DeepSeek-OCR 2 使用教程
摘要: DeepSeek-OCR 2是DeepSeek团队开源的新一代OCR模型,采用视觉因果流技术模拟人类阅读方式,智能解析文档结构,支持表格、文本和标签的高效识别。其核心架构DeepEncoder V2通过视觉-文本压缩技术,在A100 GPU上每日可处理超20万页文档。环境配置要求CUDA 11.8+、Python 3.8+及16GB+显存,推荐使用vLLM推理引擎或Gradio可视化界面部
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力,此外还有5090, 3090和P40,价格每小时只需要8毛,赠送的算礼金够用一整天。
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
1. 简介
DeepSeek-OCR 2 是 DeepSeek 团队于 2026 年 1 月 26 日正式开源的新一代光学字符识别(OCR)模型,代表了文档智能理解领域的重大突破。该模型的核心创新是 视觉因果流(Visual Causal Flow) 技术,这是一种全新的文档解析范式,彻底改变了机器"阅读"文档的方式。
与传统 OCR 系统按像素顺序从左上到右下机械扫描的方式不同,DeepSeek-OCR 2 通过视觉因果流模拟人类的阅读方式——它不会按固定的栅格顺序遍历文档,而是根据语义意义而非空间坐标来识别重要信息。模型首先对整个文档建立全局理解,然后智能地决定逻辑阅读顺序,例如遵循列的布局、将标签与其值关联、以及连贯地解析表格。
在技术架构上,DeepSeek-OCR 2 采用了 DeepEncoder V2 视觉编码器,这是一个将视觉编码器转变为推理模型的创新架构。它通过可学习的查询 token 逐步处理信息,每个步骤都依赖于前一个步骤,从而在源头修复阅读顺序,并将视觉与语言自然对齐。该模型具备高效的视觉-文本压缩能力,可以将 1,000 个文本 token 压缩成仅 100 个视觉 token,同时保持超过 97% 的解码准确率。在生产环境中,模型能够在一张 A100-40G GPU 上每天生成或解析超过 200,000 页的文档。
目前相关内容已经在官网中可以直接安装使用了NVIDIA Alpamayo自动生成项目中了。
2. 环境配置
2.1 系统要求
在开始部署 DeepSeek-OCR 2 之前,请确保您的系统满足以下硬件和软件要求。由于模型采用了大规模的视觉-语言架构,对计算资源有一定要求:
| 配置项 | 最低要求 | 推荐配置 |
|---|---|---|
| CUDA 版本 | 11.8+ | 12.1+ |
| Python 版本 | 3.8+ | 3.10/3.11 |
| GPU 显存 | 16GB | 24GB+ |
| 系统内存 | 32GB | 64GB+ |
| 操作系统 | Linux (Ubuntu 20.04+) | Ubuntu 22.04 |
注意事项:如果您的显存低于 16GB,可以通过调整 gpu_memory_utilization 参数(如设为 0.6)和减小 max_model_len(如设为 4096)来降低显存占用,但这可能会影响处理长文档的能力。
2.2 安装步骤
以下是完整的环境安装流程。建议使用 Conda 创建独立的虚拟环境,以避免与系统中其他 Python 项目产生依赖冲突。整个安装过程需要下载约 10GB 的依赖包和模型文件,请确保网络连接稳定。
# 1. 克隆代码仓库
# 从 GitHub 获取 DeepSeek-OCR 2 的官方代码
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git
cd DeepSeek-OCR-2
# 2. 创建 Conda 虚拟环境
# 使用 Python 3.8 创建名为 deepseek-ocr2 的独立环境
conda create -n deepseek-ocr2 python=3.8 -y
