一文看懂 TCP 滑动窗口与拥塞控制的底层逻辑:数据如何在复杂网络中稳定传输
在上一篇文章中,我们已经对 TCP 协议有了一个初步认识,知道它是如何通过序号、确认应答以及重传机制来保证数据可靠传输的。不过,当真正开始思考 TCP 的工作过程时,一个问题很快就会浮现出来:既然数据一定要发,那到底该发多快呢?发得太慢,网络资源被白白浪费;发得太快,又可能瞬间把网络压垮。正是为了在这两者之间找到一个平衡点,TCP 设计了动态窗口和拥塞控制机制。它们并不会一开始就“全速前进”,而是

🔥海棠蚀omo:个人主页
❄️个人专栏:《初识数据结构》,《C++:从入门到实践》,《Linux:从零基础到实践》,《Linux网络:从不懂到不会》
✨追光的人,终会光芒万丈
博主简介:

目录
前言:
在上一篇文章中,我们已经对 TCP 协议有了一个初步认识,知道它是如何通过序号、确认应答以及重传机制来保证数据可靠传输的。不过,当真正开始思考 TCP 的工作过程时,一个问题很快就会浮现出来:既然数据一定要发,那到底该发多快呢?
发得太慢,网络资源被白白浪费;发得太快,又可能瞬间把网络压垮。
正是为了在这两者之间找到一个平衡点,TCP 设计了动态窗口和拥塞控制机制。它们并不会一开始就“全速前进”,而是通过不断试探和调整,逐步找到当前网络环境下最合适的发送节奏。接下来,我们就从这些机制入手,一起看看 TCP 是如何在复杂网络中控制传输速度的。
