HBase进阶
HBase读写流程采用分布式架构,客户端通过Zookeeper定位元数据表(hbase:meta)位置,缓存Region信息后直接与目标RegionServer交互。写流程通过WAL日志和MemStore实现数据持久化,定期刷写为HFile文件,并自动进行Minor/Major合并优化存储。读流程优先查询BlockCache和MemStore,未命中则读取磁盘文件。表设计强调反范式化,通过冗余列族
读流程*
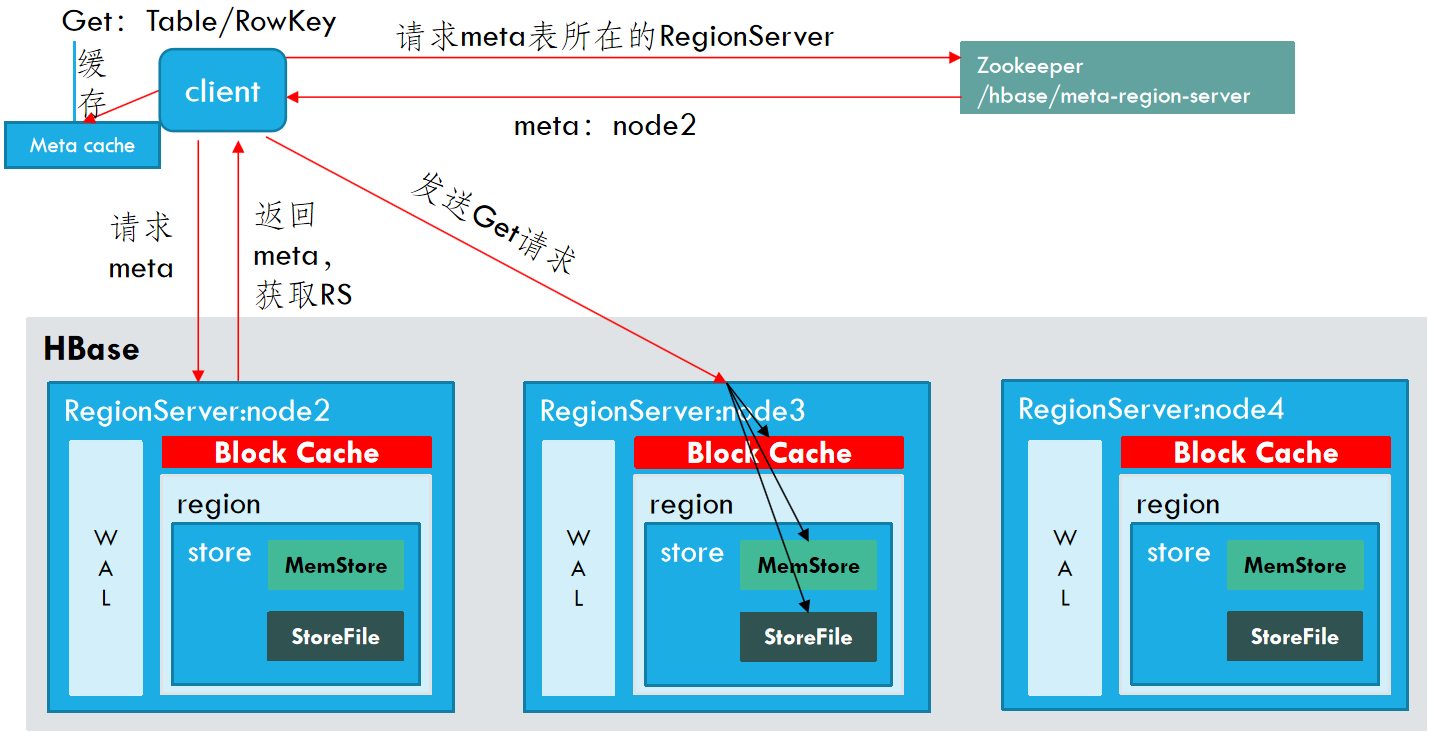
- Client访问Zookeeper,查找hbase:meta表位置,看它在哪个RegionserverR上。(类似于到图书馆总服务台,询问:“图书馆的《馆藏位置总目录》放在哪个借阅区?”)
