数里的参数【w】和【b】,也可以叫他们是步长,每一步要调多少才能让损失函数的值最小?
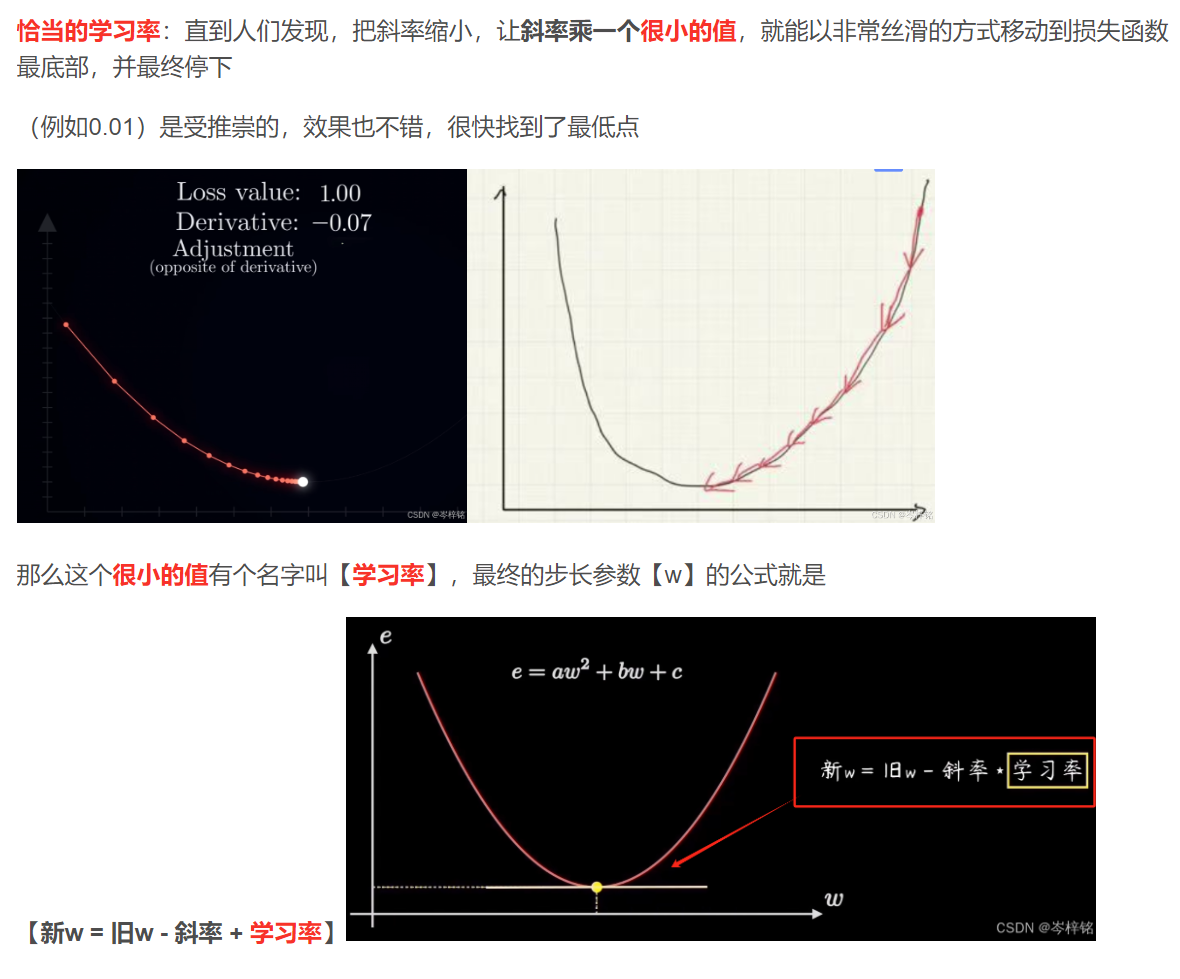
- 那就是用梯度下降算法,w = w - a * dJ(w)/dw、b = b - a * dJ(b)/db
- 其中学习率a也得是一个人为手动设的一个很小的值,若a设置的刚刚好的话就能求出一个完美的参数w和b步长,让损失函数值以很丝滑平稳的节奏速度降到最低,也就是损失函数斜率接近0的地方(变化率最小,损失函数变化、斜率 最平稳)
- 如果我说的这一套流程能理顺就够了

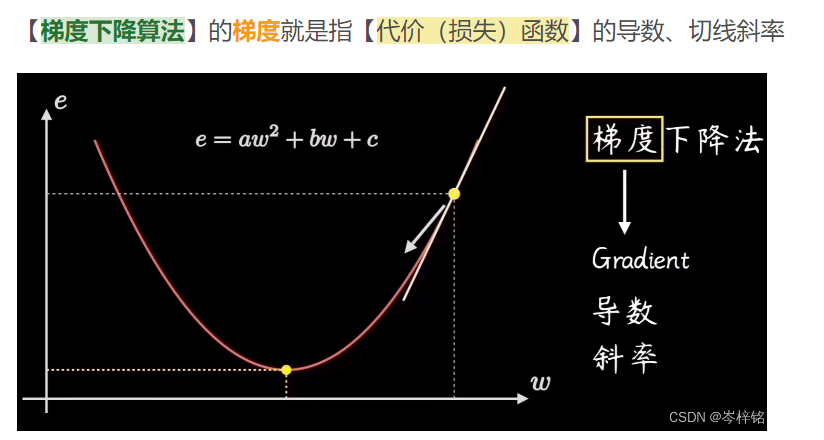


7、反向传播
1)再次回顾【前向传播】
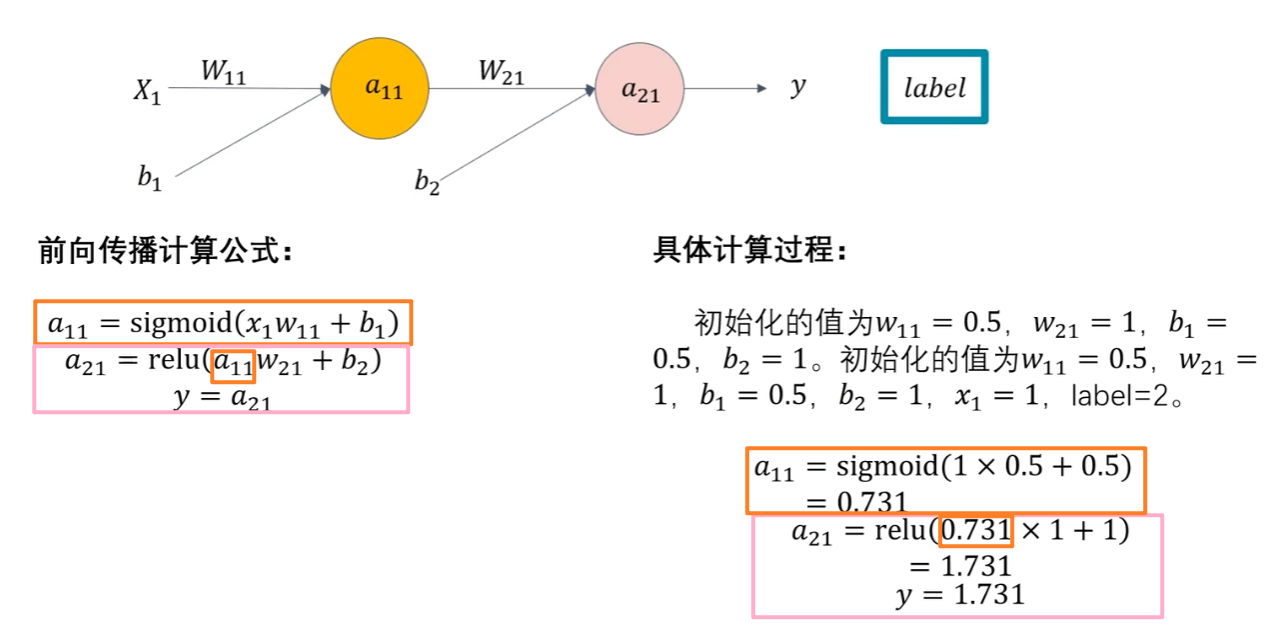
前面我们说过前向传播就是一层神经元套一层神经元,最终得到的是一个超级复杂的【复合函数(激活函数)】,输出这个【复合函数的值(预测值y)】
2)反向传播中的【求损失函数的导数】
那我们说过想要让这个激活函数完善就得通过【梯度下降】求得【最优损失函数】,公式是 w = w - a * dJ(w)/dw、b = b - a * dJ(b)/db 嘛,那其实这个导数【dJ(w)/dw】其实就是对【一层神经元输出的 y预测值——> 求得的 “损失函数” 的求导】
我们可以把【损失函数J(w)写成 J(w) = f(y)】更方便理解,而【y又等于a12这一个神经元的输出】、【a12又等于一个激活函数例如ReLU(h(x))】、【h(x)又是一个拟合函数a11*w21+b2】,所以J( w ) = f( y ) = f( a12 ) = f( ReLu( h(x) ) ) = f( ReLu( a11*w21+b2 ) )类似这样的一个复合函数形式!!!反向传播就是要对每一层神经元的这样的复合函数求导!!!!!(J(b)也是一样,J(w)、J(b)都是根据输出的预测值y求得的损失函数,然后调整参数w、b)
我知道【dy/dx】的公式让人看得很崩溃,那么换成【y '】的复合函数求导就会清晰一点
同理,我们可以接着求出【a11】这一层神经元的【损失函数的导数】

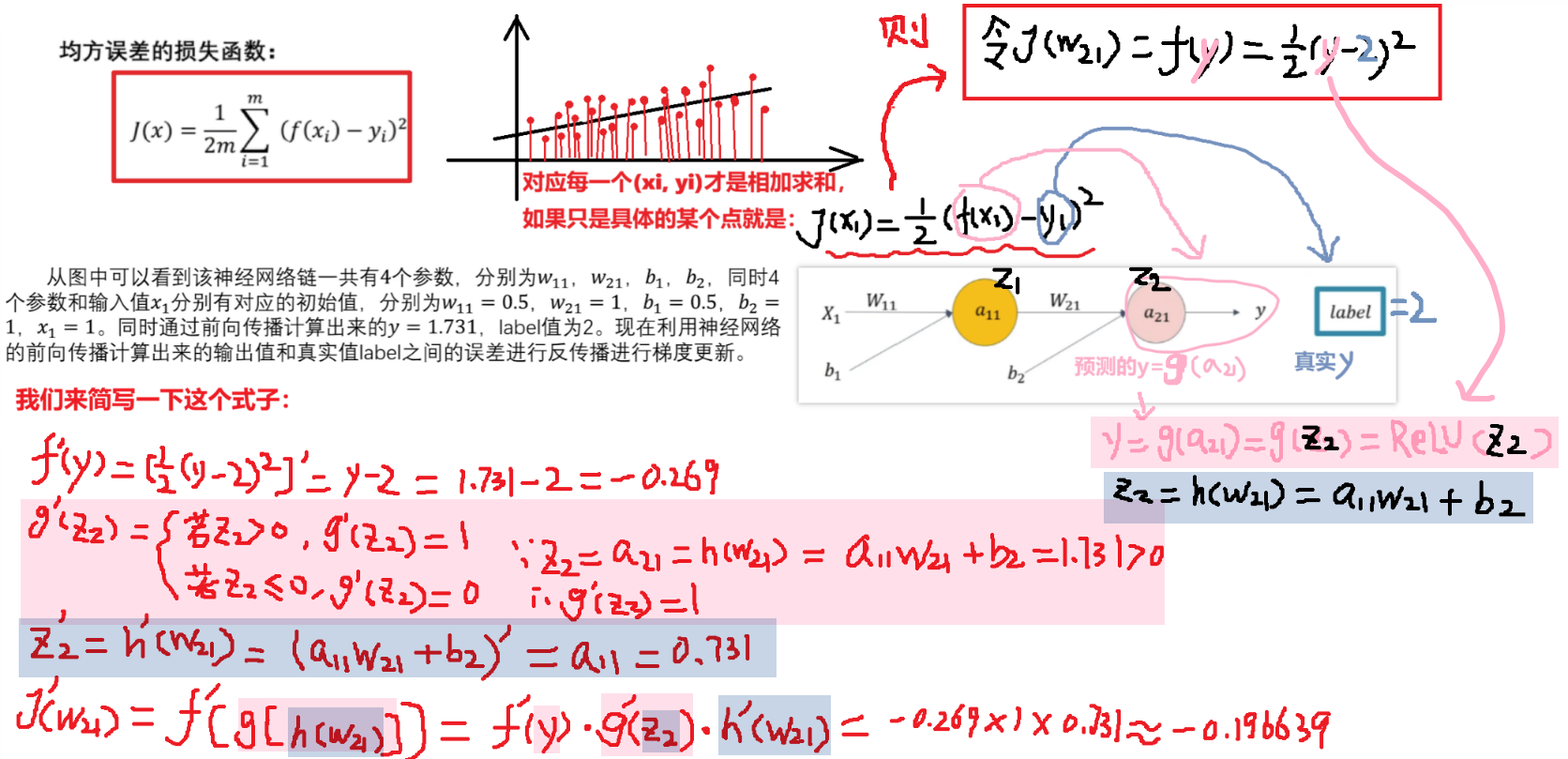

3)反向传播的【更新参数w、b】
这样一来我们就得到了 w = w - a * dJ(w)/dw、b = b - a * dJ(b)/db的【导数部分:dJ(w)/dw、dJ(b)/db】,然后我们就可以手动随便设一个很小的值【a:作为学习率】,从而算出新的参数【w】、【b】
然后再回到开头,用这些新参数进行【前向传播】,再次比较输出的【预测值y】和【真实值label】的差别,也就是【损失函数的值】,以此类推
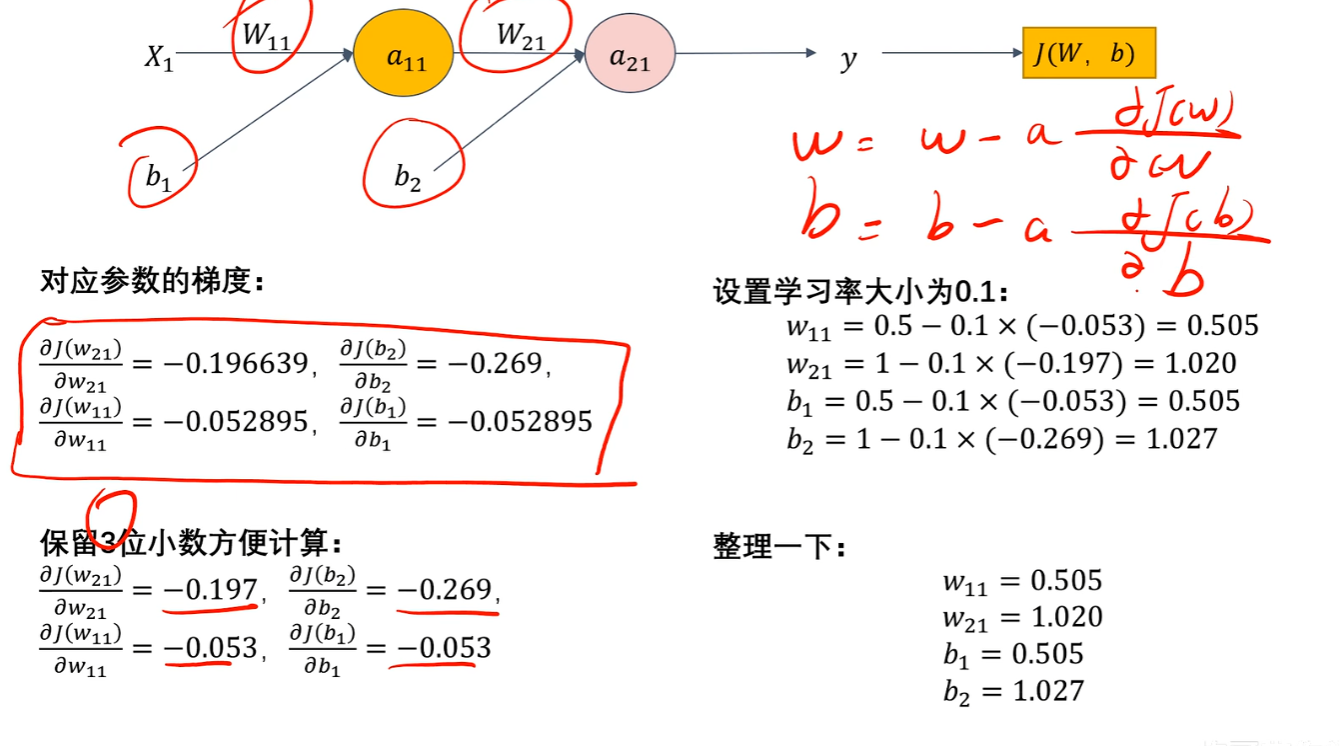


8、总结
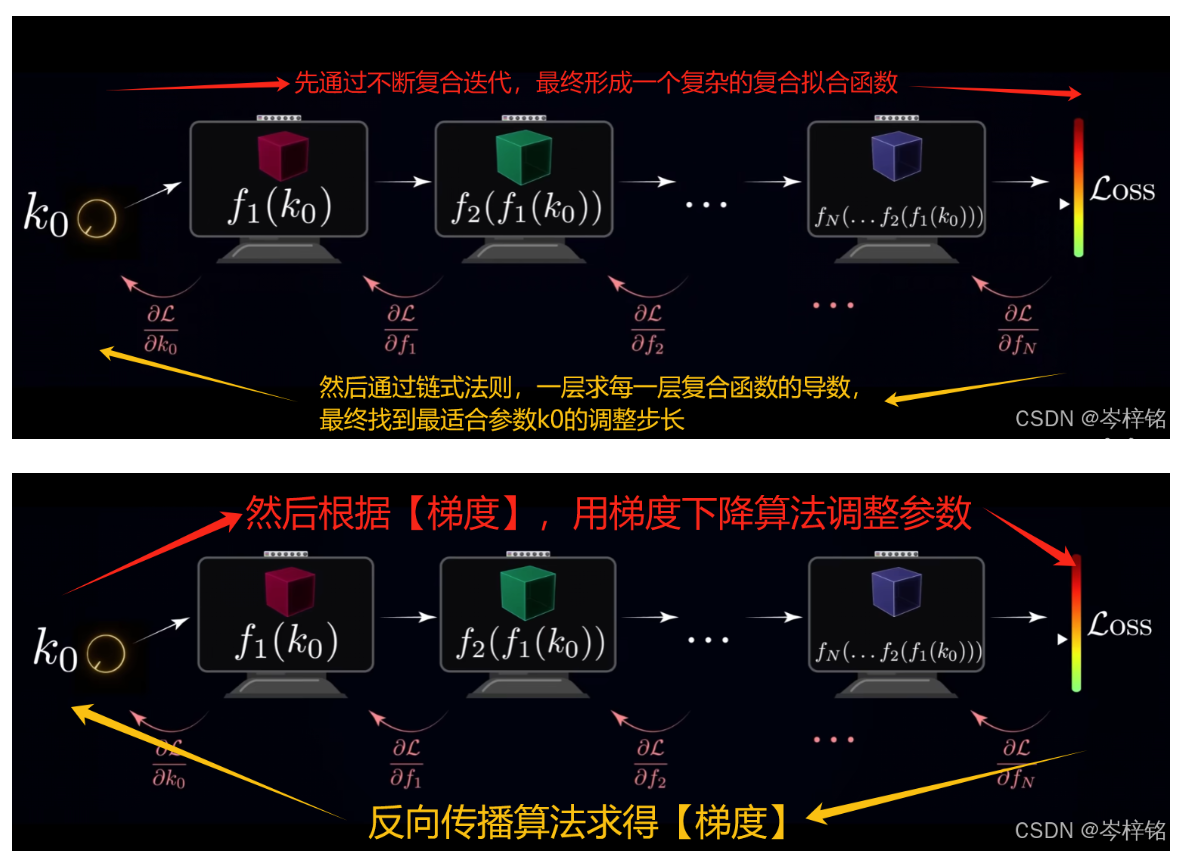
前面的公式不会算也没关系,因为计算流程科学家早已在底层写好代码逻辑,是机器代替我们计算,我们只需要知道为什么要手动调整一些【学习率参数】、【训练轮数】、【训练批次】....这些参数,上面的公式就是给你沥青整个流程
简单来说整个神经网络训练流程就是下图这样:

三、卷积神经网络CNN
1、为什么有了神经网络还需要卷积神经网络
讲了最基础的神经网络,就正式可以开始卷积神经网络CNN!!!
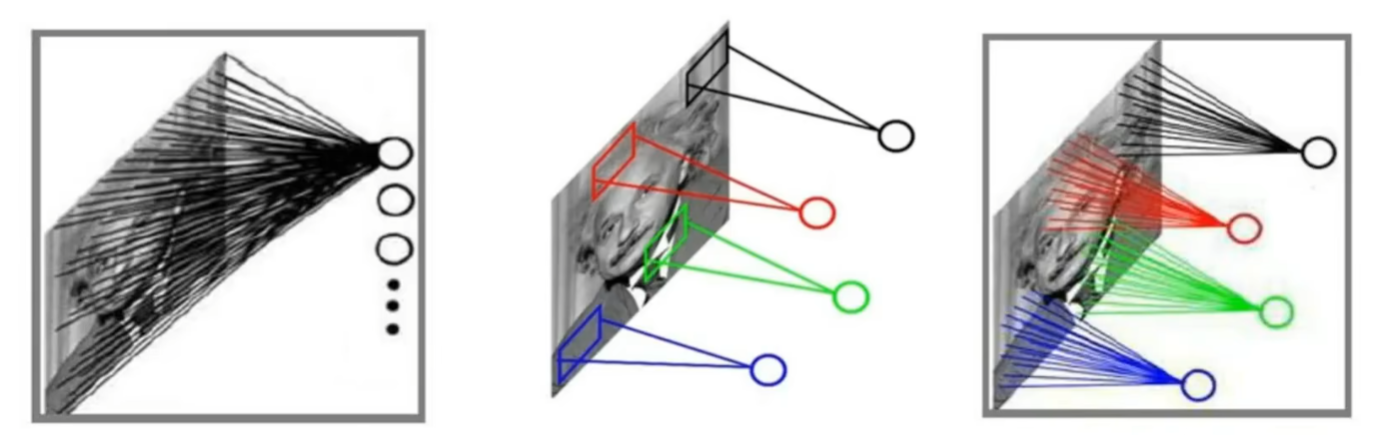
我先用最直观的效果解释为什么会有CNN,因为前面说了,神经网络是一股脑把输入数据X全给神经网络,然后整体一起计算,那么对于后续人工智能领域最常用的一些图像处理就很不合理,因为图像处理的原理是对图像进行【特征提取】,简单说就是:
- 【参数量】
- 或者1个高中生一天完成高中各科所有作业,结果效果很差
- 或者1个高中生分几天分别完成高中各科部分作业,知识能够充分吸收
- 【局部相关性】和【人的观察习惯】
- 神经网络NN看一个人是360度无死角的扫射,全身上下扫一遍;
- 而卷积神经网络CNN更符合人类习惯,先第一眼捕捉一个人的特征,比如美丽的脸蛋、浮夸的发型....然后再看一遍这个人的整体;
- 而且既然要特区特征值,一个特征值肯定只有在局部才有意义,比如左眼的局部像素值和右眼的局部像素值相似,而跟其他部位的像素值相差明显;而全局的各个像素点就只是一堆无意义的数值,肯本体现不出任何意义
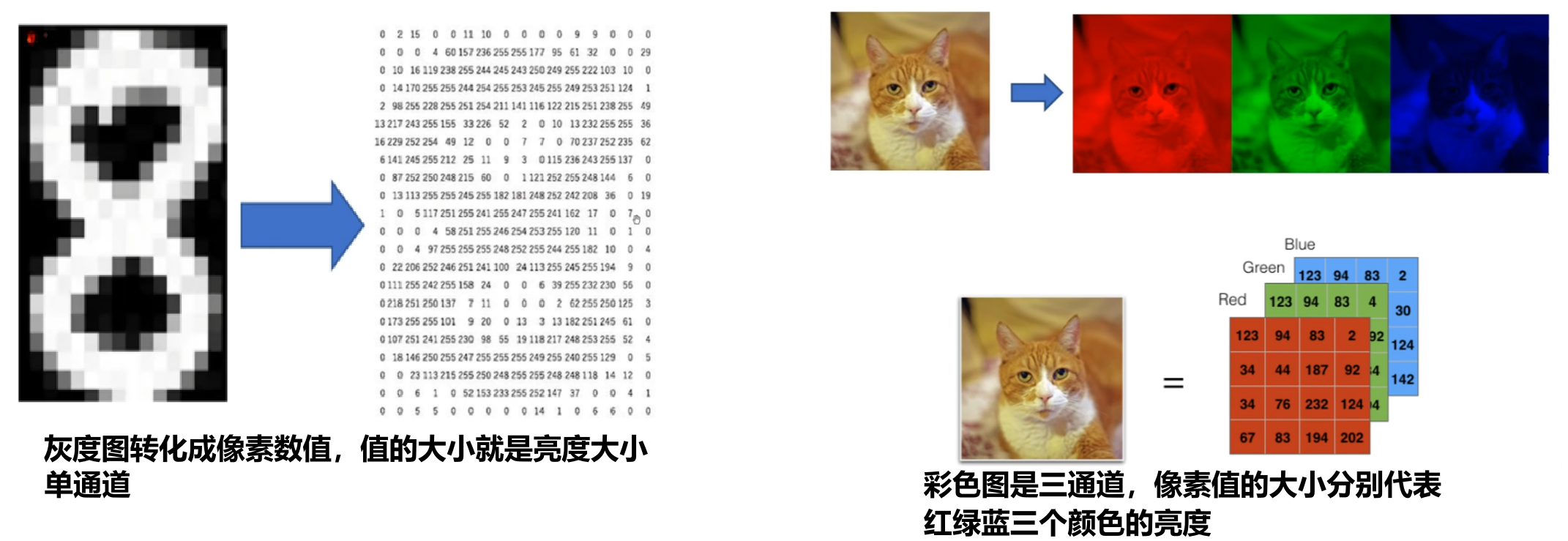
2、卷积神经网络能处理彩色三通道特征提取
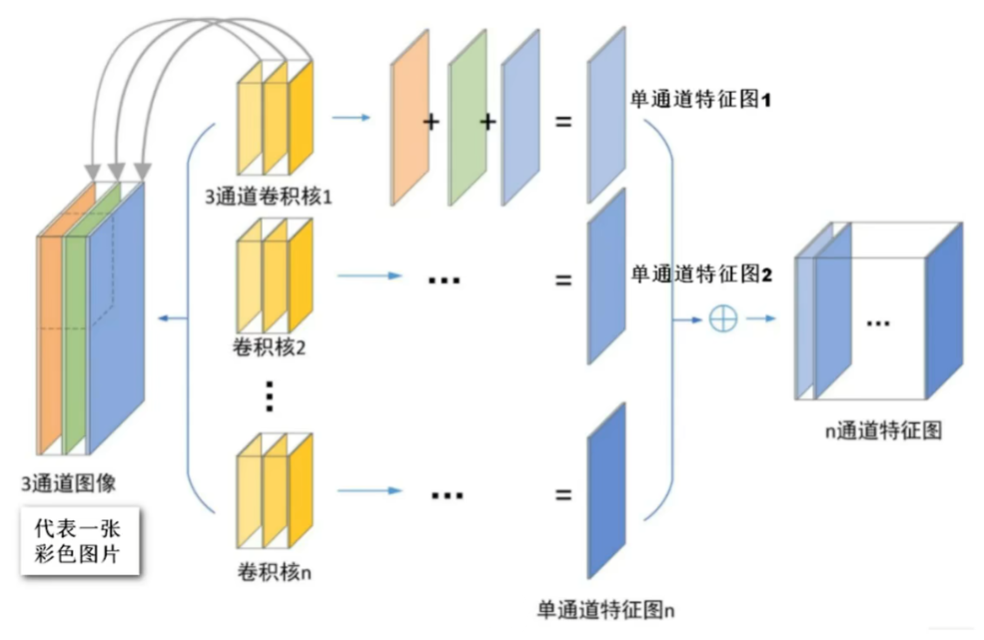
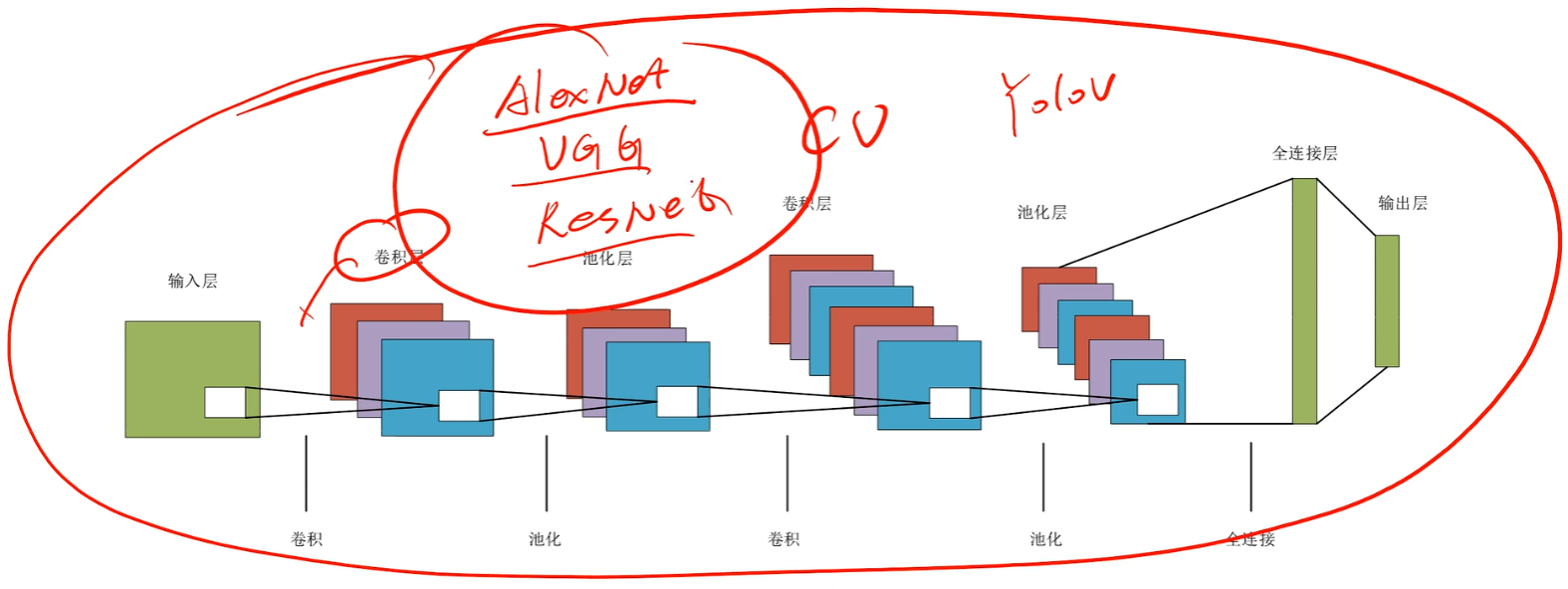
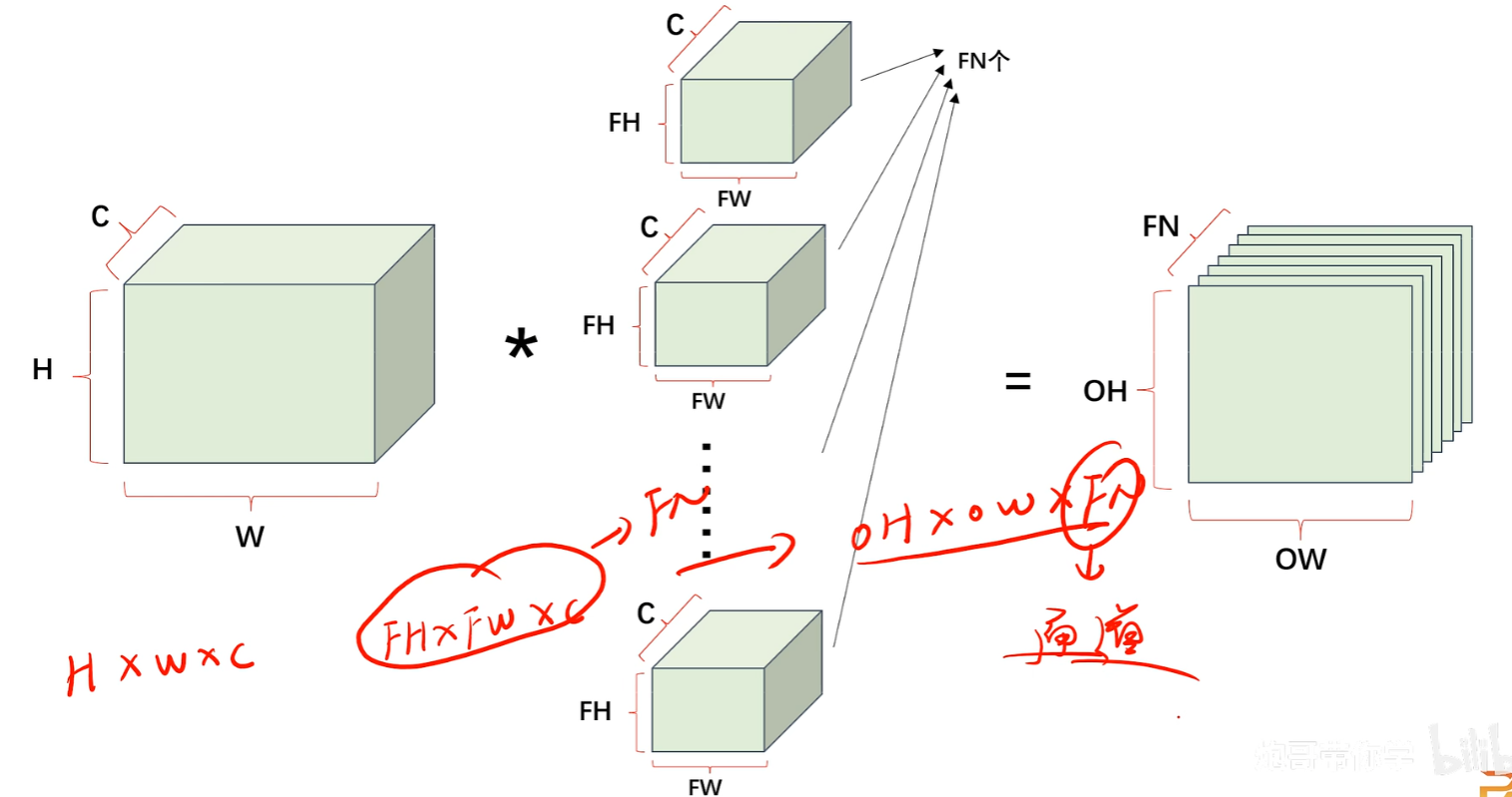
3、卷积神经网络宏观结构
其中卷积层的每一个卷积核会把【提取的特征数据】映射到后一层的【featuremap】,【featuremap】又往后继续投射优化后的特征值给后一层【featuremap】
;
注意【Featuremap】和【Filter】和【卷积核】的概念:
其实【卷积核】就是【filter】!!!!有的教材里喜欢叫 “卷积核”,有的会叫 “滤波器Filter”,但其实就是一个东西!!filter就是输出featuremap的工具,卷积核(filter工具)提取的特征值经过计算过滤,然后才投放到featuremap上作为结果