一.滑动窗口
1.1引入滑动窗口的概念
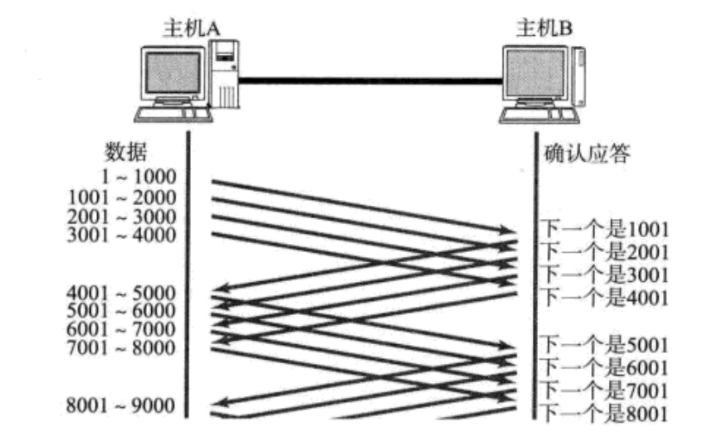
在上一篇初识TCP协议的讲解中,当我们讲到确认应答机制的时候,提到过一种通信方式,即发送方可以在没有收到应答的情况下,接着发送报文,那么这种操作是如何实现的呢?
答案就是通过滑动窗口实现的,而它的概念就是:滑动窗口就是在收到确认之前,可以连续发送数据的一种机制。
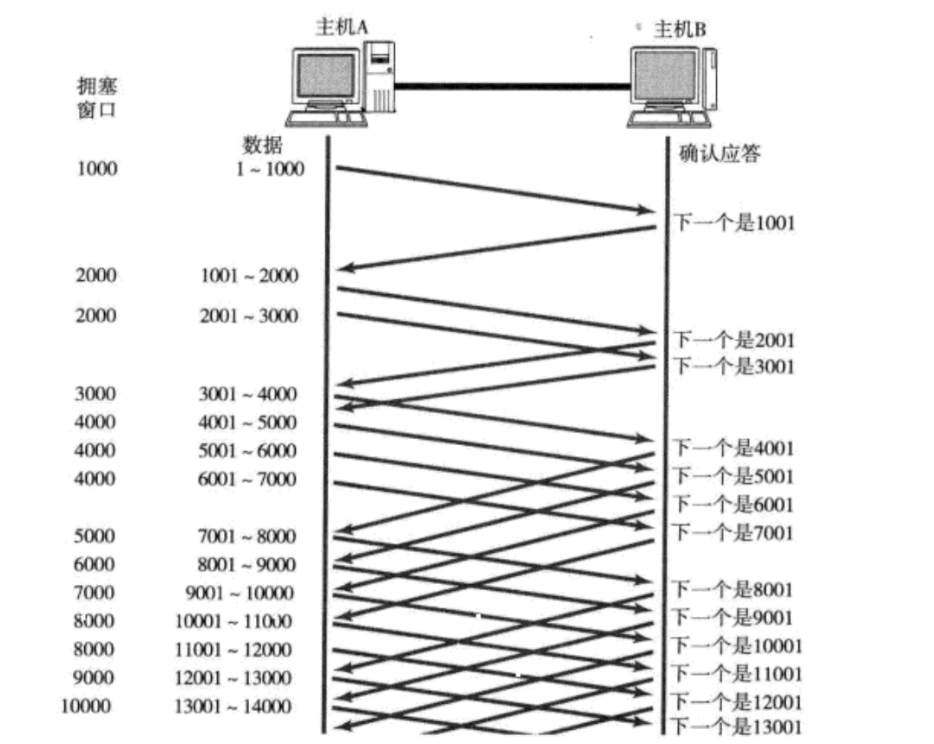
而滑动窗口的大小,或者说滑动窗口的范围则是无需确认应答而可以继续发送数据的最大值,就如上图所示的那样,此时的滑动窗口的大小就是4000个字节,发送方连着发了4次,每次1000个字节。
但是这个无需确认应答不代表不需要应答,而是暂时不需要应答。
1.2滑动窗口在哪里?如何理解?
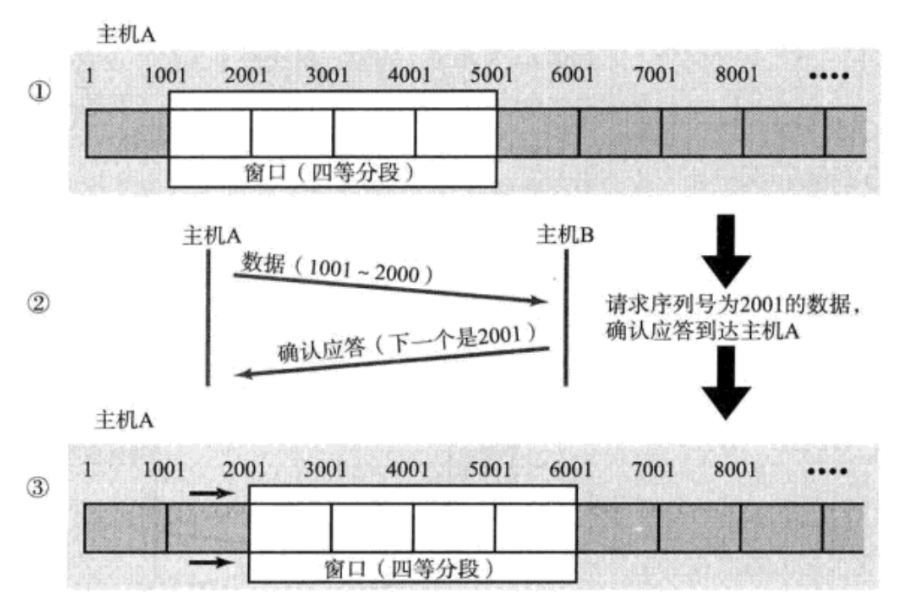
那么通过上面这张图我们就可以更好地去理解滑动窗口,滑动窗口就是在发送缓冲区中,它就属于发送缓冲区的一部分。
而在上一篇中我们当时说可以在逻辑上将发送缓冲看作线性结构,或者说数组,那么该如何在数组中表示一段内容呢?
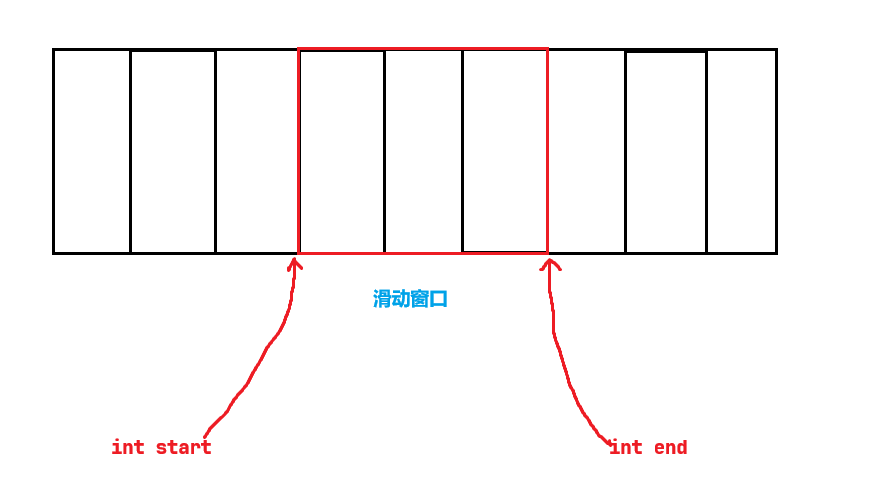
很简单,只需要两个指针start和end不就能在数组中表示一段内容吗?