- Client访问regionserverR上hbase:meta表中的数据,查找要操作rowkey的所在表对应region所在的regionserverX,将读取到的meta数据缓存到Client的Meta Cache中。(类似于到指定借阅区,找到《馆藏位置总目录》,翻查你要借的某书在某楼某区的某个书架,然后把这个位置记在自己的备忘录里)
- Client读取regionserverX上的对应的region数据(类似于带着备忘录的记录去找书)
- 定位到真正的数据所在的region的时候,按照下述步骤进行操作:查找blockcache;如果blockcache有完整的数据则直接返回;如果没有或者有部分数据则,再去读取MemStore,查找storefile的数据,同时将数据缓存与blockcache中。如果client获取不到数据,则直接结束;
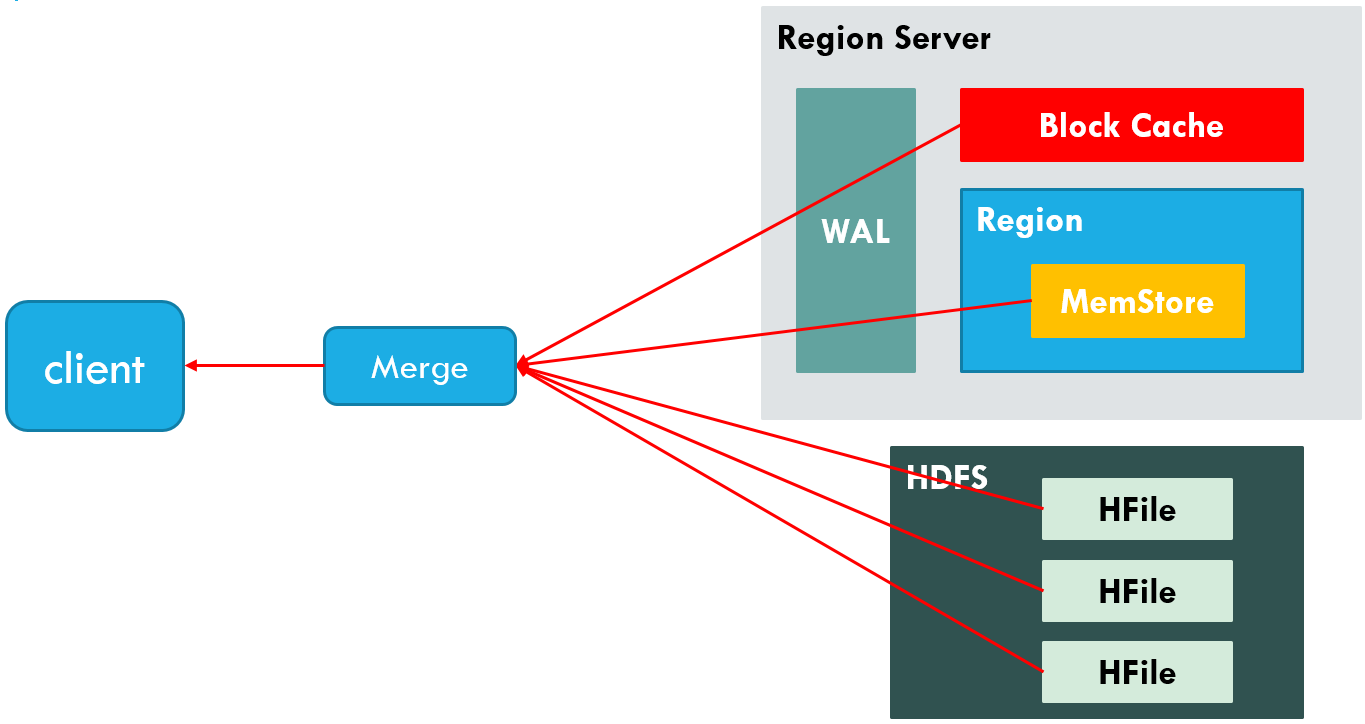
总结:
写流程*
写数据整体流程
当用户向HRegionServer发起HTable.put(Put)请求时,其会将请求交给对应的HRegion实例来处理。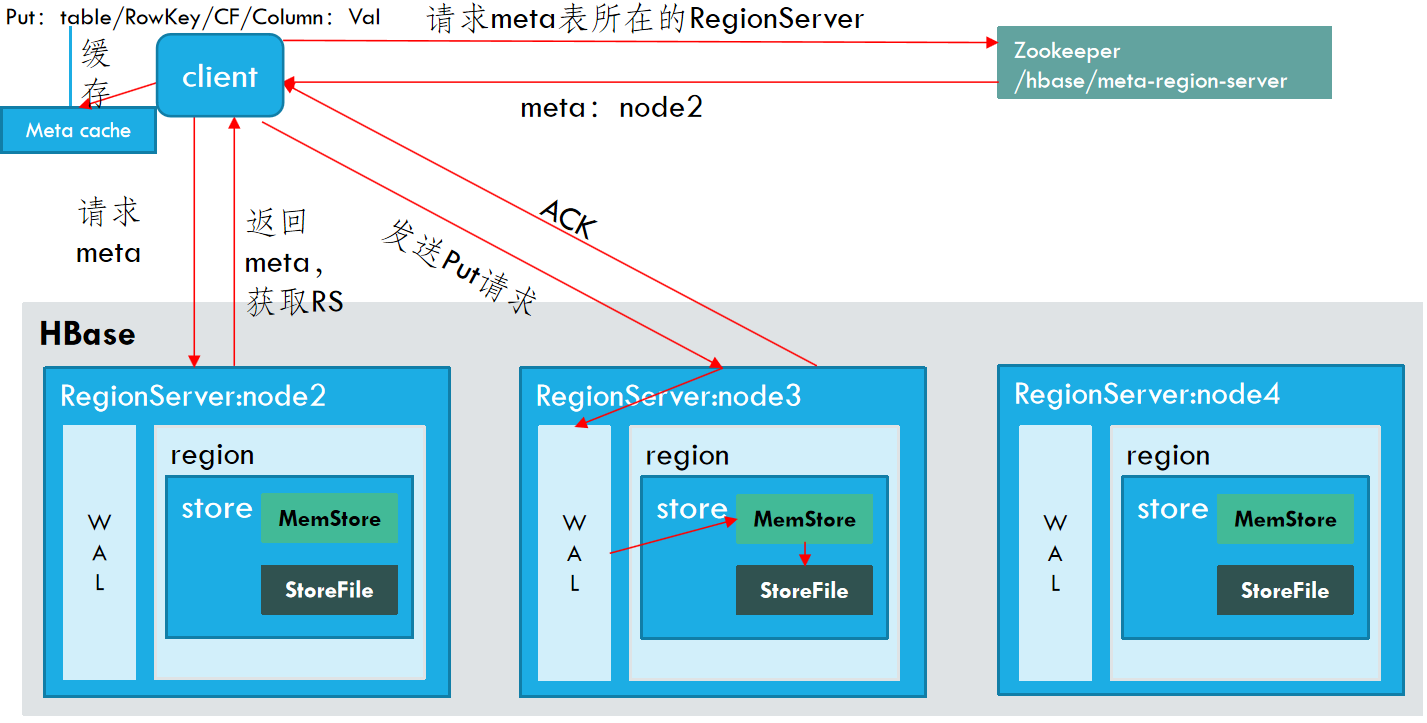
- Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