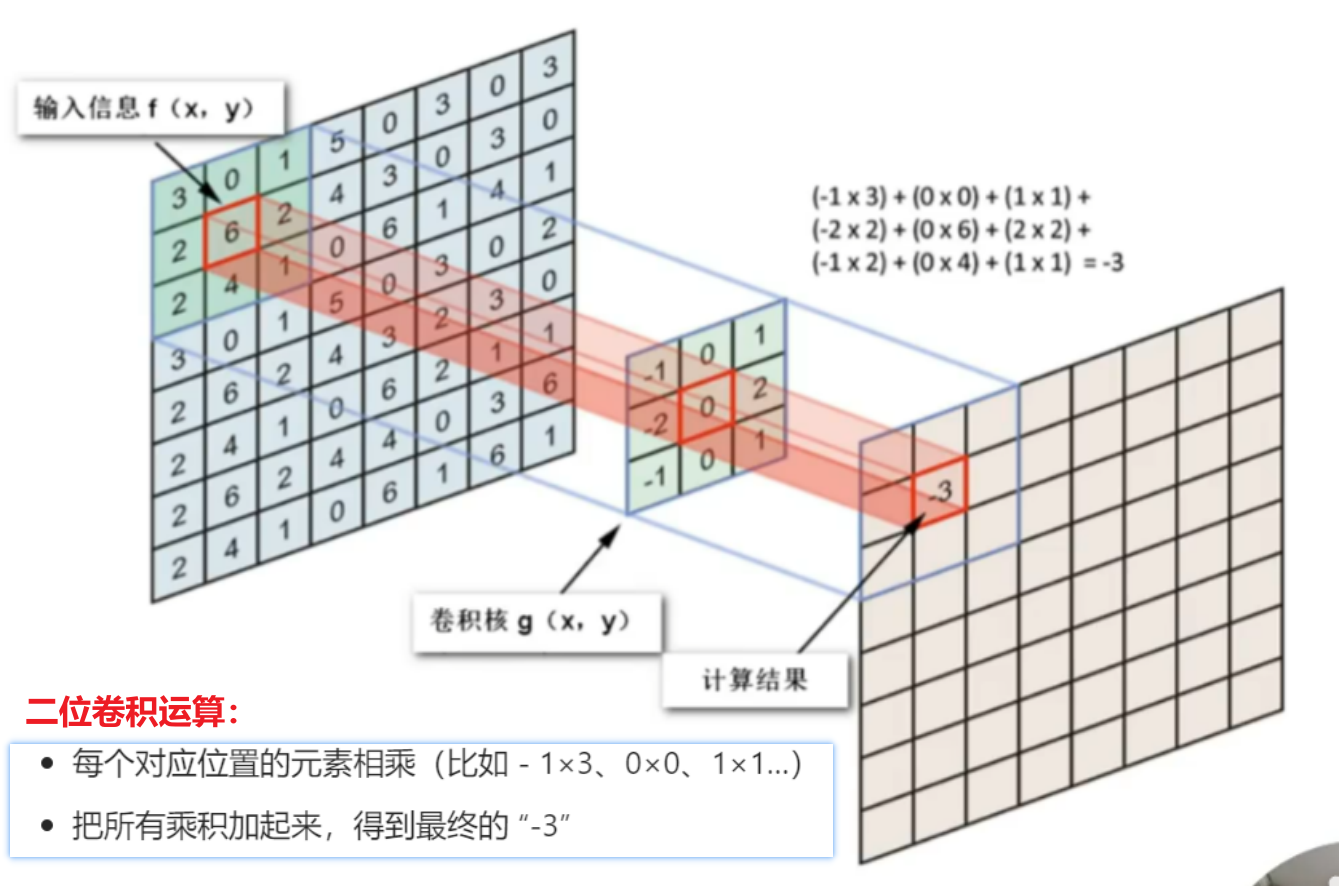
4、卷积的计算方式、参数、特性
多层的话就是多个结果相加
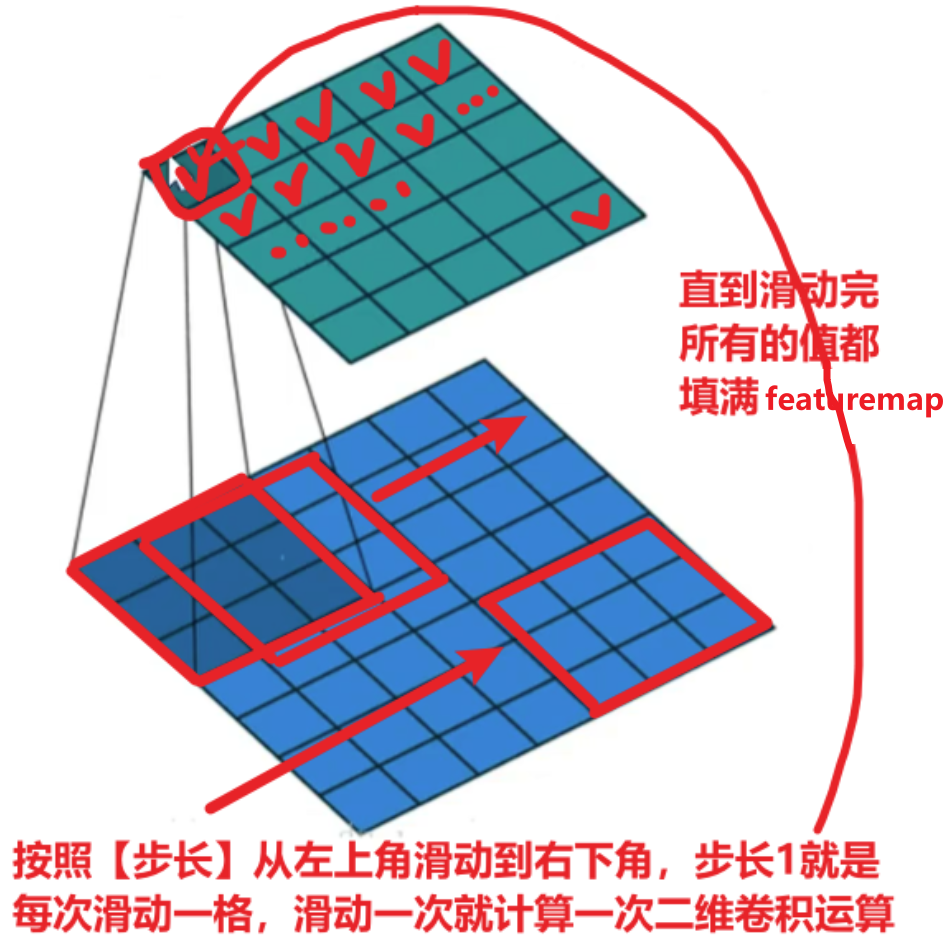
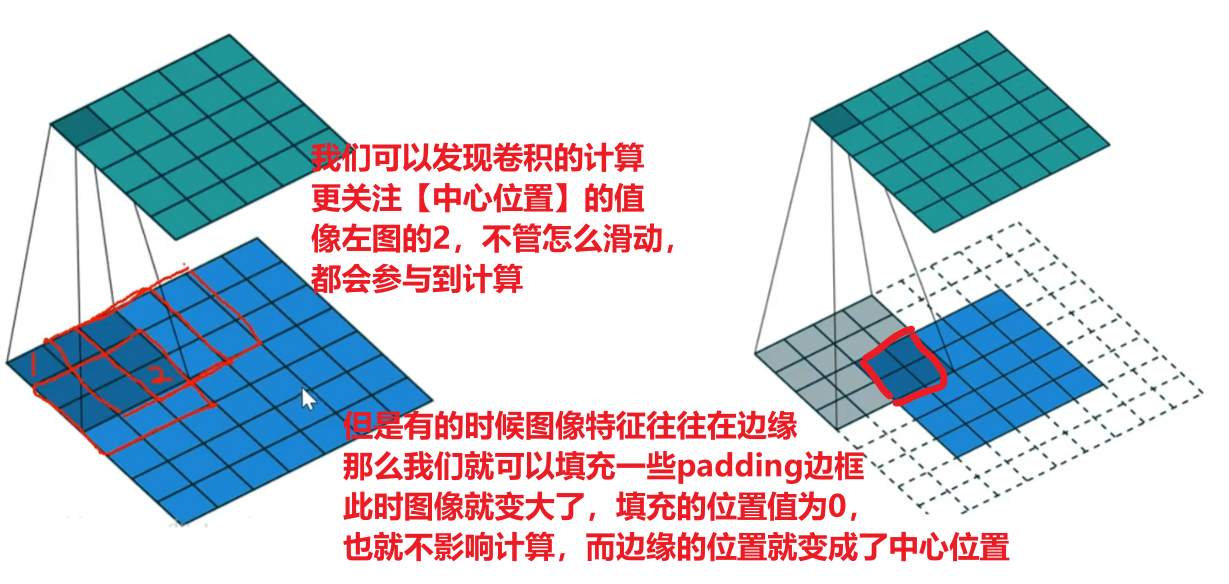
【padding填充】和【stride步长】
看下图可以理解,padding不仅可以调节输入图像尺寸、featuremap与输出尺寸以外,还可以兼顾到图像边缘的特征值提取
而stride步长则是调整featuremap获取到的特征值大小,如果步长太大,图像几步就被滑动结束,那么滑动一次给featuremap记录一次值,就会导致featuremap的值很小,而步长太大,图像要很多步才滑动结束,featuremap的值会很大
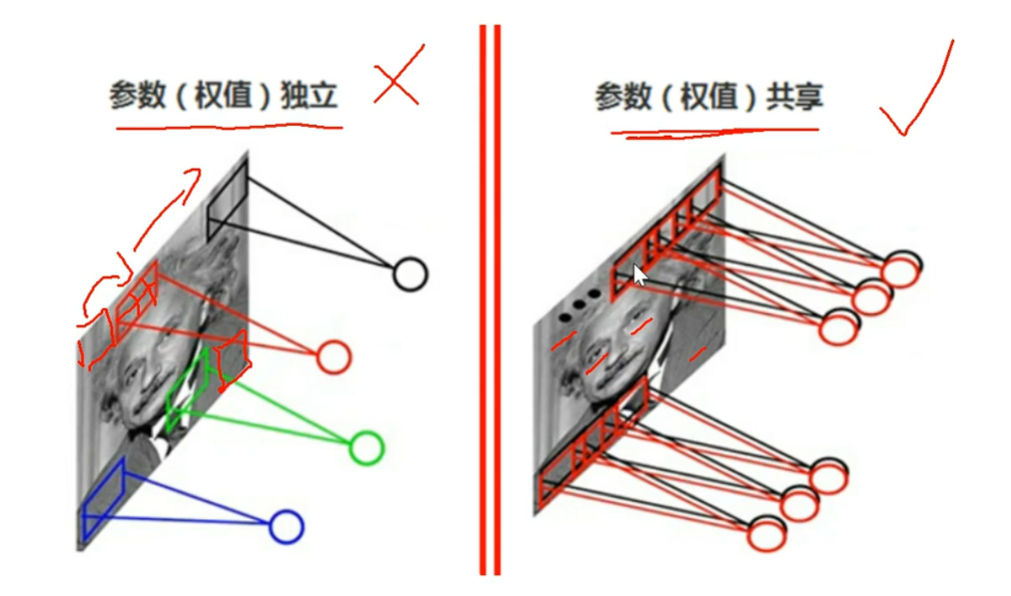
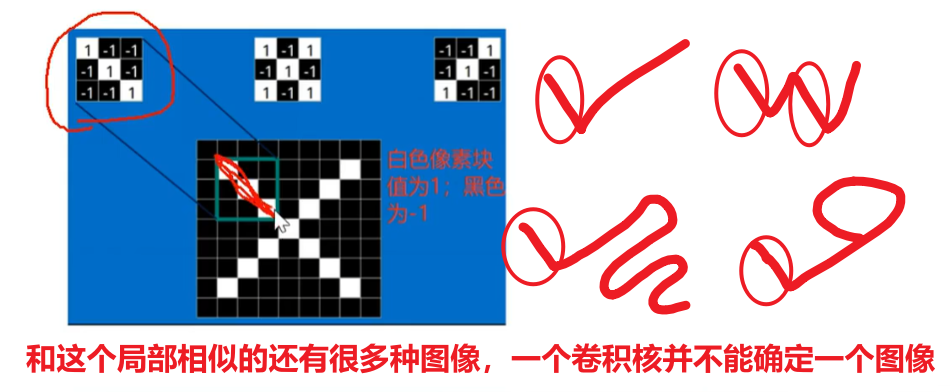
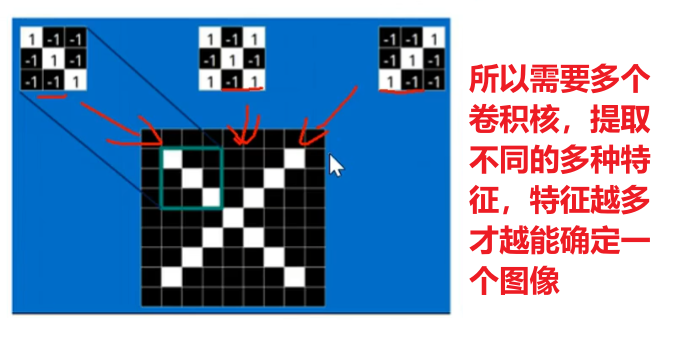
然后记住,卷积的一个特性是【参数共享】,也是【平移不变性】,是为了模仿人类在变换视角的时候对图像特征的捕捉保持不变。当然这里要补充一个知识点:【1个卷积核只进行1种特征值提取】,比如一个卷积核负责提取【眼睛】这个特征,那么从图像头滑动到最尾,它的一切获取的值都是在为认识【眼睛】而服务,具体怎么做后面讲
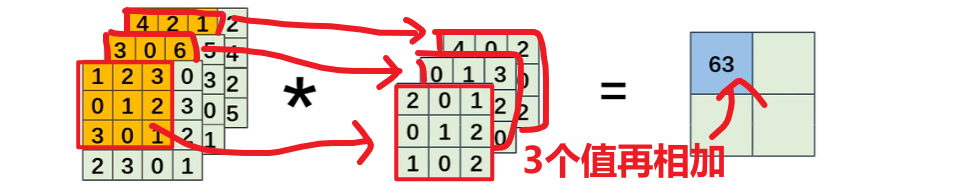
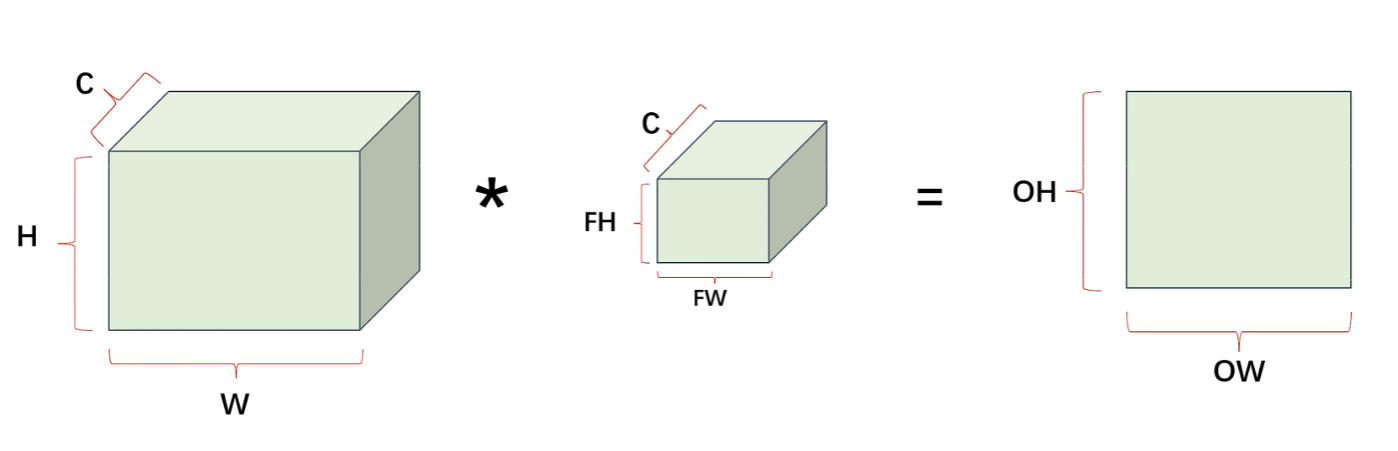
5、特征提取
那么特征值究竟是怎么提取的?
首先我前面说过:【1个卷积核只进行1种特征值提取】
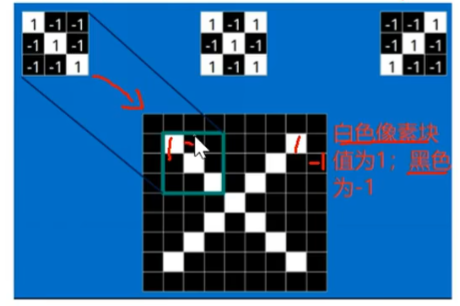
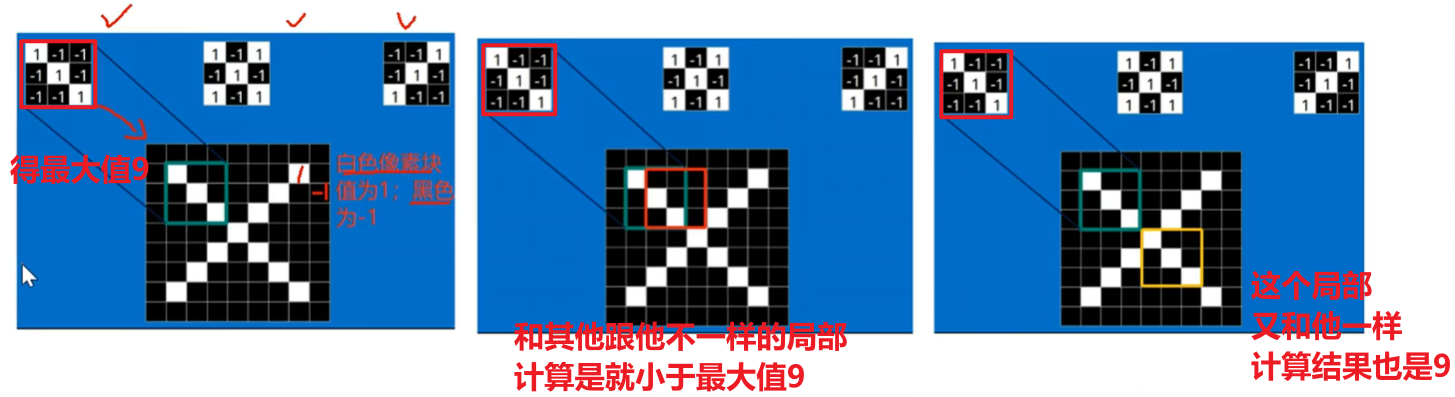
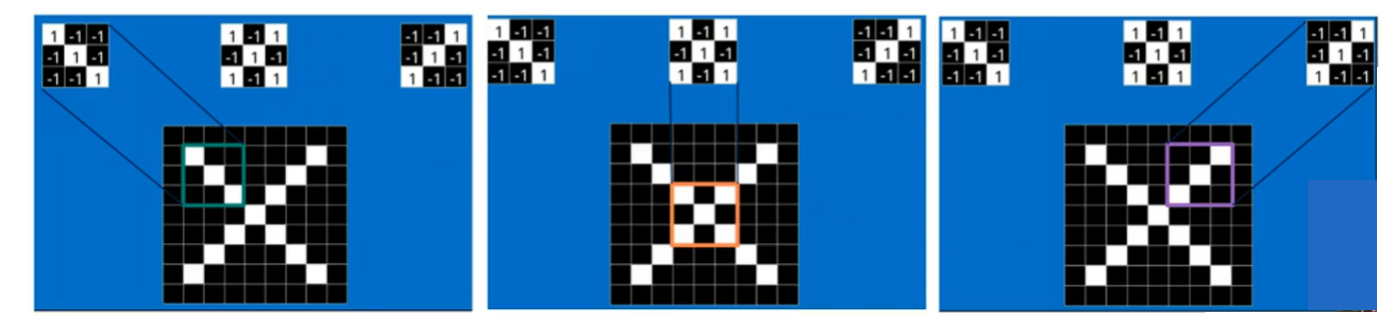
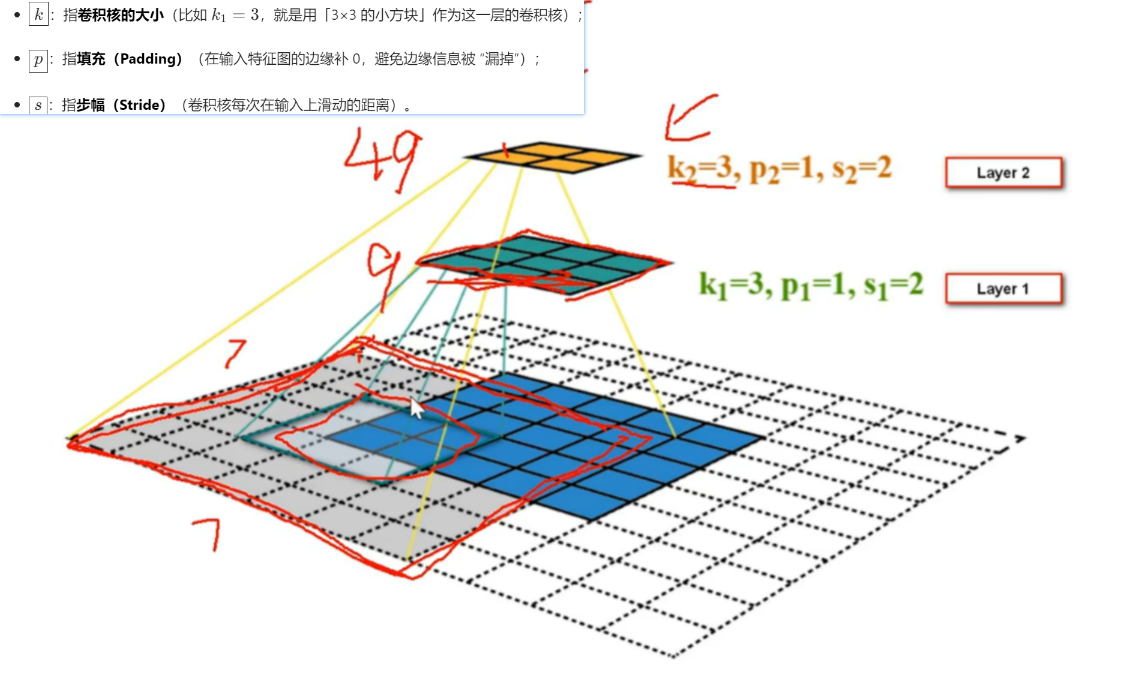
一个卷积核是电脑随机生成的一个矩阵值,比如下图的左上角第一个卷积核,他刚好对于捕捉【字母X的左上角、右下角】的特征,那么判断的依据就是【二维卷积计算的值是不是最大值】!!!
可以发现,如果扫描到图像的局部特征和卷积核计算,一样的时候,值就是最大的,卷积核跟其他不一样的局部计算时,就不可能达到最大值,所以:和这个卷积核计算结果是【最大值——就是这个卷积核要捕捉的局部特征】、【不是最大值——就不是这个卷积核要的局部特征】!!
另外,一个尺寸很小的卷积核是怎能快速识别大尺寸的图像的
是因为还有很多很多层卷积核,最贴近原输入图像的卷积核看到的范围最大,这个范围叫【感知叶】,然后下一层的卷积核基于这一层来识别,以此往复
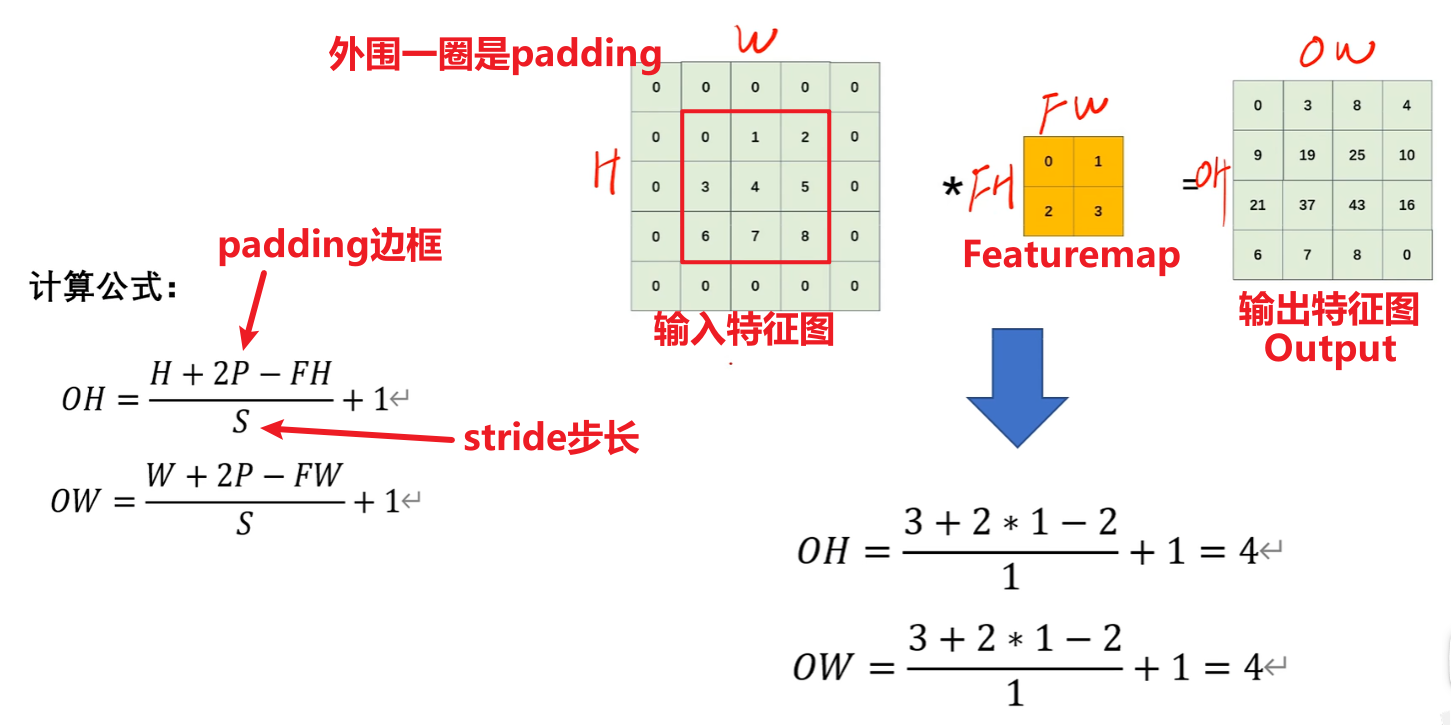
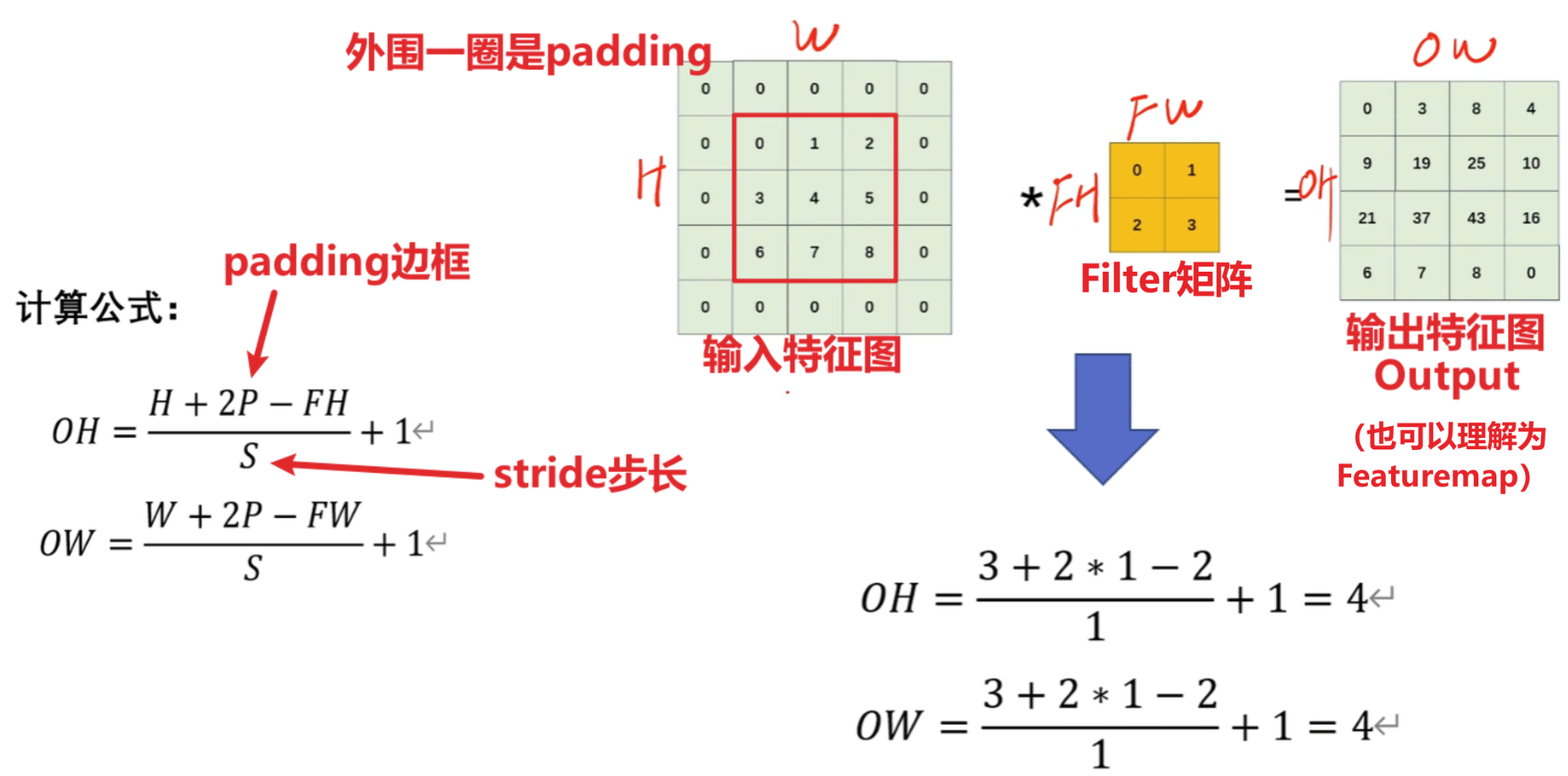
这个尺寸还有几个公式要记住,很重要!!!!!!!!!!!!
很简单,不就是【左边矩形加了padding后的宽高】—【卷积核宽高】/ 步长 + 1 = 这个卷积核能在左图上滑动几次 =【输出的矩形的宽高】吗?
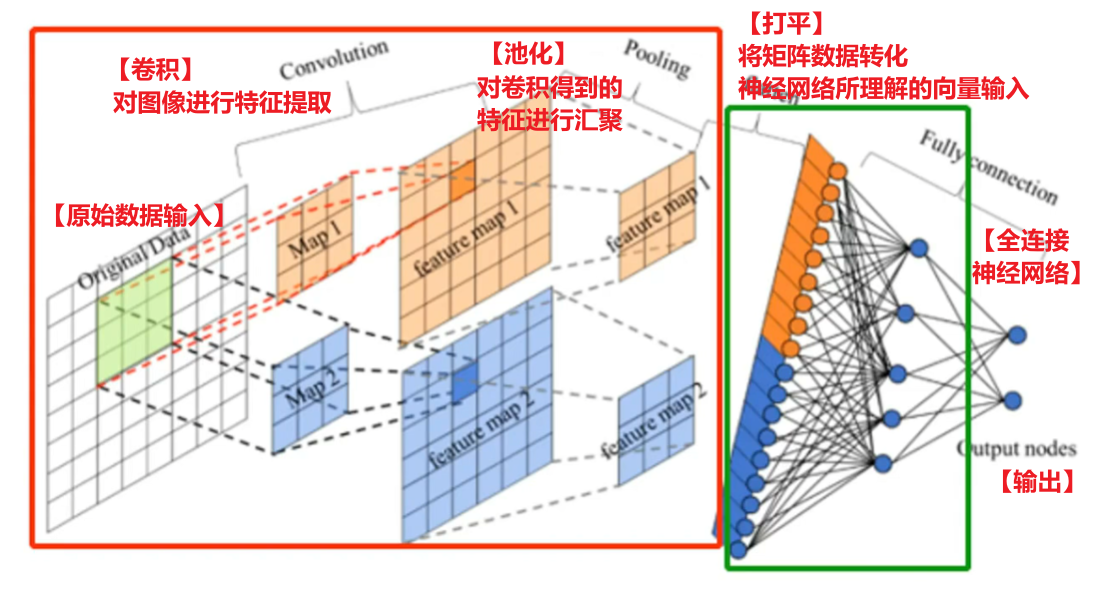
6、池化和打平
这两个概念也很好理解:
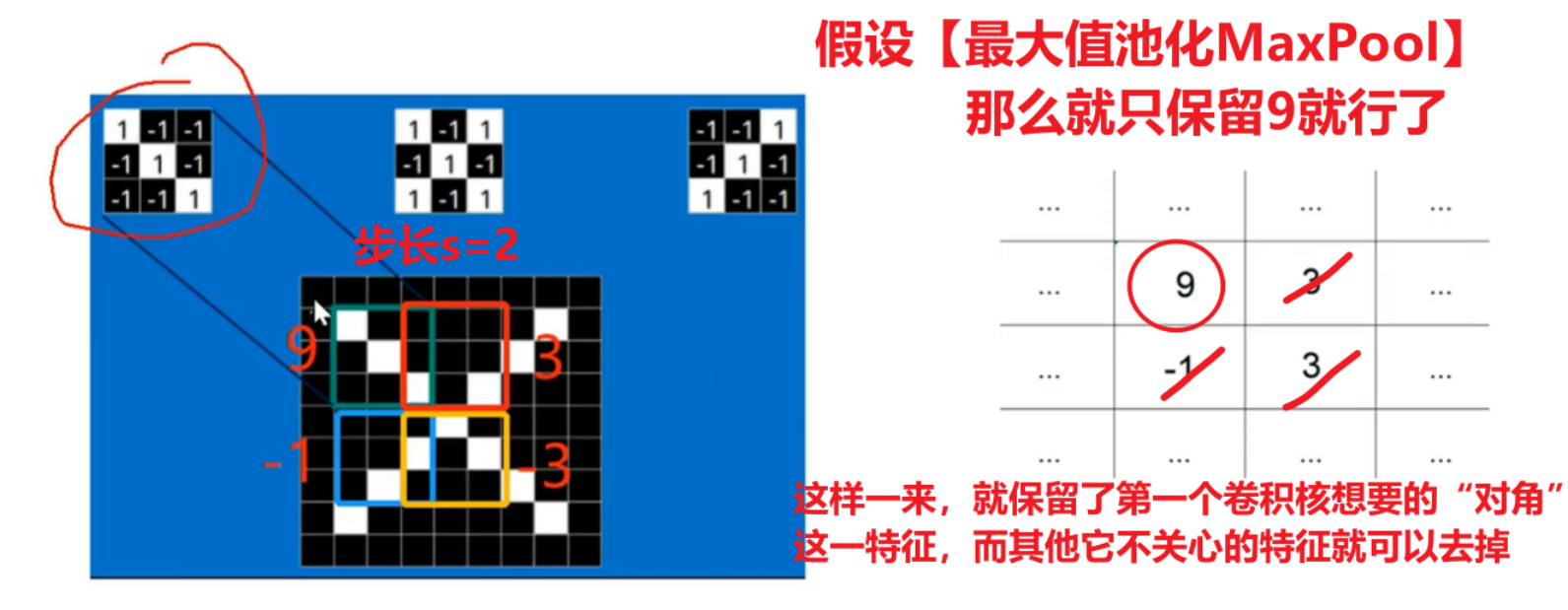
【池化】就是把卷积核经过扫描、计算后放到featuremap上的值进行一个统一汇总,通常有两种方式:【最大池化】、【平均池化】
目的就是要把多维数值尽可能的降维,去掉局部冗余的多个数值而统一用一个数值代表这个局部特征。
那么注意,如果这种降维操作没有卷积核在前面的计算,那就会丢失很多有用的值,但是池化层在卷积层后面,通过搭配卷积核计算后,卷积核求得了【他关心的特征】和【图像各个局部位置的关系】,那么我们再用池化,不就得到了该卷积核最关心的特征值、而去处理它不关心的其他局部值了吗
;
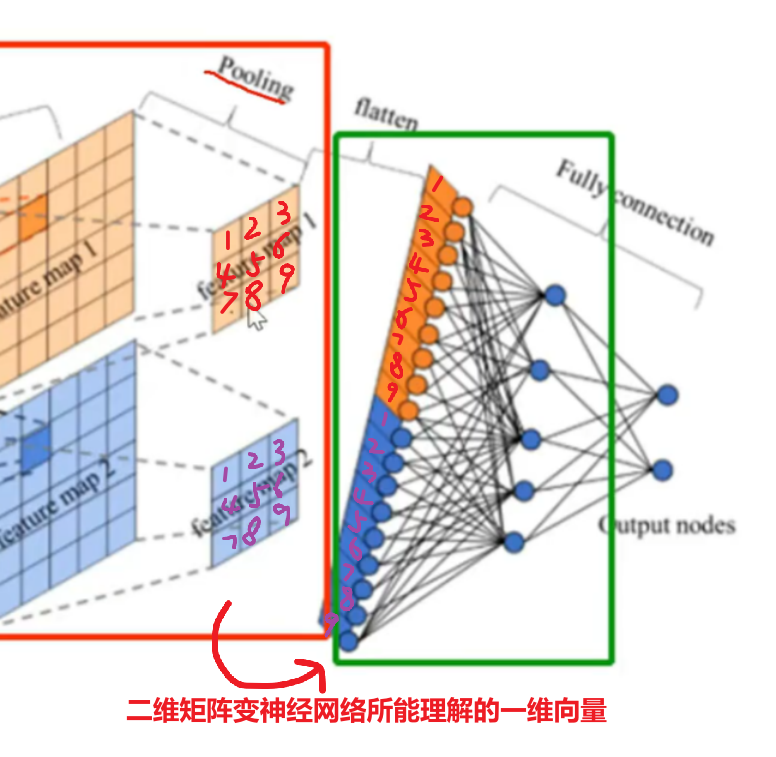
而【打平】更好理解,打平这一步不对数值进行取舍,保留数值,只不过把多维的数据转化成一维的,因为最后是要送给全连接神经网络的,而全连接神经网络只认得一维数据