有了上面的认识后,下面我们先输出几个结论:
1.滑动窗口的存在,将发送缓冲区切分为了三部分:
a.左半部分:已发送,已确认
b.窗口内的部分:直接发,暂时不要应答
c.右半部分:待发送
而左半部分已发送已确认表示的另外一个意思就是这部分数据已经无效了,这段话对于下面问题的理解是很重要的。
2.滑动窗口是从左向右滑动的,那么能否从右向左滑动呢?为什么?
答案是不能从右向左滑动,因为左半部分的数据已经无效了,向左边滑动没有意义,右边才是要发送出去的数据,所以滑动窗口的方向只能是从左向右滑动。
3.如何理解滑动?
既然上面我们已经将发送缓冲区看作是数组了,并且通过start和end指针标明了滑动窗口的范围,那么滑动不就相当于start和end指针都向后++吗?
那么在输出了上面的结论后,相信大家心中还有疑惑,下面我们接着解决存在的疑惑:
1.滑动窗口的大小是怎么决定的?
对于这个问题,我们暂时先将其认为是根据对方ACK报文中的win窗口大小来决定的,也就是根据对方的接收能力来决定的。
而在我们上一篇的讲解中,流量控制也是根据对方的接收能力来进行操作的,那么滑动窗口和流量控制之间有什么关系呢?
答案就是流量控制的底层实现就是滑动窗口,通过改变滑动窗口的大小不就可以实现流量控制吗?不过这都是后话了,下面我们再细讲这个问题。
2.滑动时start和end是怎么确定的?接收方发来的ACK报文中是含有确认序号的,这个确认序号不就是下一次从哪里开始发送吗?
这不就相当于天然的start嘛,而有了start,end直接等于start + win就行了,那么直接就可以得到后面每一次的start和end,就可以实现滑动了。
1.3滑动窗口的细节问题
通过上面的讲解,我们对于滑动窗口有了一个基本的认识,但是只有上面那些还不够,所以下面我们再深入地谈一些滑动窗口的细节问题:
细节1:滑动窗口的范围,大小会变化吗?会变大吗?什么时候,会变小吗?什么时候?会不变吗?什么时候?
因为接收方的win大小是不断变化的,那么根据win而决定的滑动窗口的大小也是会变化的。
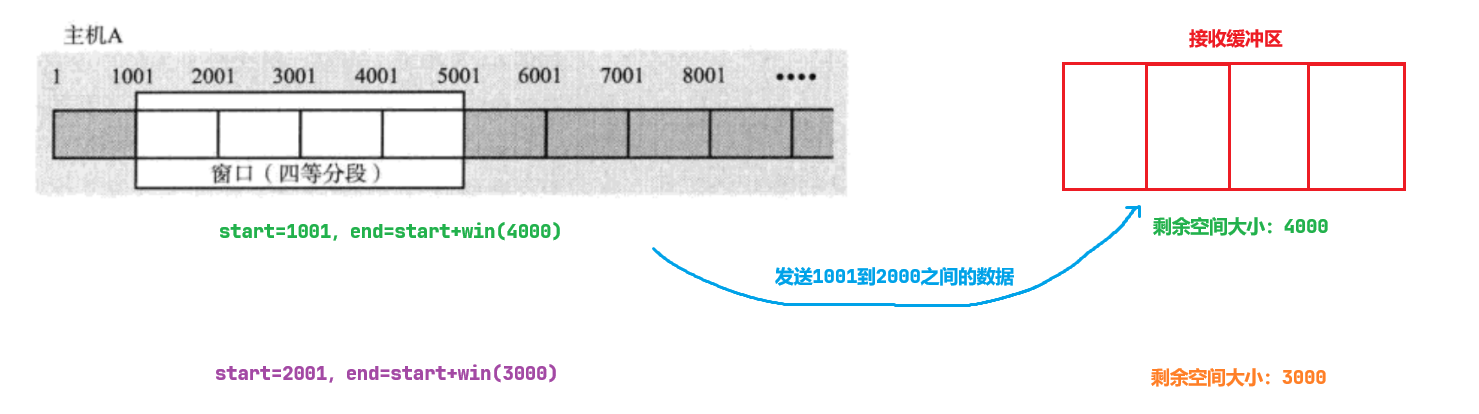
滑动窗口变大:接收方的接收缓冲区中本来就有一些数据,而发送方发过去1000字节,接收方读取2000字节,那么接收方的接收缓冲区的剩余空间不就慢慢变大了吗?