conda activate deepseek-ocr2
# 3. 安装 PyTorch(CUDA 11.8 版本)
# 根据您的 CUDA 版本选择对应的 PyTorch 安装命令
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 \
--index-url https://download.pytorch.org/whl/cu118
# 4. 安装 vLLM 推理引擎(官方指定版本)
# 必须使用 v0.8.5 版本,其他版本可能存在 API 兼容性问题
pip install https://github.com/vllm-project/vllm/releases/download/v0.8.5/vllm-0.8.5+cu121-cp38-abi3-manylinux1_x86_64.whl
# 5. 安装项目依赖和 Flash Attention
# Flash Attention 可显著提升推理速度
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
常见问题:如果在安装 flash-attn 时遇到编译错误,请确保已安装 CUDA Toolkit 和对应版本的 GCC 编译器。
3. 快速开始
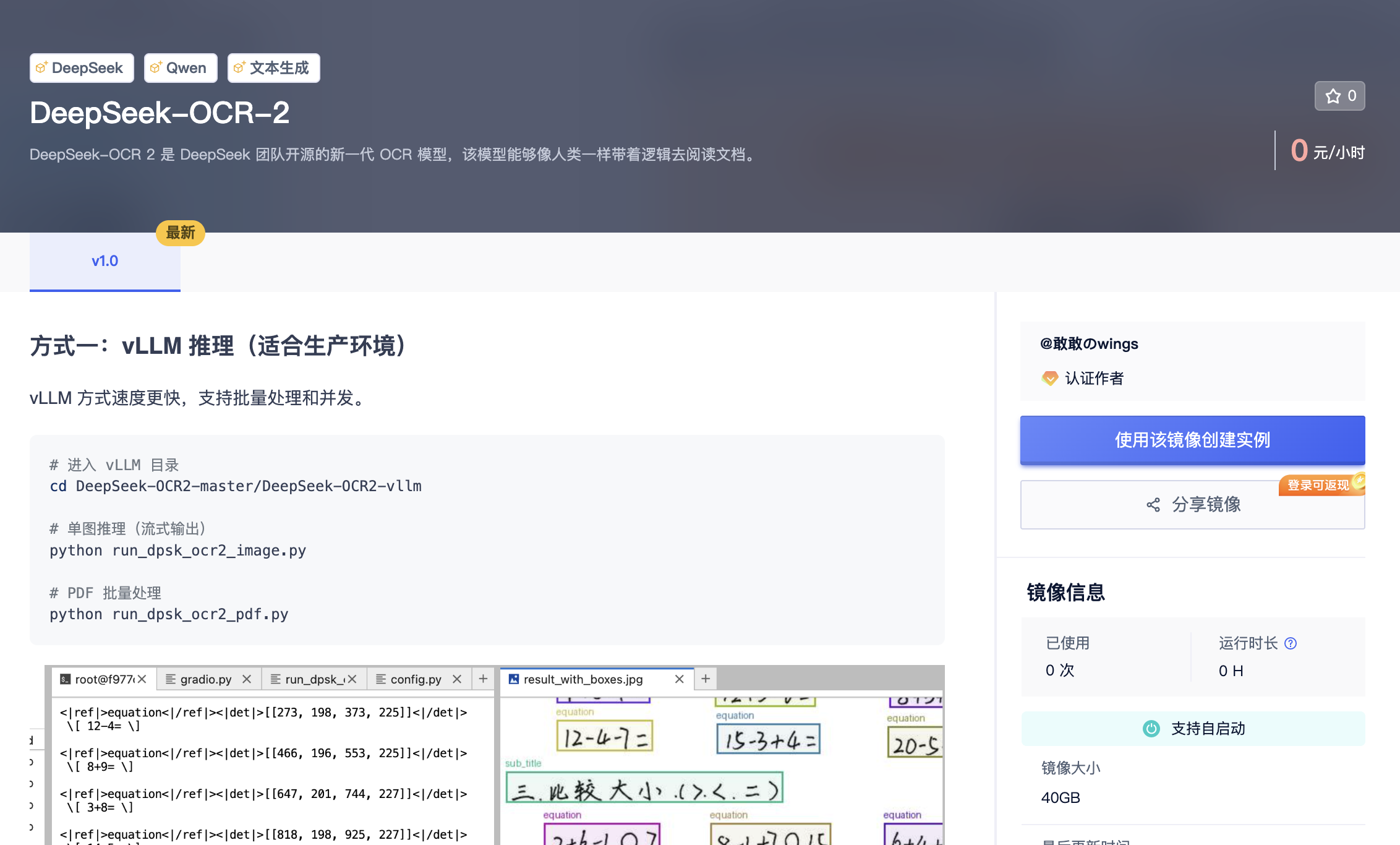
3.1 方式一:vLLM 推理(适合生产环境)
vLLM 是一个高性能的大语言模型推理引擎,专为生产环境设计。相比原生 Transformers 推理,vLLM 通过 PagedAttention 技术实现了更高效的显存管理,支持连续批处理(Continuous Batching)和并发请求处理。在实际测试中,vLLM 的推理速度可达原生实现的 3-5 倍,特别适合需要处理大量文档的批量 OCR 场景。
DeepSeek-OCR 2 官方提供了基于 vLLM 的推理脚本,支持单图推理和 PDF 批量处理两种模式。单图推理采用流式输出,可以实时查看识别进度;PDF 处理则会自动将文档拆分为单页图像,逐页进行识别后合并结果。
# 进入 vLLM 推理目录
cd DeepSeek-OCR2-master/DeepSeek-OCR2-vllm
# 单图推理(流式输出,适合交互式使用)
# 运行后会提示输入图片路径,识别结果实时显示
python run_dpsk_ocr2_image.py
# PDF 批量处理(适合文档数字化场景)
# 自动处理 PDF 中的所有页面,输出结构化 Markdown
python run_dpsk_ocr2_pdf.py
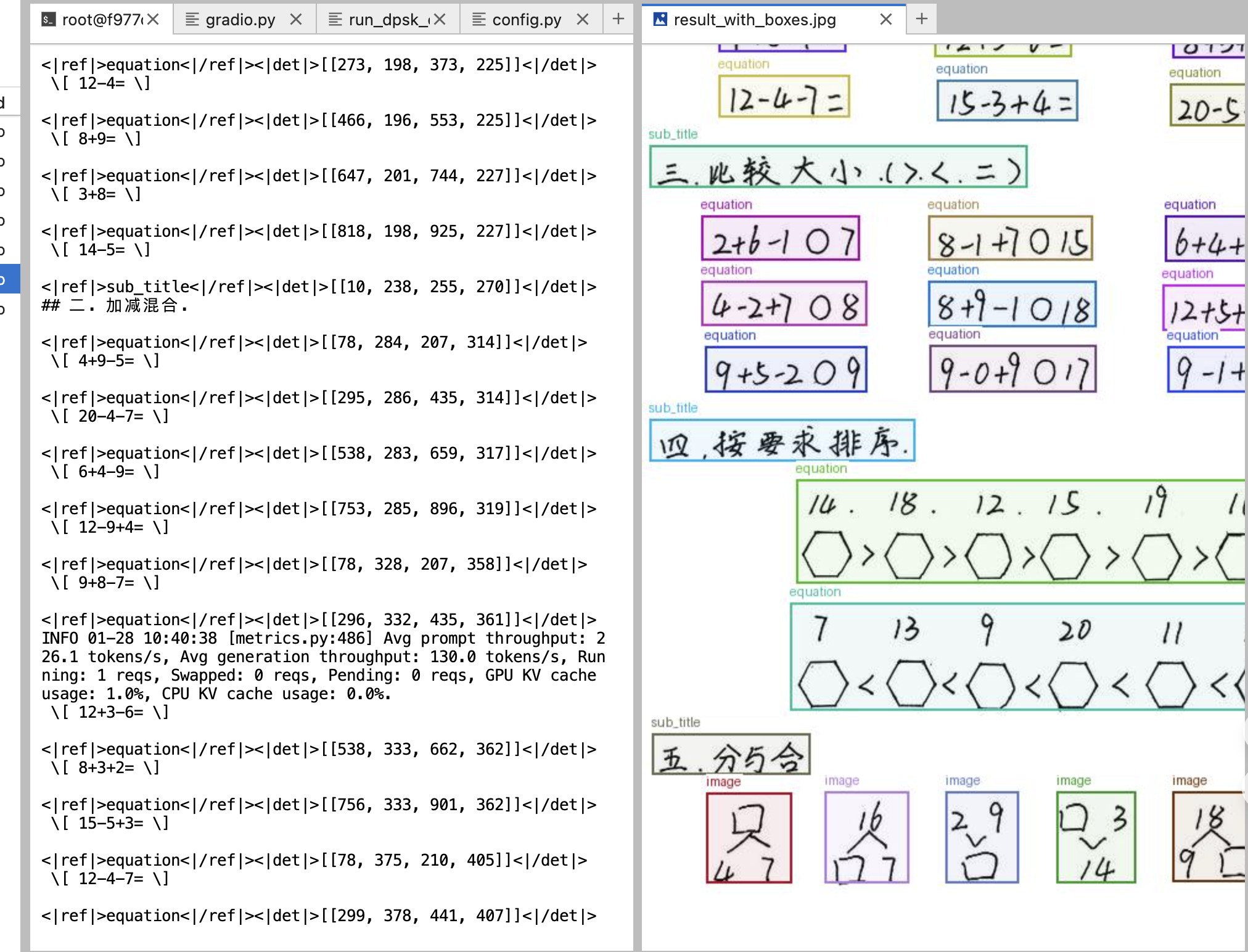
3.2 方式二:Gradio 可视化界面(推荐新手)
对于不熟悉命令行操作的用户,我们提供了基于 Gradio 框架的 Web 可视化界面。Gradio 是 Hugging Face 推出的机器学习演示工具,能够快速将 AI 模型封装为交互式 Web 应用。通过这个界面,您可以直接在浏览器中上传图片、选择识别模式、查看 OCR 结果和边界框可视化效果,无需编写任何代码。
该界面支持四种识别模式:文档转 Markdown(保留文档结构)、纯文字识别(仅提取文本)、表格识别(专门处理表格内容)以及自定义提示词(高级用户可自行编写指令)。识别完成后,界面会同时显示清理后的文本结果和带有边界框标注的可视化图像,方便您直观地了解模型对文档各区域的识别情况。
3.2.1 安装 Gradio
首先需要安装 Gradio 库。Gradio 的安装非常简单,只需一条 pip 命令即可完成。建议安装最新版本以获得最佳的界面体验和功能支持。
pip install gradio
3.2.2 启动界面
