【随机森林】:双重随机 + Bagging 思想
一、从集成学习到随机森林:基础认知
随机森林是集成学习的产物,想要理解随机森林,首先要明确集成学习的核心逻辑,这是掌握随机森林的基础。
1. 集成学习的核心定义
集成学习是将多个基学习器(基础模型)进行组合训练,最终形成一个强学习器的机器学习方法,核心思想是“三个臭皮匠,顶个诸葛亮”——通过多个简单模型的协同,实现比单一模型更优越的学习性能。
2. 集成学习的三大代表方法
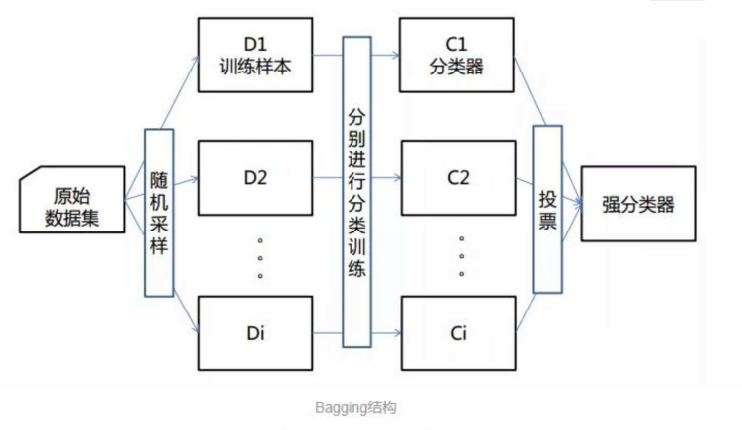
集成学习主要分为三类,不同方法的基学习器组合方式不同,随机森林属于Bagging方法的典型应用:
-
Bagging方法:并行训练多个独立的基学习器,通过投票/平均的方式输出结果,核心是降低模型方差,代表为随机森林;
-
Boosting方法:串行训练基学习器,后一个模型专注修正前一个模型的错误,核心是降低模型偏差,代表为XGBoost、LightGBM;
-
Stacking方法:堆叠模型,将多个基学习器的输出作为新特征,训练一个元学习器完成最终预测,复杂度更高。
3. 随机森林的核心定义
随机森林是以决策树为基分类器的Bagging集成模型,通过对训练数据和特征进行双重随机采样,构建多棵相互独立的决策树,最终通过多数投票(分类任务)或均值(回归任务)得到模型输出。其核心是“随机”+“森林”:随机保证了树与树之间的独立性,森林则代表由多棵决策树组成的集成模型。
二、随机森林的四大核心特性
随机森林的所有优势都源于其四大核心特性,这也是它与单一决策树、普通Bagging模型的本质区别:
1. 数据采样随机
对原始训练数据集进行有放回的随机采样(Bootstrap),生成多个与原始数据集大小相同的子数据集。每个子数据集都有部分样本重复、部分样本未被选中。
2. 特征选取随机
在训练每一棵决策树时,对特征进行随机采样——即决策树在每个节点分裂时,仅从随机选取的部分特征中选择最优分裂特征,而非使用所有特征。这种方式保证了每棵决策树的多样性,避免模型过度依赖个别特征。
3. 基分类器为决策树
随机森林的所有基学习器都是决策树,决策树的简单性和高效性为随机森林的并行训练奠定了基础,同时决策树的非线性拟合能力也让随机森林能处理复杂的特征与目标关系。
4. 多树组成“森林”
随机森林由多棵相互独立的决策树组成,单棵决策树的预测结果存在偶然性,而多棵树的投票/均值会抵消这种偶然性,大幅提升模型的泛化能力和预测准确率。
三、随机森林的生成步骤
随机森林的训练过程严格遵循Bagging的核心框架,整体步骤清晰,可分为采样-训练-集成三步,最终从多个弱决策树得到一个强分类器:
-
随机采样生成子数据集:对原始训练集进行有放回的行采样,生成 n 个与原数据集规模相同的子数据集( n 为决策树的数量),每个子数据集之间相互独立且存在样本重叠;
-
单棵决策树训练:用每个子数据集分别训练一棵决策树,训练时对特征进行随机列采样——每棵树在节点分裂时,仅从随机选取的特征集中找最优分裂点,决策树本身不做剪枝或轻度剪枝;
-
多树集成形成强学习器:所有决策树训练完成后,形成随机森林模型。对于分类任务,采用多数投票法确定最终预测类别;对于回归任务,采用所有树预测值的均值作为最终结果。
四、Sklearn中随机森林的核心API与关键参数
在Python的Sklearn库中,处理分类任务的随机森林API为sklearn.ensemble.RandomForestClassifier,处理回归任务的为RandomForestRegressor,二者参数高度一致,仅针对任务做了轻微适配。以下重点讲解分类器的核心API及参数,这是实操随机森林的关键。
1. 完整API定义
class sklearn.ensemble.RandomForestClassifier(n_estimators='warn', criterion='gini',
max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0,min_impurity_split=None,
bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0,
warm_start=False, class_weight=None)2. 核心参数详解
随机森林的参数分为独有参数(随机森林特有的,体现其Bagging特性)和继承自决策树的参数(与DecisionTreeClassifier一致)
(1)随机森林独有参数
这类参数是随机森林区别于单一决策树的关键,决定了模型的“随机性”和训练效率:
-
n_estimators:随机森林中决策树的个数,随机森林最核心的独有参数。Sklearn0.20版本默认10,0.22及以后版本默认100。实操建议:一般设置100-300即可,树的数量过多会增加时空成本,且模型性能提升趋于平缓;