而根据接收方的win来决定的滑动窗口也就会随之变大。
滑动窗口变小:如果我们发过去的数据接收方都不读,就在接收缓冲区中放着,那么随着发送的数据越来越多,原本是4000,后面变成3000,2000,接收缓冲区中的剩余空间就会却来越小,那么随之滑动窗口也会越来越小。
滑动窗口不变:如果我们发送过去的数据是1000字节,接收方也读取1000字节,也就是我们发过去多少,对方就读多少,那么接收缓冲区的剩余空间大小就会保持不变,那么滑动窗口的大小也会保持不变。
下面我们以滑动窗口大小变小的例子来简单证明一下:
比如刚开始的时候,接收缓冲区剩余空间大小是4000个字节,而现在的start是1001,通过计算end为5001。
那么当发送方将1001-2000的数据发给接收方后,返回来的ACK报文中接收方的剩余空间大小就变为了3000,并且确认序号为2001,也就是新的start,而通过计算end的值就为5001。
可以看到,在上面的情况中,左边一直在滑动,但是右边却一直没有滑动,那么滑动窗口的大小不就会一直变小吗?
细节2:start会大于end吗?
答案是不会的,根据上面计算end的公式,win的大小一定是大于等于0的,所以经过计算,start最多和end相等,不可能大于end。

细节3(重点):丢包了怎么办?
对于丢包的情况我们在上一篇中就已经做了分析,无非就两种情况:丢数据或者丢应答,那么下面我们先来看丢应答的情况:
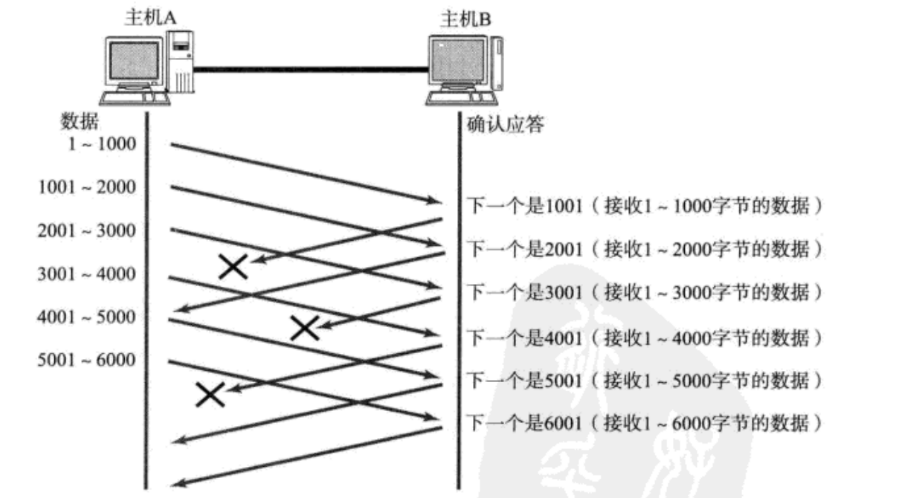
如上图所示,上面总共向接收方发送了6次数据,所有的数据都被接收方收到了,但是发送回来的应答却有几个丢失了,那么我的问题是:那些丢失了的应答报文,它们重要吗?它们丢了有影响吗?
其实它们不重要,只要最后一个ACK报文到了发送方的手里,通过确认序号6001它就知道,前面的数据已经全部发送到接收方手里了,即使没有收到前面的几个ACK报文,也不会影响发送方的判断,也就不会重发数据。
那么这时候有人就要问了:那最后一个ACK报文要是丢了呢?