- 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server进行通讯;
- 将数据顺序写入(追加)到WAL;
- 将数据写入对应的MemStore,数据会在MemStore进行排序;
- 向客户端发送ACK;
- 等达到MemStore的刷写时机后,将数据刷写到HFile。
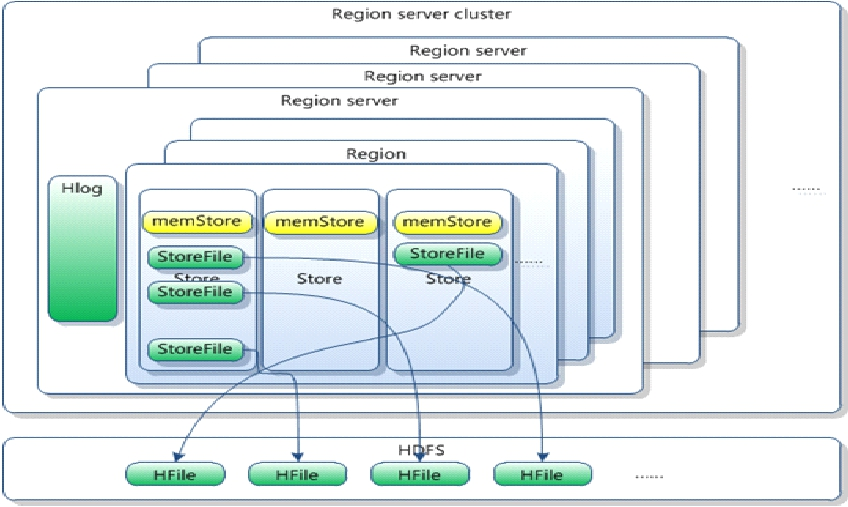
注意:WAL是标准的Hadoop SequenceFile,并且存储了HLogKey实例。这些键包括序列号和实际数据,所以在服务器崩溃时可以回滚还没有持久化的数据。
一旦数据被写入到WAL中,数据就会被放到MemStore中。同时还会检查MemStore是否已经满了,如果满了,就会被请求刷写到磁盘中去。刷写请求由当前HRegionServer的另外一个线程处理,它会把数据写成HDFS中的一个新HFile。同时也会保存最后写入的序号,系统就知道哪些数据现在被持久化了。
多次数据刷写之后会创建许多数据存储文件,后台线程就会自动将小文件聚合成大文件,这样磁盘查找就会被限制在少数几个数据存储文件中。磁盘上的树结构也可以拆分成独立的小单元,这样更新就可以被分散到多个数据存储文件中。所有的数据存储文件都按键排序,所以没有必要在存储文件中为新的键预留位置。
查询时先查找内存中的存储,然后再查找磁盘上的文件。这样在客户端看来数据存储文件的位置是透明的。