将以下代码保存为 deepseek_ocr2_gradio.py,放入 DeepSeek-OCR2-vllm 目录。这段代码实现了完整的 Web 界面功能,包括图像加载、模型推理、边界框绘制和结果展示。代码采用异步架构设计,能够高效处理用户请求,同时通过全局引擎变量避免模型重复加载,提升响应速度。
"""
DeepSeek-OCR 2 Gradio 可视化界面
"""
import asyncio
import re
import os
import time
import numpy as np
from PIL import Image, ImageDraw, ImageFont, ImageOps
import torch
import gradio as gr
# 环境配置
if torch.version.cuda == '11.8':
os.environ["TRITON_PTXAS_PATH"] = "/usr/local/cuda-11.8/bin/ptxas"
os.environ['VLLM_USE_V1'] = '0'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
from vllm import AsyncLLMEngine, SamplingParams
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.model_executor.models.registry import ModelRegistry
from deepseek_ocr2 import DeepseekOCR2ForCausalLM
from process.ngram_norepeat import NoRepeatNGramLogitsProcessor
from process.image_process import DeepseekOCR2Processor
# 配置
MODEL_PATH = "deepseek-ai/DeepSeek-OCR-2"
ModelRegistry.register_model("DeepseekOCR2ForCausalLM", DeepseekOCR2ForCausalLM)
engine = None # 全局引擎
def load_image(image):
"""加载图像"""
try:
if isinstance(image, str):
image = Image.open(image)
return ImageOps.exif_transpose(image).convert('RGB')
except:
return None
def re_match(text):
"""提取边界框"""
pattern = r'(<\|ref\|>(.*?)<\|/ref\|><\|det\|>(.*?)<\|/det\|>)'
matches = re.findall(pattern, text, re.DOTALL)
matches_image = [m[0] for m in matches if '<|ref|>image<|/ref|>' in m[0]]
matches_other = [m[0] for m in matches if '<|ref|>image<|/ref|>' not in m[0]]
return matches, matches_image, matches_other
def draw_boxes(image, refs):
"""绘制边界框"""
w, h = image.size
img_draw = image.copy()
draw = ImageDraw.Draw(img_draw)
font = ImageFont.load_default()
for ref in refs:
try:
label = ref[1]
coords = eval(ref[2])