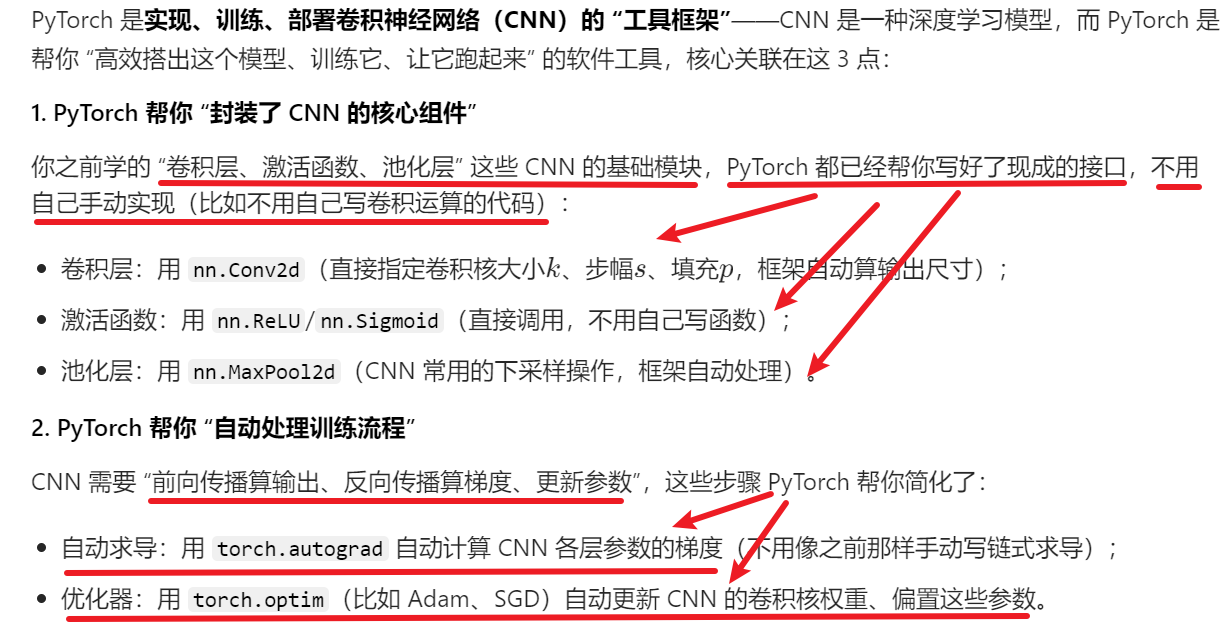
四、pytorch+卷积网络代码实战
1、理论
pytorch其实我也单独写了一篇文章描述,而且有非常详细的环境安装配置教程,可以自行去看:
《PyTorch之TensorBoard使用》
2、用pytorch代码实操卷积CNN模型
1)前置准备
数据集网址:
https://pan.baidu.com/share/init?surl=q7KFRz8ufoO1OUrKRNcN8w密码:1111
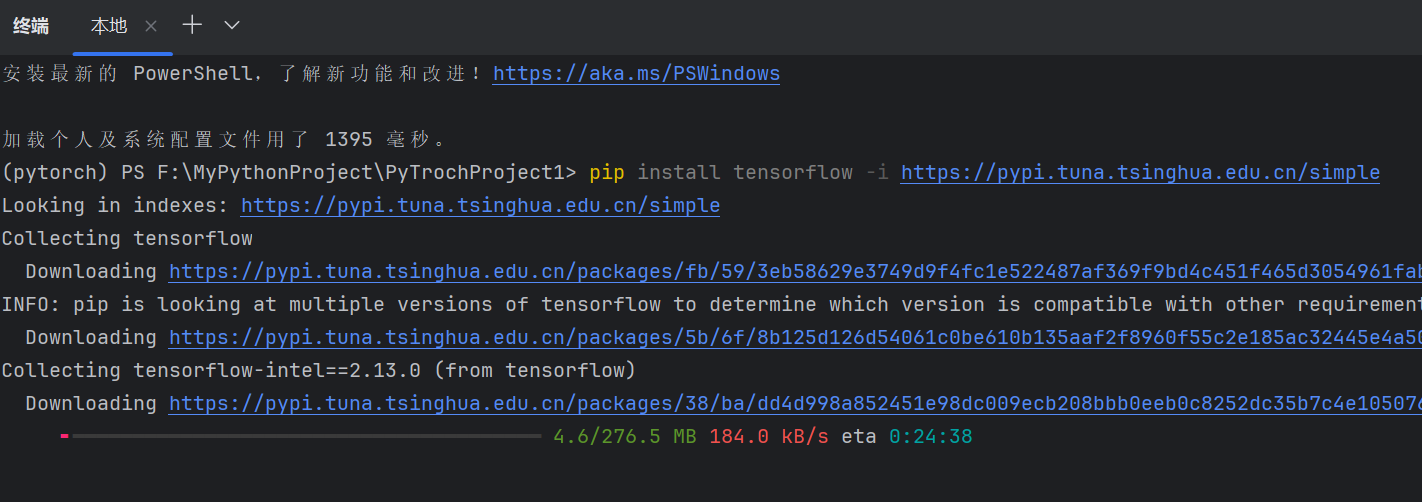
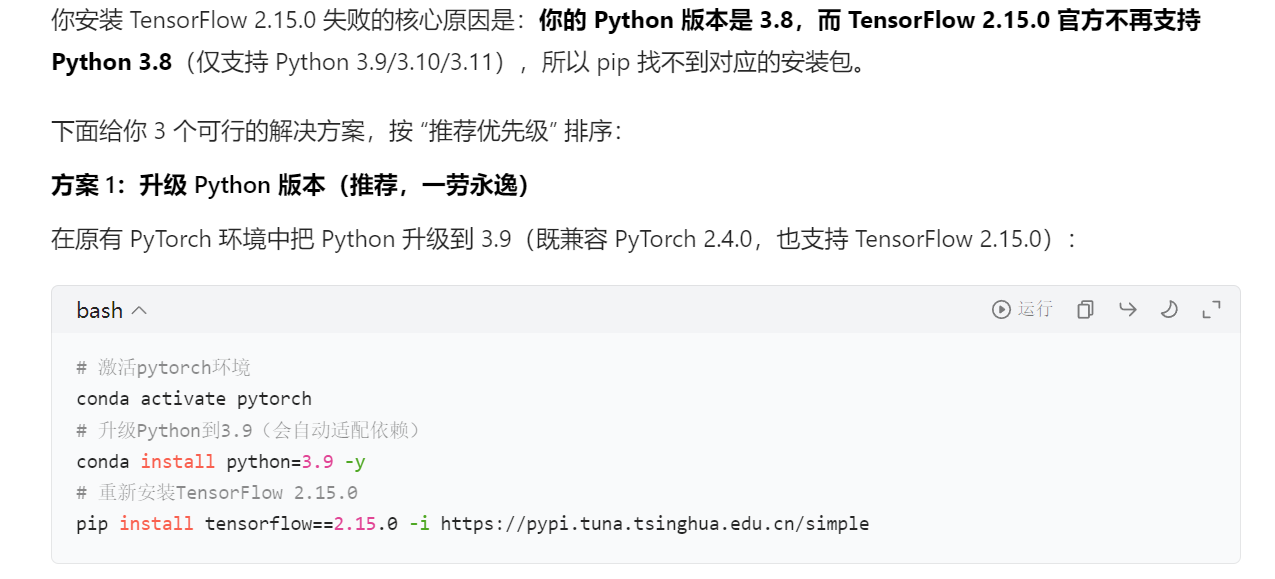
记得提前下载好【tensorflow】、
注意python环境和tensorflow版本冲突
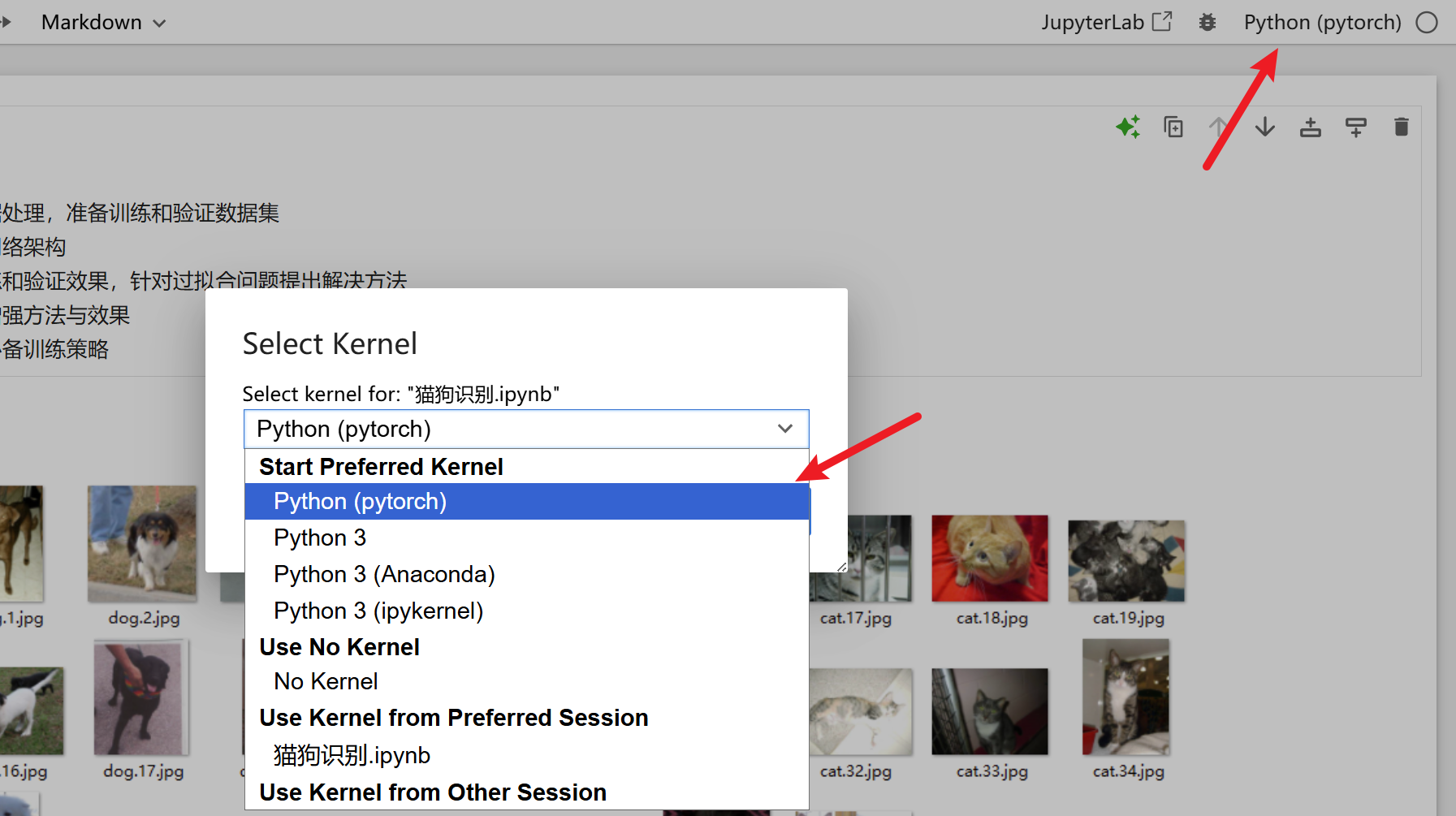
(如果用jupyter notebook写代码的,还要记得创建这个环境的内核,并选择这个内核)