删除是一种特殊的更改,当一条记录被删除标记之后,查找会跳过这些删除过的键。当页被重写时,有删除标记的键会被丢弃。
WAL(WRITE AHEADLOG)
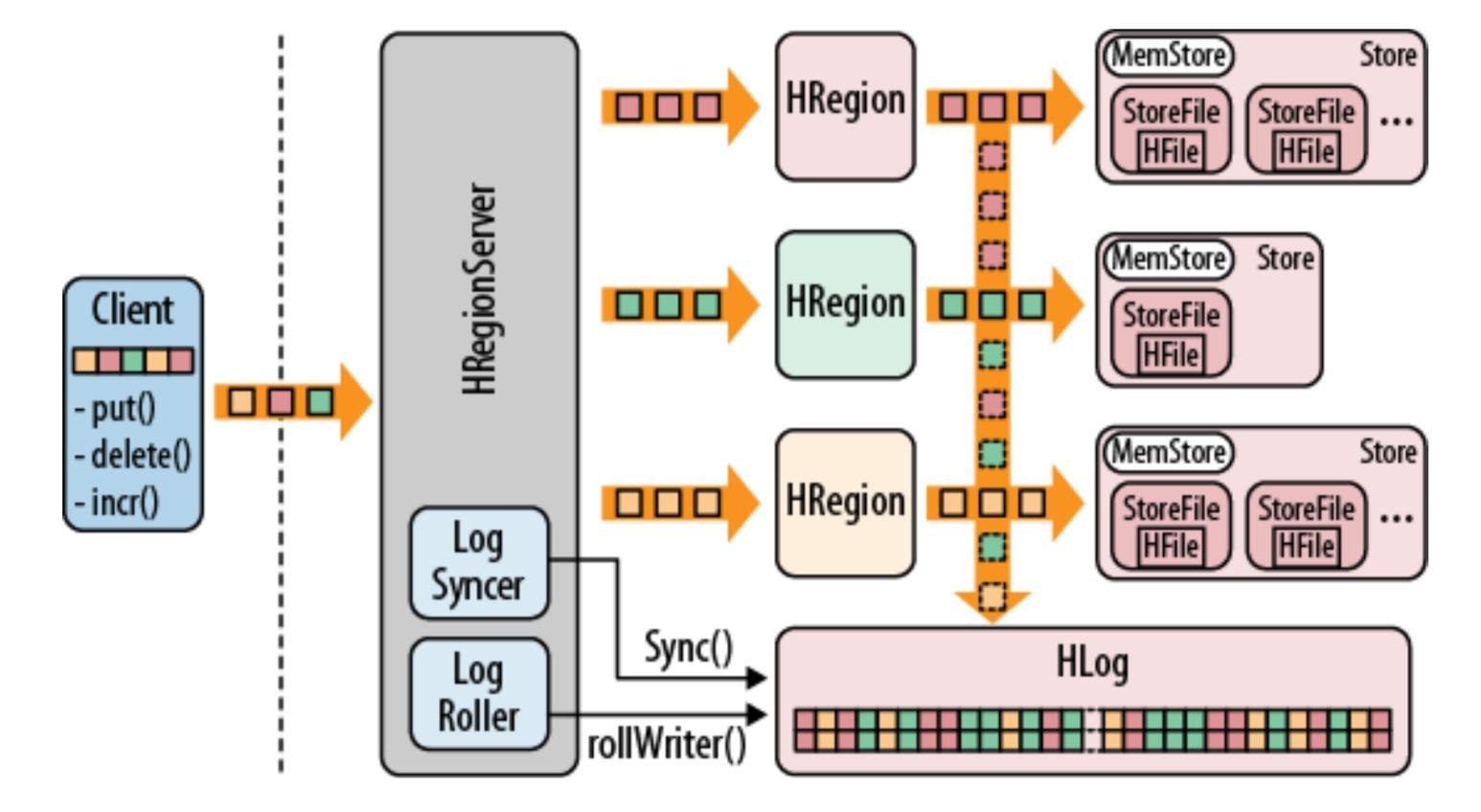
HLog文件就是一个普通的Hadoop Sequence File ,Sequence File 的Key是HLogKey对象, HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp ,timestamp是”写入时间” ,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
键(四个维度)value(单元格的值)
该文件作用是保证数据不丢失。
MemStore Flush
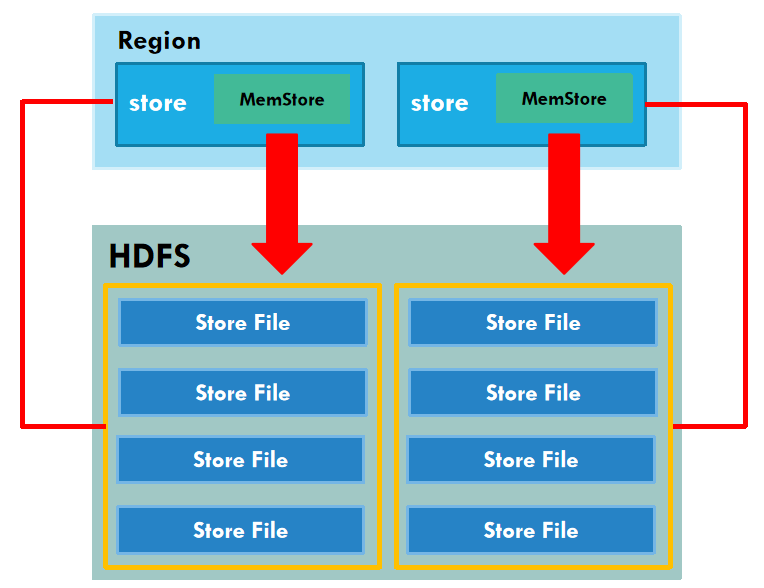
MemStore刷写时机:
- 当某个memstore的大小达到了 hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。
- 当单个 MemStore 的大小达到 hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier时,触发写阻塞。此时 RegionServer 会暂停对该 MemStore 对应 Region 的所有写操作,直到刷盘完成、MemStore 内存释放到阈值以下。