答案很简单,重发不就完了。
那么下面才是我们要讲的重点,即丢数据的情况:
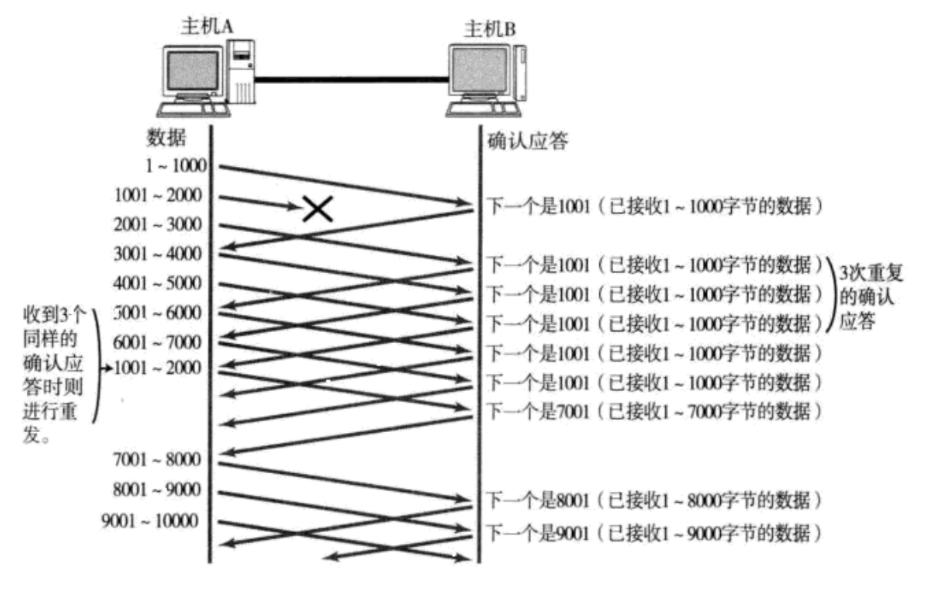
那么在上图的情况中,1001-2000这段区间的数据在发送过程中丢失了,并且因为确认序号的定义,所以返回来的所有ACK报文中的确认序号都是1001,而当发送方收到3个同样的确认应答时就会进行重发,并且这个重发是" 快重传 ",不是等到超时了再进行超时重传。
那么接下来发送方就会将1001-2000之间的数据进行" 快重传 ",而这就是上图的过程,我知道这里面会有很多问题,下面我们一一来解答:
1.发送方怎么知道只有1001-2000之间的数据丢失了,万一2001-3000,3001到4000之间的数据也丢失了呢?
其实发送方并不知道后面到底丢了多少数据,但是它能肯定1001到2000之间的数据丢失了,为什么呢?
因为1001-2000之间的数据如果没丢,那么返回来的ACK报文中确认序号就不可能是1001,而是后面的某个数字,所以对于发送方而言,它只能确定1001到2000之间的数据丢失了,所以它也只会将1001-2000之间的数据进行" 快重传 "。
那么回到我们的问题,后面的数据也丢了那怎么办呢?
从上图我们也可以看到,后面还是会有数据传来的,那么将1001-2000之间的空隙填补了之后,如果后面的2001-3000之间的数据也丢了,那么后面新发数据的ACK报文中的确认序号就会变为2001,之后的处理流程就和上面是一样的了。
总而言之,发送方它是不知道具体丢了多少数据的,所以它会通过每一次" 快重传 "来一步一步解决问题。
2.不是都有了超时重传吗?为什么还要有" 快重传 ",他们两个的作用难道不冲突吗?