-
max_features:单棵决策树分裂时可使用的最大特征数,重要。取值支持整数、小数、字符串:
auto/sqrt表示取特征数的平方根,log2表示取特征数的对数,None表示使用所有特征,小数表示取特征数×小数的结果。实操建议:该参数需平衡模型性能和多样性——增大值会提升单棵树的性能,但降低树的多样性,易过拟合;减小值则相反,需通过交叉验证选择; -
bootstrap:是否对原始数据集进行有放回的随机采样,默认
True,保持默认即可(这是Bagging的核心特性); -
n_jobs:并行训练的任务数,对大数据集至关重要。
1表示不并行,正整数表示有多少个并行,-1表示利用CPU所有核心进行并行训练。实操建议:实操中直接设为-1,充分利用硬件资源提升训练速度; -
oob_score:是否使用袋外样本评估模型性能,默认
False。开启后模型会用未被采样到的袋外样本做验证,无需单独划分验证集,适合大数据集。
(2)继承自决策树的参数
这类参数与决策树一致,用于控制单棵决策树的结构,防止单棵树过度生长,间接提升森林的泛化能力,均为实操调优重点:
-
criterion:节点分裂的判断依据,默认
gini(基尼系数),可选entropy(信息增益)。保持默认gini即可,基尼系数的计算效率高于信息增益; -
max_depth:单棵决策树的最大深度,重要。默认
None(树无限制生长,直到叶子节点纯化为止)。实操建议:数据/特征较少时保持默认;数据/特征较多时,设置10~100之间的数值,限制树的深度防止单棵树过拟合; -
min_samples_split:分裂一个内部节点所需的最小样本数,重要。默认2。实操建议:样本量小时保持默认;样本量极大时增大该值(如10、50),避免无意义的细枝分裂;
-
min_samples_leaf:叶子节点的最少样本数,重要。默认1。若叶子节点样本数小于该值,会与兄弟节点一起被剪枝。实操建议:样本量大时设置为大于50的数值,避免单棵树学习到训练集的噪声;
-
max_leaf_nodes:单棵决策树的最大叶子节点数,默认
None。设置后会限制树的分裂,防止过拟合,特征极多时可开启,值通过交叉验证选择; -
class_weight:指定样本各类别的权重,默认
None。适合不平衡数据集(如欺诈检测、疾病诊断),设为balanced时,模型会自动给样本量少的类别分配更高权重,避免模型偏向多数类; -
random_state:随机种子,默认
None。设置固定值(如0、42)可让模型的采样和分裂结果固定,保证实验可复现,实操中建议设置; -
min_impurity_split/min_impurity_decrease:限制节点的不纯度,若节点不纯度低于阈值则停止分裂,一般保持默认即可,无需调优;
-
min_weight_fraction_leaf:叶子节点的最小样本权重和,默认0,仅样本有缺失值/类别分布极不平衡时需关注,常规任务无需调整。
五、随机森林的核心优缺点
随机森林是工业界“万金油”模型,其优点贴合实际业务需求,缺点则相对次要,实操中可通过调参规避,整体性价比极高。
1. 优点【六大核心优势】
随机森林的优点源于其“双重随机+多树集成”的设计,也是它成为工业界首选模型的原因:
-
预测准确率极高:多树集成抵消了单棵决策树的偶然性,泛化能力远优于单一决策树;
-
抗噪声能力强:随机性的引入让模型对训练集中的噪声不敏感,不易被异常值干扰;
-
不易过拟合:双重随机+多树投票的机制,从根本上解决了单一决策树易过拟合的问题,即使单棵树充分生长,森林的泛化能力依然很强;
-
处理高维数据能力优秀:无需提前做特征选择,可直接处理高维稀疏数据(如文本、图像特征),模型会自动筛选重要特征;
-
训练效率高:基学习器决策树相互独立,支持并行训练,适合大数据集;
-
对数据要求低:无需对特征做标准化/归一化,对缺失值、异常值有一定的鲁棒性,减少数据预处理工作。
2. 缺点【两类可规避问题】
随机森林的缺点均非致命,可通过调参或结合其他模型规避:
-
时空成本随树的数量增加而升高:当
n_estimators设置过大时,模型的训练时间和内存占用会显著增加,实操中设置合理的树数量即可规避; -
模型可解释性差,属于“黑盒模型”:单棵决策树的逻辑清晰可解释,但多棵树的集成让随机森林的预测逻辑变得模糊,无法直观解释“某个特征如何影响预测结果”。若业务需要强可解释性(如金融风控的模型解释),可搭配决策树、逻辑回归等白盒模型使用;
-
对极端不平衡的数据集处理效果有限:虽可通过
class_weight缓解,但对类别比例极悬殊的数据集,效果不如专门的不平衡数据处理方法(如SMOTE过采样+下采样)。
六、随机森林的适用场景
结合随机森林的特性,其在分类、回归、特征选择等任务中均表现优异,尤其适合以下场景,也是工业界的主流应用方向:
-