- 当region server中memstore的总大小达到
hbase.regionserver.global.memstore.size.lower.limit (与java_heapsize相关)时,按Region 的 MemStore 总大小,由大到小排序,依次刷写整个 Region 的所有 MemStore,直到 RegionServer 总 MemStore 大小降到
lower.limit以下 。 -
当region server中memstore的总大小达到hbase.regionserver.global.memstore.size(与java_heapsize相关)时,会优先阻塞 MemStore 占用内存最大的 Region 的写操作,若刷盘后总大小仍未下降,会逐步扩大阻塞范围,极端情况下会阻止往所有 MemStore 写数据。
-
到达自动刷写的时间,也会触发 memstore flush 。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval (默认 1 小 时) 。
-
当 WAL 文件的数量超过 hbase.regionserver.max.logs , region会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.logs 以下(该属性名已经废弃,现无需手动设置,最大值为32)。
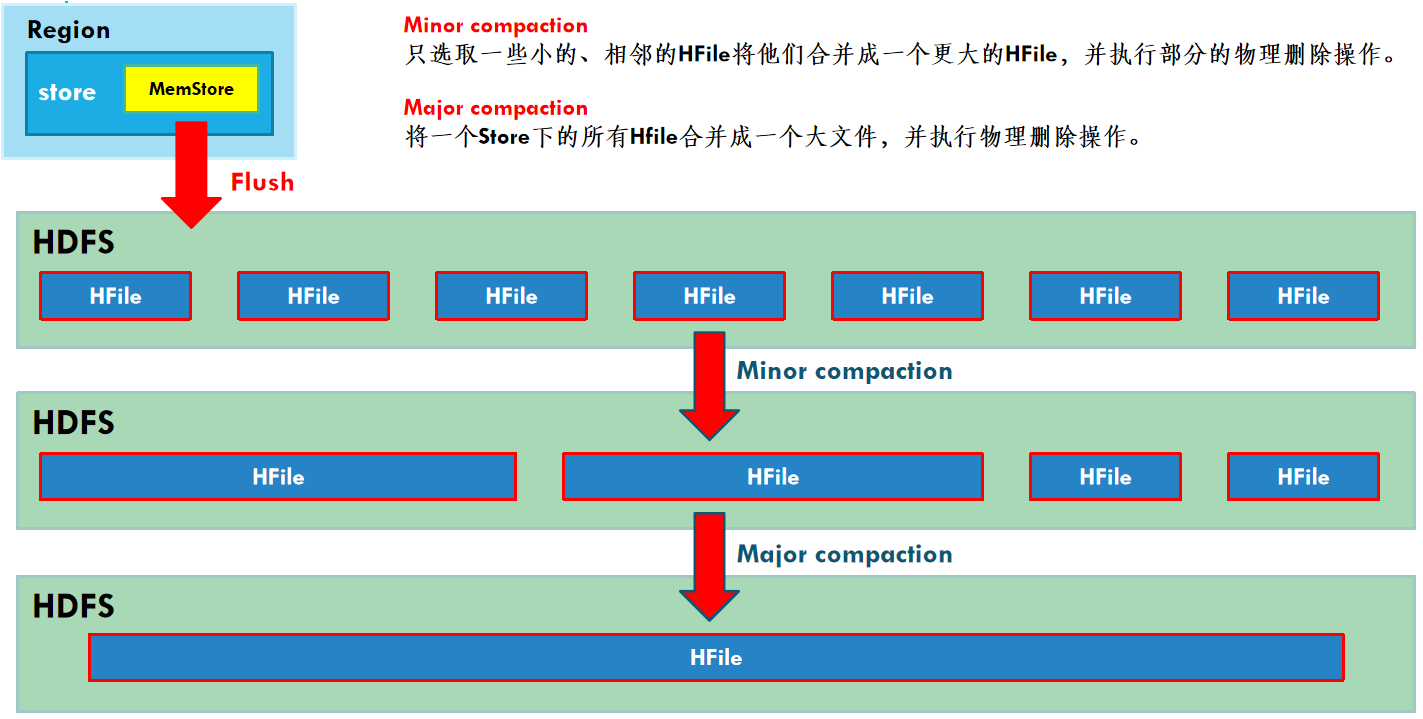
minor和major
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别是Minor Compaction和MajorCompaction。 Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
注意:
删除数据时,不会直接修改storefile,因为hadoop不允许修改。 hbase会将删除的数据标志为已删除(给该数据添加墓碑标记),如果添加了墓碑标记,查询不到该数据。在minor和major合并的时候,将标记了墓碑标记的数据真正删除。
Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入, Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑, HMaster有可能会将某个Region转移给其他的Region Server。
表设计
用户角色表设计
1. 分析传统的人员角色表:
tb_user:id,username,nickname,sex,...