答案是并不冲突的,并且是互相补充的,超时重传可以用来兜底,快重传则可以用来提高速率上限。
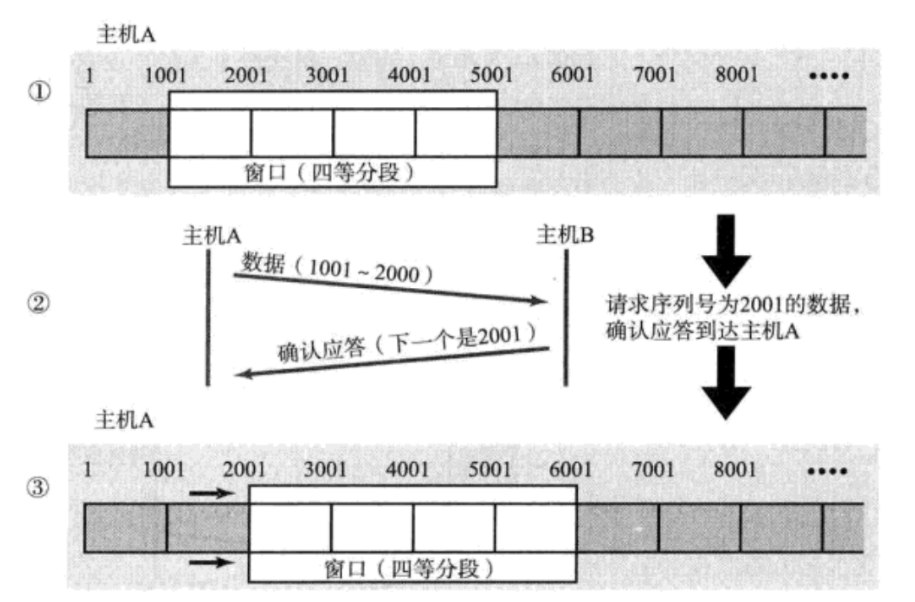
我们重新回到这张图当中,其实上面丢数据的情况我们可以将其分为3类,分别是:最左侧报文丢失,中间报文丢失和最右侧报文丢失。
我们上面讲解的情况其实就属于中间报文丢失,那么下面我们先来讲讲最左侧报文丢失会怎么样:
当最左侧报文丢失后,接收方发现后面数据的序号并不是自己所期望的,那么它就知道最左侧数据丢失了,后面的ACK报文中的确认序号就都是最左侧报文的开头,那么当发送方收到后,就会进行" 快重传 ",把丢失的数据给重新传回去。
但是我们的重点不在这,我们将视角移到上面的图上,我的问题是:在发送方没有确认最左侧数据被接收方收到之前,滑动窗口会动吗?
答案是不会动的,滑动窗口左边的数据是已发送,已确认的,最左侧数据已发送但是并未确认,所以它不能放在滑动窗口左侧区域,换言之滑动窗口的左侧就被固定住了,不会移动!!!
那么也就是数据如果在传输过程中丢包了,该数据不能从滑动窗口中删除,换句话说就是已发送,并未确认的数据会被暂存在滑动窗口内部,那么这意味着什么呢?
意味着重传机制也和滑动窗口有关系,正因为已发送,未确认的数据被暂存在了滑动窗口内部,所以重传机制才能将这部分数据重新发给接收方!!!
并且如果是中间报文丢失,最右侧报文丢失,滑动窗口都是会滑动的,那么当滑动到已发送,而确认的数据前时候,不就又变成了最左侧报文丢失问题了吗?
而这一切都与TCP协议的确认序号机制有关,它保证了滑动窗口滑动的连续性,即滑动窗口不准跳过没有确认的报文!!!
细节4:滑动窗口滑出去了怎么办?越界?
其实我们在逻辑上可以将发送缓冲区看作环形队列:
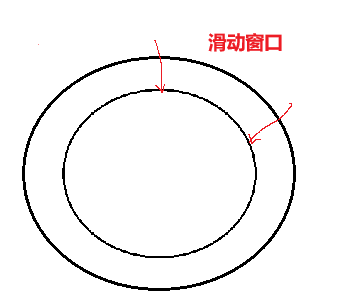
当我们将其看作是环形队列后,上面这个问题就迎刃而解了。
二.拥塞控制
2.1拥塞控制的基本概念
在上面我们所讲的所有内容,包括:确认应答机制,超时重传机制,流量控制,滑动窗口等内容全部都是针对于发送方和接收方两端进行通信的,但是别忘了,发送方和接收方要想真正通信还有一个至关重要的因素就是:网络。
如果网络非常差甚至直接没网了,任你再怎么确认应答,超时重传都没用,而判断网络问题的指标就是拥塞程度,我们不要把TCP协议太过于神化了,它也不是什么问题都能解决的,就比如:网络瘫痪,软件崩溃,OS异常等等一系列问题TCP协议都解决不了。
而TCP能解决的就是网络没有出现软硬件问题,只是比较拥堵罢了,那么该如何解决网络堵塞的问题呢?
答案就是通过拥塞控制机制,我们先来设想一种场景:
 ?
?
如果两台主机之间进行通信,如果出现少量丢包,那么你可能认为是对方的问题,重传就行了,但是如果是大量丢包呢?