color = (np.random.randint(0, 200), np.random.randint(0, 200), np.random.randint(0, 255))
for x1, y1, x2, y2 in coords:
x1, y1 = int(x1/999*w), int(y1/999*h)
x2, y2 = int(x2/999*w), int(y2/999*h)
draw.rectangle([x1, y1, x2, y2], outline=color, width=2)
draw.text((x1, max(0, y1-15)), label, font=font, fill=color)
except:
continue
return img_draw
async def async_generate(image_features, prompt):
"""异步推理"""
global engine
if engine is None:
engine_args = AsyncEngineArgs(
model=MODEL_PATH,
hf_overrides={"architectures": ["DeepseekOCR2ForCausalLM"]},
dtype="bfloat16",
max_model_len=8192,
trust_remote_code=True,
gpu_memory_utilization=0.75,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
logits_processors=[NoRepeatNGramLogitsProcessor(20, 90, {128821, 128822})],
skip_special_tokens=False,
)
request = {"prompt": prompt}
if image_features and '<image>' in prompt:
request["multi_modal_data"] = {"image": image_features}
final_output = ""
async for out in engine.generate(request, sampling_params, f"req-{time.time()}"):
if out.outputs:
final_output = out.outputs[0].text
return final_output
def process_ocr(image, mode, custom_prompt, crop_mode):
"""主处理函数"""
if image is None:
return "请上传图片", None
pil_image = load_image(image)
if pil_image is None:
return "图像加载失败", None
prompts = {
"文档转 Markdown": "<image>\n<|grounding|>Convert the document to markdown.",
"纯文字识别": "<image>\nFree OCR.",
"表格识别": "<image>\n<|grounding|>Extract the table content.",
"自定义": custom_prompt or "<image>\nFree OCR."
}
prompt = prompts.get(mode, prompts["纯文字识别"])
# 处理图像
image_features = DeepseekOCR2Processor().tokenize_with_images(
images=[pil_image], bos=True, eos=True, cropping=crop_mode