tb_role:id,name,desc,....
tb_user_role:user_id,role_id,created_date,created_by
用户表 角色表 用户和角色的关联关系表
关系型数据库中,表设计遵循三范式:
(1)主键 (2)每列不能再分 (3)外键关联
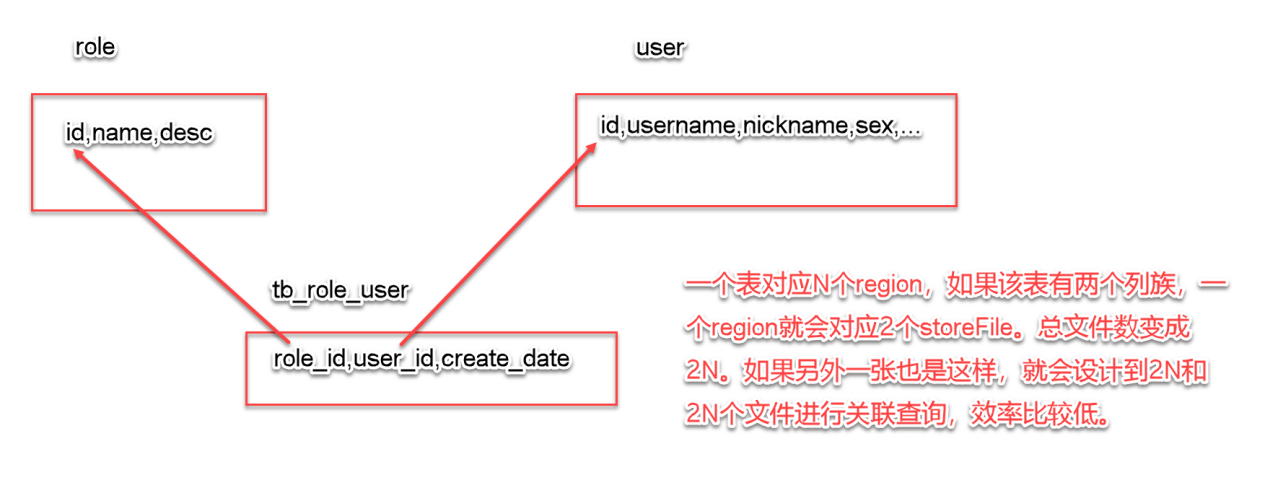
2. hbase的设计:

该方式不好,效率比较低。
为了满足数据的本地化存取,设计冗余字段。
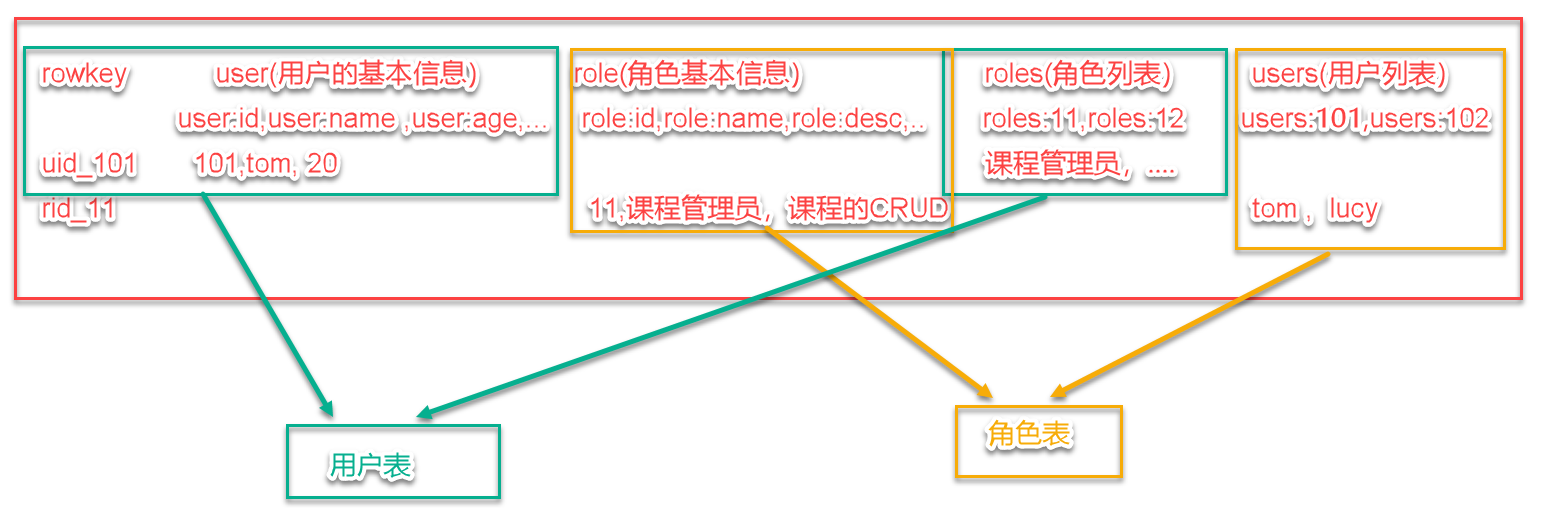
用户表user:
|
rowkey |
base(人员信息) |
roles(角色列表) |
|||
|
base:name |
base:age |
roles: |
roles: |
…… |
|
|
uid人员编号 |
人员名称 |
年龄 |
优先级1(名称) |
优先级2 |
对用户基本信息的操作是只需要操作base列族中的信息即可。不涉及到roles列族。比如要查询某用户都有哪些角色,只需要查询roles列族中的信息即可。
角色表:
|
rowkey |
base |
users(用户列表) |
|||
|
base:name |
base:desc |
users: |
users: |
…… |
|
|
角色编号 |
角色名称 |
角色描述 |
name1 |
name2 |
基本信息操作时,只需要操作base列族中的信息即可。如果需要查询某个角色都被哪些用户授予了,只需要查询users列族中的用户列表即可。
例子
用户表记录:
1001 base:name=百里守约 base:age=25 roles:101=射手,roles:102=刺客
1002 base:name=凯 base:age=32 roles:103=战士,roles:104=坦克