2)代码部分
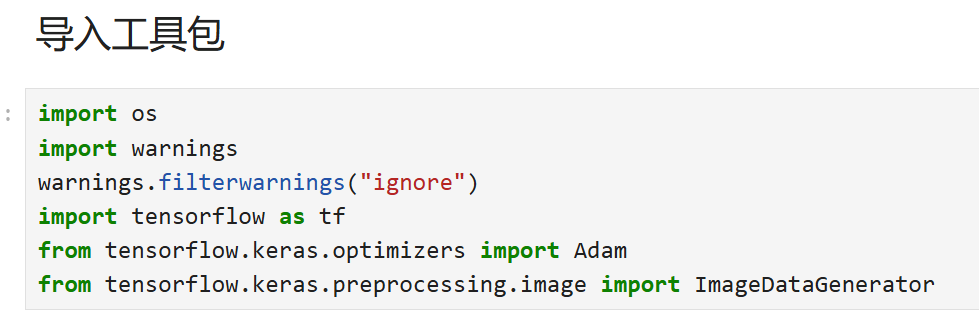
【用os打开本地数据集文件】
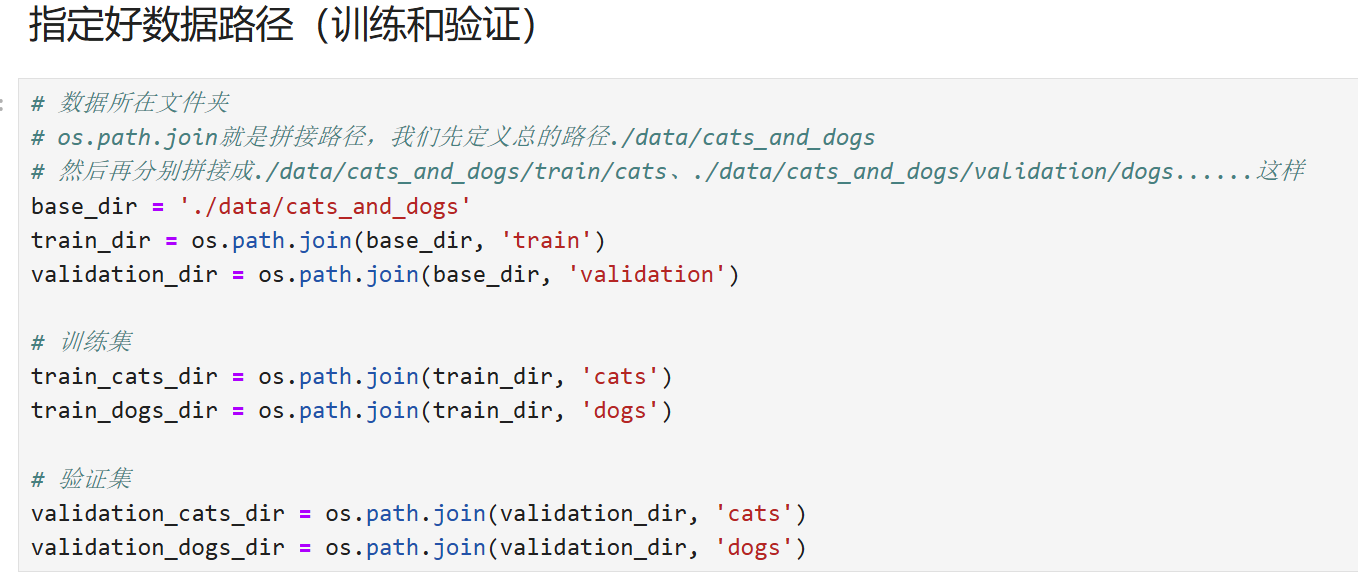
import os import warnings warnings.filterwarnings("ignore") import tensorflow as tf from tensorflow.keras.optimizers import Adam from tensorflow.keras.preprocessing.image import ImageDataGenerator # 数据所在文件夹 # os.path.join就是拼接路径,我们先定义总的路径./data/cats_and_dogs # 然后再分别拼接成./data/cats_and_dogs/train/cats、./data/cats_and_dogs/validation/dogs......这样 base_dir = './data/cats_and_dogs' train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') # 训练集 train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') # 验证集 validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
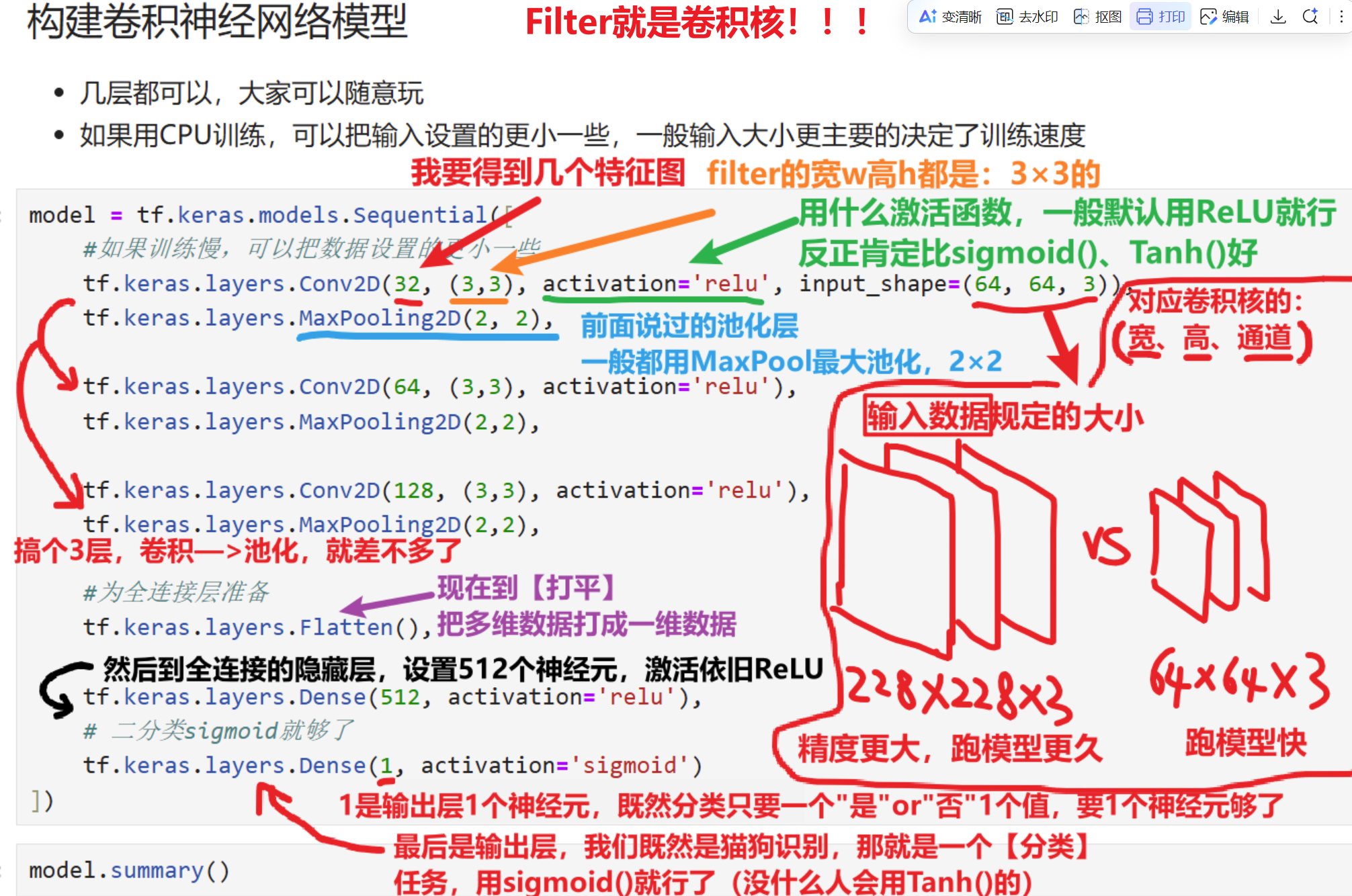
【构建卷积神经网络】
回忆前面学得理论,卷积的结构:
- 1、卷积层
- 2、池化层
- 3、打平层
- 4、全连接神经网络的隐藏层(全连接层)
- 5、全连接神经网络的输出层
- 还有我们提过的【非常重要的:根据输入特征图计算输出特征图尺寸公式】
- 可以看到公式里一共有的变量是:输入特征图的高H、输入特征图的宽W、填充padding、步长stride、Filter的高FH、Filter的宽FW,这就是我们重点要调的参数
那么就对应了下面这么简单的一段代码了
- 注意我这里没写【padding】和【stride】两个参数,所以使用【默认的padding=0】、【stride=1】,如果要写的话参照下面代码
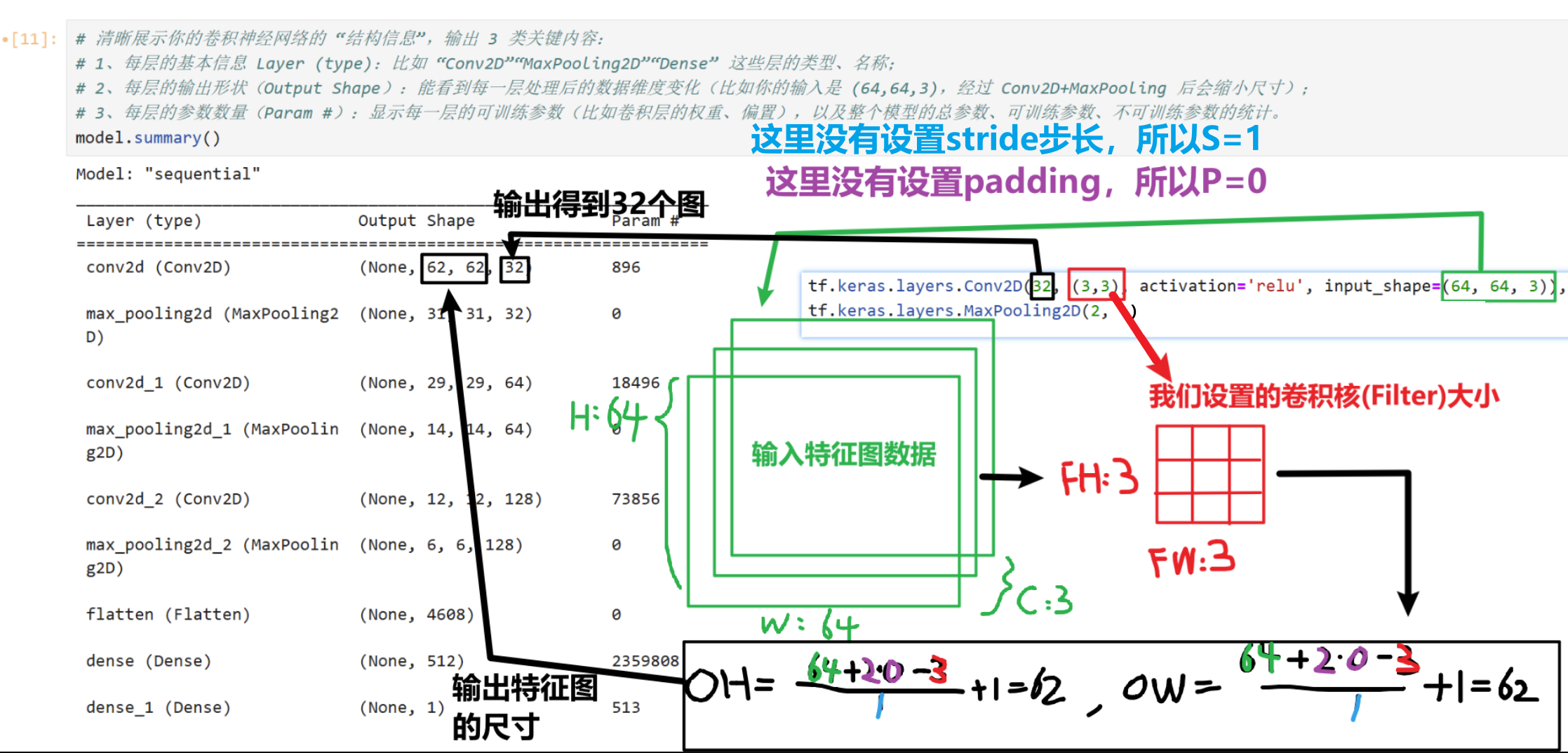
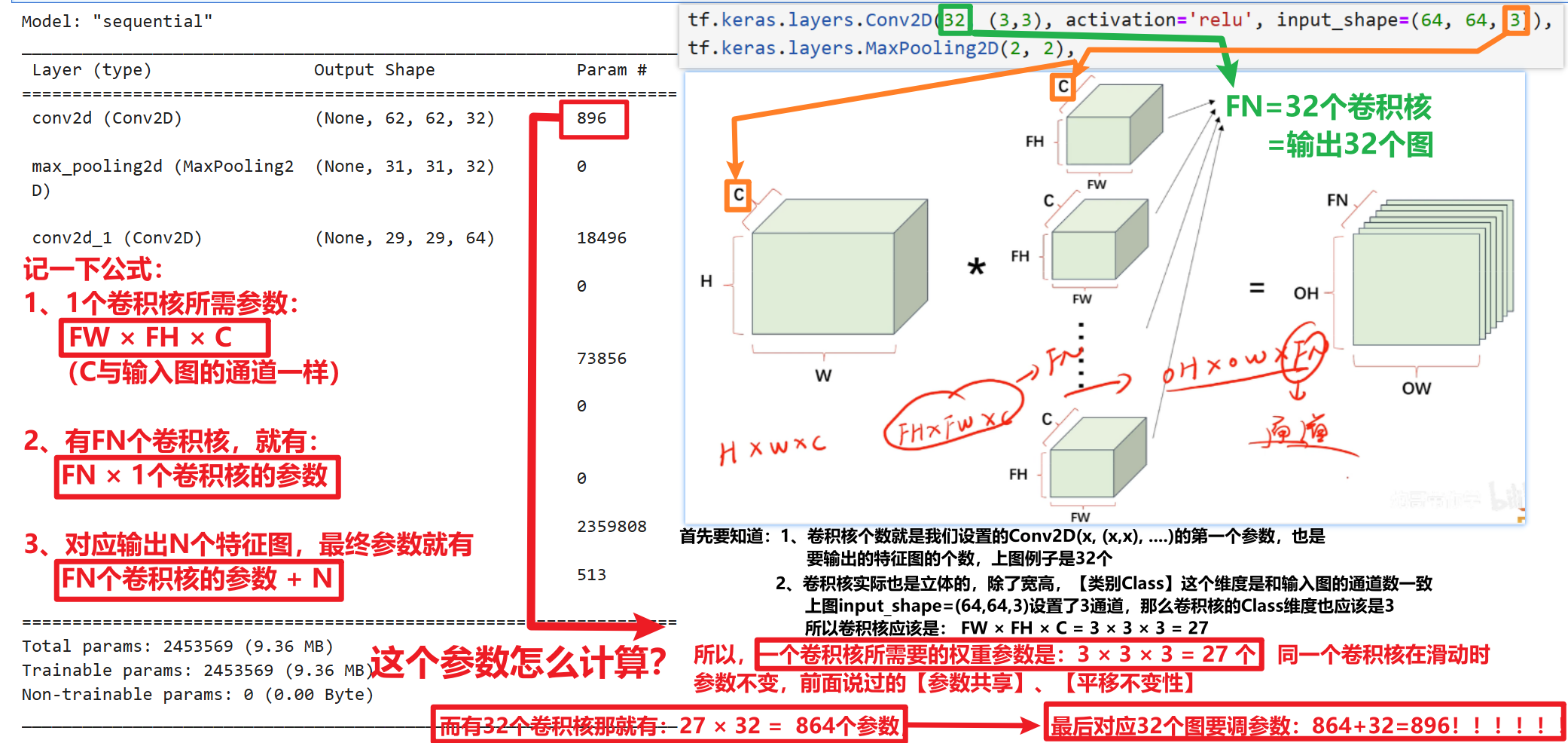
# 每次要写的时候直接复制就行,有自己想改的参数再一点点改 model = tf.keras.models.Sequential([ #如果训练慢,可以把数据设置的更小一些 tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(64, 64, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), #为全连接层准备 tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), # 二分类sigmoid就够了 tf.keras.layers.Dense(1, activation='sigmoid') ])然后我们输入一下【model.summary()】代码:来看看我们设置的卷积神经网络结构符不符合我们的想要的结构
下图我详细的联系了【代码层面】+【根据输入特征图计算输出特征图尺寸公式】,一定要看明白!!!!!!!!!!
这个也记一下