) if '<image>' in prompt else None
# 推理
try:
result = asyncio.run(async_generate(image_features, prompt))
except Exception as e:
return f"错误: {e}", None
# 绘制边界框
matches, _, _ = re_match(result)
result_image = draw_boxes(pil_image, matches)
# 清理文本
for m in matches:
result = result.replace(m[0], '')
return result, result_image
# Gradio 界面
with gr.Blocks(title="DeepSeek-OCR 2") as demo:
gr.Markdown("# DeepSeek-OCR 2 可视化界面")
with gr.Row():
with gr.Column():
input_image = gr.Image(label="上传图片", type="pil")
mode = gr.Radio(
["文档转 Markdown", "纯文字识别", "表格识别", "自定义"],
value="文档转 Markdown", label="识别模式"
)
custom_prompt = gr.Textbox(label="自定义提示词", visible=True)
crop_mode = gr.Checkbox(label="裁剪模式", value=True)
btn = gr.Button("开始识别", variant="primary")
with gr.Column():
output_text = gr.Textbox(label="识别结果", lines=15)
output_image = gr.Image(label="边界框可视化")
btn.click(process_ocr, [input_image, mode, custom_prompt, crop_mode], [output_text, output_image])
demo.launch(server_name="0.0.0.0", server_port=7860)
3.2.3 运行
完成代码保存后,在终端中执行以下命令启动 Gradio 服务。首次运行时,程序会自动从 Hugging Face 下载 DeepSeek-OCR-2 模型权重(约 8GB),请确保网络连接稳定。模型加载完成后,您将在终端看到服务启动成功的提示信息。
cd DeepSeek-OCR2-master/DeepSeek-OCR2-vllm
python deepseek_ocr2_gradio.py
启动成功后,打开浏览器访问 http://localhost:7860 即可使用 Web 界面。如果您需要从其他设备访问,可以将代码中的 server_name 参数设为 "0.0.0.0",这样局域网内的其他设备也能通过您的 IP 地址访问该服务。界面加载完成后,您将看到左侧的图片上传区域和参数设置面板,右侧则是识别结果展示区域。

4. 常用提示词
DeepSeek-OCR 2 通过不同的提示词(Prompt)来控制输出格式和识别行为。提示词中的 <image> 标记表示图像输入位置,<|grounding|> 标记则启用边界框检测功能,使模型在输出文本的同时标注各元素在图像中的位置坐标。以下是三种最常用的提示词模板:
| 任务类型 | 提示词 | 适用场景 |
|---|---|---|
| 文档转 Markdown | <image>\n<|grounding|>Convert the document to markdown. |
保留文档结构,输出带格式的 Markdown |
| 纯文字识别 | <image>\nFree OCR. |