1003 base:name=亚瑟 base:age=45 roles:104=坦克,roles:103=战士
1004 base:name=李元芳 base:age=32 roles:101=射手 roles:102=刺客
角色表记录:
101 base:name=射手 base:desc=输出 users:1001=百里守约,users:1004=李元芳
102 base:name=刺客 base:desc=收割 users:1001=百里守约,users:1004=李元芳
103 base:name=战士 base:desc=近战 users:1002=凯,users:1003=亚瑟
104 base:name=坦克 base:desc=开路 users:1002=凯,users:1003=亚瑟
注意:最好通过冗余的方式在一条记录中查到所有需要的信息,避免跨主机查询数据。
查询数据最好通过rowkey直接查询,不要扫描,扫描过滤比较慢。
组织(或分类)表设计
组织架构 部门-子部门
数据如下:
id name parent_id
1 北京分公司 -1
2 上海分公司 -1
3 朝阳分公司 1
4 海淀分公司 1
5 中关村 4
有层次关系的结构,一张表搞定(自关联)!
hbase的表设计:
|
RowKey |
base(部门信息) |
child(子部门列表) |
||||
|
base:name |
base:desc |
base:pid |
child: |
child: |
…… |
|
|
(0|1)_部门编号 |
部门名称 |
部门描述 |
上级部门id |
子部门1 |
子部门2 |

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)