【数据预处理:ImageDataGenerator】
图像数据归一化:分别把训练集核测试集放到【图像数据生成器】进行压缩
没什么好调的,用的时候直接复制下面代码就行
train_datagen = ImageDataGenerator(rescale=1./255) test_datagen = ImageDataGenerator(rescale=1./255)

创建【训练生成器】、【验证生成器】
其实就跟YOLO创建一个【训练实例化对象】、【验证实例化对象】一样,你有这么个对象(工具),设置好参数,然后才能用这个对象(工具)去真正开始训练、验证,参数也不用怎么调,直接复制代码就OK了
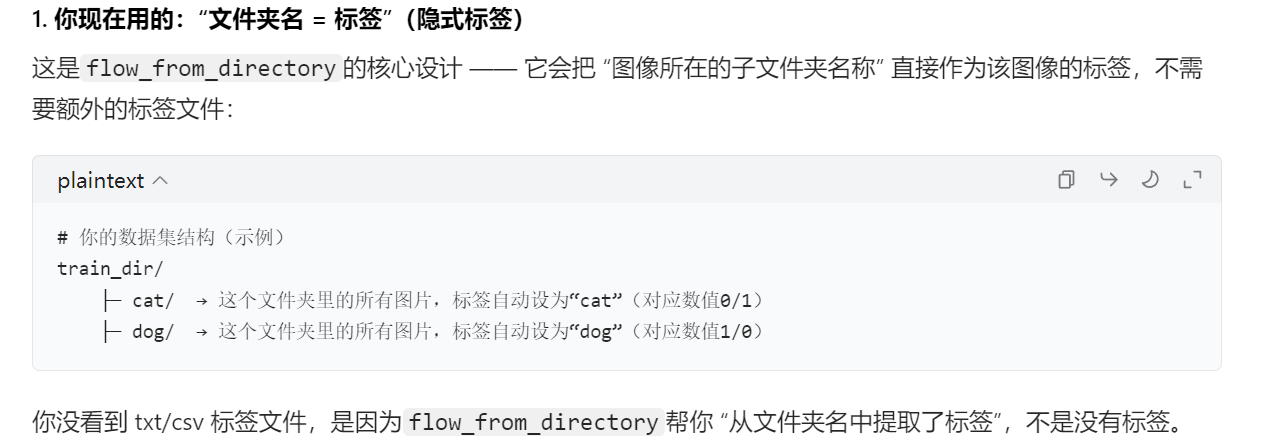
解释一下class_mode="xxx"这个参数,是根据目录层级的结构来给自动输入的图片打标签
- 在【分类任务】中目录层级结构和我们之前学得YOLO的【目标检测任务】不一样
- 【目标检测任务】可以把一堆不同种类的是图片放在同一个训练集、验证集、测试集里,因为我们是要在一堆参杂各个目标物体的图中检测出每一个物体的特征
- 另外【目标检测任务】是需要对每一张图片都有一个标签文件,文件里标注图片里各个目标物体的位置信息,因为计算机需要知道图片里的目标物体是个什么东西,在具体什么位置这些详细的细解信息
- 而【分类任务】是训练集、验证集、测试集都必须把不同种类的图片分别独立放在一个文件夹,因为我们的任务是让机器在每个独立文件夹里把海量的图片特征牢记于心,记住每个种类的特征,最后在预测推理时只回答:“是XXX”、“不是XXX”的分类答案
- 【分类任务】没有显式的标签,你会发现拿到手的分类数据集都只有【图片】,没有【txt、xml这些标签文件】,是因为它采用的是隐式标签,通过【flow_from_directory()函数】把图片所在的文件夹名字转化成0、1这样的数值作为标签,毕竟在分类任务,计算机不需要知道这个物体是什么,他只需要知道A、B两种图片,如果不是A就是B,不是B就是A
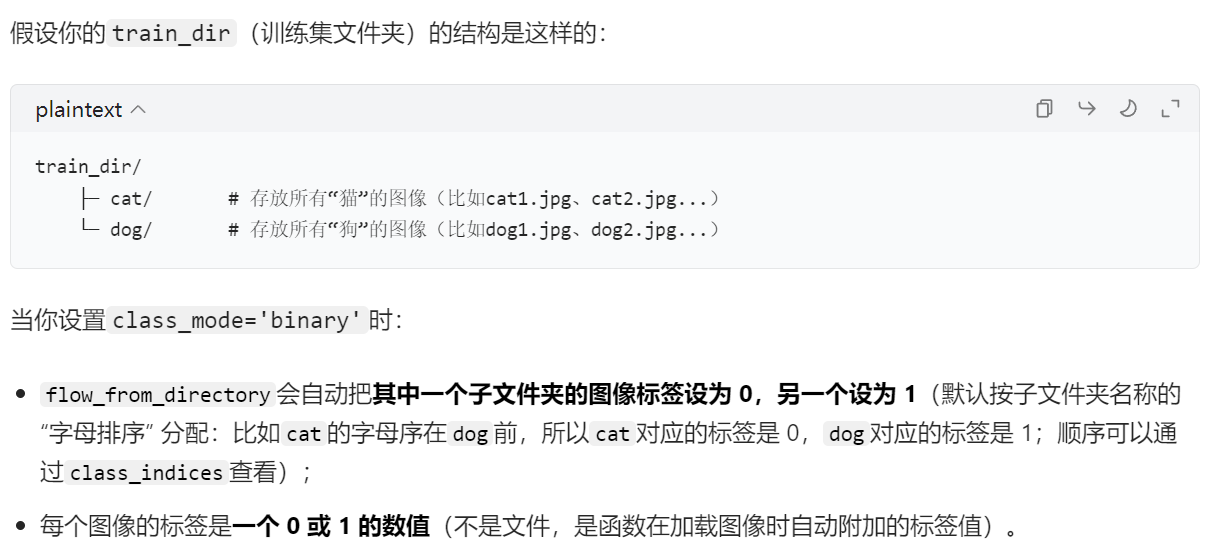
- 然后再【分类任务】中又分为【二分类】和【多分类】
- 【二分类】:只有两种种类,那么0代表一种、1代表另外一种即可
- 【多分类】:有多个种类,就要用One-hot标签来代表各个种类
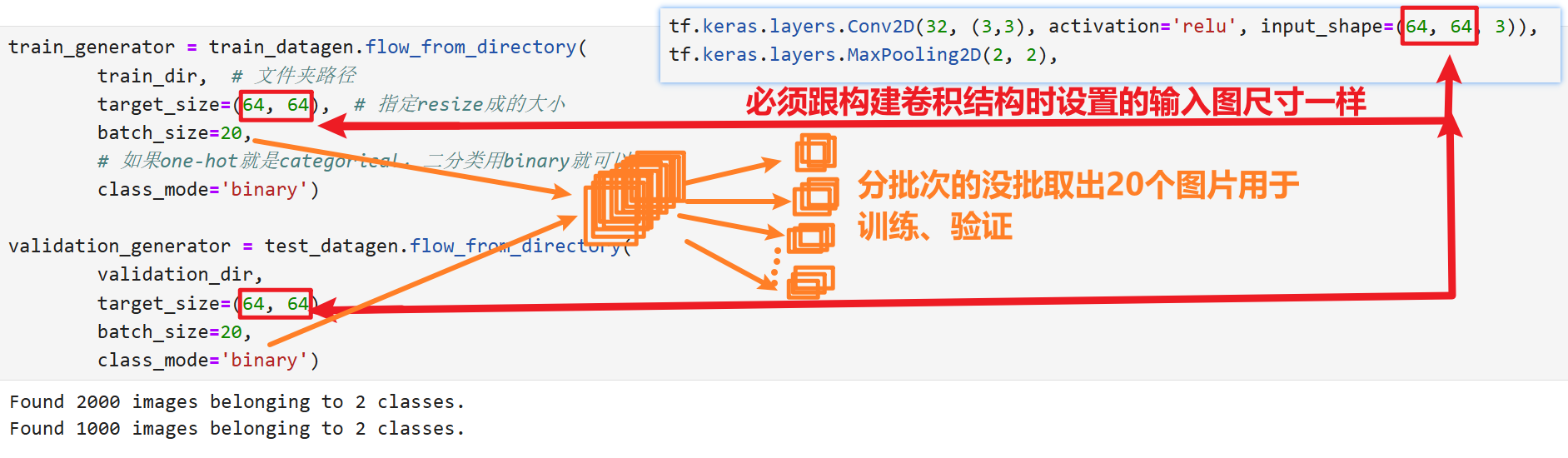
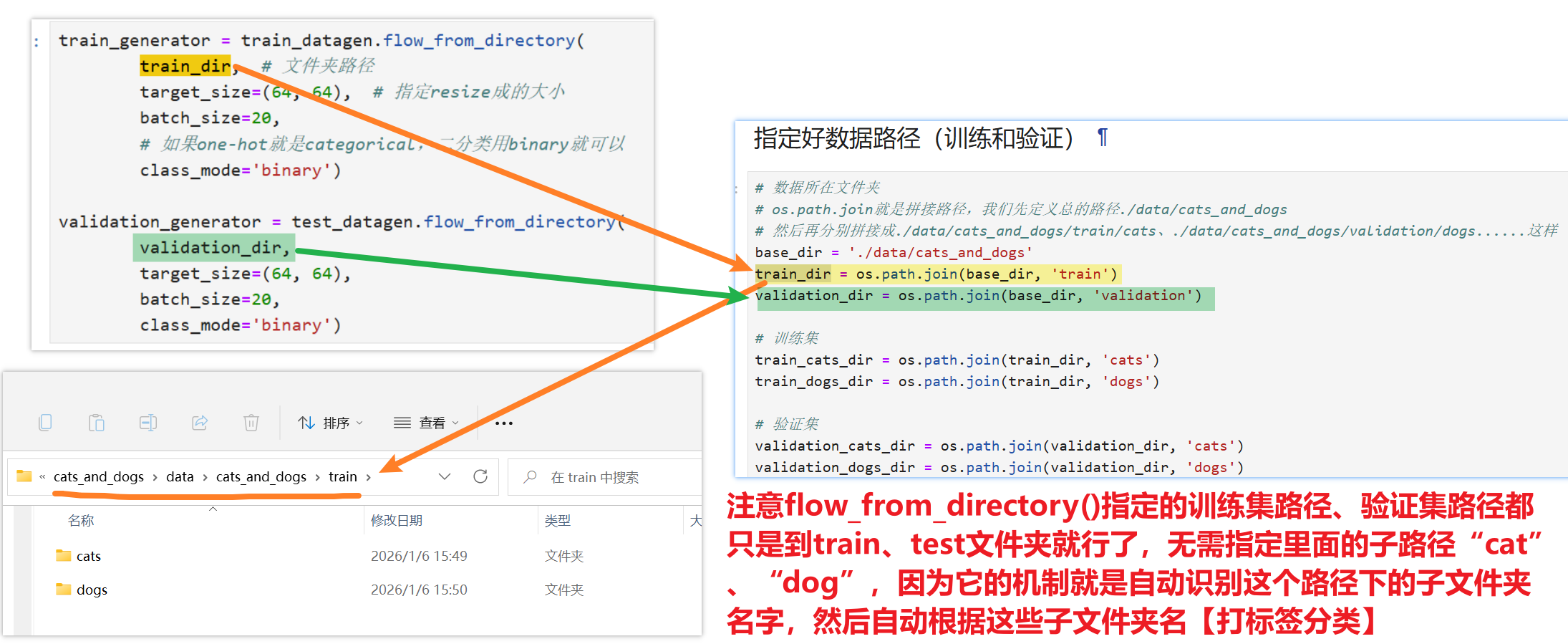
- 所以还需要特别注意在指定图片数据集路径时,不要指定具体到哪一种类图片所在的路径,只用到train、test、validation这一层父路径就行了,它会自动识别下一层的子路径
train_generator = train_datagen.flow_from_directory( train_dir, # 文件夹路径 target_size=(64, 64), # 指定resize成的大小 batch_size=20, # 如果one-hot就是categorical,二分类用binary就可以 class_mode='binary') validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(64, 64), batch_size=20, class_mode='binary')