分类任务:欺诈检测、客户流失预测、图像分类、文本分类、疾病诊断等,尤其是高维数据的分类;
-
回归任务:房价预测、销量预估、股价预测等,使用
RandomForestRegressor即可,参数与分类器基本一致; -
高维数据场景:无需做特征降维,可直接处理数百、数千维的特征,且能通过
feature_importances_输出特征重要性,实现特征选择; -
大数据集场景:支持并行训练(
n_jobs=-1),训练效率远高于单一决策树、逻辑回归等模型; -
对过拟合敏感的场景:相比单一决策树,随机森林的抗过拟合能力极强,适合训练集噪声较多的场景。
不适用场景:对模型可解释性要求极高的场景、极端不平衡的小数据集场景。
七、示例
使用随机森林+下采样的数据处理方法,分辨银行贷款的类型(正常 or 欺诈)
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
import matplotlib.pyplot as plt
#定义绘制混淆矩阵函数
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm=confusion_matrix(y,yp)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range (len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
#数据预处理
data = pd.read_csv("./creditcard.csv", encoding='utf8')
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']]) #标准化
data = data.drop(['Time'], axis=1)
X = data.drop('Class', axis=1)
y = data['Class']
from sklearn.model_selection import train_test_split, cross_val_score
#切分数据
x_train_w,x_test_w,y_train_w,y_test_w=train_test_split(X, y, test_size=0.2, random_state=0)
#下采样
x_train_w['Class']=y_train_w
data_train=x_train_w
positive_eg=data_train[data_train['Class']==0]
negative_eg=data_train[data_train['Class']==1]
positive_eg=positive_eg.sample(len(negative_eg))
data_c=pd.concat([positive_eg,negative_eg])
x_train = data_c.drop('Class', axis=1)
y_train = data_c['Class']
#构建随机森林模型
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100,
max_features=0.8,
random_state=0)
#训练模型
rf=rf.fit(x_train,y_train)
#训练集自测
train_pred = rf.predict(x_train)
print(metrics.classification_report(y_train,train_pred,digits=6))
# cm_plot(y_train,train_pred).show()
#测试集测试
test_pred = rf.predict(x_test_w)
print(metrics.classification_report(y_test_w,test_pred,digits=6))
# cm_plot(y_test_w,test_pred).show()
#标出重要影响参数(可选)
# importances = rf.feature_importances_
# im = pd.DataFrame(importances,columns=["importances"])
# cols=data.columns
# cols_1 = cols.values
# cols_2 = cols_1.tolist()
# cols = cols_2[0:-1]
# im['cols'] = cols
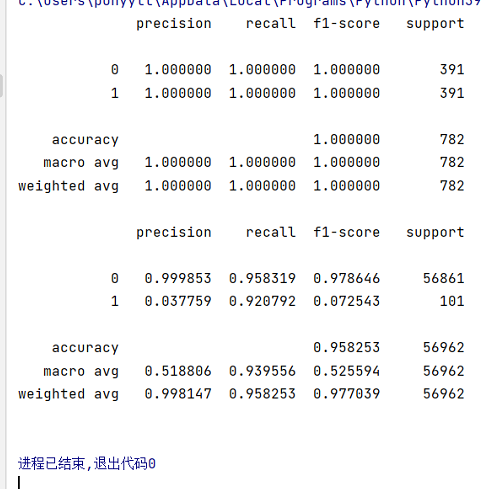
演示结果:
测试集召回率和准确率都比较高

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)