就比如传了1000个报文,900多个都丢包了,这时候你还认为是对方的问题吗?
这时候你肯定不会认为是对方的问题,而是网络拥塞了,也就是网络问题了,那么该如何解决这个问题呢?
方法就是等等或者减少数据量发送,那么具体该如何去做呢?
2.2拥塞之后,如何进行控制?
TCP为了解决网络拥塞问题,引入了" 慢启动 "机制,简单理解就是:先发少量的数据,探探路,摸清当前的网络拥堵情况,再决定按照多大的速度传输数据。但是这里就有一个问题,该如何判断当前的网络拥堵情况呢?
所以这里我们要引入一个" 拥塞窗口 "的概念,它是一个int类型的变量,起始值为1,是用来衡量网络的拥塞程度的。
我们来看这张图,刚开始发送方只发送1个报文,当接收到对方的ACK报文后,下次就发2个报文,还能收到ACK报文后,下次就会发4个报文,以此类推,一步一步摸清网络拥堵的情况,这就是" 慢启动 "机制。
而在试探的过程中,每收到一个应答,拥塞窗口就会+1,那么这个值有什么用呢?
答案就是滑动窗口的大小 = min(对端win大小,拥塞窗口),也就是取二者的最小值,上面因为没有讲拥塞窗口,所以只能暂时将滑动窗口的大小理解为由对端win大小来决定,但其实是取对端win和拥塞窗口的最小值。
这其实很好理解,对端win大,但是网络不佳,你也不能传大量的数据,因为很多都会丢包;而网络非常好,但是对端win小,你也不能传大量的数据,因为对端接收不了这么多数据。
所以" 慢启动 "的本质就是通过调整滑动窗口的大小来实现的!!!

而通过上图我们可以看到" 慢启动 "的增长是呈指数级增长的,那么为什么是指数级增长呢?
从上图我们可以看出指数级增长的曲线是" 前期慢,增长快 ",而我们要的正是它的这个特点,当前期慢慢摸清网络状况后,发现网络并不拥堵,那么主要矛盾就会变成" 尽快恢复正常通信 ",而尽快不就正好对应了" 增长快 "的特点吗?
所以使用指数级增长的原因就是其特点完美符合" 慢启动 "的要求。
但是这里就有一个问题了:难道后面就一直保持指数级增长吗?
当然不会,如果在某次指数级增长后,已经临近网络堵塞的边缘,那么下次还进行指数级增长的话可能会将网络直接压胯,那么可能有人有人会问:我就发那么点数据,在浩如烟海的网络中一点都不起眼,怎么会将网络压垮呢?
答案就是你这样想,别人也会这样想,那么网络中传输数据的用户那么多,加在一起,上面的现象难道不会发生吗?
所以为了避免这种情况我们就要有新的解决方案:
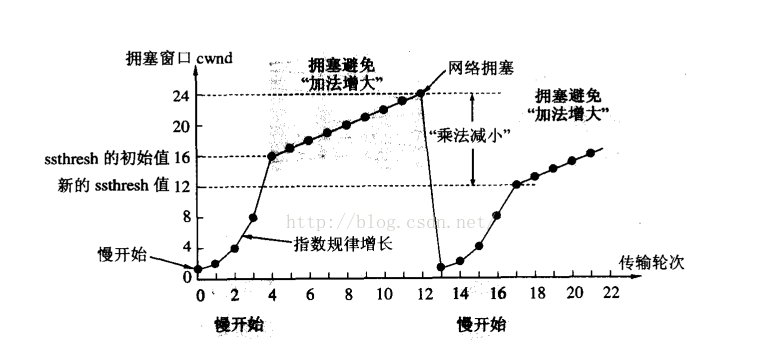
这里我们就要引入一个新的概念:ssthresh值,这个数值叫做" 慢启动 "的阈值,当拥塞窗口的值超过ssthresh后,就会从指数增长变为线性增长。
而当探测到网络拥塞时,就会重新进行" 慢启动 ",并且ssthresh的值就是上一次拥塞窗口最大值的一半。
那么最后我们来思考一下:拥塞窗口增长的本质是什么?
其实本质就是在探测最真实的网络状况,或者说在不断探测当前网络所能承受的真实传输能力!!!
以上就是一文看懂 TCP 动态窗口与拥塞控制的底层逻辑:数据如何在复杂网络中稳定传输的全部内容。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 81
81 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)