【开始调用 model.fit()函数 训练】
在训练之前,还有最后最后两步要搞:
1、要用先给模型【制定规则】:
复制代码就行,没啥好调的
# 相当于模型训练的“规则”,没有这些配置,模型不知道如何调整参数、如何衡量训练效果 model.compile( loss='binary_crossentropy', # 损失函数:二分类任务对应binary_crossentropy,可以自己豆包查一下 optimizer=Adam(learning_rate=1e-4), # 优化器:用你头文件导入的Adam这个工具,不用管为啥,用就行 metrics=['acc'] # 训练过程中监控的指标:准确率 )2、调用【训练函数】开始训练
卷积神经网络有两种【模型训练函数】,【model.fit()】和【model.fit_generator()】,后者基本已经被定位过时启用函数,以前【model.fit()】是把你训练集、验证集的图片一股脑全读取到内存,然后再让模型从内存里拿数据训练,但是如果数据集非常非常大,一般电脑的内存遭不住。但是后面【model.fit()】已经完全支持 “生成器(generator)” 输入以及分批次读取数据
但是大部分教程还会用这个过时的【model.fit_generator()】函数,运行时出现warning不是报错,只是告诉你这个函数要过时了,那么下图我是用老的【model.fit_generator()】函数,代码时新的【model.fit()】,参数是一样的
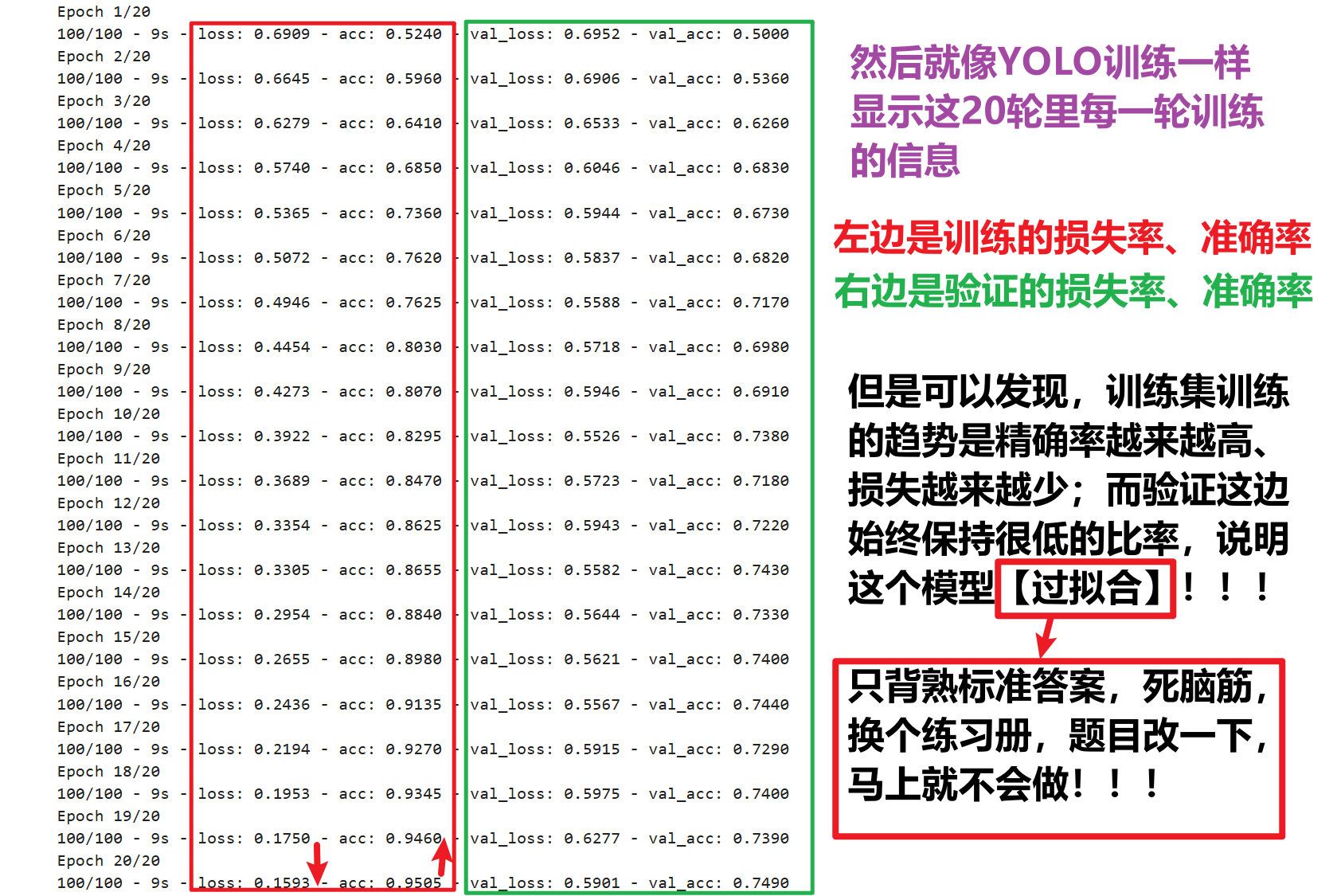
# 把 fit_generator 改成 fit history = model.fit( # 仅改这一个函数名 train_generator, steps_per_epoch=100, # 2000 images = batch_size * steps epochs=20, validation_data=validation_generator, validation_steps=50, # 1000 images = batch_size * steps verbose=2)但是留意:模型可能会发生【过拟合】
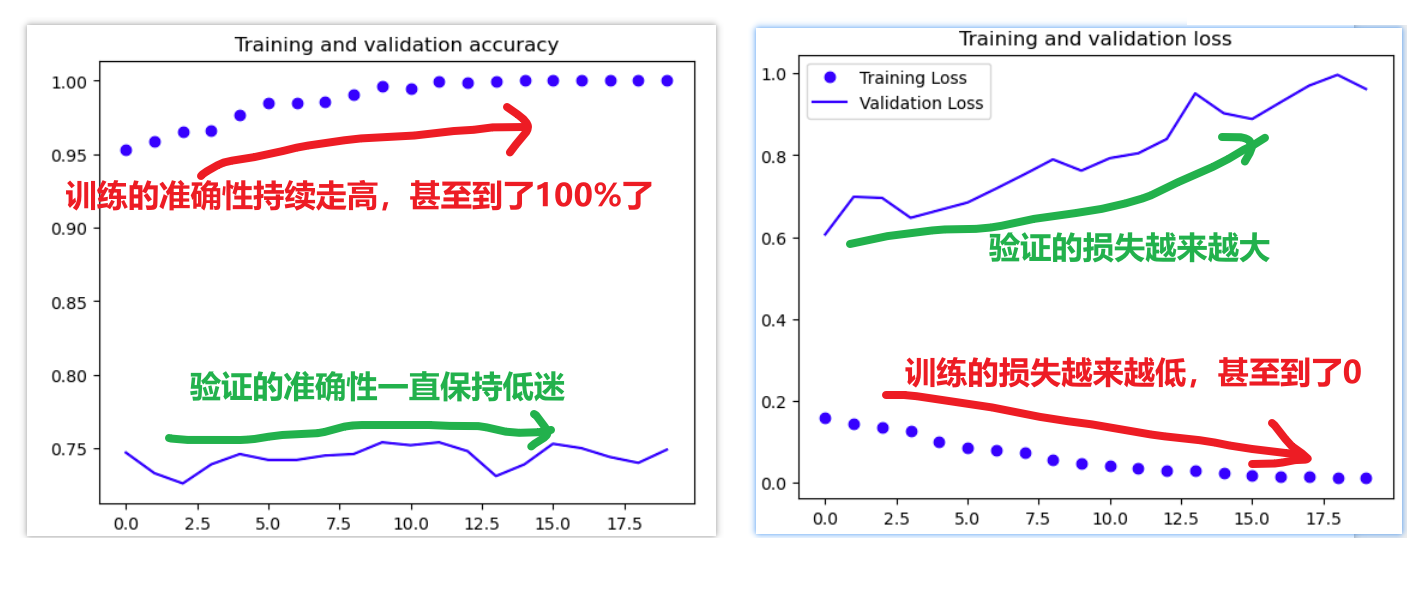
就是模型只读训练集的学习滚瓜烂熟,但是对验证、预测的效果很差,过度依赖了训练集,这也很可能是我之前训练YOLO模型时老是效果很差的原因,所以要关注一下怎么解决
用matplotlib可以把模型评估指标结果更清晰展示
import matplotlib.pyplot as plt # history是我们刚刚调用model.fit()函数时返回的评估数据对象 # 可以打印这个history看看都有些什么数据可以查看 acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(len(acc)) plt.plot(epochs, acc, 'bo', label='Training accuracy') plt.plot(epochs, val_acc, 'b', label='Validation accuracy') plt.title('Training and validation accuracy') plt.figure() plt.plot(epochs, loss, 'bo', label='Training Loss') plt.plot(epochs, val_loss, 'b', label='Validation Loss') plt.title('Training and validation loss') plt.legend() plt.show()
要怎么解决过拟合问题————那就是从数据层面调整修改


五、tensorflow库的Keras数据增强
要解决过拟合问题,最简单的就是猛猛的加数据集,2000张不够就10000张,还不够就1000000张,但是我们学生个人电脑恐怕没有能力跑这么多图片,也没有能力获取这么多图片,那就只能通过别的办法,比如【数据增强】
【数据增强】的好处:1、有些模糊、小的目标特征可以放大、去杂这些操作,让这些特征明显放大,可以被卷积捕捉到;2、本身很少的本地数据,当你对一张图进行反转、放大、旋转、调色.....等操作,不就又是新的图像数据了吗,在原有的数据集基础上又翻了几倍数据量。
那么就有人会想到最常用的图像处理工具————【opencv】,但是我们的【tensorflow库的Keras】已经集成了内置非常强大的图像处理工具:【ImageDataGenerator】,为什么用它而不用【opencv】呢?——————一句话:图省事,没有那么多自定义需求要操作(Keras只用一两句代码,opencv要自己手写一堆)

1、常用的一些数据增强方法
【数据准备】
首先先去数据集随便取3张图片试一试先,我们创建一个【train / cat】的路径,把图片放进去。为什么要这样:
- 1、我尽量模拟训练模型的规范,之所以选train文件夹是因为【数据增强】一般只对训练集增强
- 举个例子,你学习的时候肯定是会对书本的题举一反三、改动一下数值、题意再做几次来加深记忆,甚至故意刁难自己做一些怪题、错题。
- 但是在真正课堂测试的时候你会希望老师用一堆怪题、错题来考你吗?所以【验证集】没必要数据增强
- 2、我前面强调过,数据增强还是用【flow_from directory()函数】,它指定的数据集路径只用到【train】、【test】、【validation】这些路径,然后他会到这些路径的下一层去分别读取“cat”、“dog”.......这种子文件夹的数据,一定要保证是【train / 种类A / xxx.jpg】这样的层级关系
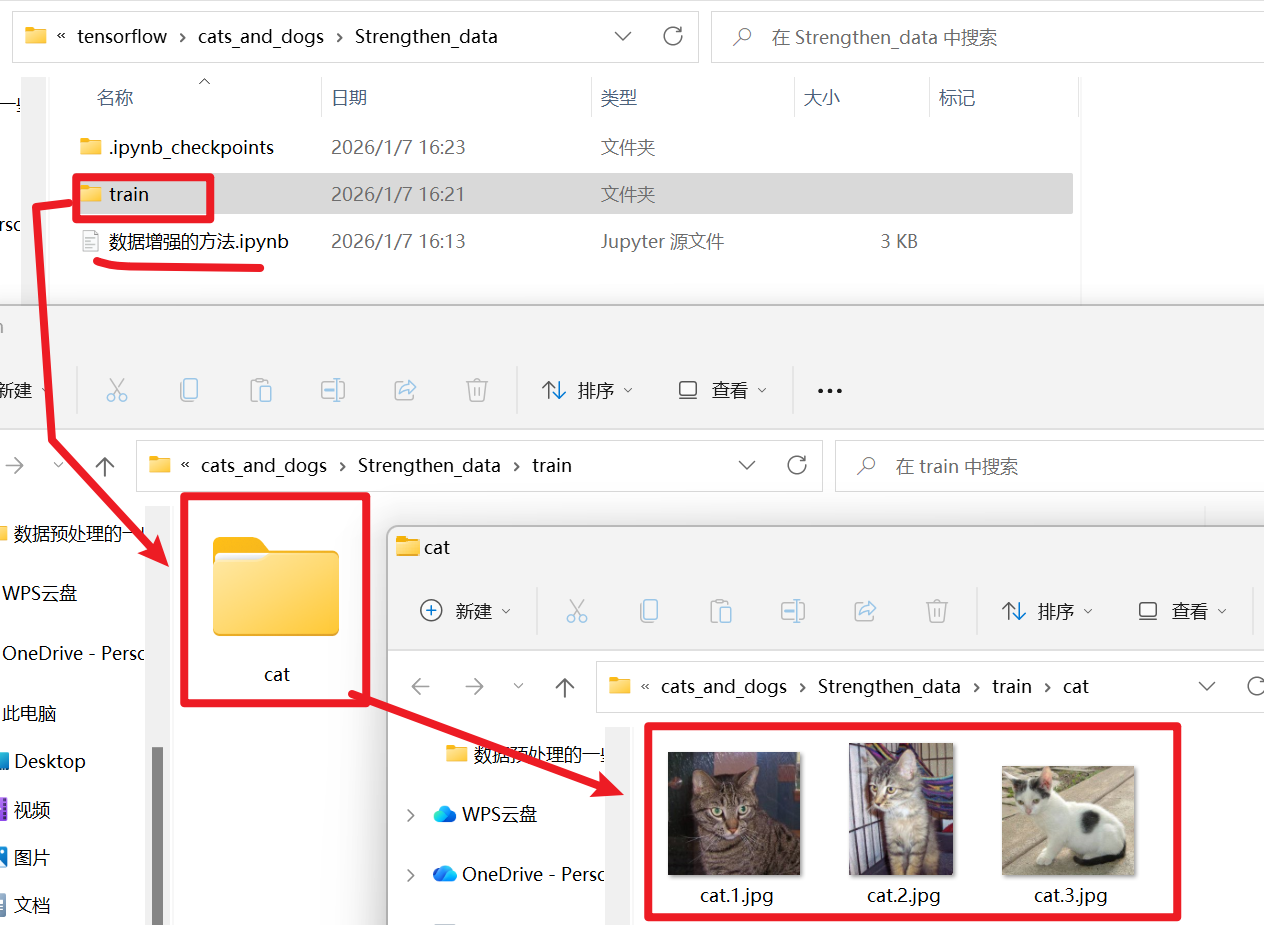
【导包、读取数据】
导工具包,直接复制:
import matplotlib.pyplot as plt from PIL import Image %matplotlib inline from tensorflow.keras.preprocessing import image # 注意很多教程这里是老的tensorflow的keras库,我这个是最新的 import tensorflow.keras.backend as K # 注意很多教程这里是老的tensorflow的keras库,我这个是最新的 import os import glob import numpy as np # 配置字体:使用SimHei(黑体)支持中文,同时解决负号显示问题 plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体为SimHei plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常的问题
【开始处理:设置target_size】
其实完整的Keras【数据增强】的流程就这么4步(不保存结果)
完整代码:
# 1. 定义输入路径 in_path = "./train/" # 输入路径:你的train文件夹(包含cat子文件夹) # 2. 初始化ImageDataGenerator:数据增强的规则配置器 # 仅定义数据增强的规则(比如是否旋转、是否平移、是否归一化),不直接处理图片 datagen = image.ImageDataGenerator( rescale=1./255, # 必须做的【归一化】,依旧是把像素值从0~255压缩到0~1 rotation_range=0, # 图片的随机旋转角度范围(单位:度),这里先展示尺寸缩放,所以先设为0不旋转,当然不写这个参数也是0 width_shift_range=0, # 水平随机平移比例(范围 0~1,代表图片宽度的百分比),这里先展示尺寸缩放,所以先设为0不旋转,当然不写这个参数也是0 height_shift_range=0 # 图片的垂直随机平移比例(逻辑和 width 一致) ) # 3. 核心:flow_from_directory # 是ImageDataGenerator的方法,负责执行规则,读取图片,按照规则增强图片,生成 “批量图片数据” change1 = datagen.flow_from_directory( directory=in_path, # 输入路径:你的train文件夹 target_size=(224, 224), # 调整后的尺寸是224×244 batch_size=3, # 1批次对应生产几张增强后的图,我们只看3张,大小设为3就刚好 class_mode=None, # 前面我们说过训练模型的时候是设置"binary",但是这里仅做数据增强示例,先不用打标签 shuffle=False # 不打乱顺序,对应原图 ) # 4. 触发生成器.next() # 获取1个批次的图片数据(shape: (3, 224, 224, 3)) batch_imgs = change1.next() # 负责“获取增强后的图片数据”(只是拿到数据,不会显示) #---------------------后面这段可有可无,你想显示效果就写 # 靠change1.next()拿到的增强后的数据,用plt显示这3张图片 plt.figure(figsize=(15, 5)) # 设置画布大小 for i in range(3): plt.subplot(1, 3, i+1) plt.imshow(batch_imgs[i]) # 直接显示生成的图片数组 plt.title(f"调整后 (224×224)") plt.axis('off') # 隐藏坐标轴 plt.tight_layout() plt.show()
;
;
如果需要把数据增强的结果保存,就还要多加几个【输出路径、前缀名...】这么几个参数
完整代码:
# 1、定义输入/输出路径(关键:和示例的in_path/out_path对应) in_path = "./train/" # 输入路径:你的train文件夹(包含cat子文件夹) out_path = "./aug_data/" # 输出路径:增强后的图片保存位置 # 确保输出文件夹存在(避免报错) os.makedirs(out_path + "resize", exist_ok=True) # 2、初始化ImageDataGenerator(先只做resize,后续可加其他增强) # 必须做的【归一化】,依旧是把像素值从0~255压缩到0~1(其他参数既然不设,就可以设为0或者先不写) datagen = image.ImageDataGenerator(rescale=1./255) # 3、核心:flow_from_directory change1 = datagen.flow_from_directory( directory=in_path, # 输入要进行数据增强的文件夹路径(train训练集) target_size=(224, 224), # 调整后的尺寸(用224×224来把图像放大) batch_size=3, # 生成1个批次(3张图)(同时也是一次从你数据读几张图处理) save_to_dir=out_path + "resize", # 增强后的图片保存路径 save_prefix="change1", # 保存的图片名前缀 save_format="jpg", # 保存格式 shuffle=False # 不打乱顺序,方便对应原图 ) # 4、也很重要,触发图片生成 change1.next() # 生成1个batch(3张)的图片并保存到指定文件夹,没有这个.next()的话,上面的操作就没有生效 print(f"✅ 图片已生成并保存到:{out_path}resize/")