仅提取文本内容,不保留格式 |
| 表格识别 | <image>\n<|grounding|>Extract the table content. |
专门处理表格,输出结构化数据 |
提示:您也可以编写自定义提示词来实现特定需求,例如 <image>\n<|grounding|>Extract all mathematical formulas. 可以专门提取文档中的数学公式。
5. 参数说明
在使用 DeepSeek-OCR 2 时,有几个关键参数会影响识别效果和性能表现。合理调整这些参数可以在不同场景下获得最佳的识别结果。以下是各参数的详细说明:
| 参数 | 说明 | 默认值 | 调整建议 |
|---|---|---|---|
base_size |
基础分辨率,影响图像预处理 | 1024 | 高清文档可适当增大 |
image_size |
图像处理尺寸,影响显存占用 | 768 | 显存不足时可减小 |
crop_mode |
是否启用裁剪模式 | True | 大图/长文档推荐开启 |
save_results |
是否保存结果到文件 | True | 批量处理时建议开启 |
gpu_memory_utilization |
GPU 显存利用率 | 0.75 | 显存不足时可降至 0.6 |
max_model_len |
最大序列长度 | 8192 | 长文档需要更大值 |
裁剪模式说明:当处理大尺寸图像或长文档时,启用裁剪模式(crop_mode=True)可以将图像智能分割为多个子区域分别处理,然后合并结果。这种方式能够有效避免显存溢出,同时保持识别精度。
6. 常见问题
6.1 Q1: 出现 ImportError: cannot import name 'SamplingMetadata' 错误
原因:vLLM 版本不兼容。DeepSeek-OCR 2 依赖特定版本的 vLLM API,而较新或较旧版本的 vLLM 可能已经修改了相关接口。
解决方案:卸载当前 vLLM 版本,安装官方指定的 v0.8.5 版本:
pip uninstall vllm -y
pip install https://github.com/vllm-project/vllm/releases/download/v0.8.5/vllm-0.8.5+cu121-cp38-abi3-manylinux1_x86_64.whl
6.2. Q2: 显存不足(CUDA Out of Memory)
原因:模型加载和推理过程中显存占用超过了 GPU 可用显存。
解决方案:调整以下参数降低显存占用:
engine_args = AsyncEngineArgs(
gpu_memory_utilization=0.6, # 降低显存利用率
max_model_len=4096, # 减小最大序列长度
)
6.3 Q3: 模型下载速度慢或失败
原因:Hugging Face 服务器在国内访问可能不稳定。
解决方案:使用国内镜像源或手动下载模型后指定本地路径:
MODEL_PATH = "/path/to/local/DeepSeek-OCR-2" # 修改为本地模型路径
7. 总结
DeepSeek-OCR 2 作为新一代智能文档识别模型,通过视觉因果流技术实现了从"像素扫描"到"语义理解"的范式跃迁。本教程介绍了从环境配置、模型部署到实际使用的完整流程,涵盖了命令行推理和可视化界面两种使用方式。无论您是需要批量处理企业文档的开发者,还是希望快速体验 OCR 能力的研究人员,都可以根据自身需求选择合适的部署方案。
随着 DeepSeek 团队持续迭代优化,未来模型在多语言支持、手写识别、复杂版式解析等方面还将带来更多惊喜。建议关注官方 GitHub 仓库获取最新更新,也欢迎在社区中分享您的使用经验和改进建议。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)