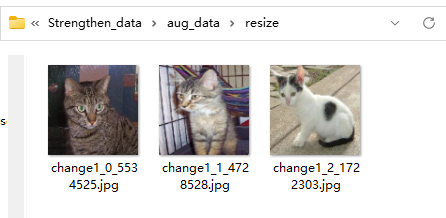
【角度旋转】
还是一样的操作
只不过把第2步【ImageDataGenerator】的规则参数设为【旋转角度:rotation_range=?】
不保存的生成器
保存本地的生成器
完整代码:
# 1. 定义输入路径 in_path = "./train/" # 输入路径:你的train文件夹(包含cat子文件夹) out_path = "./aug_data/" # 输出路径:增强后的图片保存位置 # 确保输出文件夹存在(避免报错) os.makedirs(out_path + "rotation_ranger", exist_ok=True) # 2. 初始化ImageDataGenerator:数据增强的规则配置器 # 仅定义数据增强的规则(这次是角度旋转) datagen = image.ImageDataGenerator( rotation_range=90, # 图片的随机旋转角度范围(单位:度) # 是在你设定的角度内(比如这里0~90度),各个图片随机旋转这范围的任意度 ) # 3. 核心:flow_from_directory # 我们可以创建2个生成器 # 第1个:这个生成器用于把旋转后的图片直接转化成numpy数值(不保存文件),喂给卷积直接用 gen = datagen.flow_from_directory( in_path, batch_size=1, # 每次生成1张图 class_mode=None, # 只生成图片数据,不要标签 shuffle=True, # 随机顺序生成 target_size=(224, 224) ) # 生成3张旋转后的图片,拼接成一个numpy数组(shape: (3,224,224,3)) np_data = np.concatenate( [gen.next() for i in range(3)] ) # 第2个:这个生成器用于保存旋转后的图 save_gen = datagen.flow_from_directory( in_path, batch_size=3, shuffle=False, # 按原图顺序生成 save_to_dir=out_path+'rotation_ranger', # 保存到这个文件夹 save_prefix='change2', # 保存的文件名前缀 target_size=(224,224) ) # 生成3张旋转后的图片,保存到指定文件夹 save_gen.next()




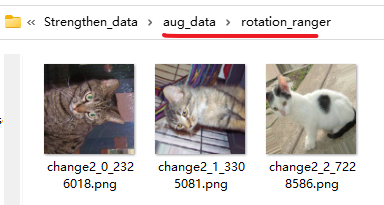
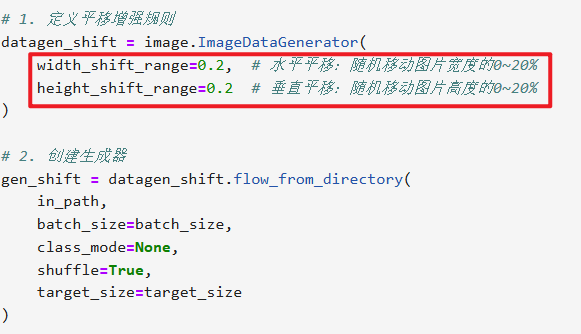
【平移增强(水平 + 垂直平移)】
其实这些数据增强的操作区别就是在【ImageDataGenerator】设置
其他部分全都不用改直接复制粘贴,除非你要保存本地就改一下
# 通用参数(所有增强共用) in_path = "./train/" # 你的train文件夹路径 target_size = (224, 224) # 统一调整为224×224 batch_size = 1 # 每次生成1张,方便拼接3张 # 1. 定义平移增强规则 datagen_shift = image.ImageDataGenerator( width_shift_range=0.2, # 水平平移:随机移动图片宽度的0~20% height_shift_range=0.2 # 垂直平移:随机移动图片高度的0~20% ) # 2. 创建生成器 gen_shift = datagen_shift.flow_from_directory( in_path, batch_size=batch_size, class_mode=None, shuffle=True, target_size=target_size ) # 3. 获取3张平移后的图片数据 np_shift = np.concatenate([gen_shift.next() for i in range(3)]) # 4. 拼接成一行展示效果 plt.figure(figsize=(10, 2)) for i in range(3): plt.subplot(1, 3, i+1) plt.imshow(np_shift[i].astype('uint8')) # 转成uint8避免显示异常 plt.title(f"平移增强 第{i+1}张") plt.axis('off') plt.tight_layout() plt.show()


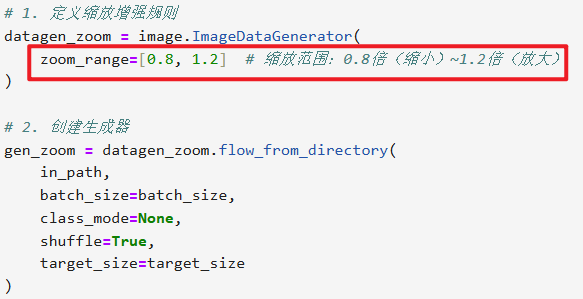
【缩放增强(随机放大 / 缩小)】
其实这些数据增强的操作区别就是在【ImageDataGenerator】设置
其他部分全都不用改直接复制粘贴,除非你要保存本地就改一下
# 通用参数(所有增强共用) in_path = "./train/" # 你的train文件夹路径 target_size = (224, 224) # 统一调整为224×224 batch_size = 1 # 每次生成1张,方便拼接3张 # 1. 定义缩放增强规则 datagen_zoom = image.ImageDataGenerator( zoom_range=[0.8, 1.2] # 缩放范围:0.8倍(缩小)~1.2倍(放大) ) # 2. 创建生成器 gen_zoom = datagen_zoom.flow_from_directory( in_path, batch_size=batch_size, class_mode=None, shuffle=True, target_size=target_size ) # 3. 获取3张缩放后的图片数据 np_zoom = np.concatenate([gen_zoom.next() for i in range(3)]) # 4. 拼接成一行展示效果 plt.figure(figsize=(10, 2)) for i in range(3): plt.subplot(1, 3, i+1) plt.imshow(np_zoom[i].astype('uint8')) plt.title(f"缩放增强 第{i+1}张") plt.axis('off') plt.tight_layout() plt.show()

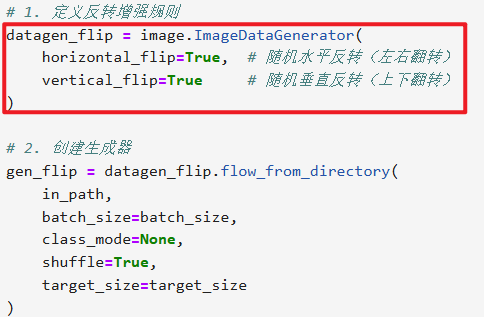
【反转增强(水平 + 垂直反转)】
其实这些数据增强的操作区别就是在【ImageDataGenerator】设置
其他部分全都不用改直接复制粘贴,除非你要保存本地就改一下
# 通用参数(所有增强共用) in_path = "./train/" # 你的train文件夹路径 target_size = (224, 224) # 统一调整为224×224 batch_size = 1 # 每次生成1张,方便拼接3张 # 1. 定义反转增强规则 datagen_flip = image.ImageDataGenerator( horizontal_flip=True, # 随机水平反转(左右翻转) vertical_flip=True # 随机垂直反转(上下翻转) ) # 2. 创建生成器 gen_flip = datagen_flip.flow_from_directory( in_path, batch_size=batch_size, class_mode=None, shuffle=True, target_size=target_size ) # 3. 获取3张反转后的图片数据 np_flip = np.concatenate([gen_flip.next() for i in range(3)]) # 4. 拼接成一行展示效果 plt.figure(figsize=(10, 2)) for i in range(3): plt.subplot(1, 3, i+1) plt.imshow(np_flip[i].astype('uint8')) plt.title(f"反转增强 第{i+1}张") plt.axis('off') plt.tight_layout() plt.show()

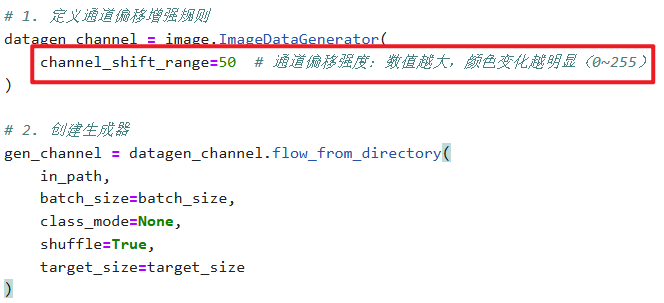
【通道偏移(channel_shift)增强(改变颜色)】
这个【虽然肉眼看不出区别,但是像素值确实有变化】
其实这些数据增强的操作区别就是在【ImageDataGenerator】设置
其他部分全都不用改直接复制粘贴,除非你要保存本地就改一下
# 通用参数(所有增强共用) in_path = "./train/" # 你的train文件夹路径 target_size = (224, 224) # 统一调整为224×224 batch_size = 1 # 每次生成1张,方便拼接3张 # 1. 定义通道偏移增强规则 datagen_channel = image.ImageDataGenerator( channel_shift_range=50 # 通道偏移强度:数值越大,颜色变化越明显(0~255) ) # 2. 创建生成器 gen_channel = datagen_channel.flow_from_directory( in_path, batch_size=batch_size, class_mode=None, shuffle=True, target_size=target_size ) # 3. 获取3张通道偏移后的图片数据 np_channel = np.concatenate([gen_channel.next() for i in range(3)]) # 4. 拼接成一行展示效果 plt.figure(figsize=(10, 2)) for i in range(3): plt.subplot(1, 3, i+1) plt.imshow(np_channel[i].astype('uint8')) plt.title(f"通道偏移 第{i+1}张") plt.axis('off') plt.tight_layout() plt.show()

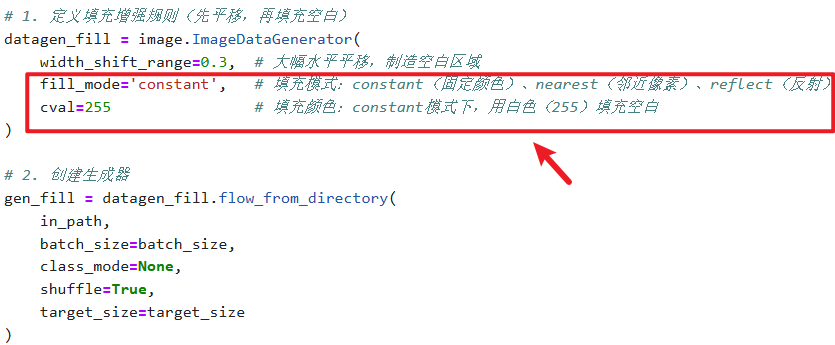
【填充增强(配合平移 / 旋转后的空白填充)】
其实这些数据增强的操作区别就是在【ImageDataGenerator】设置
其他部分全都不用改直接复制粘贴,除非你要保存本地就改一下
# 通用参数(所有增强共用) in_path = "./train/" # 你的train文件夹路径 target_size = (224, 224) # 统一调整为224×224 batch_size = 1 # 每次生成1张,方便拼接3张 # 1. 定义填充增强规则(先平移,再填充空白) datagen_fill = image.ImageDataGenerator( width_shift_range=0.3, # 大幅水平平移,制造空白区域 fill_mode='constant', # 填充模式:constant(固定颜色)、nearest(邻近像素)、reflect(反射) cval=255 # 填充颜色:constant模式下,用白色(255)填充空白 ) # 2. 创建生成器 gen_fill = datagen_fill.flow_from_directory( in_path, batch_size=batch_size, class_mode=None, shuffle=True, target_size=target_size ) # 3. 获取3张填充后的图片数据 np_fill = np.concatenate([gen_fill.next() for i in range(3)]) # 4. 拼接成一行展示效果 plt.figure(figsize=(10, 2)) for i in range(3): plt.subplot(1, 3, i+1) plt.imshow(np_fill[i].astype('uint8')) plt.title(f"填充增强 第{i+1}张") plt.axis('off') plt.tight_layout() plt.show()

2、回到实际项目代码
1)前面的猫狗识别项目前置工作
这几步全都跟前面说的一模一样
导包;(不变)
写好训练集、验证集路径;(不变)
设卷积神经网络结构;(不变)
model.compile设定规则(不变)
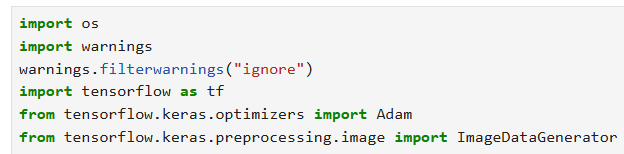



2)加入数据增强【ImageDatagenerator】
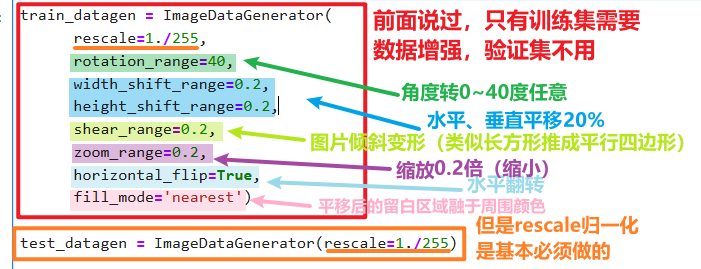
只有【ImageDataGenerator】有变化
只用给【训练集】进行数据增强,添加多几种增强方式
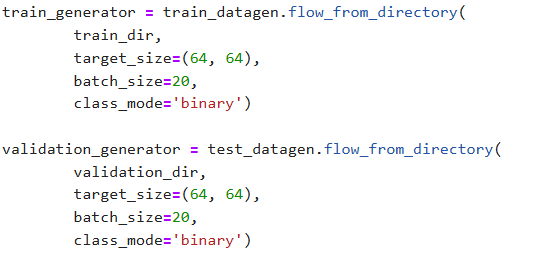
3)【训练生成器】、【验证生成器】
不变!
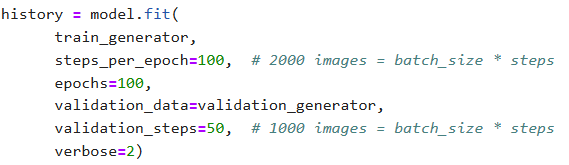
4)【开始model.fit()训练模型】
没什么变化,就多加几轮训练次数epoch就行了
然后我们用matplotlib图表展示一下效果
import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(len(acc)) plt.plot(epochs, acc, 'b', label='Training accuracy') plt.plot(epochs, val_acc, 'r', label='Validation accuracy') plt.title('Training and validation accuracy') plt.legend() plt.figure() plt.plot(epochs, loss, 'b', label='Training Loss') plt.plot(epochs, val_loss, 'r', label='Validation Loss') plt.title('Training and validation loss') plt.legend() plt.show()
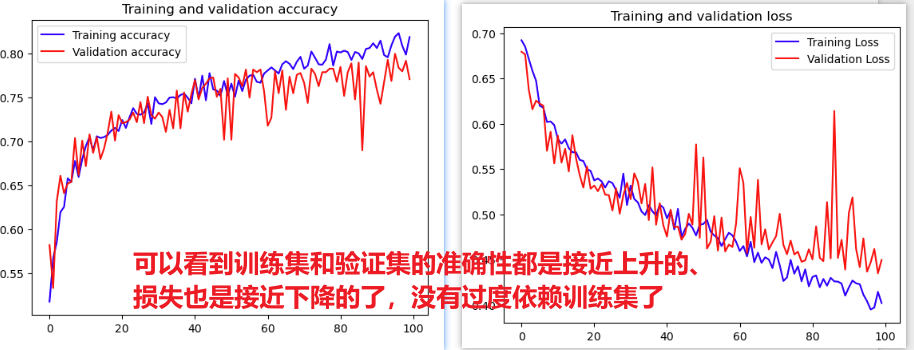
六、Dropout防止过拟合
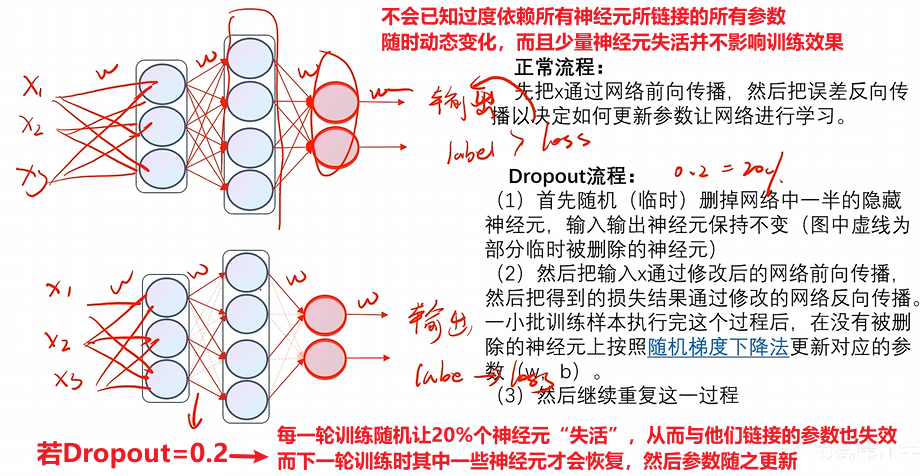
最后还有一招可以解决过拟合的问题,就是运用Dropout机制
1)原理
简单看一下,知道是个什么东西大致有概念就行,因为代码很简单


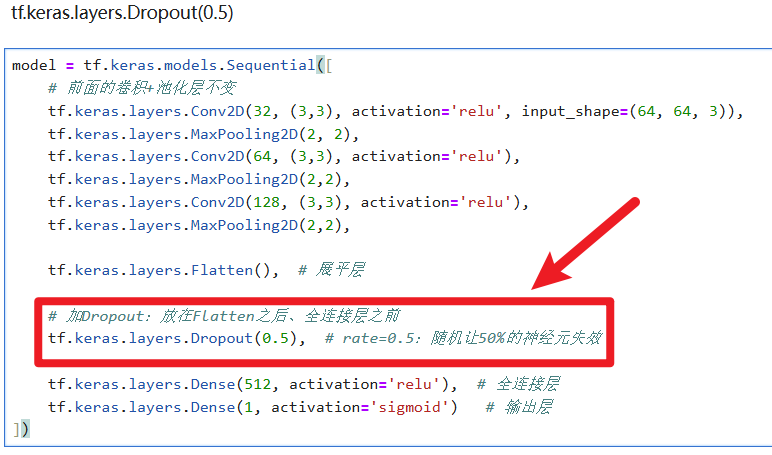
2)怎么添加Dropout
就这么简单


至此,最复杂的底层原理先告一段落,下一篇开始正式了解怎么把这些应用到YOLO算法改进优化

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)